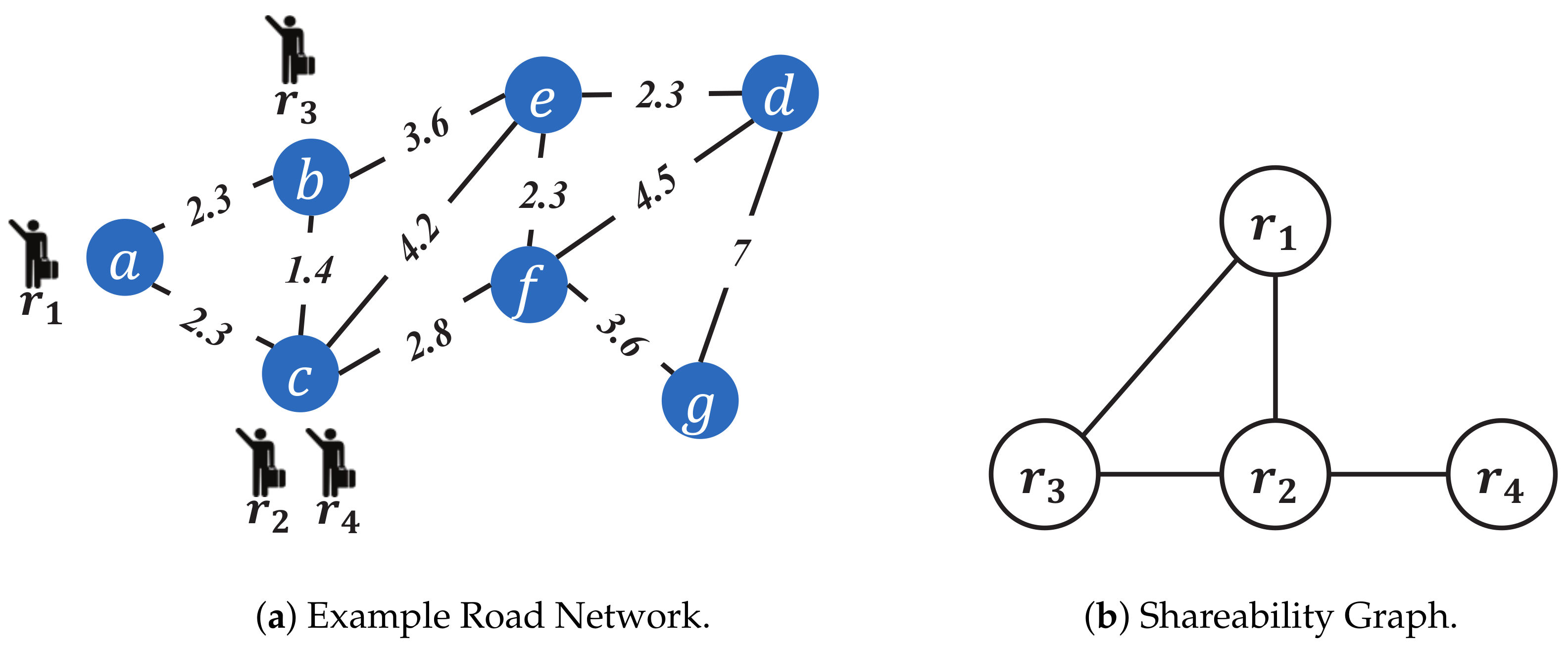
4.1. Shareability Graph
Shareable request group enumeration is a fundamental operator in batch-based methods (e.g., line 7 in Algorithm 1). Therefore, to optimize the efficiency of the shareable request group enumeration, we first define the following shareability graph for visualizing the shareable relationships between requests intuitively.
Definition 5 (Shareability Graph). Given a set of requests R, denotes the shareability graph of R, where reflects that request and are shareable.
Here, clique [
17,
18,
19] is an extensively studied subgraph structure, and
k-clique is a subset of
k nodes in the graph that satisfies any two distinct nodes in the
k-clique are adjacent in graph theory. With the shareability graph, we have the following Theorem 2 for enumerating those request groups that form a
k-clique in the sharability graph rather than an arbitrary enumeration, which helps to reduce the search space by pruning infeasible groups.
Theorem 2. Given a feasible route S for k requests, the corresponding nodes of these k requests form a k-clique in the shareability graph.
