



Limitations of Nature-Inspired Algorithms for Pricing on Digital Platforms

Abstract
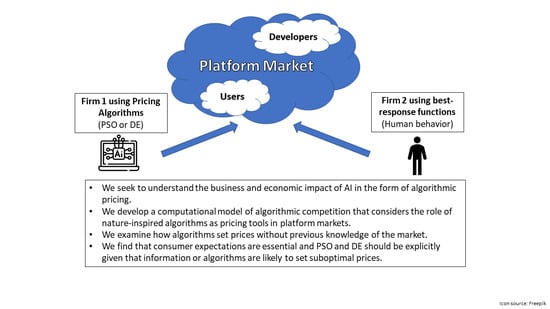
:
1. Introduction
- For pricing, we find that the basic version of PSO works better than the basic version of DE.
- Basic versions of these algorithms are not capable of adapting to changes in consumer expectations.
- The more passive consumers are, the more errors both algorithms generate.
- These errors imply that the algorithms set suboptimal prices, which reduces profit.
2. Materials and Methods
2.1. Biologically Inspired Algorithms
2.1.1. Particle Swarm Optimization (PSO)
2.1.2. Differential Evolution (DE)
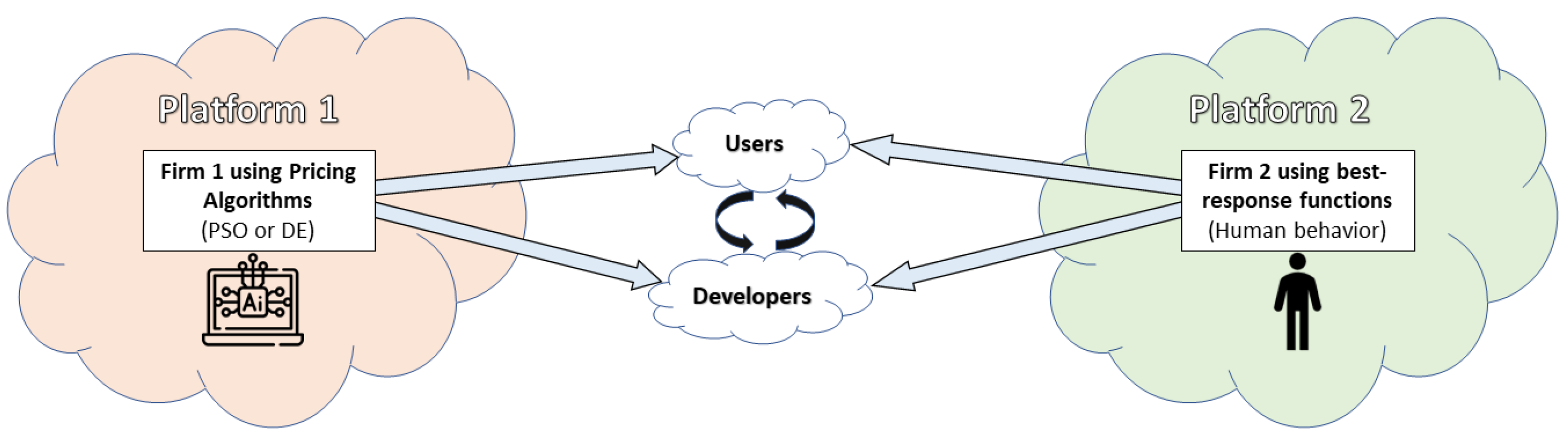
2.2. Market Environment and Parametrization
Parametrization
3. Results
3.1. Baseline Model Responsive Expectations
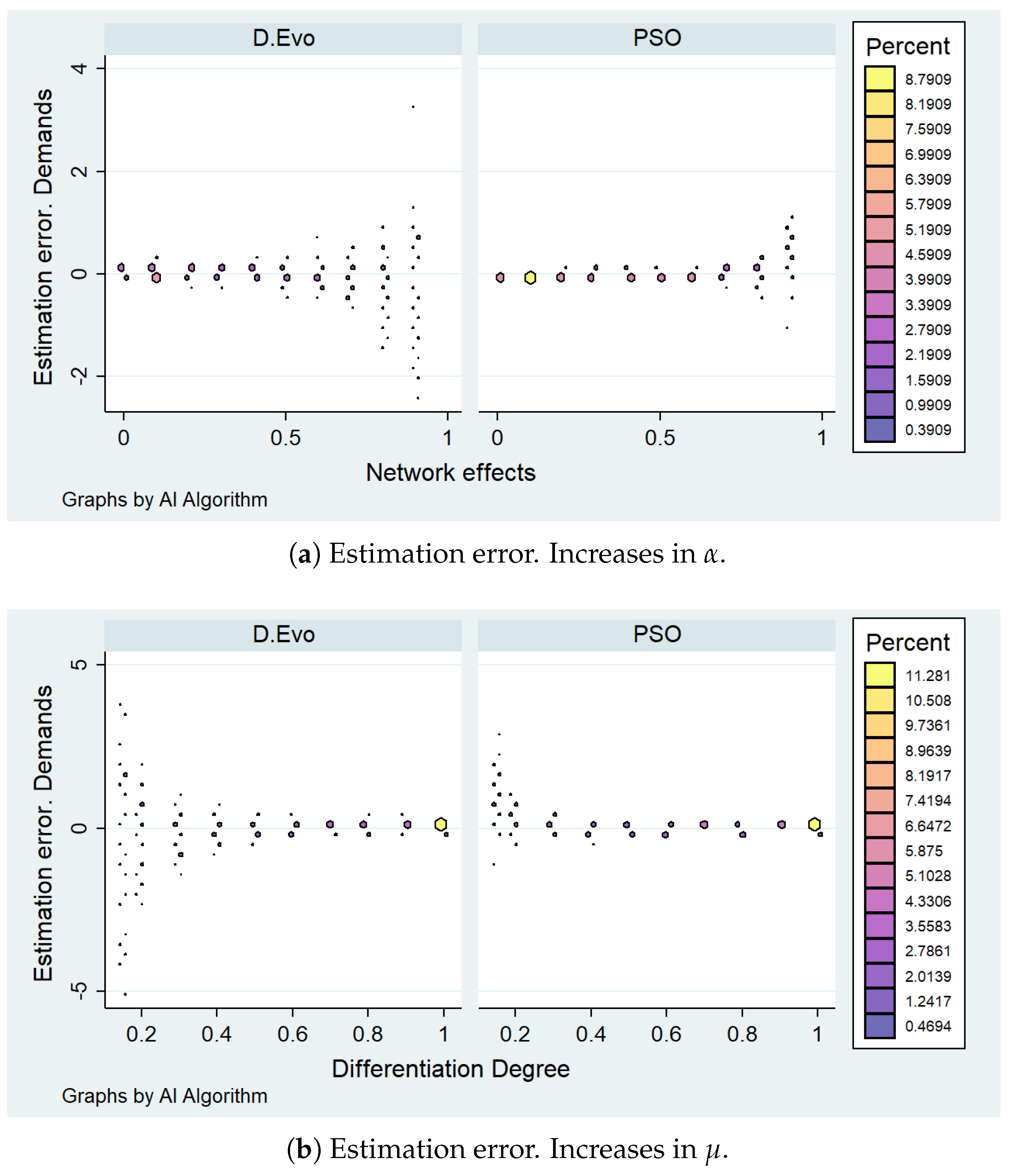
3.2. Cases with Different Information Levels
4. Discussion
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| PSO | particle swarm optimization |
| DE | differential evolution |
