
Recommending Reforming Trip to a Group of Users

 ,
,  ,
,  , ,
, ,
Abstract
:1. Introduction
- This advanced research introduces a progressive sequence of the POI suggestion structures named RRT, through which one can recommend a sequence of POIs dynamically as per the recorded direction;
- To utilize different data about POIs, such as geographical data, the POI embeds quality and the absolute impacts of recorded demand with the positional encoding in the RRT;
- This advanced research likewise introduces two advanced measurements, i.e., adjusted precision (AP) and sequence-mindful precision (SMP), that examine both POI property and traveling order and can assess the suggestion precision of the sequence of POIs;
- This research recommends a series of POIs to a group of users, and not only to a single user;
- We appraise the performance of RRT with real-world datasets from Weeplaces and compare it with some baselines. The experimental results show that RRT is superior to other trip recommendation techniques.
2. Related Work
3. Our Approach
3.1. Problem Statement
3.2. Summing-Up the Designed Framework
3.3. Generating a Trip for a Group of Users
3.4. Explanation of Model Design
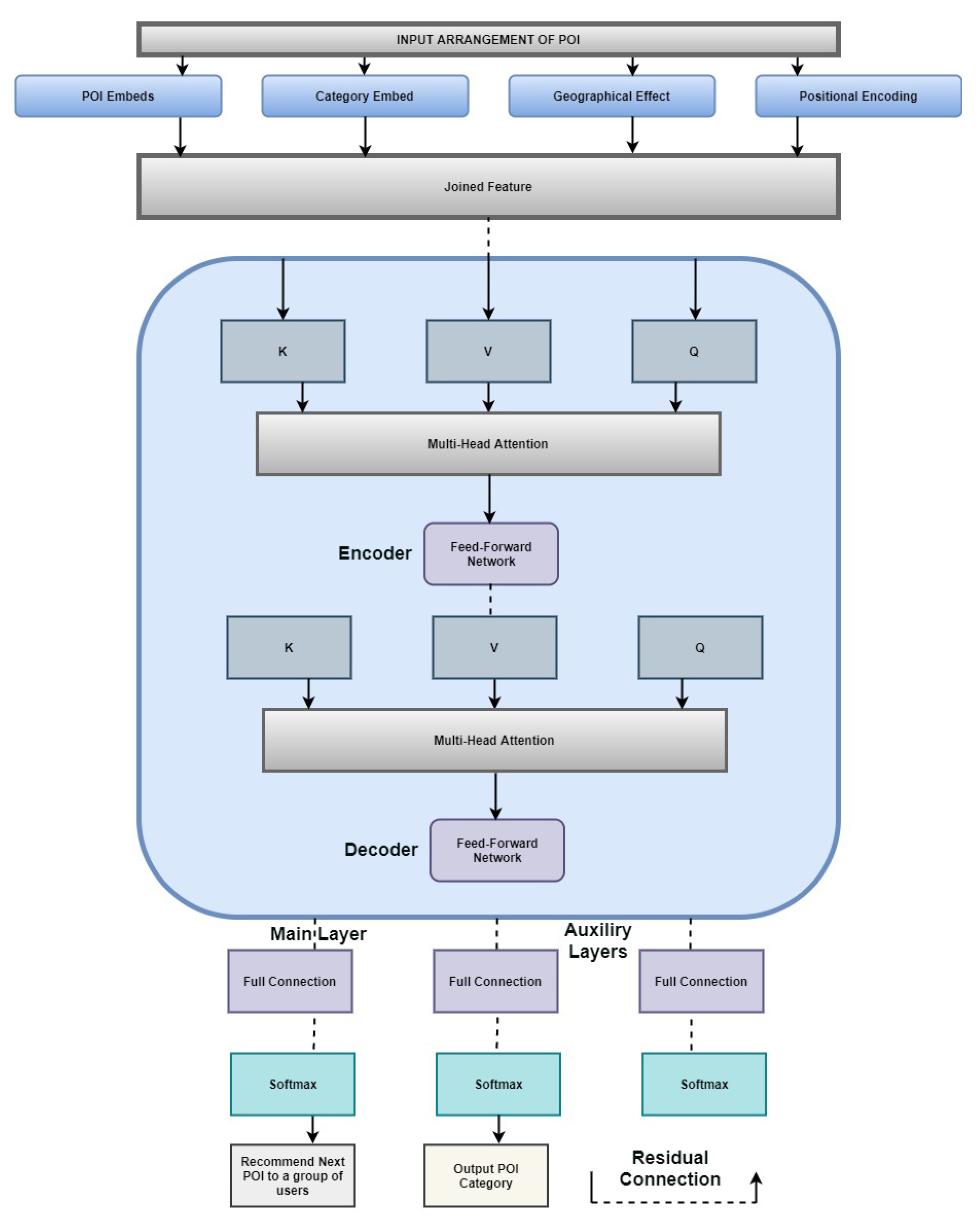
3.4.1. Input Part
3.4.2. Encoder and Decoder Part
3.4.3. Output Part
3.5. Dynamic Recommendation
4. Experiments
4.1. Experimental Setup
4.1.1. The Dataset
4.1.2. Evaluation Metrics
4.1.3. Baselines and Implementation Details
- LOcation REcommendation (LORE) [30]. This first mines successive examples of certain POI arrangements and represents the successive examples as a unique location–location transition graph (LLTG). In light of the LLTG and the geographical effect, LORE would be able to foresee the user’s likelihood of traveling to every POI.
