1. Introduction
With the COVID-19 pandemic, there were disruptions in many sectors including education. Young people in Turkey had to continue their education with the courses given online and through television. In face-to-face lessons, teachers can easily monitor if students follow the subject and the course flow is directed accordingly. It is important to determine instantly how much the education has reached to the students and to direct the course accordingly. In this project, it was aimed to recognize the student in e-learning and to measure if the student concentrates on the lesson, to determine and analyze the non-verbal behaviors of the students during the lesson through image processing techniques.
Just like the teacher observes the classroom, the e-learning system must also see and observe the student. In the field of computer vision, subjects, such as object recognition, face detection, face tracking, face recognition, emotion recognition, human action recognition/tracking, classification of gender/age, driver drowsiness detection, gaze detection, and head pose estimation are among the subjects that attract many researchers and are being studied extensively.
Detecting and analyzing human behavior with image processing techniques has also gained popularity in recent times and significant studies have been carried out in different fields.
It is important for students to pay attention to the teacher and the lesson in order to learn the relevant lesson. One of the most important indicators showing that the student pays attention to the lesson and the teacher is that the student is looking towards the teacher.
In this study, it was aimed to find the real-time distraction rates and real-time recognition of students in the classroom or in front of the computer by using images taken from the camera, image processing techniques, and machine learning algorithms. An algorithm has been developed to organize the learning materials in a way to increase interest by providing instant feedback from the obtained data to the teacher or autonomous lecture system. Before going into the details about the study, it will be useful to mention what is student engagement and the symptoms of distraction which are a good indicator to detect student engagement.
The Australian Council of Educational Research defines student engagement as “students’ involvement with activities and conditions likely to generate high quality learning” [
1]. According to Kuh: “Student engagement represents both the time and energy students invest in educationally purposeful activities and the effort institutions devote to using effective educational practices” [
2].
Student engagement is a significant contributor to student success. Several research projects made with students reveal the strong relation between student engagement and academic achievement [
3,
4]. Similarly, Trowler, who published a comprehensive literature review on student engagement, stated that a remarkable amount of literature has established robust correlations between student involvement and positive outcomes of student success and development [
5].
As cited by Fredrickj et al. [
6], student engagement has three dimensions: behavioral, cognitive, and emotional engagement. Behavioral engagement refers to student’s participation and involvement in learning activities. Cognitive engagement corresponds to student’s psychological investment in the learning process, such as being thoughtful and focusing on achieving goals. On the other hand, emotional engagement can be understood as the student’s relationship with his/her teacher and friends; feelings about learning process, such as being happy, sad, bored, angry, interested, and disappointed.
Observable symptoms of distraction in students can be listed as looking away from the teacher or the object to be focused on, dealing with other things, closing eyes, dozing off, not perceiving what is being told. While these symptoms can be easily perceived by humans, detecting them via computer is a subject that is still being studied and keeps up to date. Head pose, gaze, and facial expressions are the main contributors to behavioral and emotional engagement. Automated engagement detection studies are mostly based on these features. In order to detect the gaze direction for determining distraction, methods such as image processing techniques, following head pose and eye movements with the help of a device attached to the person’s head and processing the EEG signals of the person, were utilized in several studies.
In this study, we focus on behavioral engagement, since its symptoms, such as drowsiness, looking at an irrelevant place can be detected explicitly, and we prefer using image processing techniques for recognizing students and detecting student engagement due to their easy applicability and low cost.