| AI | artificial intelligence |
References
- Waltman, L.; Kaymak, U. Q-learning agents in a Cournot oligopoly model. J. Econ. Dyn. Control 2008, 32, 3275–3293. [Google Scholar] [CrossRef]
- Eschenbaum, N.; Mellgren, F.; Zahn, P. Robust algorithmic collusion. arXiv 2022, arXiv:2201.00345. [Google Scholar]
- Sanchez-Cartas, J.M.; Katsamakas, E. Artificial Intelligence, algorithmic competition and market structures. IEEE Access 2022, 10, 10575–10584. [Google Scholar] [CrossRef]
- Calvano, E.; Calzolari, G.; Denicolo, V.; Pastorello, S. Artificial intelligence, algorithmic pricing, and collusion. Am. Econ. Rev. 2020, 110, 3267–3297. [Google Scholar] [CrossRef]
- Klein, T. Autonomous algorithmic collusion: Q-learning under sequential pricing. RAND J. Econ. 2021, 52, 538–558. [Google Scholar] [CrossRef]
- Sanchez-Cartas, J.M.; Katsamakas, E. Effects of Algorithmic Pricing on Platform Competition; Working Paper; SSRN, 2022; p. 4027365. Available online: https://ssrn.com/abstract=4027365 (accessed on 5 November 2022).