- Additive Markov Chain (AMC) [31]. This suggests POI arrangements by utilizing consecutive impact. In particular, given an authentic direction Su of the user u, while suggesting the POI at location p, AMC at first provides likelihood figures of the user’s traveling to every POI dependent upon the full set of POIs before location p. This suggests the POI with extreme likelihood at location p.
- RAND. The random-based strategy arbitrarily suggests POIs among the applicants to which the objective user has not traveled.
- LSTM-Seq2Seq [24]. This involves a multifaceted long short-term memory (LSTM) to plan the input grouping to a vector having a fixed measurement, and afterward utilizes another profound LSTM to translate the objective succession from the vector.
4.1.4. The Variable Setting
4.2. Experimental Results
4.3. The Impact of Components
4.4. Cold-Start Problem
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Zheng, Y.; Zhou, X. Computing with Spatial Trajectories, 1st ed.; Springer: Berlin/Heidelberg, Germany, 2011; Available online: https://www.springer.com/gp/book/9781461416289 (accessed on 20 February 2022).
- Mei, T.; Hsu, W.H.; Luo, J. Knowledge Discovery from Community-Contributed Multimedia. IEEE Multimed. 2010, 17, 16–17. Available online: https://ieeexplore.ieee.org/document/5638050 (accessed on 20 February 2022). [CrossRef]
- Cheng, C.; Yang, H.; Lyu, M.R.; King, I. Where you like to go next: Successive point-of-interest recommendation. In Proceedings of the IJCAI International Joint Conference on Artificial Intelligence, Beijing, China, 3–9 August 2013; pp. 2605–2611. Available online: https://www.aaai.org/ocs/index.php/IJCAI/IJCAI13/paper/view/6633 (accessed on 20 February 2022).
- Liu, Q.; Wu, S.; Wang, L.; Tan, T. Predicting the Next Location: A Recurrent Model with Spatial and Temporal Contexts. In Proceedings of the Thirtieth AAAI Conference on Artificial Intelligence, Phoenix, AZ, USA, 12–17 February 2016; pp. 194–200. Available online: https://www.aaai.org/ocs/index.php/AAAI/AAAI16/paper/view/11900 (accessed on 20 February 2022).
