1. Introduction
The most commonly used technique for validating the quality of software is testing, which is a labor intensive process. It occupies more than half the total costs during software development and maintenance [
1]. Among the various kinds of testing techniques, unit testing is popular for checking the aspects of the implementation for software component under test. However, it is a tedious task for programmers to write test cases manually. However, manual test cases are difficult to evaluate by coverage criteria, such as branch coverage, path coverage, etc.
Symbolic execution [
2] is a well-known technique to automate test-case generation. Instead of supplying concrete inputs to a program, symbolic execution supplies symbols that represent arbitrary values. Dynamic symbolic execution [
3,
4,
5] is proposed to intertwine concrete and symbolic execution together in a way that analyzes program behaviors dynamically for automatically generating new test inputs systematically. Though dynamic symbolic execution improves the efficiency of generating test cases to an extent, it is still difficult to be applied to complicated or large programs. The main reason is that dynamic symbolic execution intends to explore the whole space that may impose the state explosion problem. In fact, the testers do not need to generate all possible test cases for the program under test, because what we care about is those test cases, which may lead to program faults with high probability.
To overcome the weakness of existing techniques, we present a new test-case generation framework. This framework combines dataflow analysis with dynamic symbolic execution and heuristically searches for program path space based on the tabu search strategy and the program fault statistics. This approach relies on the program code itself and directs program paths to automatically follow the ones that most likely contain faults, instead of searching the whole feasible path space. These techniques enable us to find more possible errors in programs with fewer test cases generated, and it scales well w.r.t. program sizes (about 5000 lines per unit). As a result, this approach can be applied to real-world programs to find potential errors with reasonable costs.
The main contribution made by this approach is the path-selection model with which the exploration process will be likely to search sub state spaces where the probability of hidden errors is high based on the statistical results.
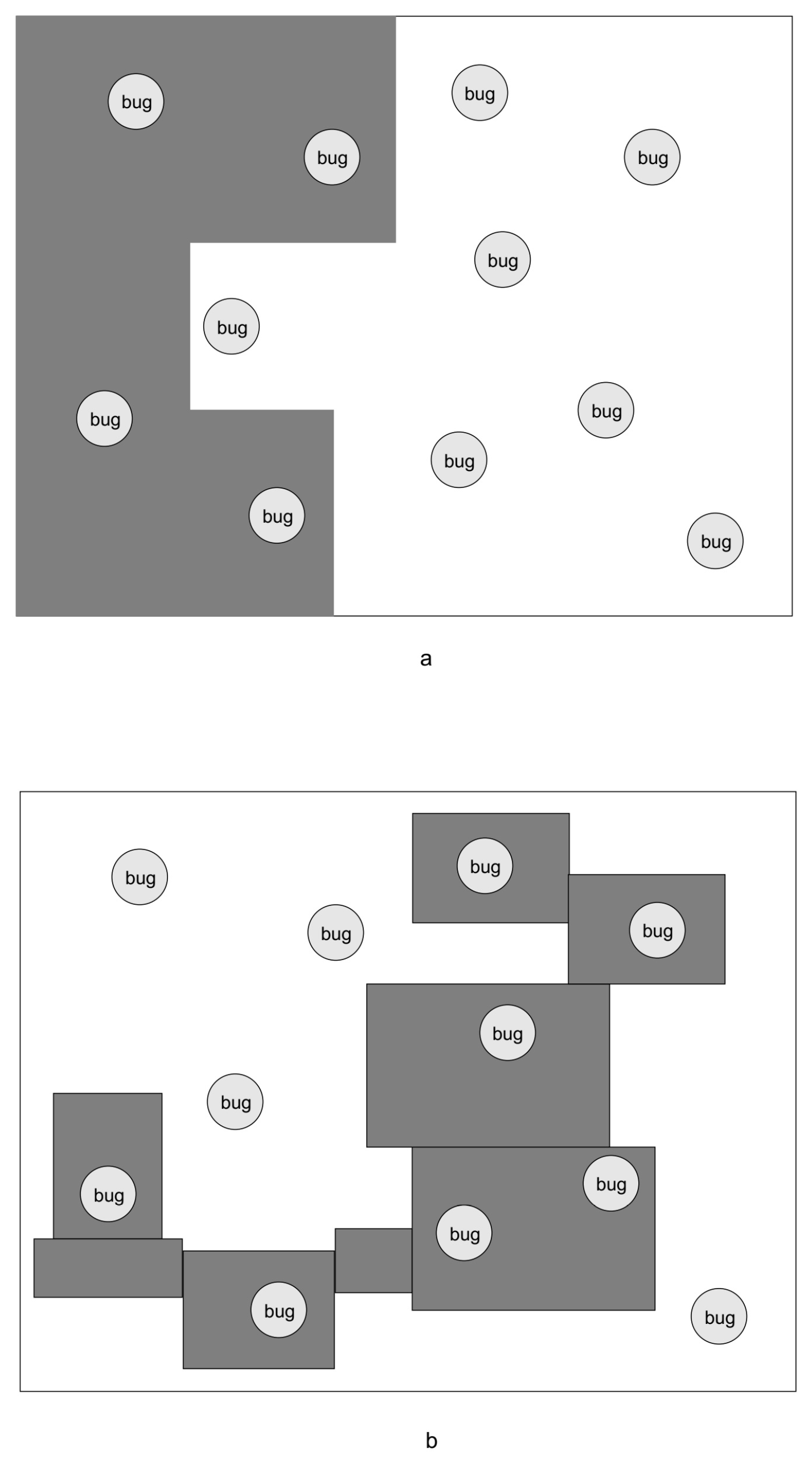
Figure 1 shows a diagrammatic comparison between a pure dynamic symbolic execution technique (CUTE [
3], DART [
4] ) and our approach. The boxes stand for the entire program state space, and the small circles distributed in boxes are possible bugs hidden in the state space.
