
Deletion-Based Tangle Architecture for Edge Computing


Abstract
:1. Introduction
- Instant deletions on the finite lifetime data;
- Guaranteed deletion of the unknown lifetime data based on the delete request;
- Storage utilization on managing finite lifetime data.
2. Related Work
3. Background and Motivations
3.1. Blockchain
3.2. Direct Acyclic Graph
- Each new transaction must verify two old transactions.
- Transactions are confirmed after getting verifications.
- By joining the IOTA network, everyone can verify and write transactions, instead of relying on other nodes.
- IOTA offers storage-utilized membership, whereby nodes are not forced to copy the full database.
3.3. Data Deletions
- Arrival time ordering maintains the physical order of the blocks and follows the blockchain protocol.
- Expiration time ordering locates the blocks by expiring time and enables the deletion from the last in the chain.
3.4. Motivations
4. D-Tangle Architecture
- New data arrives with a specific expiration time.
- Based on the expiration time, the coordinator node saves the data using climb-up write technique.
- While writing the new transaction, the coordinator node checks the lifetimes of old transactions and performs deletion on expired ones.
4.1. Data Deletions
- Finite—the nodes whose expiration time is provided upon insertion.
- Immutable—the nodes with no expiration time that need to be saved forever.
- Unknown—the nodes with an unspecified expiration time that may or may not expire.
4.2. Climp-up Write Technique
- Unverified nodes have the highest priority according to creation order.
- Expired nodes should be eliminated from Tangle.
- New nodes verify only if the old node has a longer expiration time.
| Algorithm 1. Climb-up write technique | |
| |
4.3. Theoretical Anaylsis
- Write efficiency. The implementation of the climb-up write technique may seem to stall the traditional write mechanism in terms of deleting consideration. However, this does not considerably affect the performance. In a distributed system, the delay is predominantly caused by network communication and waiting for the response during propagation. In the D-Tangle case, the climb-up write technique operates only on the coordinator node and runs several extra logics compared with traditional logic. Delete operations are confirmed by consensus, similarly to writing new data. Therefore, there is no considerable delay in the write mechanism to maintain traditional verification performance.
- Delete efficiency. Deletions can be categorized in two ways as follows: finite data and unknown data deletions. Considering the climb-up write technique, the finite data is automatically sorted such that the first to delete nodes is invariably saved as leaves. Therefore, deletions in finite data can be performed instantly. However, unknown data can be validated by finite data, irrespective of the expiration time. If a delete request occurs, the unknown data are expected to wait until the child node expires. Estimating the possible delay for unknown lifetime data is unlikely. However, this possibility can be estimated depending on the workload configuration. Considering the workload of none or full unknown data, the latency is expected to decrease because the unknown data do not validate each other. Therefore, the worst performance could occur in the mixed (half finite, half unknown) workloads, wherein the validation occurs for each unknown datum. In this case, the latency is fully dependent on the expiration time of the finite data.
- Storage efficiency. Another important factor for distributed storage reliability is efficiency. Remarkably, the traditional Tangle is an efficiency-friendly architecture that implements partial copies. To maintain the same scenario, the following architecture should also be storage efficient in implementation: when enabling deletions, the meaning of the storage efficiency changes; then, efficiency refers to how fast used storage can be freed up after requesting data deletions. Considering the unpredictable case of unknown lifetime data, storage may be allocated for slightly longer than expected during deletions. However, D-Tangle eventually guarantees deletion. Therefore, storage is also freed. Considering that the traditional approach forces the allocation of storage forever, freeing up after a delay seems much more efficient in real-life applications.
