
Resistive-RAM-Based In-Memory Computing for Neural Network: A Review



Abstract
:1. Introduction
2. Background and Related Work
2.1. Processing In-Memory Architecture
2.2. Processing-In-Memory vs. Near-Memory Processing
2.3. Resistive RAM
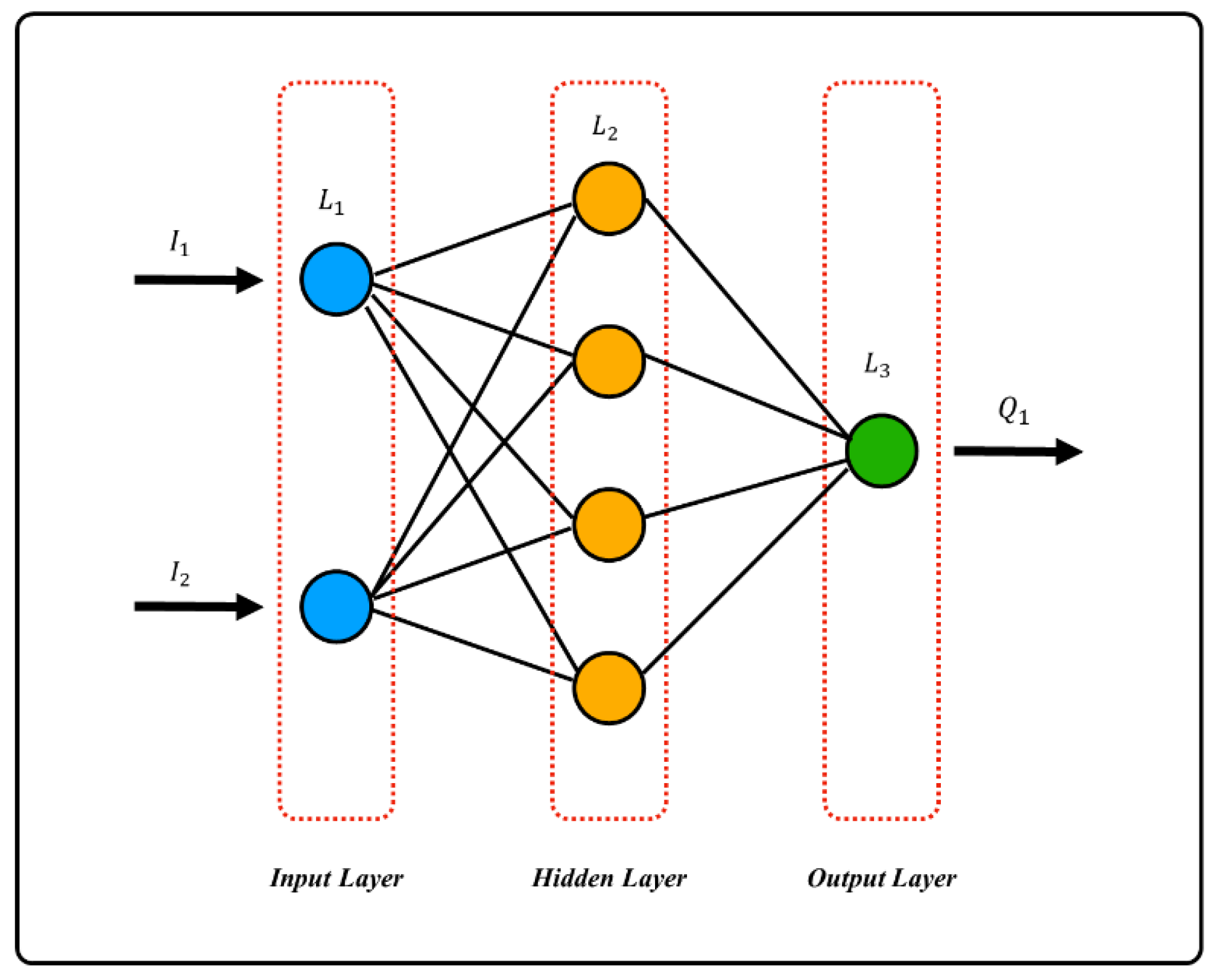
2.4. Neural Network
2.5. ReRAM Based Processing-In-Memory Architecture vs. Memristor-Based Neural Network Circuit of Associative Memory
3. Research Methodology
3.1. Search Strategies
3.2. Inclusion Criteria
3.3. Exclusion Criteria
3.4. Study Design
3.5. Assessment of Quality
3.6. Data Extraction
- Publication details: The names of the authors and publication year;
- Model: An overview of the novel model proposed in existing research;
- Method: The detailed steps and frameworks used for the models to setup experiments;
- Experiment results: Statistical output of each model for comparison and discussion on the effects; and
- Future work and challenges: The difficulties faced and flaws detected for future improvements.
