
Construction of a Character Dataset for Historical Uchen Tibetan Documents under Low-Resource Conditions


Abstract
:1. Introduction
2. Related Work
2.1. Character Annotation
2.2. Character Image Extraction
2.3. Dataset Construction and Augmentation
2.4. Character Recognition
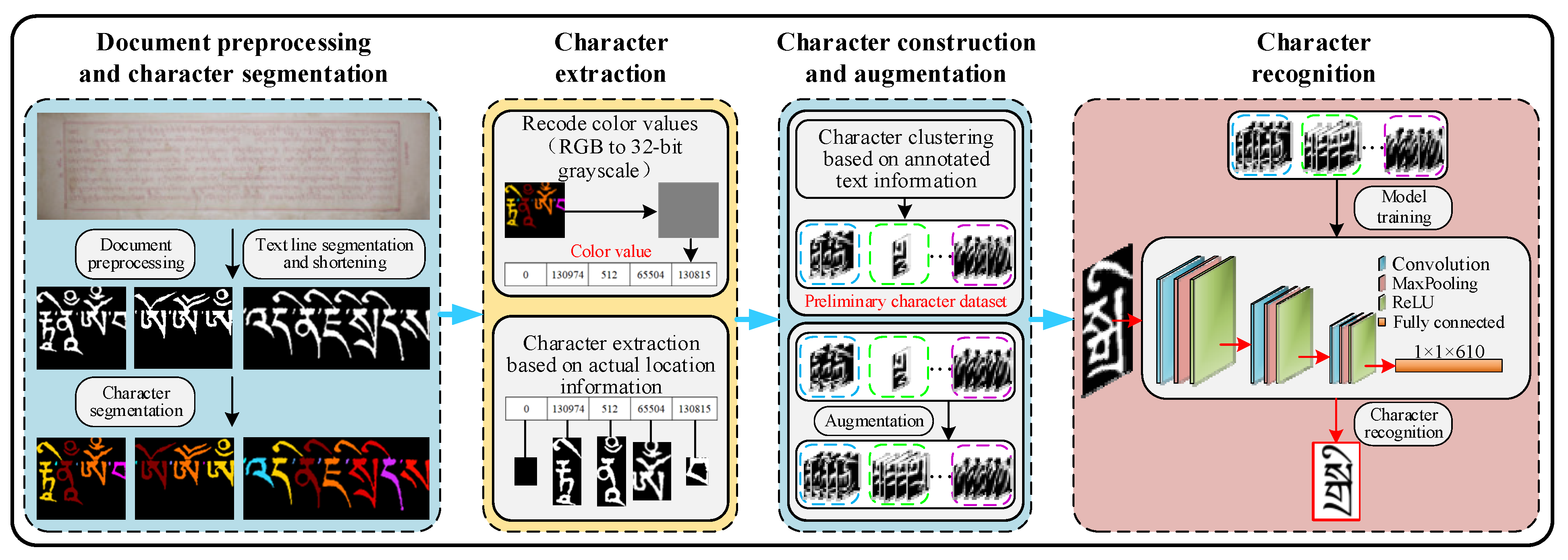
3. Methodology
3.1. Character Annotation
3.2. Character Image Extraction
| Algorithm 1: Character extraction algorithm based on real location information |
| Input: Encoded character block ECB Output: Single character SC 1: H, W ← size function(ECB) 2: NC ← count the number of colors in ECB 3: for l = 1: 2: H do 4: ECBL ← ECB(1: l,:) = 0, ECB(l + 2, :) = 0 5: NCL ← count the number of colors in ECBL 6: if NC == NCL 7: for c = 1: NC do 8: for h, w = 1: H, 1: W do 9: if ECB(h, w) ≠ NCL(c) 10: ECB(h, w) = 0 11: end if 12: end for 13: SC ← cropping function(ECB) 14: end for 15: end if 16: end for |
3.3. Dataset Construction and Augmentation
3.3.1. Character Dataset Construction
| Algorithm 2: Construction of the algorithm of the character dataset based on real position sequence matching |
| Input: Single character annotations SCA, Single characters SC Output: Preliminary character dataset PCD 1: NSCA ← count the number of SCA 2: for d = 1: NSCA do 3: MN ← read the mapping name of SCA[d] 4: ISEF ← exist the class folder of SCA[d] or not 5: if not ISEF 6: CF ← create the class folder of SCA[d] 7: the MN in SC is written into CF //the MN corresponds to a single character name 8: else 9: the MN in SC is written into CF 10: end if 11: PCD ← save function(CF) //each CF represents a character class 12: end for |
3.3.2. Character Dataset Augmentation
- Ordinary characterWe use characters synthesized by “Tibetan-Sanskrit” handwritten sample generation method based on component combination [15].