5. Evaluations
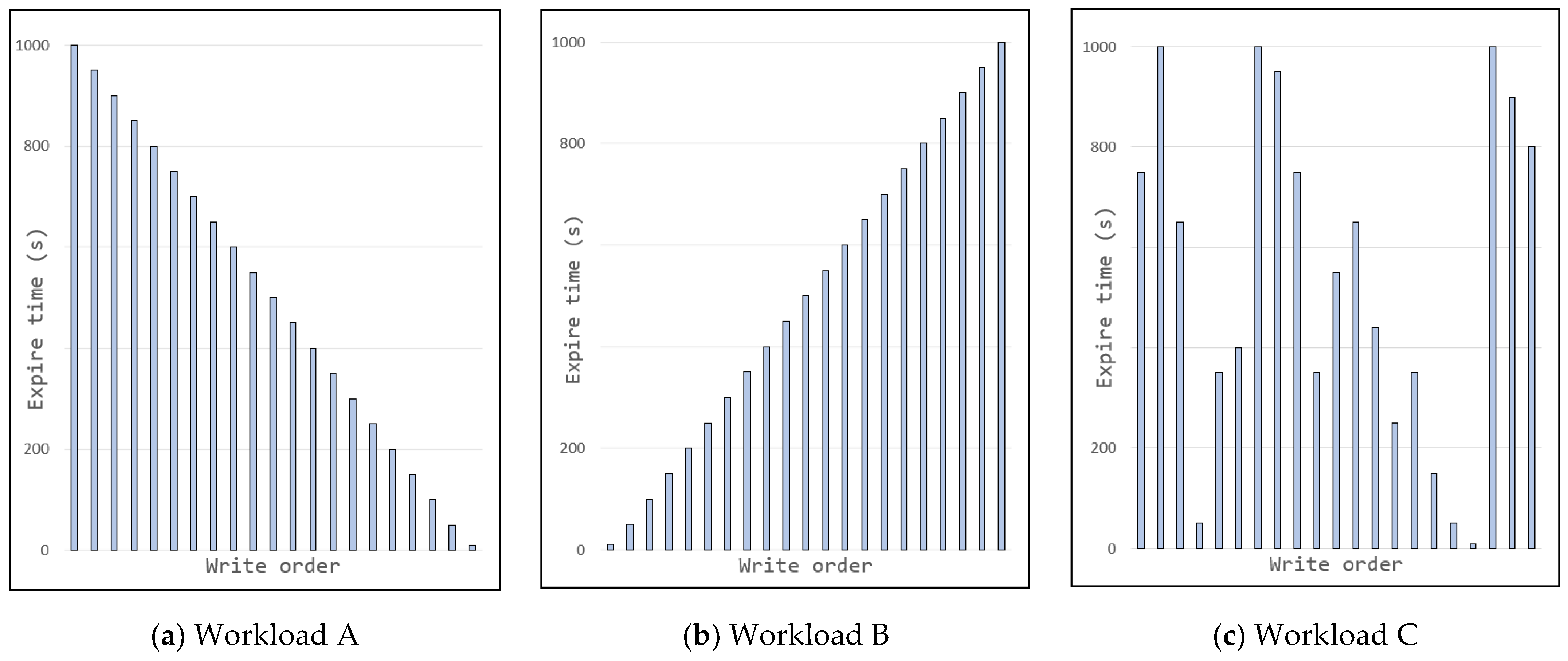
5.1. Environment Setup
5.2. Evaluation Results
5.3. Storage Cost
5.4. Comparison
5.5. Write Performance
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Wang, H.; Zheng, Z.; Xie, S.; Dai, H.-N.; Chen, X. Blockchain challenges and opportunities: A survey. Int. J. Web Grid Serv. 2018, 14, 352–375. [Google Scholar] [CrossRef]
- Monrat, A.A.; Schelén, O.; Andersson, K. A Survey of Blockchain from the Perspectives of Applications, Challenges, and Opportunities. IEEE Access 2019, 7, 117134–117151. [Google Scholar] [CrossRef]
- Eyal, I. Blockchain Technology: Transforming Libertarian Cryptocurrency Dreams to Finance and Banking Realities. Computer 2017, 50, 38–49. [Google Scholar] [CrossRef]
- Nakomoto, S. Bitcoin: A Peer-to-Peer Electronic Cash System. 2008. Available online: http:/bitcoin.org/bitcoin.pdf (accessed on 18 October 2022).