Figure 1a shows the dynamic symbolic execution search, and this will exhaustively explore continuous parts of the state space. In this way, this technique may be stuck in parts of program space while other bugs cannot be uncovered in the left space where there may be more possible bugs. Based on the bug statistical report [
6], those possible bugs are not in a uniform distribution in the program space.
Figure 1b shows our approach, which will search those sub-spaces where the possibility of hidden bugs highly relies on statistic results.
Consequently, our approach does not search the program space in a uniform way, and it works as an intelligent searching technique to some extent to further improve the search quality. The other advantage of adopting the tabu heuristic [
7,
8,
9,
10] is to keep the search process from becoming stuck in sub-spaces, as a tabu list can help escape from the local search space.
This paper is organized as follows. We present a motivating example in
Section 2.
Section 3 describes the test-case generation framework.
Section 4 presents our algorithm for effective path selection and discusses how to apply the tabu search strategy in order to find potential defects more efficiently.
Section 5 discusses the related work.
Section 6 reports the experimental results that we obtained with the implementation of our approach. The last section concludes the study.
2. Motivating Example
We illustrate the benefits of our approach using a simple example. The code fragment is listed in the following, where there exists a pointer misuse in the branch, which may lead to a runtime error. The runtime error of accessing null pointers takes place when there is only one node in the linked list.
struct Node {
int v;
struct Node *next;
};
struct Table {
int a[1000];
struct Node *p;
int cnt;
};
void delete_from_table(struct Table *p_table) {
struct Node *p1;
int i;
if(p_table->p == NULL){
for(i = 1; i < p_table->cnt && i < 1000; i++)
p_table->a[i - 1] = p_table->a[i];
}
else{
p1 = p_table->p->next;
p_table->p->next = p1->next;
p_table->p->v = p1->v;
free(p1);
}
p_table->cnt--;
}
The first step of using our approach is to instrument the program under test. For instance, the function
under test will be transformed into the following, where the
structure is replaced by
statement with an
one. Note that there are three embedded
branches in the code after the transformation. Thus, the path analysis can rely on the branches of
in a uniform way. On the other hand, some instrumented code snippets are inserted into the original in order to collect program information based on the CIL tool [
11]. For simplicity, we omit those instrumented code snippets here.
void delete_from_table(struct Table *p_table) {
struct Node *p1;
int i;
if(p_table->p == NULL){
i = 1;
while(1)
{
if(i < 1000){
if(i < p_table->cnt)
;
else break;
}
else break;
p_table->a[i - 1] = p_table->a[i];
i++;
}
}
else{
p1 = p_table->p->next;
p_table->p->next = p1->next;
p_table->p->v = p1->v;
free(p1);
}
p_table->cnt--;
}
