On the whole, our work is mainly divided into two parts. First, for the FGVC task, to extract more detailed image features, we designed a multilevel feature fusion module to improve the ViT. Second, we designed a data enhancement method called RAMix to enhance the network capability.
3.1. Algorithm Framework
Figure 1 shows the algorithm framework, which follows ViT and includes patch embedding, a Transformer encoder, a multilevel feature fusion module, classification head components, and data augmentation.
The patch embedding module blocks and transforms the image, and embeds the class token and position. The backbone network is consistent with ViT, and includes 12 layers of Transformer blocks for basic feature extraction. A lightweight feature fusion module, MFF, further improves the expressiveness of features. Through parallel classification heads, the final classification is obtained from the weighted average method of three classifications.
In the model training stage, starting from the data, referring to ResizeMix [
21] and TransMix [
19], RAMix is based on Resize for image cropping and pasting, and a Transformer-based attention mechanism is used for label assignment.
3.2. Backbone and MFF
The key challenge of FGVC is to detect discriminative regions that significantly contribute to finding subtle differences between subordinate classes, which can be well met for the multi-head self-attention MSA mechanism in ViT. Deep MSA pays more attention to global information, while FGVC tasks require more attention to detail. Therefore, we propose multilevel feature fusion to ensure the use of high-level global information while obtaining mid- and low-level information. The backbone network and multilevel feature fusion module are the core parts of the algorithm and are, respectively, shown in the left and right of
Figure 2.
The backbone network is consistent with the original ViT. We use a division method similar to Swin Transformer [
13] to divide the 12-layer Transformer block into stages 1–4. Stages 1, 2, and 4 have two blocks, and stage 3 has six blocks. The output of each stage contains certain feature information, which is effective and complementary, and the fused features have stronger expressiveness.
The Transformer block is the basic unit of the backbone network.
Figure 3 shows the structure of two Transformer blocks connected in series.
A Transformer block includes multi-head self-attention (
), multilayer perceptron (
), and layer normalization (
). The forward propagation of layer
l is calculated as
and multi-head self-attention is calculated as
where
Q,
K, and
V refer to the query, key, and value, respectively;
refers to the key vector dimension;
refers to parameters when performing linear transformations on
Q,
K, and
V; and
h is the number of heads. The
Concat operation concatenates the outputs of multiple heads.
Feature fusion combines features from different layers or branches, and often fuses features of different scales to improve the deep learning performance. In the network architecture, low-level features have a higher resolution and more detailed information, and high-level features have stronger semantic information but a poorer perception of details [
16]. Their efficient integration is the key to improving the classification model.
After the basic features are extracted from the backbone network, a lightweight feature fusion method is adopted. A consult feature pyramid (FPN) [
29,
30] in CNN, top-down pathways, and horizontal connections are added to the network structure. As shown on the right side of
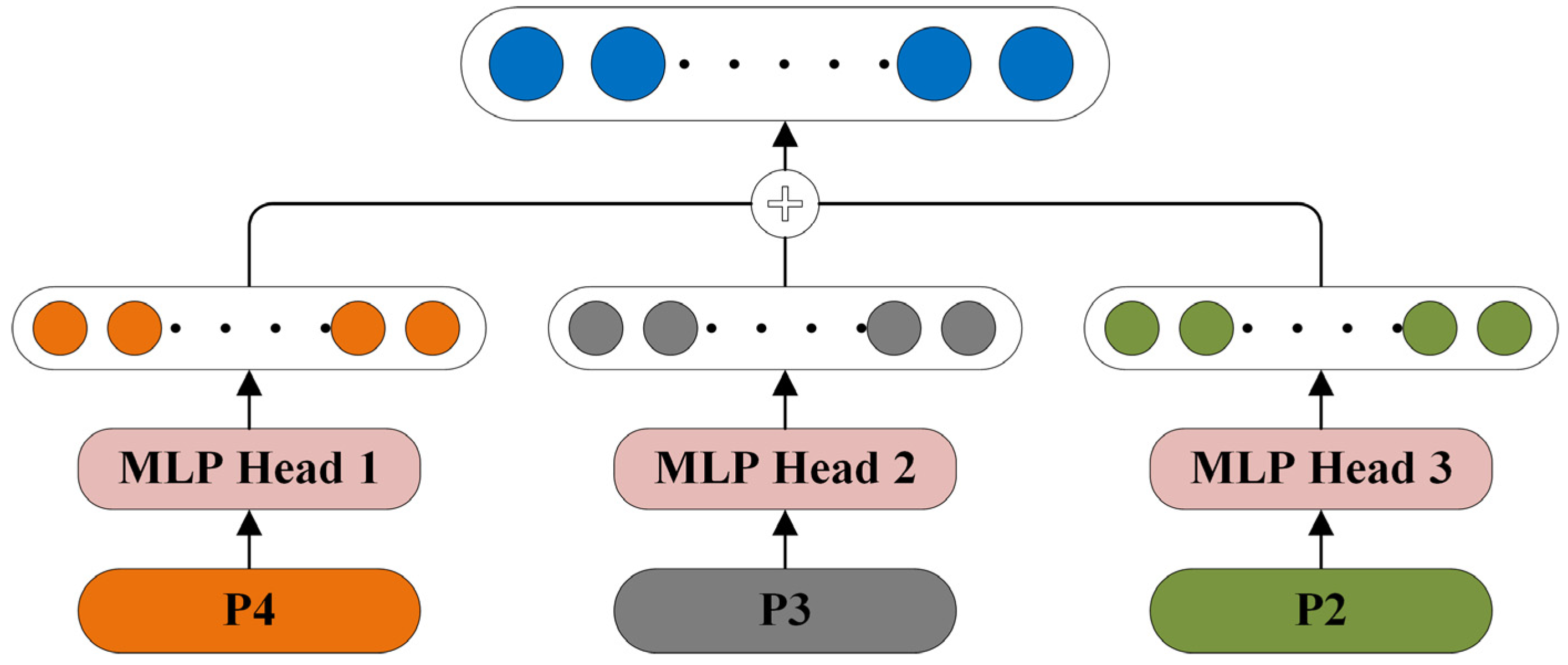
Figure 2, the last features of stages 4 and 3 are fused. We use three features for classification from different layers: P4 is the output of stage 4, P3 is obtained by fusing the output of stage 3 and P4, and P2 is obtained by fusing the output of stage 2 and P3.
3.3. Classification Head and Loss Function
The detection performance can be improved by combining the detection results of different layers. Before the final fusion is completed, detection starts on the partially fused layer; there will be multiple layers of detection, and the multiple detection results are finally fused.