3.7. Outcome
4. Recurrent Neural Network
4.1. ReRAM-Based System Architecture
4.2. PSB-RNN
5. Convolutional Neural Network
5.1. ReRAM Memory Wall Accelerator
5.2. CNN Accelerator Reusing Data at Multiple Levels
6. Generative Adversarial Network
6.1. ReRAM-Based Accelerator for Deconvolutional Computation
6.2. LerGAN
7. Sparse Neural Network
7.1. ReRAM-Based Accelerator for Sparse Neural Network
7.2. Sparse ReRAM Engine
8. Deep Neural Network
8.1. HitM: Multi-Modal Deep Neural Network Accelerator
8.2. Re2PIM: Reconfigurable ReRAM-based Deep Neural Network Accelerator
9. Faults in ReRAM Based Neural Networks
10. Research Trend
11. Conclusions and Future Studies
Author Contributions
Funding
Conflicts of Interest
References
- Moreau, M.; Muhr, E.; Bocquet, M.; Aziza, H.; Portal, J.-M.; Giraud, B.; Noel, J.-P. Reliable ReRAM-based Logic Operations for Computing in Memory. In Proceedings of the 2018 IFIP/IEEE International Conference on Very Large Scale Integration (VLSI-SoC), Verona, Italy, 8–10 October 2018; pp. 192–195. [Google Scholar] [CrossRef]
- Long, Y.; Na, T.; Mukhopadhyay, S. ReRAM-Based Processing-in-Memory Architecture for Recurrent Neural Network Acceleration. IEEE Trans. Very Large Scale Integr. (VLSI) Syst. 2018, 26, 2781–2794. [Google Scholar] [CrossRef]
- Vatwani, T.; Dutt, A.; Bhattacharjee, D.; Chattopadhyay, A. Floating Point Multiplication Mapping on ReRAM Based In-memory Computing Architecture. In Proceedings of the 2018 31st International Conference on VLSI Design and 2018 17th International Conference on Embedded Systems (VLSID), Pune, India, 6–10 January 2018; pp. 439–444. [Google Scholar] [CrossRef]
- Halawani, Y.; Mohammad, B.; Abu Lebdeh, M.; Al-Qutayri, M.; Al-Sarawi, S.F. ReRAM-Based In-Memory Computing for Search Engine and Neural Network Applications. IEEE J. Emerg. Sel. Top. Circuits Syst. 2019, 9, 388–397. [Google Scholar] [CrossRef]
- Mittal, S. A survey of architectural techniques for improving cache power efficiency. Sustain. Comput. Inform. Syst. 2014, 4, 33–43. [Google Scholar] [CrossRef] [Green Version]
- Soudry, D.; Di Castro, D.; Gal, A.; Kolodny, A.; Kvatinsky, S. Memristor-Based Multilayer Neural Networks with Online Gradient Descent Training. IEEE Trans. Neural Networks Learn. Syst. 2015, 26, 2408–2421. [Google Scholar] [CrossRef]
- Lin, J.; Zhu, Z.; Wang, Y.; Xie, Y. Learning the sparsity for ReRAM: Mapping and pruning sparse neural network for ReRAM based accelerator. In Proceedings of the 24th Asia and South Pacific Design Automation Conference, New York, NY, USA, 21–24 January 2019; pp. 639–644. [Google Scholar] [CrossRef]
- Li, B.; Wang, Y.; Chen, Y. HitM: High-Throughput ReRAM-based PIM for Multi-Modal Neural Networks. In Proceedings of the 2020 IEEE/ACM International Conference on Computer Aided Design (ICCAD), Online, 2–5 November 2020; pp. 1–7. [Google Scholar]
- Degraeve, R.; Fantini, A.; Raghavan, N.; Goux, L.; Clima, S.; Govoreanu, B.; Belmonte, A.; Linten, D.; Jurczak, M. Causes and consequences of the stochastic aspect of filamentary RRAM. Microelectron. Eng. 2015, 147, 171–175. [Google Scholar] [CrossRef]
- Xia, L.; Liu, M.; Ning, X.; Chakrabarty, K.; Wang, Y. Fault-Tolerant Training with On-Line Fault Detection for RRAM-Based Neural Computing Systems. IEEE Trans. Comput.-Aided Des. Integr. Circuits Syst. 2019, 38, 1611–1624. [Google Scholar] [CrossRef]
- Cheng, M.; Xia, L.; Zhu, Z.; Cai, Y.; Xie, Y.; Wang, Y.; Yang, H. TIME: A training-in-memory architecture for memristor-based deep neural networks. In Proceedings of the 54th Annual Design Automation Conference 2017, Austin, TX, USA, 18–22 June 2017; pp. 1–6. [Google Scholar] [CrossRef]
- Ghose, S.; Boroumand, A.; Kim, J.S.; Gomez-Luna, J.; Mutlu, O. Processing-in-memory: A workload-driven perspective. IBM J. Res. Dev. 2019, 63, 3:1–3:19. [Google Scholar] [CrossRef]
- Connolly, M. A Programmable Processing-in-Memory Architecture for Memory Intensive Applications; RIT Scholar Works; Rochester Institute of Technology: Rochester, NY, USA, 2021; Available online: https://scholarworks.rit.edu/theses/10736/ (accessed on 13 October 2021).
