
Enhancement of the HILOMOT Algorithm with Modified EM and Modified PSO Algorithms for Nonlinear Systems Identification


Abstract
:1. Introduction
2. Partition Strategies
2.1. Grid-Based and Clustering-Based Partitioning
2.2. Data-Based Partitioning
2.3. Nonlinear Optimization-Based Partitioning
2.4. Heuristic Tree-Based Partitioning
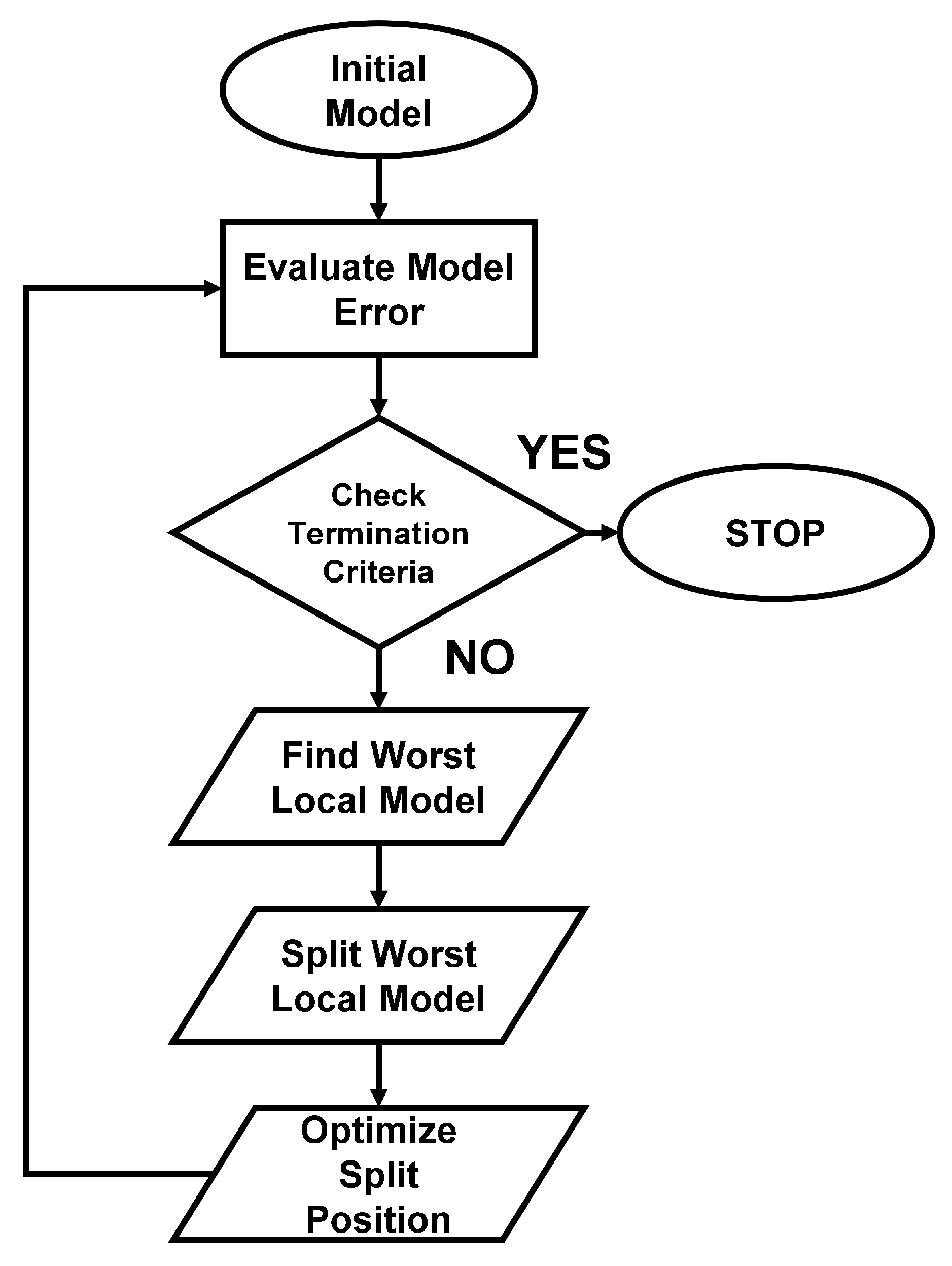
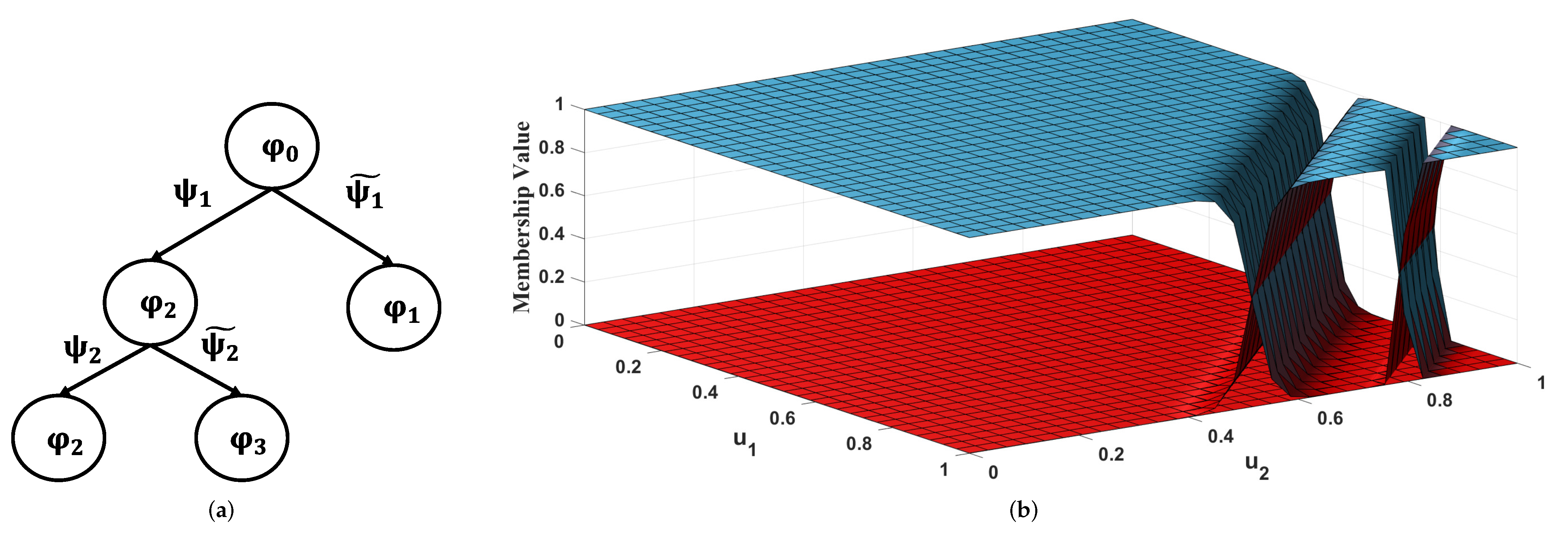
3. HILOMOT Algorithm
4. Split Optimization Algorithms
4.1. Expectation–Maximization (EM) Algorithm
- Initialize and .