For choosing those paths that contain potential bugs with high probability, we are supposed to evaluate the paths in the search space. Thus, we designed a path selection model dealing with the evaluation and choice of those feasible paths. We also designed a path analysis engine, which helps in the analysis of the paths. To achieve this goal, the engine uses control flow graph (CFG) to facilitate the analysis process.
Figure 2 shows the corresponding control flow graph of function
.
However, it is impossible to evaluate each path in the search space; thus, we construct the control flow graph of the corresponding program by which the paths can be evaluated based on some criteria. For instance,
Figure 2 shows the CFG of the example, where each branch path has been evaluated with a weight that is computed by a simple error-statistical model that will be explained in detail in
Section 4. For instance, the path in the
part of the transformed program is of the highest value 4.03. With the beginning of the process of test-case generation, a memory is allocated dynamically and the corresponding address is assigned to the pointer
.
The initial values of
and
are
and
, respectively. Then, the path analysis engine first enters the
branch where (
) holds and goes into the
loop afterwards. If we denote the
branch as
and
as
, then we obtain an initial path whose first two elements are recorded as
, and the third element is 0.
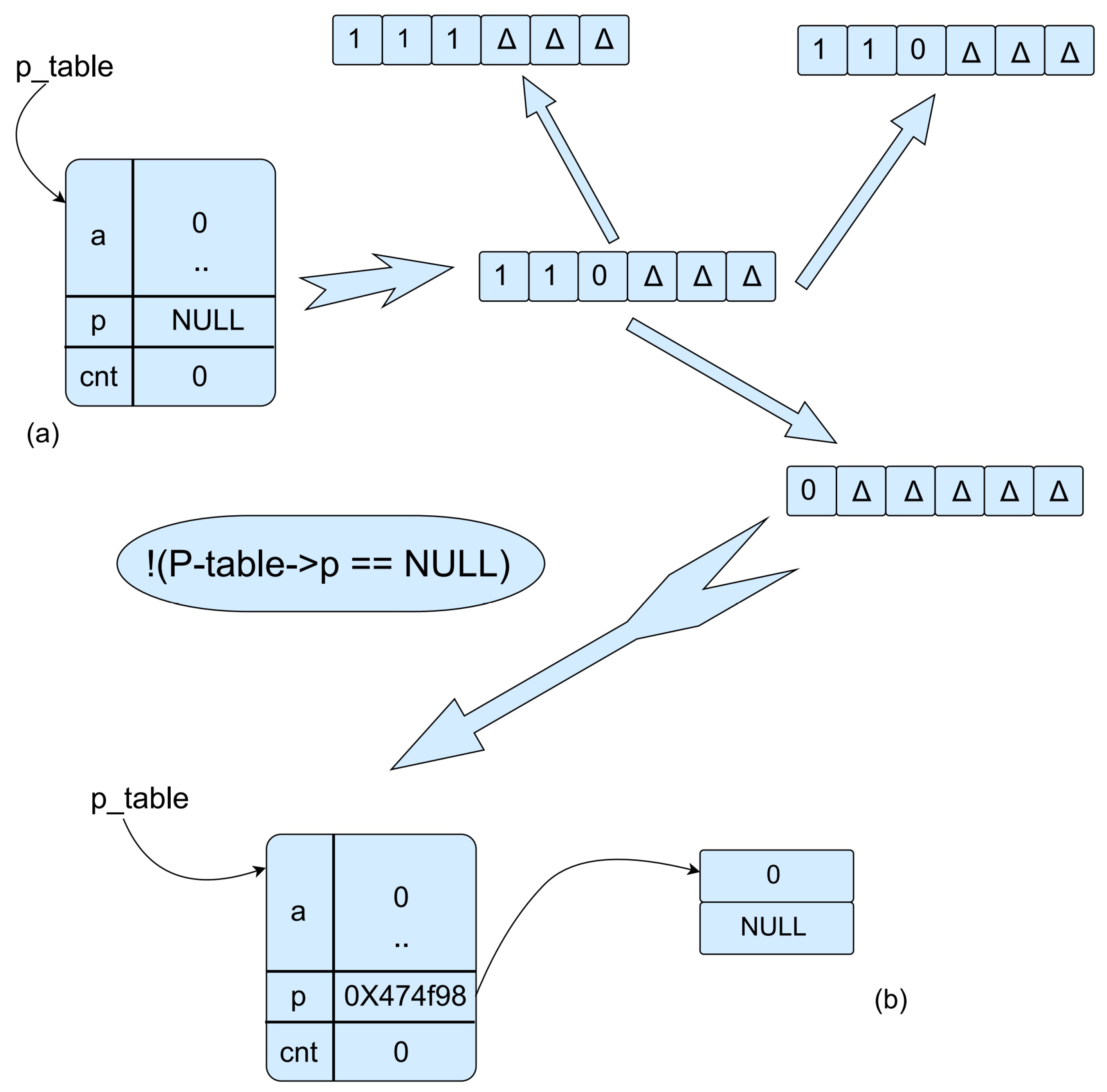
Figure 3a shows this scenario, where the array stands for a real program path, and the triangle in a array represents the uncovered parts in the path.
In this situation, we obtain three neighbors of the current execution path. Based on our path-selection model, the next path whose weight is the highest will be selected to be explored. As a result, the path that goes into the outmost
branch will be selected. In
Figure 2, the path in which the first element is
is chosen. As a result, the error in this path will be found in only the second execution under our path-selection model.
On the other hand, if we use the depth-first search instead of path-selection model we adopt, the path analysis engine will first enter the branch and stay there for thousands of iterations because of the loop structure in that branch. To generate the test case that leads to the path to be explored, the dynamic symbolic execution is used in the test-case generation framework. During the execution of the current path, the path analysis engine collects the branch constraints at the same time.
When the next path is chosen, new test input data are generated by solving the corresponding constraints. For instance, by solving the constraints
, the test case in
Figure 3b is generated, which directs the execution of the chosen path.
3. Test Case Generation Framework
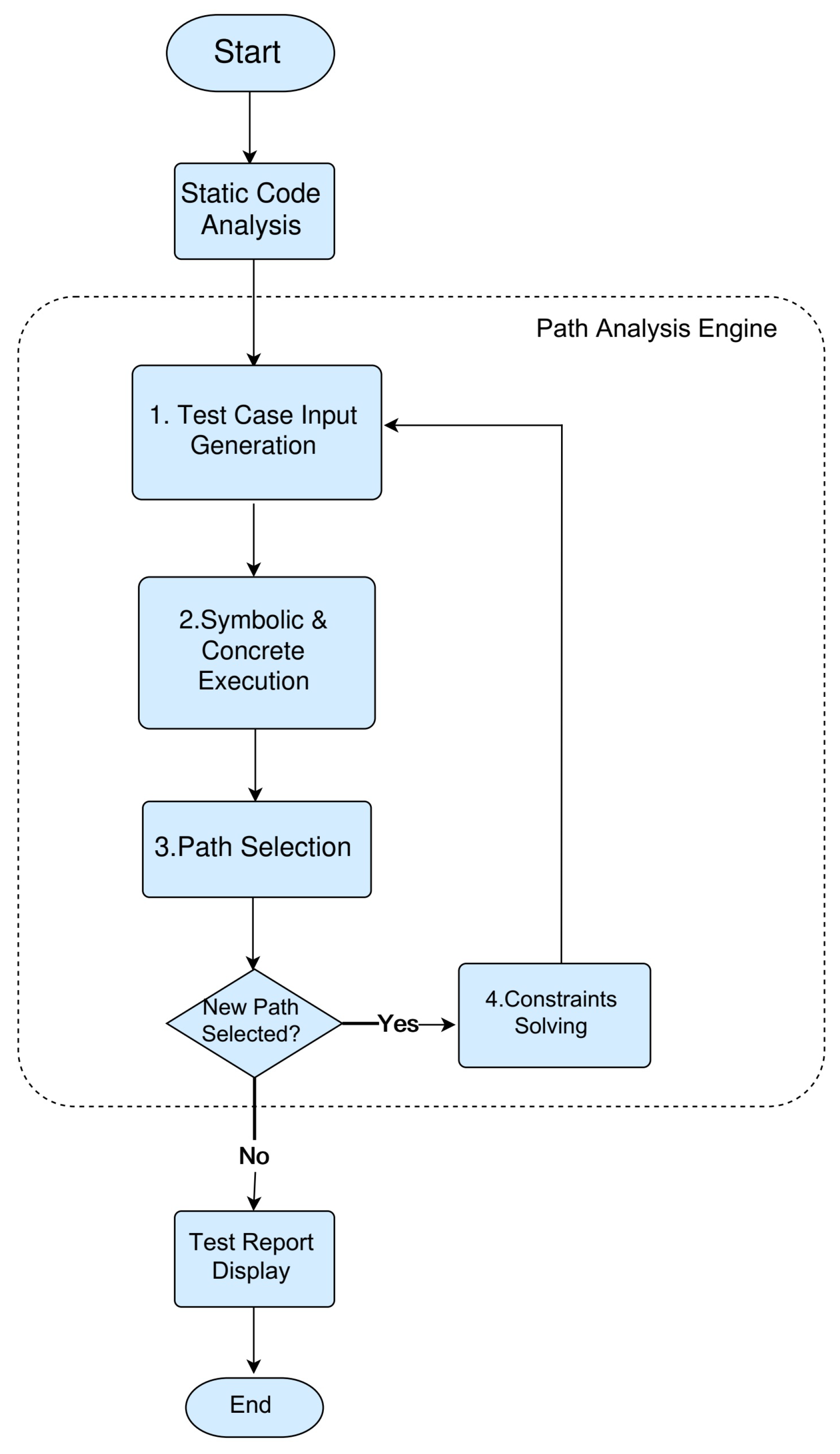
There are two main parts in the test-case generation framework shown in
Figure 4. The first handles the dataflow analysis, which provides information for the second part. In this part, we designed a dynamic def-use chain and a path execution tree as the engine infrastructures. The second part is the path analysis engine, which is the core part of this framework. The dynamic symbolic execution is integrated to generate test cases automatically. During the process of path exploration, tabu search is applied to select paths to be analyzed.
