
TdmTracker: Multi-Object Tracker Guided by Trajectory Distribution Map


Abstract
:1. Introduction
- We propose TdmTracker, a novel anchor-free attention mechanism-based end-to-end MOT model, which presents a more unified and lightweight architecture by integrating separate subtasks into a whole network. It has comparable tracking accuracy with other state-of-the-art MOT methods and achieves a relatively high efficiency.
- We adopt a comparative learning mode similar to that in few-shot learning and utilize optimized class query instead of static learned object query to detect objects of target category. Our model takes optimized class query and track query to form the adaptive query embedding set to realize the unification of query-key attention operations.
- We propose a trajectory distribution map for motion prediction to realize tracking conditioned detection and association through predicted trajectory.
2. Related Works
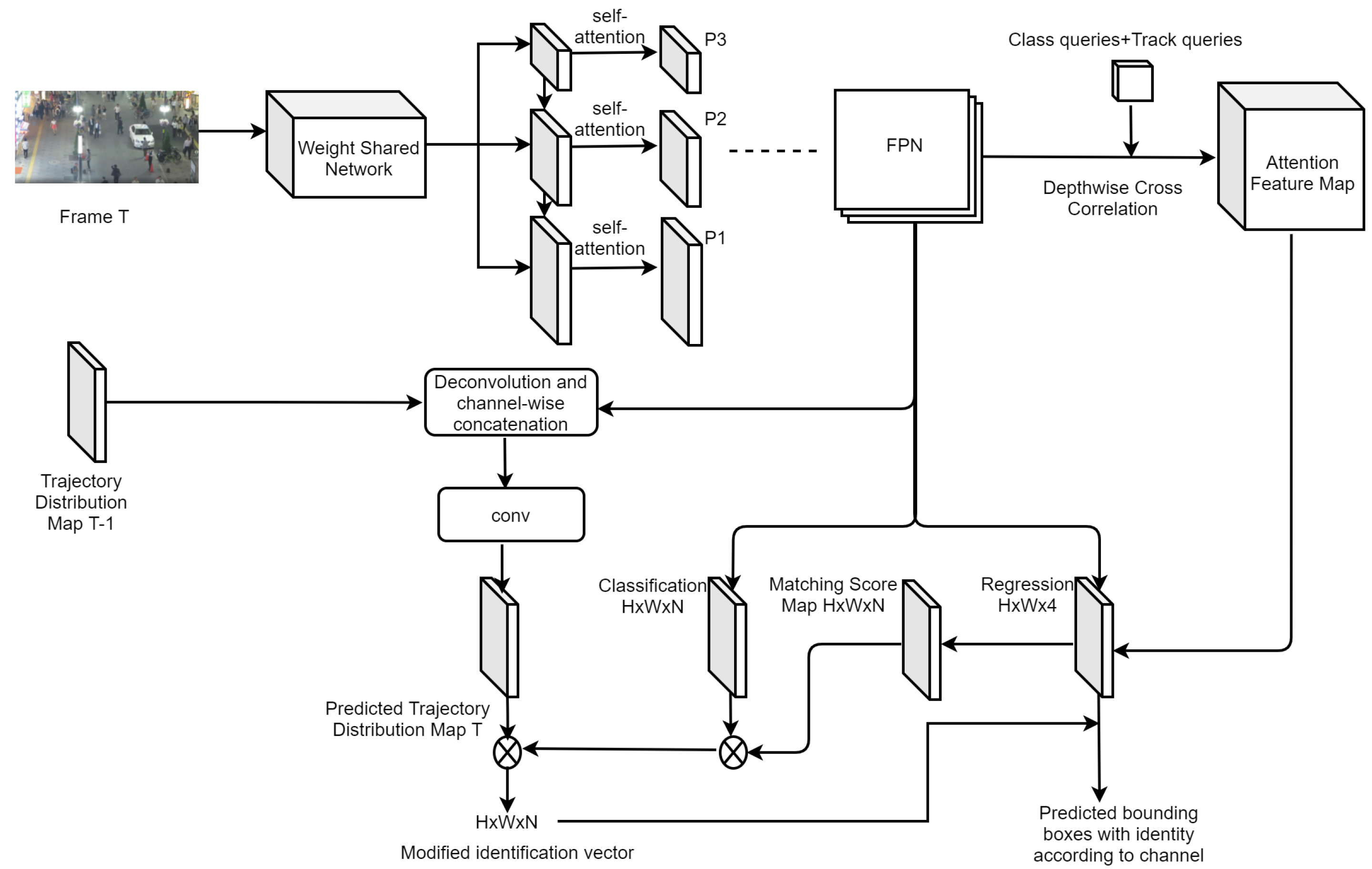
3. TdmTracker
3.1. Architecture and Pipeline
3.2. Model Details
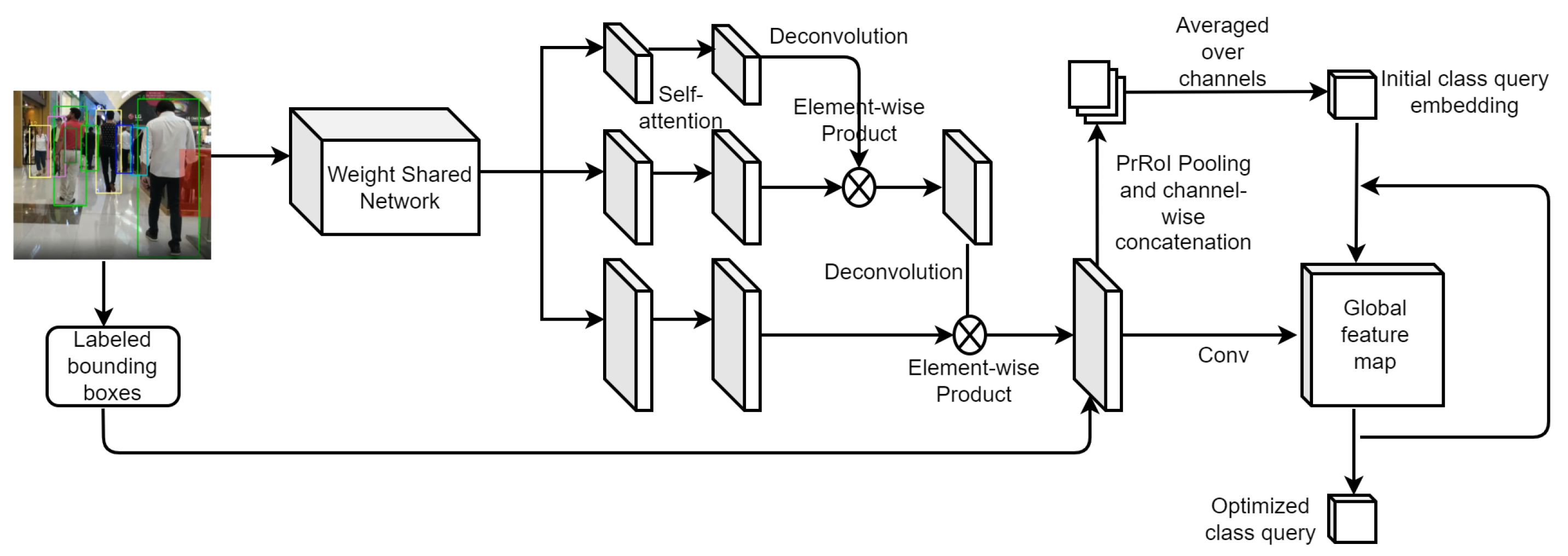
3.2.1. Optimized Class Query
3.2.2. Adaptive Query Embedding Set and Attention Feature Map
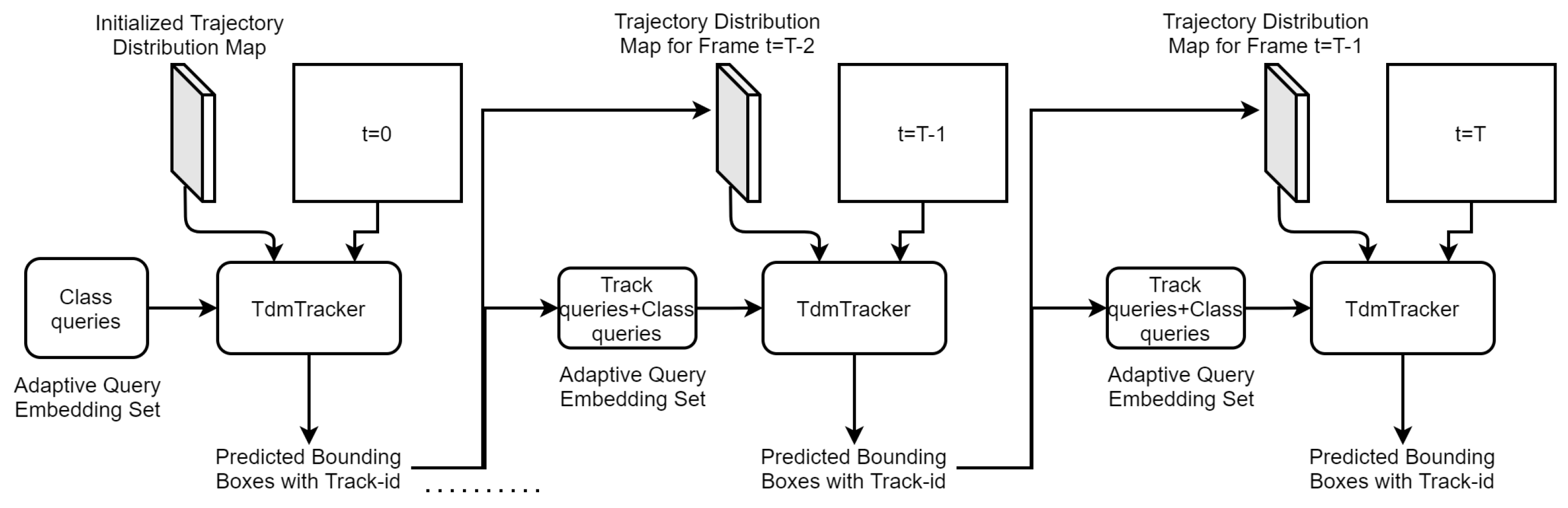
3.2.3. Trajectory Distribution Map
3.2.4. Matching Score Map
4. Training TdmTracker
4.1. Dataset
4.2. Training Strategy and Training Loss
4.3. Post-Processing
5. Experiments
5.1. Implementation Details and Evaluation Metrics
5.2. Model Differences and Performance Comparison with Other MOT Methods on MOT17
5.3. Ablation Studies
- Baseline. It only covers the classification branch and the bounding box regression branch, without guidance from the trajectory distribution map. In addition, it does not use self-attention to encode the relationship between pixel patches and the relationship between queries to obtain more representative embedding, and we use static learned object query instead of optimized class query.
