1. Introduction
Unlicensed taxis are private vehicles that transport passengers for a fee without formal operating authorization from the traffic police department. In recent years, unlicensed taxis have become more prevalent in urban areas. In a survey conducted by Tencent Technology on users’ experiences with unlicensed taxis, 80% of the nearly 25,000 respondents from more than 20 provinces reported that they frequently or occasionally ride in unlicensed taxis [
1]. The operation of unlicensed taxis is associated with numerous concerns and concealed safety risks, such as inconsistent charging standards, deliberate detours, poor car conditions, insufficient liability safety insurance, and potential criminal risks, which endanger and harm passengers significantly. In China, the situation of unofficial taxis has been associated with a serious crime. In the early morning of 6 May 2018, an unlicensed taxi driver raped and murdered 21-year-old flight attendant Li Mingzhu [
2].
It is common practice for traffic police to conduct spot checks for unlicensed taxis by setting up temporary checkpoints or conducting hot spot searches. However, these schemes are frequently time- and resource-intensive and have a low detection rate. Moreover, unlicensed taxis can evade such detection with relative ease. In addition, obtaining evidence of illegal conduct is difficult because unlicensed taxis are disguised as private vehicles.
Advanced technological devices such as road sensors, intersection cameras, and vehicle global positioning systems (GPS) have gathered substantial vehicle trajectory data pertaining to a variety of driving behavior traits. Recently, these trajectory data have been extensively used to address a variety of urban traffic issues with positive results. The mining of vehicle trajectory characteristics from these data and the detection of unlicensed taxis is a topic of active research. The trajectory data are subdivided into three additional categories: electronic registration identification (ERI) data [
3], GPS data [
4], and automatic number plate recognition (ANPR) data [
5]. Only ANPR data do not require installation in moving vehicles, and they record the entire trajectory of moving vehicles. Due to the fact that ANPR data collection equipment is frequently installed at road intersections, the data provide only limited insight into the condition of urban road connectivity. The trajectory data from ANPR intersection cameras have been utilized extensively in traffic management to understand vehicle travel behavior and estimate travel time.
Existing models for detecting suspected unlicensed taxis are developed using similar steps. Step 1: analysis of the trajectory features of taxis and a feature extraction method is proposed; Step 2: a certain number of taxis and other vehicles are adopted as positive samples and negative samples from the original data set, the features of these samples are extracted utilizing the method proposed in Step 1, then a binary classification model is trained with the extracted features.
Section 2.1 provides specific details.
Step 1 is a complex task due to the inefficiency of manually designing feature classification and extraction strategies. In practice, there are two types of trajectories for vehicles primarily involved in traffic: periodic and random. Taxis typically follow random trajectories, which have characteristics that are difficult to summarize and extract, and are therefore overlooked by researchers. Step 2 presents a challenge that the task of detecting unlicensed taxis cannot simply be viewed as a binary classification task. Prior studies utilized a high ratio of taxis to other vehicles when constructing the training set, whereas the ratio of taxis to other vehicles in the original data set may be quite low. This method of constructing the training set exposes the conundrum of uneven sampling of these two types of vehicles, which makes the binary classification task susceptible to producing incorrect results.
Therefore, this study designs and implements a graph embedding-based unlicensed taxi detection model, entitled Trajectory Graph Embedding-based Unlicensed Taxi Detection (TGE-UTD), based on an equal proportion sampling trajectory data set.
This study accomplishes the following:
In the TGE-UTD, an ANPR dataset is transformed into a weighted trajectory graph, and vehicles are added as graph nodes. The graph fully depicts the driving trajectory and inclination of each vehicle.
To collect the trajectory features of each vehicle equally in the TGE-UTD, a biased random walk trajectory sampling strategy on the map is proposed to augment the possible vehicle trajectories and obtain the trajectory features of each vehicle.
A graph embedding machine learning model is trained according to the sampled trajectory to obtain the graph embedding vector of each vehicle in the TGE-UTD. The “similar-vehicle set” is obtained by setting the similarity threshold and comparing the similarity of vectors. Whereupon, potential unlicensed taxis are located and evaluated by comparing them to the set of similar vehicles.
In this study, a method is presented for transforming ANPR records into a trajectory graph, from which vehicle trajectory features are extracted utilizing machine learning, thereby reducing or even eliminating the need for manually designed feature extraction in previous studies. In addition, 100,000 vehicles are selected at random from the original data set to serve as the training set, after which taxis are identified as positive samples and other vehicles as negative samples. In contrast to the uneven sampling proportion in the training set that has been a problem in the existing literature, this method can make the proportion of vehicles in the training set consistent with that in the original data set, offering future researchers guidance for vehicle dataset sampling. In addition, the performance of three machine learning methods is compared, and it is demonstrated that TGE-UTD has the best performance in distinguishing between different types of vehicles, thereby providing enlightenment for methods regarding machine learning on a trajectory graph in vehicle detection tasks.