- Special symbolsBecause the component samples of special symbols are not collected in the “Tibetan-Sanskrit” handwritten sample generation method based on component combination, special symbols cannot be synthesized by this method. In addition to the syllable point (“
![Electronics 11 03919 i001]() ”) and single vertical line (“
”) and single vertical line (“![Electronics 11 03919 i002]() ”), there are seven main kinds of special symbols commonly used in the document images of historical Uchen Tibetan documents, namely, “
”), there are seven main kinds of special symbols commonly used in the document images of historical Uchen Tibetan documents, namely, “![Electronics 11 03919 i003]() ”, “
”, “![Electronics 11 03919 i004]() ”, “
”, “![Electronics 11 03919 i005]() ”, “
”, “![Electronics 11 03919 i006]() ”, “
”, “![Electronics 11 03919 i007]() ”, “
”, “![Electronics 11 03919 i008]() ” and “
” and “![Electronics 11 03919 i009]() ”. For the first four special characters mentioned above, we collect them directly from the images of historical Uchen Tibetan documents. The fifth to sixth special symbols are highly similar to the single vertical line in shape and structure. By cutting a point and two points on the head position above the single vertical line symbol, we can obtain the fifth and sixth symbols, respectively. For the seventh special symbol, due to the small number of historical Tibetan documents, the direct acquisition method has difficulty achieving the purpose of augmentation. Through observation, the upper and lower strokes of the seventh special symbol (“
”. For the first four special characters mentioned above, we collect them directly from the images of historical Uchen Tibetan documents. The fifth to sixth special symbols are highly similar to the single vertical line in shape and structure. By cutting a point and two points on the head position above the single vertical line symbol, we can obtain the fifth and sixth symbols, respectively. For the seventh special symbol, due to the small number of historical Tibetan documents, the direct acquisition method has difficulty achieving the purpose of augmentation. Through observation, the upper and lower strokes of the seventh special symbol (“![Electronics 11 03919 i009]() ”) have symmetry. The difference between the special symbols mainly lies in the spacing between the upper and lower strokes. We propose a special character synthesis method based on the random distance between upper and lower strokes (Algorithm 3).
”) have symmetry. The difference between the special symbols mainly lies in the spacing between the upper and lower strokes. We propose a special character synthesis method based on the random distance between upper and lower strokes (Algorithm 3).









