
Hardware Acceleration and Implementation of YOLOX-s for On-Orbit FPGA



Abstract
:1. Introduction
- Based on a detailed analysis of the YOLOX-s model, an efficient, low-latency, and reliable parallel processing architecture is proposed, which is fully compatible with YOLOX-s, YOLOX-l, and YOLOX-Darknet53 in the YOLOX family.
- The main modules in YOLOX are designed, and the core convolution module is further optimized. Meanwhile, the design strategy of a three-path prefetch cache queue is proposed to maximize the reuse pattern of on-chip data, relieve the bandwidth bottleneck of the external DDR in the multi-level cache, ensure the efficient operation of the DSP array, and improve the overall inference performance. The peak performance can reach 408.4 GOPS under the condition of a guaranteed detection accuracy.
- The design strategy of multi-layer small-scale cascade computing is adopted for the core pooling module and the three-path cache queue design reusing mode. In this way, the consumption of resources is reduced, and the logic timing is optimized.
- The real-time processing performance of the architecture was simulated and verified, and it was comprehensively analyzed from all aspects. Meanwhile, the related work of other FPGA-accelerated YOLO series networks was taken for comparison and analysis, which provides new research directions for the following research work.
2. Architecture Design and Module Implementation
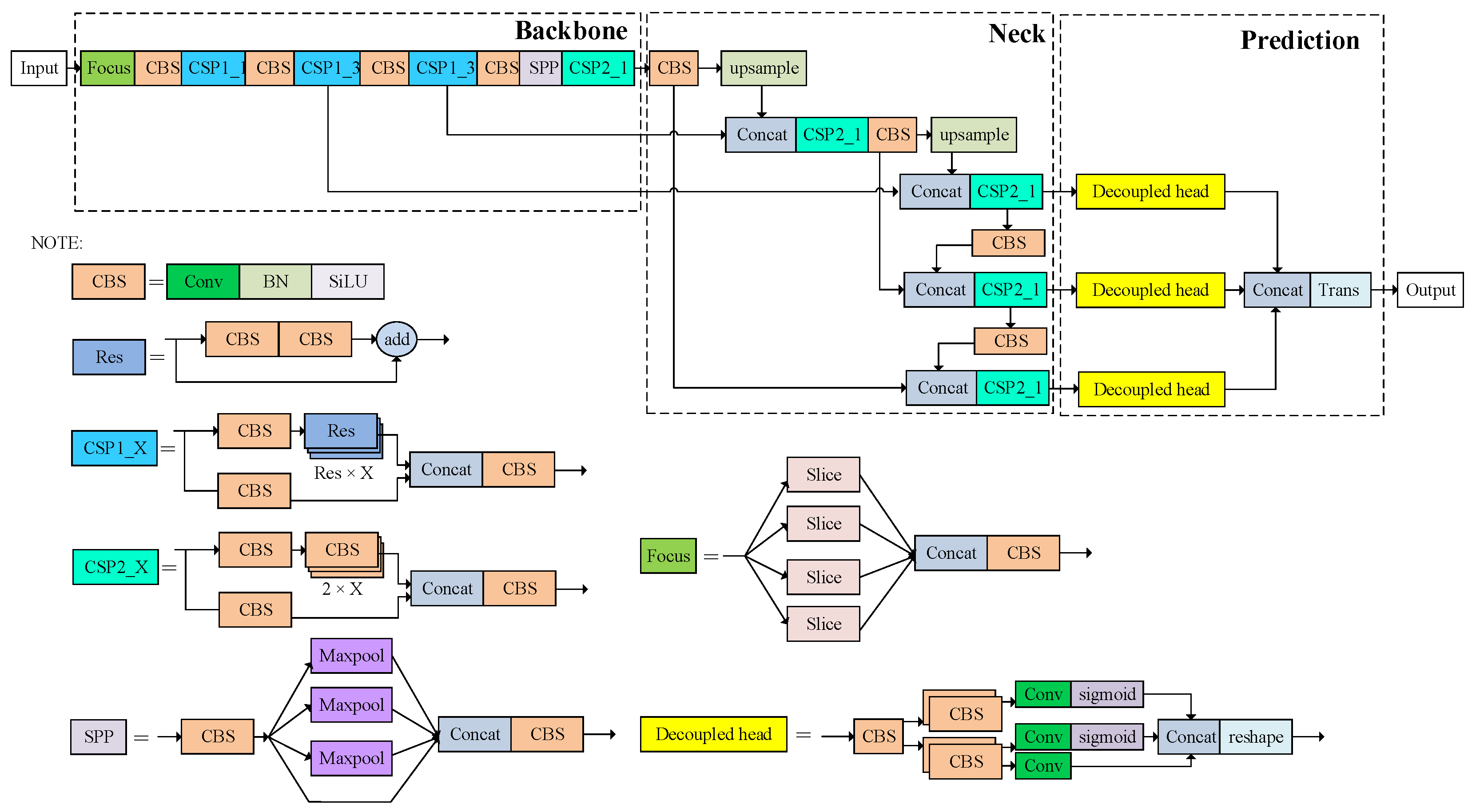
2.1. Analysis of YOLOX-s
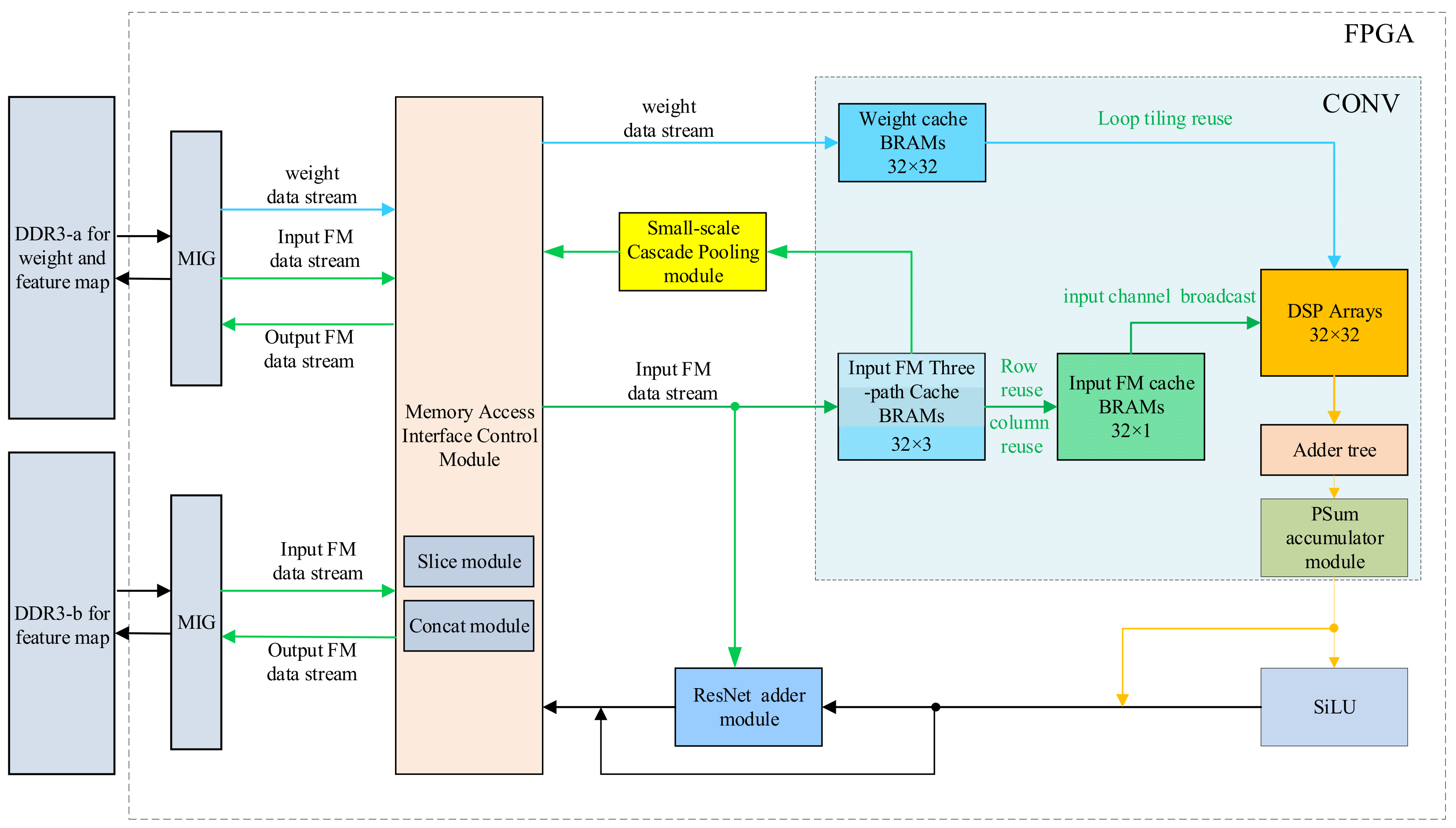
2.2. The Overall Architecture Design
2.3. Design of Convolution Module
- 5.
