
MetaEar: Imperceptible Acoustic Side Channel Continuous Authentication Based on ERTF

Abstract
:1. Introduction
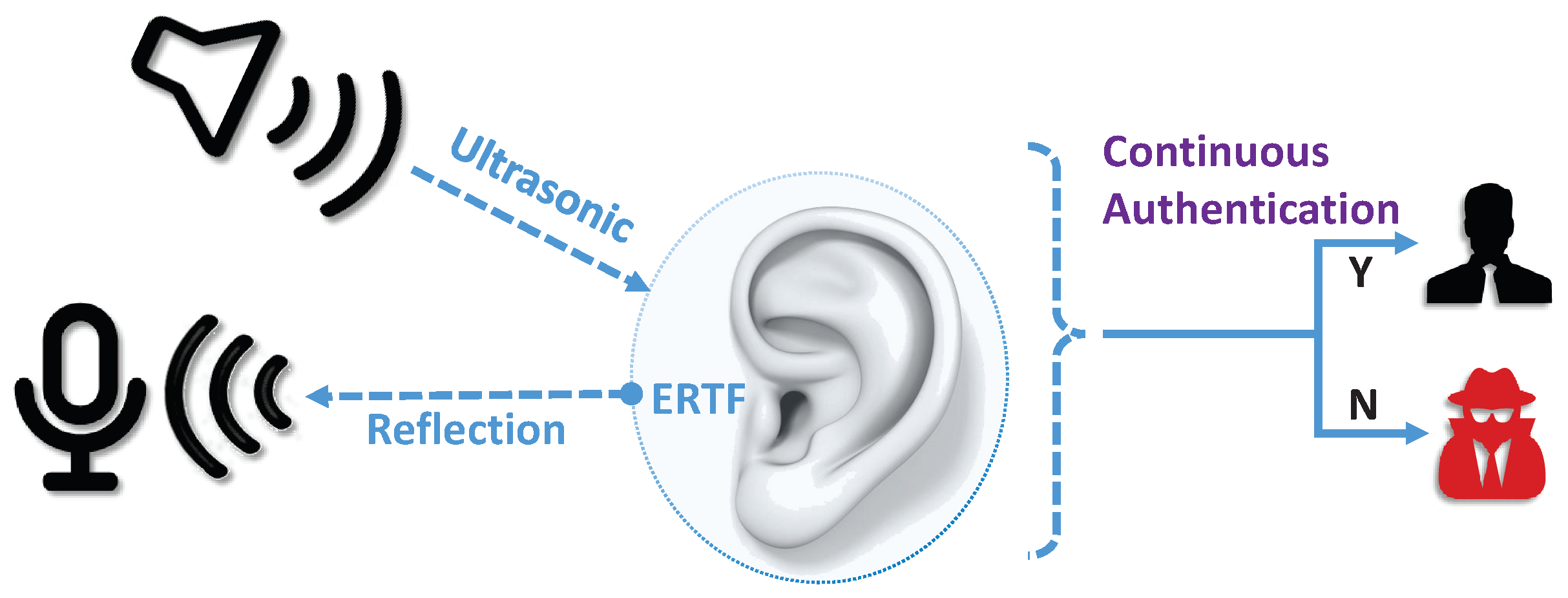
- We propose the MetaEar system, which uses the ultrasonic reflection signals of the auricle and ear canal to continuously authenticate users with ERTF, which effectively prevents replay attacks and counterfeiting attacks.
- We design a characteristic function to represent the auricle and ear canal biometric features through the principle of the impulse response of channel estimation, which effectively expresses the unique biological characteristics of the human auricle and ear canal.