- Han, L.; Shen, Z.; Shao, Z.; Huang, H.H.; Li, T. A novel ReRAM-based processing-in-memory architecture for graph computing. In In Proceedings of the 2017 IEEE 6th Non-Volatile Memory Systems and Applications Symposium (NVMSA), Hsinchu, Taiwan, 16–18 August 2017; pp. 1–6. [Google Scholar] [CrossRef]
- Khan, K.; Pasricha, S.; Kim, R.G. A Survey of Resource Management for Processing-In-Memory and Near-Memory Processing Architectures. J. Low Power Electron. Appl. 2020, 10, 30. [Google Scholar] [CrossRef]
- Qi, Z.; Chen, W.; Naqvi, R.A.; Siddique, K. Designing Deep Learning Hardware Accelerator and Efficiency Evaluation. Comput. Intell. Neurosci. 2022, 2022, 1291103. [Google Scholar] [CrossRef]
- Ou, Q.-F.; Xiong, B.-S.; Yu, L.; Wen, J.; Wang, L.; Tong, Y. In-Memory Logic Operations and Neuromorphic Computing in Non-Volatile Random Access Memory. Materials 2020, 13, 3532. [Google Scholar] [CrossRef]
- Varshika, M.L.; Corradi, F.; Das, A. Nonvolatile Memories in Spiking Neural Network Architectures: Current and Emerging Trends. Electronics 2022, 11, 1610. [Google Scholar] [CrossRef]
- Banerjee, W. Challenges and Applications of Emerging Nonvolatile Memory Devices. Electronics 2020, 9, 1029. [Google Scholar] [CrossRef]
- Zahoor, F.; Zulkifli, T.Z.A.; Khanday, F.A. Resistive Random Access Memory (RRAM): An Overview of Materials, Switching Mechanism, Performance, Multilevel Cell (mlc) Storage, Modeling, and Applications. Nanoscale Res. Lett. 2020, 15, 90. [Google Scholar] [CrossRef]
- Gao, S.; Song, C.; Chen, C.; Zeng, F.; Pan, F. Dynamic Processes of Resistive Switching in Metallic Filament-Based Organic Memory Devices. J. Phys. Chem. C 2022, 116, 17955–17959. [Google Scholar] [CrossRef]
- Wu, Y.; Lee, B.; Wong, H.-S.P. Al2O3-Based RRAM Using Atomic Layer Deposition (ALD) With 1-μA RESET Current. IEEE Electron Device Lett. 2010, 31, 1449–1451. [Google Scholar] [CrossRef]
- Yang, L.; Kuegeler, C.; Szot, K.; Ruediger, A.; Waser, R. The influence of copper top electrodes on the resistive switching effect in TiO2 thin films studied by conductive atomic force microscopy. Appl. Phys. Lett. 2019, 95, 1611–1624. [Google Scholar] [CrossRef]
- Chiu, F.-C.; Li, P.-W.; Chang, W.-Y. Reliability characteristics and conduction mechanisms in resistive switching memory devices using ZnO thin films. Nanoscale Res. Lett. 2012, 7, 178. [Google Scholar] [CrossRef] [Green Version]
- Kumar, D.; Aluguri, R.; Chand, U.; Tseng, T.Y. Metal oxide resistive switching memory: Materials, properties and switching mechanisms. Ceram. Int. 2017, 43, S547–S556. [Google Scholar] [CrossRef]
- Strukov, D.B.; Snider, G.S.; Stewart, D.R.; Williams, R.S. The missing memristor found. Nature 2008, 453, 80–83. [Google Scholar] [CrossRef]
- Rabbani, P.; Dehghani, R.; Shahpari, N. A multilevel memristor–CMOS memory cell as a ReRAM. Microelectron. J. 2015, 46, 1283–1290. [Google Scholar] [CrossRef]
- Niu, D.; Xiao, Y.; Xie, Y. Low power memristor-based ReRAM design with Error Correcting Code. In Proceedings of the 17th Asia and South Pacific Design Automation Conference, Sydney, NSW, Australia, 30 January–2 February 2012; pp. 79–84. [Google Scholar] [CrossRef]
- Chua, L.O.; Kang, S.M. Memristive devices and systems. Proc. IEEE 1976, 64, 209–223. [Google Scholar] [CrossRef]
- Tedesco, J.L.; Stephey, L.; Hernandez-Mora, M.; Richter, C.A.; Gergel-Hackett, N. Switching mechanisms in flexible solution-processed TiO2 memristors. Nanotechnology 2012, 23, 305206. Available online: https://iopscience.iop.org/article/10.1088/0957-4484/23/30/305206/meta (accessed on 13 October 2021). [CrossRef] [PubMed]