- In the conditions allowed by the FPGA on-chip computing resources, according to the structural characteristics of the YOLOX-s, the strategy of multi-dimensional parallel loop unrolling is selected to build the largest parallel computing array and optimize the logic timing, thus improving the processing performance of the accelerator.
- 6.
- In the conditions allowed by the on-chip cache resources of the FPGA, the three-path cache queue design is proposed by adopting the strategy of maximizing on-chip cache data reuse. This overcomes the bandwidth bottleneck caused by the external DDR3 in the multi-level cache structure, thereby guaranteeing the computational efficiency of the DSP array. Meanwhile, the number of accesses to external storage is reduced as much as possible to reduce the hardware power consumption.
- 7.
- In the conditions allowed by the on-chip cache resources of the FPGA, an optimization strategy is adopted to minimize the partial sum cache. Combined with the three-path cache queue, data partitioning, and loop sequence optimization, the cache pressure of the data input queue and output partial sum is balanced, which further ensures the efficient calculation of the DSP array.
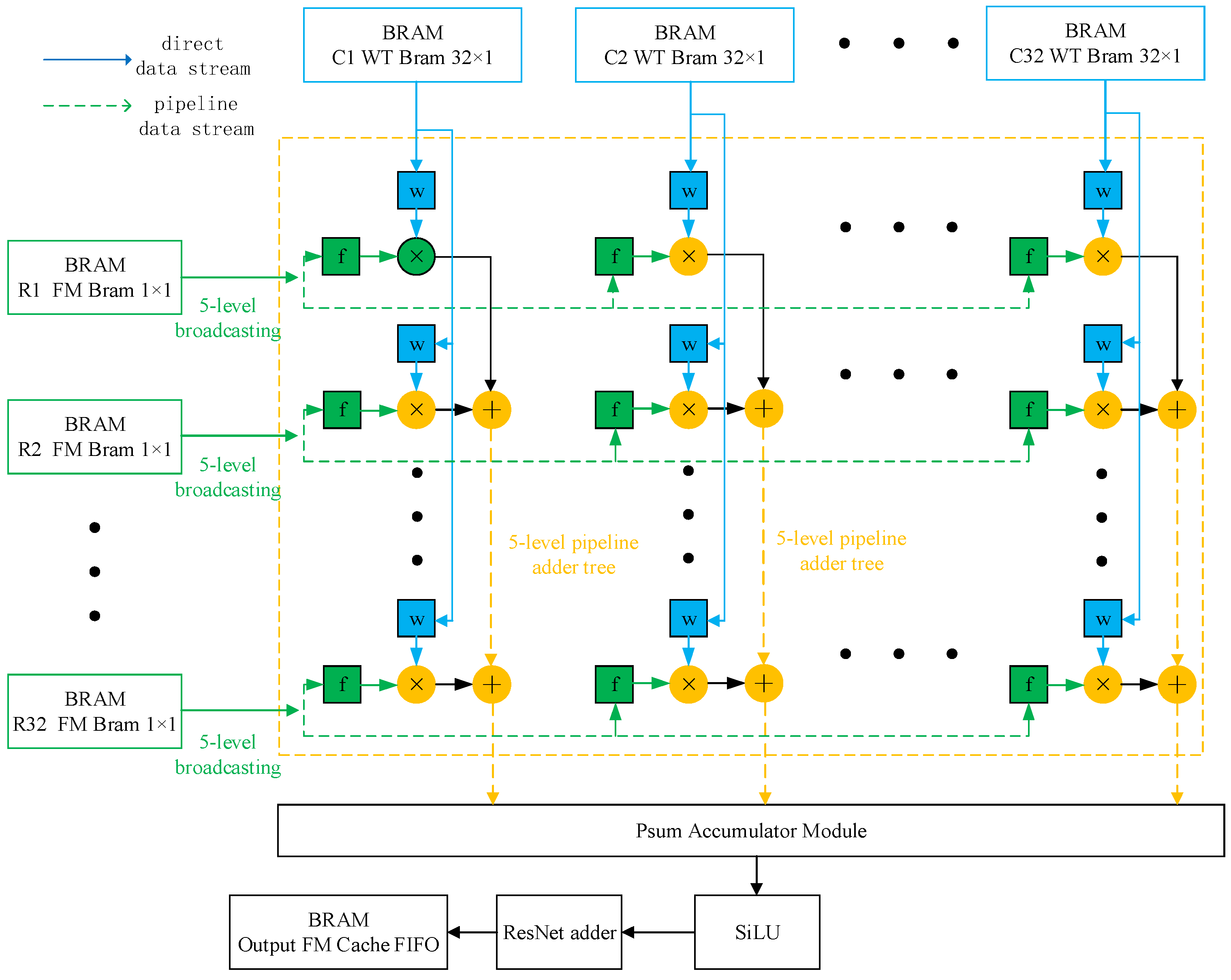
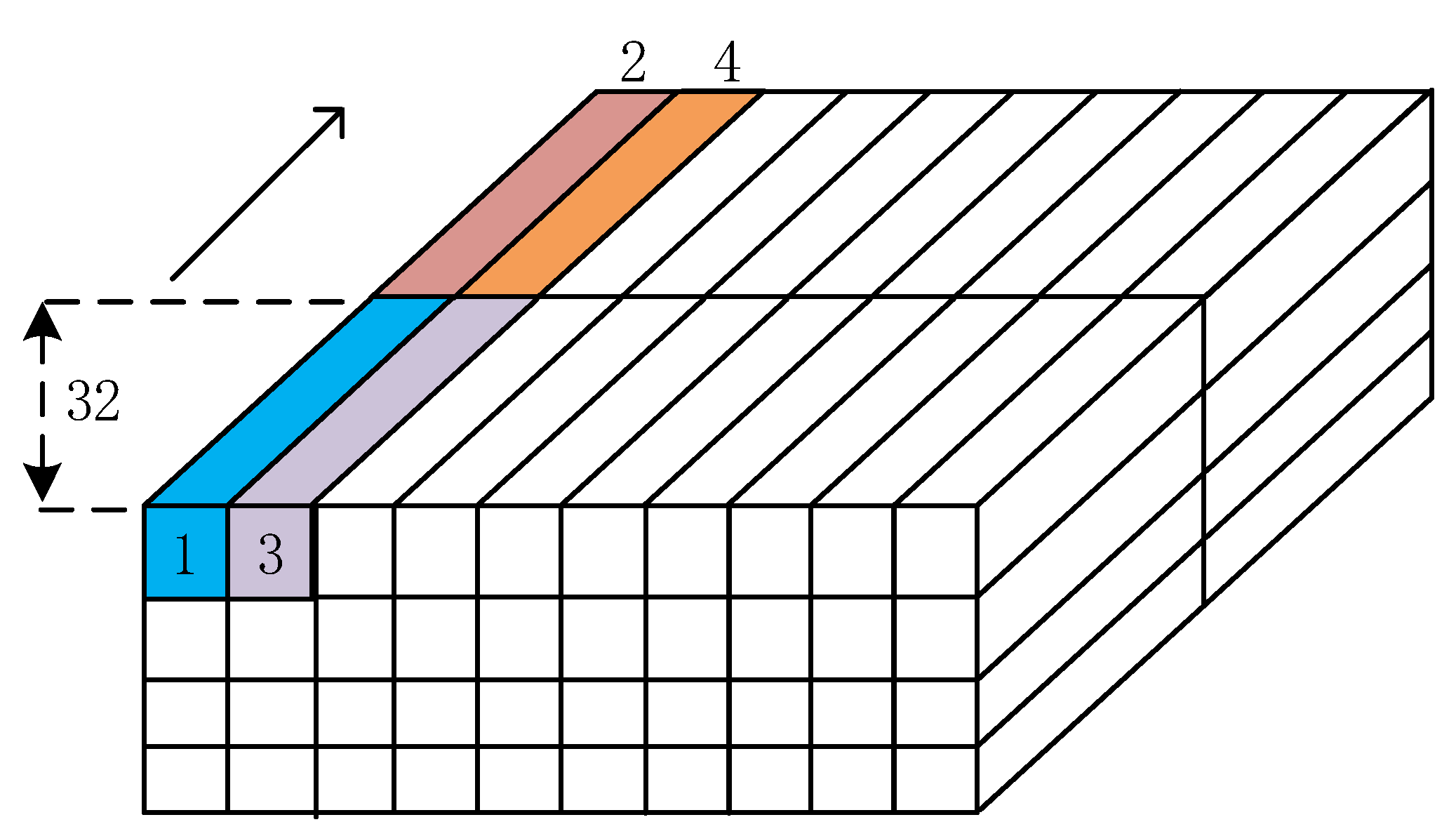
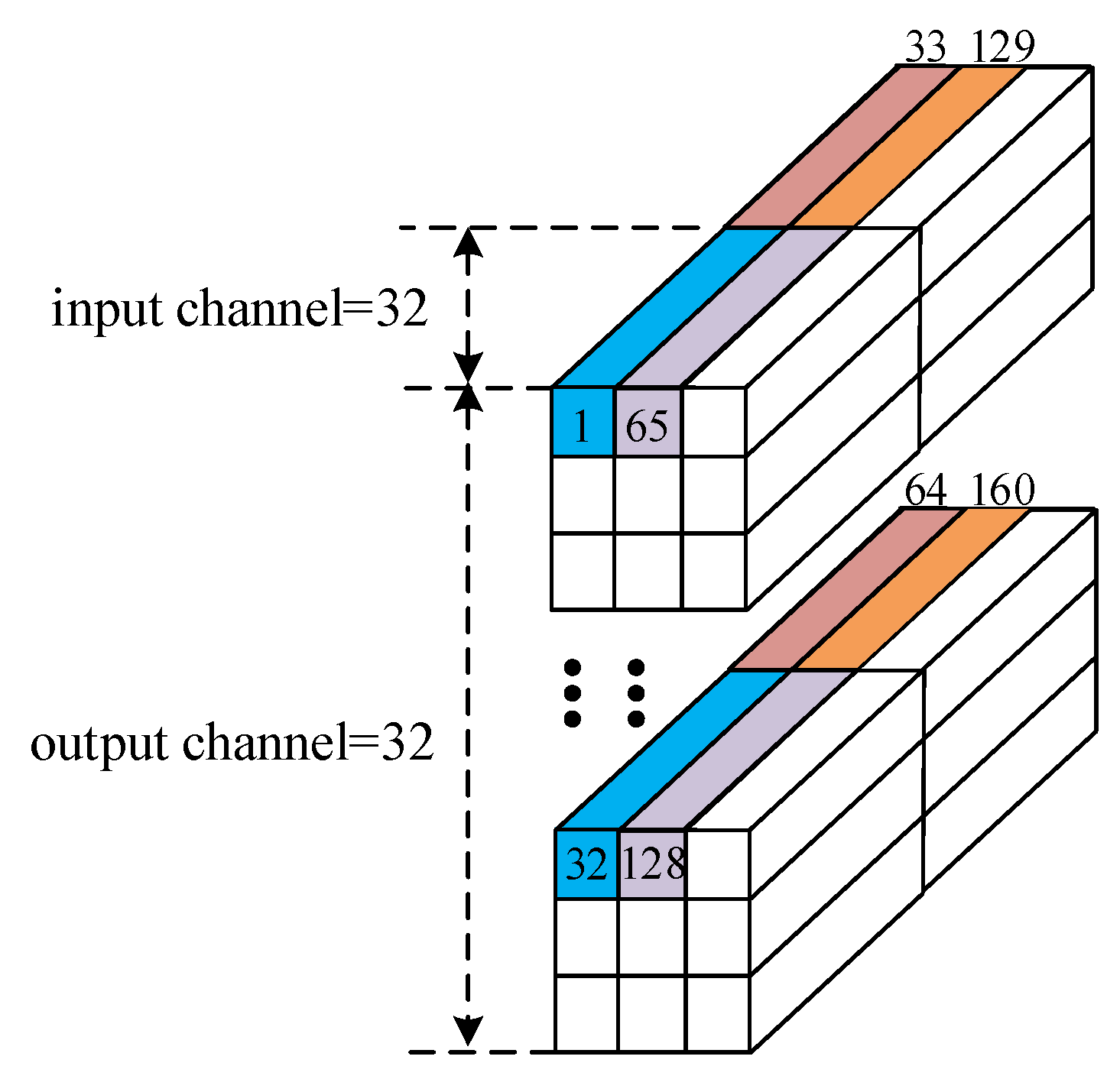