- Lu, Y.; Wright, J. Tacit collusion with price-matching punishments. Int. J. Ind. Organ. 2010, 28, 298–306. [Google Scholar] [CrossRef]
- Zhang, Z.J. Price-matching policy and the principle of minimum differentiation. J. Ind. Econ. 1995, 43, 287–299. [Google Scholar] [CrossRef]
- Werner, T. Algorithmic and Human Collusion; Working Paper; SSRN, 2021; p. 3960738. Available online: https://ssrn.com/abstract=3960738 (accessed on 5 November 2022).
- Zhang, T.; Brorsen, B.W. Particle swarm optimization algorithm for agent-based artificial markets. Comput. Econ. 2009, 34, 399. [Google Scholar] [CrossRef]
- Collins, A.; Thomas, L. Comparing reinforcement learning approaches for solving game theoretic models: A dynamic airline pricing game example. J. Oper. Res. Soc. 2012, 63, 1165–1173. [Google Scholar] [CrossRef]
- Seele, P.; Dierksmeier, C.; Hofstetter, R.; Schultz, M.D. Mapping the ethicality of algorithmic pricing: A review of dynamic and personalized pricing. J. Bus. Ethics 2021, 170, 697–719. [Google Scholar] [CrossRef] [Green Version]
- Schwalbe, U. Algorithms, machine learning, and collusion. J. Compet. Law Econ. 2018, 14, 568–607. [Google Scholar] [CrossRef]
- Enke, D.; Mehdiyev, N. Stock market prediction using a combination of stepwise regression analysis, differential evolution-based fuzzy clustering, and a fuzzy inference neural network. Intell. Autom. Soft Comput. 2013, 19, 636–648. [Google Scholar] [CrossRef]
- Hachicha, N.; Jarboui, B.; Siarry, P. A fuzzy logic control using a differential evolution algorithm aimed at modelling the financial market dynamics. Inf. Sci. 2011, 181, 79–91. [Google Scholar] [CrossRef]
- Maschek, M.K. Particle Swarm Optimization in Agent-Based Economic Simulations of the Cournot Market Model. Intell. Syst. Account. Financ. Manag. 2015, 22, 133–152. [Google Scholar] [CrossRef]
- Das, S.; Suganthan, P.N. Differential evolution: A survey of the state-of-the-art. IEEE Trans. Evol. Comput. 2010, 15, 4–31. [Google Scholar] [CrossRef]
- Bonate, P.L.; Howard, D.R. Evolutionary Optimization Algorithms: Biologically Inspired and Population-Based Approaches to Computer Intelligence; John Wiley & Sons: Hoboken, NJ, USA, 2013; ISBN 978-0470937419. [Google Scholar]
- Lampinen, J.; Storn, R. Differential evolution. In New Optimization Techniques in Engineering; Springer: Berlin/Heidelberg, Germany, 2004; pp. 123–166. [Google Scholar]
- Eberhart, R.; Kennedy, J. Particle swarm optimization. In Proceedings of the IEEE International Conference on Neural Networks, Perth, Australia, 27 November–1 December 1995; Volume 4, pp. 1942–1948. [Google Scholar]
- Chatterjee, A.; Siarry, P. Nonlinear inertia weight variation for dynamic adaptation in particle swarm optimization. Comput. Oper. Res. 2006, 33, 859–871. [Google Scholar] [CrossRef]
- Storn, R.; Price, K. Differential evolution–a simple and efficient heuristic for global optimization over continuous spaces. J. Glob. Optim. 1997, 11, 341–359. [Google Scholar] [CrossRef]