Proof. We will prove it by a contradiction. Suppose a feasible route S of k requests whose corresponding nodes did not form a k-clique in the shareability graph. Thus, there are at least two nodes and that are not connected. We derive the subroute from S by removing location except the source and destination of and . Since removing existing waypoints reduces the detour, the subroute is also a feasible route. According to the definition of the shareability graph, there must exist an edge between and , which contradicts our assumption. In summary, these k requests form a k-clique in the shareability graph. □
With the Theorem 2, a shareable request group of size
k in the shareability graph must constitute a
k-clique. Therefore, we can achieve efficient enumeration of shareable request groups by the state-of-the-art algorithm of
k-clique listing [
18] in graph theory.
4.2. Shareability Prediction with Hyper Graph
The dynamic shareability graph proposed in
Section 4.1 can provide an intuitive representation of the shareable relationship between pairs of requests. In reality, for the ridesharing problem, the sharing relationship between requests may often contain three, four, or even more requests. Therefore, the higher-order shareable relationships cannot be expressed by such a traditional graph. However, the higher-order sharable relationships widely exist for most batch-based algorithms. So, we propose the structure of the shareability hypergraph to represent the higher-order shareability relations as follows.
Definition 6 (Shareability Hyper Graph). Let denote the shareability hypergraph for a given set of requests R, where (where is the power set of R). For each, represents that the requests included in e are shareable.
The shareability hypergraph
can represent the different sizes of shareable request groups intuitively, but enumerating all hyper-edges of
can be extremely expensive. We need to perform
times shareable judgments to determine whether there are corresponding hyper-edges between nodes. Thus, it is impractical to construct the shareability hypergraph by enumerating all hyper-edges brutally in an online scenario, but a city’s historical shareable request groups are instructive in the guidance for the existence of shareable hyper-edges. Therefore, we propose the following shareability prediction model based on the hyper-edge prediction model Hyper-SAGNN [
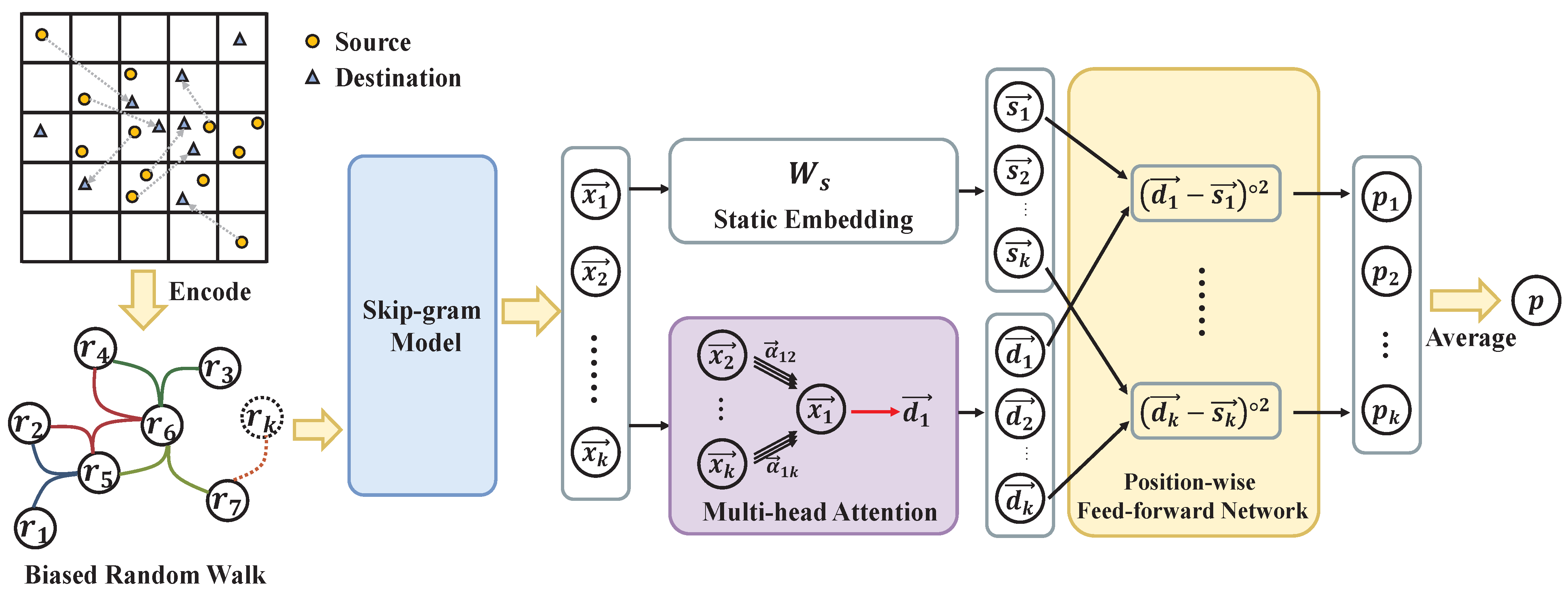
30] as shown in
Figure 2, which trains according to the historical shareable request groups in a city and predicts the shareability among the given requests by batch in a fixed time.