- Step 1: Calculate the validity functions.
- Step 2: Calculate the local model parameters of the local models.
- Step 3: Optimize the reduced parameter vector .
- Step 4: Repeat steps 1 to 4 until the stopping criteria are met.
4.2. Particle Swarm Optimization (PSO) Algorithm
- Select appropriate values for , , , and .
- Initialize position and velocities of the entire swarm.
- Evaluate the objective function and update p and g.
- Step 1: Calculate w.
- Step 2: Calculate velocity of each particle.
- Step 3: Update current position for each particle.
- Step 4: Evaluate the objective function with current position.
- Step 5: Update p and g if required.
- Step 6: Repeat steps 1 to 6 until the termination criteria are met.
4.3. Nested Optimization
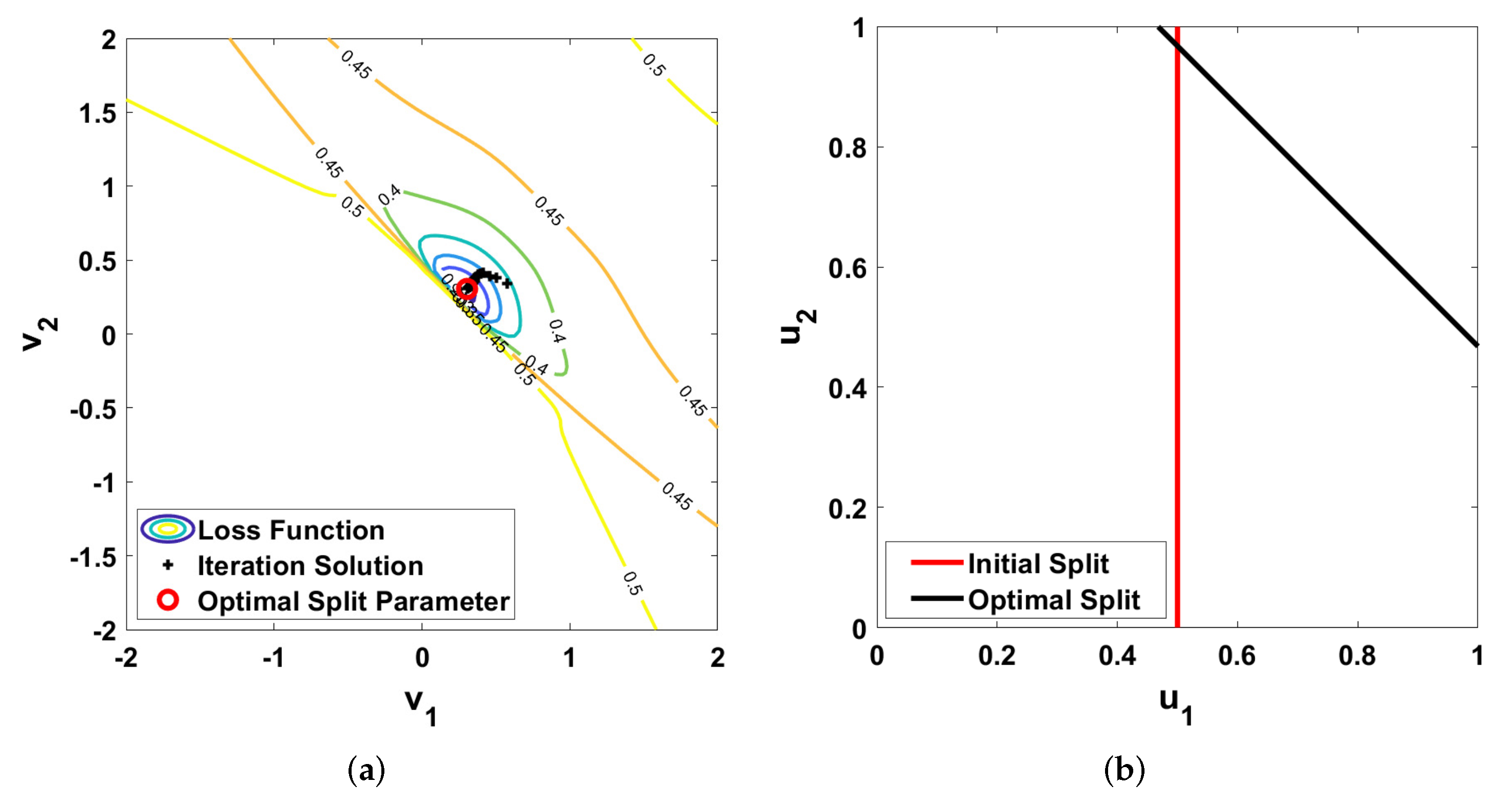
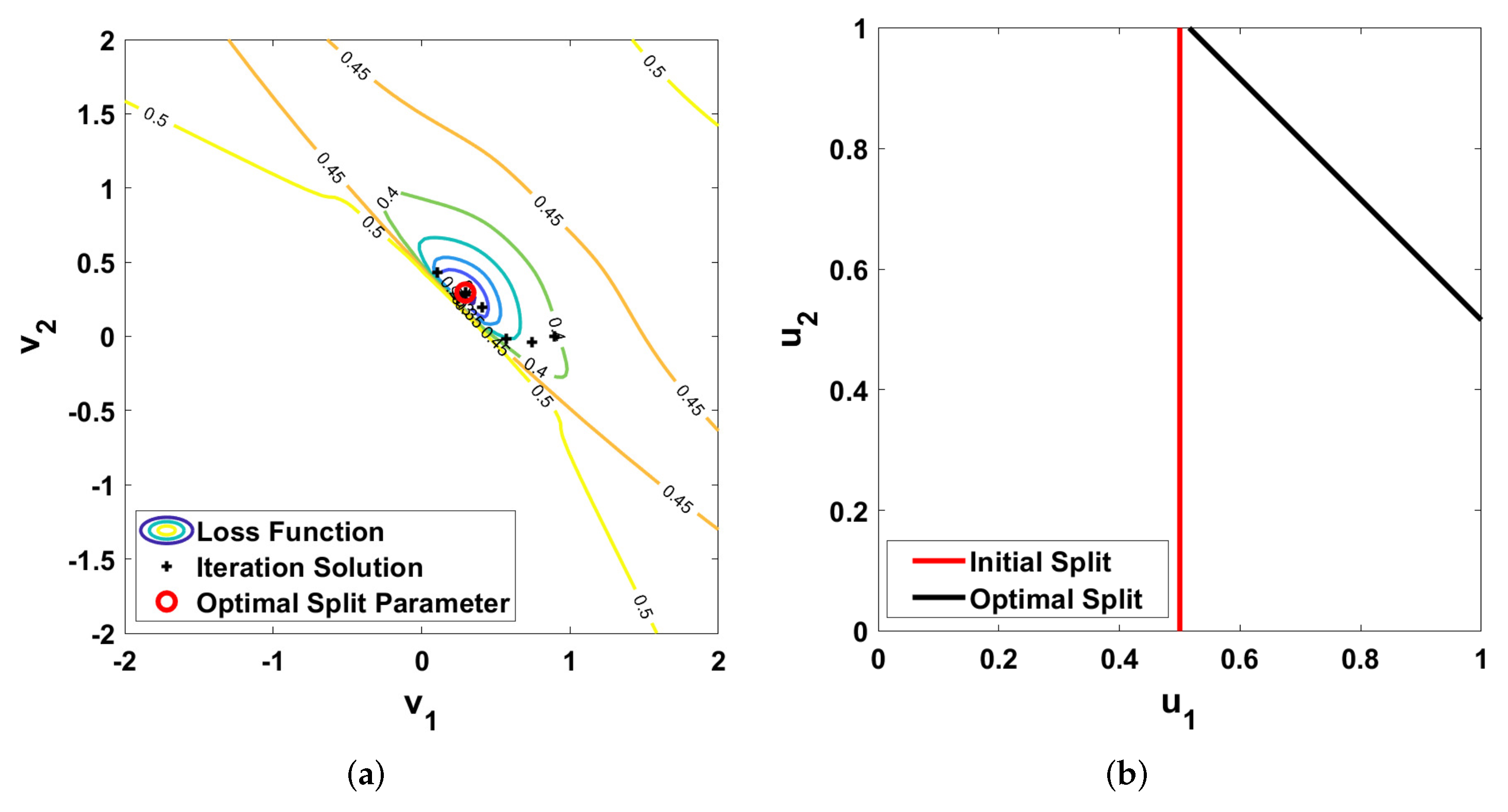
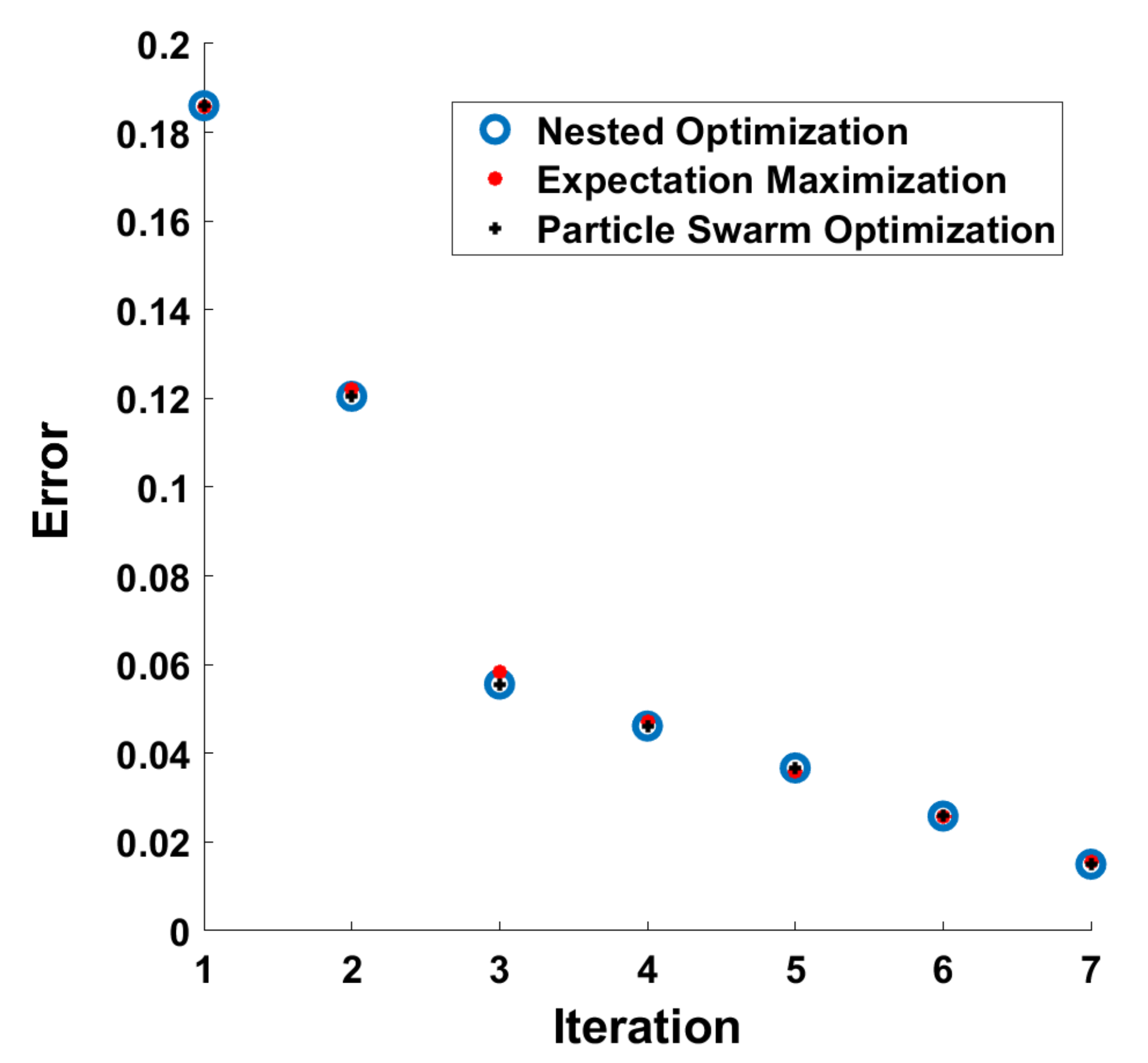
5. Results and Validation
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
Abbreviations
| LMN | Local Model Network |
| MMF | Multi-Model Framework |
| LRBFN | Local Radial Basis Function Network |
| PWC | Piece-Wise Continuous |
| NARX | Nonlinear Autoregressive Network with Exogenous Inputs |
| HILOMOT | Hierarchical Local Model Tree |
| LOLIMOT | Local Linear Model Tree |
| LLM | Local Linear Model |
| GK | Gustafson–Kessel |
| GG | Gath–Geva |
| EM | Expectation–Maximization |
| PSO | Particle Swarm Optimization |
| NRMSE | Normalized Root Mean Squared Error |
| NeO | Nested Optimization |
| PEMS | Predictive Emission Monitoring System |
References
- Novak, A.; Simon, L.; Kadlec, F.; Lotton, P. Nonlinear system identification using exponential swept-sine signal. IEEE Trans. Instrum. Meas. 2009, 59, 2220–2229. [Google Scholar] [CrossRef] [Green Version]
- Westwick, D.T.; Perreault, E.J. Closed-loop identification: Application to the estimation of limb impedance in a compliant environment. IEEE Trans. Biomed. Eng. 2010, 58, 521–530. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zhao, Y.; Westwick, D.T.; Kearney, R.E. Subspace methods for identification of human ankle joint stiffness. IEEE Trans. Biomed. Eng. 2010, 58, 3039–3048. [Google Scholar] [CrossRef] [PubMed]
- Lai, C.Y.; Xiang, C.; Lee, T.H. Data-based identification and control of nonlinear systems via piecewise affine approximation. IEEE Trans. Neural Netw. 2011, 22, 2189–2200. [Google Scholar]
- Talmon, R.; Kushnir, D.; Coifman, R.R.; Cohen, I.; Gannot, S. Parametrization of linear systems using diffusion kernels. IEEE Trans. Signal Process. 2011, 60, 1159–1173. [Google Scholar] [CrossRef] [Green Version]
- Bloch, G.; Lauer, F. Reduced-size kernel models for nonlinear hybrid system identification. IEEE Trans. Neural Netw. 2011, 22, 2398–2405. [Google Scholar]
- Chen, H.F. New approach to recursive identification for ARMAX systems. IEEE Trans. Autom. Control 2010, 55, 868–879. [Google Scholar] [CrossRef]
- Chen, X.M.; Chen, H.F. Recursive identification for MIMO Hammerstein systems. IEEE Trans. Autom. Control 2010, 56, 895–902. [Google Scholar] [CrossRef]
- Er-Wei, B. Non-Parametric Nonlinear System Identification: An Asymptotic Minimum Mean Squared Error Estimator. IEEE Trans. Autom. Control 2010, 55, 1615–1626. [Google Scholar] [CrossRef]
