
An Efficient Simulation-Based Policy Improvement with Optimal Computing Budget Allocation Based on Accumulated Samples



Abstract
:1. Introduction
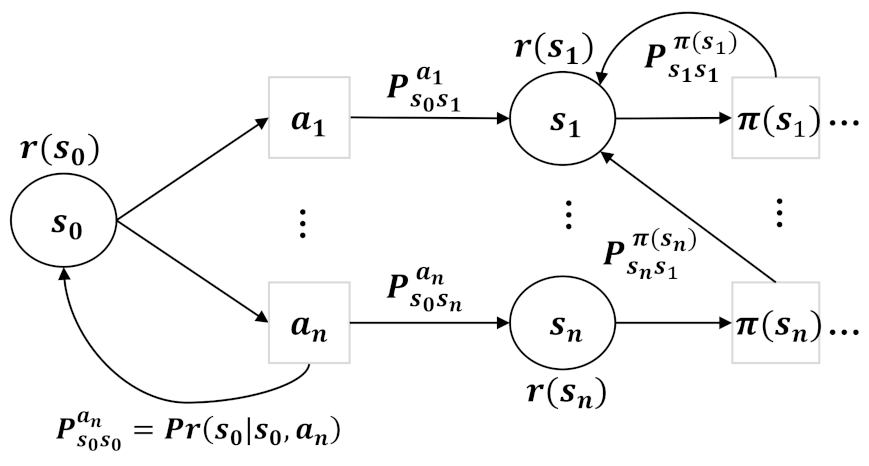
2. Problem Definition
3. Proposed Method
| Algorithm 1 Efficient simulation-based policy improvement with optimal computing budget allocation based on accumulated samples. |
| Require: a base policy , an incremental replication △, simulation budget N, an initial state , total simulation budget B. Initialize the probability table. Set the iteration number of SBPI . Determine T using Equation (13). |
|
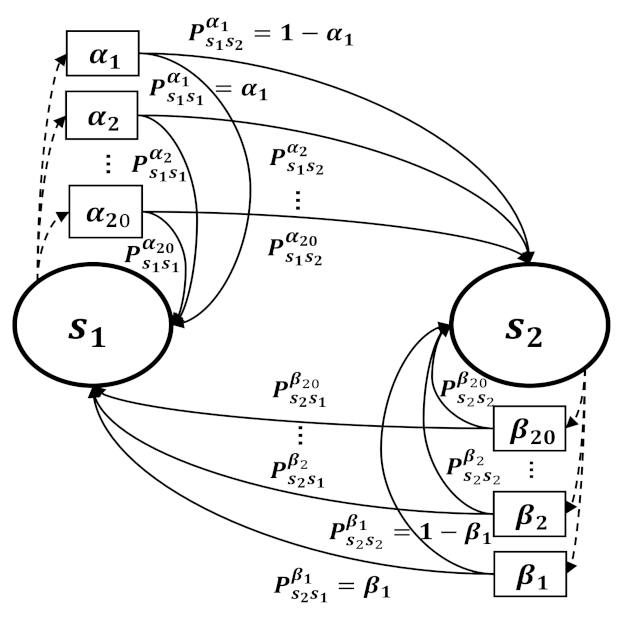
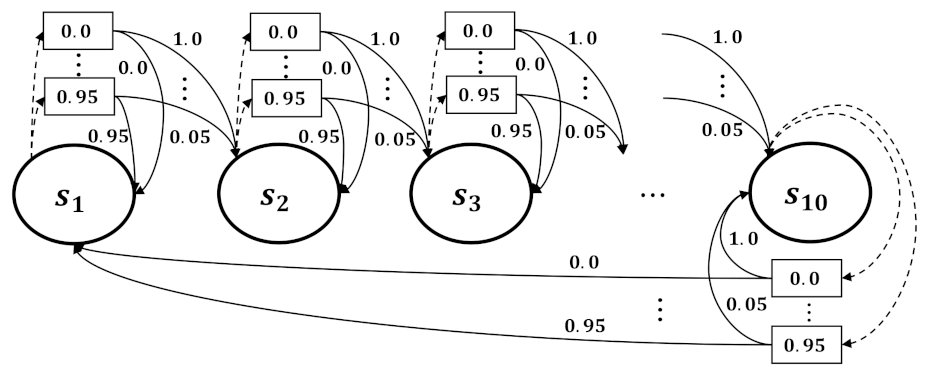
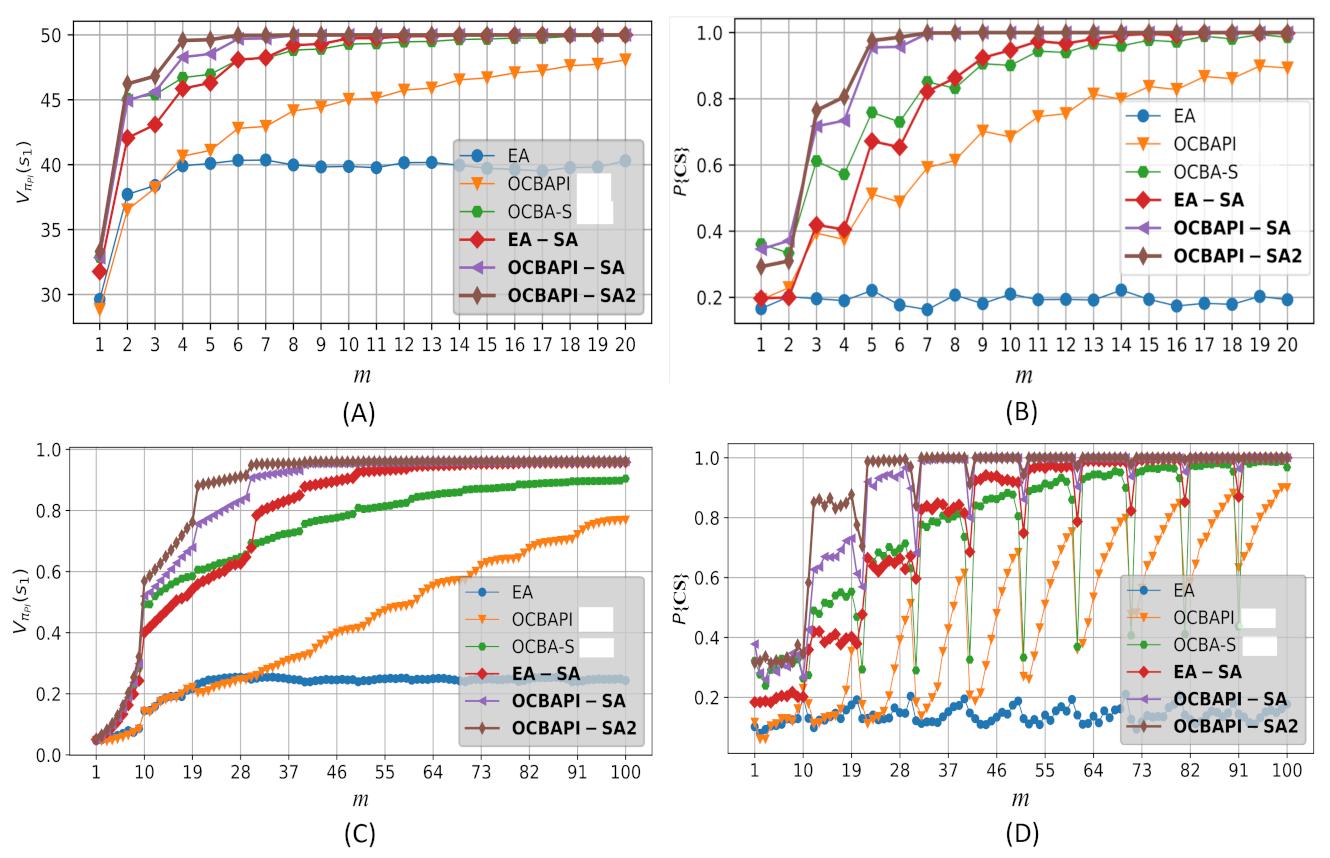
4. Experiments
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Hendy, A.S.; Zaky, M.A.; Doha, E.H. On a discrete fractional stochastic Grönwall inequality and its application in the numerical analysis of stochastic FDEs involving a martingale. Int. J. Nonlinear Sci. Numer. Simul. 2021. [Google Scholar] [CrossRef]
- Hendy, A.S.; Zaky, M.A.; Suragan, D. Discrete fractional stochastic Grönwall inequalities arising in the numerical analysis of multi-term fractional order stochastic differential equations. Math. Comput. Simul. 2022, 193, 269–279. [Google Scholar] [CrossRef]
- Moghaddam, B.; Mendes Lopes, A.; Tenreiro Machado, J.; Mostaghim, Z. Computational scheme for solving nonlinear fractional stochastic differential equations with delay. Stoch. Anal. Appl. 2019, 37, 893–908. [Google Scholar] [CrossRef]
- Moghaddam, B.; Zhang, L.; Lopes, A.; Tenreiro Machado, J.; Mostaghim, Z. Sufficient conditions for existence and uniqueness of fractional stochastic delay differential equations. Stochastics 2020, 92, 379–396. [Google Scholar] [CrossRef]
- Jahanshahi, H.; Jafarzadeh, M.; Sari, N.N.; Pham, V.T.; Huynh, V.V.; Nguyen, X.Q. Robot motion planning in an unknown environment with danger space. Electronics 2019, 8, 201. [Google Scholar] [CrossRef] [Green Version]