- We build a prototype of MetaEar with commercial off-the-shelf smartphones and evaluate its effectiveness and security in different settings. Extensive experiments show that it authentication accuracy over 96.8%.
2. Related Works
2.1. Earable Computing
2.2. Acoustic Authentication
2.3. Continue Authentication
3. Threat Model
4. ERTF Model
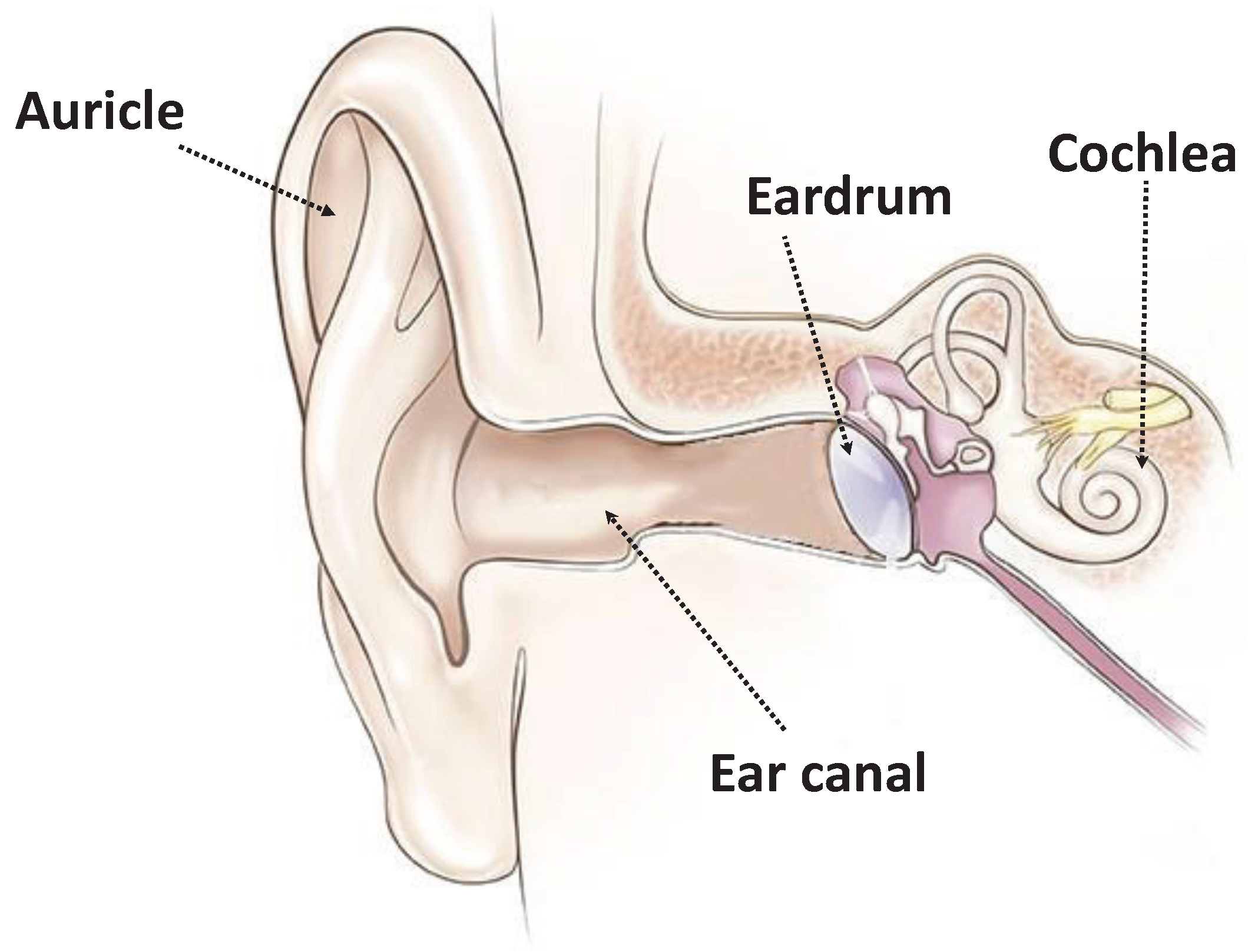
4.1. Ear Structure
4.2. ERTF
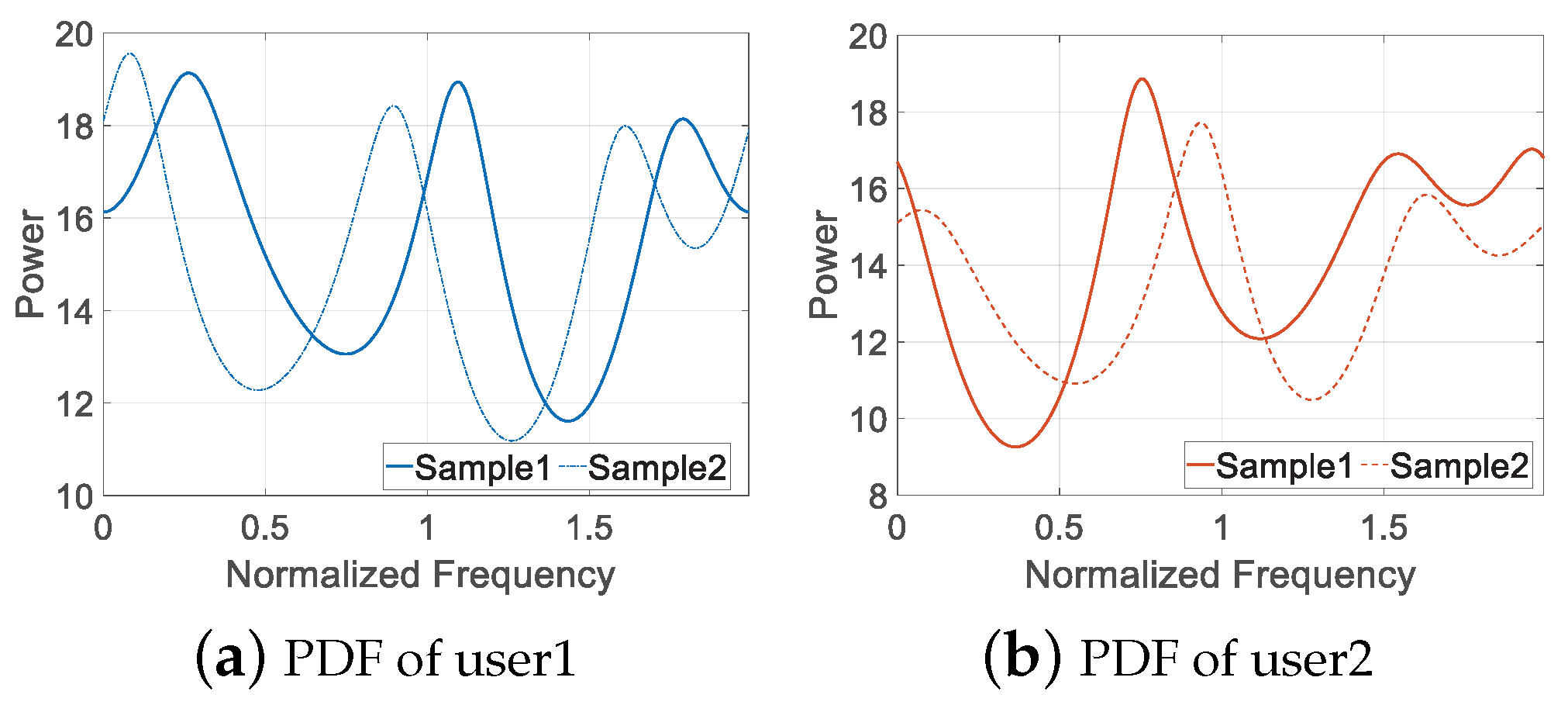
4.3. Feasibility Analysis
5. System Design
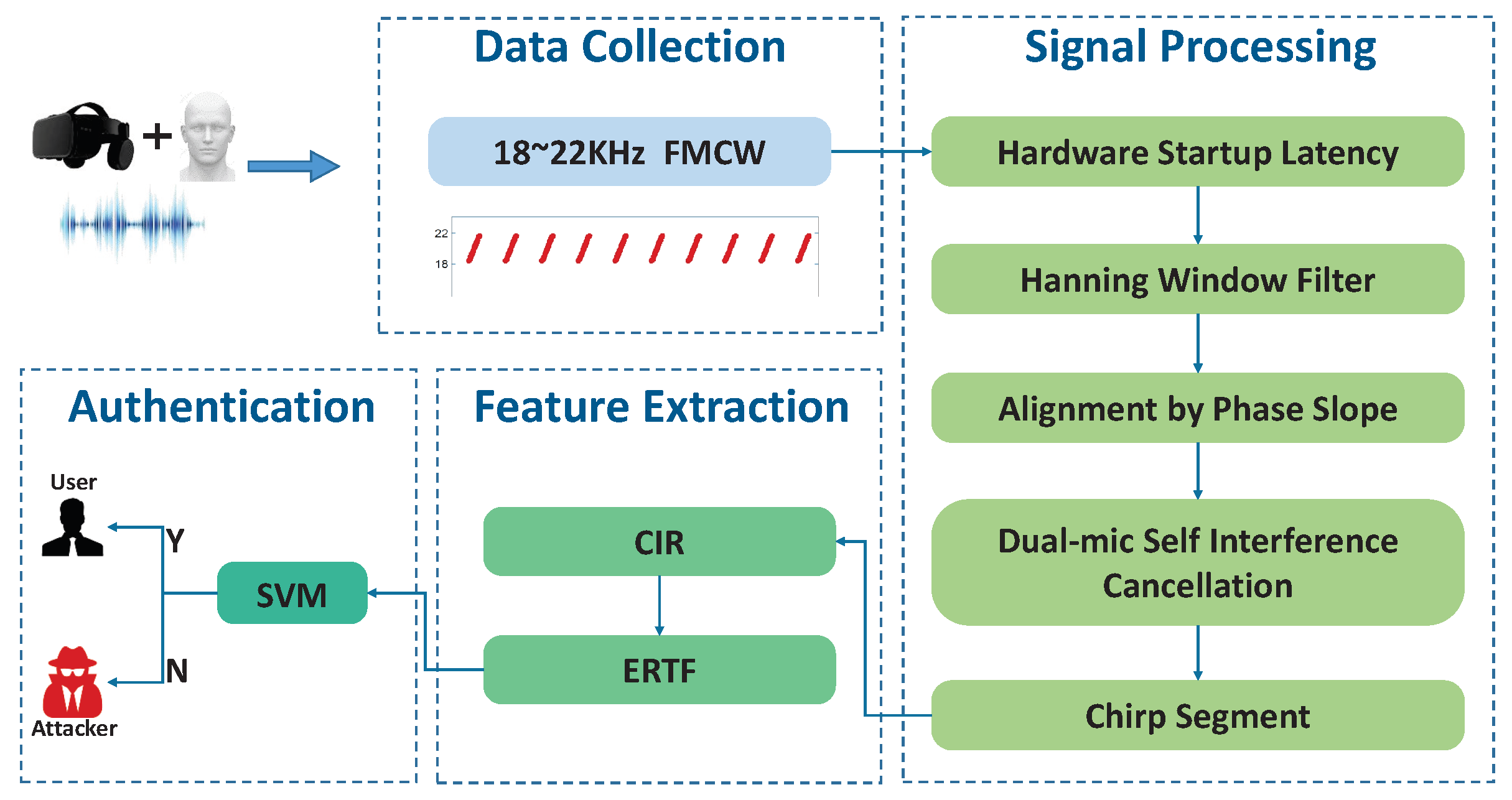
5.1. Overview
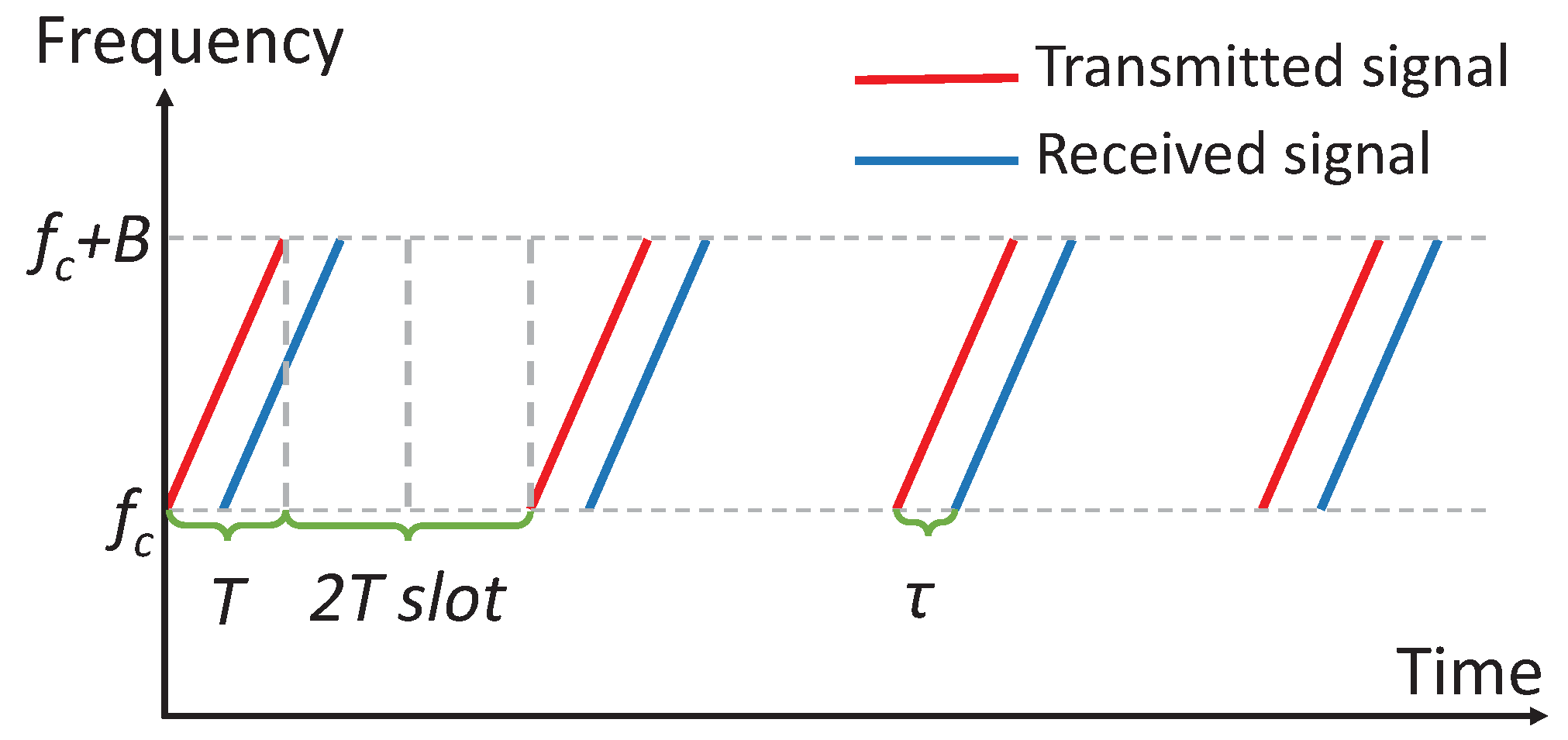
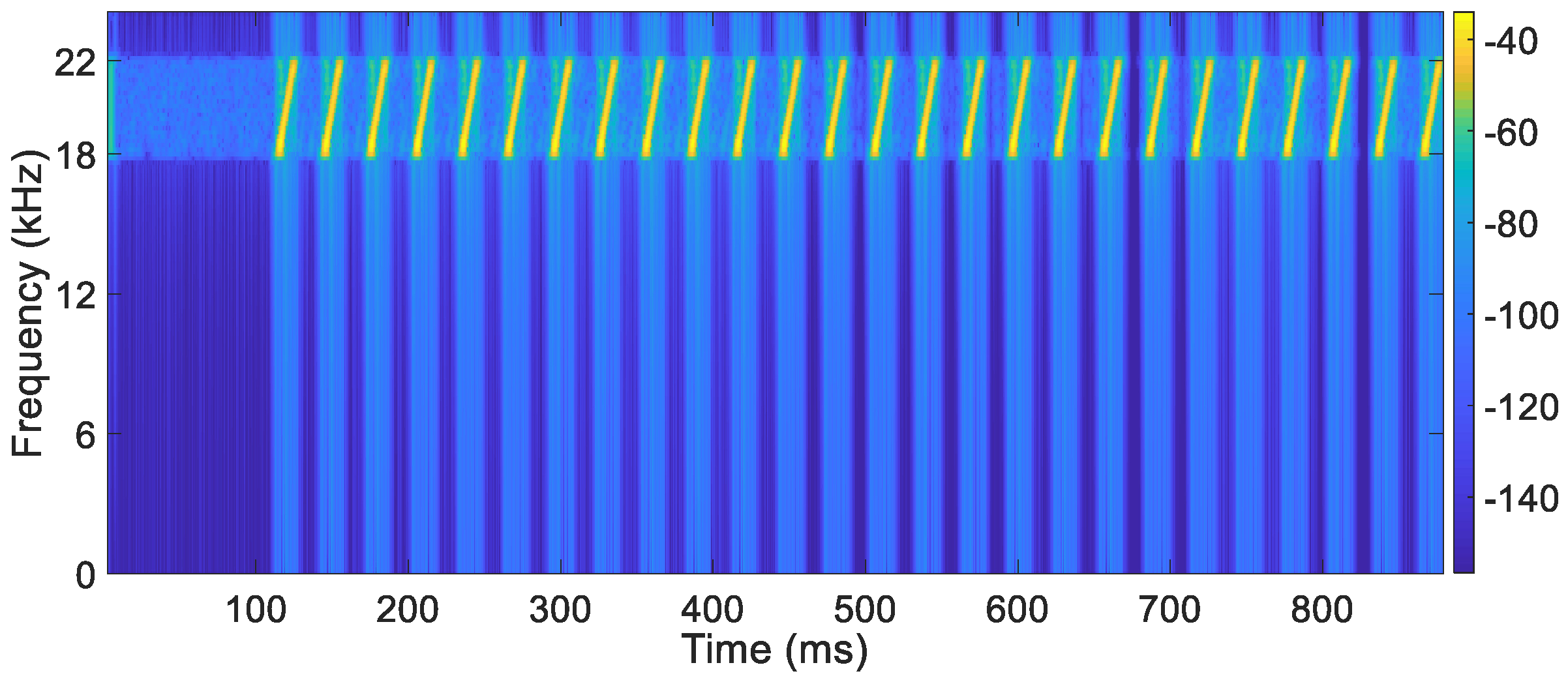
