
Partial Atrous Cascade R-CNN


Abstract
:1. Introduction
- (1)
- We introduce the feature from the semantic branch into the instance segmentation task to exploit the accuracy improvement.
- (2)
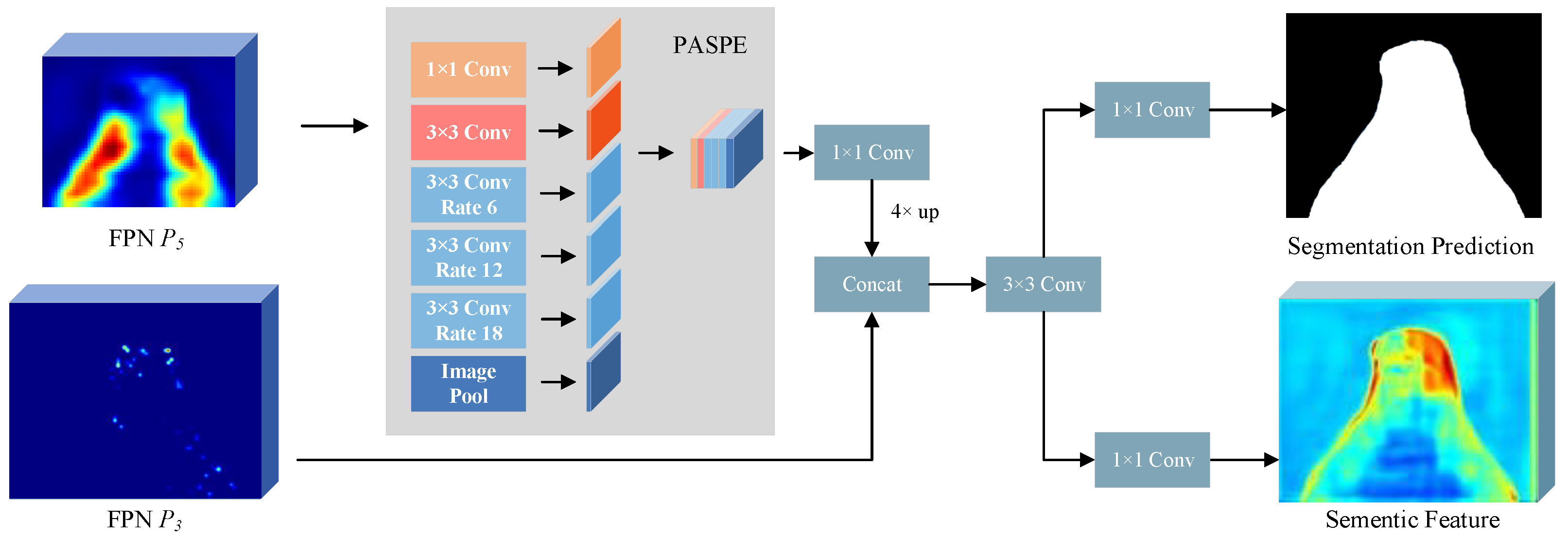
- We propose a partial atrous spatial pyramid extraction (PASPE) module that strengthens spatial context information and the boundary resolution. The semantic branch integrated with the PASPE module accounts for discriminating objects from the cluttered background.