| Algorithm 3: Special character synthesis algorithm based on the random distance between upper and lower strokes |
| Input: Special symbols SS Output: Synthesized special symbols SSS 1: NSS ← count the number of SS 2: for s = 1: NSS do 3: SSU, SSL ← extract the upper and lower strokes of SS //use the Y coordinate of centroid 4: SSUs, SSLs ← rotate function(SSU, SSL) //rotate 90 degrees counterclockwise 5: RI ← generate a random integer in [−2,12] //[−2,12] is the priori distance range 6: SSL, SSU ← SSUs, SSLs //the upper(lower) stroke is as the lower(upper) stroke of SSS 7: SSS ← synthesis function(SSL, SSU, RI) 8: end for |
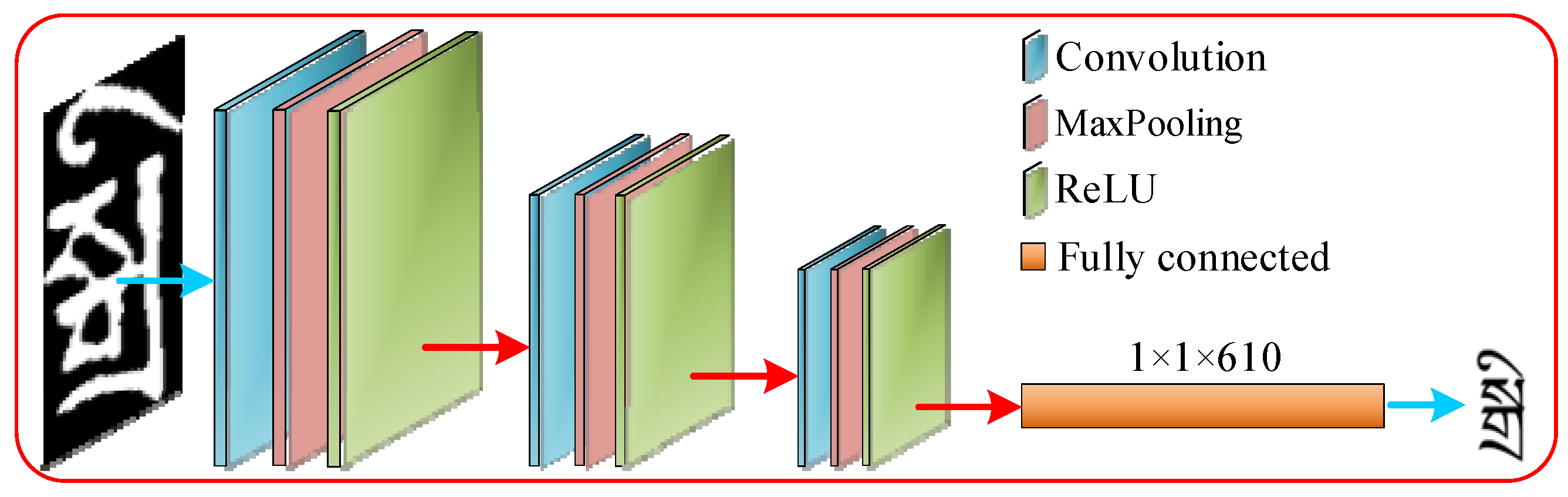
3.4. Character Recognition
4. Experimental Results and Analysis
4.1. Character Image Extraction Results
4.2. Character Dataset Augmentation and Construction Results


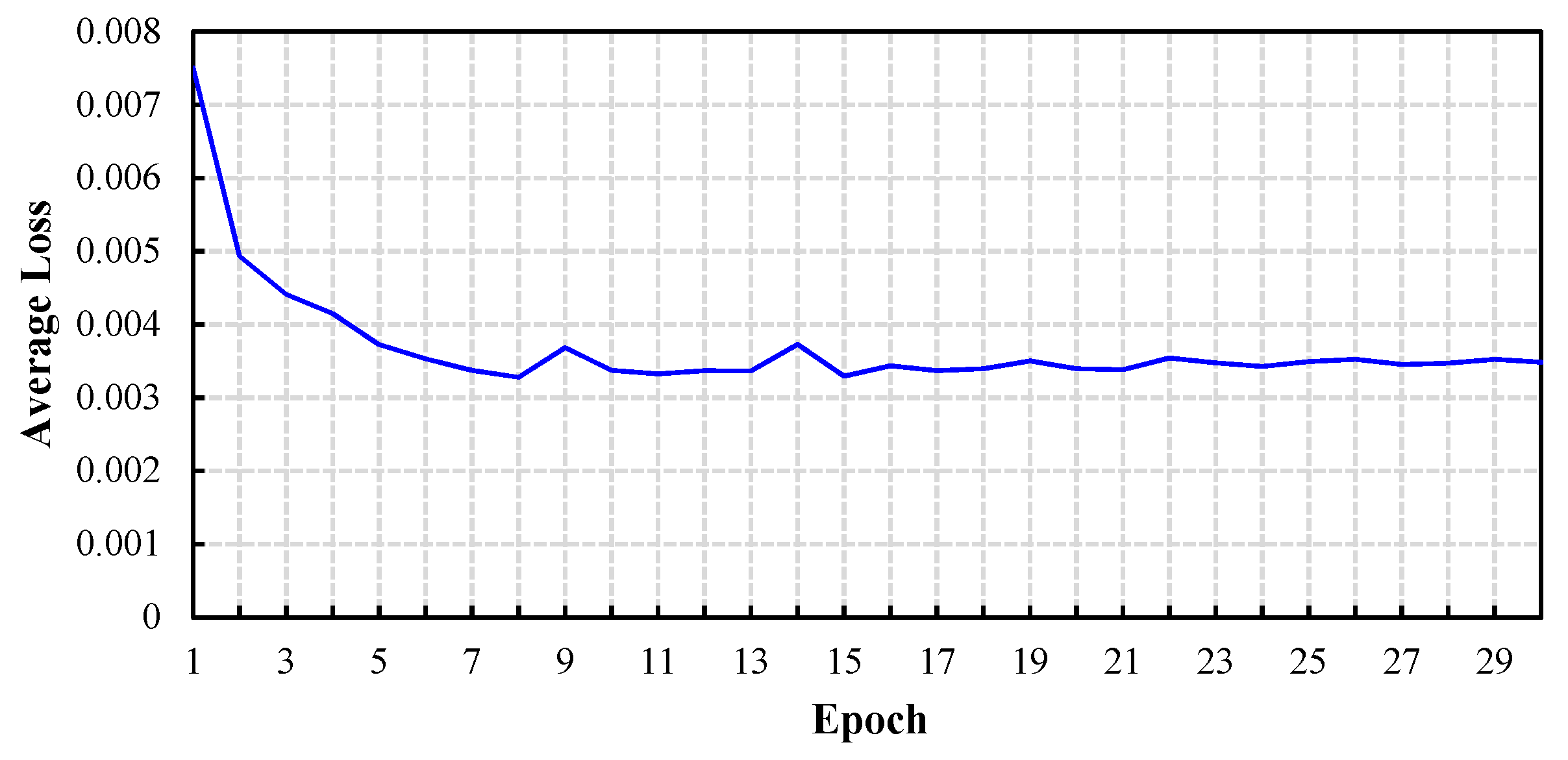
4.3. Character Annotation and Recognition Results
4.4. Limitation Analysis
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Kojima, M.; Kawazoe, Y.; Kimura, M. Automatic character recognition for Tibetan script. J. Indian Buddh. Stud. 1991, 39, 844–848. [Google Scholar] [CrossRef]
- Kojima, M.; Kawazoe, Y.; Kimura, M. Character recognition of wooden blocked Tibetan similar manuscripts by using Euclidean distance with deferential weight. Ipsj Sig Notes 1996, 1996, 13–18. [Google Scholar]
- Kojima, M.; Akiyama, Y.; Kawazoe, Y.; Kimura, M. Extraction of characteristic features in Tibetan wood-block editions. J. Indian Buddh. Stud. 1994, 42, 866–869. [Google Scholar] [CrossRef]
- Zhang, X.Q.; Ma, L.L.; Duan, L.J.; Liu, Z.Y.; Wu, J. Layout analysis for historical Tibetan documents based on convolutional denoising autoencoder. J. Chin. Inform. Process. 2018, 32, 67–73. [Google Scholar] [CrossRef]