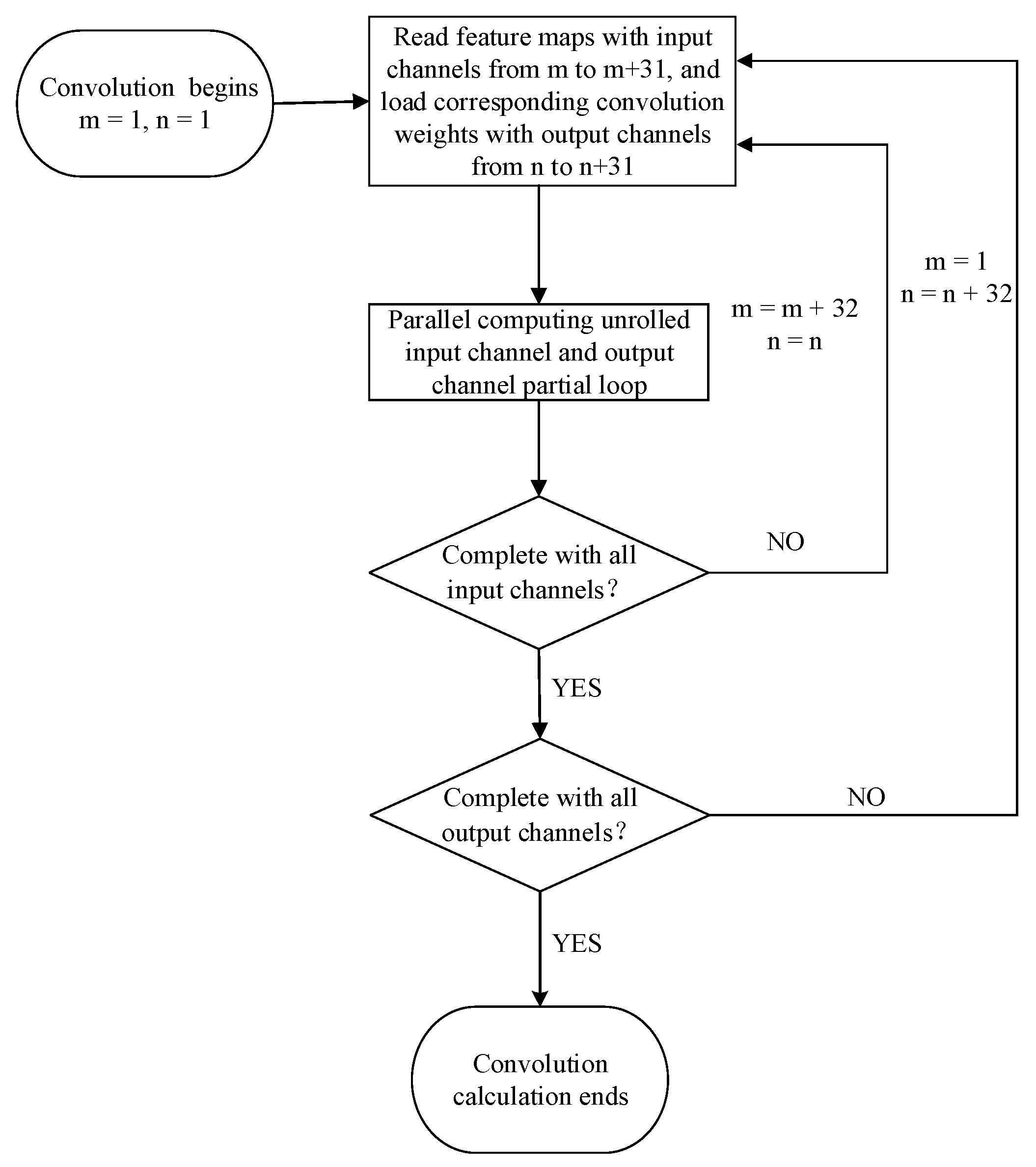
2.3.1. Design of Parallel Loop Unrolling
2.3.2. Convolution Computation Array Architecture
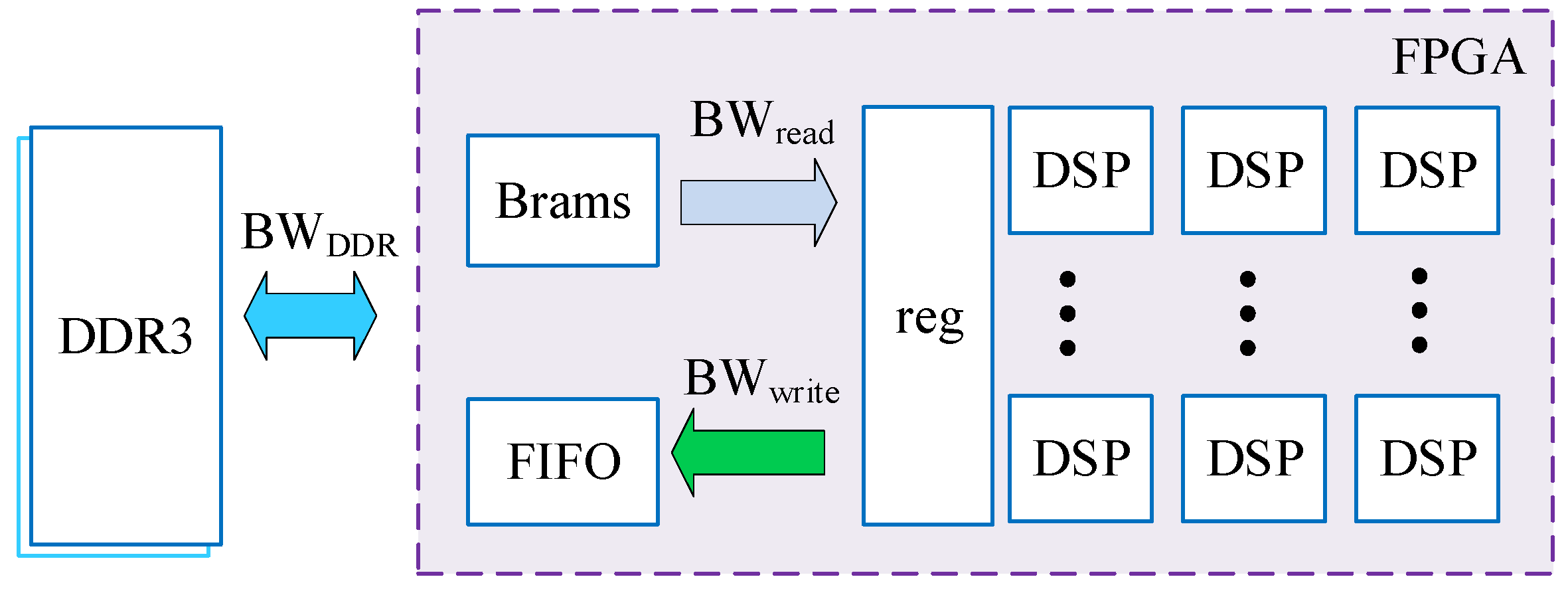
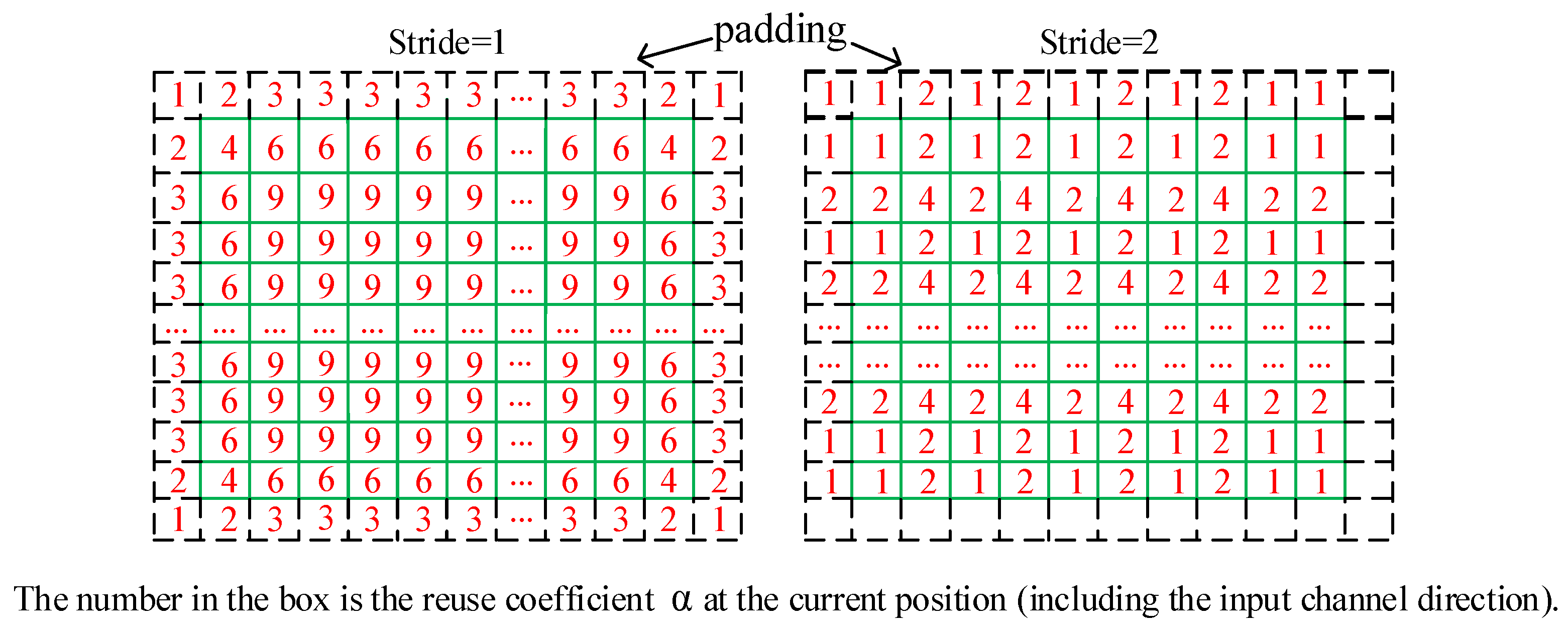
2.3.3. Multi-Level Cache and Bandwidth Analysis
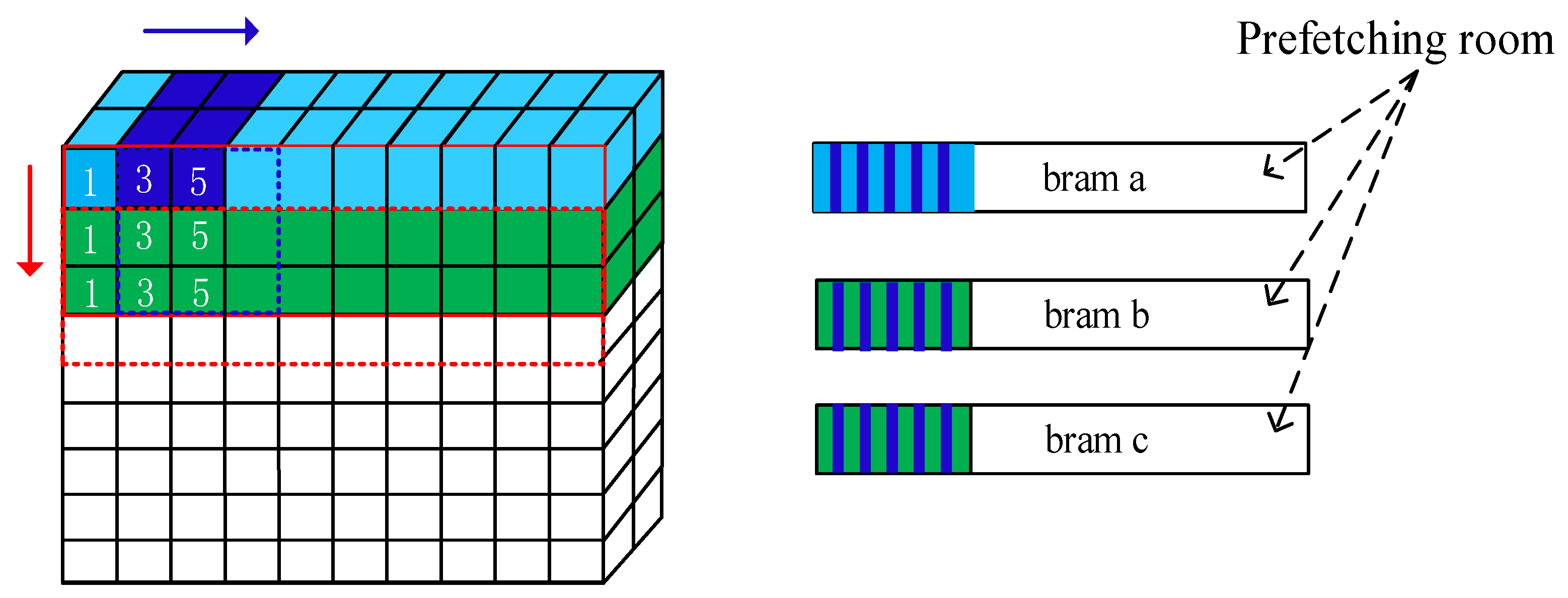
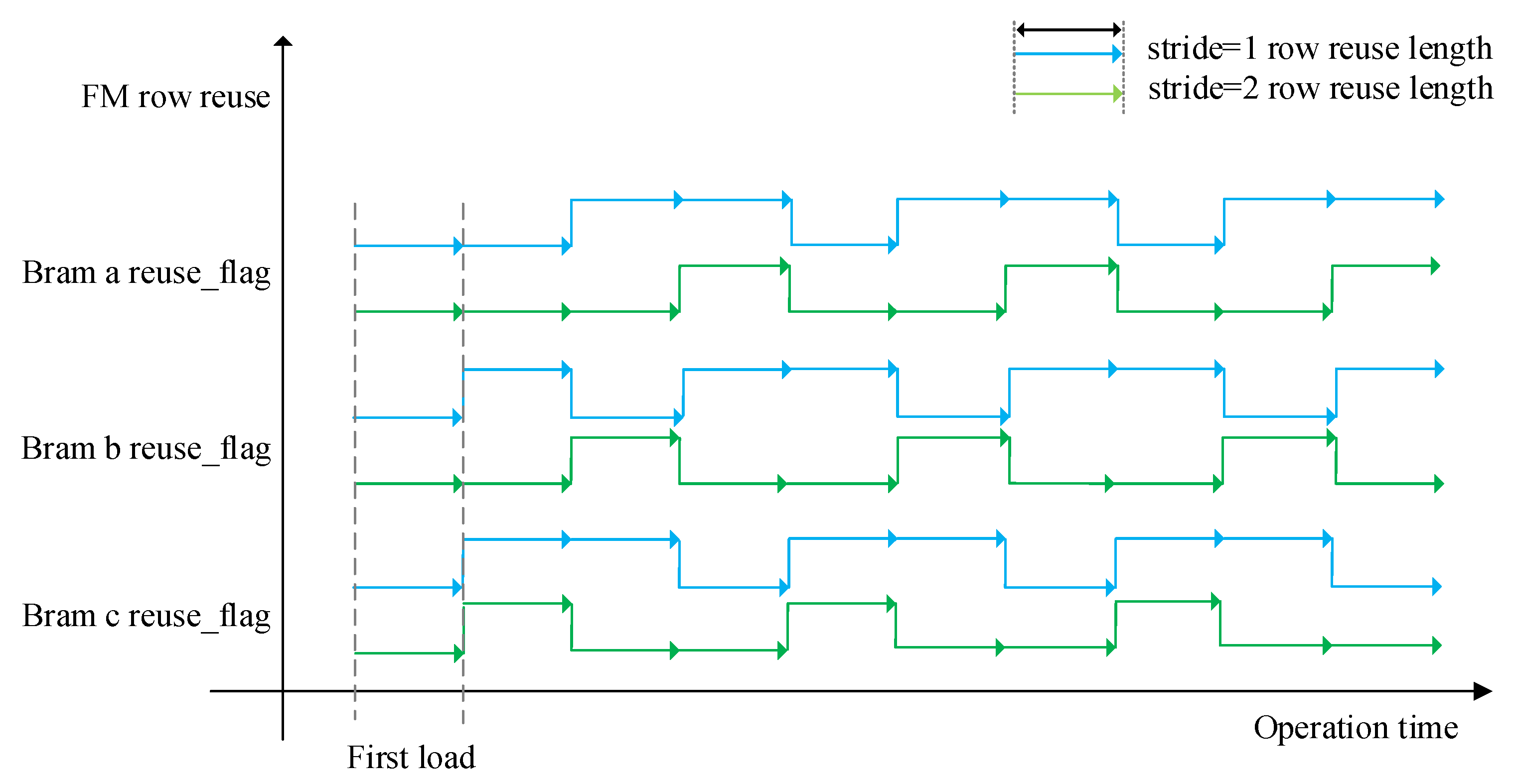
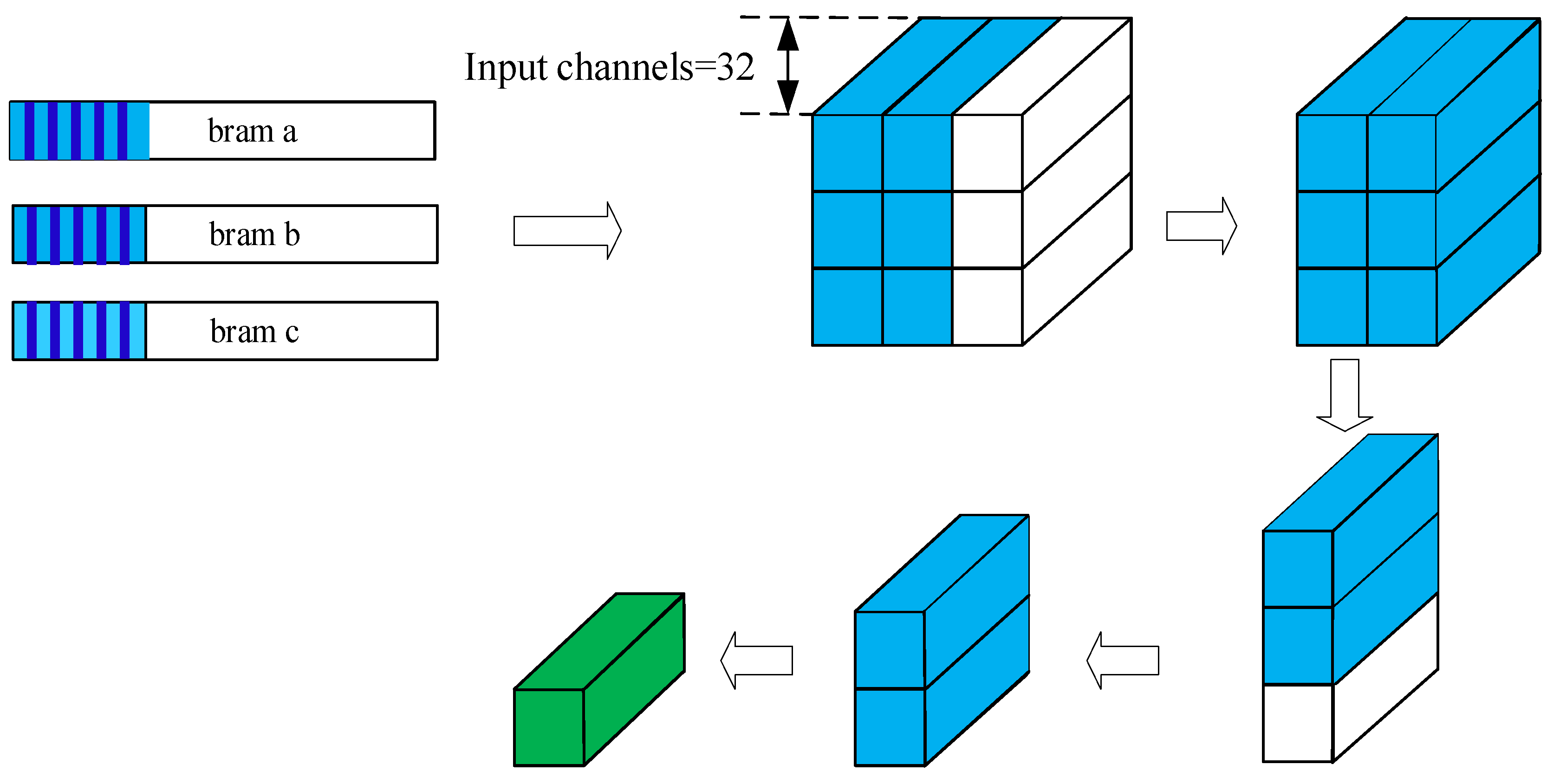
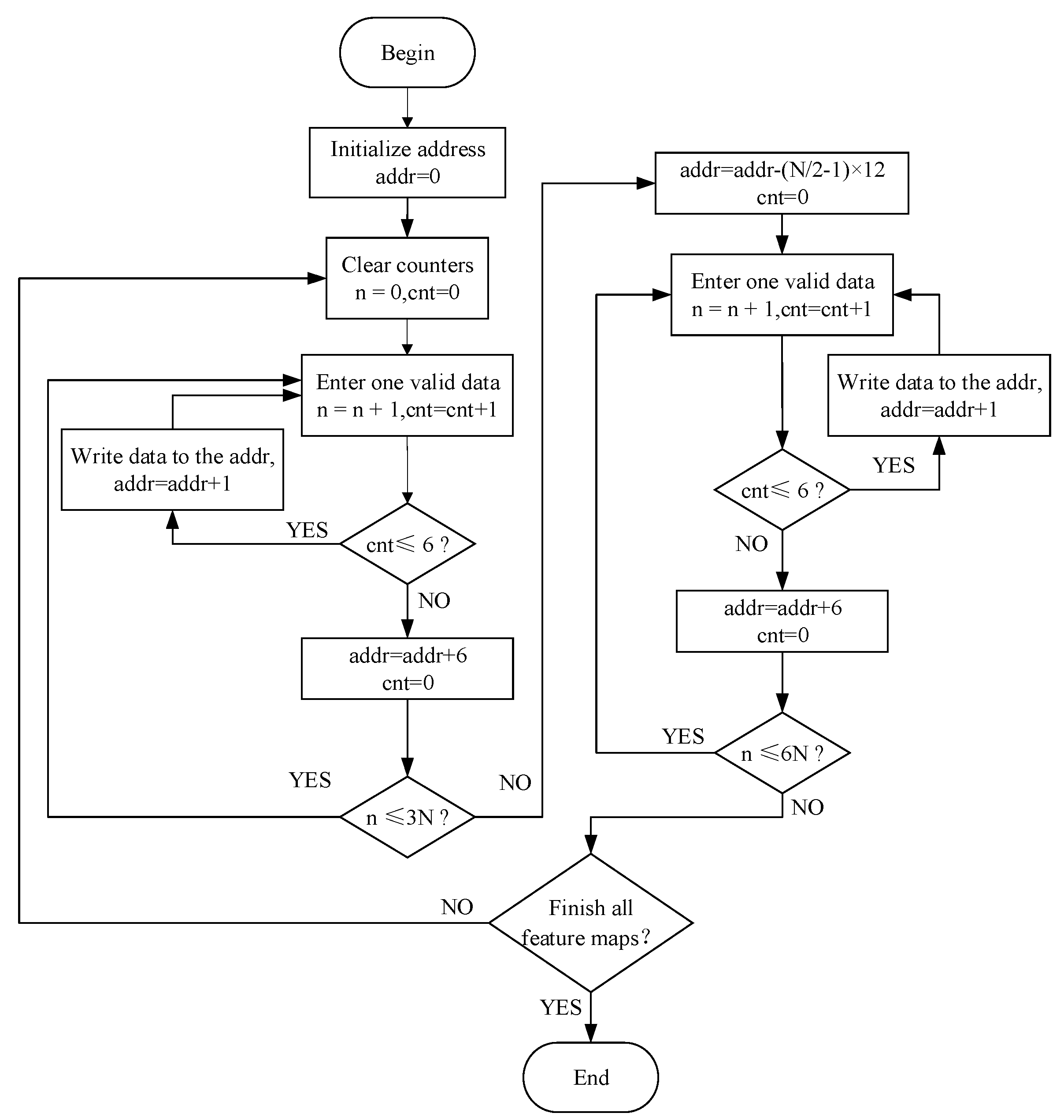
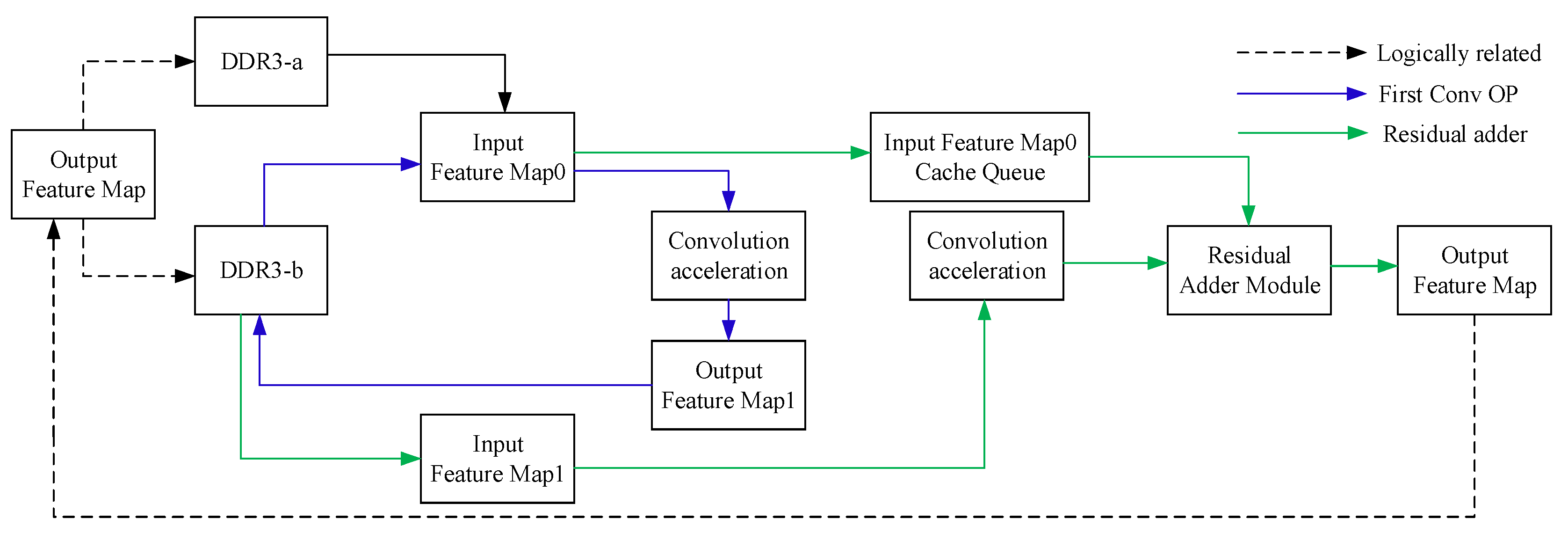
2.3.4. Data Partitioning and the Three-Path Cache Queue Design
2.4. Design of the Small-Scale Cascade Pooling Module
2.5. Design of Slice Module
2.6. Design of Residual Module
3. Experiment
3.1. Experimental Environment Setup
3.2. Results and Comparison Analysis
4. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Nikouei, S.Y.; Chen, Y.; Song, S.; Xu, R.; Choi, B.Y.; Faughnan, T.R. Real-Time Human Detection as an Edge Service Enabled by a Lightweight CNN. In Proceedings of the 2018 IEEE International Conference on Edge Computing (EDGE), San Francisco, CA, USA, 2–7 July 2018. [Google Scholar] [CrossRef] [Green Version]
- Wang, M.; Li, Q.; Pan, J.; Gu, Y. SCSF-Net: Single Class Scale Fixed Network for Object Detection in Optical Remote Sensing Images on Limited Hardware. In Proceedings of the 2021 IEEE International Geoscience and Remote Sensing Symposium IGARSS, Brussels, Belgium, 11–16 July 2021. