
A Full-Scale Feature Fusion Siamese Network for Remote Sensing Change Detection


Abstract
:1. Introduction
2. Materials and Methods
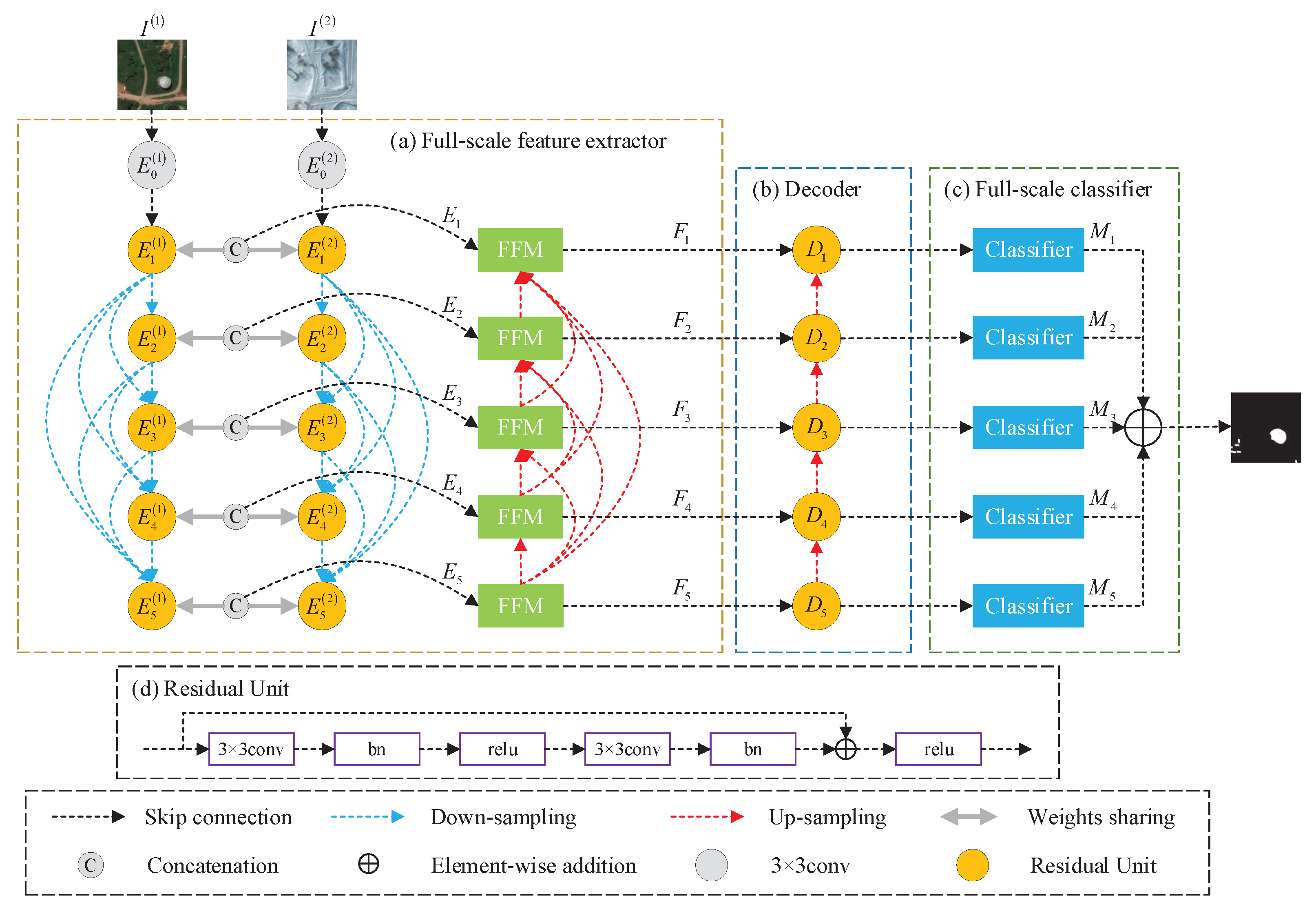
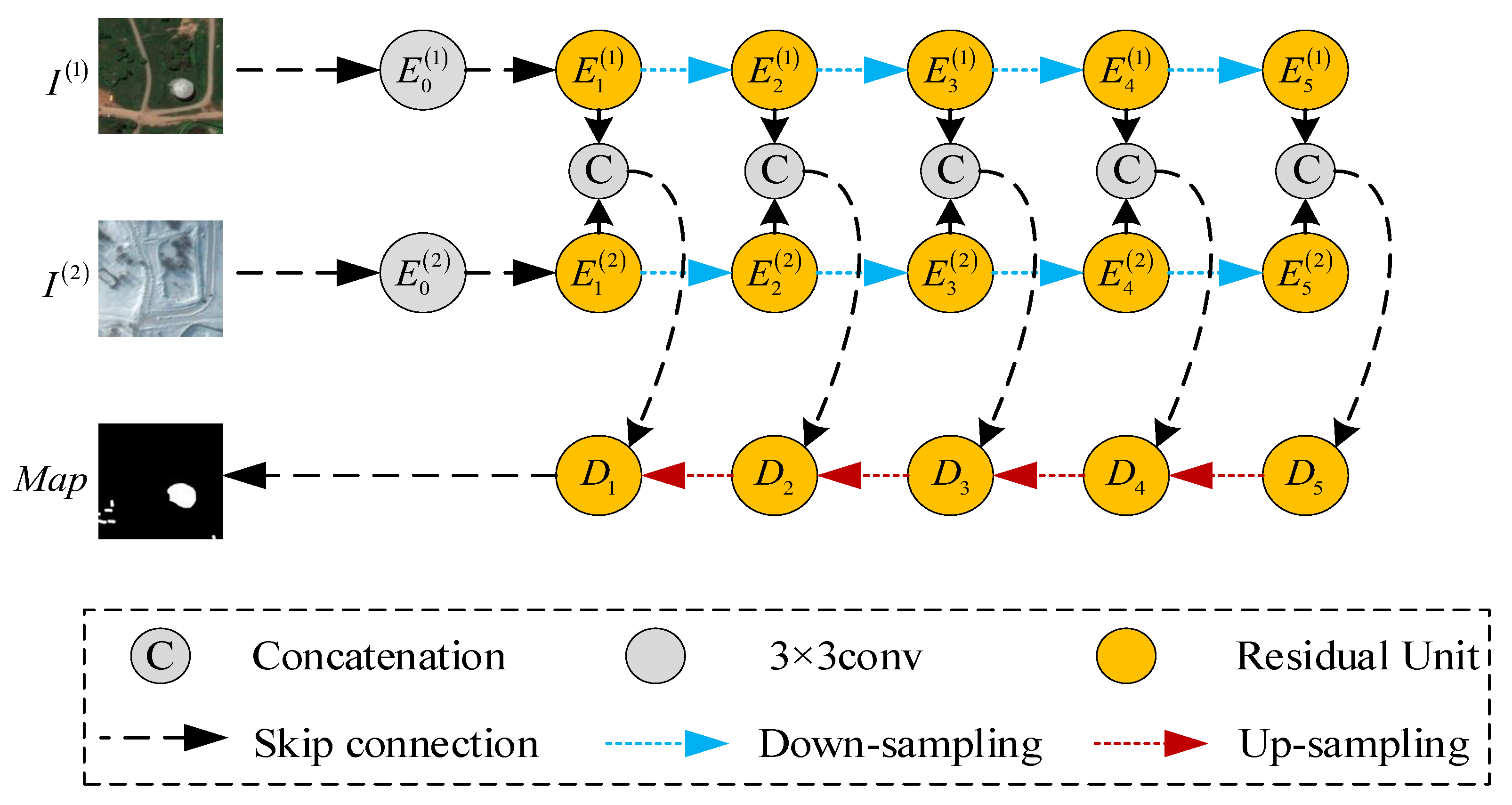
2.1. Full-Scale Feature Extractor (FFE)
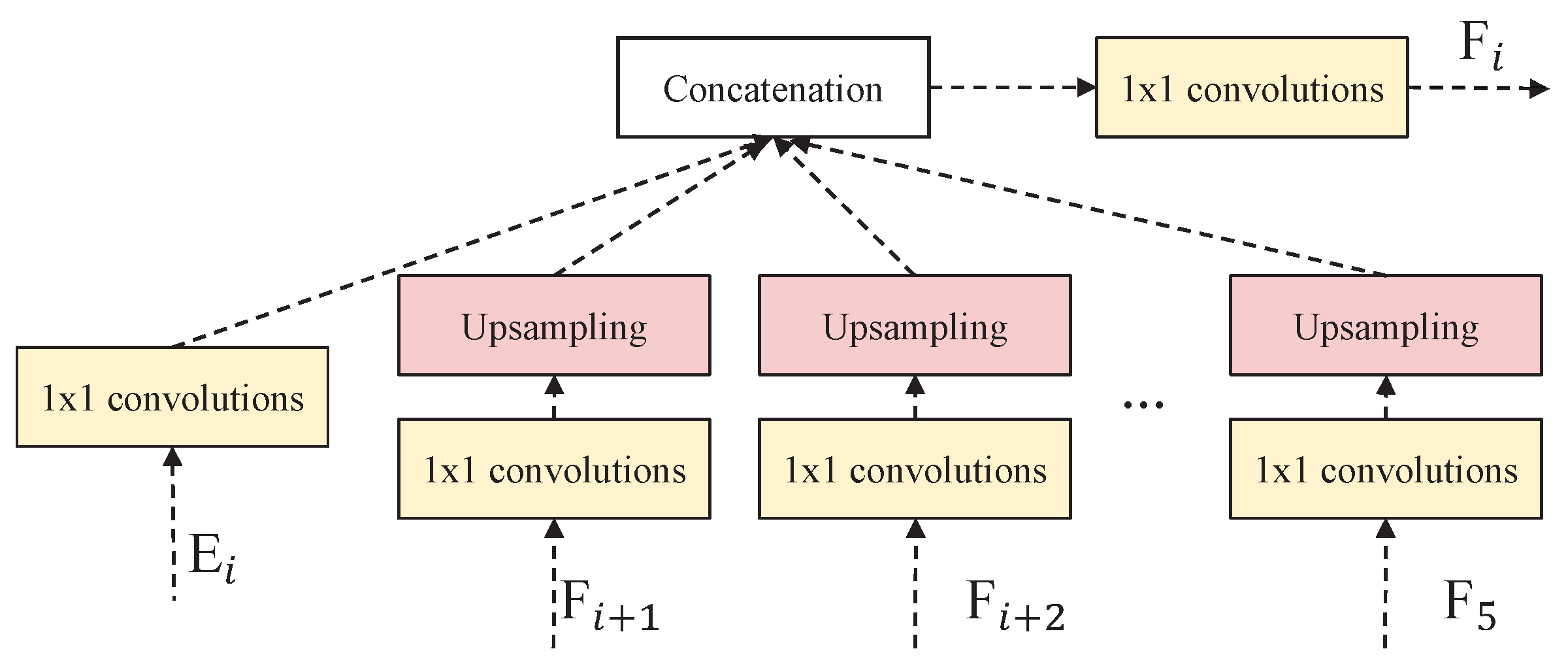
2.2. Decoder and Full-Scale Classifier (FC)
3. Experiments
3.1. Data Set
3.2. Metrics and Implementation Details
3.3. Experimental Results
3.3.1. Comparison with Other Methods
- FC-EF [25]: The EF architecture concatenates bi-temporal images as different color channels and feeds them into a convolutional neural network.
- FC-Siam-conc [25]: A combination of siamese networks and UNet. The deep features of the raw image are extracted by the two-stream encoder and then fed into the decoder to extract the change semantic information further.
- FC-Siam-diff [25]: Deep features of the raw images are extracted by a siamese network, and the feature differences are fed into the decoder.
- IFN [26]: The pre-trained VGG-16 is used as a branch of the two-stream encoder, and the attention module is used to guide a better fusion of the feature maps of the encoder and decoder.
- DASNet [33]: Through the dual-attention mechanism, long-range dependencies are captured to obtain more discriminative feature representations.
- STANet [34]: A siamese-based spatial-temporal attention neural network, which partitions the image into multi-scale subregions and introduces self-attention into all sub-regions.
- SNUNet [30]: A combination of the Siamese network and the NestedUNet, which alleviates the loss of localization information in deeper layers by reusing shallow features.