- Han, M.; Fan, J.; Wang, J. A dynamic feedforward neural network based on Gaussian particle swarm optimization and its application for predictive control. IEEE Trans. Neural Netw. 2011, 22, 1457–1468. [Google Scholar] [CrossRef]
- Kolodziej, J.R.; Mook, D.J. Model determination for nonlinear state-based system identification. Nonlinear Dyn. 2011, 63, 735–753. [Google Scholar] [CrossRef]
- Jakubek, S.; Keuth, N. A local neuro-fuzzy network for high-dimensional models and optimization. Eng. Appl. Artif. Intell. 2006, 19, 705–717. [Google Scholar] [CrossRef]
- Pottmann, M.; Pearson, R.K. Block-oriented NARMAX models with output multiplicities. AIChE J. 1998, 44, 131–140. [Google Scholar] [CrossRef]
- Pearson, R.K.; Pottmann, M. Gray-box identification of block-oriented nonlinear models. J. Process Control 2000, 10, 301–315. [Google Scholar] [CrossRef]
- Greblicki, W. Nonparametric identification of Wiener systems by orthogonal series. IEEE Trans. Autom. Control 1994, 39, 2077–2086. [Google Scholar] [CrossRef]
- Eskinat, E.; Johnson, S.H.; Luyben, W.L. Use of Hammerstein models in identification of nonlinear systems. AIChE J. 1991, 37, 255–268. [Google Scholar] [CrossRef]
- Hou, J.; Chen, F.; Li, P.; Zhu, Z. Gray-Box Parsimonious Subspace Identification of Hammerstein-Type Systems. IEEE Trans. Ind. Electron. 2021, 68, 9941–9951. [Google Scholar] [CrossRef]
- Abba, S.; Abdulkadir, R.; Gaya, M.; Sammen, S.S.; Ghali, U.; Nawaila, M.; Oğuz, G.; Malik, A.; Al-Ansari, N. Effluents quality prediction by using nonlinear dynamic block-oriented models: A system identification approach. Desalin. Water Treat. 2021, 218, 52–62. [Google Scholar] [CrossRef]
- Kashiwagi, H.; Rong, L. Identification of Volterra Kernels of Nonlinear Van do Vusse Reactor. Trans. Control Autom. Syst. Eng. 2002, 4, 109–113. [Google Scholar]
- Chen, S.; Billings, S.A.; Luo, W. Orthogonal least squares methods and their application to non-linear system identification. Int. J. Control 1989, 50, 1873–1896. [Google Scholar] [CrossRef]
- Piroddi, L.; Spinelli, W. An identification algorithm for polynomial NARX models based on simulation error minimization. Int. J. Control 2003, 76, 1767–1781. [Google Scholar] [CrossRef]
- Di Nunno, F.; de Marinis, G.; Gargano, R.; Granata, F. Tide prediction in the Venice Lagoon using nonlinear autoregressive exogenous (NARX) neural network. Water 2021, 13, 1173. [Google Scholar] [CrossRef]
- Di Nunno, F.; Granata, F.; Gargano, R.; de Marinis, G. Prediction of spring flows using nonlinear autoregressive exogenous (NARX) neural network models. Environ. Monit. Assess. 2021, 193, 1–17. [Google Scholar] [CrossRef] [PubMed]
- Billings, S.A.; Wei, H.L. A new class of wavelet networks for nonlinear system identification. IEEE Trans. Neural Netw. 2005, 16, 862–874. [Google Scholar] [CrossRef] [Green Version]
- Nash, D.A.; Ragsdale, D.J. Simulation of self-similarity in network utilization patterns as a precursor to automated testing of intrusion detection systems. IEEE Trans. Syst. Man Cybern. Part A Syst. Hum. 2001, 31, 327–331. [Google Scholar] [CrossRef]