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Hu, H.R.; Duan, J.X.; Bi, J.Q.; Fang, L.L. Target Recognition Technology Based on Improved Faster RCNN. In Proceedings of the 2022 3rd International Conference on Electronic Communication and Artificial Intelligence (IWECAI), Zhuhai, China, 14–16 January 2022. [Google Scholar] [CrossRef]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask R-CNN. In Proceedings of the 2017 IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017. [Google Scholar] [CrossRef]
- Yin, X.; Yang, Y.; Xu, H.; Li, W.; Deng, J. Enhanced Faster-RCNN Algorithm for Object Detection in Aerial Images. In Proceedings of the 2020 IEEE 9th Joint International Information Technology and Artificial Intelligence Conference (ITAIC), Chongqing, China, 11–13 December 2020. [Google Scholar] [CrossRef]
- Tan, M.; Le, Q.V. EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks. In Proceedings of the 36th International Conference on Machine Learning, Long Beach, CA, USA, 10–15 June 2019. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. SSD: Single Shot MultiBox Detector. In Proceedings of the 14th European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016. [Google Scholar] [CrossRef] [Green Version]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, Real-Time Object Detection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar] [CrossRef] [Green Version]
- Redmon, J.; Farhadi, A. YOLO9000: Better, Faster, Stronger. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar] [CrossRef] [Green Version]
- Redmon, J.; Farhadi, A. YOLOv3: An Incremental Improvement. arXiv 2018, arXiv:804.02767. [Google Scholar] [CrossRef]
- Bochkovskiv, A.; Wang, C.Y.; Liao, H. YOLOv4: Optimal Speed and Accuracy of Object Detection. arXiv 2020, arXiv:2004.10934. [Google Scholar] [CrossRef]
- Garea, A.S.; Heras, D.B.; Arguello, F. Caffe CNN-Based Classification of Hyperspectral Images on GPU. J. Supercomput. 2018, 75, 1–13. [Google Scholar] [CrossRef]
- Chen, L.; Chang, Y.; Yan, L. On-Orbit Real-Time Variational Image Destriping: FPGA Architecture and Implementation. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–12. [Google Scholar] [CrossRef]
- Li, Y.; Yao, B.; Peng, Y. FPGA-Based Large-Scale Remote Sensing Image ROI Extraction for On-Orbit Ship Detection. In Proceedings of the 2022 IEEE International Instrumentation and Measurement Technology Conference (I2MTC), Ottawa, ON, Canada, 16–19 May 2022. [Google Scholar] [CrossRef]
- Zhang, J.; Cheng, L.; Li, C.; Li, Y.; He, G.; Xu, N.; Lian, Y. A Low-Latency FPGA Implementation for Real-Time Object Detection. In Proceedings of the 2021 IEEE International Symposium on Circuits and Systems (ISCAS), Daegu, Korea, 22–28 May 2021. [Google Scholar] [CrossRef]