- Duan, L.J.; Zhang, X.Q.; Ma, L.L.; Wu, J. Text extraction method for historical Tibetan document images based on block projections. Optoelectron. Lett. 2017, 13, 457–461. [Google Scholar] [CrossRef]
- Ngodrup; Zhao, D.C. Research on wooden blocked Tibetan character segmentation based on drop penetration algorithm. In Proceedings of the 2010 Chinese Conference on Pattern Recognition (CCPR), Chongqing, China, 21–23 October 2010; pp. 1–5. [Google Scholar] [CrossRef]
- Zhao, Q.C.; Ma, L.L.; Duan, L.J. A touching character database from Tibetan historical documents to evaluate the segmentation algorithm. In Proceedings of the Chinese Conference on Pattern Recognition and Computer Vision (PRCV), Guangzhou, China, 23–26 November 2018; pp. 309–321. [Google Scholar] [CrossRef]
- Han, Y.H.; Wang, W.L.; Liu, H.M.; Wang, Y.Q. A combined approach for the binarization of historical Tibetan document images. Int. J. Pattern Recog. Artif. Intell. 2019, 33, 1954038. [Google Scholar] [CrossRef]
- Zhao, P.H.; Wang, W.L.; Zhang, G.W.; Lu, Y.Q. Alleviating pseudo-touching in attention U-Net-based binarization approach for the historical Tibetan document images. Neural Comput Applic 2021. [Google Scholar] [CrossRef]
- Zhou, F.M.; Wang, W.L.; Lin, Q. A novel text line segmentation method based on contour curve tracking for Tibetan historical documents. Int. J. Pattern Recog. Artif. Intell. 2018, 32, 1854025. [Google Scholar] [CrossRef]
- Wang, Y.Q.; Wang, W.L.; Li, Z.J.; Han, Y.Q.; Wang, X.J. Research on Text Line Segmentation of Historical Tibetan Documents Based on the Connected Component Analysis. In Proceedings of the Chinese Conference on Pattern Recognition and Computer Vision (PRCV), Guangzhou, China, 23–26 November 2018; pp. 74–87. [Google Scholar] [CrossRef]