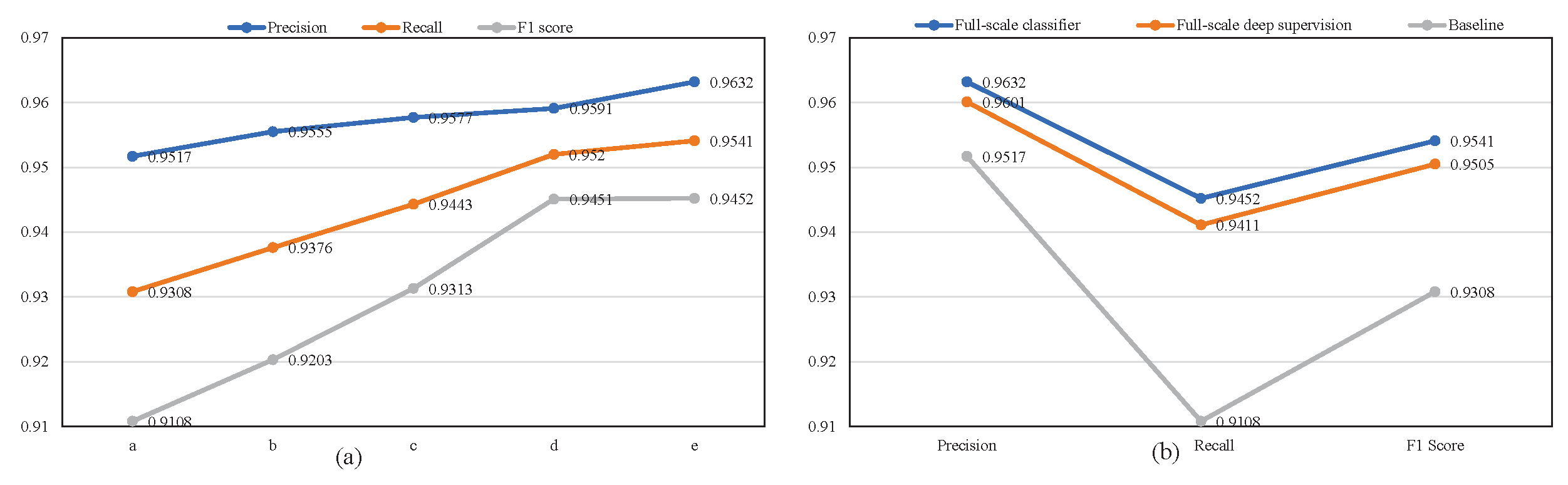
3.3.2. Ablation Study for Full-Scale Feature Extractor (FFE) and Full-Scale Classifier (FC)
3.3.3. Visualization of FFE and FC Effect
3.3.4. Comparison with Wider Baseline
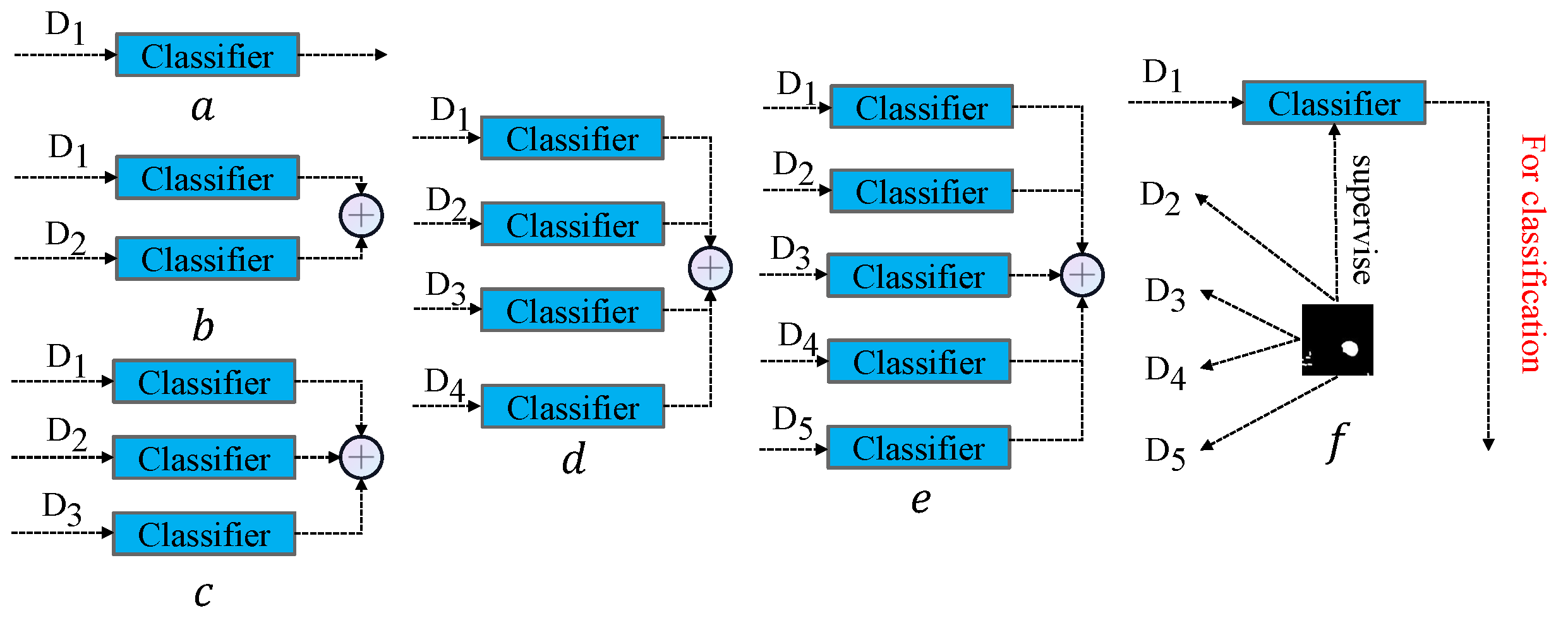
3.3.5. Evaluation of Full-Scale Classifiers
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Eismann, M.T.; Meola, J.; Hardie, R.C. Hyperspectral Change Detection in the Presenceof Diurnal and Seasonal Variations. IEEE Trans. Geosci. Remote Sens. 2008, 46, 237–249. [Google Scholar] [CrossRef]
- Choi, E.; Kim, J. Robust Change Detection Using Channel-Wise co-Attention-Based Siamese Network With Contrastive Loss Function. IEEE Access 2022, 10, 45365–45374. [Google Scholar] [CrossRef]
- Zhou, Y.; Feng, Y.; Huo, S.; Li, X. Joint Frequency-Spatial Domain Network for Remote Sensing Optical Image Change Detection. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5627114. [Google Scholar] [CrossRef]
- Nagatani, I.; Hayashi, M.; Watanabe, M.; Tadono, T.; Watanabe, T.; Koyama, C.; Shimada, M. Seasonal Change Analysis for ALOS-2 PALSAR-2 Deforestation Detection. In Proceedings of the IGARSS 2020–2020 IEEE International Geoscience and Remote Sensing Symposium, Waikoloa, HI, USA, 26 September–2 October 2020; pp. 3807–3810. [Google Scholar]
- Zhang, J.; Pan, B.; Zhang, Y.; Liu, Z.; Zheng, X. Building Change Detection in Remote Sensing Images Based on Dual Multi-Scale Attention. Remote Sens. 2022, 14, 5405. [Google Scholar] [CrossRef]
- Jiang, J.; Xiang, J.; Yan, E.; Song, Y.; Mo, D. Forest-CD: Forest Change Detection Network Based on VHR Images. IEEE Geosci. Remote. Sens. Lett. 2022, 19, 2506005. [Google Scholar] [CrossRef]
- Li, L.; Ma, H.; Jia, Z. Multiscale geometric analysis fusion-based unsupervised change detection in remote sensing images via FLICM Model. Entropy 2022, 24, 291. [Google Scholar] [CrossRef]
- Arjasakusuma, S.; Kusuma, S.S.; Melati, P.; Hafiudzan, A. Change Detection Analysis using Bitemporal PRISMA Hyperspectral Data: Case Study of Magelang and Boyolali Districts, Central Java Province, Indonesia. J. Indian Soc. Remote. Sens. 2022, 50, 1803–1811. [Google Scholar] [CrossRef]
- Soto, P.J.; Costa, G.A.; Feitosa, R.Q.; Ortega, M.X.; Bermudez, J.D.; Turnes, J.N. Domain-Adversarial Neural Networks for Deforestation Detection in Tropical Forests. IEEE Geosci. Remote Sens. Lett. 2022, 19, 2504505. [Google Scholar] [CrossRef]
- Marinelli, D.; Coops, N.C.; Bolton, D.K.; Bruzzone, L. An unsupervised change detection method for lidar data in forest areas based on change vector analysis in the polar domain. In Proceedings of the IGARSS 2018—2018 IEEE International Geoscience and Remote Sensing Symposium, Valencia, Spain, 22–27 July 2018; pp. 1922–1925. [Google Scholar]