- Bi, F.; Yang, J. Target Detection System Design and FPGA Implementation Based on YOLO v2 Algorithm. In Proceedings of the 2019 3rd International Conference on Imaging, Signal Processing and Communication (ICISPC), Singapore, 27–29 July 2019. [Google Scholar] [CrossRef]
- Zhang, S.; Cao, J.; Zhang, Q.; Zhang, Q.; Zhang, Y.; Wang, Y. An FPGA-Based Reconfigurable CNN Accelerator for YOLO. In Proceedings of the 2020 IEEE 3rd International Conference on Electronics Technology (ICET), Chengdu, China, 8–12 May 2020. [Google Scholar] [CrossRef]
- Nguyen, D.T.; Nguyen, T.N.; Kim, H.; Lee, H. A High-Throughput and Power-Efficient FPGA Implementation of YOLO CNN for Object Detection. IEEE Trans. Very Large Scale Integr. VLSI Syst. 2019, 27, 1861–1873. [Google Scholar] [CrossRef]
- Hu, K.Y.; Hu, H.S.; Liu, X.M. The Application of TMR on the High Performance and Anti-Radiation DSP. Microelectron. Comput. 2019, 36, 58–60. (In Chinese) [Google Scholar]
- Ge, Z.; Liu, S.; Wang, F.; Li, Z.; Sun, J. YOLOX: Exceeding YOLO Series in 2021. arXiv 2021, arXiv:2107.08430. Available online: https://doi.org/10.48550/arXiv.2107.08430 (accessed on 6 August 2021). [CrossRef]
- Ma, Y.; Cao, Y.; Vrudhula, S.; Seo, J. Optimizing the Convolution Operation to Accelerate Deep Neural Networks on FPGA. IEEE Trans. Very Large Scale Integr. (VLSI) Syst. 2018, 26, 1354–1367. [Google Scholar] [CrossRef]