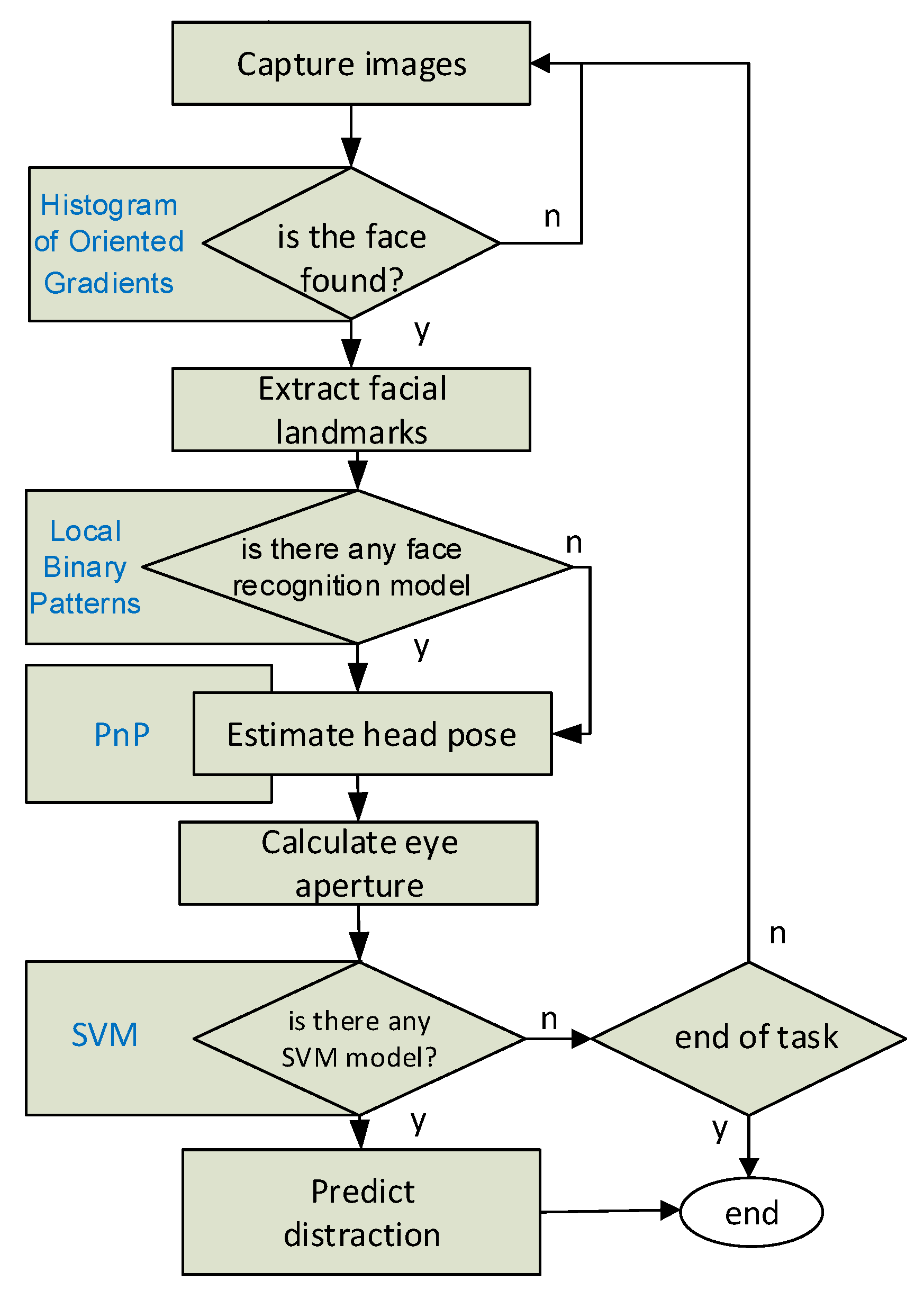
By processing the real-time images of the students in the classroom or in front of the computer captured by a CMOS camera, with the help of image processing and machine learning technologies, we obtain the following results:
Face recognition models of the students were created, students’ faces were recognized using these models and course attendance was reported by the application we developed;
Face detection and tracking were performed in real time for each student;
Facial landmarks for each student were extracted and used at the stage of estimating head pose and calculating Eye Aspect Ratio;
Engagement result was determined both for the classroom and each student by utilizing head pose estimation and Eye Aspect Ratio.
There are research works and various applications on the determination of distraction in numerous fields, such as education, health, and driving safety. This study was carried out to recognize a student in a classroom or in front of a computer and to estimate his/her attention to the lesson.
The literature review was made under two main titles including the studies conducted on face recognition to identify student participating in the lesson and determining the distraction and gaze direction of the students taking the course.