This study pioneers the application of machine learning for feature extraction in the detection of unlicensed taxis. Developed to identify unlicensed taxis, this method may also be applied to a wider range of vehicles.
3. Methodology
This section describes the datasets employed, the methods for detecting unlicensed taxis referred to as Trajectory Graph Embedding-based Unlicensed Taxi Detection (TGE-UTD), and the experimental design.
3.1. Dataset Description
This study utilizes the ANPR trajectory data from the intelligent transportation big data system in Changsha (a city in the Hunan Province of China), which encompasses the license plate information of passing vehicles and the time at which they passed through an intersection. These systems are deployed at intersections and can obtain information about all vehicles passing through intersections 24 h a day, in contrast to GPS devices, which are installed on individual vehicles. When a system detects a vehicle passing through the intersection, it takes a photograph of the vehicle, identifies the license plate and license plate color, and then transmits this data to the main server through the network. These systems generate approximately 30 million data points per day from over 700 intersections. The ANPR data set is not accessible to the public as it contains a large quantity of travel information involving personal privacy.
Table 2 displays the ANPR records of a vehicle. In the table, “License ” and “Color” represent, respectively, the license plate and its color. In general, the color of the license plate is used to differentiate between small cars, large cars (including buses and construction vehicles), and special vehicles; 0 or 2 represent the blue license plate of small vehicles, whereas 9 represents the yellow license plate of large vehicles. The combination of the license and color of a vehicle can represent a unique vehicle. The number of the intersection where the ANPR equipment installed is denoted by “Intersection ”. A “Timestamp” denotes the passing time of a vehicle. Therefore, an ANPR record (
) is represented in the following format:
In April 2016 in Changsha, ANPR intersection cameras generated a dataset totaling 41 gigabytes and 170 million records. Errors in license plate recognition were discovered in the data set and attributed to intersection camera issues involving light, angle, and data transmission delays.
According to the transportation department’s license issuance policies, licensed taxi license plates with a color code of 0 or 2 are prefixed with XiangAT and XiangAX (Xiang is the abbreviation for Hunan Province). Since no rigorous restriction is in place on the use of XiangAT and XiangAX as license plate prefixes for private vehicles, the distinguishment of taxis from other vehicles proves challenging based solely on the license plate setting rule.
3.2. Unlicensed Taxi Detection Model