- Bach, L.M.; Mihaljevic, B.; Zagar, M. Comparative analysis of blockchain consensus algorithms. In Proceedings of the 41st International Convention on Information and Communication Technology, Electronics and Microelectronics (MIPRO), Opatija, Croatia, 21–25 May 2018; pp. 1545–1550. [Google Scholar] [CrossRef]
- Tulkinbekov, K.; Kim, D.H. CaseDB: Lightweight Key-Value Store for Edge Computing Environment. IEEE Access 2020, 8, 149775–149786. [Google Scholar] [CrossRef]
- Dutta, P.; Choi, T.-M.; Somani, S.; Butala, R. Blockchain technology in supply chain operations: Applications, challenges and research opportunities. Transp. Res. Part E Logist. Transp. Rev. 2020, 142, 102067. [Google Scholar] [CrossRef]
- Kim, J.-S.; Shin, N. The Impact of Blockchain Technology Application on Supply Chain Partnership and Performance. Sustainability 2019, 11, 6181. [Google Scholar] [CrossRef] [Green Version]
- Wang, Y.; Huirong Chen, C.; Zghari-Sales, A. Designing a blockchain enabled supply chain. Int. J. Prod. Res. 2021, 59, 1450–1475. [Google Scholar] [CrossRef]
- Park, J.H.; Park, J.H. Blockchain Security in Cloud Computing: Use Cases, Challenges, and Solutions. Symmetry 2017, 9, 164. [Google Scholar] [CrossRef] [Green Version]
- Awadallah, R.; Samsudin, A.; The, J.S.; Almazrooie, M. An Integrated Architecture for Maintaining Security in Cloud Computing Based on Blockchain. IEEE Access 2021, 9, 69513–69526. [Google Scholar] [CrossRef]
- Agbo, C.C.; Mahmoud, Q.H.; Eklund, J.M. Blockchain Technology in Healthcare: A Systematic Review. Healthcare 2019, 7, 56. [Google Scholar] [CrossRef] [Green Version]
- Hölbl, M.; Kompara, M.; Kamišalić, A.; Nemec Zlatolas, L. A Systematic Review of the Use of Blockchain in Healthcare. Symmetry 2018, 10, 470. [Google Scholar] [CrossRef] [Green Version]
- Mettler, M. Blockchain technology in healthcare: The revolution starts here. In Proceedings of the IEEE 18th International Conference on e-Health Networking, Applications and Services (Healthcom), Munich, Germany, 14–16 September 2016; pp. 1–3. [Google Scholar] [CrossRef]
- Tulkinbekov, K.; Kim, D.-H. Blockchain-enabled Approach for Big Data Processing in Edge Computing. IEEE Internet Things J. 2022, 9, 18473–18486. [Google Scholar] [CrossRef]
- He, Y.; Wang, Y.; Qiu, C.; Lin, Q.; Li, J.; Ming, Z. Blockchain-Based Edge Computing Resource Allocation in IoT: A Deep Reinforcement Learning Approach. IEEE Internet Things J. 2021, 8, 2226–2237. [Google Scholar] [CrossRef]
- Guo, S.; Dai, Y.; Guo, S.; Qiu, X.; Qi, F. Blockchain Meets Edge Computing: Stackelberg Game and Double Auction Based Task Offloading for Mobile Blockchain. IEEE Trans. Veh. Technol. 2020, 69, 5549–5561. [Google Scholar] [CrossRef]
- Marjani, M. Big IoT Data Analytics: Architecture, Opportunities, and Open Research Challenges. IEEE Access 2017, 5, 5247–5261. [Google Scholar] [CrossRef]
- Dennis, R.; Owenson, G.; Aziz, B. A Temporal Blockchain: A Formal Analysis. In Proceedings of the 2016 International Conference on Collaboration Technologies and Systems (CTS), Orlando, FL, USA, 31 October–4 November 2016; pp. 430–437. [Google Scholar] [CrossRef] [Green Version]