- Zhao, H.; Zhang, J. Nonlinear dynamic system identification using pipelined functional link artificial recurrent neural network. Neurocomputing 2009, 72, 3046–3054. [Google Scholar] [CrossRef]
- Majhi, B.; Panda, G. Robust identification of nonlinear complex systems using low complexity ANN and particle swarm optimization technique. Expert Syst. Appl. 2011, 38, 321–333. [Google Scholar] [CrossRef]
- De Veaux, R.D.; Psichogios, D.; Ungar, L. A comparison of two nonparametric estimation schemes: MARS and neural networks. Comput. Chem. Eng. 1993, 17, 819–837. [Google Scholar] [CrossRef]
- Sahu, B.N.; Bisoi, R.; Samal, D. Identification of nonlinear dynamic system using machine learning techniques. Int. J. Power Energy Convers. 2021, 12, 23. [Google Scholar] [CrossRef]
- Kumar, R.; Srivastava, S. A novel dynamic recurrent functional link neural network-based identification of nonlinear systems using Lyapunov stability analysis. Neural Comput. Appl. 2021, 33, 7875–7892. [Google Scholar] [CrossRef]
- Gretton, A.; Doucet, A.; Herbrich, R.; Rayner, P.J.; Scholkopf, B. Support vector regression for black-box system identification. In Proceedings of the 11th IEEE Signal Processing Workshop on Statistical Signal Processing (Cat. No. 01TH8563), Singapore, 8 August 2001; pp. 341–344. [Google Scholar]
- Dewapura, P.W.; Jayawardhana, K.; Harsha, A.M.; Abeykoon, S. Object Identification using Support Vector Regression for Haptic Object Reconstruction. In Proceedings of the 2021 3rd International Conference on Electrical Engineering (EECon), Colombo, Sri Lanka, 24 September 2021; pp. 144–150. [Google Scholar]
- Salat, R.; Awtoniuk, M.; Korpysz, K. Black-box identification of a pilot-scale dryer model: A Support Vector Regression and an Imperialist Competitive Algorithm approach. IFAC-PapersOnLine 2017, 50, 1559–1564. [Google Scholar] [CrossRef]
- Ažman, K.; Kocijan, J. Dynamical systems identification using Gaussian process models with incorporated local models. Eng. Appl. Artif. Intell. 2011, 24, 398–408. [Google Scholar] [CrossRef]
- Yassin, I.M.; Taib, M.N.; Adnan, R. Recent advancements & methodologies in system identification: A review. Sci. Res. J. 2013, 1, 14–33. [Google Scholar]
- Lee, Y.S.; Tsakirtzis, S.; Vakakis, A.F.; Bergman, L.A.; McFarland, D.M. A time-domain nonlinear system identification method based on multiscale dynamic partitions. Meccanica 2011, 46, 625–649. [Google Scholar] [CrossRef]
- Babuška, R.; Verbruggen, H. Neuro-fuzzy methods for nonlinear system identification. Annu. Rev. Control 2003, 27, 73–85. [Google Scholar] [CrossRef]
- Johansen, T.A.; Foss, B.A. Identification of non-linear system structure and parameters using regime decomposition. Automatica 1995, 31, 321–326. [Google Scholar] [CrossRef]
- Johansen, T.A.; Foss, B.A. A NARMAX model representation for adaptive control based on local models. MIC J. 1992, 13, 25–39. [Google Scholar] [CrossRef]
- Kumar, M.; Kumar, B.; Rani, A. Neuro-fuzzy based estimation of rotor flux for Electric Vehicle operating under partial loading. J. Intell. Fuzzy Syst. 2021, 41, 5653–5663. [Google Scholar] [CrossRef]