Studies on Face Recognition:
Passwords, PINs, smart cards, and techniques based on biometrics are used in the authentication of individuals in physical and virtual environment. Passwords, PINs can be stolen, guessed or forgotten but biometric characteristics of a person cannot be forgotten, lost, stolen, and imitated [
7].
With the developments in computer technology, techniques that do not require interaction based on biometrics have come to the fore in the identification of individuals. While characteristics, such as face, ear, fingerprint, hand veins, palm, hand geometry, iris, retina, etc., are frequently used in the recognition based on physiological properties, characteristics, such as walking type, signature, and the way of pushing a button, are used in the recognition based on behavioral properties.
There are many identification techniques based on biometrics that make it possible to identify the individuals or verify them. While fingerprint-based verification has reliable accuracy rates, face recognition provides lower accuracy rates due to reasons, such as using flash, image quality, beard, mustache, glasses, etc. However, while a fingerprint reader device is needed for fingerprint recognition and also the person needs to scan his/her fingers on this device, only a camera will be fine to capture images of people. That is why face recognition has become widespread recently.
The first step in computer-assisted face recognition is to detect the face in the video image (face detection). After the face is detected, the face obtained from the video image is cropped and normalized by considering the factors such as lighting and picture size (preprocessing). The features on the face are extracted (feature extraction) and training is performed using these features. By classifying with the most suitable image among the features in the database, face recognition is achieved.
Bledsoe, Chan, and Bisson carried out various studies on face recognition with a computer in 1964 and 1965 [
8,
9,
10].
A small portion of Bledsoe’s work has only been published because an intelligence agency sponsoring the project allowed only limited sharing of the results of the study. In the study, images matching or resembling with an image questioned in a large database formed a subset. It was stated that the success of the method can be measured in terms of the ratio of the number of photos in the answer list to the total number of pictures in the database [
11].
Bledsoe reported that parameters in face recognition problem, such as head pose, lighting intensity and angle, facial expressions, and age, affect the result [
9]. In the study, the coordinates associated with the feature set in the photos (center of the pupil, inner corner of the eye, outer corner of the eye, mid-point of the hair-forehead line, etc.) were derived by an operator and these coordinates were used by the computer. For this reason, he named his project “man-machine”. A total of 20 different distances (such as lip width, width of eyes, pupillary distance, etc.) were calculated from these coordinates. It was stated that people doing this job can process 40 photos per hour. While forming the database, distances related to a photograph and the name of the person in that photograph were associated and saved to the computer. In the recognition phase, distance associated with the photograph in question were compared with the distances in each photograph in the database and the most compatible records were found.
In recent years, significant improvement has been made also in face recognition and some groundbreaking methods have emerged in this field. Now, let us check some of these methods and studies.
The Eigenfaces method uses the basic components of the face space and the projection of the face vectors onto the basic components. It was used by Sirovich and Kirby for the first time to express the face effectively [
12]. This method is based of Principal Component Analysis (PCA), which is a statistical approach or the Karhunen–Loève extension. The purpose of this method is to find the basic components affecting the variety in pictures the most. In this way, images in the face space can be expressed in a subspace with lower dimension. It is based on a holistic approach. Since this method is based on dimension reduction, recognition and learning processes are fast.
In their study, Turk and Pentland made this method more stable for face recognition. In this way, the use of this method has also accelerated [
13].
The Fisherfaces method is a method based on a holistic approach that was found as an alternative to the Eigenfaces method [
14]. The Fisherfaces method is based on reducing the dimension of the feature space in the face area using the Principal Component Analysis (PCA) method and then applying the LDA method formulated by Fisher—also known as the Fisher’s Linear Discriminant (FLD) method—to obtain the facial features [
15].
Another method widely used in pattern recognition applications is the Local Binary Patterns method. This method was first proposed by Ojala et al. [
16,
17]. This method provides extraction of features statistically based on the local neighborhood; it is not a holistic method. It is preferred because it is not affected by light changes. The success of this method in face recognition has been demonstrated in the study conducted by [
18].
Another method that has started to be used widely in recent years in face recognition is deep learning. With the development of Backpropagation applied in the late 1980s [
19,
20], the deep learning method emerged. Deep learning suggests methods that better model the work of the human brain compared to artificial neural networks. Most of the algorithms used in deep learning are based on the studies made by Geoffrey Hinton and by the researcher from the University of Toronto. Since these algorithms presented in the 1980s required intensive matrix operations and high processing power to process big data, they did not have a widespread application area in those years.