The process of static code analysis instruments the program unit under test and collects the path information for path selection using CIL [
11]. The path analysis engine first generates test case inputs from the results of the solving constraints recorded in the previous executions. In the initial iteration, the test case input is generated randomly. The second step of the engine takes the current test input generated to execute the instrumented codes using the dynamic symbolic execution technique, which runs the program both in concrete and symbolic value states. Third, during the exploration of the path space, the engine smartly selects the next path to be executed and analyzed based on the tabu search strategy. If a new path is selected successfully, the engine enters the process of constraint solving, which generates the new test input to direct the next path execution. Otherwise, a test report is generated for the testers.
3.1. Dynamic Symbolic Execution
Traditionally, symbolic execution supplies symbols as input data to the program under test to represent arbitrary values. Our approach takes both symbols and normal concrete value as the test input. The greatest advantage of this approach is that the program under test can be executed normally, and there is no need to implement a special simulator to execute it symbolically. This technique maintains two representation forms for variables dynamically: the symbolic form is denoted by sym_structure, and the concrete one denoted by con_structure. A dynamic def-use chain is implemented by the dataflow analysis technique, which is used to collect and record data information and path constraints during dynamic symbolic execution.
Dynamic symbolic execution is a classical test generation technique, where the program under test starts from some random inputs and is then executed through gathering symbolic constraints on inputs from predicates in branch program points; a constraint solver is then used to generate another input to guard different feasible path executions. On the other hand, static symbolic execution [
12] does not need to execute programs under test, and it uses a static analysis technique to collect constraints information. However, this approach does not perform well as complex programs always need to call APIs or functions provided by systems, but is not easy for static analysis to abstract and reason about complex functions effectively.
3.2. Path Execution Tree
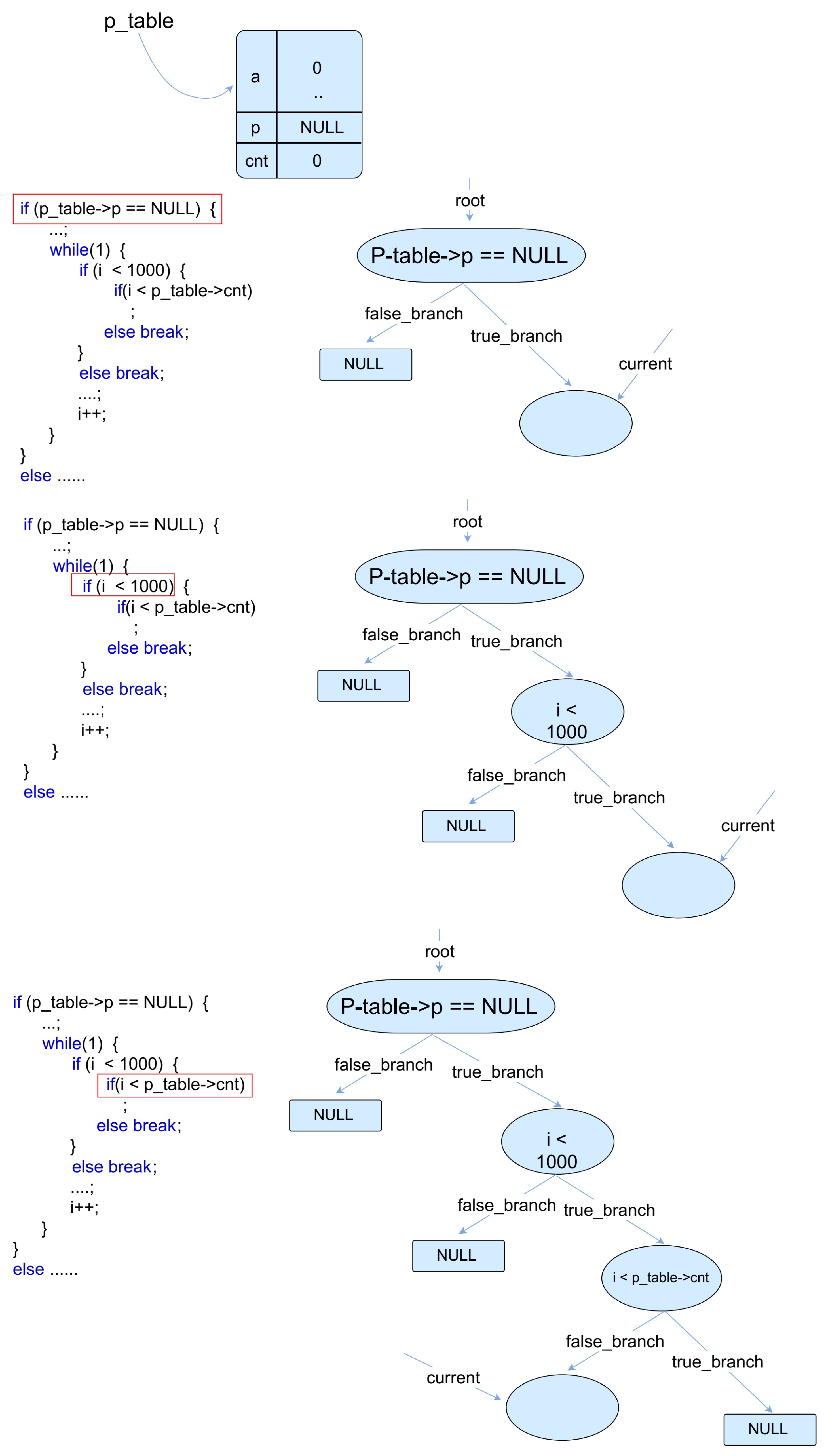
We designed the path execution tree to record explored paths; it is the basis of our path-selection model. This tree grows dynamically and it is a persistent data structure during the whole process of test-case generation. When a branch statement is encountered during the symbolic execution, the branch condition is collected, and a node is added to this tree if the corresponding child of the current node is . Then, the current node is set to be its false branch or true branch depending on the choice of the branch statement.