- (3)
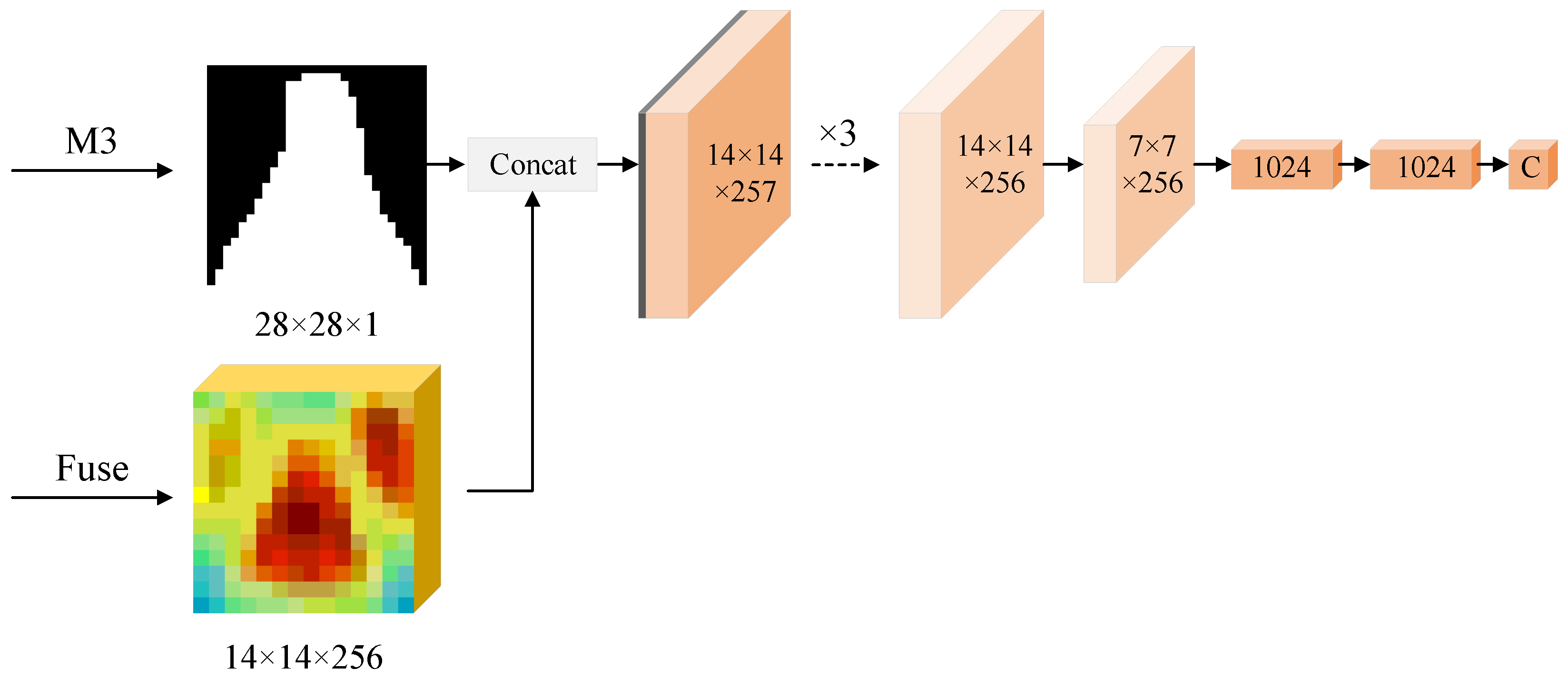
- We design a mask quality (MQ) module that calibrates the scores of masks. By regressing the IoU between the mask and the ground truth, the quality of the mask is correctly assessed. At the same time, appropriate mask quality evaluation improves segmentation performance.
2. Related Work
2.1. Instance Segmentation
2.2. Semantic Segmentation with Atrous Convolution
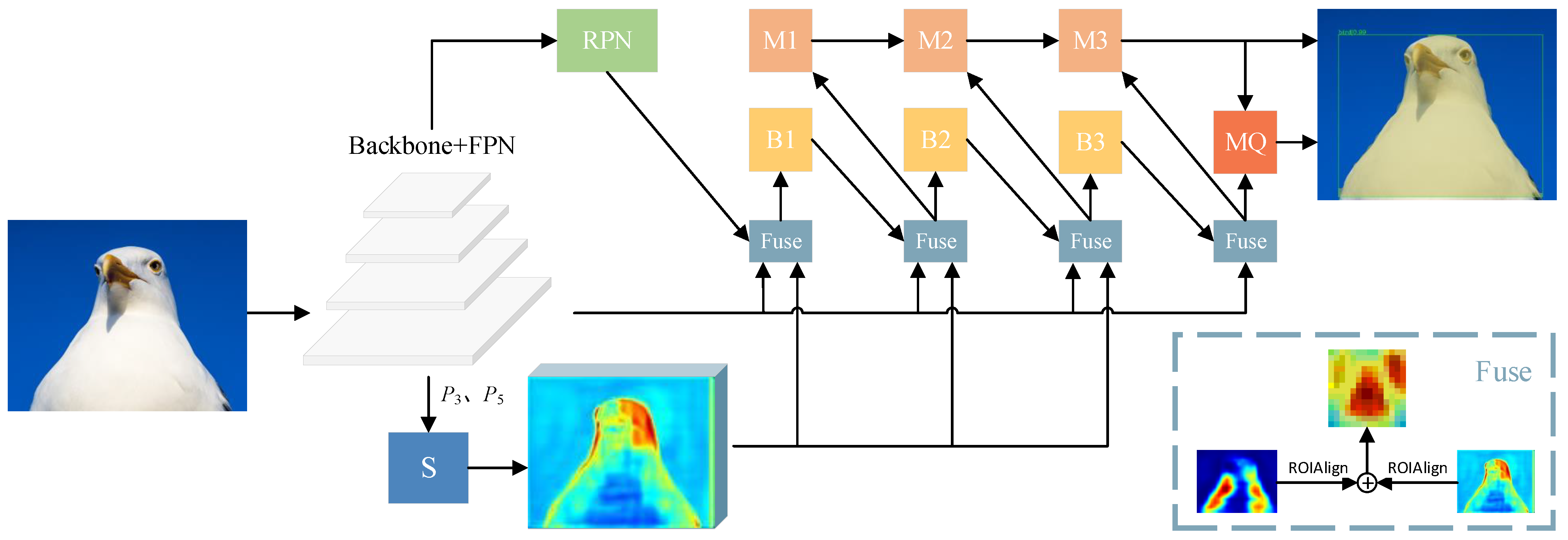
3. Method
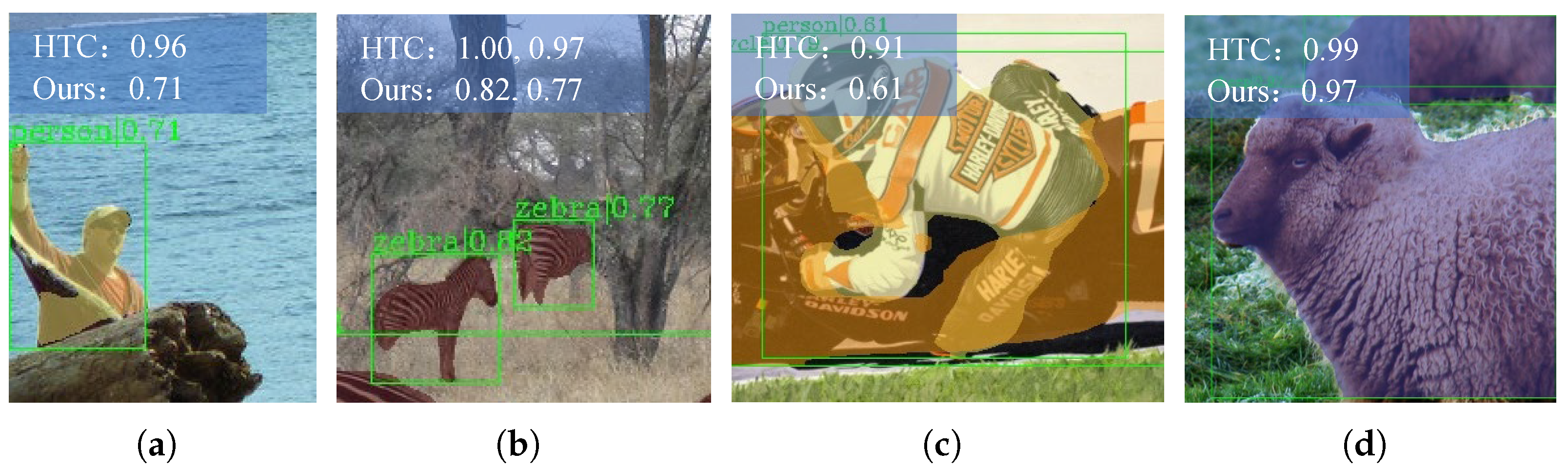
3.1. Motivation
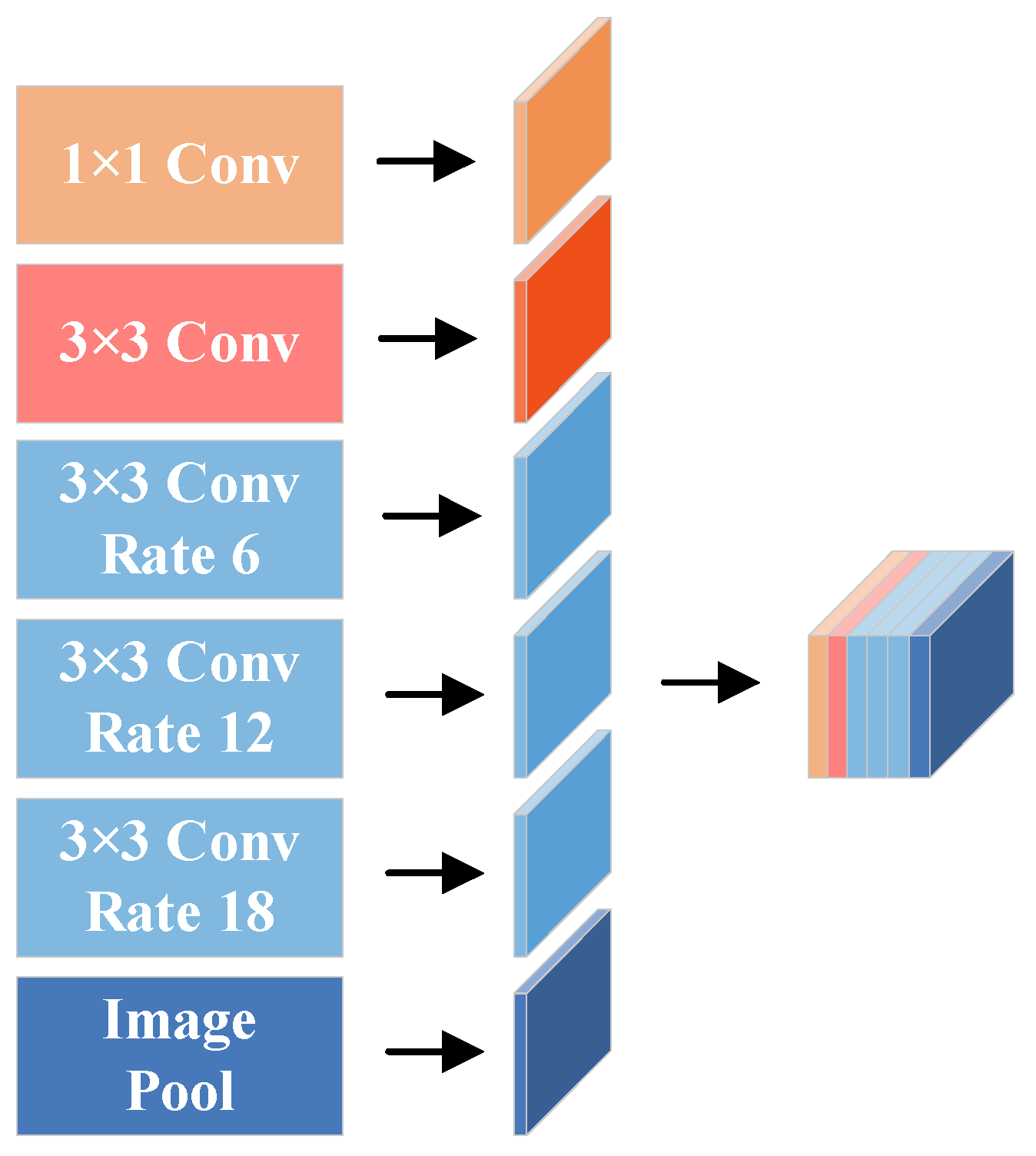
3.2. Semantic Branch
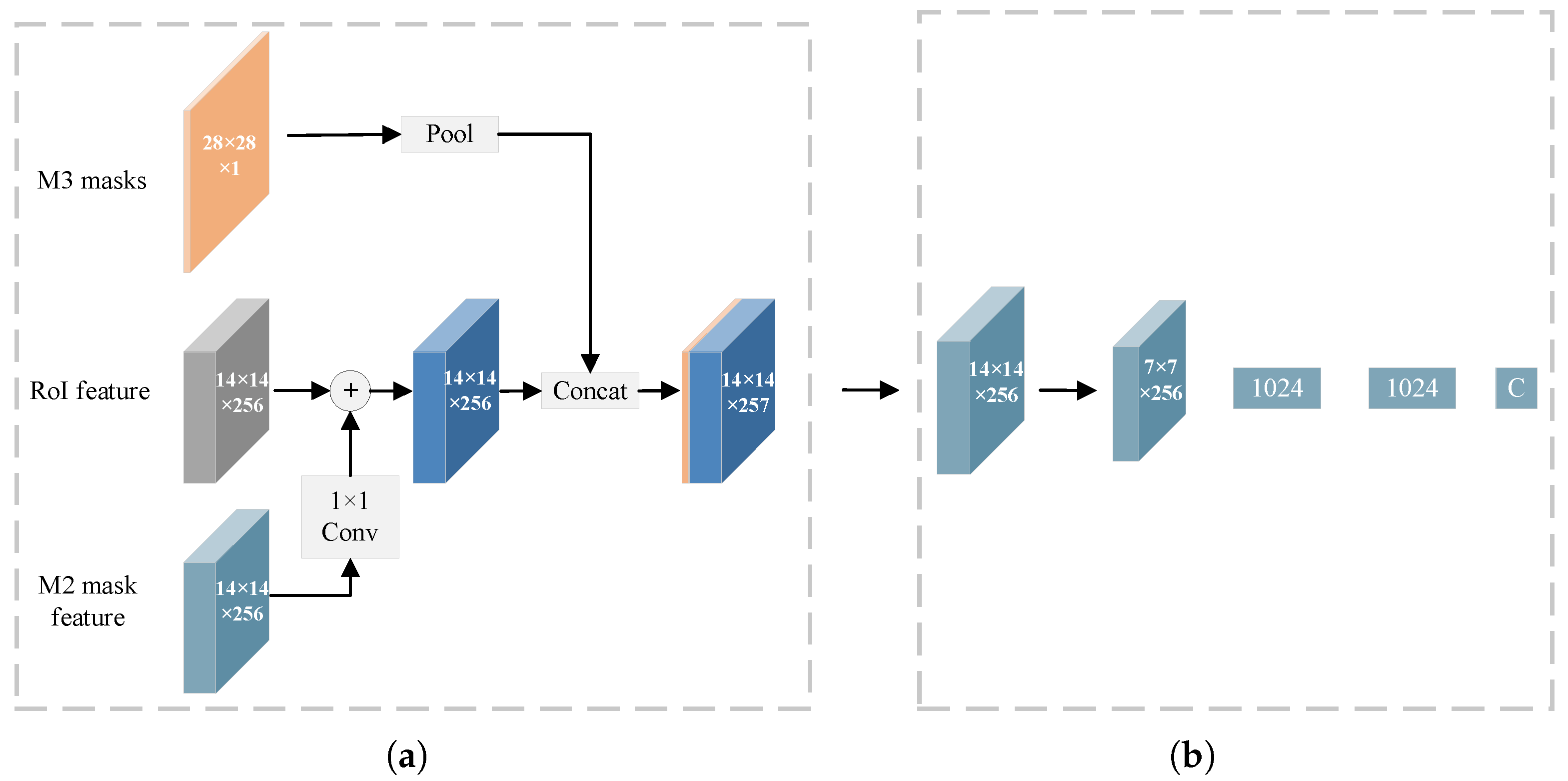
3.3. Mask Quality Module
3.4. Training Strategy
4. Results
4.1. Datasets and Evaluation Metrics
4.2. Implementation Details
4.3. Semantic Branch Optimization Results
4.4. MQ Module Optimization Results
4.5. Quantitative Results
5. Ablation Study
5.1. The Architecture of the MQ Module
5.2. The Architecture of the PASPE Module
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Adv. Neural Inf. Process. Syst. 2012, 25, 1097–1105. [Google Scholar] [CrossRef]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Li, F.-F. Imagenet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Garcia-Garcia, A.; Orts-Escolano, S.; Oprea, S.; Villena-Martinez, V.; Garcia-Rodriguez, J. A review on deep learning techniques applied to semantic segmentation. arXiv 2017, arXiv:1704.06857. [Google Scholar]