This section describes a method to identify and analyze unlicensed taxis based on the trajectory graph embedding model.
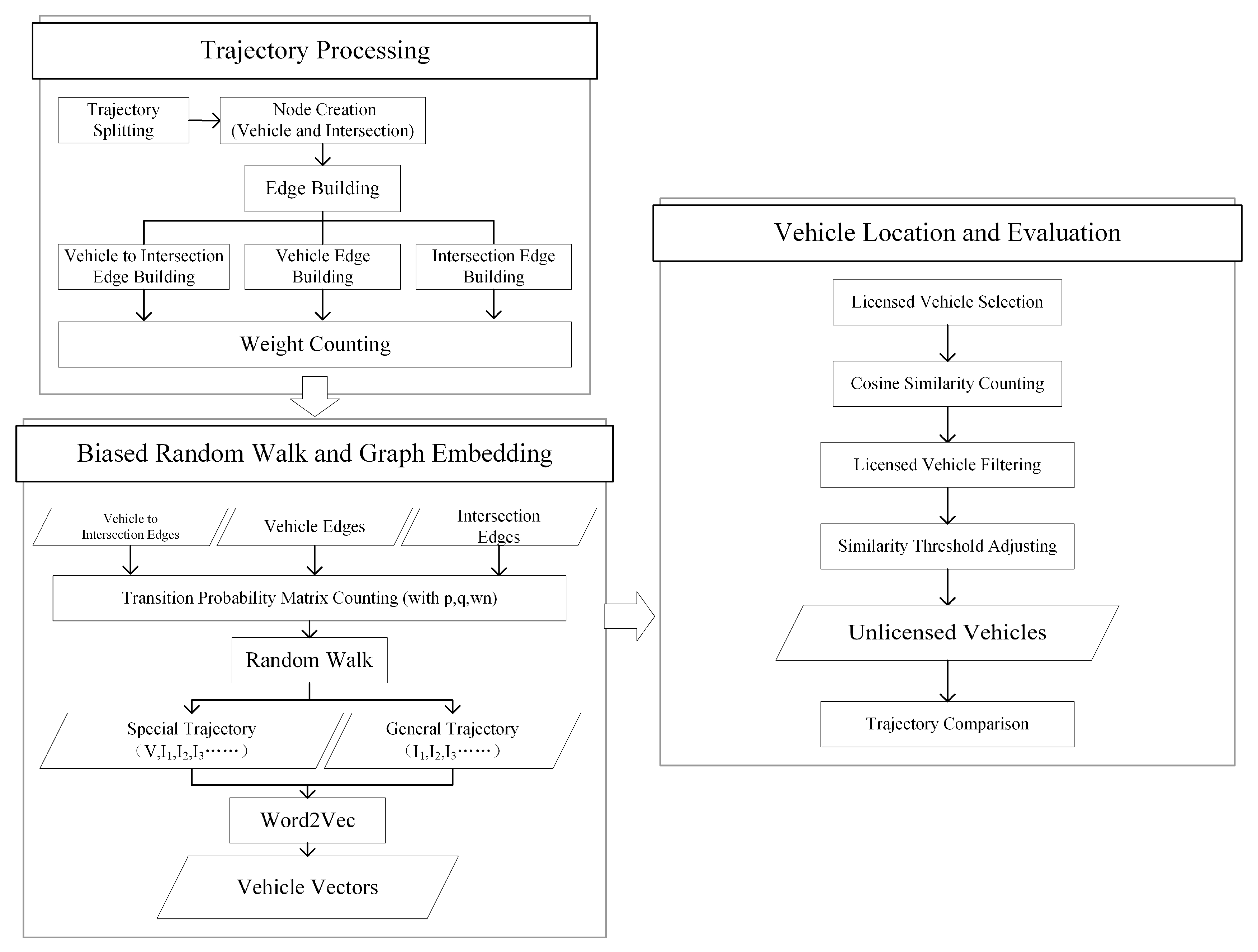
Figure 1 outlines the process of Trajectory Graph Embedding-based Unlicensed Taxi Detection (TGE-UTD). This process comprises trajectory processing, biased random walk and graph embedding, and vehicle location and evaluation.
The trajectory processing part involves the construction of the trajectory graph. The vehicles and intersections are considered nodes of the graph. The vehicle trajectories are converted into graph edges, and the edge weight is calculated according to the vehicle passing frequency. The biased random walk and graph embedding part indicate the different transition matrix calculation methods used for various nodes in the trajectory graph. In the random walk, based on the idea of Node2Vec, the walk weight is adjusted to learn the vehicle trajectory features in a biased way, and then the word embedding method is used to train the graph embedding vector to obtain the vehicle embedding vector. In the vehicle location and evaluation part, the licensed taxi vector is taken as the baseline to find private cars with high cosine similarity [
23] to the baseline vector. The real trajectories of the private cars found are manually compared with those of licensed taxis. If the two have a high similarity on the 3D trajectory diagram and a high percentage of common intersections, the found private cars are finally determined to be suspected unlicensed taxis.
3.2.1. Trajectory Processing
The trajectory of a vehicle (
) is determined by multiple records of the same vehicle according to the vehicle passing time and is represented as follows:
represents the
m-th intersection. If the time interval of a vehicle passing through two intersections exceeds 30 min [
24], the vehicle has a parking behavior between the two intersections. Therefore, the trajectory is split into multiple sub-trajectories containing start and end points in the 30 min time interval. The resulting multiple sub-trajectories of vehicle
V (
) are described as follows:
indicates the
n-th trajectory.
is divided into edges forming the trajectory graph, and each edge contains the corresponding identifier of the passing vehicle. If the vehicle
V travels from
to
, an edge from node
to node
(
) is added to the trajectory graph, represented as follows:
If the vehicle travels from
to
multiple times, then the weight
is added to the
based on the number of passing times. Therefore, the intersection edge set of the graph (
) is as follows:
Each edge in the set represents the record of all cars passing through the two intersections, and
w is the number of passes. The vehicle is also added to the graph as a node, and the edge set of vehicle
V (
) is represented as follows:
An example of the final trajectory graph is shown in
Figure 2.