Convolutional Neural Networks (CNN), which are a specialized architecture of deep learning gives successful results especially in the image processing field and are used more commonly in recent times [
21].
It can be said that the popularity of CNN constituting the basis of deep learning in the science world started when the team including Alex Krizhevsky, Ilya Sutskever, and Geoffrey E. Hinton won the “ImageNet Large Scale Visual Recognition Challenge-ILSVRC 2012” organized in 2012 by using this method [
22,
23].
In recent years, there are successful studies using YOLO V
3 (You only look once) algorithm [
24], which is an artificial neural network-based, for face detection, and Microsoft Azure (face database), which uses a face API for face recognition [
24].
Today, many open-source deep learning libraries and framework, including TensorFlow, Keras, Microsoft Cognitive Toolkit, Caffe, PyTorch, etc., are offered to users.
Studies on Determining Distraction and Gaze Direction
Correct determination of a person’s gaze direction is an important factor in daily interaction [
25,
26]. Gaze direction comes first among the parameters used in determining visual attention. The role of gaze direction in determining attention level was emphasized in a study conducted by [
25] in the 1970s and these findings were confirmed in later studies by [
27].
It is stated that the gaze direction defined as the direction the eyes point in space, is composed of head orientation and eye orientation. That is, in order to determine the true gaze direction, both directions must be known [
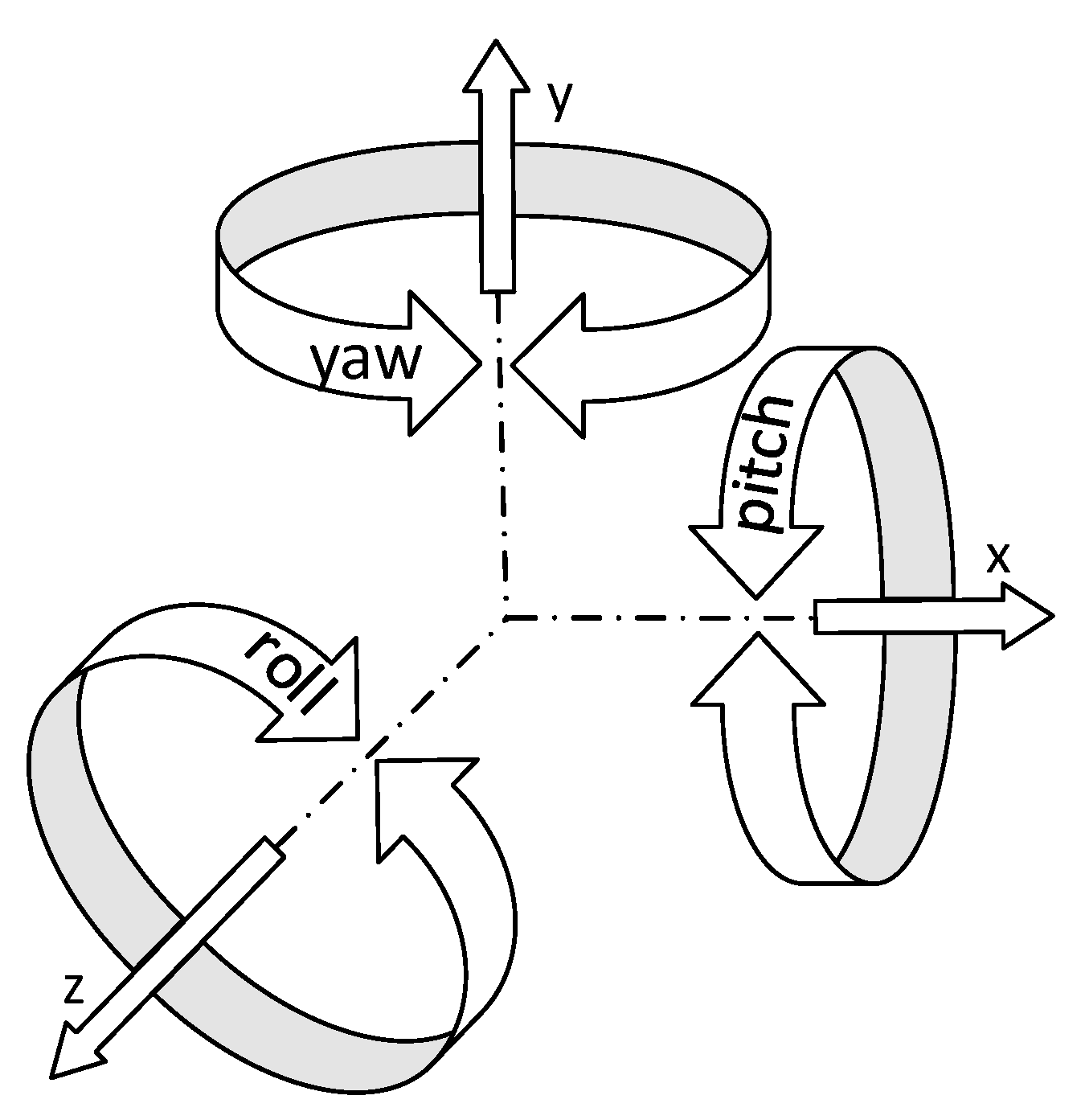
28]. In this study, it was revealed that head pose contributes to gaze direction by 68.9% and to the focus of attention by 88.7%. These results show that head pose is a good indicator for detecting distraction.
In other words, it can be said that the visual focus of attention (VFoA) of a person is closely related to his/her gaze direction and thus the head pose. Similarly, in the study conducted by [
29], head pose was used in determining the visual focus of attention of the participants in the meetings.
When the head and eye orientations are not in the same direction, two kinds of deviations in the perceived gaze direction were stated [
30,
31,
32,
33]. These two deviations in the literature are named as repulsive (overshoot) and attractive (attractive).
The study conducted by Wollaston, is one of the pioneers in this field [