- El Khanboubi, Y.; Hanoune, M.; El Ghazouani, M. A New Data Deletion Scheme for a Blockchain-based De-duplication System in the Cloud. Int. J. Commun. Netw. Inf. Secur. IJCNIS 2021, 13, 331–339. [Google Scholar] [CrossRef]
- Zhu, Q.; Kouhizadeh, M. Blockchain Technology, Supply Chain Information, and Strategic Product Deletion Management. IEEE Eng. Manag. Rev. 2019, 47, 36–44. [Google Scholar] [CrossRef]
- Li, C.; Hu, J.; Zhou, K.; Wang, Y.; Deng, H. Using Blockchain for Data Auditing in Cloud Storage. In Proceedings of the International Conference on Cloud Computing and Security—ICCCS, Haikou, China, 8–10 June 2018; Sun, X., Pan, Z., Bertino, E., Eds.; Lecture Notes in Computer Science (LNISA). Springer: Cham, Switzerland, 2018; Volume 11065. [Google Scholar] [CrossRef]
- Yang, C.; Chen, X.; Xiang, Y. Blockchain-based publicly verifiable data deletion scheme for cloud storage. J. Netw. Comput. Appl. 2018, 103, 185–193. [Google Scholar] [CrossRef]
- Politou, E.; Casino, F.; Alepis, E.; Patsakis, C. Blockchain Mutability: Challenges and Proposed Solutions. IEEE Trans. Emerg. Top. Comput. 2021, 9, 1972–1986. [Google Scholar] [CrossRef] [Green Version]
- Kuperberg, M. Towards Enabling Deletion in Append-Only Blockchains to Support Data Growth Management and GDPR Compliance. In Proceedings of the IEEE International Conference on Blockchain (Blockchain), Rhodes, Greece, 2–6 November 2020; pp. 393–400. [Google Scholar] [CrossRef]
- Buterin, V. A Next-Generation Smart Contract and Decentralized Application Platform. Whitepaper. 2014. Available online: https://ethereum.org/en/whitepaper/ (accessed on 18 October 2022).
- IOTA Research Papers. Available online: https://www.iota.org/foundation/research-papers (accessed on 18 October 2022).
- Benčić, F.M.; Podnar Žarko, I. Distributed Ledger Technology: Blockchain Compared to Directed Acyclic Graph. In Proceedings of the 2018 IEEE 38th International Conference on Distributed Computing Systems (ICDCS), Vienna, Austria, 2–6 July 2018; pp. 1569–1570. [Google Scholar] [CrossRef] [Green Version]
- Pyoung, C.K.; Baek, S.J. Blockchain of Finite-Lifetime Blocks with Applications to Edge-Based IoT. IEEE Internet Things J. 2020, 7, 2102–2116. [Google Scholar] [CrossRef]
- Hillmann, P.; Knüpfer, M.; Heiland, E.; Karcher, A. Selective Deletion in a Blockchain. In Proceedings of the 2020 IEEE 40th International Conference on Distributed Computing Systems (ICDCS), Singapore, 29 November–1 December 2020; pp. 1249–1256. [Google Scholar] [CrossRef]
- Guo, F.; Xiao, X.; Hecker, A.; Dustdar, S. Characterizing IOTA Tangle with Empirical Data. In Proceedings of the GLOBECOM 2020—2020 IEEE Global Communications Conference, Taipei, Taiwan, 7–11 December 2020; pp. 1–6. [Google Scholar] [CrossRef]
- Bu, G.; Gürcan, Ö.; Potop-Butucaru, M. G-IOTA: Fair and confidence aware tangle. In Proceedings of the IEEE INFOCOM 2019—IEEE Conference on Computer Communications Workshops (INFOCOM WKSHPS), Paris, France, 29 April–2 May 2019; pp. 644–649. [Google Scholar] [CrossRef] [Green Version]