- Baral, R.; Li, T. Exploiting the roles of aspects in personalized POI recommender systems. Data Min. Knowl. Discov. 2017, 32, 320–343. [Google Scholar] [CrossRef]
- Choudhury, M.D.; Feldman, M.; Amer-Yahia, S.; Golbandi, N.; Lempel, R.; Yu, C. Automatic construction of travel itineraries using social breadcrumbs. In Proceedings of the 21st ACM Conference on Hypertext and Hypermedia, Toronto, ON, Canada, 13–16 June 2010; pp. 35–44. [Google Scholar] [CrossRef]
- Bolzoni, P.; Helmer, S.; Wellenzohn, K.; Gamper, J.; Andritsos, P. Efficient Itinerary Planning with Category Constraints. In Proceedings of the 22nd ACM SIGSPATIAL International Conference on Advances in Geographic Information Systems, Dallas, TX, USA, 4–7 November 2014; ACM: New York, NY, USA, 2014; pp. 203–212. [Google Scholar] [CrossRef] [Green Version]
- Bin, C.; Gu, T.; Sun, Y.; Chang, L.; Sun, W.; Sun, L. Personalized POIs Travel Route Recommendation System Based on Tourism Big Data. In Proceedings of the 15th Pacific Rim International Conference on Artificial Intelligence, Nanjing, China, 28–31 August 2018; pp. 290–299. Available online: https://www.springerprofessional.de/en/personalized-pois-travel-route-recommendation-system-based-on-to/15986358 (accessed on 20 February 2022).
- Lim, K.H.; Chan, J.; Leckie, C.; Karunasekera, S. Personalized trip recommendation for tourists based on user interests, points of interest visit durations and visit recency. Knowl. Inf. Syst. 2018, 54, 375–406. [Google Scholar] [CrossRef]
- Porras, C.; Pérez-Cañedo, B.; Pelta, D.A.; Verdegay, J.L. A Critical Analysis of a Tourist Trip Design Problem with Time-Dependent Recommendation Factors and Waiting Times. Electronics 2022, 11, 357. [Google Scholar] [CrossRef]
- Zhang, M.; Yang, Y.; Abbas, R.; Deng, K.; Li, J.; Zhang, B. SNPR: A Serendipity-Oriented Next POI Recommendation Model. In Proceedings of the CIKM ’21 30th ACM International Conference on Information & Knowledge Management, Gold Coast, Australia, 1–5 November 2021. [Google Scholar] [CrossRef]
- Lu, E.H.C.; Chen, C.Y.; Tseng, V.S. Personalized trip recommendation with multiple constraints by mining user check-in behaviors. In Proceedings of the SIGSPATIAL ’12 20th International Conference on Advances in Geographic Information Systems, Beach, CA, USA, 6–9 November 2012; pp. 209–218. [Google Scholar] [CrossRef]
- Gionis, A.; Lappas, T.; Pelechrinis, K.; Terzi, E. Customized tour recommendations in urban areas. In Proceedings of the WSDM ’14 7th ACM International Conference on Web Search and Data Mining, New York, NY, USA, 24–28 February 2014; pp. 313–322. [Google Scholar] [CrossRef] [Green Version]
- Gavalas, D.; Konstantopoulos, C.; Mastakas, K.; Pantziou, G.; Vathis, N. Heuristics for the time dependent team orienteering problem: Application to tourist route planning. Comput. Oper. Res. 2015, 62, 36–50. Available online: https://www.sciencedirect.com/science/article/abs/pii/S0305054815000817 (accessed on 20 February 2022). [CrossRef]
- Jiang, S.; Qian, X.; Mei, T.; Fu, Y. Personalized Travel Sequence Recommendation on Multi-Source Big Social Media. IEEE Trans. Big Data 2016, 2, 43–56. Available online: https://ieeexplore.ieee.org/document/7444160 (accessed on 20 February 2022). [CrossRef]
- Wu, Y.; Li, K.; Zhao, G.; Qian, X. Long- and Short-Term Preference Learning for Next POI Recommendation. In Proceedings of the CIKM ’19 28th ACM International Conference on Information and Knowledge Management, Beijing, China, 3–7 November 2019; pp. 2301–2304. [Google Scholar] [CrossRef] [Green Version]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Advances in Neural Information Processing Systems; 30 Curran Associates, Inc.: Red Hook, NY, USA, 2017; pp. 5998–6008. Available online: https://arxiv.org/pdf/1706.03762.pdf (accessed on 20 February 2022).