- Verma, H.C.; Ahmed, T.; Rajan, S.; Hasan, M.K.; Khan, A.; Gohel, H.; Adam, A. Development of LR-PCA Based Fusion Approach to Detect the Changes in Mango Fruit Crop by Using Landsat 8 OLI Images. IEEE Access 2022, 10, 85764–85776. [Google Scholar] [CrossRef]
- Sadeghi, V.; Etemadfard, H. Optimal cluster number determination of FCM for unsupervised change detection in remote sensing images. Earth Sci. Inform. 2022, 15, 1045–1057. [Google Scholar] [CrossRef]
- Martinez-Izquierdo, M.d.E.; Molina-Sánchez, I.; Morillo-Balsera, M.d.C. Efficient Dimensionality Reduction using Principal Component Analysis for Image Change Detection. IEEE Lat. Am. Trans. 2019, 17, 540–547. [Google Scholar] [CrossRef]
- Toure, S.; Diop, O.; Kpalma, K.; Maiga, A.S. Shoreline Detection using Optical Remote Sensing: A Review. ISPRS Int. J. Geo-Inf. 2019, 8, 75. [Google Scholar] [CrossRef] [Green Version]
- Han, T.; Wulder, M.A.; White, J.C.; Coops, N.C.; Alvarez, M.F.; Butson, C. An Efficient Protocol to Process Landsat Images for Change Detection With Tasselled Cap Transformation. IEEE Geosci. Remote Sens. Lett. 2007, 4, 147–151. [Google Scholar] [CrossRef]
- Gong, M.; Yang, H.; Zhang, P. Feature learning and change feature classification based on deep learning for ternary change detection in SAR images. ISPRS J. Photogramm. Remote Sens. 2017, 129, 212–225. [Google Scholar] [CrossRef]
- Grinblat, G.L.; Uzal, L.C.; Granitto, P.M. Abrupt change detection with One-Class Time-Adaptive Support Vector Machines. Expert Syst. Appl. 2013, 40, 7242–7249. [Google Scholar] [CrossRef] [Green Version]
- Fanara, L.; Gwinner, K.; Hauber, E.; Oberst, J. Automated detection of block falls in the north polar region of Mars. Planet. Space Sci. 2020, 180, 104733. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; Springer: Cham, Switzerland, 2015; pp. 234–241. [Google Scholar]
- Lv, Z.; Wang, F.; Cui, G.; Benediktsson, J.A.; Lei, T.; Sun, W. Spatial–Spectral Attention Network Guided with Change Magnitude Image for Land Cover Change Detection Using Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2022, 60, 4412712. [Google Scholar] [CrossRef]
- Zheng, H.; Gong, M.; Liu, T.; Jiang, F.; Zhan, T.; Lu, D.; Zhang, M. HFA-Net: High frequency attention siamese network for building change detection in VHR remote sensing images. Pattern Recognit. 2022, 129, 108717. [Google Scholar] [CrossRef]
- Zhou, Z.; Rahman Siddiquee, M.M.; Tajbakhsh, N.; Liang, J. UNet++: A Nested U-Net Architecture for Medical Image Segmentation. In Deep Learning in Medical Image Analysis and Multimodal Learning for Clinical Decision Support; Springer International Publishing: Cham, Switzerland, 2018; pp. 3–11. [Google Scholar]