- Bhandary, M.; Parmar, M.; Ambawade, D. A Blockchain Solution based on Directed Acyclic Graph for IoT Data Security using IoTA Tangle. In Proceedings of the 2020 5th International Conference on Communication and Electronics Systems (ICCES), Coimbatore, India, 10–12 June 2020; pp. 827–832. [Google Scholar] [CrossRef]
- Shabandri, B.; Maheshwari, P. Enhancing IoT Security and Privacy Using Distributed Ledgers with IOTA and the Tangle. In Proceedings of the 2019 6th International Conference on Signal Processing and Integrated Networks (SPIN), Noida, India, 7–8 March 2019; pp. 1069–1075. [Google Scholar] [CrossRef]
- Gangwani, P.; Perez-Pons, A.; Bhardwaj, T.; Upadhyay, H.; Joshi, S.; Lagos, L. Securing Environmental IoT Data Using Masked Authentication Messaging Protocol in a DAG-Based Blockchain: IOTA Tangle. Future Internet 2021, 13, 312. [Google Scholar] [CrossRef]
- Mukhopadhyay, U.; Skjellum, A.; Hambolu, O.; Oakley, J.; Yu, L.; Brooks, R. A brief survey of Cryptocurrency systems. In Proceedings of the 2016 14th Annual Conference on Privacy, Security and Trust (PST), Auckland, New Zealand, 12–14 December 2016; pp. 745–752. [Google Scholar] [CrossRef]
- Polygon Whitepaper, Ethereum’s Internet of Blockchains. Available online: https://polygon.technology/lightpaper-polygon.pdf (accessed on 18 October 2022).
- Chia Business Whitepaper. Available online: https://www.chia.net/whitepaper/ (accessed on 18 October 2022).
- Yekovenko, A. Solana: A New Architecture for a High Performance Blockchain v0.8.13. Available online: https://solana.com/solana-whitepaper.pdf (accessed on 18 October 2022).
- Donet Donet, J.A.; Pérez-Solà, C.; Herrera-Joancomartí, J. The Bitcoin P2P Network. In Proceedings of the International Conference on Financial Cryptography and Data Security—FC 2014, Christ Church, Barbados, 7 March 2014; Böhme, R., Brenner, M., Moore, T., Smith, M., Eds.; Lecture Notes in Computer Science (LNSC). Springer: Berlin/Heidelberg, Germany, 2014; Volume 8438. [Google Scholar] [CrossRef]
- Nvidia Developer Website. Available online: https://developer.nvidia.com/embedded/jetson-agx-xavier-developer-kit (accessed on 18 October 2022).









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Type | Name | CPU | DRAM | Storage |
|---|---|---|---|---|
| Coordinator | Amazon EC2 (i3en.xlarge) | 4 vCPUs, 2.5 GHz | 32 GB | 5 TB |
| Full node | PC | 8 AMD Ryzen 7 1700 CPUs 3.0GHz | 16 GB | 3 TB |
| Local server | 2 Intel Core i5 CPUs, 3.3GHz | 8 GB | 3 TB | |
| Partial node | Jetson AGX Xavier embedded board | 4 ARMv8 Processors | 16 GB | 1 TB |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tulkinbekov, K.; Kim, D.-H. Deletion-Based Tangle Architecture for Edge Computing. Electronics 2022, 11, 3488. https://doi.org/10.3390/electronics11213488
Tulkinbekov K, Kim D-H. Deletion-Based Tangle Architecture for Edge Computing. Electronics. 2022; 11(21):3488. https://doi.org/10.3390/electronics11213488
Chicago/Turabian StyleTulkinbekov, Khikmatullo, and Deok-Hwan Kim. 2022. "Deletion-Based Tangle Architecture for Edge Computing" Electronics 11, no. 21: 3488. https://doi.org/10.3390/electronics11213488