- Baseline + Tdm. Based on Baseline, it adds the branch of predicting trajectory distribution map to adjust the final result.
- Baseline + Tdm + Cq. It uses optimized class query instead of static learned object query on the basis of model (2).
- TdmTracker. It uses self-attention to encode the relationship between pixel patches and the relationship between queries to obtain more representative embedding on the basis of model (3). It is the complete version of our proposed model.
5.4. Comparison of Different Loss Functions for Training the Branches of Classification and Regression
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Conflicts of Interest
References
- Wojke, N.; Bewley, A.; Paulus, D. Simple online and realtime tracking with a deep association metric. In Proceedings of the 2017 IEEE International Conference on Image Processing (ICIP), Beijing, China, 17–20 September 2017; pp. 3645–3649. [Google Scholar]
- Kumar, M.; Chhabra, P.; Garg, N.K. An efficient content based image retrieval system using bayesnet and k-nn. Multimed. Tools Appl. 2018, 77, 21557–21570. [Google Scholar] [CrossRef]
- Chhabra, P.; Garg, N.K.; Kumar, M. Content-based image retrieval system using ORB and SIFT features. Neural Comput. Appl. 2020, 32, 2725–2733. [Google Scholar] [CrossRef]
- Garg, D.; Garg, N.K.; Kumar, M. Underwater image enhancement using blending of CLAHE and percentile methodologies. Multimed. Tools Appl. 2017, 77, 26545–26561. [Google Scholar] [CrossRef]
- Wang, Q.; Zheng, Y.; Pan, P.; Xu, Y. Multiple Object Tracking with Correlation Learning. arXiv 2021, arXiv:2104.03541. [Google Scholar]