- McDonald, N.R.; Pino, R.E.; Rozwood, P.J.; Wysocki, B.T. Analysis of dynamic linear and non-linear memristor device models for emerging neuromorphic computing hardware design. In Proceedings of the 2010 International Joint Conference on Neural Networks (IJCNN), Barcelona, Spain, 18–23 July 2010; pp. 1–5. [Google Scholar] [CrossRef] [Green Version]
- Shen, Z.; Zhao, C.; Qi, Y.; Xu, W.; Liu, Y.; Mitrovic, I.Z.; Yang, L.; Zhao, C. Advances of RRAM Devices: Resistive Switching Mechanisms, Materials and Bionic Synaptic Application. Nanomaterials 2020, 10, 1437. [Google Scholar] [CrossRef]
- Chi, P.; Li, S.; Xu, C.; Zhang, T.; Zhao, J.; Liu, Y.; Wang, Y.; Xie, Y. PRIME: A Novel Processing-in-Memory Architecture for Neural Network Computation in ReRAM-Based Main Memory. In Proceedings of the 2016 ACM/IEEE 43rd Annual International Symposium on Computer Architecture (ISCA), Seoul, Korea, 18–22 June 2016; pp. 27–39. [Google Scholar] [CrossRef]
- Qiu, K.; Jao, N.; Zhao, M.; Mishra, C.S.; Gudukbay, G.; Jose, S.; Sampson, J.; Kandemir, M.T.; Narayanan, V. ResiRCA: A Resilient Energy Harvesting ReRAM Crossbar-Based Accelerator for Intelligent Embedded Processors. In Proceedings of the 2020 IEEE International Symposium on High Performance Computer Architecture (HPCA), San Diego, CA, USA, 22–26 February 2020; pp. 315–327. [Google Scholar] [CrossRef]
- Babatunde, D.E.; Anozie, A.; Omoleye, J. Artificial Neural Network and Its Applications in The Energy Sector—An Overview. Int. J. Energy Econ. Policy 2020, 10, 250–264. [Google Scholar] [CrossRef]
- Benidis, K.; Rangapuram, S.S.; Flunkert, V.; Wang, B.; Maddix, D.; Turkmen, C.; Gasthaus, J.; Bohlke-Schneider, M.; Salinas, D.; Stella, L.; et al. Neural forecasting: Introduction and literature overview. arXiv 2020, arXiv:abs/2004.10240. [Google Scholar]
- Zhang, C.; Liu, Z. Application of big data technology in agricultural Internet of Things. Int. J. Distrib. Sens. Networks 2019, 15, 1550147719881610. [Google Scholar] [CrossRef]
- Nabavinejad, S.M.; Baharloo, M.; Chen, K.-C.; Palesi, M.; Kogel, T.; Ebrahimi, M. An Overview of Efficient Interconnection Networks for Deep Neural Network Accelerators. IEEE J. Emerg. Sel. Top. Circuits Syst. 2020, 10, 268–282. [Google Scholar] [CrossRef]
- Ji, Y.; Zhang, Y.; Xie, X.; Li, S.; Wang, P.; Hu, X.; Zhang, Y.; Xie, Y. FPSA: A Full System Stack Solution for Reconfigurable ReRAM-based NN Accelerator Architecture. In Proceedings of the Twenty-Fourth International Conference on Architectural Support for Programming Languages and Operating Systems, Association for Computing Machinery, New York, NY, USA, 13–17 April 2019; pp. 733–747. [Google Scholar] [CrossRef] [Green Version]
- Gale, E. TiO2-based Memristors and ReRAM: Materials, Mechanisms and Models. Semicond. Sci. Technol. 2014, 29, 104004. Available online: https://iopscience.iop.org/article/10.1088/0268-1242/29/10/104004/meta (accessed on 13 October 2021). [CrossRef] [Green Version]
- Hamdioui, S.; Taouil, M.; Haron, N.Z. Testing Open Defects in Memristor-Based Memories. IEEE Trans. Comput. 2015, 64, 247–259. [Google Scholar] [CrossRef]
- Kim, S.; Jeong, H.Y.; Kim, S.K.; Choi, S.-Y.; Lee, K.J. Flexible Memristive Memory Array on Plastic Substrates. Nano Lett. 2011, 11, 5438–5442. [Google Scholar] [CrossRef]
- Gale, E.; Pearson, D.; Kitson, S.; Adamatzky, A.; Costello, B.d.L. Aluminium electrodes effect the operation of titanium oxide sol-gel memristors. arXiv 2011, arXiv:1106.6293v2. [Google Scholar]