The graph describes two vehicles, Vehicle A and Vehicle B. Vehicle A has two trajectories, and Vehicle B has one. The vehicle node directly connects multiple intersection nodes, which are the starting points of each vehicle trajectory. For example, Vehicle A directly connects and , the starting points of the Vehicle A trajectories. However, multiple directed edges with weights and vehicle identifiers exist between intersections. For example, there are edges with vehicle identifiers and between and . The edge with vehicle identifier indicates that Vehicle A has a trajectory that goes through and sequentially, while the edge with vehicle identifier indicates that Vehicle B has a trajectory that goes through and sequentially. One trajectory of Vehicle A starts from and goes through and to the end point . One trajectory of Vehicle B starts from and goes through , , and to the end point . Both trajectories go through , , and . Vehicle A also has a trajectory that starts at and ends at , which is labeled .
Based on the graph structure, the intersection transition probability of a vehicle can be calculated by the edges with specific identifiers between nodes, and that of all vehicles can be calculated by all edges between nodes, laying a foundation for the subsequent random walk.
3.2.2. Biased Random Walk and Graph Embedding
The traditional random walk model assumes a homogeneous graph. However, the trajectory graph constructed in this study contains vehicle nodes, intersection nodes, and edges between nodes marked with vehicle identifiers and is thus a heterogeneous graph. Therefore, a corresponding random walk strategy is proposed for this heterogeneous graph. As shown in the “Biased Random Walk and Graph Embedding” part in
Figure 1, different calculation methods of the transition probability matrix are selected for various starting nodes.
The transition probability matrix is calculated by weighted sampling [
25]. The intersection transition probability matrix shows the transition probability between intersection nodes, and the sampling weight is the number of times all vehicles pass between the nodes. The vehicle transition probability matrix indicates the transfer probability of a specified vehicle between intersection nodes, and the sampling weight is the number of times the vehicle passes between the nodes.
Parameters p and q are added in this study to control the breadth-first transition and depth-first transition tendencies based on the walk method of Node2Vec and conducts a random walk on the trajectory graph in a biased way. When , the breadth-first transition probability increases, and then the starting node features increase. When , the depth-first transition probability increases, and then the destination node features increase. Algorithm 1 describes the calculation process of the transition probability matrix. When the input graph G is the trajectory subgraph of the vehicle V, and contains only the trajectory of the vehicle V, the algorithm calculates the vehicle transition probability matrix of the vehicle V. When the input graph G contains the trajectories of all vehicles, the algorithm then calculates the intersection transition probability matrix.
| Algorithm 1: Calculation of walk transition probability matrix. |
![Electronics 11 03410 i001]() |
The random walk is performed after calculating the walk transition probability matrix . During this procedure, the scale of the specific experimental data determines the walk length () and the number of walks (). As shown in Algorithm 2, the trajectory graph and the set of vehicle trajectory subgraphs are considered input. If the starting node is a vehicle, the vehicle transition probability matrix is used to impose a biased weighted random walk on , and if the starting node is an intersection, the intersection transition probability matrix is used to impose a biased weighted random walk on graph G. Finally, the walk model produces the random walk trajectories with a length of , which are used as learning samples for node embedding.
Most traditional feature learning models for vehicle trajectories directly use the original vehicle trajectories, but this study uses the random walk method to find potential vehicle trajectories. When used, this method increases the number of training samples and balances the number of trajectories between vehicles, enables TGE-UTD to capture the driving characteristics of vehicles with random trajectories, and makes TGE-UTD fault-tolerant for data sets with certain misrecognition records.
The random walk trajectories of each node are used as the training data, and the skip-gram model in Word2Vec is used to embed each node. TGE-UTD can obtain the node embedding vectors of all of the graph nodes, including the vehicle node vectors and intersection node vectors.
| Algorithm 2: Random walk in graph. |
![Electronics 11 03410 i002]() |
3.2.3. Vehicle Location and Evaluation
A licensed taxi with a random trajectory is selected after all vehicle vectors have been obtained. The cosine similarity between the vectors of the licensed taxis and those of other vehicles is calculated by Equation (
7). Vehicles having a high cosine similarity to the licensed taxis are found and added to the result set.
In the result set, the known licensed taxis are marked according to the plate setting rules, and the rest are suspected unlicensed taxis. The detection rate of suspected unlicensed taxis (
) is calculated by counting the number of known licensed taxis (
) and the number of suspected unlicensed taxis (
). The equation is as follows:
A high value indicates that there are many suspected unlicensed taxis in the result set and the detection scope in the vector space is too large; therefore, some private cars with low similarity are misjudged as suspected unlicensed taxis. A low value may indicate that there are no suspected unlicensed taxis or that the detection scope is too small and only a small number of suspected illegal unlicensed taxis are detected, indicating that the detection scope should be expanded. This study sets a maximum threshold of 10%. It also develops an analysis method to control the detection rate of unlicensed taxis and improve the accuracy of the screening result of TGE-UTD. (100 initially) is set to control the number of vehicles in the result set and ensure the efficiency of manual screening. Then, by adjusting , a similarity threshold (0.8 initially) is set to control . When is too high, is increased to make the detection similarity higher and the detection scope smaller. When is too low and the similarity in the result set exceeds , is increased to expand the detection scope, while is unchanged.