- Bewley, A.; Ge, Z.; Ott, L.; Ramos, F.; Upcroft, B. Simple online and realtime tracking. In Proceedings of the 2016 IEEE International Conference on Image Processing (ICIP), Phoenix, AZ, USA, 25–28 September 2016. [Google Scholar] [CrossRef] [Green Version]
- Kumar, M.; Kumar, R.; Saluja, K.K.; Singh, N. Gait Recognition Based on Vision Systems: A Systematic Survey. J. Vis. Commun. Image Represent. 2021, 75, 103052. [Google Scholar] [CrossRef]
- Gupta, S.; Kumar, M.; Garg, A. Improved object recognition results using SIFT and ORB feature detector. Multimed. Tools Appl. 2019, 78, 34157–34171. [Google Scholar] [CrossRef]
- Kumar, M.; Gupta, S. 2D-human face recognition using SIFT and SURF descriptors of face’s feature regions. Vis. Comput. 2021, 37, 447–456. [Google Scholar]
- Wang, Z.; Zheng, L.; Liu, Y.; Li, Y.; Wang, S. Towards Real-Time Multi-Object. In Proceedings of the Computer Vision—ECCV 2020, Glasgow, UK, 23–28 August 2020; Springer: Cham, Switzerland, 2020. [Google Scholar]
- Zhang, Y.; Wang, C.; Wang, X.; Zeng, W.; Liu, W. FairMOT: On the Fairness of Detection and Re-Identification in Multiple Object Tracking. arXiv 2021, arXiv:2004.01888. [Google Scholar] [CrossRef]
- Zhou, X.; Koltun, V.; Krhenbühl, P. Tracking Objects as Points. arXiv 2020, arXiv:2004.01177. [Google Scholar]
- Peng, J.; Wang, C.; Wan, F.; Wu, Y.; Fu, Y. Chained-Tracker: Chaining Paired Attentive Regression Results for End-to-End Joint Multiple-Object Detection and Tracking. arXiv 2020, arXiv:2007.14557. [Google Scholar]
- Carion, N.; Massa, F.; Synnaeve, G.; Usunier, N.; Kirillov, A.; Zagoruyko, S. End-to-End Object Detection with Transformers. arXiv 2020, arXiv:2005.12872. [Google Scholar]
