
Mapping and Optimization Method of SpMV on Multi-DSP Accelerator
{kind=link}
{kind=link}
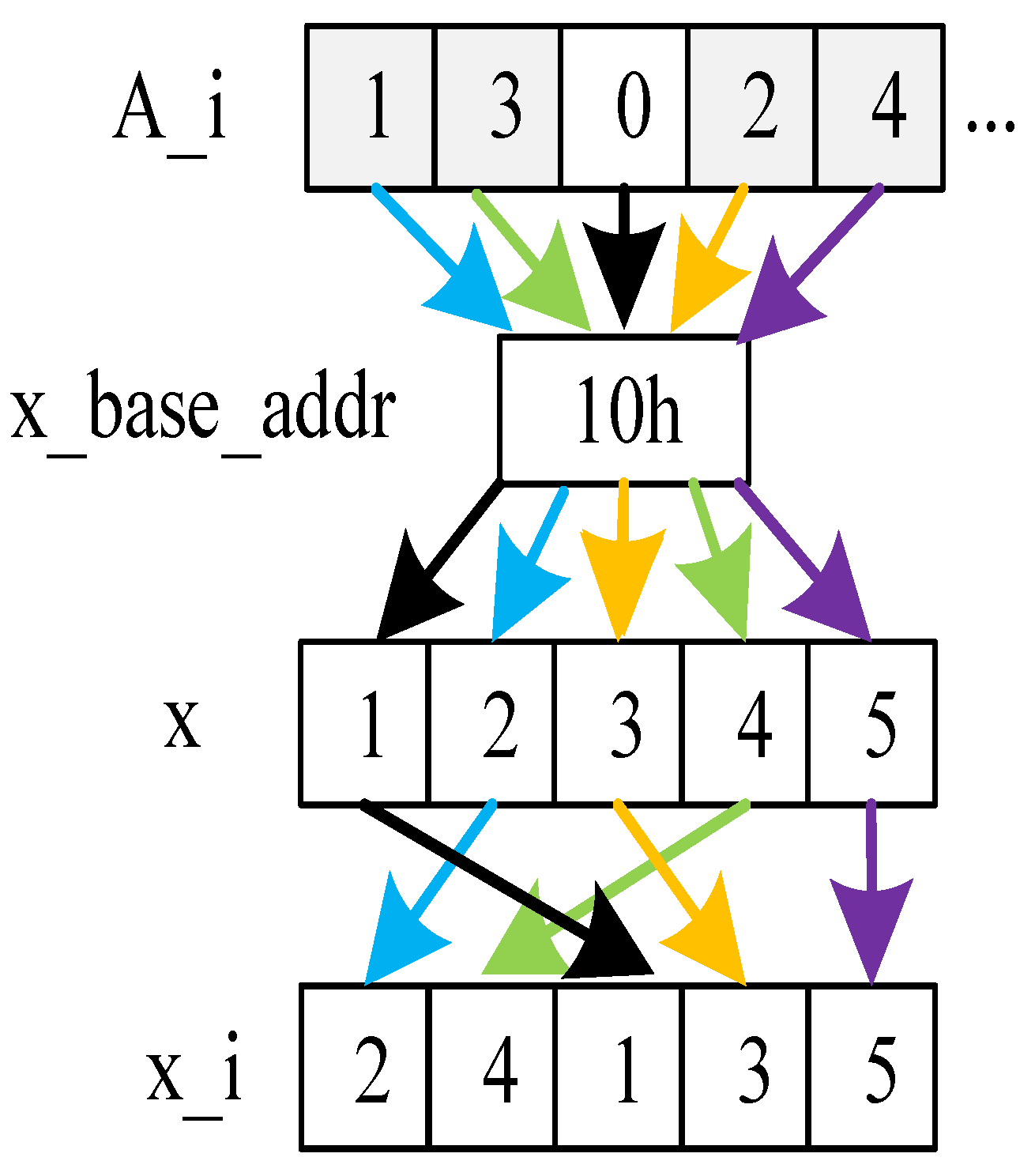{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
- We propose a SuperGather data transmission method and implement it in the DMA of the multi-DSP architecture;
- We explore the optimal mapping method of SpMV operation in multi-DSP architecture and get the optimal scheme that has the highest performance and the best bandwidth utilization;
- According to the optimal scheme, we have run the High Performance Conjugate Gradient (HPCG) benchmark on the accelerator, and the result proves the superiority of our design.