- Ghosh, S.; Das, N.; Das, I.; Maulik, U. Understanding deep learning techniques for image segmentation. ACM Comput. Surv. 2019, 52, 1–35. [Google Scholar] [CrossRef] [Green Version]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- Girshick, R. Fast r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. Adv. Neural Inf. Process. Syst. 2015, 28, 91–99. [Google Scholar] [CrossRef] [Green Version]
- Chen, K.; Pang, J.; Wang, J.; Xiong, Y.; Li, X.; Sun, S.; Feng, W.; Liu, Z.; Shi, J.; Ouyang, W.; et al. Hybrid task cascade for instance segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 4974–4983. [Google Scholar]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft coco: Common objects in context. In European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2014; pp. 740–755. [Google Scholar]
- Dai, J.; He, K.; Li, Y.; Ren, S.; Sun, J. Instance-sensitive fully convolutional networks. In European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2016; pp. 534–549. [Google Scholar]
- Li, Y.; Qi, H.; Dai, J.; Ji, X.; Wei, Y. Fully convolutional instance-aware semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2359–2367. [Google Scholar]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar]
- Cai, Z.; Vasconcelos, N. Cascade r-cnn: Delving into high quality object detection. In Proceedings of the IEEE conference on computer vision and pattern recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 6154–6162. [Google Scholar]
- Huang, Z.; Huang, L.; Gong, Y.; Huang, C.; Wang, X. Mask scoring r-cnn. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 6409–6418. [Google Scholar]