Each path from root of the tree to a leaf in the execution tree stands for a real execution path in the program under test. As we use CIL to instrument the tested program so that any branch statement in the transformed program is a simple two-choice statement, a sequence of “
” can be used to denote a path. A node in the execution tree has two children representing the
branch and
branch, respectively. The process of building an execution tree is shown in
Figure 5.
We take the program used in
Section 2 as an example. The top part of
Figure 5 shows the test input data. First, the branch statement “
” encounters, the branch condition of current node in execution tree is set to be “
”, and then the current node becomes to be the
branch of the previous current node. The next branch statement encountered is “
”.
The condition of this statement is used as the branch condition of the current node in the execution tree. In this case, the value of is , and thus the branch is taken, and the current node turns to the branch of the previous current node. Then, the engine executes the branch statement “”, and the branch condition of current node is set to be “”. The concrete value of is 1 and “” is 0. Therefore, the branch is taken.
When this symbolic execution terminates, the path covered in this iteration can be presented as a sequence “110”. Path constraints can be gained from the execution tree. For example, as
Section 2 shows, the next path selected to cover is “0”. Thus, the path constraint directing this path is “
”. If the path selected to cover is “111”, the path constraints will be “
”.
4. Path Selection Model
When the program unit under test is complicated, exploring every path in the program state space is an impossible job for industry applications. To alleviate the problem, we present our path selection model and integrate it into the path analysis engine previously mentioned. This algorithm uses tabu search and a simple statistical model for efficient and effective path selection.
4.1. Tabu Search
We use
to denote the search space of the problem under consideration, which could be either finite or infinite. For a point
in the space,
is called the neighborhood of
defined by the problem,
. A step of the tabu search algorithm is defined as moving from the current point
s to a neighboring point
,
. Function
is a function to evaluate the quality of the solutions. The general process of the tabu search algorithm is described in
Listing 1.
Listing 1. Basic scheme of the tabu search.
- 1
s = RandomlyGet();
- 2
while (!StopingCondition) {
- 3
who = null;
- 4
local = MIN_VALUE;
- 5
for each () {
- 6
if ( ∉ tabu list ⋀ eval() > local)
- 7
who = ;
- 8
local = eval();
- 9
else if (Aspiration())
- 10
who = ;
- 11
local = eval();
- 12
}
- 13
s = who;
- 14
}
The tabu search algorithm maintains a list (tabu list) recording the features of the last visited solutions, preventing the searching process from revisiting solutions with such features, where is called the tabu tenure length. The search process selects the best solution that is not recorded in the tabu list as its target of the next step. To make the searching process more robust, an aspiration criteria can be introduced to accept solutions rejected under certain conditions. One widely used form is that when is rejected but evaluation function is better than the best solution ever found before. At this time, is accepted as the next visiting point despite of its tabu state.
4.2. Search Space
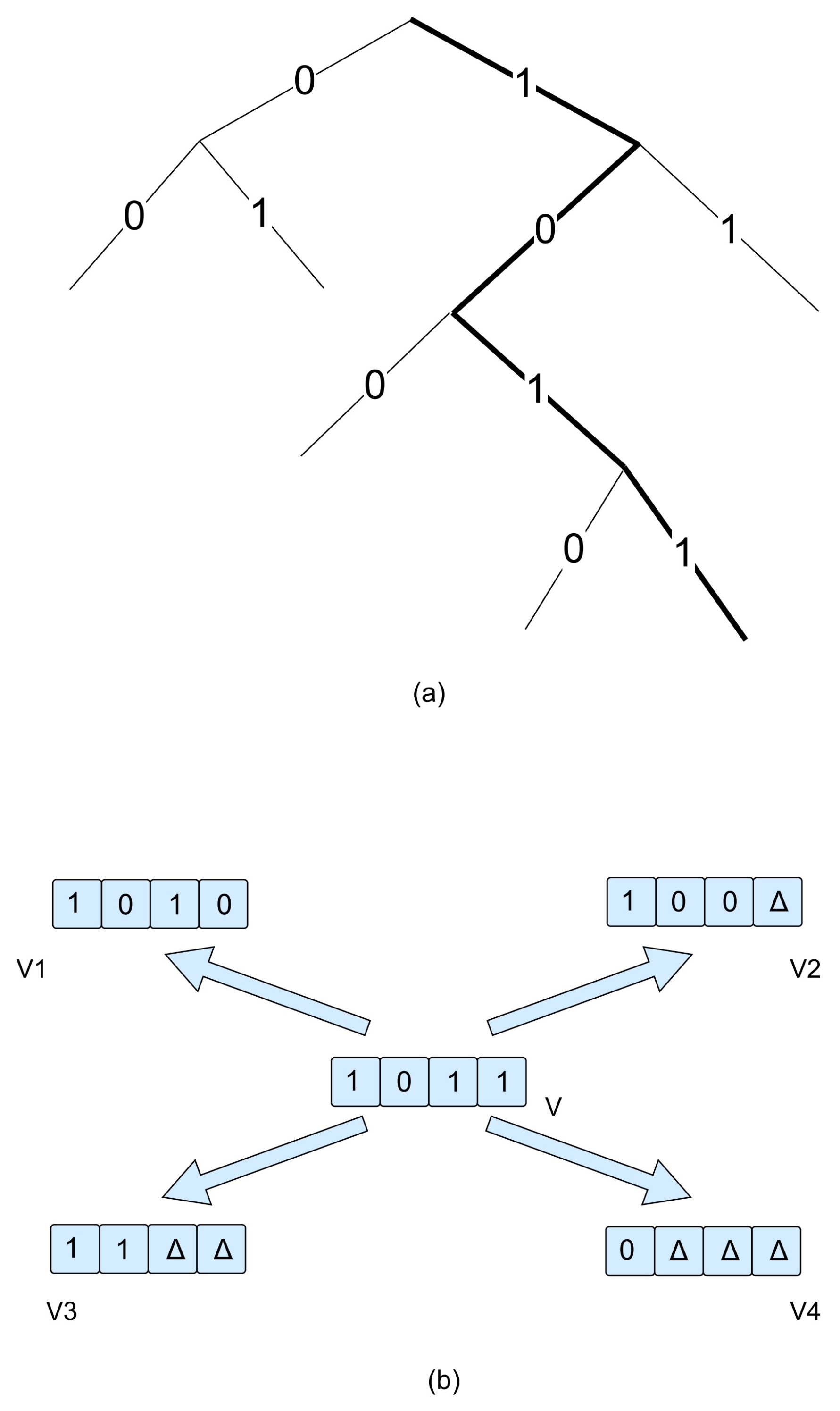
The search space in the path-selection model is based on the path execution tree that we designed earlier. The search space is composed of all the feasible paths in the path execution tree. For example,
Figure 6a denotes a path execution tree with a height of 4. If we use 0 to denote the
branch and 1 as
branch, then a sequence of digital 0 or 1 denotes a path. In
Figure 6a, the path with thick dark can be denoted the sequence 1011. Thus, all the possible combinations of digital 0 and 1 form the search space in our model. With the search space fixed, we define the neighborhood of element
v denoted as
. To illustrate the construction of the neighborhood, we use the same example in
Figure 6a.
The construction of the neighborhood of element
