
A Lightweight Learning Method for Stochastic Configuration Networks Using Non-Inverse Solution

Abstract
:1. Introduction
- To avoid adopting M–P generalized inverse with SVD, a positive definite equation for solving output weights is established based on normal equation theory to replace the over-determined equation;
- The consistency of the solutions of the positive definite equation and the over-determined equation in calculating the output weights is proved;
- A low complexity method for solving the positive definite equations based on Cholesky decomposition is proposed.
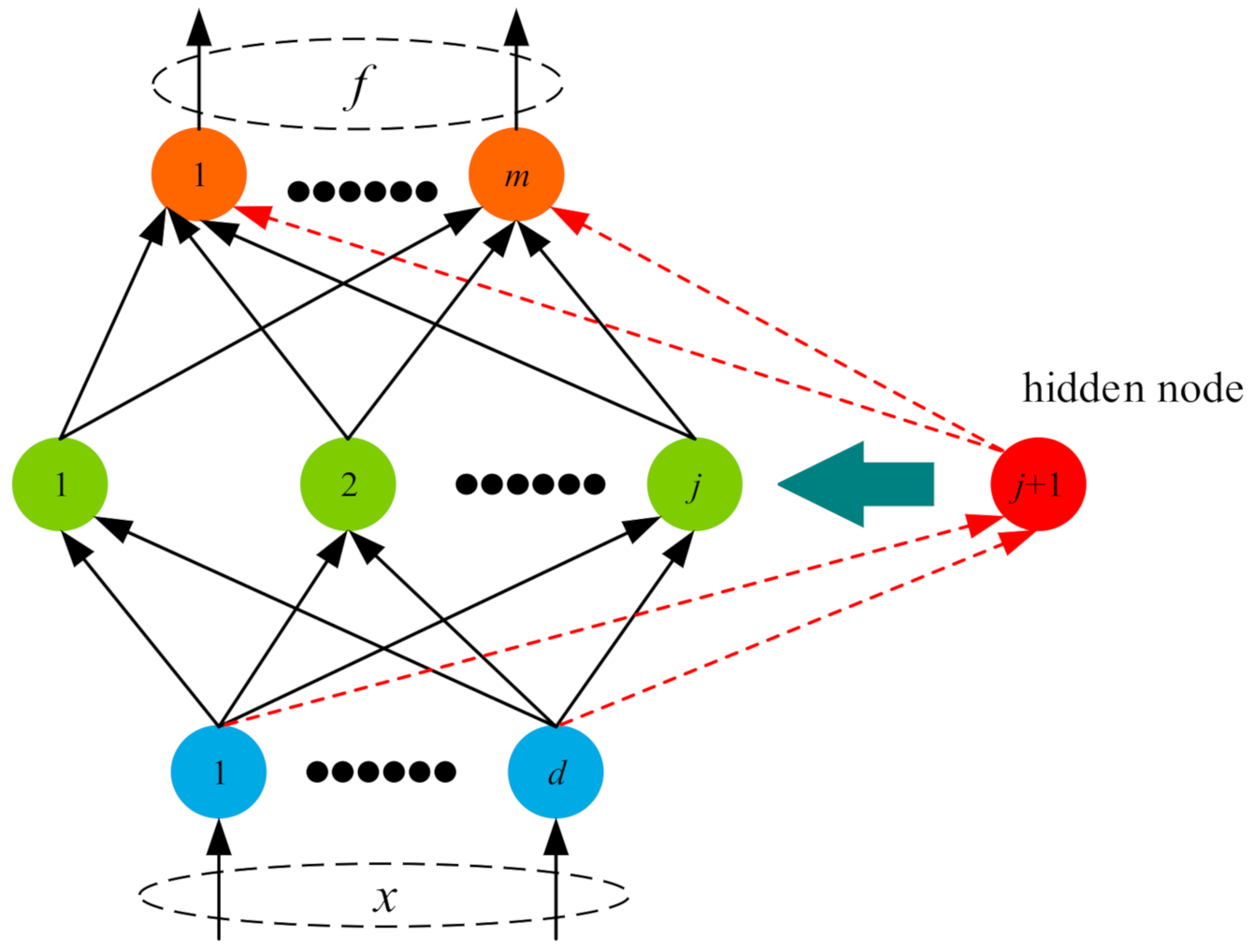
2. Brief Review of SCNs
3. L-SCNs Method
3.1. Positive Definite Equation
3.2. SCNs with Cholesky Decomposition
| Algorithm 1 L-SCNs |
| Inputs: , Outputs: , Initialization parameters: as the maximum times of random configuration, as the maximum number of hidden nodes, as the error tolerance, |