- Zhang, G.; Lu, X.; Tan, J.; Li, J.; Zhang, Z.; Li, Q.; Hu, X. RefineMask: Towards High-Quality Instance Segmentation with Fine-Grained Features. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 6861–6869. [Google Scholar]
- Tang, C.; Chen, H.; Li, X.; Li, J.; Zhang, Z.; Hu, X. Look Closer to Segment Better: Boundary Patch Refinement for Instance Segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 13926–13935. [Google Scholar]
- Ke, L.; Tai, Y.W.; Tang, C.K. Deep Occlusion-Aware Instance Segmentation with Overlapping BiLayers. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 4019–4028. [Google Scholar]
- Bolya, D.; Zhou, C.; Xiao, F.; Lee, Y.J. Yolact: Real-time instance segmentation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 9157–9166. [Google Scholar]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Bolya, D.; Zhou, C.; Xiao, F.; Lee, Y.J. Yolact++: Better real-time instance segmentation. arXiv 2019, arXiv:1912.06218. [Google Scholar] [CrossRef]
- Xie, E.; Sun, P.; Song, X.; Wang, W.; Liu, X.; Liang, D.; Shen, C.; Luo, P. Polarmask: Single shot instance segmentation with polar representation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 12193–12202. [Google Scholar]
- Wang, X.; Kong, T.; Shen, C.; Jiang, Y.; Li, L. Solo: Segmenting objects by locations. In European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2020; pp. 649–665. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In International Conference on Medical Image Computing and Computer-Assisted Intervention; Springer: Berlin/Heidelberg, Germany, 2015; pp. 234–241. [Google Scholar]