5.2. Acoustic Design
5.3. Denoise
5.4. Synchronization
5.5. Dual-Mic Subtraction
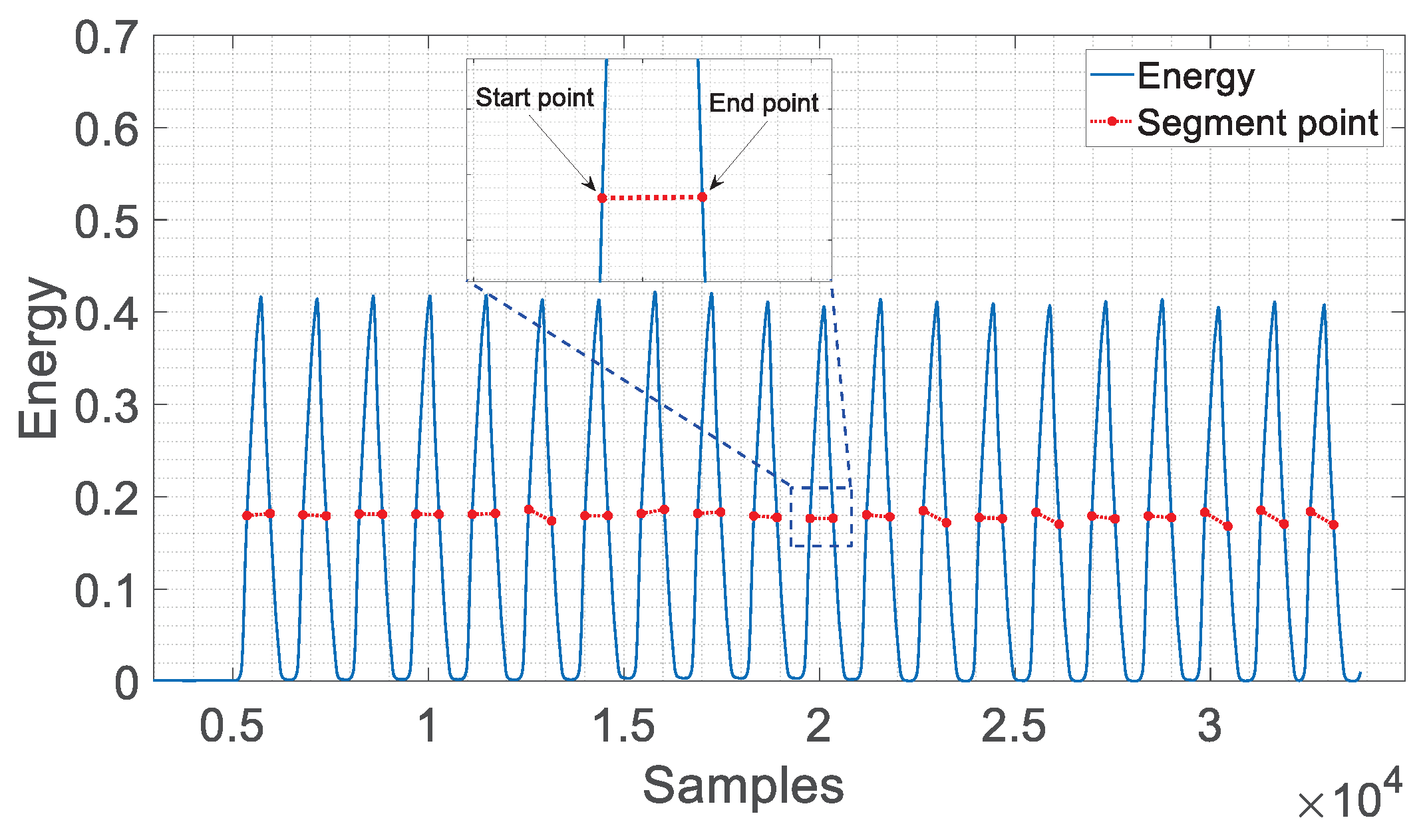
5.6. Chirp Segment
| Algorithm 1: Chirp Segmentation. |
Input: Denoised & Synchronized FMCW Sequence: Output: Segmented Chirp Sequence: //Get the envelope of r[n]. 1 2 //Find peaks of envelope[i]. 3 4 //Detect start/end points of chirp segment. 5 6 while do 7 8 end 9 10 while do 11 12 end 13 14 |
5.7. ERTF
5.8. Authentication
6. Implementation Setup
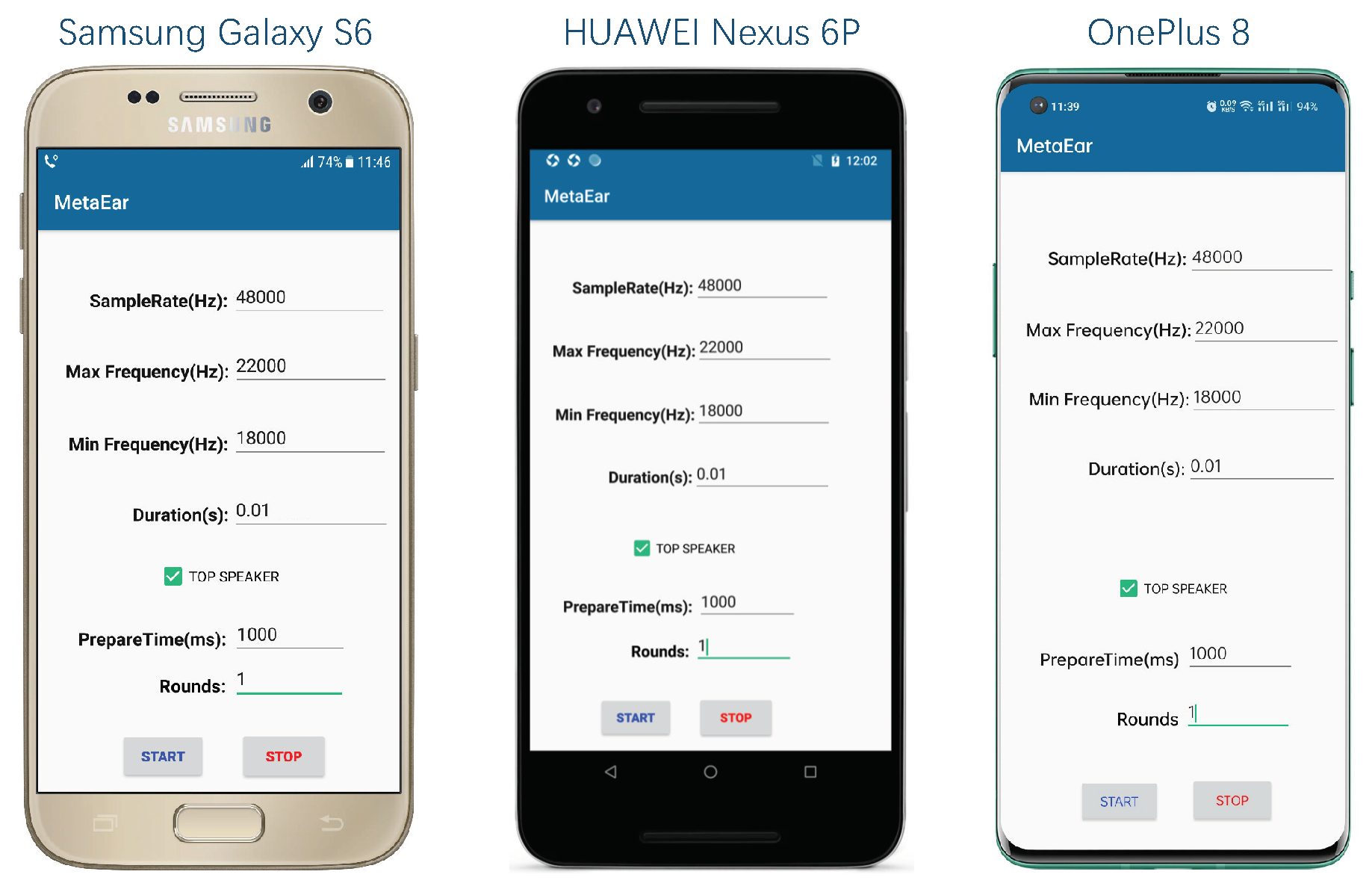
6.1. Mobile APP
6.2. Environment
7. Evaluation
7.1. Dataset
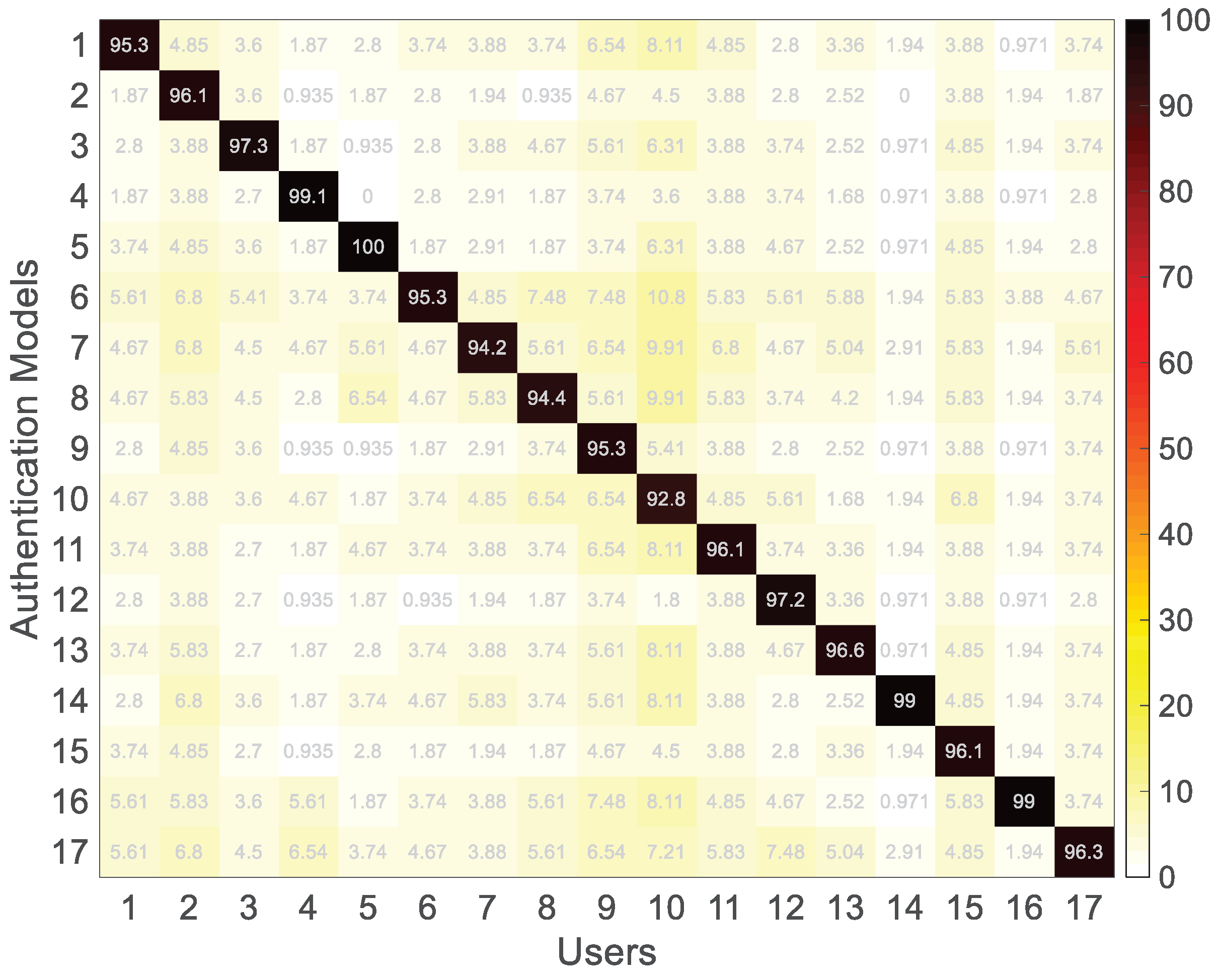
7.2. Overall Accuracy