- Raza, A.; Huo, H.; Fang, T. EUNet-CD: Efficient UNet++ for Change Detection of Very High-Resolution Remote Sensing Images. IEEE Geosci. Remote Sens. Lett. 2022, 19, 3510805. [Google Scholar] [CrossRef]
- Peng, X.; Zhong, R.; Li, Z.; Li, Q. Optical Remote Sensing Image Change Detection Based on Attention Mechanism and Image Difference. IEEE Trans. Geosci. Remote Sens. 2021, 59, 7296–7307. [Google Scholar] [CrossRef]
- Caye Daudt, R.; Le Saux, B.; Boulch, A. Fully Convolutional Siamese Networks for Change Detection. In Proceedings of the 2018 25th IEEE International Conference on Image Processing (ICIP), Athens, Greece, 7–10 October 2018; pp. 4063–4067. [Google Scholar]
- Zhang, C.; Yue, P.; Tapete, D.; Jiang, L.; Shangguan, B.; Huang, L.; Liu, G. A deeply supervised image fusion network for change detection in high resolution bi-temporal remote sensing images. ISPRS J. Photogramm. Remote Sens. 2020, 166, 183–200. [Google Scholar] [CrossRef]
- Ji, S.; Wei, S.; Lu, M. Fully Convolutional Networks for Multisource Building Extraction From an Open Aerial and Satellite Imagery Data Set. IEEE Trans. Geosci. Remote Sens. 2019, 57, 574–586. [Google Scholar] [CrossRef]
- Bao, T.; Fu, C.; Fang, T.; Huo, H. PPCNET: A Combined Patch-Level and Pixel-Level End-to-End Deep Network for High-Resolution Remote Sensing Image Change Detection. IEEE Geosci. Remote Sens. Lett. 2020, 17, 1797–1801. [Google Scholar] [CrossRef]
- Yu, B.; Chen, F.; Wang, Y.; Wang, N.; Yang, X.; Ma, P.; Zhou, C.; Zhang, Y. Res2-Unet+, a Practical Oil Tank Detection Network for Large-Scale High Spatial Resolution Images. Remote Sens. 2021, 13, 4740. [Google Scholar] [CrossRef]
- Fang, S.; Li, K.; Shao, J.; Li, Z. SNUNet-CD: A Densely Connected Siamese Network for Change Detection of VHR Images. IEEE Geosci. Remote Sens. Lett. 2021, 19, 8007805. [Google Scholar] [CrossRef]
- Li, X.; Du, Z.; Huang, Y.; Tan, Z. A deep translation (GAN) based change detection network for optical and SAR remote sensing images. ISPRS J. Photogramm. Remote Sens. 2021, 179, 14–34. [Google Scholar] [CrossRef]
- Chen, Z.; Zhou, Y.; Wang, B.; Xu, X.; He, N.; Jin, S.; Jin, S. EGDE-Net: A building change detection method for high-resolution remote sensing imagery based on edge guidance and differential enhancement. ISPRS J. Photogramm. Remote Sens. 2022, 191, 203–222. [Google Scholar] [CrossRef]
- Chen, J.; Yuan, Z.; Peng, J.; Chen, L.; Huang, H.; Zhu, J.; Liu, Y.; Li, H. DASNet: Dual Attentive Fully Convolutional Siamese Networks for Change Detection in High-Resolution Satellite Images. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 1194–1206. [Google Scholar] [CrossRef]