Instead of using the output features of the last layer for classification prediction, we use multilevel features and fuse the classification prediction results to obtain the final prediction. As shown in
Figure 4, we use three classification heads for classification prediction, and each classification head consists of a fully connected layer.
We obtained three different levels of features from MFF; we use three classification heads to classify the three levels of features. Classification heads 1, 2, and 3 were classified using features P4, P3, and P2, respectively, and the final classification result was obtained by averaging the three classification results.
We use soft target cross-entropy as the loss function in each classification head,
where
is the number of samples,
is the number of categories,
represents the input label,
represents the prediction label,
is the loss function of
, and
h takes values from 1 to 3.
To adjust the influence of the classification results of different levels on the final classification, the overall loss function is the weighted average of three loss functions,
where
,
, and
are weight parameters.
3.4. RAMix Data Augmentation
The Transformer has great expressive power, but, according to the experiments of ViT and DeiT [
17], the network needs a large quantity of data for model training. Hence, data augmentation is an important part of model training, which can prevent overfitting and improve model performance. We use CutMix data augmentation in the FGVC task, but the random crop and paste operation adds no usefulness to the target image when the cropped area is in the background, without object information. However, when labels are calculated, they will be allocated according to the size ratio of the mixed images, resulting in the loss of object information and label allocation errors. This has a greater impact on the use of small datasets for training in the FGVC task. We design RAMix to address this problem, as
Figure 5 shows.
In the training set, images A and B are randomly selected, and and y are used to represent the training image and its label, respectively. The goal is to generate a new training sample () by combining training samples () and ().
Image A is randomly cropped to through the crop value and is reduced to a small image block by the scale ratio and the resize operation, i.e., , where represents the reduction operation, , which means that is evenly distributed between min and max, and denotes the minimum and maximum of the image block . To ensure that the image block contains as many objects as possible, and the objects are not too small to be distinguished, we set 0.7, = 0.25, and = 1. This means that the minimum image block is a quarter of the size of the input image, and the maximum of the is the same as the input image size.
Image block
is pasted onto a random area
of image B to generate a new image.
where
is a binary mask representing location
. Since scale ratios and paste regions are obtained randomly, this mixing operation adds little cost.
The last step is to assign labels. Due to the different sizes of pasting areas, the occlusion of the target in the original image will be different, as should the assignment of labels, so we have improved the label assignment. We utilize the attention map A instead of the size of the paste region to compute the mixing weight
λ. Labels
and
of images A and B, respectively, are mixed according to
λ to obtain the label of the mixed image,
The calculation of
λ is guided by the attention map
A and calculates the weights that mix the labels of the two sample images,
where
is the attention map from the class token to the image patch tokens, summarizing which patches are most useful to the final classifier.
denotes nearest-neighbor interpolation down-sampling to transform the original M from HW to
p pixels. In this way, the network can learn to dynamically reassign the weights of labels for each data point based on their responses in the attention map. An input that is better focused by the attention map will be assigned a higher value in the mixed label.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}