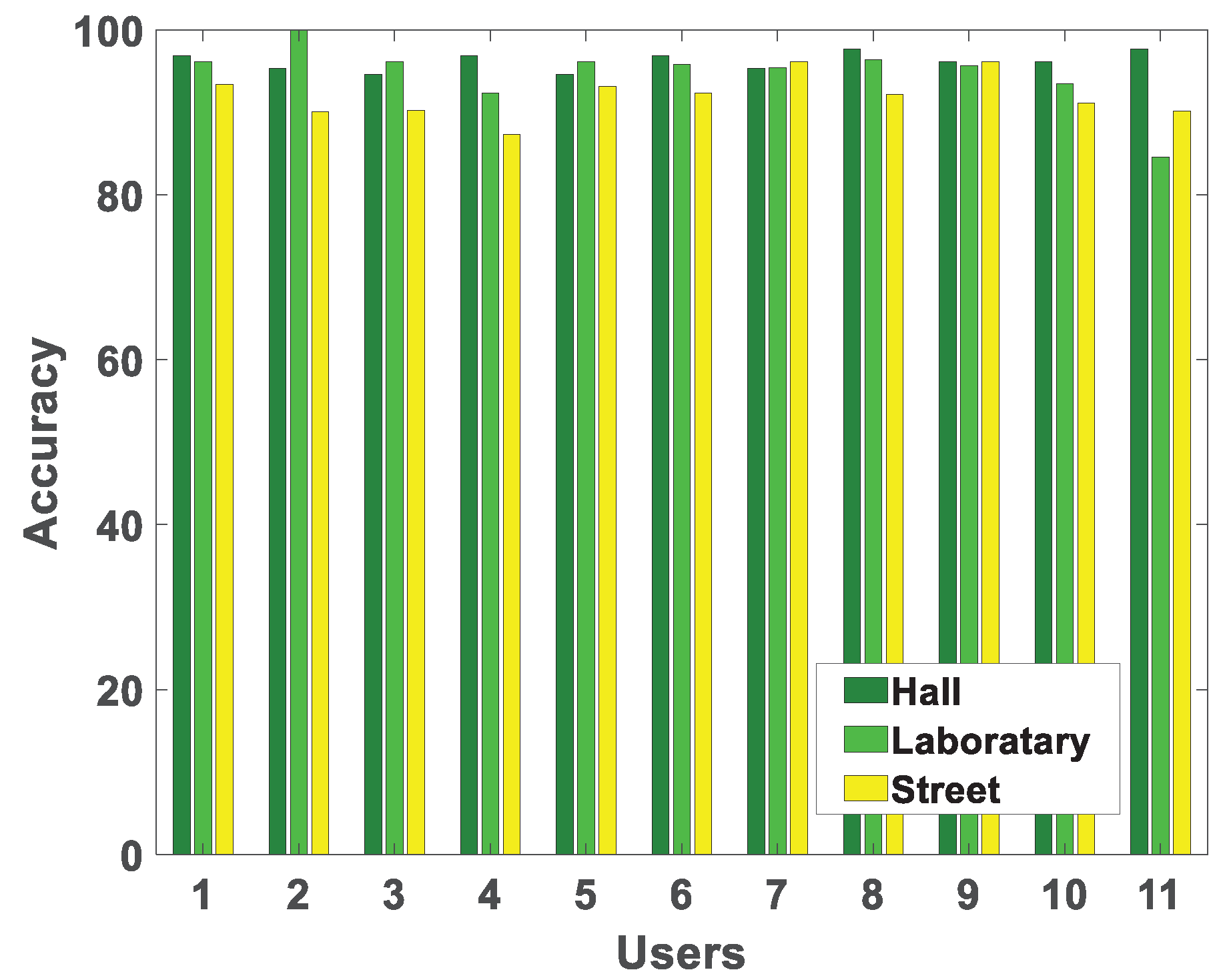
7.3. Impact of Environment
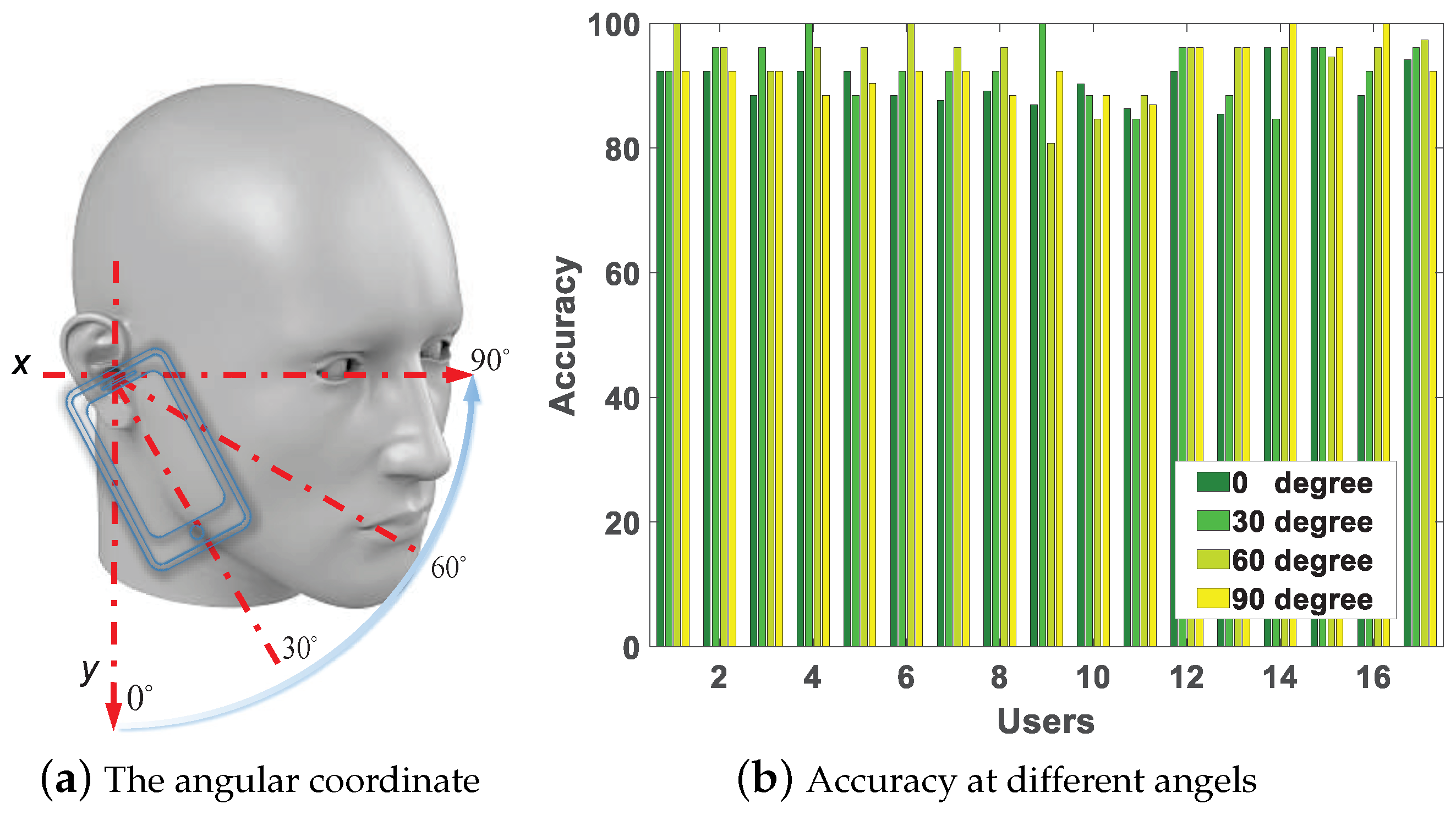
7.4. Impact of Angel
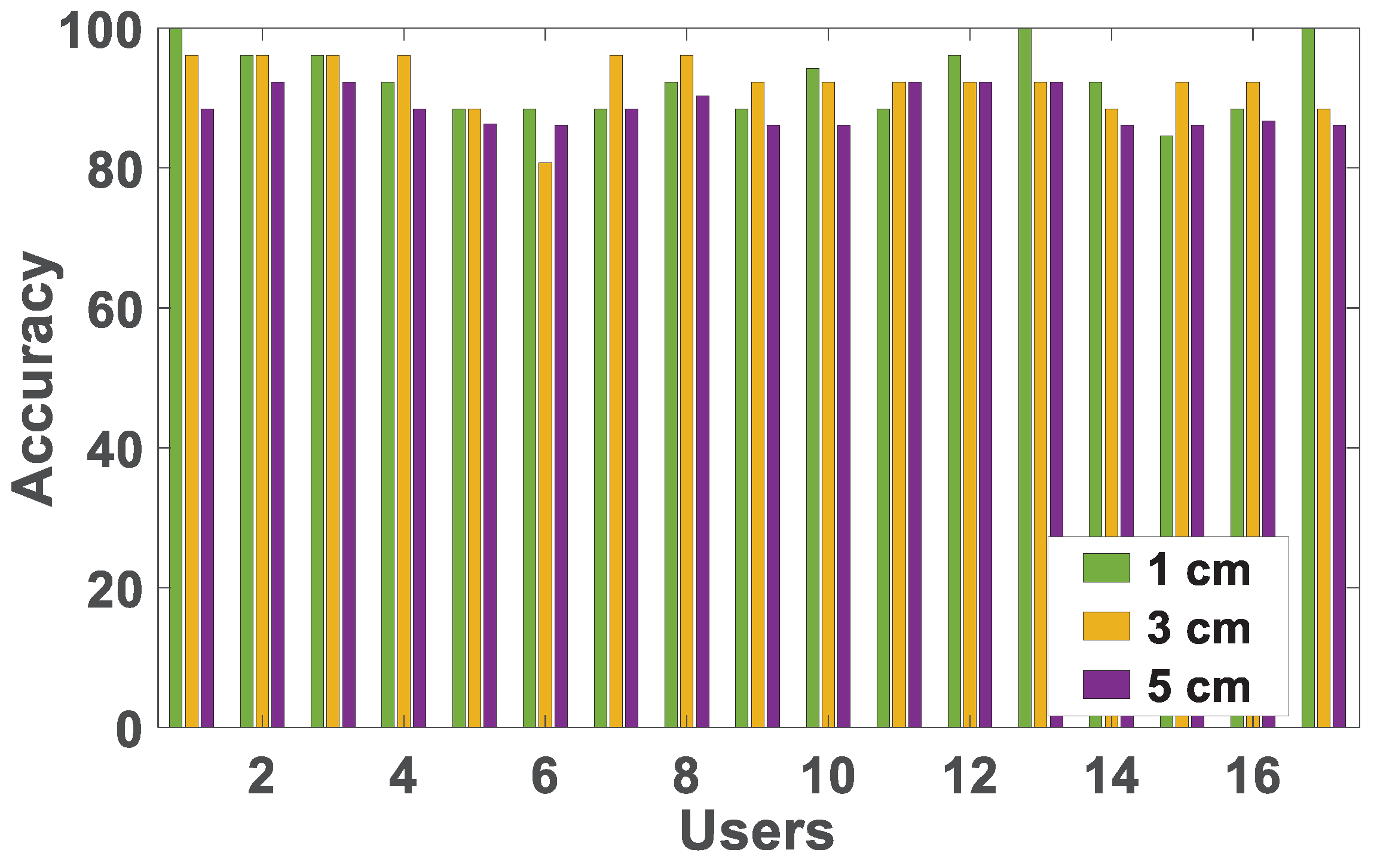
7.5. Impact of Distance
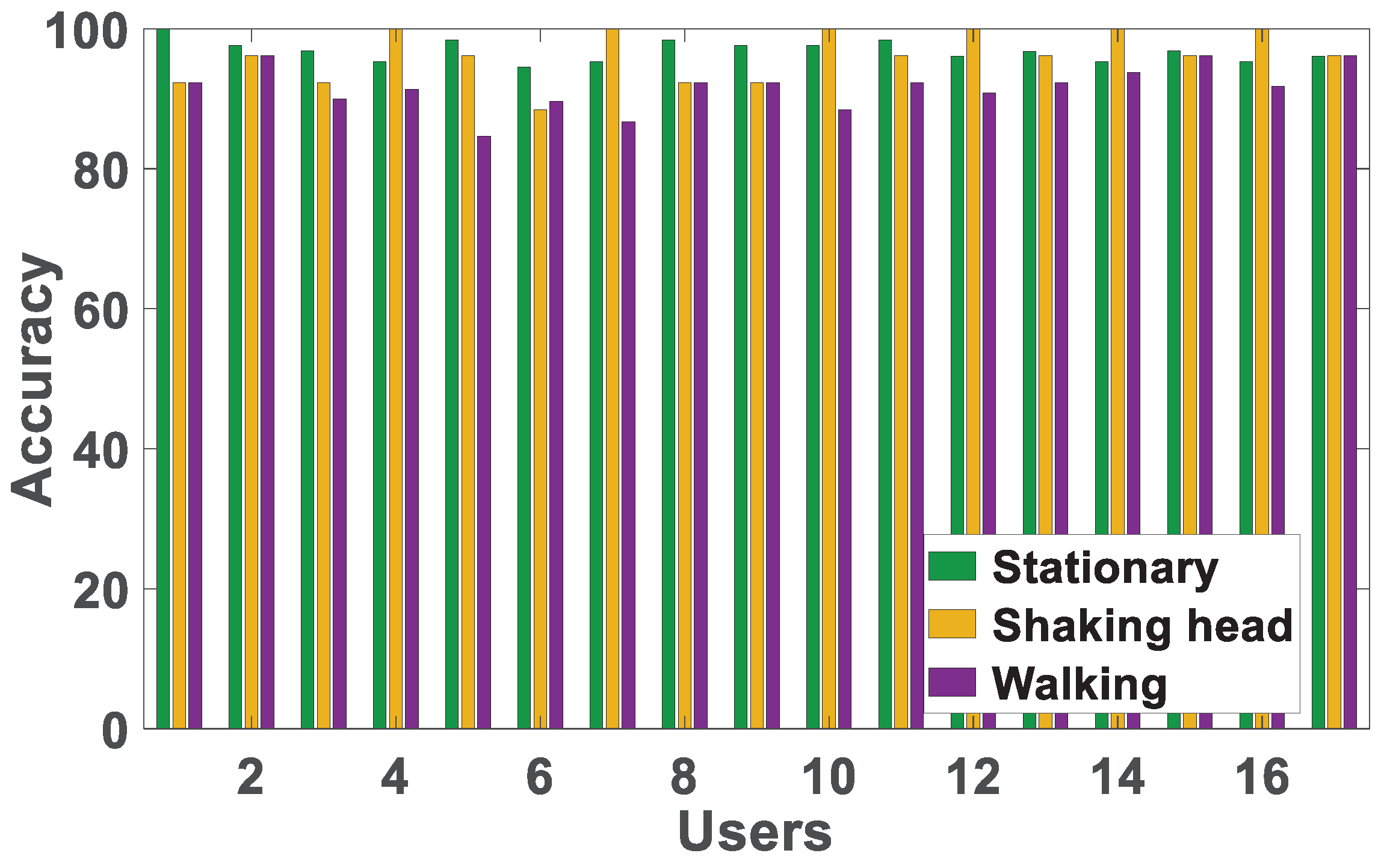
7.6. Impact of Different Behavior
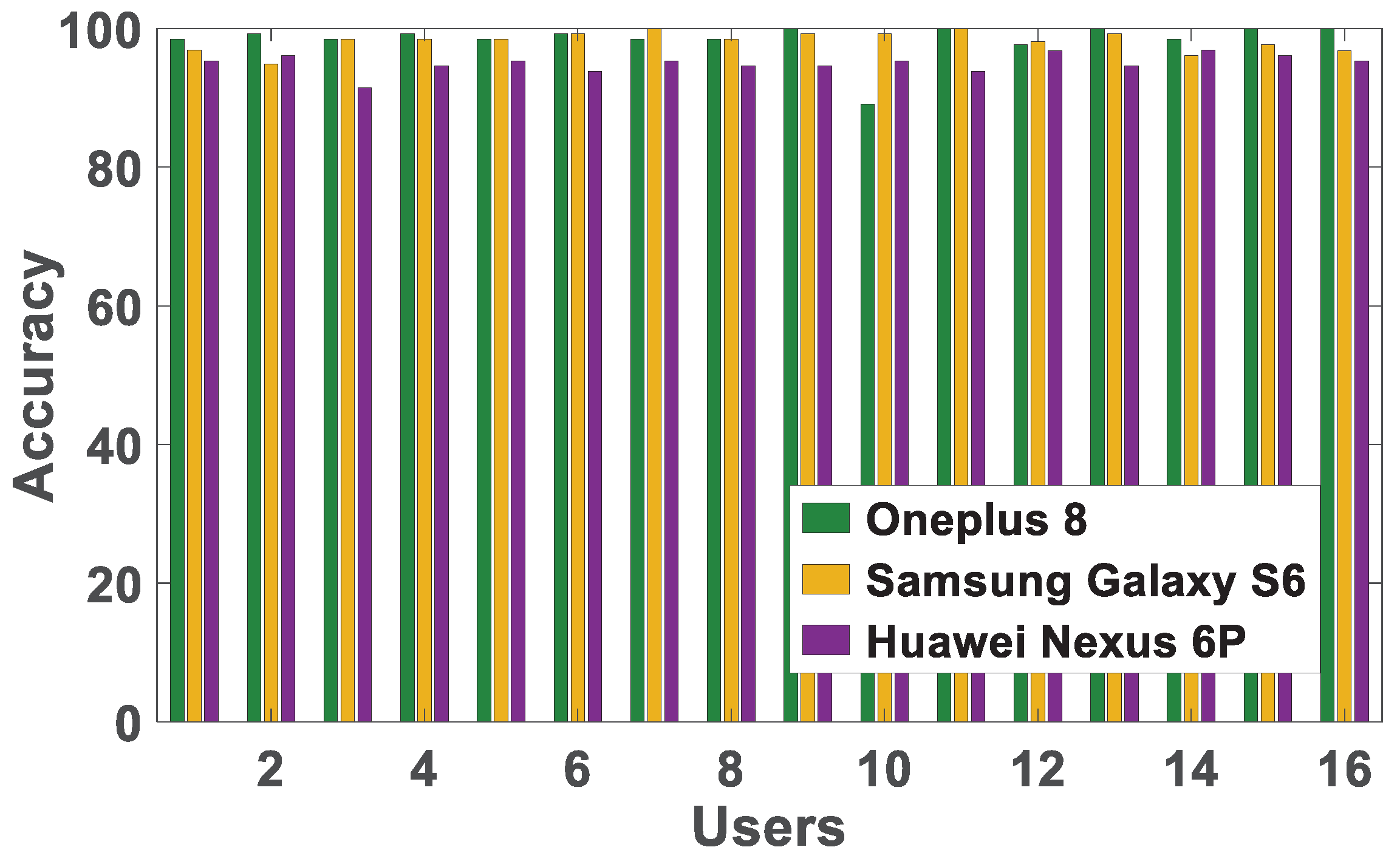
7.7. Impact of Different Devices
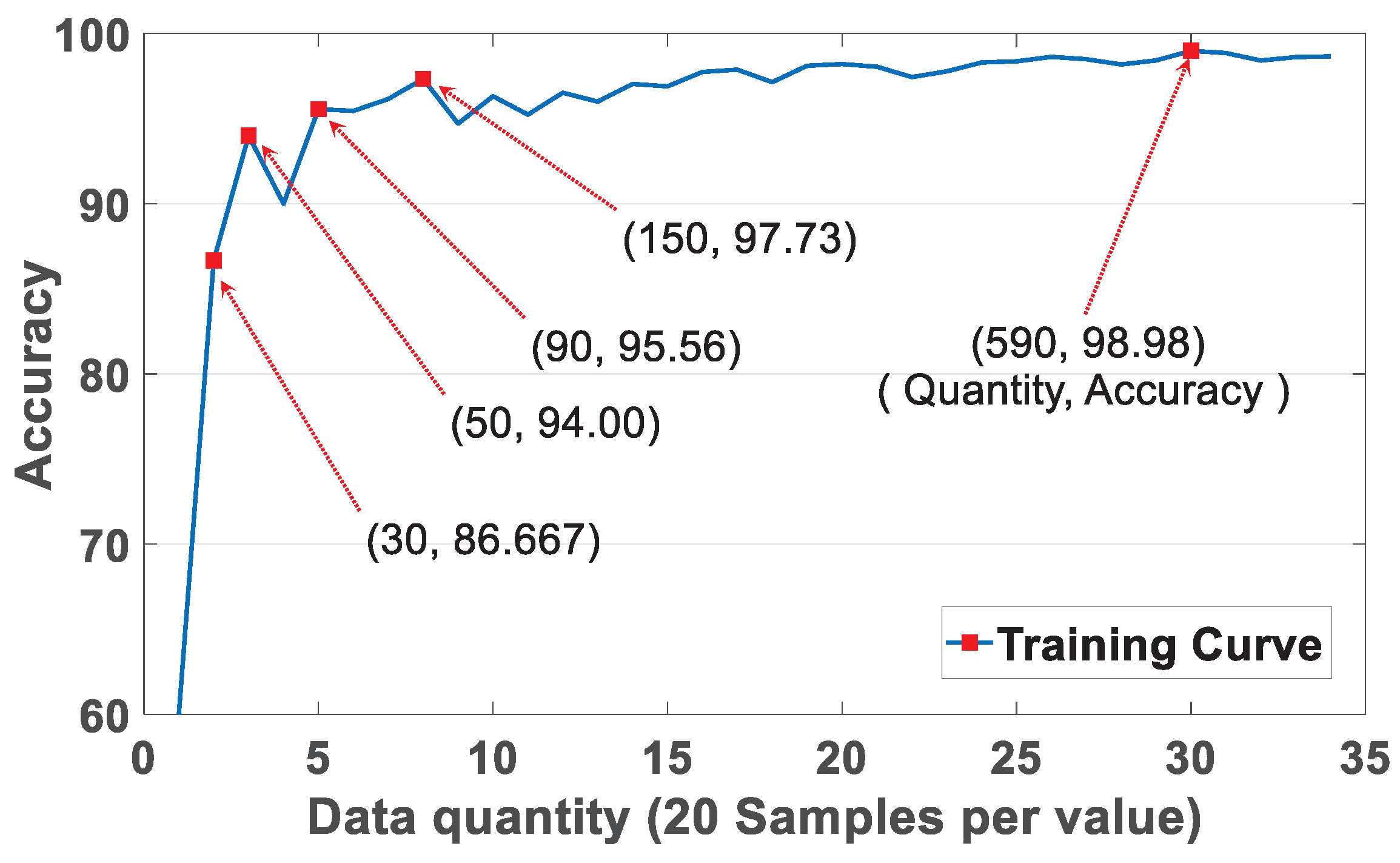
7.8. Impact of Data Quantity
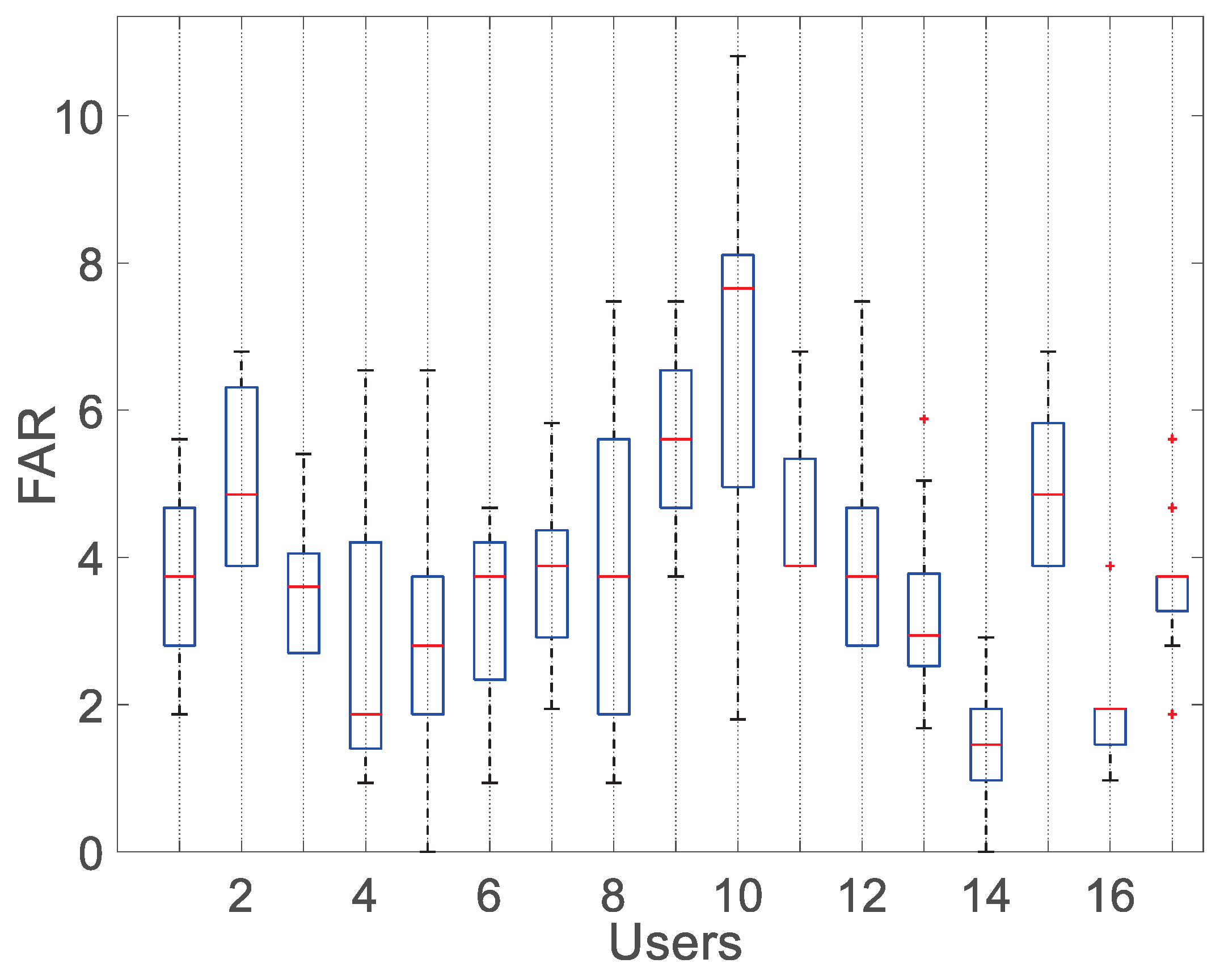
7.9. Efficiency of Attack Defense
7.10. Analysis of Time Efficiency
7.11. Comparison of Different System
8. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Conflicts of Interest