- Wu, X.; Han, H.; Liu, Z.; Qiao, J. Data-Knowledge-Based Fuzzy Neural Network for Nonlinear System Identification. IEEE Trans. Fuzzy Syst. 2020, 28, 2209–2221. [Google Scholar] [CrossRef]
- Johansen, T.A.; Foss, B.A. State-space modeling using operating regime decomposition and local models. IFAC Proc. Vol. 1993, 26, 39–42. [Google Scholar] [CrossRef]
- Xu, J.; Huang, X.; Wang, S. Nonlinear model predictive control using adaptive hinging hyperplanes model. In Proceedings of the 48h IEEE Conference on Decision and Control (CDC) Held Jointly with 2009 28th Chinese Control Conference, Shanghai, China, 15–18 December 2009; pp. 2598–2603. [Google Scholar]
- Nelles, O.; Sinsel, S.; Isermann, R. Local basis function networks for identification of a turbocharger. In Proceedings of the UKACC International Conference on Control, Control ’96, Exeter, UK, 2–5 September 1996. [Google Scholar]
- Takagi, T.; Sugeno, M. Fuzzy identification of systems and its applications to modeling and control. IEEE Trans. Syst. Man Cybern. 1985, 1, 116–132. [Google Scholar] [CrossRef]
- Nelles, O.; Fink, A.; Isermann, R. Local linear model trees (LOLIMOT) toolbox for nonlinear system identification. IFAC Proc. Vol. 2000, 33, 845–850. [Google Scholar] [CrossRef]
- Billings, S.A. Models for Linear and Nonlinear Systems. In Nonlinear System Identification; John Wiley & Sons: Hoboken, NJ, USA, 2013; Chapter 2; pp. 17–59. [Google Scholar] [CrossRef]
- Li, J.; Bo, C.; Zhang, J.; Du, J. Fault diagnosis and accommodation based on online multi-model for nonlinear process. In International Conference on Intelligent Computing; Springer: Berlin/Heidelberg, Germany, 2006; pp. 661–666. [Google Scholar]
- Selmic, R.R.; Lewis, F.L. Multimodel neural networks identification and failure detection of nonlinear systems. In Proceedings of the 40th IEEE Conference on Decision and Control (Cat. No. 01CH37228), Orlando, FL, USA, 4–7 December 2001; Volume 4, pp. 3128–3133. [Google Scholar]
- Toivonen, H.T.; Sandström, K.V.; Nyström, R.H. Internal model control of nonlinear systems described by velocity-based linearizations. J. Process Control 2003, 13, 215–224. [Google Scholar] [CrossRef]
- Cai, G.B.; Duan, G.R.; Hu, C.H. A velocity-based LPV modeling and control framework for an airbreathing hypersonic vehicle. Int. J. Innov. Comput. Inf. Control 2011, 7, 2269–2281. [Google Scholar]
- Hartmann, B.; Nelles, O.; Belič, A.; Zupančič-Božič, D. Local model networks for the optimization of a tablet production process. In International Conference on Artificial Intelligence and Computational Intelligence; Springer: Berlin/Heidelberg, Germany, 2009; pp. 241–250. [Google Scholar]
- Zhou, C.; Huang, S.; Xiong, N.; Yang, S.H.; Li, H.; Qin, Y.; Li, X. Design and analysis of multimodel-based anomaly intrusion detection systems in industrial process automation. IEEE Trans. Syst. Man Cybern. Syst. 2015, 45, 1345–1360. [Google Scholar] [CrossRef]
- Vasu, J.Z.; Deb, A.K.; Mukhopadhyay, S. MVEM-based fault diagnosis of automotive engines using Dempster—Shafer theory and multiple hypotheses testing. IEEE Trans. Syst. Man Cybern. Syst. 2015, 45, 977–989. [Google Scholar] [CrossRef]