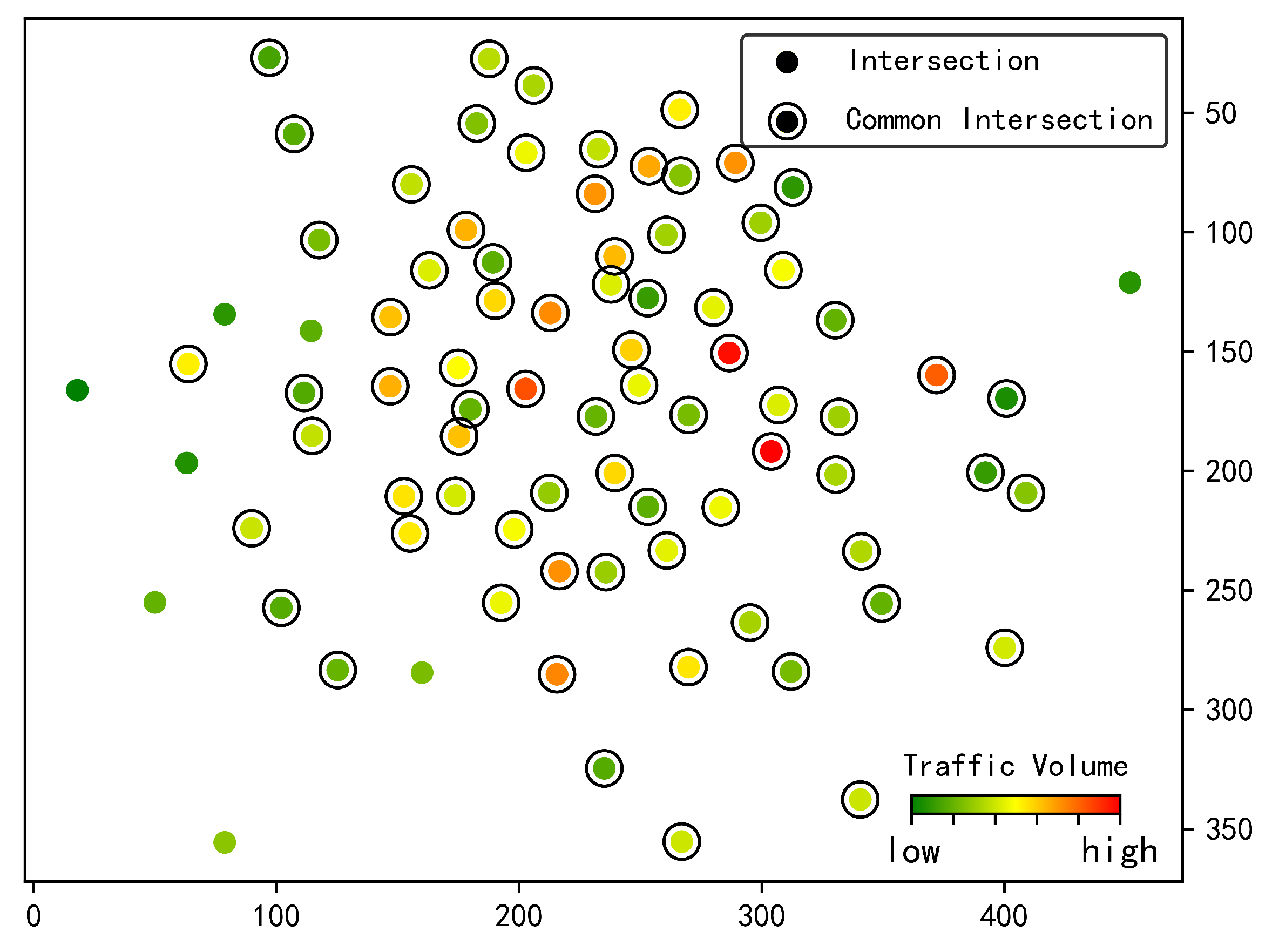
Suspected unlicensed taxis should also be screened manually. In this study, according to the original vehicle trajectories, a 3D trajectory diagram of the vehicles and a common intersection diagram with intersection traffic volume are constructed to assist in the determination of suspected unlicensed taxis. When comparing two vehicles, the 3D trajectory diagram can display the vehicles’ active regions and periods to allow manual verification of similar parts of their trajectories. The common intersection diagram shows the intersections passed by each vehicle, the intersections passed by both vehicles, and the traffic volume at the intersections. In this paper, in order to visually reflect the difference between the walk model and the no-walk model, t-SNE [
26] is used to reduce the vector dimension, and different types of vehicles and detected unlicensed taxis are classified and colored.