- Chen, H.; Shi, Z. A spatial-temporal attention-based method and a new dataset for remote sensing image change detection. Remote Sens. 2020, 12, 1662. [Google Scholar] [CrossRef]
- Fu, J.; Liu, J.; Tian, H.; Li, Y.; Bao, Y.; Fang, Z.; Lu, H. Dual Attention Network for Scene Segmentation. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–17 June 2019; pp. 3141–3149. [Google Scholar]
- Zhou, T.; Wang, S.; Zhou, Y.; Yao, Y.; Li, J.; Shao, L. Motion-Attentive Transition for Zero-Shot Video Object Segmentation. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 13066–13073. [Google Scholar]
- Song, A.; Choi, J.; Han, Y.; Kim, Y. Change Detection in Hyperspectral Images Using Recurrent 3D Fully Convolutional Networks. Remote Sens. 2018, 10, 1827. [Google Scholar] [CrossRef]
- Ibtehaz, N.; Rahman, M.S. MultiResUNet: Rethinking the U-Net architecture for multimodal biomedical image segmentation. Neural Networks 2020, 121, 74–87. [Google Scholar] [CrossRef] [PubMed]
- Lebedev, M.; Vizilter, Y.V.; Vygolov, O.; Knyaz, V.; Rubis, A.Y. Change detection in remote sensing images using conditional adversarial networks. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2018, 42, 565–571. [Google Scholar] [CrossRef] [Green Version]
- He, H.; Chen, Y.; Li, M.; Chen, Q. ForkNet: Strong Semantic Feature Representation and Subregion Supervision for Accurate Remote Sensing Change Detection. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2022, 15, 2142–2153. [Google Scholar] [CrossRef]
- Wang, J.; Sun, K.; Cheng, T.; Jiang, B.; Deng, C.; Zhao, Y.; Liu, D.; Mu, Y.; Tan, M.; Wang, X.; et al. Deep High-Resolution Representation Learning for Visual Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 43, 3349–3364. [Google Scholar] [CrossRef]
- Lal, S.; Nalini, J.; Reddy, C.S. DIResUNet: Architecture for multiclass semantic segmentation of high resolution remote sensing imagery data. Appl. Intell. 2022, 52, 15462–15482. [Google Scholar]
- Zhou, R.H.M.; Xing, Y.; Zou, Y.; Fan, W. Change detection with various combinations of fluid pyramid integration networks. Neurocomputing 2021, 437, 84–94. [Google Scholar]
- Xu, J.; Luo, Y.; Chen, X.; Luo, C. An Adaptive Multi-Scale and Multi-Level Features Fusion Network with Perceptual Loss for Change Detection. In Proceedings of the ICASSP 2021–2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Toronto, ON, Canada, 6–11 June 2021; pp. 2275–2279. [Google Scholar]
- Chen, H.; Wu, C.; Du, B.; Zhang, L. Deep Siamese Multi-scale Convolutional Network for Change Detection in Multi-temporal VHR Images. In Proceedings of the 2019 10th International Workshop on the Analysis of Multitemporal Remote Sensing Images (MultiTemp), Shanghai, China, 5–7 August 2019; pp. 1–4. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | FLOPs (G) | CDD | LEVIR-CD | ||||||