2. Related Work
3. Background
3.1. The ELL Storage Format and the SpMV Algorithm
| Algorithm 1 SpMV Algorithm of ELL Storage Format |
|
3.2. M Processor Architecture
4. Methods and Design
4.1. SuperGather
4.2. A Dedicated Channel
4.3. The Algorithm Structure
5. SpMV Mapping on the M Processor
5.1. Performance Calculation Principle
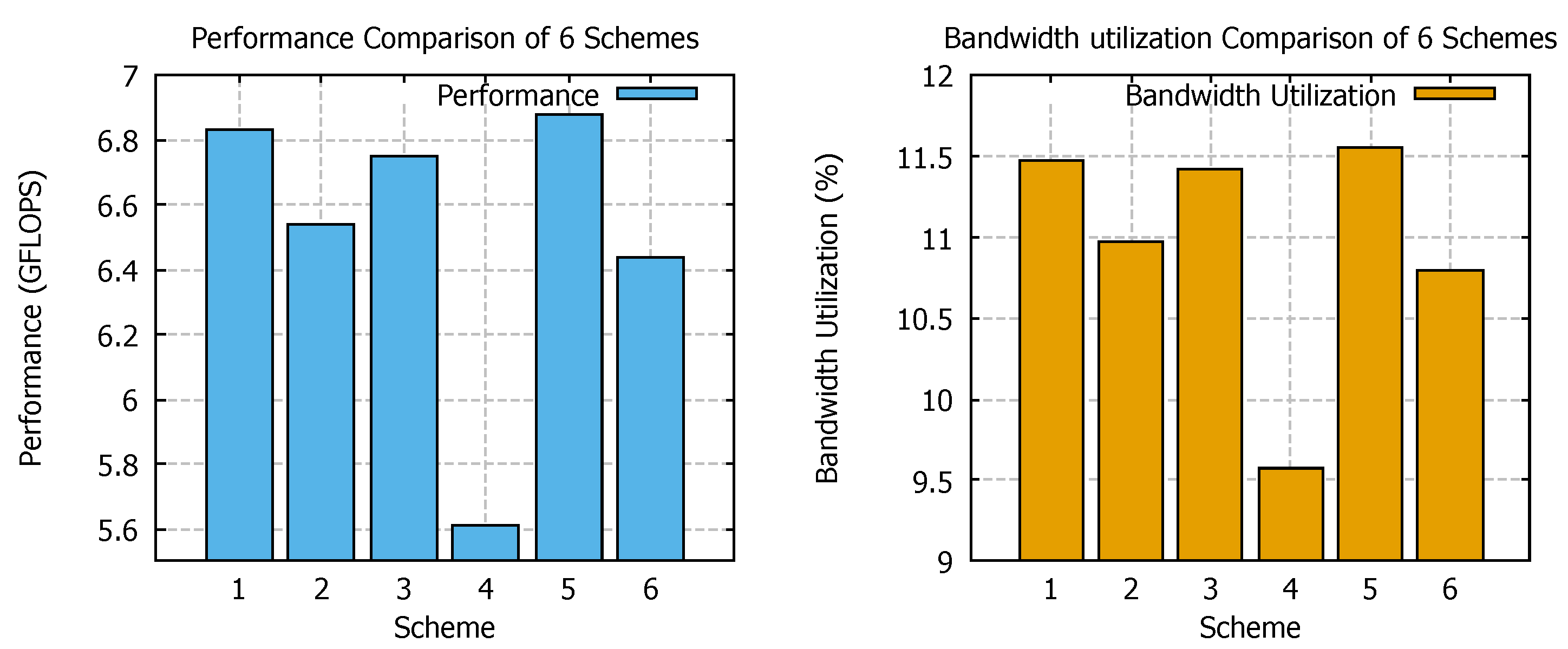
5.2. Optimization of the SpMV Algorithm
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Oyarzun, G.; Peyrolon, D.; Alvarez, C.; Martorell, X. An FPGA cached sparse matrix vector product (SpMV) for unstructured computational fluid dynamics simulations. arXiv 2021, arXiv:2107.12371. [Google Scholar]
- Demirci, G.V.; Ferhatosmanoglu, H. Partitioning Sparse Deep Neural Networks for Scalable Training and Inference. In Proceedings of the ACM International Conference on Supercomputing, Virtual, 14–17 June 2021; Association for Computing Machinery: New York, NY, USA, 2021; pp. 254–265. [Google Scholar] [CrossRef]
- Langr, D.; Tvrdík, P. Evaluation Criteria for Sparse Matrix Storage Formats. IEEE Trans. Parallel Distrib. Syst. 2016, 27, 428–440. [Google Scholar] [CrossRef]
- Bell, N.; Garland, M. Implementing sparse matrix-vector multiplication on throughput-oriented processors. In Proceedings of the Conference on High Performance Computing Networking, Storage and Analysis, Portland, OR, USA, 14–20 November 2009; pp. 1–11. [Google Scholar] [CrossRef] [Green Version]
- Kourtis, K.; Karakasis, V.; Goumas, G.; Koziris, N. CSX: An Extended Compression Format for SpMV on Shared Memory Systems. In Proceedings of the 16th ACM SIGPLAN Symposium on Principles and Practice of Parallel Programming, PPOPP 2011, San Antonio, TX, USA, 12–16 February 2011; Volume 46, pp. 247–256. [Google Scholar] [CrossRef]
- Liu, W.; Vinter, B. CSR5: An Efficient Storage Format for Cross-Platform Sparse Matrix-Vector Multiplication. In Proceedings of the 29th ACM on International Conference on Supercomputing, Newport Beach, CA, USA, 8–11 June 2015. [Google Scholar] [CrossRef]
- Yan, S.; Li, C.; Zhang, Y.; Zhou, H. yaSpMV: Yet another SpMV framework on GPUs. In Proceedings of the 19th ACM SIGPLAN Symposium on Principles and Practice of Parallel Programming, Orlando, FL, USA, 15–19 February 2014; Volume 49, pp. 107–118. [Google Scholar] [CrossRef]
- Dufrechou, E.; Ezzatti, P.; Quintana-Ortí, E. Selecting optimal SpMV realizations for GPUs via machine learning. Int. J. High Perform. Comput. Appl. 2021, 35, 254–267. [Google Scholar] [CrossRef]
- Katagiri, T.; Sato, M. An Auto-tuning Method for Run-time Data Transformation for Sparse Matrix-Vector Multiplication. IPSJ SIG Notes 2011, 41, 130. [Google Scholar]
- Guo, P.; Wang, L.; Chen, P. A Performance Modeling and Optimization Analysis Tool for Sparse Matrix-Vector Multiplication on GPUs. IEEE Trans. Parallel Distrib. Syst. 2014, 25, 1112–1123. [Google Scholar] [CrossRef]