- Fan, Q.; Zhuo, W.; Tang, C.K.; Tai, Y.W. Few-Shot Object Detection With Attention-RPN and Multi-Relation Detector. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Meinhardt, T.; Kirillov, A.; Leal-Taixe, L.; Feichtenhofer, C. TrackFormer: Multi-Object Tracking with Transformers. arXiv 2021, arXiv:2101.02702. [Google Scholar]
- Zhu, X.; Su, W.; Lu, L.; Li, B.; Dai, J. Deformable DETR: Deformable Transformers for End-to-End Object Detection. arXiv 2021, arXiv:2010.04159. [Google Scholar]
- Sun, P.; Jiang, Y.; Zhang, R.; Xie, E.; Luo, P. TransTrack: Multiple Object Tracking with Transformer. arXiv 2021, arXiv:2012.15460. [Google Scholar]
- Gao, Y.; Hou, R.; Gao, Q.; Hou, Y. A fast and accurate few-shot detector for objects with fewer pixels in drone image. Electronics 2021, 10, 783. [Google Scholar] [CrossRef]
- Bochinski, E.; Eiselein, V.; Sikora, T. High-Speed Tracking-by-Detection Without Using Image Information. In Proceedings of the International Workshop on Traffic and Street Surveillance for Safety and Security at IEEE AVSS 2017, Lecce, Italy, 29 August–1 September 2017. [Google Scholar]
- Pirsiavash, H.; Ramanan, D.; Fowlkes, C. Globally optimal greedy algorithms for tracking a variable number of objects. In Proceedings of the Computer Vision and Pattern Recognition, Colorado Springs, CO, USA, 20–25 June 2011. [Google Scholar]
- Kuhn, H.W. The hungarian method for the assignment problem. In 50 Years of Integer Programming 1958–2008; Jünger, M., Liebling, T.M., Naddef, D., Nemhauser, G.L., Pulleyblank, W.R., Reinelt, G., Rinaldi, G., Wolsey, L.A., Eds.; Springer: Berlin/Heidelberg, Germany, 2010. [Google Scholar] [CrossRef] [Green Version]
- Brasó, G.; Leal-Taixé, L. Learning a Neural Solver for Multiple Object Tracking. arXiv 2020, arXiv:1912.07515. [Google Scholar]
- Kim, C.; Li, F.; Ciptadi, A.; Rehg, J.M. Multiple Hypothesis Tracking Revisited, In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015.