v begins with changing the last bit of
v. In
Figure 6b,
is one of the neighborhood of
v from which only the last location of
is different. The second neighbor of
v is
, which is different with
v on the last second location. Note that the last bit of
is set a triangle, which denotes that the last location is unknown. The reason is that the execution tree is generated dynamically, and thus the path analysis engine does not know what other exact paths should be executed except for the current path denoted as
v.
Thus, actually denotes a branch of unexplored paths. Similarly, and in the neighborhood of v are constructed like and . As a result, although the current path v has only four neighbors, and each neighbor represents a set of paths. How to choose a path to be performed from a neighbor will be discussed in the following parts.
In general, if n denotes the height of the execution tree without a circle, a point in the search space has exactly n elements as its neighborhood. If there are circles denoting iterations existed in the tree, we can expand the path circles as two-path branches recursively. The loop structure may lead to the infinite paths in the search space, and one advantage of adopting tabu search can avoid being stuck in the loop structure based on the path-selection model.
4.3. Path Evaluation Function
To decide which neighbor of the current path should be chosen, the path evaluation function should be designed carefully. The basic idea behind the path evaluation function
is that the errors hidden in programs are not universally distributed—they may obey some statistical rules. Thus, our evaluation function is based on bug taxonomy and statistics [
6] summarized for a large number of software projects using a statistical approach. Here, we enumerate the bug taxonomy considered in
Table 1.
This table shows that the bug statistics model from [
6], which covers from the requirement to testing phases. We only list the bugs related to the usage of statements and compute the corresponding weights based on the statistics column. For example, bugs related to pointers take up almost half of all the syntax-related bugs. This tells us that the intensive uses of pointers may introduce more bugs and the path analysis engine is intended to set a higher priority to explore those program codes.
To compute the usage of statements listed in
Table 1, we collect those information on the corresponding control flow graph. A CFG can be represented as
, where
N stands for the set of nodes and
E is a set of edges. Nodes in this graph are used to denote those branch statements, such as the if-else and loop statements; the directed edges connecting the nodes show the direction of programs running logic and keep records of a sequence of instructions that lie between the connected branch statements.
Figure 7 shows the CFG with the corresponding program, where a tuple attached on the edge denotes the usage information in the current branch. For instance, tuple {1, 1, 0, 0, 1, 0} on the
branch denotes that there is one pointer, one predicate and one boolean evaluation in this path. Thus, the tuple is the usage time of pointers, assignments etc.
Next, we define the path evaluation function
, which is a key to the path selection algorithm, which will be introduced in the next section. Note that function
has a parameter
v, which is actually a point in search space. As shown in
Figure 6, a point
v denotes a set of unexplored paths, and
will obtain the highest weight from this set of paths as the weight of
v.
Listing 2 shows the algorithm of evaluation function
.
Function calls the recursive procedure , which will always select the branch with the higher weight. Function computes the weight of the corresponding path, where the normalization mechanism is applied to reduce the interference of the abnormal data. When dealing with a loop structure, we select and evaluate two different paths. One is the path that does not enter the loop, and the other is the path that goes into the loop once. Thus, the weight of a point containing loop structure can be computed easily. The weights in the CFG are pre-computed in our model, and this technique can improve the efficiency of the search process very much.