- Dood, P.E.; Shaneyfelt, M.R.; Schwank, J.R.; Felix, J.A. Current and Future Challenges in Radiation Effects on CMOS Electronics. IEEE Trans. Nucl. Sci. 2010, 57, 1747–1763. [Google Scholar] [CrossRef]
- Binder, D.; Smith, E.C.; Holman, A.B. Satellite Anomalies from Galactic Cosmic Rays. IEEE Trans. Nucl. Sci. 1975, 22, 2675–2680. [Google Scholar] [CrossRef]
- Zhang, X.; Wang, J.; Zhu, C.; Lin, Y.; Xiong, J.; Hwu, W.M.; Chen, D. DNNBuilder: An Automated Tool for Building High-Performance DNN Hardware Accelerators for FPGAs. In Proceedings of the 2018 IEEE/ACM International Conference on Computer-Aided Design (ICCAD), San Diego, CA, USA, 5–8 November 2018; pp. 1–8. [Google Scholar] [CrossRef]



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Resource | Used | Available | Utilization % |
|---|---|---|---|
| LUT | 165,981 | 433,200 | 38.32% |
| LUTRAM | 3329 | 174,200 | 1.91% |
| FF | 228,309 | 866,400 | 26.35% |
| BRAM | 1094 | 1470 | 74.42% |
| DSP | 1024 | 1200 | 85.33% |
| IO | 231 | 850 | 27.18% |
| BUFG | 8 | 32 | 25.00% |
| MMCM | 5 | 20 | 25.00% |
| PLL | 2 | 20 | 25.00% |
| Categories | Layers/Total | Least Efficiency % | |
|---|---|---|---|
| Kernel size = 1, Output channel ≤ 32 | 1 | 9/83 | 55.3 |