34]. Starting from a portrait in which the eyes is pointing to the front and the head is directed to the left from our perspective, Wollaston draw a portrait with eyes copied from the previous image and the head directed to the right from our perspective and investigated the perceived gaze directions in these two portraits. Although the eyes in the two portraits are exactly the same, the person in the second portrait is perceived as looking to the right. Due to this study, the perception of gaze direction towards the side of the head pose is also called the Wollaston effect as well as the attractive effect [
32].
Three important articles were published on this topic in the 1960s [
35,
36,
37]. The results of two of these studies were investigated and interpreted in different ways by many authors. In the study conducted by Moors et al., the possible reasons for the confusion that causes these two studies to be interpreted in different ways, were discussed [
33]. In order to eliminate these uncertainties and clarify the issue, they repeated the experiments performed in both studies and found that there was a repulsive effect in both studies.
Although there are different interpretations and studies, it can be easily said that head pose has a significant effect on the gaze direction.
In their study, Gee and Cipolla also preferred image processing techniques [
38]. In the method they used, five points on the face (right eye, left eye, right and left end points of the mouth, and tip of the nose) were firstly determined. By using eye and mouth coordinates, the starting point of the nose above the mouth is found, and the gaze direction was detected with an acceptable accuracy by drawing a straight line (facial normal) from this point to the tip of the nose. This method which does not require much processing power was applied in real time in video images and the obtained results were shared.
Sapienza and Camilleri [
39] developed the method of Gee and Cipolla [
38] a little further and used 4 points by taking the midpoint of the mouth rather than two points used for the mouth. By using the Viola–Jones’ algorithm, face and facial features were detected, the facial features were tracked with the normalized sum of squared difference method and the head pose was estimated from the features followed using a geometric approach. This head-pose estimation system they designed found the head pose with a deviation of about 6 degrees in 2 ms.