- Jo, S.H.; Chang, T.; Ebong, I.; Bhadviya, B.B.; Mazumder, P.; Lu, W. Nanoscale Memristor Device as Synapse in Neuromorphic Systems. Nano Lett. 2010, 10, 1297–1301. [Google Scholar] [CrossRef] [PubMed]
- Pan, C.; Hong, Q.; Wang, X. A Novel Memristive Chaotic Neuron Circuit and Its Application in Chaotic Neural Networks for Associative Memory. IEEE Trans. Comput. Des. Integr. Circuits Syst. 2021, 40, 521–532. [Google Scholar] [CrossRef]
- Sun, J.; Han, G.; Zeng, Z.; Wang, Y. Memristor-Based Neural Network Circuit of Full-Function Pavlov Associative Memory with Time Delay and Variable Learning Rate. IEEE Trans. Cybern. 2020, 50, 2935–2945. [Google Scholar] [CrossRef]
- Sun, J.; Han, J.; Liu, P.; Wang, Y. Memristor-based neural network circuit of pavlov associative memory with dual mode switching. AEU Int. J. Electron. Commun. 2021, 129, 153552. [Google Scholar] [CrossRef]
- Sun, J.; Han, J.; Wang, Y.; Liu, P. Memristor-Based Neural Network Circuit of Emotion Congruent Memory With Mental Fatigue and Emotion Inhibition. IEEE Trans. Biomed. Circuits Syst. 2021, 15, 606–616. [Google Scholar] [CrossRef]
- Sun, J.; Wang, Y.; Liu, P.; Wen, S.; Wang, Y. Memristor-Based Neural Network Circuit with Multimode Generalization and Differentiation on Pavlov Associative Memory. IEEE Trans. Cybern. 2022. [Google Scholar] [CrossRef]
- Long, Y.; Jung, E.M.; Kung, J.; Mukhopadhyay, S. ReRAM Crossbar based Recurrent Neural Network for human activity detection. In Proceeding of the 2016 International Joint Conference on Neural Networks (IJCNN), Vancouver, BC, Canada, 24–29 July 2016; pp. 939–946. [Google Scholar] [CrossRef]
- Challapalle, N.; Rampalli, S.; Chandran, M.; Kalsi, G.; Subramoney, S.; Sampson, J.; Narayanan, V. PSB-RNN: A Processing-in-Memory Systolic Array Architecture using Block Circulant Matrices for Recurrent Neural Networks. In Proceeding of the 2020 Design, Automation & Test in Europe Conference & Exhibition (DATE), Grenoble, France, 9–13 March 2020; pp. 180–185. [Google Scholar] [CrossRef]
- Luo, C.; Diao, J.; Chen, C. FullReuse: A Novel ReRAM-based CNN Accelerator Reusing Data in Multiple Levels. In Proceeding of the 2020 IEEE 5th International Conference on Integrated Circuits and Microsystems (ICICM), Nanjing, China, 23–25 October 2020; pp. 177–183. [Google Scholar] [CrossRef]
- Chen, Y.-H.; Krishna, T.; Emer, J.S.; Sze, V. Eyeriss: An Energy-Efficient Reconfigurable Accelerator for Deep Convolutional Neural Networks. IEEE J. Solid-state Circuits 2017, 52, 127–138. [Google Scholar] [CrossRef] [Green Version]
- Peng, X.; Liu, R.; Yu, S. Optimizing Weight Mapping and Data Flow for Convolutional Neural Networks on RRAM Based Processing-In-Memory Architecture. In Proceeding of the 2019 IEEE International Symposium on Circuits and Systems (ISCAS), Sapporo, Japan, 26–29 May 2019; pp. 1–5. [Google Scholar] [CrossRef]
- Li, Z.; Li, B.; Fan, Z.; Li, H. RED: A ReRAM-Based Efficient Accelerator for Deconvolutional Computation. IEEE Trans. Comput. Des. Integr. Circuits Syst. 2020, 39, 4736–4747. [Google Scholar] [CrossRef]
- Mao, H.; Song, M.; Li, T.; Dai, Y.; Shu, J. LerGAN: A Zero-Free, Low Data Movement and PIM-Based GAN Architecture. In Proceeding of the 2018 51st Annual IEEE/ACM International Symposium on Microarchitecture (MICRO), Fukuoka, Japan, 20–24 October 2018; pp. 669–681. [Google Scholar] [CrossRef]
- Bandaru, R. Pruning Neural Networks. Towards Data Science. 2 September 2020. Available online: https://towardsdatascience.com/pruning-neural-networks-1bb3ab5791f9#:~:text=Neural%20network%20pruning%20is%20a,removing%20unnecessary%20neurons%20or%20weights (accessed on 20 November 2021).