- Covington, P.; Adams, J.; Sargin, E. Deep Neural Networks for YouTube Recommendations. In Proceedings of the 10th ACM Conference on Recommender Systems, Boston, MA, USA, 15–19 September 2016; ACM: New York, NY, USA, 2016; pp. 191–198. [Google Scholar]
- Ding, R.; Chen, Z. A deep neural network for personalized POI recommendation in location-based social networks. Int. J. Geogr. Inf. Sci. 2018, 32, 1631–1648. [Google Scholar] [CrossRef]
- Lin, I.C.; Lu, Y.S.; Shih, W.Y.; Huang, J.L. Successive POI Recommendation with Category Transition and Temporal Influence. In Proceedings of the 2018 IEEE 42nd Annual Computer Software and Applications Conference (COMPSAC), Tokyo, Japan, 23–27 July 2018; pp. 23–27. Available online: https://ieeexplore.ieee.org/document/8377830/ (accessed on 20 February 2022).
- Wang, H.; Shen, H.; Ouyang, W.; Cheng, X. Exploiting POI-Specific Geographical Influence for Point-of-Interest Recommendation. In Proceedings of the Twenty-Seventh International Joint Conference on Artificial Intelligence, Stockholm, Sweden, 13–19 July 2018; pp. 3877–3883. [Google Scholar] [CrossRef] [Green Version]
- Hornik, K. Approximation Capabilities of Multilayer Feedforward Networks. Neural Netw. 1991, 4, 251–257. Available online: https://linkinghub.elsevier.com/retrieve/pii/089360809190009T (accessed on 20 February 2022). [CrossRef]
- Cho, K.; van Merrienboer, B.; Gülçehre, Ç.; Bougares, F.; Schwenk, H.; Bengio, Y. Learning Phrase Representations using RNN Encoder–Decoder for Statistical Machine Translation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 25–29 October 2014; pp. 175–191. [Google Scholar]
- Sutskever, I.; Vinyals, O.; Le, Q.V. Sequence to Sequence Learning with Neural Networks. In Advances in Neural Information Processing Systems; Curran Associates, Inc.: Red Hook, NY, USA, 2014; pp. 3104–3112. Available online: https://proceedings.neurips.cc/paper/2014/hash/a14ac55a4f27472c5d894ec1c3c743d2-Abstract.html (accessed on 20 February 2022).
- Kim, Y.; Denton, C.; Hoang, L.; Rush, A.M. Structured Attention Networks. arXiv 2017, arXiv:1702.00887. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. Available online: https://ieeexplore.ieee.org/document/7780459 (accessed on 20 February 2022).
- Liu, X.; Liu, Y.; Aberer, K.; Miao, C. Personalized Point-of-interest Recommendation by Mining Users’ Preference Transition. In Proceedings of the 22nd ACM International Conference on Information & Knowledge Management, San Francisco, CA, USA, 27 October–1 November 2013; pp. 733–738. [Google Scholar] [CrossRef]
- Zhao, P.; Zhu, H.; Liu, Y.; Li, Z.; Xu, J.; Sheng, V.S. Where to Go Next: A Spatio-temporal LSTM model for Next POI Recommendation. arXiv 2018, arXiv:1806.06671. [Google Scholar]
- Baral, R.; Iyengar, S.S.; Li, T.; Zhu, X. HiCaPS: Hierarchical Contextual POI Sequence Recommender. In Proceedings of the 26th ACM SIGSPATIAL International Conference on Advances in Geographic Information Systems, Seattle, WA, USA, 6–9 November 2018; pp. 436–439. [Google Scholar] [CrossRef]
- Zhang, J.D.; Chow, C.Y.; Li, Y. LORE: Exploiting Sequential Influence for Location Recommendations. In Proceedings of the 22nd ACM SIGSPATIAL International Conference on Advances in Geographic Information Systems, Dallas, TX, USA, 4–7 November 2014; pp. 103–112. [Google Scholar] [CrossRef]
- Usatenko, O. Random Finite-Valued Dynamical Systems: Additive Markov Chain Approach. In Kharkov Series in Physics and Mathematics; Cambridge Scientific Publishers: Cambridge, UK, 2009; Available online: https://iucat.iu.edu/iun/11414611 (accessed on 20 February 2022).