3.3. Experimental Setting
3.3.1. Experimental Dataset Features
There are an estimated 3 million vehicles in Changsha, with approximately 6000 taxis representing 1/500 of the total. To ensure the viability and efficacy of the experiment, 100,000 vehicles were selected at random from the original data set to serve as the training data set for the experiment. The total number of trajectories in the data set is 4,144,612, and the frequency of passing vehicles is 9,498,874. This study did not obtain a specific taxi information record, and as such, taxis must be manually marked in accordance with the rules governing license issuance. In the training set, 4443 vehicles with a license plate prefix of XiangAT or XiangAX and a plate color code of 0 or 2 are marked as taxis, 16,729 vehicles with a plate color code of 9 are marked as large vehicles, and 78,828 unmarked vehicles are classified as other vehicles. As there is no rigorous restriction on private cars using the prefixes XiangAT and XiangAX on their license plates, it is possible that private cars with such license plate prefixes could be incorrectly identified as taxis. This study added a taxi marking rule requiring the number of vehicle passing records to be greater than 100 based on the experience of the traffic management department in detecting unlicensed taxis and the fact that the number of commercial vehicle passing records is typically greater than 100. The number of taxis in the training set was reduced from 4443 to 202 as a consequence of this rule. Finally, the training set contains 202 taxis, 16,729 large vehicles, and 83,069 other vehicles. Taxis account for 1/500 of the total. Thereby, the proportion of taxis in the training set matches the proportion in the original data set.
Figure 3 depicts the characteristics of trajectories and traffic volume in the training set. The value of trajectory length (represented by the number of intersections passed by the trajectory) is predominantly distributed below 10 in
Figure 3a of the density distribution diagram for the training set. The density distribution diagram of the number of vehicle trajectories in the training set is depicted in
Figure 3b, and the number of trajectories is distributed below 200.