- Tibaldi, M.; Palermo, G.; Pilato, C. Dynamically-Tunable Dataflow Architectures Based on Markov Queuing Models. Electronics 2022, 11, 555. [Google Scholar] [CrossRef]
- Ouyang, W.; Chen, Z.; Wu, J.; Yu, G.; Zhang, H. Dynamic Task Migration Combining Energy Efficiency and Load Balancing Optimization in Three-Tier UAV-Enabled Mobile Edge Computing System. Electronics 2021, 10, 190. [Google Scholar] [CrossRef]
- Bertsekas, D.P.; Castanon, D.A. Rollout algorithms for stochastic scheduling problems. J. Heuristics 1999, 5, 89–108. [Google Scholar] [CrossRef]
- Huang, Q.L.; Jia, Q.S.; Qiu, Z.F.; Guan, X.H.; Deconinck, G. Matching EV charging load with uncertain wind: A simulation-based policy improvement approach. IEEE Trans. Smart Grid 2015, 6, 1425–1433. [Google Scholar] [CrossRef]
- Sarkale, Y.; Nozhati, S.; Chong, E.K.P.; Ellingwood, B.R.; Mahmoud, H. Solving Markov decision processes for network-level post-hazard recovery via simulation optimization and rollout. In Proceedings of the IEEE 14th International Conference on Automation Science and Engineering, Munich, Germany, 20–24 August 2018; pp. 906–912. [Google Scholar]
- Kim, S.H.; Nelson, B.L. A fully sequential procedure for indifference-zone selection in simulation. ACM Trans. Model. Comput. 2001, 11, 251–273. [Google Scholar] [CrossRef]
- Choi, S.H.; Kim, T.G. Efficient ranking and selection for stochastic simulation model based on hypothesis test. IEEE Trans. Syst. Man Cybern. Syst. 2017, 48, 1555–1565. [Google Scholar] [CrossRef]
- Chen, C.H.; Lin, J.W.; Yücesan, E.; Chick, S.E. Simulation budget allocation for further enhancing the efficiency of ordinal optimization. J. Discr. Event Dyn. Syst. Theory Appl. 2000, 10, 251–270. [Google Scholar] [CrossRef] [Green Version]
- Jia, Q.S. Efficient computing budget allocation for simulation-based policy improvement. IEEE Trans. Autom. Sci. Eng. 2012, 9, 342–352. [Google Scholar] [CrossRef]