- Yang, T.-H.; Cheng, H.-Y.; Yang, C.-L.; Tseng, I.-C.; Hu, H.-W.; Chang, H.-S.; Li, H.-P. Sparse ReRAM Engine: Joint Exploration of Activation and Weight Sparsity in Compressed Neural Networks. In Proceedings of the 2019 ACM/IEEE 46th Annual International Symposium on Computer Architecture (ISCA), Phoenix, AZ, USA, 22–26 June 2016; pp. 236–249. [Google Scholar] [CrossRef]
- Shafiee, A.; Nag, A.; Muralimanohar, N.; Balasubramonian, R.; Strachan, J.P.; Hu, M.; Williams, R.S.; Srikumar, V. ISAAC: A Convolutional Neural Network Accelerator with In-Situ Analog Arithmetic in Crossbars. In Proceedings of the 2016 ACM/IEEE 43rd Annual International Symposium on Computer Architecture (ISCA), Seoul, Korea, 18–22 June 2016; pp. 14–26. [Google Scholar] [CrossRef]
- Bernardi, R.; Cakici, R.; Elliott, D.; Erdem, A.; Erdem, E.; Ikizler-Cinbis, N.; Keller, F.; Muscat, A.; Plank, B. Automatic description generation from images: A survey of models, datasets, and evaluation measures. J. Artif. Intell. Res. 2016, 55, 409–442. Available online: https://dl.acm.or (accessed on 13 October 2021). [CrossRef] [Green Version]
- Chou, T.; Tang, W.; Botimer, J.; Zhang, Z. CASCADE: Connecting RRAMs to Extend Analog Dataflow in An End-To-End In-Memory Processing Paradigm. In Proceedings of the 52nd Annual IEEE/ACM International Symposium on Microarchitecture, Columbus, OH, USA, 12–16 October 2019; pp. 114–125. [Google Scholar] [CrossRef]
- Li, W.; Xu, P.; Zhao, Y.; Li, H.; Xie, Y.; Lin, Y. TIMELY: Pushing Data Movements and Interfaces in PIM Accelerators towards Local and in Time Domain. In Proceedings of the ACM/IEEE 47th Annual International Symposium on Computer Architecture, Online, 30 May–3 June 2020; pp. 832–845. [Google Scholar] [CrossRef]
- Zhao, Y.; He, Z.; Jing, N.; Liang, X.; Jiang, L. Re2PIM: A Reconfigurable ReRAM-Based PIM Design for Variable-Sized Vector-Matrix Multiplication. In Proceedings of the 2021 on Great Lakes Symposium on VLSI, Online, 22–25 June 2021; pp. 15–20. [Google Scholar] [CrossRef]
- Li, W.; Wang, Y.; Li, H.; Li, X. RRAMedy: Protecting ReRAM-Based Neural Network from Permanent and Soft Faults During Its Lifetime. In Proceedings of the 2019 IEEE 37th International Conference on Computer Design (ICCD), Abu Dhabi, Unite Arab Emirates, 17–20 November 2019; pp. 91–99. [Google Scholar] [CrossRef]
- Chen, C.-Y.; Shih, H.-C.; Wu, C.-W.; Lin, C.-H.; Chiu, P.-F.; Sheu, S.-S.; Chen, F.T. RRAM Defect Modeling and Failure Analysis Based on March Test and a Novel Squeeze-Search Scheme. IEEE Trans. Comput. 2015, 64, 180–190. [Google Scholar] [CrossRef]
- Tosson, A.M.; Yu, S.; Anis, M.H.; Wei, L. Analysis of RRAM Reliability Soft-Errors on the Performance of RRAM-Based Neuromorphic Systems. In Proceedings of the 2017 IEEE Computer Society Annual Symposium on VLSI (ISVLSI), Bochum, Germay, 3–5 July 2017; pp. 62–67. [Google Scholar] [CrossRef]
- Li, G.; Hari, S.K.S.; Sullivan, M.; Tsai, T.; Pattabiraman, K.; Emer, J.; Keckler, S.W. Understanding Error Propagation in Deep Learning Neural Network (DNN) Accelerators and Applications. In Proceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis, Denver, CO, USA, 12–17 November 2017; pp. 1–12. [Google Scholar] [CrossRef]
- Song, L.; Qian, X.; Li, H.; Chen, Y. PipeLayer: A Pipelined ReRAM-Based Accelerator for Deep Learning. In Proceedings of the 2017 IEEE International Symposium on High Performance Computer Architecture (HPCA), Austin, TX, USA, 4–8 February 2017; pp. 541–552. [Google Scholar] [CrossRef]
- Chen, F.; Song, L.; Chen, Y. ReGAN: A pipelined ReRAM-based accelerator for generative adversarial networks. In Proceedings of the 2018 23rd Asia and South Pacific Design Automation Conference (ASP-DAC), Jeju Island, Korea, 22–25 January 2018; pp. 178–183. [Google Scholar] [CrossRef]