Figure 3c depicts the traffic volume during various training set time intervals. The volume distribution is consistent with the volume analysis results of Chen et al. [
9], indicating that the vehicle trajectory features in this paper’s training set are consistent with previously analyzed trajectory features.
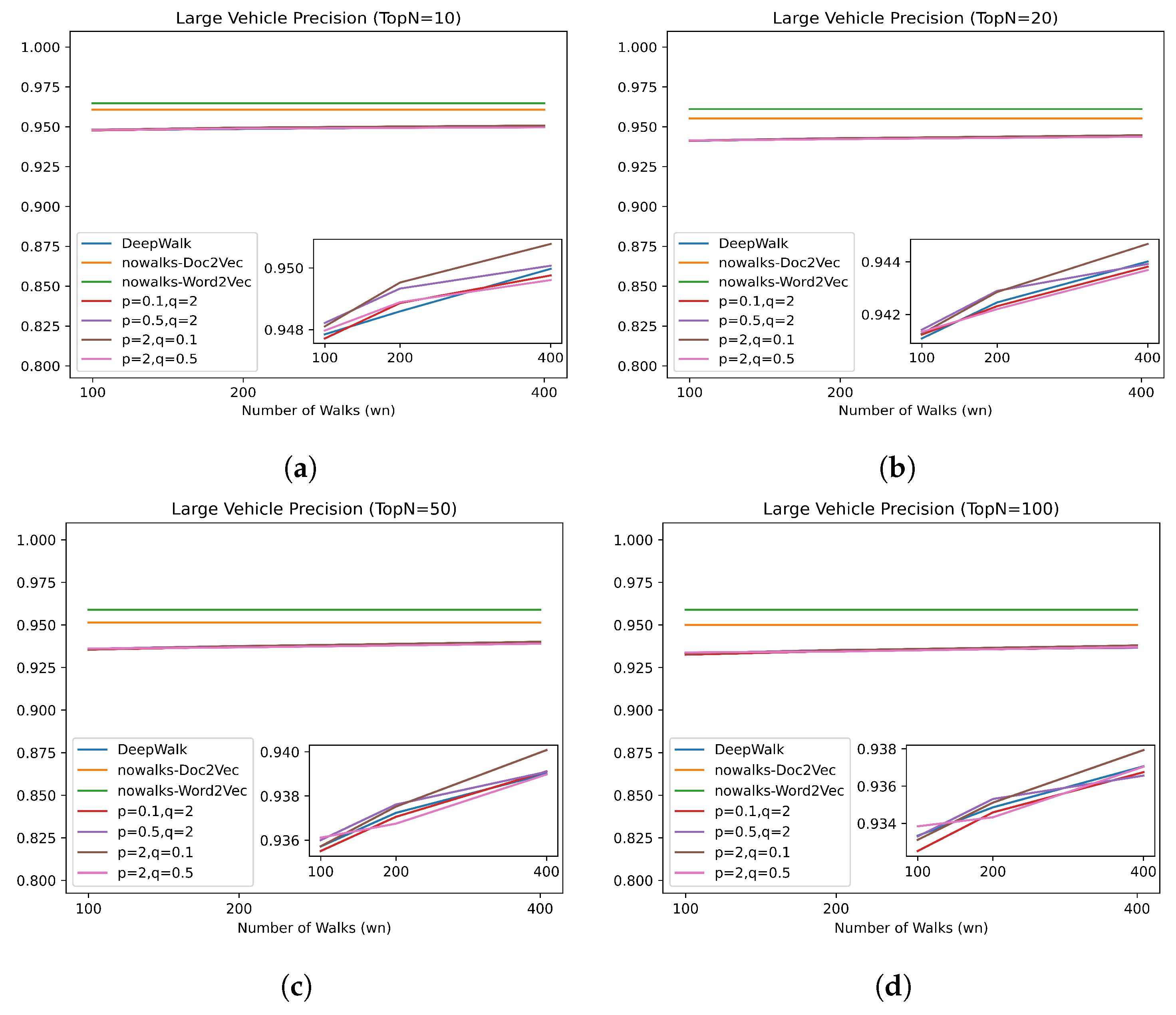
Figure 3d portrays the traffic volume of each intersection in the training set (ranked from highest to lowest), indicating that approximately 50 intersections in the training set feature a high traffic volume.
3.3.2. Model Parameters
There are six main parameters in the proposed model TGE-UTD:
p,
q,
,
,
, and
. In calculating the transition probability matrix,
p and
q control the breadth-first and depth-first transition probabilities of the random walk model. When
, the breadth-first transition probability increases and the walk focuses on the characteristics of the starting point of the trajectory; when
, the depth-first transition probability increases and the walk focuses on the characteristics of the end point of the trajectory. In the walking process,
and
control the walk length and the number of walks, respectively. As shown in
Figure 3a, the trajectory length is distributed between 1 and 10, so
is set as 10. As shown in
Figure 3b, the trajectory number density is mainly distributed between 1 and 125, so
is set at no less than 100. In the TGE-UTD training process,
and
control the embedding vector dimension and the sliding window size of skip-gram, respectively. To comprehensively represent the relationship between vehicles and intersections, win is set as 10, and
is set as 128 by default. Therefore, the parameters to be adjusted in this experiment are
p,
q, and
, as shown in
Table 3.
A grid search method [
27] is used to select the optimal values of
p,
q, and
. When
or
and
, the breadth-first transition probability of the walk model increases; when
and
, the transition probability of the walk model remains unchanged, and Node2Vec can be seen as DeepWalk; and when
,
or
, the depth-first transition probability of the walk model increases. Besides, according to the number of trajectories distributed below 200 in
Figure 3b,
is set to 100, 200, or 400.