- Abadi, M.; Barham, P.; Chen, J.; Chen, Z.; Davis, A.; Dean, J.; Devin, M.; Ghemawat, S.; Irving, G.; Isard, M.; et al. TensorFlow: A System for Large-Scale Machine Learning. In Proceedings of the 12th USENIX Symposium on Operating Systems Design and Implementation (OSDI 16), Savannah, GA, USA, 2–4 November 2016; pp. 265–283. Available online: https://www.usenix.org/conference/osdi16/technical-sessions/presentation/abadi (accessed on 20 February 2022).


{kind=link}
| Items | NY | SF | BK | LDN |
|---|---|---|---|---|
| Total users | 4811 | 3220 | 2724 | 1935 |
| Total POIs | 28,333 | 13,366 | 7334 | 10,405 |
| Total check-ins | 720,350 | 330,975 | 159,946 | 147,610 |
| Number of Users per Group | ||||||||
|---|---|---|---|---|---|---|---|---|
| Cities | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
| NY | 15,915 | 18,685 | 19,451 | 17,774 | 15,602 | 13,789 | 11,386 | 7951 |
| SF | 9633 | 9486 | 6777 | 3369 | 1121 | 265 | 45 | 4 |
| BK | 8750 | 9552 | 8633 | 6142 | 3452 | 1579 | 585 | 160 |
| LDN | 3398 | 1716 | 711 | 269 | 102 | 36 | 9 | 1 |
| NY | SF | BK | LDN | |||||
|---|---|---|---|---|---|---|---|---|
| Methods | AP | SMP | AP | SMP | AP | SMP | AP | SMP |
| RAND | 0.09 | 0.010 | 0.004 | 0.064 | 0.009 | 0.165 | 0.009 | 0.023 |
| AMC | 5.232 | 8.454 | 6.565 | 8.454 | 7.343 | 11.343 | 9.454 | 14.655 |
| LORE | 6.354 | 8.234 | 7.675 | 8.345 | 8.454 | 10.343 | 11.354 | 13.564 |
| LSTM | 7.243 | 11.345 | 9.354 | 13.344 | 8.456 | 20.456 | 12.453 | 25.454 |
| RRT | 8.443 | 18.453 | 12.454 | 17.344 | 9.453 | 21.453 | 13.453 | 27.344 |
| NY | SF | BK | LDN | |||||
|---|---|---|---|---|---|---|---|---|
| Methods | AP | SMP | AP | SMP | AP | SMP | AP | SMP |
| RAND | 0.005 | 0.024 | 0.005 | 0.024 | 0.009 | 0.024 | 0.014 | 0.024 |
| AMC | 5.543 | 9.453 | 4.656 | 9.345 | 6.453 | 12.564 | 9.344 | 18.353 |
| LORE | 4.344 | 8.634 | 4.233 | 6.345 | 6.345 | 9.344 | 10.344 | 14.454 |
| LSTM | 6.454 | 17.433 | 6.345 | 17.345 | 7.345 | 16.345 | 10.343 | 25.343 |
| RRT | 7.353 | 19.445 | 7.454 | 18.434 | 10.354 | 20.345 | 13.343 | 28.344 |
| NY | SF | BK | LDN | |||||
|---|---|---|---|---|---|---|---|---|
| Methods | Precision | Recall | Precision | Recall | Precision | Recall | Precision | Recall |
| RAND | 0.004 | 0.004 | 0.003 | 0.002 | 0.004 | 0.008 | 0.001 | 0.001 |
| AMC | 0.633 | 0.750 | 1.644 | 1.435 | 3.644 | 12.453 | 2.634 | 9.453 |
| LORE | 1.455 | 5.345 | 4.345 | 0.453 | 0.534 | 9.453 | 3.453 | 9.543 |