Function is like the algorithm of transversal of a binary tree, and the complexity of is linear with the number of nodes in the tree. It does not need to enumerate all the possible paths in the search space. Thus, the computing of the weight of the points in the neighborhood of v is quick. Note that the path with highest weight may not be an executable one for the current unit under test. The reason for this is that we do not analyze the reachability property of the path, and it can be solved by path reachability analysis before using our test-case generation framework.
Listing 2. Evaluation function.
- 1
/*
- 2
tuple : statistical information
- 3
{po, pr, lo, ae, be, as}
- 4
tuplei : the i field of tuple
- 5
node : a node in CFG
- 6
node → tuple :
- 7
statistical information of node
- 8
node → false_branch :
- 9
false branch of node,
- 10
also a node of CFG
- 11
node → true_branch :
- 12
true branch of node,
- 13
also a node of CFG
- 14
eval : evaluation funciton
- 15
*/
- 16
- 17
procedure eval
- 18
input : node
- 19
output : value
- 20
value = eval_tuple(max_tuple(node))
- 21
- 22
procedure max_tuple
- 23
input : node
- 24
output : tuple
- 25
if (node == NULL)
- 26
return < 0, 0, 0, 0, 0, 0 >
- 27
else
- 28
tuple1 = max_tuple(node → false_branch);
- 29
tuple2 = max_tuple(node → true_branch);
- 30
if (eval_tuple(tuple1) > eval_tuple(tuple2))
- 31
return node → tuple ⊕ tuple1;
- 32
else return node → tuple ⊕ tuple2;
- 33
- 34
procedure eval_tuple
- 35
input : tuple
- 36
output : value
- 37
- 38
- 39
- 40
4.4. Path Selection Algorithm
Based on the previous discussions, we present the path selection algorithm, which is actually a variant of tabu search. The basic idea of this algorithm is to choose the best point not in the tabu list from the neighborhood of the current point. The tabu list can keep the search process from falling in the local search space. For instance, this algorithm can easily escape from the loop structure, while the depth-first search used in CUTE or DART will recursively perform in the loop. If the loop is infinite, then the search will not terminate. Here, the best point refers to the path with highest bug-hidden probability based on our computation model. The algorithm framework is presented in
Listing 3.
Listing 3. Path selection algorithm.
- 1
/*
- 2
cp : current path
- 3
nps : all neighbors of cp
- 4
bnp : best element in the neighborhood
- 5
gbp : globally best element
- 6
J : tabu length
- 7
*/
- 8
- 9
procedure : path selection
- 10
- 11
cp = Initial(); gbp = cp; base = ; TabuLen =
- 12
RandomGetFrom(0.9 ∗ base, 1.1 ∗ base);
- 13
- 14
while(1){
- 15
if (stopCondition())
- 16
break;
- 17
nps = getNeighborhoodPaths(cp);
- 18
nps = removeVisitedorTabuedElements(nps);
- 19
if (isEmpty(nps)){
- 20
J = 0.9 ∗ J;
- 21
continue;
- 22
}
- 23
select bnp from nps;
- 24
if (eval(bnp) > eval(gbp)){
- 25
J = 1.05 ∗ J;
- 26
gbp = bnp;
- 27
add other paths in nps into tabu list;
- 28
}
- 29
randomly select a real executable path from bnp
The current path is an executable one performed by the last test case. denotes all neighbors of , each of which is a set of paths containing both performed and unperformed paths. The paths in the element of have the same path prefix explored, which was discussed previously. We use and to denote the best element in the neighborhood and the globally best one respectively. Note that and both stand for a bunch of paths with the same path prefix.
The algorithm begins with initializing tabu length with a random value near to the square root of the length of the path. Then, are obtained from the current path , and those paths explored in are removed. If all the paths in search space are covered, then the algorithm terminates. The path is marked as a covered one if the symbolic execution finishes (i.e., an executed path), or a constraint solving fails (i.e., an unreachable path). In practice, we can set other stop conditions such that a predefined search height is arrived.
During the searching process, if all the possible moves become tabu ones and thus cannot find a element in , will be reduced by a factor, say , to help some points to escape from its tabu state faster. When the best path ever found is better than the global best path in one iteration, will be increased by another factor, say , to help the searching process to spread to further areas from the current local area. All the neighbors except in the current path will be added to tabu list, thus, ensuring that the searching process will travel in the local space in the next iterations, where determines how long the tabu state of a specific point persists.
The key aspect for selecting a path containing possible potential errors to be executed in tabu search is the evaluation function: , which estimates whether the current node in the search space can be chosen as the point for the next iteration. The design of has been discussed previously. Though the evaluation function is dynamically computed from the corresponding CFG, the computation speed of evaluation function is very fast because it is linear to the number of elements in the search space.
As a neighbor of a the current path may be a branch of paths in tabu search space, we randomly choose the path as a next point. It is interesting that though the chosen path to be executed is not the one with the highest weight, the later iterations may still be performed in the local space where the highest weight path exists. If the path with the highest weight is performed, the later iteration will escape from the current local space and goes into the other parts of the search space.
6. Related Work
Automating unit testing is a great challenge and is still a dream for most software vendors. One key obstacle for achieving automating unit testing is how to generate appropriate test inputs. Many methodologies [
4,
14,
15,
16] have been devised in recent decades. Symbolic execution [
2,
17,
18,
19] is a traditional approach in static test-case generation, which was initially proposed by James C. King in 1976. By this methodology, a program is analyzed to build an execution tree without actually executing the program. The result tree is complete enough to be explored to find possible bugs.
Every path along the tree is a set of constraints that can affect the execution of the program. By using a theorem prover, the satisfiability of constraints can be reasoned [
20]. Unfortunately, due to the limitations of theorem provers, a constraint containing statements, such as function calls, is not solvable. The exclusive use of symbolic execution cannot process pointers or complex data structures. For example, Symstra [
21] cannot handle such code that contains array indexing with variables.