In a study conducted in 2017 by Zaletelj and Kosir, students in the classroom were monitored with Kinect cameras, their body postures, gaze directions, and facial expressions were determined, features were extracted through computer vision techniques, and 7 separate classifiers were trained with 3 separate datasets using machine learning algorithms [
40]. Five observers were asked to estimate the attention levels of the students in the classroom for each second in their images and these data are included in the datasets and used as a reference during the training phase. The trained model was tested with a dataset of 18 people and an achievement of 75.3% was obtained in the automatic detection of distraction. Again, in another study conducted in the same year by Monkaresi et al. [
41], a success of 75.8% was obtained when reports were used during activity and 73.3% success was obtained when the reports after the activities were used in determining the attention of students using the Kinect sensor.
In Raca’s doctoral thesis titled “Camera-based estimation of student’s attention in class”, the students in the classroom were monitored with multiple cameras and the movements (yaw) of the students’ head direction in the horizontal plane were determined. The position of the teacher on the horizontal plane was determined by following his/her movements along the blackboard. Then, a questionnaire was applied for each student with 10-min intervals during the lesson, to report their attention levels. According to the answers of the questionnaire, it has been determined that engaged students are those whose heads are towards the teacher’s location on the horizontal axis [
42].
Krithika and Lakshmi Priya developed a system in which students can be monitored with a camera in order to improve the e-learning experience [
43]. This system processes the image taken from the camera and uses the Viola–Jones and Local Binary Patterns algorithms to detect the face and eyes. They tried to determine the concentration level according to the detection of the face and eyes of the students. Three different concentration levels (high, medium, and low) were determined. The image frames are marked as low concentration in which the face could not be detected; medium concentration in which the face was detected but one of the eyes could not be detected (in cases where the head was not exactly looking forward); high concentration in which the face and both eyes were detected. The developed system was tested by showing a 10-minute video course to 5 students and the test results were shared. According to the concentration levels in test results, parts of course which needed to be improved were determined.
Ayvaz, ve Gürüler also conducted a study and developed an application using OpenCV and dlib image processing libraries aiming to increase the quality of in-class education [
44]. Similar to determining the attention level, it was aimed to determine the students’ emotional states in real time by watching them with a camera. This system performed the face recognition with the Viola–Jones algorithm, then the emotional state was determined according to the facial features. The training dataset used in determining the emotional state was obtained from the face data of 12 undergraduate students (5 female and 7 male students). The facial features of each student for 7 different emotional states (happiness, sadness, anger, surprise, fear, disgust, and normal) were recorded in this training dataset. A Support Vector Machine is trained with this dataset and emotional states of the students during the lesson were determined with an accuracy of 97.15%. Thanks to this system, a teacher can communicate directly with the students and motivate them when necessary.
In addition to the above studies, there are numerous studies conducted on automatically detecting student engagement and participation in class by utilizing image processing techniques based on the gaze direction determined the student engagement and participation based on their facial expressions [
45,
46,
47,
48,
49,
50,
51]. In China, a system determining the students’ attentions based on their facial expressions was developed and this system was tested as a pilot application in some schools [
52].
In the study conducted by [
53], the visual focus of attention of the person was tried to be determined by finding his/her head pose using image processing techniques. For this purpose, a system with two cameras was designed in which one camera was facing to the user and the other was facing where the user looks. They developed an application by using OpenCV and Stasm libraries. They tried to estimate head pose of the person in vertical axis (right, left, front) from the images taken from the camera looking directly to the person and which object the person paid attention by determining the objects in the environment from the images taken from the other camera. In order to estimate head pose, the point-based geometric analysis method was used and Euclidean distances between the eye and the tip of the nose were utilized. In the determination of objects, the Sobel edge detection algorithm and morphological image processing technique were used. It was stated that satisfactory results were obtained in determining the gaze direction, detecting objects and which objects were looked at, and the test results were shared.
One of the parameters used in determining the visual focus of attention of a person is the gaze direction. Gaze detection can be made with image processing techniques or eye tracking devices attached to the head. The use of image processing techniques is more advantageous than other methods in terms of cost. However, getting successful results from this method depends on having images of the eye area with sufficient resolution. On the other hand, eye tracking devices are preferred because of their high sensitivity, although they are expensive.