References
- Chen, K.; Zhang, D.; Yao, L.; Guo, B.; Yu, Z.; Liu, Y. Deep Learning for Sensor-Based Human Activity Recognition: Overview, Challenges, and Opportunities. ACM Comput. Surv. 2021, 54, 1–40. [Google Scholar] [CrossRef]
- Choudhury, R.R. Earable Computing: A New Area to Think About. In Proceedings of the 22nd International Workshop on Mobile Computing Systems and Applications, Virtual, 24–26 February 2021; Association for Computing Machinery: New York, NY, USA, 2021. HotMobile ’21. pp. 147–153. [Google Scholar]
- Bhalla, A.; Sluganovic, I.; Krawiecka, K.; Martinovic, I. MoveAR: Continuous Biometric Authentication for Augmented Reality Headsets. In Proceedings of the 7th ACM on Cyber–Physical System Security Workshop, Hong Kong, China, 7 June 2021; pp. 41–52. [Google Scholar]
- Lee, L.H.; Braud, T.; Zhou, P.; Wang, L.; Xu, D.; Lin, Z.; Kumar, A.; Bermejo, C.; Hui, P. All one needs to know about metaverse: A complete survey on technological singularity, virtual ecosystem, and research agenda. arXiv 2021, arXiv:2110.05352. [Google Scholar]
- Biometric Authentication & Identification Market 2022 with Growth Opportunities, Top Countries Data, Future Trends and Business Size and Share with Revenue Forecast to 2026; MarketWatch: New York, NY, USA, 2022.