Dynamic test-case generation [
22] is a more practicable approach. It can be treated as a combined technique to an extent by applying static analysis, symbolic execution and constraint solving. It executes the target program repeatedly, usually starts with random inputs and then collects symbolic constraints along the real executing path. By using a constraint solver, these collected constraints are solved to infer alternative sets of inputs that direct the next execution paths.
One mainstream of dynamic test generation is adaptive random testing, which aims to more evenly spread the test cases over the input domain. [
23,
24]. Cristian Cadar et al. devised a dynamic bug-finding method [
5,
25,
26]. That method is based on the observation that code can generate its own test cases at run-time by a combination of symbolic and concrete execution. Its symbolic execution has a special feature that is bit-level symbolic execution. Based on this method, a prototype EGT system [
25] was developed and applied to real programs.
DART [
4], abbreviation of Directed Automated Random Testing, proposed by Patrice Godefroid et al., is a typical tool using dynamic test-case generation technique. The goal of DART is to systematically execute all feasible program paths to detect latent runtime errors. It adopts an improved random testing technique to achieve better coverage. Systematic Modular Automated Random Testing (SMART) [
27] is an extension to DART. SMART extends DART by testing functions in isolation, encoding test results as function summaries expressed using input preconditions and output post-conditions and then re-using those summaries when testing higher-level functions.
The motivation is to achieve a scalable DART, as it is clear that systematically executing all feasible paths does not fit large programs. CUTE [
3] is another tool on dynamic test-case generation. It mixes dynamic concrete and symbolic execution—called concolic execution, which is good for dealing with pointers and complex data types and has some optimized constraint solving algorithms. It supports bounded depth-first search to avoid search space explosion.
Hybrid Concolic Testing [
28,
29] extends the CUTE work, where random search and bounded depth-first search are combined. A bounded depth-first search algorithm attempts to explore all neighborhoods of the current paths exhaustively, while a random search algorithm has the ability of reaching deep program branches quickly. The branch coverage by using this method has a notable boost. Many other concolic unit testing tools do exist, such as those in [
30,
31]. Compared to Hybrid CUTE, the difference is the path selection. We use the tabu strategy instead of random search, and this is an orthogonal improvement for scalability without reducing the ability to find bugs.
A key problem of dynamic test-case generation technique is the selection of alternative paths. Although a bounded depth-first algorithm can improve the branch coverage observably, it is not helpful to find bugs quickly, especially in large and complex program units. The depth-first path selector has to explore every branch exhaustedly in a fixed and unpredictable order, as if exploring in the dark. In some extreme situations, such as an infinite loop, depth-first search may cause a path set explosion and lose other paths as in the given experiment.
To an extent, bounded depth-first search in program paths can be almost classified as a random algorithm, because the locations of targets (bugs) as well as the paths are completely unpredictable to the search algorithm. Fortunately, by some statistical work [
6], there is evidence to show that the bugs appearing in programs are not distributed completely randomly. The heuristical algorithm introduced in this paper benefits from those previous works.
The algorithm in this paper combined with control flow graph analysis is good at selecting latent error-relevant paths as well as avoiding path set explosions. The tabu search strategy directs coming dynamic executions to alternative paths where bugs may appear with high probability. The resulting set of test cases generated by our approach was designed to indicate bugs earlier with greater code coverage.
Tabu search is also frequently used for test generation. Tabu search is a local heuristic method based on the neighborhood. It prohibits already visited solutions and others through user-provided rules, significantly enhancing the performance of searches. Tabu search has been applied to test generation and/or prioritization.
Díaz et al. designed a testing technique that combines Tabu search with the Korel chaining approach to obtain a specific coverage in software testing [
32]. They then presented a tabu search metaheuristic algorithm for generating structural software tests. The test generator has a cost function for intensifying the search and another for diversifying the search. It also combines the use of memory with a backtracking process to avoid becoming stuck in local minima [
33].
Perumal et al. combined Cuckoo and Tabu Search in test data generation [
34]. Srivastava et al. presented a search algorithm for the automatic test generation and prioritization through a clustering technique of data mining [
35]. They also presented an approach for test data generation using the cuckoo search and tabu search algorithms (CSTS) [
36]. It uses the cuckoo algorithm for converging to the solution in minimal time, and uses the tabu mechanism of backtracking from local optima by Lévy flight.
Zamli et al. proposed a hybrid t-way test generation strategy HHH. HHH adopts Tabu search as the meta-heuristic and leverages four low level meta-heuristics. HHH is able to adaptively select the most suitable meta-heuristic at any particular time [
10]. Yu et al. generated test cases based on tabu search and genetic algorithm, aiming at improving the effectiveness of generating test case for algebraic specification [
9].
To ensure the quality of current highly configurable software systems, Hasan et al. presented a search-based strategy to generate constrained interaction test suites to cover all possible combinations [
7]. The strategy generates the set of all possible t-tuple combinations, and then filters out the set by removing forbidden t-tuples. The strategy also utilizes a mixed neighborhood tabu search to construct optimal or near-optimal constrained test suites.
Rathore et al. generated test-data by combining genetic and tabu search algorithms [
37]. The approach uses genetic algorithm to generate test-data, supplemented by a tabu search heuristic in mutation step. It also incorporates backtracking process that moves search away from local optima. Sharma et al. optimized the cost of testing using Tabu search, which provides maximum code coverage along with an Aspiration criteria of Tabu Search in order to optimize the cost and generate a minimum cost path with maximum coverage [
38].
Comparatively, our approach combines dataflow analysis with dynamic symbolic execution and heuristically searches for program path space based on the tabu search strategy and the program fault statistics. These techniques are combined together, enabling us to find more possible errors in programs with fewer test cases; it also scales well w.r.t. program sizes and, thus, can be applied to real-world software systems with reasonable costs.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}