Because of the constraints of requests defined in
Section 3.1, the shareable requests often satisfy the following two conditions: (1)
Temporal Locality—the requests are released in a similar time; (2)
Spatial Locality—the requests share similar sources and destinations. For online ridesharing platforms, the shareability prediction model primarily serves to quickly predict the shareability between requests released in close time on the platform. Therefore, the request groups to be predicted already possess the temporal locality characteristics. To satisfy the spatial locality requirement, we intuitively divide the city into a certain number of grids. Specifically, we first divided the road network into
grids according to a fixed grid size
as a parameter, and the sources and destinations of each request
corresponded to
and
among the grids, respectively. Then, we uniformly encoded the requests whose sources and destinations fall in the same grid as the node
in the shareability hypergraph
, where
. Thus, each node of the shareability hypergraph represents a class of requests that satisfy both temporal locality and spatial locality.
With the nodes on the hypergraph generated from the above steps, we enumerate the hyper-edges present in the historical request data of a specific city, i.e., the shareable request groups (as shown on the left of
Figure 2, each color edge represents a single hyper-edge). Then, we generate a walking path for each node based on the constructed hypergraph by a biased random walk method and extract the features of the nodes
by a skip-gram model, which enables nodes with similar contexts to have similar embeddings. We feed the above node features to Hyper-SAGNN [
30], a self-attentive-based graph neural network for hypergraphs, which can support arbitrary-sized link prediction tasks. Specifically, Hyper-SAGNN feeds the features of the nodes into both the static embedding network and the multi-headed attention layer to generate the corresponding static embedding and dynamic embedding of the nodes in the hypergraph. Then, the probability scores
are generated by a layer of position-wise feed-forward network with a sigmoid activation function. Finally, the average value of these probability scores is regarded as the probability of the existence of hyper-edge among requests
.
Based on such a prediction model, we encode the online requests to the nodes on the corresponding hypergraph in constant time to determine the shareability of the request group, so that we can quickly build a shareable network in batch mode. Meanwhile, the determination of the shareability between requests is a fundamental operation for different upper-level request dispatching algorithms, and the complexity of these algorithms can be greatly reduced by such a prediction model. For example, in the batch-base method shown in Algorithm 1, we have to enumerate up to request groups line 7. However, based on the sharability prediction model, we can efficiently predict whether the request groups are shareable or not in batch with GPU devices, which greatly reduces the search space of request groups and improves the efficiency of the algorithm.