- Tong, H.; Fang, Z.; Wei, Z.; Cai, Q.; Gao, Y. SAT-Net: A side attention network for retinal image segmentation. Appl. Intell. 2021, 51, 5146–5156. [Google Scholar] [CrossRef]
- Hesamian, M.H.; Jia, W.; He, X.; Wang, Q.; Kennedy, P.J. Synthetic CT images for semi-sequential detection and segmentation of lung nodules. Appl. Intell. 2020, 51, 1616–1628. [Google Scholar] [CrossRef]
- Wang, P.; Chen, P.; Yuan, Y.; Liu, D.; Huang, Z.; Hou, X.; Cottrell, G. Understanding convolution for semantic segmentation. In Proceedings of the 2018 IEEE winter conference on applications of computer vision (WACV), Lake Tahoe, NV, USA, 12–15 March 2018; pp. 1451–1460. [Google Scholar]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 834–848. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Chen, L.C.; Papandreou, G.; Schroff, F.; Adam, H. Rethinking atrous convolution for semantic image segmentation. arXiv 2017, arXiv:1706.05587. [Google Scholar]
- Chen, L.C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-decoder with atrous separable convolution for semantic image segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 801–818. [Google Scholar]
- Zhu, H.; Wang, B.; Zhang, X.; Liu, J. Semantic image segmentation with shared decomposition convolution and boundary reinforcement structure. Appl. Intell. 2020, 50, 2676–2689. [Google Scholar] [CrossRef]
- Paszke, A.; Chaurasia, A.; Kim, S.; Culurciello, E. Enet: A deep neural network architecture for real-time semantic segmentation. arXiv 2016, arXiv:1606.02147. [Google Scholar]