- Hagiu, A.; Hałaburda, H. Information and two-sided platform profits. Int. J. Ind. Organ. 2014, 34, 25–35. [Google Scholar] [CrossRef] [Green Version]
- Armstrong, M. Competition in two-sided markets. RAND J. Econ. 2006, 37, 668–691. [Google Scholar] [CrossRef] [Green Version]
- Sanchez-Cartas, J.M. Agent-based models and industrial organization theory. A price-competition algorithm for agent-based models based on Game Theory. Complex Adapt. Syst. Model. 2018, 6, 1–30. [Google Scholar] [CrossRef] [Green Version]
- Zielinski, K.; Weitkemper, P.; Laur, R.; Kammeyer, K.D. Parameter study for differential evolution using a power allocation problem including interference cancellation. In Proceedings of the 2006 IEEE International Conference on Evolutionary Computation, Vancouver, BC, Canada, 16–21 July 2006; pp. 1857–1864. [Google Scholar]
- Storn, R. On the usage of differential evolution for function optimization. In Proceedings of the North American Fuzzy Information Processing, Berkeley, CA, USA, 19–22 June 1996; pp. 519–523. [Google Scholar]
- Sanchez-Cartas, J.M.; Sancristobal, I.P. Nature-inspired algorithms and individual decision-making. In Proceedings of the 5th International Conference on Decision Economics, DECON, L’Aquila, Italy, 13–15 July 2022; In Press. [Google Scholar]
- Asker, J.; Fershtman, C.; Pakes, A. Artificial Intelligence and Pricing: The Impact of Algorithm Design; Technical Report; National Bureau of Economic Research: Cambridge, MA, USA, 2021. [Google Scholar]
- Evans, D.S. Some empirical aspects of multi-sided platform industries. Rev. Netw. Econ. 2003, 2, 191–209. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Information Levels | Intuition |
|---|---|
| Responsive | Users and developers are aware of the prices paid by all groups |
| Passive | Users and developers are not aware of the prices paid by the other group (expectations are fixed) |
| Semipassive | Users are not aware of the developer price, but developers know all prices (expectations are fixed for users but responsive for developers) |
| Wary | Users do not observe developer prices but infer their price from user prices (expectations are responsive for all agents, but for users, they are more rigid) |
| Equilibria by Expectations | Developer Price | User Price |
|---|---|---|
| Responsive | ||
| Wary | ||
| Semipassive | ||
| Passive |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sanchez-Cartas, J.M.; Sancristobal, I.P. Limitations of Nature-Inspired Algorithms for Pricing on Digital Platforms. Electronics 2022, 11, 3927. https://doi.org/10.3390/electronics11233927
Sanchez-Cartas JM, Sancristobal IP. Limitations of Nature-Inspired Algorithms for Pricing on Digital Platforms. Electronics. 2022; 11(23):3927. https://doi.org/10.3390/electronics11233927
Chicago/Turabian StyleSanchez-Cartas, J. Manuel, and Ines P. Sancristobal. 2022. "Limitations of Nature-Inspired Algorithms for Pricing on Digital Platforms" Electronics 11, no. 23: 3927. https://doi.org/10.3390/electronics11233927