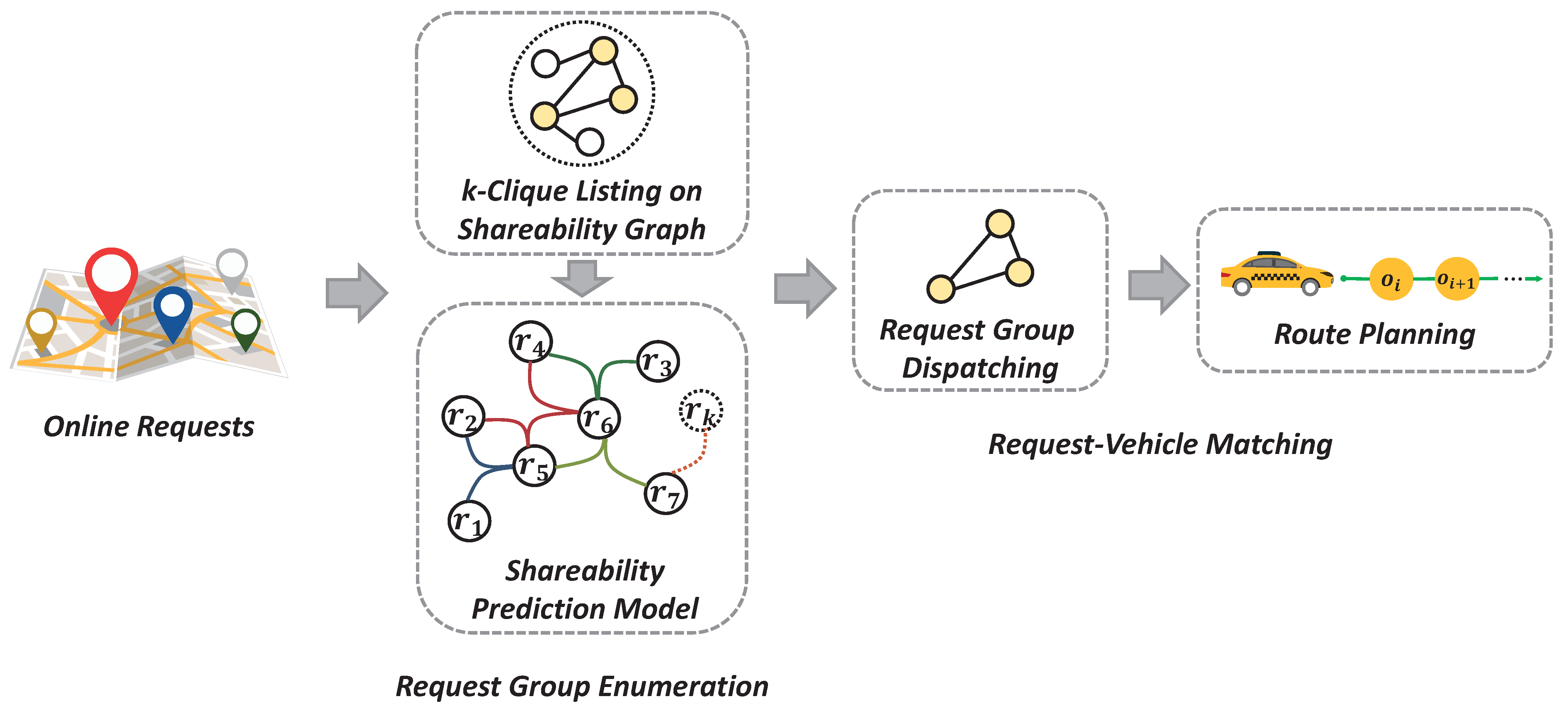
4.3. P-Ride: Shareability Prediction Based Ridesharing Framework
Based on Theorem 2 presented in
Section 4.1 and the shareability prediction model proposed in
Section 4.2, we devise the online ridehsharing framework
P-Ride as shown in
Figure 3. The P-Ride framework adopts the batch-based processing mode that optimizes the request group enumeration and route planning of existing batch-based methods.
In the request group enumeration, the P-Ride framework first enumerates the request groups by k-clique listing in the shareability graph. Then, it further checks the filtered candidate request groups in a batch manner by the shareability prediction model. In the request-vehicle matching, the P-Ride framework selects the optimal group of requests among all feasible request groups for each vehicle. Since in [
31], Ma et al. revealed that reordering waypoints almost has no change in effectiveness but needs more time and space. Therefore, we generate service routes for the request groups based on the insertion method instead of enumerating all feasible routes.
The detailed steps of the P-Ride framework are shown in Algorithm 2. Firstly, we extract all the requests
within the batch window and construct the corresponding shareability graph
for the request set
(line 3–4). Then, we try to select the most appropriate request group for each vehicle and plan a service route for it (line 5–15). In particular, we first search for all feasible candidate request groups (line 6–10). Based on Theorem 2, we enumerate the candidate request groups
in the shareability graph
by the
k-clique listing algorithm (line 8). Then, we predict the set of candidate request groups
in bulk by the pre-trained sharability prediction model
based on the historical sharable request groups. We only retain the request groups that are reported as shareable by the shareability prediction model
(line 9). After that, we pick the request group
with the optimal unified cost
and plan a service route
for it (line 11–14). More specifically, we insert the source and destination of each request in the optimal request group
into the appropriate position of the vehicle’s route
in turn (line 12–14).
| Algorithm 2 P-Ride |
- Require:
A set R of n requests, a set W of m vehicles, a batch period and a shareability prediction model - Ensure:
The planned routes set for vehicle - 1:
current timestamp; - 2:
for every time period do - 3:
; - 4:
building the sharability graph for ; - 5:
for do - 6:
initialize a empty set for candidate shareable groups; - 7:
for do - 8:
listing k-cliques g in ; - 9:
; - 10:
end for - 11:
; - 12:
for do - 13:
insert and into by insertion; - 14:
end for - 15:
end for - 16:
; - 17:
end for - 18:
return;
|















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}