- Acquisti, A.; Gross, R.; Stutzman, F.D. Face recognition and privacy in the age of augmented reality. J. Priv. Confid. 2014, 6, 1. [Google Scholar] [CrossRef] [Green Version]
- Raghavendra, R.; Raja, K.B.; Busch, C. Presentation attack detection for face recognition using light field camera. IEEE Trans. Image Process. 2015, 24, 1060–1075. [Google Scholar] [CrossRef] [PubMed]
- Boulkenafet, Z.; Komulainen, J.; Li, L.; Feng, X.; Hadid, A. OULU-NPU: A mobile face presentation attack database with real-world variations. In Proceedings of the 2017 12th IEEE International Conference on Automatic Face & Gesture Recognition (FG 2017), Washington, DC, USA, 30 May–3 June 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 612–618. [Google Scholar]
- Komkov, S.; Petiushko, A. Advhat: Real-world adversarial attack on arcface face id system. In Proceedings of the 2020 25th International Conference on Pattern Recognition (ICPR), Milan, Italy, 10–15 January 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 819–826. [Google Scholar]
- ISO—ISO/IEC 30107-1:2016, I.I. Information Technology—Biometric Presentation Attack Detection—Part 1: Framework. Available online: https://www.iso.org/standard/53227.html (accessed on 26 September 2022).
- Zhang, L.; Tan, S.; Yang, J.; Chen, Y. Voicelive: A phoneme localization based liveness detection for voice authentication on smartphones. In Proceedings of the 2016 ACM SIGSAC Conference on Computer and Communications Security, Vienna, Austria, 24–28 October 2016; pp. 1080–1091. [Google Scholar]
- Zhang, L.; Tan, S.; Wang, Z.; Ren, Y.; Wang, Z.; Yang, J. Viblive: A continuous liveness detection for secure voice user interface in iot environment. In Proceedings of the Annual Computer Security Applications Conference, Austin, TX, USA, 7–11 December 2020; pp. 884–896. [Google Scholar]
- Tuyls, P.T.; Verbitskiy, E.; Ignatenko, T.; Schobben, D.; Akkermans, T.H. Privacy-protected biometric templates: Acoustic ear identification. In Biometric Technology for Human Identification; International Society for Optics and Photonics: Bellingham, DC, USA, 2004; Volume 5404, pp. 176–182. [Google Scholar]
- Xu, X.; Gao, H.; Yu, J.; Chen, Y.; Zhu, Y.; Xue, G.; Li, M. ER: Early recognition of inattentive driving leveraging audio devices on smartphones. In Proceedings of the IEEE INFOCOM 2017-IEEE Conference on Computer Communications, Atlanta, GA, USA, 1–4 May 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 1–9. [Google Scholar]
- Xu, X.; Yu, J.; Chen, Y.; Zhu, Y.; Kong, L.; Li, M. Breathlistener: Fine-grained breathing monitoring in driving environments utilizing acoustic signals. In Proceedings of the 17th Annual International Conference on Mobile Systems, Applications, and Services, Seoul, Korea, 17–21 June 2019; pp. 54–66. [Google Scholar]
- Yang, Z.; Choudhury, R.R. Personalizing Head Related Transfer Functions for Earables. In Proceedings of the 2021 ACM SIGCOMM 2021 Conference, Virtual, 23–27 August 2021; Association for Computing Machinery: New York, NY, USA, 2021. SIGCOMM ’21. pp. 137–150. [Google Scholar]
- Prakash, J.; Yang, Z.; Wei, Y.L.; Hassanieh, H.; Choudhury, R.R. EarSense: Earphones as a Teeth Activity Sensor. In Proceedings of the 26th Annual International Conference on Mobile Computing and Networking, London, UK, 21–25 September 2020; Association for Computing Machinery: New York, NY, USA, 2020. [Google Scholar]
- Yang, Z.; Wei, Y.L.; Shen, S.; Choudhury, R.R. Ear-AR: Indoor Acoustic Augmented Reality on Earphones. In Proceedings of the 26th Annual International Conference on Mobile Computing and Networking, London, UK, 21–25 September 2020; Association for Computing Machinery: New York, NY, USA, 2020. [Google Scholar]
- Gao, Y.; Wang, W.; Phoha, V.V.; Sun, W.; Jin, Z. EarEcho: Using ear canal echo for wearable authentication. Proc. ACM Interact. Mob. Wearable Ubiquitous Technol. 2019, 3, 1–24. [Google Scholar] [CrossRef]
- Wang, Z.; Ren, Y.; Chen, Y.; Yang, J. Earable Authentication via Acoustic Toothprint. In Proceedings of the 2021 ACM SIGSAC Conference on Computer and Communications Security, Virtual, 15–19 November 2021; Association for Computing Machinery: New York, NY, USA, 2021. CCS ’21. pp. 2390–2392. [Google Scholar]
- Wang, Z.; Tan, S.; Zhang, L.; Ren, Y.; Wang, Z.; Yang, J. An Ear Canal Deformation Based Continuous User Authentication Using Earables. In Proceedings of the 27th Annual International Conference on Mobile Computing and Networking, New Orleans, LA, USA, 25–29 October 2021; Association for Computing Machinery: New York, NY, USA, 2021. MobiCom ’21. pp. 819–821. [Google Scholar]
- Cai, C.; Pu, H.; Ye, L.; Jiang, H.; Luo, J. Active Acoustic Sensing for Hearing Temperature under Acoustic Interference. In IEEE Transactions on Mobile Computing; IEEE: Piscataway, NJ, USA, 2021; p. 1. [Google Scholar]
- Yun, S.; Chen, Y.C.; Zheng, H.; Qiu, L.; Mao, W. Strata: Fine-grained acoustic-based device-free tracking. In Proceedings of the 15th Annual International Conference on Mobile Systems, Applications, and Services, New York, NY, USA, 19–23 June 2017; pp. 15–28. [Google Scholar]
- Wang, W.; Liu, A.X.; Sun, K. Device-free gesture tracking using acoustic signals. In Proceedings of the 22nd Annual International Conference on Mobile Computing and Networking, New York, NY, USA, 3–7 October 2016; pp. 82–94. [Google Scholar]
- Cai, C.; Pu, H.; Wang, P.; Chen, Z.; Luo, J. We Hear Your PACE: Passive Acoustic Localization of Multiple Walking Persons. Proc. ACM Interact. Mob. Wearable Ubiquitous Technol. 2021, 5, 1–24. [Google Scholar] [CrossRef]
- Ling, K.; Dai, H.; Liu, Y.; Liu, A.X.; Wang, W.; Gu, Q. Ultragesture: Fine-grained gesture sensing and recognition. IEEE Trans. Mob. Comput. 2020, 21, 2620–2636. [Google Scholar] [CrossRef]
- Ruan, W.; Sheng, Q.Z.; Yang, L.; Gu, T.; Xu, P.; Shangguan, L. AudioGest: Enabling fine-grained hand gesture detection by decoding echo signal. In Proceedings of the 2016 ACM International Joint Conference on Pervasive and Ubiquitous Computing, Heidelberg, Germany, 12–16 September 2016; pp. 474–485. [Google Scholar]
- Zheng, T.; Chao, C.; Chen, Z.; Luo, J. Sound of Motion: Real-time Wrist Tracking with A Smart Watch-Phone Pair. In Proceedings of the IEEE INFOCOM 2022-IEEE Conference on Computer Communications, London, UK, 2–5 May 2022. [Google Scholar]
- Feng, H.; Fawaz, K.; Shin, K.G. Continuous Authentication for Voice Assistants. In Proceedings of the 23rd Annual International Conference on Mobile Computing and Networking, Snowbird, UT, USA, 16–20 October 2017; Association for Computing Machinery: New York, NY, USA, 2017. MobiCom ’17. pp. 343–355. [Google Scholar]
- Xie, Y.; Li, F.; Wu, Y.; Chen, H.; Zhao, Z.; Wang, Y. TeethPass: Dental Occlusion-based User Authentication via In-ear Acoustic Sensing. In Proceedings of the IEEE INFOCOM 2022-IEEE Conference on Computer Communications, London, UK, 2–5 May 2022. [Google Scholar]
- Lu, L.; Yu, J.; Chen, Y.; Wang, Y. Vocallock: Sensing vocal tract for passphrase-independent user authentication leveraging acoustic signals on smartphones. Proc. ACM Interact. Mob. Wearable Ubiquitous Technol. 2020, 4, 1–24. [Google Scholar] [CrossRef]