- Schuurmans, M.; Berman, M.; Blaschko, M.B. Efficient semantic image segmentation with superpixel pooling. arXiv 2018, arXiv:1806.02705. [Google Scholar]
- Szegedy, C.; Ioffe, S.; Vanhoucke, V.; Alemi, A.A. Inception-v4, inception-resnet and the impact of residual connections on learning. In Proceedings of the Thirty-First AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017. [Google Scholar]
- Xie, S.; Girshick, R.; Dollár, P.; Tu, Z.; He, K. Aggregated residual transformations for deep neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1492–1500. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Backbone | SH | MQ | Mask AP | AP50 | AP75 | Box AP | AP50 | AP75 |
|---|---|---|---|---|---|---|---|---|
| ResNet-18 FPN | 34.0 | 53.8 | 36.6 | 38.3 | 56.2 | 41.5 | ||
| ✓ | 34.5 | 54.9 | 36.8 | 38.8 | 57.4 | 41.9 | ||
| ✓ | 35.0 | 53.7 | 37.6 | 38.3 | 55.5 | 41.6 | ||
| ResNet-50 FPN | 38.1 | 59.4 | 41.0 | 43.2 | 62.1 | 46.8 | ||
| ✓ | 38.3 | 59.8 | 41.2 | 43.7 | 62.8 | 47.3 | ||
| ✓ | 38.9 | 58.9 | 42.0 | 43.0 | 60.8 | 46.7 | ||
| ✓ | ✓ | 39.5 | 60.3 | 42.6 | 43.6 | 61.9 | 47.2 | |
| ResNeXt-101 FPN | 40.3 | 62.2 | 43.5 | 46.1 | 65.3 | 50.1 | ||
| ✓ | 40.3 | 62.5 | 43.6 | 46.2 | 65.6 | 50.2 | ||
| ✓ | 41.1 | 62.1 | 44.5 | 45.8 | 63.8 | 49.8 | ||
| ✓ | ✓ | 41.5 | 62.6 | 44.9 | 46.2 | 65.4 | 50.2 |
| Method | Backbone | Box AP | Mask AP | AP50 | AP75 | APS | APM | APL |
|---|---|---|---|---|---|---|---|---|
| Mask R-CNN [13] | ResNet-50 FPN | 39.2 | 35.4 | 56.4 | 37.9 | 19.1 | 38.6 | 48.4 |