| Kernel size = 1, Output channel = 64 | 2 | 9/83 | 83.5 |
| Others | ≥3 | 65/83 | 99.1 |
| Method | ISCAS2021 [16] | ICISPC2019 [17] | ICET2020 [18] | Ours |
|---|---|---|---|---|
| FPGA Platform | ZC709 | XC7K325T | ZCU102 | VC709 |
| Target Network | YOLOv2-tiny | YOLOv2 | YOLOv2 | YOLOX-s |
| Precision/bit | Fix-8 | Fix-32 | Fix-16 | Fix-16 |
| Clock Frequency/MHz | 200 | 100 | 300 | 200 |
| DSP | 610/900 | — | 609 | 1024/1200 |
| BRAM | 256/545 | — | 491 | 1094/1470 |
| LUT | 84 K/219 K | — | 95 K | 165 K/433 K |
| FF | 65 K/437 K | — | 90 K | 228 K/866 K |
| Throughput/GOPS | 464.5 | 6.222 | 102.2 | 399.6 |
| Power/W | 10.25 | 2.555 | 11.8 | 14.76 |
| DSP efficiency | 95.2% | — | — | 97.56% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, L.; Zhou, H.; Bian, C.; Jiang, K.; Cheng, X. Hardware Acceleration and Implementation of YOLOX-s for On-Orbit FPGA. Electronics 2022, 11, 3473. https://doi.org/10.3390/electronics11213473
Wang L, Zhou H, Bian C, Jiang K, Cheng X. Hardware Acceleration and Implementation of YOLOX-s for On-Orbit FPGA. Electronics. 2022; 11(21):3473. https://doi.org/10.3390/electronics11213473
Chicago/Turabian StyleWang, Ling, Hai Zhou, Chunjiang Bian, Kangning Jiang, and Xiaolei Cheng. 2022. "Hardware Acceleration and Implementation of YOLOX-s for On-Orbit FPGA" Electronics 11, no. 21: 3473. https://doi.org/10.3390/electronics11213473