- Lu, L.; Yu, J.; Chen, Y.; Liu, H.; Zhu, Y.; Kong, L.; Li, M. Lip Reading-Based User Authentication Through Acoustic Sensing on Smartphones. IEEE/ACM Trans. Netw. 2019, 27, 447–460. [Google Scholar] [CrossRef]
- Zhou, M.; Wang, Q.; Li, Q.; Jiang, P.; Yang, J.; Shen, C.; Wang, C.; Ding, S. Securing Face Liveness Detection Using Unforgeable Lip Motion Patterns. arXiv 2021, arXiv:2106.08013. [Google Scholar]
- Kong, H.; Lu, L.; Yu, J.; Chen, Y.; Xu, X.; Tang, F.; Chen, Y.C. MultiAuth: Enable Multi-User Authentication with Single Commodity WiFi Device. In Proceedings of the Twenty-Second International Symposium on Theory, Algorithmic Foundations, and Protocol Design for Mobile Networks and Mobile Computing, Shanghai, China, 26–29 July 2021; Association for Computing Machinery: New York, NY, USA, 2021. MobiHoc ’21. pp. 31–40. [Google Scholar]
- Shi, C.; Liu, J.; Liu, H.; Chen, Y. WiFi-Enabled User Authentication through Deep Learning in Daily Activities. ACM Trans. Internet Things 2021, 2, 1–25. [Google Scholar] [CrossRef]
- Zhao, T.; Wang, Y.; Liu, J.; Chen, Y. Your Heart Won’t Lie: PPG-Based Continuous Authentication on Wrist-Worn Wearable Devices. In Proceedings of the 24th Annual International Conference on Mobile Computing and Networking, New Delhi, India, 29 October–2 November 2018; Association for Computing Machinery: New York, NY, USA, 2018. MobiCom ’18. pp. 783–785. [Google Scholar]
- Qian, K.; Wu, C.; Xiao, F.; Zheng, Y.; Zhang, Y.; Yang, Z.; Liu, Y. Acousticcardiogram: Monitoring heartbeats using acoustic signals on smart devices. In Proceedings of the IEEE INFOCOM 2018-IEEE Conference on Computer Communications, Honolulu, HI, USA, 16–19 April 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 1574–1582. [Google Scholar]
- Lin, F.; Song, C.; Zhuang, Y.; Xu, W.; Li, C.; Ren, K. Cardiac Scan: A Non-Contact and Continuous Heart-Based User Authentication System. In Proceedings of the 23rd Annual International Conference on Mobile Computing and Networking, Snowbird, UT, USA, 16–20 October 2017; Association for Computing Machinery: New York, NY, USA, 2017. MobiCom ’17. pp. 315–328. [Google Scholar]
- Wang, T.; Zhang, D.; Zheng, Y.; Gu, T.; Zhou, X.; Dorizzi, B. C-FMCW Based Contactless Respiration Detection Using Acoustic Signal. Proc. ACM Interact. Mob. Wearable Ubiquitous Technol. 2018, 1, 1–20. [Google Scholar] [CrossRef]
- Chen, Y.; Xue, M.; Zhang, J.; Guan, Q.; Wang, Z.; Zhang, Q.; Wang, W. ChestLive: Fortifying Voice-based Authentication with Chest Motion Biometric on Smart Devices. Proc. ACM Interact. Mob. Wearable Ubiquitous Technol. 2021, 5, 1–25. [Google Scholar] [CrossRef]
- Eberz, S.; Rasmussen, K.B.; Lenders, V.; Martinovic, I. Evaluating Behavioral Biometrics for Continuous Authentication: Challenges and Metrics. In Proceedings of the 2017 ACM on Asia Conference on Computer and Communications Security, Abu Dhabi, UAE, 2–6 April 2017; Association for Computing Machinery: New York, NY, USA, 2017. ASIA CCS ’17. pp. 386–399. [Google Scholar]
- Zhang, Y.; Hu, W.; Xu, W.; Chou, C.T.; Hu, J. Continuous Authentication Using Eye Movement Response of Implicit Visual Stimuli. Proc. ACM Interact. Mob. Wearable Ubiquitous Technol. 2018, 1, 1–22. [Google Scholar] [CrossRef]
- Liu, J.; Li, D.; Wang, L.; Xiong, J. BlinkListener: “Listen” to Your Eye Blink Using Your Smartphone. Proc. ACM Interactive Mob. Wearable Ubiquitous Technol. 2021, 5, 1–27. [Google Scholar] [CrossRef]
- Kinnunen, T.; Sahidullah, M.; Delgado, H.; Todisco, M.; Evans, N.; Yamagishi, J.; Lee, K.A. The ASVspoof 2017 Challenge: Assessing the Limits of Replay Spoofing Attack Detection. In Proceedings of the 18th Annual Conference of the International Speech Communication Association, Stockholm, Sweden, 20–24 August 2017; pp. 2–6. [Google Scholar]
- Huang, W.; Tang, W.; Jiang, H.; Luo, J.; Zhang, Y. Stop Deceiving! An Effective Defense Scheme Against Voice Impersonation Attacks on Smart Devices. IEEE Internet Things J. 2022, 9, 5304–5314. [Google Scholar] [CrossRef]
- Gao, Y.; Jin, Y.; Chauhan, J.; Choi, S.; Li, J.; Jin, Z. Voice In Ear: Spoofing-Resistant and Passphrase-Independent Body Sound Authentication. Proc. ACM Interact. Mob. Wearable Ubiquitous Technol. 2021, 5, 1–25. [Google Scholar] [CrossRef]
- Kates, J.M. A computer simulation of hearing aid response and the effects of ear canal size. J. Acoust. Soc. Am. 1988, 83, 1952–1963. [Google Scholar] [CrossRef] [PubMed]
- Rappaport, T.S. Wireless Communications: Principles and Practice; Prentice Hall PTR: Hoboken, NJ, USA, 1996; Volume 2. [Google Scholar]
- Adib, F.; Katabi, D. See through walls with WiFi! In Proceedings of the ACM SIGCOMM 2013 Conference on SIGCOMM, Hong Kong, China, 12–16 August 2013; pp. 75–86. [Google Scholar]
- Sun, K.; Zhao, T.; Wang, W.; Xie, L. Vskin: Sensing touch gestures on surfaces of mobile devices using acoustic signals. In Proceedings of the 24th Annual International Conference on Mobile Computing and Networking, New Delhi, India, 29 October–2 November 2018; pp. 591–605. [Google Scholar]
- Zhou, Z.; Diao, W.; Liu, X.; Zhang, K. Acoustic fingerprinting revisited: Generate stable device id stealthily with inaudible sound. In Proceedings of the 2014 ACM SIGSAC Conference on Computer and Communications Security, Scottsdale, AZ, USA, 3–7 November 2014; pp. 429–440. [Google Scholar]
- Han, D.; Chen, Y.; Li, T.; Zhang, R.; Zhang, Y.; Hedgpeth, T. Proximity-proof: Secure and usable mobile two-factor authentication. In Proceedings of the 24th Annual International Conference on Mobile Computing and Networking, New Delhi, India, 29 October–2 November 2018; pp. 401–415. [Google Scholar]
- Chang, C.C.; Lin, C.J. LIBSVM: A library for support vector machines. ACM Trans. Intell. Syst. Technol. (TIST) 2011, 2, 1–27. [Google Scholar] [CrossRef]
- Wang, Z.; Tan, S.; Zhang, L.; Ren, Y.; Wang, Z.; Yang, J. EarDynamic: An Ear Canal Deformation Based Continuous User Authentication Using In-Ear Wearables. Proc. ACM Interact. Mob. Wearable Ubiquitous Technol. 2021, 5, 1–27. [Google Scholar] [CrossRef]


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Phase | Pre | Denoise | Ali | SIC | Seg | FE | Train | Auth | Total |
|---|---|---|---|---|---|---|---|---|---|
| Reg(s) | 0.364 | 0.414 | 0.880 | 0.883 | 20.056 | 0.544 | 1.335 | None | 24.476 |
| Login(s) | 0.015 | 0.018 | 0.008 | 0.009 | 0.273 | 0.022 | None | 0.594 | 0.939 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chang, Z.; Wang, L.; Li, B.; Liu, W. MetaEar: Imperceptible Acoustic Side Channel Continuous Authentication Based on ERTF. Electronics 2022, 11, 3401. https://doi.org/10.3390/electronics11203401
Chang Z, Wang L, Li B, Liu W. MetaEar: Imperceptible Acoustic Side Channel Continuous Authentication Based on ERTF. Electronics. 2022; 11(20):3401. https://doi.org/10.3390/electronics11203401
Chicago/Turabian StyleChang, Zhuo, Lin Wang, Binbin Li, and Wenyuan Liu. 2022. "MetaEar: Imperceptible Acoustic Side Channel Continuous Authentication Based on ERTF" Electronics 11, no. 20: 3401. https://doi.org/10.3390/electronics11203401