|---|---|---|---|---|---|---|---|---|---|
| Pre | Rec | F1 | IoU | Pre | Rec | F1 | IoU | ||
| FC-EF | 7.14 | 0.749 | 0.494 | 0.595 | 0.423 | 0.754 | 0.730 | 0.742 | 0.590 |
| FC-Siam-con | 10.64 | 0.779 | 0.622 | 0.692 | 0.529 | 0.852 | 0.736 | 0.790 | 0.653 |
| FC-Siam-diff | 9.44 | 0.786 | 0.588 | 0.673 | 0.507 | 0.861 | 0.687 | 0.764 | 0.618 |
| IFN | 164.58 | 0.950 | 0.861 | 0.903 | 0.823 | 0.903 | 0.876 | 0.889 | 0.800 |
| STANet | 25.76 | 0.863 | 0.760 | 0.787 | 0.649 | 0.838 | 0.910 | 0.873 | 0.775 |
| DASNet | 113.09 | 0.914 | 0.925 | 0.919 | 0.850 | 0.811 | 0.788 | 0.799 | 0.665 |
| SNUNet | 109.62 | 0.956 | 0.949 | 0.953 | 0.910 | 0.889 | 0.874 | 0.881 | 0.787 |
| F3SNet/8 | 3.24 | 0.952 | 0.907 | 0.929 | 0.867 | 0.913 | 0.898 | 0.905 | 0.826 |
| F3SNet/16 | 12.56 | 0.964 | 0.944 | 0.954 | 0.912 | 0.917 | 0.897 | 0.907 | 0.830 |
| F3SNet/24 | 27.98 | 0.967 | 0.964 | 0.966 | 0.934 | 0.907 | 0.908 | 0.907 | 0.830 |
| F3SNet/32 | 49.49 | 0.970 | 0.965 | 0.968 | 0.938 | 0.919 | 0.900 | 0.909 | 0.833 |
| Method | FC-EF | IFN | DASNet | SNUNet | F3SNet/8 | F3SNet/32 |
|---|---|---|---|---|---|---|
| Train Time (s/epoch) | 179 | 1218 | 926 | 745 | 133 | 546 |
| Testing Time (s) | 31 | 84 | 79 | 70 | 32 | 55 |
| Parameters (M) | 1.35 | 35.72 | 16.25 | 12.03 | 0.97 | 15.77 |
| Index | FFE | FC | Par (M) | GFLOPs | Pre | Rec | F1 | IOU |
|---|---|---|---|---|---|---|---|---|
| 1 | 13.54 | 43.89 | 0.9517 | 0.9108 | 0.9308 | 0.8706 | ||
| 2 | ✓ | 15.76 | 49.47 | 0.9665 | 0.9530 | 0.9597 | 0.9225 | |
| 3 | ✓ | 13.55 | 43.91 | 0.9632 | 0.9452 | 0.9541 | 0.9123 | |
| 4 | ✓ | ✓ | 15.77 | 49.49 | 0.9701 | 0.9657 | 0.9679 | 0.9378 |
| Model | Channels | Params (M) | Pre | Rec | F1 | IOU |
|---|---|---|---|---|---|---|
| baseline | 32 | 13.54 | 0.9517 | 0.9108 | 0.9308 | 0.8706 |
| baseline | 35 | 16.20 | 0.9558 | 0.9109 | 0.9328 | 0.8741 |
| baseline | 32 | 15.76 | 0.9665 | 0.9530 | 0.9597 | 0.9225 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhou, H.; Song, M.; Sun, K. A Full-Scale Feature Fusion Siamese Network for Remote Sensing Change Detection. Electronics 2023, 12, 35. https://doi.org/10.3390/electronics12010035
Zhou H, Song M, Sun K. A Full-Scale Feature Fusion Siamese Network for Remote Sensing Change Detection. Electronics. 2023; 12(1):35. https://doi.org/10.3390/electronics12010035
Chicago/Turabian StyleZhou, Huaping, Minglong Song, and Kelei Sun. 2023. "A Full-Scale Feature Fusion Siamese Network for Remote Sensing Change Detection" Electronics 12, no. 1: 35. https://doi.org/10.3390/electronics12010035