- Tirado, J.M.; Higuero, D.; Isaila, F.; Carretero, J. Multi-model prediction for enhancing content locality in elastic server infrastructures. In Proceedings of the 2011 18th International Conference on High Performance Computing, Bengaluru, India, 18–21 December 2011; pp. 1–9. [Google Scholar]
- Yager, R.R.; Grichnik, A.J.; Yager, R.L. A soft computing approach to controlling emissions under imperfect sensors. IEEE Trans. Syst. Man Cybern. Syst. 2013, 44, 687–691. [Google Scholar] [CrossRef]
- Adeniran, A.A.; El Ferik, S. Modeling and identification of nonlinear systems: A review of the multimodel approach—Part 1. IEEE Trans. Syst. Man Cybern. Syst. 2016, 47, 1149–1159. [Google Scholar] [CrossRef]
- Ltaief, M.; Abderrahim, K.; Abdennour, R.B.; Ksouri, M. Contributions to the multimodel approach: Systematic determination of a models’ base and validities estimation. Int. J. Autom. Syst. Eng. 2008, 2, 213–220. [Google Scholar]
- Nelles, O. Axes-oblique partitioning strategies for local model networks. In Proceedings of the 2006 IEEE Conference on Computer Aided Control System Design, 2006 IEEE International Conference on Control Applications, 2006 IEEE International Symposium on Intelligent Control, Munich, Germany, 4–6 October 2006; pp. 2378–2383. [Google Scholar]
- Ernst, S. Hinging hyperplane trees for approximation and identification. In Proceedings of the 37th IEEE Conference on Decision and Control (Cat. No. 98CH36171), Tampa, FL, USA, 18 December 1998; Volume 2, pp. 1266–1271. [Google Scholar]
- Tao, Q.; Xu, J.; Li, Z.; Xie, N.; Wang, S.; Li, X.; Suykens, J.A.K. Toward Deep Adaptive Hinging Hyperplanes. IEEE Trans. Neural Netw. Learn. Syst. 2021. [Google Scholar] [CrossRef]
- Breiman, L. Hinging hyperplanes for regression, classification, and function approximation. IEEE Trans. Inf. Theory 1993, 39, 999–1013. [Google Scholar] [CrossRef] [Green Version]
- Pucar, P.; Millnert, M. Smooth Hinging Hyperplanes—An Alternative to Neural Nets; Linköping University: Linköping, Sweden, 1995. [Google Scholar]
- Pucar, P.; Sjoberg, J. On the hinge-finding algorithm for hingeing hyperplanes. IEEE Trans. Inf. Theory 1998, 44, 1310–1319. [Google Scholar] [CrossRef] [Green Version]
- Fischer, T.; Hartmann, B.; Nelles, O. Increasing the performance of a training algorithm for local model networks. In Proceedings of the World Congress of Engineering and Computer Science (WCECS), San Francisco, CA, USA, 25–27 October 2012. [Google Scholar]
- Kuroda, M. Fast Computation of the EM Algorithm for Mixture Models. In Computational Statistics and Applications; IntechOpen: London, UK, 2021. [Google Scholar]
- Panić, B.; Klemenc, J.; Nagode, M. Improved Initialization of the EM Algorithm for Mixture Model Parameter Estimation. Mathematics 2020, 8, 373. [Google Scholar] [CrossRef] [Green Version]
- Gath, I.; Geva, A.B. Unsupervised optimal fuzzy clustering. IEEE Trans. Pattern Anal. Mach. Intell. 1989, 11, 773–780. [Google Scholar] [CrossRef]
- Hametner, C.; Jakubek, S. Neuro-fuzzy modelling using a logistic discriminant tree. In Proceedings of the 2007 American Control Conference, New York, NY, USA, 9–13 July 2007; pp. 864–869. [Google Scholar]