- Hu, P.F.; Wang, W.L.; Li, Q.Q.; Wang, T.J. Touching text line segmentation combined local baseline and connected component for Uchen Tibetan historical documents. Inform. Process. Manag. 2021, 58, 102689. [Google Scholar] [CrossRef]
- Zhao, P.H.; Wang, W.L.; Cai, Z.Q.; Zhang, G.W.; Lu, Y.Q. Accurate fine-grained layout analysis for the historical Tibetan document based on the instance segmentation. IEEE Access 2021, 9, 154435–154447. [Google Scholar] [CrossRef]
- Zhang, C.; Wang, W.L.; Liu, H.M.; Zhang, G.W.; Lin, Q. Character Detection and Segmentation of Historical Uchen Tibetan Documents in Complex Situations. IEEE Access 2022, 10, 25376–25391. [Google Scholar] [CrossRef]
- Wang, W.L.; Lu, X.B.; Cai, Z.Q.; Shen, W.T.; Fu, J.; Caike, Z.X. Online handwritten sample generated based on component combination for Tibetan-Sanskrit. J. Chin. Informat. Process. 2017, 31, 64–73. [Google Scholar]
- Li, Z.J.; Wang, W.L. Tibetan historical document recognition of uchen script using baseline information. In Proceedings of the SPIE Tenth International Conference on Graphic and Image Processing (ICGIP), Chengdu, China, 6 May 2019; Volume 11069, p. 110693. [Google Scholar] [CrossRef]
- Buddhist Digital Resource Center (BDRC) [EB/OL]. Available online: https://www.google.com.hk/url?sa=t&rct=j&q=&esrc=s&source=web&cd=&ved=2ahUKEwiU_6jpstX7AhWoUPUHHaHCBYwQFnoECAgQAQ&url=https%3A%2F%2Fwww.bdrc.io%2F&usg=AOvVaw2UzWbivOaU6W0AWZ70AKwx (accessed on 1 January 2018).
- Tibetan (0F00-0FFF), The Unicode Standard, Version 14.0 [EB/OL]. Available online: https://unicode.org/charts/PDF/U0F00.pdf (accessed on 28 August 2022).