- Lou, Q.; Wen, W.; Jiang, L. 3DICT: A Reliable and QoS Capable Mobile Process-In-Memory Architecture for Lookup-based CNNs in 3D XPoint ReRAMs. In Proceedings of the 2018 IEEE/ACM International Conference on Computer-Aided Design (ICCAD), San Diego, CA, SUA, 5–8 November 2018; pp. 1–8. [Google Scholar] [CrossRef]
- Chen, F.; Song, L.; Li, H. Efficient process-in-Memory architecture design for unsupervised GAN-based deep learning using ReRAM. In Proceedings of the 2019 on Great Lakes Symposium on VLSI, Tysons Corner, VA, USA, 9–11 May 2019; pp. 423–428. [Google Scholar] [CrossRef]
- He, Y.; Wang, Y.; Wang, Y.; Li, H.; Li, X. An Agile Precision-Tunable CNN Accelerator based on ReRAM. In Proceedings of the 2019 IEEE/ACM International Conference on Computer-Aided Design (ICCAD), Westminster, CO, USA, 4–7 November 2019; pp. 1–7. [Google Scholar] [CrossRef]
- She, X.; Long, Y.; Mukhopadhyay, S. Improving robustness of reram-based spiking neural network accelerator with stochastic spike-timing-dependent-plasticity. In Proceedings of the 2019 International Joint Conference on Neural Networks (IJCNN), Budapest, Hungary, 14–19 July 2019. [Google Scholar] [CrossRef] [Green Version]
- Li, B.; Doppa, J.R.; Pande, P.P.; Chakrabarty, K.; Qiu, J.X.; Li, H. 3D-ReG: A 3D ReRAM-based Heterogeneous Architecture for Training Deep Neural Networks. ACM J. Emerg. Technol. Comput. Syst. 2020, 16, 1–24. [Google Scholar] [CrossRef] [Green Version]
- Zheng, Q.; Wang, Z.; Feng, Z.; Yan, B.; Cai, Y.; Huang, R.; Chen, Y.; Yang, C.-L.; Li, H.H. Lattice: An ADC/DAC-less ReRAM-based Processing-In-Memory Architecture for Accelerating Deep Convolution Neural Networks. In Proceedings of the 2020 57th ACM/IEEE Design Automation Conference (DAC), Online, 20–24 June 2020; pp. 1–6. [Google Scholar] [CrossRef]
- Han, J.; Liu, H.; Wang, M.; Li, Z.; Zhang, Y. ERA-LSTM: An Efficient ReRAM-Based Architecture for Long Short-Term Memory. IEEE Trans. Parallel Distrib. Syst. 2020, 31, 1328–1342. [Google Scholar] [CrossRef]
- Chu, C.; Chen, F.; Xu, D.; Wang, Y. RECOIN: A Low-Power Processing-in-ReRAM Architecture for Deformable Convolution. In Proceedings of the 2021 on Great Lakes Symposium on VLSI, Online, 22–25 June 2021; pp. 235–240. [Google Scholar] [CrossRef]
- Mittal, S. A Survey of ReRAM-Based Architectures for Processing-In-Memory and Neural Networks. Mach. Learn. Knowl. Extr. 2019, 1, 5. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Memory Technology | ReRAM | DRAM | SRAM | PCM | STTRAM | Flash (NAND) | HDD |
|---|---|---|---|---|---|---|---|
| Energy per bit (pJ) | 2.7 | ~0.05 | ~0.0005 | 2–25 | 0.1–2.5 | ~0.00002 | |
| Read time (ns) | 5 | ~10 | ~1 | 50 | 10–35 | ||
| Write time (ns) | 5 | ~10 | ~1 | 10 | 10–90 | ||
| Retention time | ~64 ms | - | |||||
| Voltage (V) | 1 | <1 | <1 | 1.5 | <2 | <10 | <10 |
| Endurance (circle) |
| No | Citation | NN Type | Architecture Summary |
|---|---|---|---|
| 1 | [2] | RNN | ReRAM-based PIM RNN accelerator whereby the processing engine was divided into three subarrays for different functions, and a lower bit-precision number was utilized to enhance computing efficiency. |
| 2 | [7] | Sparse NN | Sparse NN mapping approach using k-means clustering and pruning algorithm to minimize low utilization crossbars with minimal impact on accuracy. |
| 3 | [8] | Multimodal-DNN | HitM: Combined NN accelerator model of CNN and RNN by extracting layer-wise information and determining optimized throughput. |
| 4 | [33] | MLP and CNN | PRIME: PIM-based architecture using ReRAM crossbar arrays that be configured as the accelerator, with an input and synapse composing scheme. |
| 5 | [51] | RNN | PSB-RNN: ReRAM crossbar-based PIM RNN accelerator with systolic dataflow encompassing block circulant compression. This approach has reduced unnecessary space and complexity computation. |
| 6 | [52] | CNN | FullReuse: CNN accelerator that aims for maximum utilization of data reusability, including input data, output data and weights. |