- Hametner, C.; Jakubek, S. Comparison of EM algorithm and particle swarm optimisation for local model network training. In Proceedings of the 2010 IEEE Conference on Cybernetics and Intelligent Systems, Singapore, 28–30 June 2010; pp. 267–272. [Google Scholar]
- Moody, J.; Darken, C.J. Fast learning in networks of locally-tuned processing units. Neural Comput. 1989, 1, 281–294. [Google Scholar] [CrossRef]
- Stokbro, K.; Umberger, D.; Hertz, J.A. Exploiting neurons with localized receptive fields to learn chaos. Complex Syst. 1990, 4, 603–622. [Google Scholar]
- Gustafson, D.E.; Kessel, W.C. Fuzzy clustering with a fuzzy covariance matrix. In Proceedings of the 1978 IEEE Conference on Decision and Control including the 17th Symposium on Adaptive Processes, San Diego, CA, USA, 10–12 January 1979; pp. 761–766. [Google Scholar]
- Wang, L.X.; Mendel, J.M. Fuzzy basis functions, universal approximation, and orthogonal least-squares learning. IEEE Trans. Neural Netw. 1992, 3, 807–814. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Hohensohn, J.; Mendel, J.M. Two-pass orthogonal least-squares algorithm to train and reduce fuzzy logic systems. In Proceedings of the 1994 IEEE 3rd International Fuzzy Systems Conference, Orlando, FL, USA, 26–29 June 1994; pp. 696–700. [Google Scholar]
- Mastorocostas, P.; Theocharis, J.; Kiartzis, S.; Bakirtzis, A. A hybrid fuzzy modeling method for short-term load forecasting. Math. Comput. Simul. 2000, 51, 221–232. [Google Scholar] [CrossRef]
- Murry-Smith, R. A Local Model Network Approach to Nonlinear Modeling. Ph.D. Thesis, University of Strathclyde, Strathclyde, UK, 1994. [Google Scholar]
- Breiman, L.; Friedman, J.H.; Olshen, R.A.; Stone, C.J. Classification and Regression Trees; Routledge: New York, NY, USA, 2017. [Google Scholar]
- Sugeno, M.; Kang, G. Structure identification of fuzzy model. Fuzzy Sets Syst. 1988, 28, 15–33. [Google Scholar] [CrossRef]
- Nelles, O. Nonlinear System Identification; IOP Publishing: Bristol, UK, 2002. [Google Scholar]
- Glass, L.; Hilali, W.; Nelles, O. Compressing Interpretable Representations of Piecewise Linear Neural Networks using Neuro-Fuzzy Models. In Proceedings of the 2021 IEEE Symposium Series on Computational Intelligence (SSCI), Orlando, FL, USA, 5–7 December 2021; pp. 1–8. [Google Scholar]
- Zavřel, J.; Jílek, M.; Šika, Z.; Beneš, P. Dexterity Optimization for Tensegrity Structures Using Local Linear Model Trees. In Proceedings of the 2021 9th International Conference on Control, Mechatronics and Automation (ICCMA), Luxembourg, 11–14 November 2021; pp. 46–49. [Google Scholar]
- Ramezani-Khansari, E.; Tabibi, M.; Moghadas Nejad, F. Estimating Lane Change Duration for Overtaking in Nonlane-Based Driving Behavior by Local Linear Model Trees (LOLIMOT). Math. Probl. Eng. 2021, 2021, 4388776. [Google Scholar] [CrossRef]
- Tabatabaei, M.; Kimiaefar, R.; Hajian, A.; Akbari, A. Robust outlier detection in geo-spatial data based on LOLIMOT and KNN search. Earth Sci. Inform. 2021, 14, 1065–1072. [Google Scholar] [CrossRef]
- Schüssler, M.; Münker, T.; Nelles, O. Local model networks for the identification of nonlinear state space models. In Proceedings of the 2019 IEEE 58th Conference on Decision and Control (CDC), Nice, France, 11–13 December 2019; pp. 6437–6442. [Google Scholar]