Cöster and Ohlsson conducted a study aiming to measure human attention using OpenCV library and Viola–Jones face recognition algorithm [
54]. In this study, images in which faces were detected and not detected were classified by the application developed in this context. It is assumed that if a person is looking towards an object, that person’s attention is focused on that object and images, in which no face can be detected because of the head pose, are assumed to be inattentive. The face recognition algorithm was tested with a dataset in which each student is placed in a separate image and looking towards different directions during the lesson. It is ensured with the dataset that the students in the images are centered and there are no other objects in the background. In order to make a more comprehensive evaluation, three different pre-trained face detection models that come with OpenCV Library are used for face detection. The images in the dataset were classified as attentive or inattentive according to the face detection results. It was expressed that this experiment, which is conducted in a controlled environment, yielded successful results.
Additionally, an important part of the studies on detecting distraction is within the scope of driving safety. Driver drowsiness detection is one of the popular research topics in image processing. Tracking the eye and head movements/direction is one of the mostly used methods in the area of driver drowsiness detection. Although there are many studies on this subject in the literature, Alexander Zelinsky is one of the leading names in this field. He released the first commercial version of the driver support system called faceLAB in 2001 [
55]. This application performs eye and head tracking with the help of two cameras monitoring the driver and determining where the driver is looking, the driver’s eye closeness, and blinking. The driver’s attention status is calculated by analyzing all these inputs and the driver is warned before his/her attention level reaches critical levels [
56,
57].
5. Conclusions
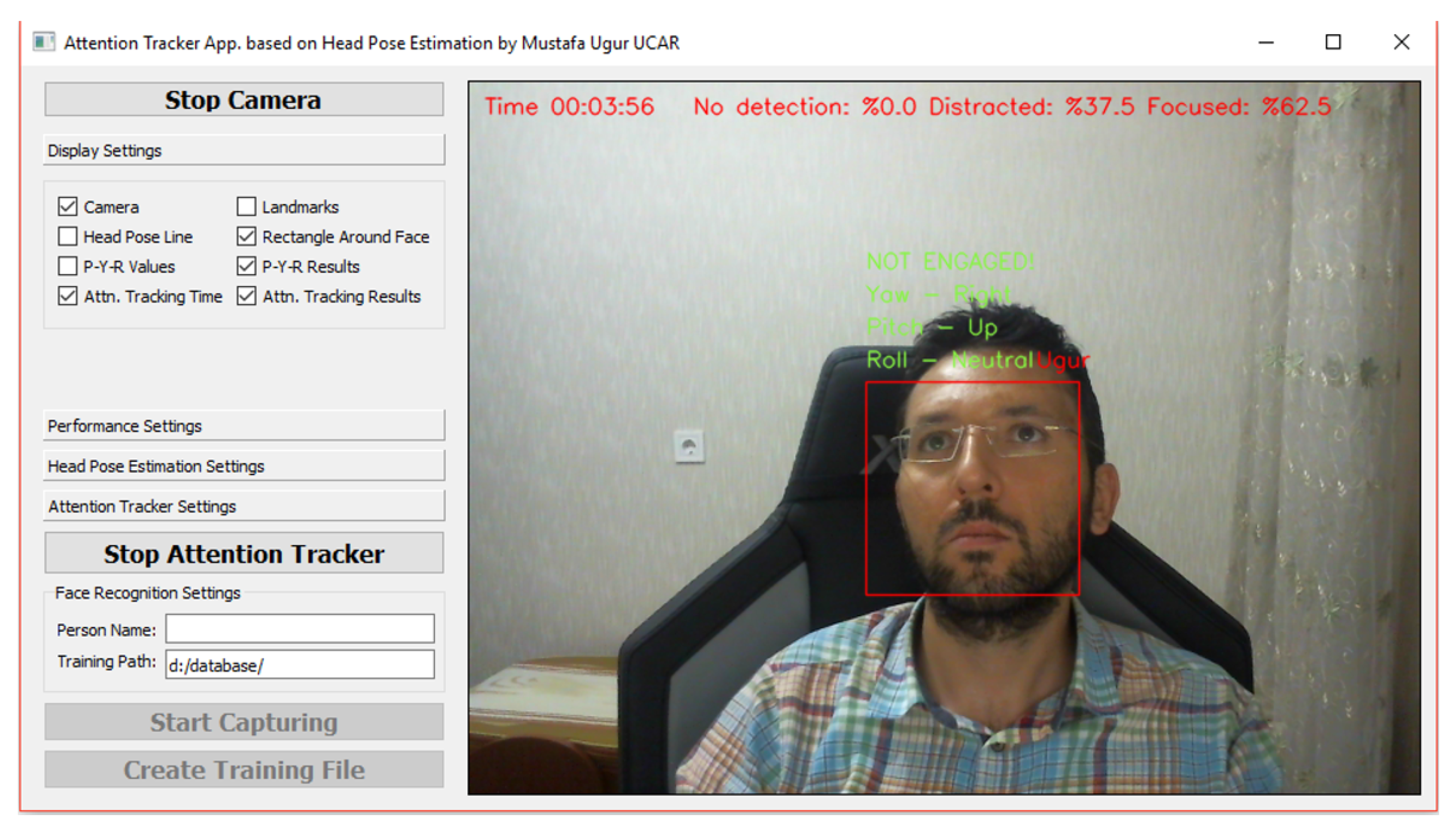
With the application developed for this study:
A total of 50 random photo frames were taken for each person from videos of 10 people in the UPNA Head Pose Database; these photos were saved in separate folders with the names of those people and a face recognition model was prepared using these photos. The prepared face recognition model was tested using all videos in the UPNA Head Pose Database and a 98.95% face recognition success was achieved with the LBP method.
Head pose angles were estimated for 120 videos each of which consists of 300 frames in the UPNA Head Pose Database using image processing techniques. The obtained pitch, yaw, and roll angles were compared with the angle values measured precisely by the sensors. The estimated pitch, yaw, and roll angles were obtained with mean absolute deviation values of 1.34°, 4.97°, and 4.35°, respectively.
In the literature, 75.3% success was reported in the model trained with the data obtained with the Kinect One sensor, which is used to determine the distraction of students, and 75.8% success in another study.