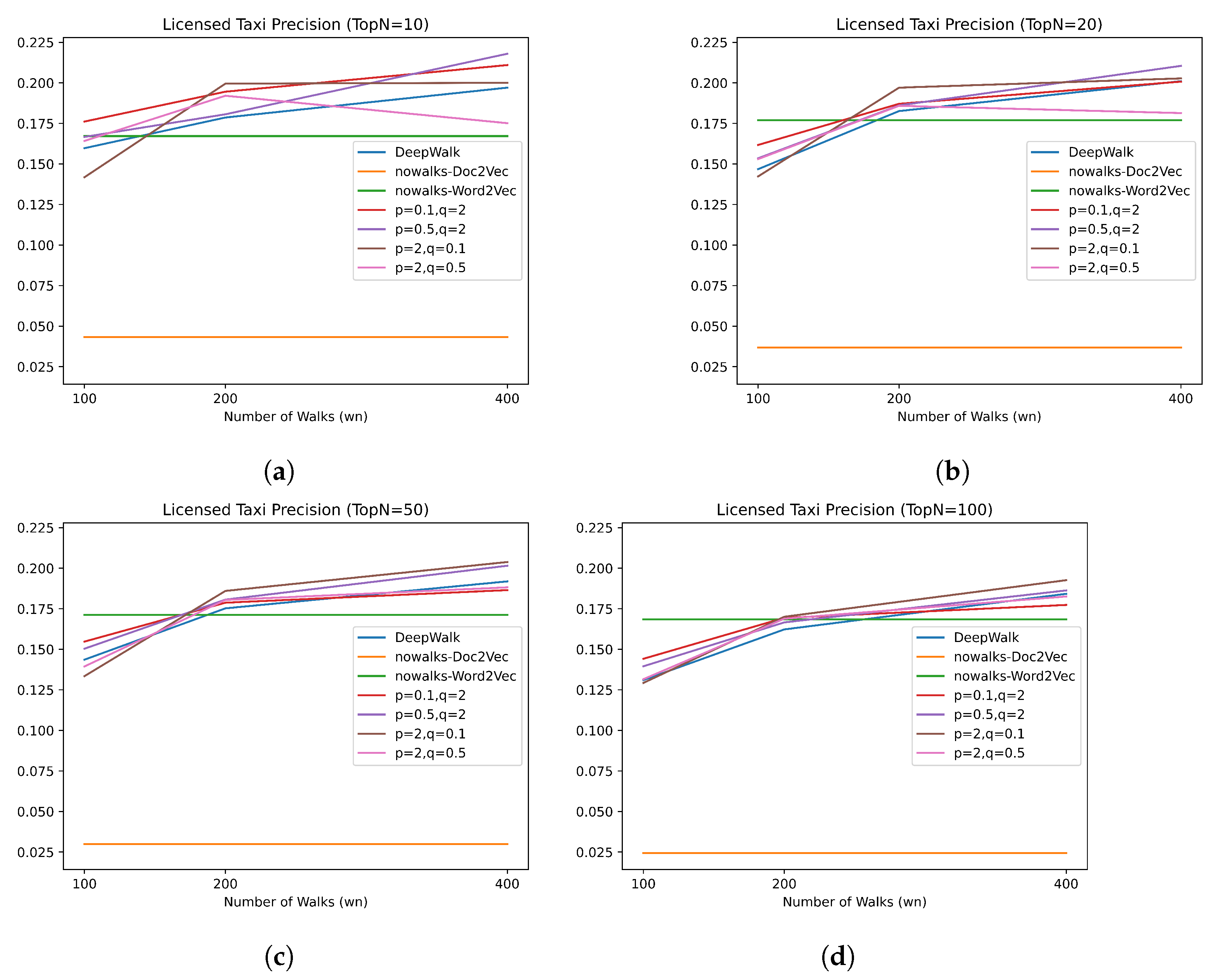
3.3.3. Evaluation Metrics
To evaluate the performance of the vector embedding model, the average precision rate is used to describe the vector similarity performance of TGE-UTD for different vehicle types. First, the
vehicles with the largest cosine similarity to the Vehicle
V are found, and then the precision rate is calculated according to the number of
vehicles of the same type as
V. Finally, the average precision rate of all vehicles of this type (
) is calculated as follows:
is a function to obtain the vehicle type of Vehicle V, t is a given vehicle type, is a vehicle of type t, and is a function for finding the similar-vehicle set of , which adds the vehicles with the largest similarity into this set. is used in this study.
5. Conclusions
On the basis of real vehicle trajectory datasets, an unsupervised learning method for trajectory features is designed to detect suspected unlicensed taxis. The fundamental concept is to use a random walk to balance the number of vehicle trajectories and increase the number of possible trajectories. The average precision rate of the no-walk model and the walk model in detecting large vehicles and taxis is compared, and it is determined that the walk model can better learn trajectory features, and the vehicle vectors obtained by the model can more accurately represent the vehicle trajectory features. The performance of TGE-UTD under different parameters is addressed, and the optimal parameters are ascertained. The experimental results demonstrate that TGE-UTD can detect taxis and private cars with random trajectories and has a high precision rate for detecting large vehicles with periodic trajectories. Therefore, this study proposes a detection scheme for suspected unlicensed taxis by which 188 suspected unlicensed taxis are detected in the experimental data set. A 3D trajectory diagram and a common intersection diagram are deployed to evaluate the detection results.
Traditional methods for detecting suspect unlicensed taxis rely heavily on the manual analysis and extraction of suspicious trajectory features by experts. However, the proposed TGE-UTD can automatically learn trajectory features and successfully accomplish the detection task. It has the ability to identify suspected unlicensed taxis and other types of vehicles, and thereby offers a decision-making and information foundation for traffic management departments.














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}