| LSTM | 2.453 | 7.454 | 4.454 | 2.454 | 5.454 | 13.544 | 4.454 | 10.345 |
| RRT | 4.444 | 10.454 | 5.454 | 5.434 | 7.544 | 14.454 | 6.544 | 13.343 |
| NY | SF | BK | LDN | |||||
|---|---|---|---|---|---|---|---|---|
| Methods | Precision | Recall | Precision | Recall | Precision | Recall | Precision | Recall |
| RAND | 0.001 | 0.002 | 0.013 | 0.013 | 0.014 | 0.032 | 0.031 | 0.029 |
| AMC | 0.454 | 1.444 | 3.454 | 0.988 | 1.454 | 9.454 | 1.454 | 4.454 |
| LORE | 0.454 | 5.454 | 1.454 | 0.865 | 0.234 | 10.454 | 0.454 | 6.454 |
| LSTM | 0.745 | 6.454 | 6.454 | 1.454 | 2.454 | 11.454 | 1.454 | 8.545 |
| RRT | 2.454 | 7.545 | 7.454 | 3.454 | 5.454 | 13.344 | 3.645 | 10.454 |
| NY | SF | BK | LDN | |||||
|---|---|---|---|---|---|---|---|---|
| Methods | AP | SMP | AP | SMP | AP | SMP | AP | SMP |
| RRT | 8.443 | 18.453 | 12.454 | 17.344 | 9.453 | 21.453 | 13.453 | 27.344 |
| No PE | 1.435 | 2.343 | 2.534 | 4.433 | 2.444 | 5.234 | 3.443 | 6.453 |
| No CE | 5.454 | 8.354 | 6.344 | 9.354 | 7.345 | 13.345 | 10.544 | 16.354 |
| No GE | 6.454 | 8.454 | 7.354 | 9.545 | 7.544 | 12.454 | 11.543 | 12.354 |
| No Pos | 2.454 | 3.454 | 5.454 | 8.454 | 6.344 | 10.454 | 8.454 | 11.454 |
| NY | SF | BK | LDN | |||||
|---|---|---|---|---|---|---|---|---|
| Methods | AP | SMP | AP | SMP | AP | SMP | AP | SMP |
| RAND | 0.003 | 0.024 | 0.008 | 0.054 | 0.016 | 0.032 | 0.013 | 0.024 |
| AMC | 1.434 | 5.345 | 1.434 | 2.453 | 3.454 | 5.453 | 2.345 | 5.533 |
| LORE | 3.543 | 6.543 | 1.453 | 2.434 | 4.453 | 6.534 | 5.534 | 7.534 |
| LSTM | 3.453 | 7.453 | 3.453 | 6.453 | 6.753 | 15.435 | 8.454 | 18.345 |
| RRT | 4.434 | 10.453 | 5.434 | 9.643 | 6.953 | 16.454 | 8.745 | 22.453 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Abbas, R.; Amran, G.A.; Alsanad, A.; Ma, S.; Almisned, F.A.; Huang, J.; Al Bakhrani, A.A.; Ahmed, A.B.; Alzahrani, A.I. Recommending Reforming Trip to a Group of Users. Electronics 2022, 11, 1037. https://doi.org/10.3390/electronics11071037
Abbas R, Amran GA, Alsanad A, Ma S, Almisned FA, Huang J, Al Bakhrani AA, Ahmed AB, Alzahrani AI. Recommending Reforming Trip to a Group of Users. Electronics. 2022; 11(7):1037. https://doi.org/10.3390/electronics11071037
Chicago/Turabian StyleAbbas, Rizwan, Gehad Abdullah Amran, Ahmed Alsanad, Shengjun Ma, Faisal Abdulaziz Almisned, Jianfeng Huang, Ali Ahmed Al Bakhrani, Almesbahi Belal Ahmed, and Ahmed Ibrahim Alzahrani. 2022. "Recommending Reforming Trip to a Group of Users" Electronics 11, no. 7: 1037. https://doi.org/10.3390/electronics11071037