| Mask R-CNN [13] | ResNeXt-101 FPN | 42.2 | 37.8 | 59.6 | 40.6 | 19.8 | 41.4 | 51.9 |
| MS R-CNN [15] | ResNet-50 FPN | 38.8 | 36.3 | 56.1 | 39.2 | 18.8 | 39.3 | 50.8 |
| MS R-CNN [15] | ResNeXt-101 FPN | 41.8 | 38.7 | 59.3 | 41.9 | 20.8 | 42.3 | 52.9 |
| BPR [17] | ResNeXt-101 FPN | - | 39.2 | - | - | - | - | - |
| BCNet [18] | ResNet-50 FPN | - | 38.4 | 59.6 | 41.5 | 21.9 | 40.9 | 49.3 |
| BCNet [18] | ResNet-101 FPN | - | 39.8 | 61.5 | 43.1 | 22.7 | 42.4 | 51.1 |
| HTC [9] | ResNet-50 FPN | 43.2 | 38.1 | 59.4 | 41.0 | 20.3 | 41.1 | 52.8 |
| HTC [9] | ResNeXt-101 FPN | 46.1 | 40.3 | 62.2 | 43.5 | 22.3 | 43.7 | 55.5 |
| RefineMask [16] | ResNet-50 FPN | - | 38.2 | - | - | - | - | - |
| RefineMask [16] | ResNeXt-101 FPN | - | 41.0 | - | - | - | - | - |
| PAC | ResNet-50 FPN | 43.6 | 39.5 | 60.3 | 42.6 | 21.1 | 42.8 | 55.0 |
| PAC | ResNeXt-101 FPN | 46.2 | 41.5 | 62.6 | 44.9 | 23.1 | 45.3 | 57.3 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cheng, M.; Fan, C.; Chen, L.; Zou, L.; Wang, J.; Liu, Y.; Yu, H. Partial Atrous Cascade R-CNN. Electronics 2022, 11, 1241. https://doi.org/10.3390/electronics11081241
Cheng M, Fan C, Chen L, Zou L, Wang J, Liu Y, Yu H. Partial Atrous Cascade R-CNN. Electronics. 2022; 11(8):1241. https://doi.org/10.3390/electronics11081241
Chicago/Turabian StyleCheng, Mofan, Cien Fan, Liqiong Chen, Lian Zou, Jiale Wang, Yifeng Liu, and Hu Yu. 2022. "Partial Atrous Cascade R-CNN" Electronics 11, no. 8: 1241. https://doi.org/10.3390/electronics11081241