- Li, J.; Tan, G.; Chen, M.; Sun, N. SMAT: An Input Adaptive Auto-Tuner for Sparse Matrix-Vector Multiplication. In Proceedings of the 34th ACM SIGPLAN Conference on Programming Language Design and Implementation, Seattle, WA, USA, 16–19 June 2013; Association for Computing Machinery: New York, NY, USA, 2013; pp. 117–126. [Google Scholar] [CrossRef]
- Sedaghati, N.; Mu, T.; Pouchet, L.N.; Parthasarathy, S.; Sadayappan, P. Automatic Selection of Sparse Matrix Representation on GPUs. In Proceedings of the 29th ACM on International Conference on Supercomputing, Newport Beach, CA, USA, 8–11 June 2015; Association for Computing Machinery: New York, NY, USA, 2015; pp. 99–108. [Google Scholar] [CrossRef]
- Neelima, B.; Reddy, G.; Raghavendra, P. A GPU Framework for Sparse Matrix Vector Multiplication. In Proceedings of the 2014 IEEE 13th International Symposium on Parallel and Distributed Computing, Marseille, France, 24–27 June 2014; pp. 51–58. [Google Scholar] [CrossRef]
- Bian, H.; Huang, J.; Liu, L.; Huang, D.; Wang, X. ALBUS: A method for efficiently processing SpMV using SIMD and Load balancing. Future Gener. Comput. Syst. 2021, 116, 371–392. [Google Scholar] [CrossRef]
- Benatia, A.; Ji, W.; Wang, Y.; Shi, F. BestSF: A Sparse Meta-Format for Optimizing SpMV on GPU. ACM Trans. Archit. Code Optim. 2018, 15, 1–27. [Google Scholar] [CrossRef] [Green Version]
- Vuduc, R.W.; Moon, H.J. Fast Sparse Matrix-Vector Multiplication by Exploiting Variable Block Structure. In Proceedings of the High Performance Computing and Communications, Austin, TX, USA, 15–20 November 2015; Yang, L.T., Rana, O.F., Di Martino, B., Dongarra, J., Eds.; Springer: Berlin/Heidelberg, Germany, 2005; pp. 807–816. [Google Scholar]
- Monakov, A.; Lokhmotov, A.; Avetisyan, A. Automatically Tuning Sparse Matrix-Vector Multiplication for GPU Architectures. In Proceedings of the High Performance Embedded Architectures and Compilers, Pisa, Italy, 25–27 January 2010; Patt, Y.N., Foglia, P., Duesterwald, E., Faraboschi, P., Martorell, X., Eds.; Springer: Berlin/Heidelberg, Germany, 2010; pp. 111–125. [Google Scholar]
- Liu, X.; Smelyanskiy, M.; Chow, E.; Dubey, P. Efficient Sparse Matrix-Vector Multiplication on X86-Based Many-Core Processors. In Proceedings of the 27th International ACM Conference on International Conference on Supercomputing, Eugene, OR, USA, 10–14 June 2013; Association for Computing Machinery: New York, NY, USA, 2013; pp. 273–282. [Google Scholar] [CrossRef]









Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, S.; Cao, Y.; Sun, S. Mapping and Optimization Method of SpMV on Multi-DSP Accelerator. Electronics 2022, 11, 3699. https://doi.org/10.3390/electronics11223699
Liu S, Cao Y, Sun S. Mapping and Optimization Method of SpMV on Multi-DSP Accelerator. Electronics. 2022; 11(22):3699. https://doi.org/10.3390/electronics11223699
Chicago/Turabian StyleLiu, Sheng, Yasong Cao, and Shuwei Sun. 2022. "Mapping and Optimization Method of SpMV on Multi-DSP Accelerator" Electronics 11, no. 22: 3699. https://doi.org/10.3390/electronics11223699