- Wu, J.; Cao, J.; Song, L.; Wang, Y.; Yuan, J. Track to Detect and Segment: An Online Multi-Object Tracker. arXiv 2021, arXiv:2103.08808. [Google Scholar]
- Zhou, X.; Wang, D.; Krhenbühl, P. Objects as Points. arXiv 2019, arXiv:1904.07850. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. arXiv 2016, arXiv:1506.01497. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Learning to Compare: Relation Network for Few-Shot Learning. arXiv 2015, arXiv:1512.03385. [Google Scholar]
- Lin, T.Y.; Dollar, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature Pyramid Networks for Object Detection. arXiv 2017, arXiv:1612.03144. [Google Scholar]
- Jiang, B.; Luo, R.; Mao, J.; Xiao, T.; Jiang, Y. Acquisition of Localization Confidence for Accurate Object Detection. arXiv 2018, arXiv:1807.11590. [Google Scholar]
- Tian, Z.; Shen, C.; Chen, H.; He, T. FCOS: Fully convolutional one-stage object detection. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019. [Google Scholar]
- Jia, D.; Wei, D.; Socher, R.; Li, L.J.; Kai, L.; Li, F.F. Imagenet: A large-scale hierarchical image database. In Proceedings of the IEEE Computer Vision & Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Kuznetsova, A.; Rom, H.; Alldrin, N.; Uijlings, J.; Ferrari, V. The open images dataset v4: Unified image classification, object detection, and visual relationship detection at scale. Int. J. Comput. Vis. 2020, 128, 1956–1981. [Google Scholar] [CrossRef] [Green Version]
- Milan, A.; Leal-Taixe, L.; Reid, I.; Roth, S.; Schindler, K. MOT16: A Benchmark for Multi-Object Tracking. arXiv 2016, arXiv:1603.00831. [Google Scholar]
- Rezatofighi, H.; Tsoi, N.; Gwak, J.Y.; Sadeghian, A.; Savarese, S. Generalized Intersection Over Union: A Metric and a Loss for Bounding Box Regression. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 5–20 June 2019. [Google Scholar]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. In Proceedings of the IEEE Transactions on Pattern Analysis & Machine Intelligence, Venice, Italy, 22–29 October 2017; pp. 2999–3007. [Google Scholar]
- Kendall, A.; Gal, Y.; Cipolla, R. Multi-Task Learning Using Uncertainty to Weigh Losses for Scene Geometry and Semantics. arXiv 2018, arXiv:1705.07115. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | MOTA↑ | IDF1↑ | MT↑ | ML↓ | FP↓ | FN↓ | IDs↓ | Speed (Hz)↑ |
|---|---|---|---|---|---|---|---|---|
| DeepSORT | 60.3 | 61.2 | 31.5 | 20.3 | 36,111 | 185,301 | 2442 | 5.1 |
| FairMOT | 73.7 | 72.3 | 43.2 | 17.3 | 27,507 | 117,477 | 3303 | 6.1 |
| CTracker | 66.6 | 57.4 | 32.2 | 24.2 | 22,284 | 160,491 | 5529 | 9.0 |
| CenterTrack | 67.8 | 64.7 | 34.6 | 24.6 | 18,498 | 160,332 | 3039 | 5.2 |
| TrackFormer | 65.0 | 63.9 | 45.5 | 13.8 | 70,443 | 123,552 | 3528 | 8.7 |
| TransTrack | 74.5 | 63.9 | 46.8 | 11.3 | 28,323 | 112,137 | 3663 | 6.4 |
| TdmTracker (ours) | 70.2 | 65.5 | 43.1 | 15.4 | 30,367 | 115,986 | 3265 | 10.7 |
| Model | MOTA↑ | IDF1↑ | MT↑ | ML↓ | FP↓ | FN↓ | IDs↓ |
|---|---|---|---|---|---|---|---|
| Baseline | 52.4 | 51.9 | 30.6 | 25.4 | 64,597 | 120,895 | 7351 |
| Baseline + Tdm | 61.8 | 59.6 | 36.9 | 19.3 | 32,262 | 135,603 | 4176 |
| Baseline + Tdm + Cq | 69.1 | 64.7 | 42.6 | 15.8 | 30,980 | 115,054 | 3317 |
| TdmTracker | 70.2 | 65.5 | 43.1 | 15.4 | 30,367 | 115,986 | 3265 |
| Loss Function | Weighting Strategy | Detection | MOT | |
|---|---|---|---|---|
| AP↑ | MOTA↑ | IDs↓ | ||
| App.Opt | 78.4 | 60.7 | 4266 | |
| Uncertainty | 79.5 | 62.2 | 4037 | |
| App.Opt | 83.6 | 68.3 | 3603 | |
| Uncertainty | 84.8 | 70.2 | 3265 | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gao, Y.; Gu, X.; Gao, Q.; Hou, R.; Hou, Y. TdmTracker: Multi-Object Tracker Guided by Trajectory Distribution Map. Electronics 2022, 11, 1010. https://doi.org/10.3390/electronics11071010
Gao Y, Gu X, Gao Q, Hou R, Hou Y. TdmTracker: Multi-Object Tracker Guided by Trajectory Distribution Map. Electronics. 2022; 11(7):1010. https://doi.org/10.3390/electronics11071010
Chicago/Turabian StyleGao, Yuxuan, Xiaohui Gu, Qiang Gao, Runmin Hou, and Yuanlong Hou. 2022. "TdmTracker: Multi-Object Tracker Guided by Trajectory Distribution Map" Electronics 11, no. 7: 1010. https://doi.org/10.3390/electronics11071010