- Wu, D.; Jia, Q.S.; Chen, C.H. Sample path sharing in simulation-based policy improvement. In Proceedings of the IEEE International Conference on Robotics and Automation, Hong Kong, China, 31 May–5 June 2014; pp. 3291–3296. [Google Scholar]
- Huang, X.L.; Choi, S.H. A Simulation Sample Accumulation Method for Efficient Simulation-based Policy Improvement in Markov Decision Process. J. Korea Multimed. Soc. 2020, 23, 830–839. [Google Scholar]
- DeGroot, M.H. Optimal Statistical Decisions; John Wiley & Sons: Hoboken, NJ, USA, 2005; Volume 82. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Description | Allocation Rule | Best Action Selection |
|---|---|---|---|
| EA | Standard SBPI | ||
| OCBAPI | Using OCBA to allocate the simulation budget efficiently | Equation (12) | |
| OCBA-S | Improving efficiency of OCBAPI with sample path sharing | Equation (12) | |
| EA-SA | Using sample accumulation for EA to select the best action via Equation (27) | ||
| OCBAPI-SA | Using sample accumulation for OCBAPI to select the best action via Equation (27) | Equation (12) | |
| OCBAPI-SA2 (Algorithm 1) | Using the estimated mean from Equation (27) and variance from Equation (28) of the Q-value to efficiently allocate computing budget for OCBAPI-SA. | use , for Equation (12) |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Huang, X.; Choi, S.H. An Efficient Simulation-Based Policy Improvement with Optimal Computing Budget Allocation Based on Accumulated Samples. Electronics 2022, 11, 1141. https://doi.org/10.3390/electronics11071141
Huang X, Choi SH. An Efficient Simulation-Based Policy Improvement with Optimal Computing Budget Allocation Based on Accumulated Samples. Electronics. 2022; 11(7):1141. https://doi.org/10.3390/electronics11071141
Chicago/Turabian StyleHuang, Xilang, and Seon Han Choi. 2022. "An Efficient Simulation-Based Policy Improvement with Optimal Computing Budget Allocation Based on Accumulated Samples" Electronics 11, no. 7: 1141. https://doi.org/10.3390/electronics11071141