- Hartmann, B.; Nelles, O. Advantages of hierarchical versus flat model structures for high-dimensional mappings. In Proceedings of the 19th Workshop on Computational Intelligence Publication Series of the Institute for Applied Computer Science / Automation Technology, Dortmund, Germany, 2–4 December 2009; Volume 19, pp. 87–100. [Google Scholar]
- Hartmann, B.; Ebert, T.; Fischer, T.; Belz, J.; Kampmann, G.; Nelles, O. LMNTOOL—Toolbox zum automatischen Trainieren lokaler Modellnetze. In Proceedings of the 22th Workshop Computational Intelligence, Dortmund, Germany, 27–28 November 2014; pp. 341–355. [Google Scholar]
- Hartmann, B.; Nelles, O.; Skrjanc, I.; Sodja, A. Supervised hierarchical clustering (SUHICLUST) for nonlinear system identification. In Proceedings of the 2009 IEEE Symposium on Computational Intelligence in Control and Automation, Nashville, TN, USA, 30 March–2 April 2009; pp. 41–48. [Google Scholar]
- Bänfer, O.; Hartmann, B.; Nelles, O. Comparison of different subset selection algorithms for learning local model networks with higher degree polynomials. In Proceedings of the 2010 11th International Conference on Control Automation Robotics & Vision, Singapore, 7–10 December 2010; pp. 30–35. [Google Scholar]
- Trelea, I.C. The particle swarm optimization algorithm: Convergence analysis and parameter selection. Inf. Process. Lett. 2003, 85, 317–325. [Google Scholar] [CrossRef]
- Skalska, K.; Miller, J.S.; Ledakowicz, S. Trends in NOx abatement: A review. Sci. Total Environ. 2010, 408, 3976–3989. [Google Scholar] [CrossRef] [PubMed]
- Kaya, H.; Tüfekci, P.; Uzun, E. Predicting co and no x emissions from gas turbines: Novel data and a benchmark pems. Turk. J. Electr. Eng. Comput. Sci. 2019, 27, 4783–4796. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Function | NRMSE | ||
|---|---|---|---|
| Symbol | PSO | EM | NeO |
| 0.017499 | 0.020576 | 0.018527 | |
| 0.057793 | 0.061598 | 0.083211 | |
| 0.011538 | 0.012598 | 0.013768 | |
| 0.119732 | 0.112734 | 0.113158 | |
| 0.054929 | 0.053244 | 0.055226 | |
| Function | Mean | Standard Deviation () |
|---|---|---|
| 0.017527 | 1.6636 | |
| 0.057820 | 1.6927 | |
| 0.011559 | 1.1638 | |
| 0.119749 | 1.2787 | |
| 0.054952 | 1.4889 |
| Normalized Root Mean Squared Error | ||
|---|---|---|
| PSO | EM | NeO |
| 0.475962 | 0.479747 | 0.484005 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mahfuz, A.; Mannan, M.A.; Muyeen, S.M. Enhancement of the HILOMOT Algorithm with Modified EM and Modified PSO Algorithms for Nonlinear Systems Identification. Electronics 2022, 11, 729. https://doi.org/10.3390/electronics11050729
Mahfuz A, Mannan MA, Muyeen SM. Enhancement of the HILOMOT Algorithm with Modified EM and Modified PSO Algorithms for Nonlinear Systems Identification. Electronics. 2022; 11(5):729. https://doi.org/10.3390/electronics11050729
Chicago/Turabian StyleMahfuz, Asif, Mohammad Abdul Mannan, and S. M. Muyeen. 2022. "Enhancement of the HILOMOT Algorithm with Modified EM and Modified PSO Algorithms for Nonlinear Systems Identification" Electronics 11, no. 5: 729. https://doi.org/10.3390/electronics11050729