| 7 | [55] | GAN and FCN | RED: ReRAM-based approach with pixel-wise mapping scheme and zero-skipping data flow for deconvolutional computation. This approach has solved the massive zero insertion and maximizes the reuse of input data. |
| 8 | [56] | GAN | LerGAN: PIM-based architecture with zero-free data reshaping scheme and ReRAM-based reconfigurable 3D interconnection. |
| 9 | [58] | Sparse NN | Spare ReRAM Engine (SRE) exploiting sparsity in weight and activation in fine-grained operational unit computations. |
| 10 | [61] | CNN/DNN | TIMELY: ReRAM-based PIM accelerators addressing the bottlenecks of the high energy cost of data movement and ADC/DAC processes. This approach adopts analoe local buggers, time-domain interfaces and an only-once input read mapping scheme. |
| 11 | [62] | DNN | Re2PIM: DNN accelerator using ReRAM with a reconfigurable size of computing units (CUs) known as reconfigurable units. This design is able to adapt to in-memory computing designs with variably sized matrix vector multiplication. |
| 12 | [68] | CNN | PipeLayer: ReRAM-based PIM accelerator that aims to support deep learning applications. Improved pipelined architecture contributed to enabling the continuous flow of data in consecutive cycles. Spike-based data scheme was used to eliminate overhead of DAC/ADC. |
| 13 | [69] | GAN | ReGAN: ReRAM-based PIM GAN accelerator with spatial parallelism and computation sharing. This approach reduces memory accesses and increases system throughput with layered computation. |
| 14 | [70] | CNN | 3DICT: Mobile PIM accelerator that is capable of quality of service (QoS), including high accuracy, low latency and low energy consumption. |
| 15 | [71] | GAN | ReRAM-based PIM GAN accelerator with a novel computation deformation technique that completely eliminates zero-insertion. Spatial parallelism and computation sharing has been proposed to improve the training efficiency. |
| 16 | [72] | CNN | ReRAM-based network processing unit and training method with mixed precision. This scheme enables low power edge CNN with instant precision tuning. |
| 17 | [73] | Spiking NN | A robust ReRAM-based PIM spiking NN accelerator with frequency-dependent stochastic spike-timing-dependent-plasticity (STDP), which achieved better accuracy under noisy input conditions. |
| 18 | [74] | DNN | 3D-ReG: ReRAM-based PIM architecture and Graphics Processing Unit (GPU) with three-dimensional integration. This design exploits the diversity of 3D-ReG to determine the optimal balance between efficiency and accuracy. |
| 19 | [75] | DCNN | Deep Convolutional NN (DCNN) accelerator by avoiding expensive ADC and DAC processes. This is done by moving the computation of network layers to a CMOS peripheral circuit. |
| 20 | [76] | RNN | ERA-LSTM: Tiled ReRAM-based PIM with an elaborate mapping scheme that enables the concatenation of tiles for large-scale long short-term memory (LSTM) and inter-tile pipeline. This approach supports LSTM pruning method and saves half of the ReRAM crossbar overhead. |
| 21 | [77] | DCN | RECOIN: Deformable Convolution Network (DCN) with low power ReRAM-based PIM architecture by addressing irregular DCN data access. In addition, the authorsproposed a bilinear interpolation (BLI) processing engine to avoid high write latency. |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, W.; Qi, Z.; Akhtar, Z.; Siddique, K. Resistive-RAM-Based In-Memory Computing for Neural Network: A Review. Electronics 2022, 11, 3667. https://doi.org/10.3390/electronics11223667
Chen W, Qi Z, Akhtar Z, Siddique K. Resistive-RAM-Based In-Memory Computing for Neural Network: A Review. Electronics. 2022; 11(22):3667. https://doi.org/10.3390/electronics11223667
Chicago/Turabian StyleChen, Weijian, Zhi Qi, Zahid Akhtar, and Kamran Siddique. 2022. "Resistive-RAM-Based In-Memory Computing for Neural Network: A Review" Electronics 11, no. 22: 3667. https://doi.org/10.3390/electronics11223667