In this study, using 1000 photos taken from the videos from the UPNA Head Pose Database, a distraction database was prepared. Pitch, yaw, roll, and eye aperture rates were calculated for each photo and feature vectors were formed. Each photo in the dataset was labelled as “Engaged” or “Not Engaged” by 5 labellers. Fleiss’ kappa coefficient was calculated as 0.85 (high reliability) in order to determine the reliability of the labelling process. While assigning labels to each photo in the dataset, the majority of decisions were taken as the basis. Half of the labelled dataset was used in the training of machine learning algorithms and the other half was used in testing. In the conducted tests, the SVM machine learning algorithm showed 72.4% success rate in determining distraction.
Considering the results of this study conducted on student engagement classification, it is seen that the results obtained using a simple CMOS camera gave similar results with the studies conducted with the Kinect sensor. In addition, the developed system is more useful in terms of recognizing the student and associating the student engagement result with the student.
In this study, algorithms were developed for face detection and recognition, estimation of head pose, and classification of student engagement in the lesson, and successful results were obtained.
Moreover, it was seen that the viewing angle and distance were limited due to the camera used in the developed system. This is especially effective for the success of the face recognition algorithm. In order for the system to provide more successful results in the classroom environment, it is planned to conduct in-class tests using more professional, wide-angle cameras and using additional light.
A labelled dataset consisting of 1000 photos was prepared for the training and tests of machine learning algorithms that will determine student engagement. Expanding this dataset will make the results more successful.
The feature vector used in training student engagement classifiers consists of 5 parameters. In addition to these parameters, adding features, such as eye direction, emotional state of the student, and body direction, is predicted to be effective in increasing the success of student engagement classification.
We continue to work on algorithms that guide the teaching method of the course by determining the course topics and weights, taking into account the characteristics of the students. To give a brief detail, data from this study are one of the input parameters of the fuzzy logic algorithm we use to determine the level of expression during the lesson. Students in front of the computer or in the classroom who are engaged in the lesson are counted. The obtained value and the time spent in that lesson are entered into the fuzzy logic algorithm as input data. From here, it is decided at which level the lecture of the course, which is prepared at different levels, will be chosen. The student’s interest is tried to be kept during the lesson. Our work on this issue continues.



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}