- Wang, D.H.; Wang, W.L.; Qian, J.J. 2DPCA and IMLDA method of feature extraction for online handwritten Tibetan recognition. In Proceedings of the 2nd International Conference on Networking and Digital Society (ICNDS), Wenzhou, China, 30–31 May 2010; pp. 563–566. [Google Scholar]
- Qian, J.J.; Wang, W.L.; Wang, D.H. A Novel Approach for Online Handwriting Recognition of Tibetan Characters. In Proceedings of the International MultiConference of Engineers and Computer Scientists (IMECS), Hong Kong, China, 17–19 March 2010; pp. 333–337. [Google Scholar]
- Huang, H.M.; Da, F.P. Sparse representation-based classification algorithm for optical Tibetan character recognition. Int. J. Light Electron Opt. 2014, 125, 1034–1037. [Google Scholar] [CrossRef]
- Ma, L.L.; Wu, J. Online handwritten Tibetan syllable recognition based on component segmentation method. In Proceedings of the 2015 13th International Conference on Document Analysis and Recognition (ICDAR), Tunis, Tunisia, 23–26 August 2015; pp. 46–50. [Google Scholar] [CrossRef]
- Hedayati, F.; Chong, J.; Keutzer, K. Recognition of Tibetan wood block prints with generalized hidden markov and kernelized modified quadratic distance function. In Proceedings of the 2011 Joint Workshop on Multilingual OCR and Analytics for Noisy Unstructured Text Data, Beijing, China, 17 September 2011. [Google Scholar] [CrossRef] [Green Version]
- Ma, L.L.; Long, C.J.; Duan, L.J.; Zhang, X.Q.; Li, Y.X.; Zhao, Q.C. Segmentation and recognition for historical Tibetan document images. IEEE Access 2020, 8, 52641–52651. [Google Scholar] [CrossRef]
- Keret, S.; Wolf, L.; Dershowitz, N.; Werner, E.; Almogi, O.; Wangchuk, D. Transductive Learning for Reading Handwritten Tibetan Manuscripts. In Proceedings of the 2019 International Conference on Document Analysis and Recognition (ICDAR), Sydney, NSW, Australia, 20–25 September 2019; pp. 214–221. [Google Scholar] [CrossRef]
- Lecun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| No. | Tibetan Character | Component Unit and Code | Character Code |
|---|---|---|---|
| 1 |  |  | 0F00 |
 | 0F68 0F7C 0F7E | ||
| 2 |  |  | 0F57 0FB2 0F75 0F83 |
 | 0F56 0FB7 0FB2 0F75 0F83 |
| Type | Configuration |
|---|---|
| Convolution | k5 × 5 |
| MaxPooling | k2 × 2, s2 |
| Convolution | k5 × 5 |
| MaxPooling | k2 × 2, s2 |
| Convolution | k5 × 5 |
| Linear | 1 × 1 × 610 |
| Softmax | 1 × 1 × 610 |
| Sampling Method | Stroke Attribution Method | Data Abbreviation | NCCB | NACB | PACB | NCASS |
|---|---|---|---|---|---|---|
| Systematic sampling | Cen-AM | SS-Cen | 9916 | 5581 | 56.28% | 7728 |
| Con-AM | SS-Con | 9971 | 5571 | 55.87% | 7705 | |
| ConCen-AM | SS-ConCen | 9868 | 5555 | 56.29% | 7657 | |
| Random sampling | Cen-AM | RS-Cen | 9963 | 5615 | 56.36% | 7753 |
| Con-AM | RS-Con | 10,056 | 5674 | 56.42% | 7959 | |
| ConCen-AM | RS-ConCen | 9927 | 5562 | 56.03% | 7689 |
| Epoch | SS-Cen | SS-Con | SS-ConCen | RS-Cen | RS-Con | RS-ConCen |
|---|---|---|---|---|---|---|
| 1–10 | 0.9067 | 0.9062 | 0.9073 | 0.8978 | 0.8909 | 0.8950 |
| 11–14 | 0.9019 | 0.9015 | 0.9028 | 0.8937 | 0.8873 | 0.8924 |
| 15–18 | 0.9057 | 0.9053 | 0.9064 | 0.8964 | 0.8923 | 0.8948 |
| 19–30 | 0.9072 | 0.9071 | 0.9082 | 0.8989 | 0.8935 | 0.8982 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, C.; Wang, W.; Zhang, G. Construction of a Character Dataset for Historical Uchen Tibetan Documents under Low-Resource Conditions. Electronics 2022, 11, 3919. https://doi.org/10.3390/electronics11233919
Zhang C, Wang W, Zhang G. Construction of a Character Dataset for Historical Uchen Tibetan Documents under Low-Resource Conditions. Electronics. 2022; 11(23):3919. https://doi.org/10.3390/electronics11233919
Chicago/Turabian StyleZhang, Ce, Weilan Wang, and Guowei Zhang. 2022. "Construction of a Character Dataset for Historical Uchen Tibetan Documents under Low-Resource Conditions" Electronics 11, no. 23: 3919. https://doi.org/10.3390/electronics11233919