| 1. Initialization: , set and , , 2. While or , Do (1). Hidden Node Parameters Configuration (3–20) 3. For , Do 4. For , Do 5. Randomly assign hidden nodes (, ) from and , respectively, 6. Calculate based on , set and calculate by Equation (3) 7. If 8. Save in W, and in 9. Else 10. go to back to step 4 11. End If 12. End For (step4) 13. If W is not empty 14. Find that maximize in 15. Set 16. Break (step 21) 17. Else 18. Randomly take and let 19. End If 20. End For (step 3) (2). Evaluate the Output Weights (21–28) 21. Obtain 22. Calculate A by Equation (14) 23. Calculate S by Equation (16) 24. Calculate by Equations (18)–(20) 25. Calculate 26. Update , 27. End While 28. Return , , |
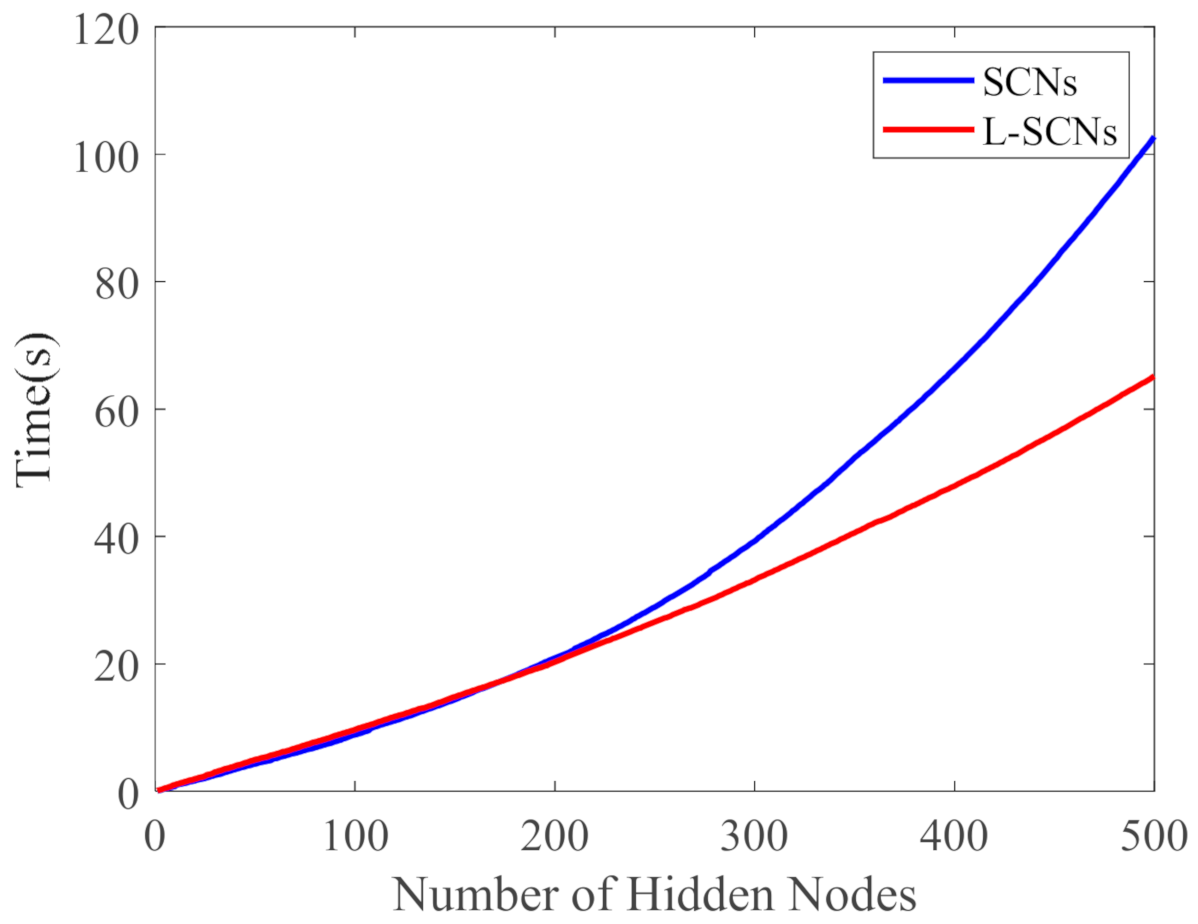
3.3. Computational Complexity Analysis
4. Experiments
4.1. Data Sets Description
4.2. Experimental Setup
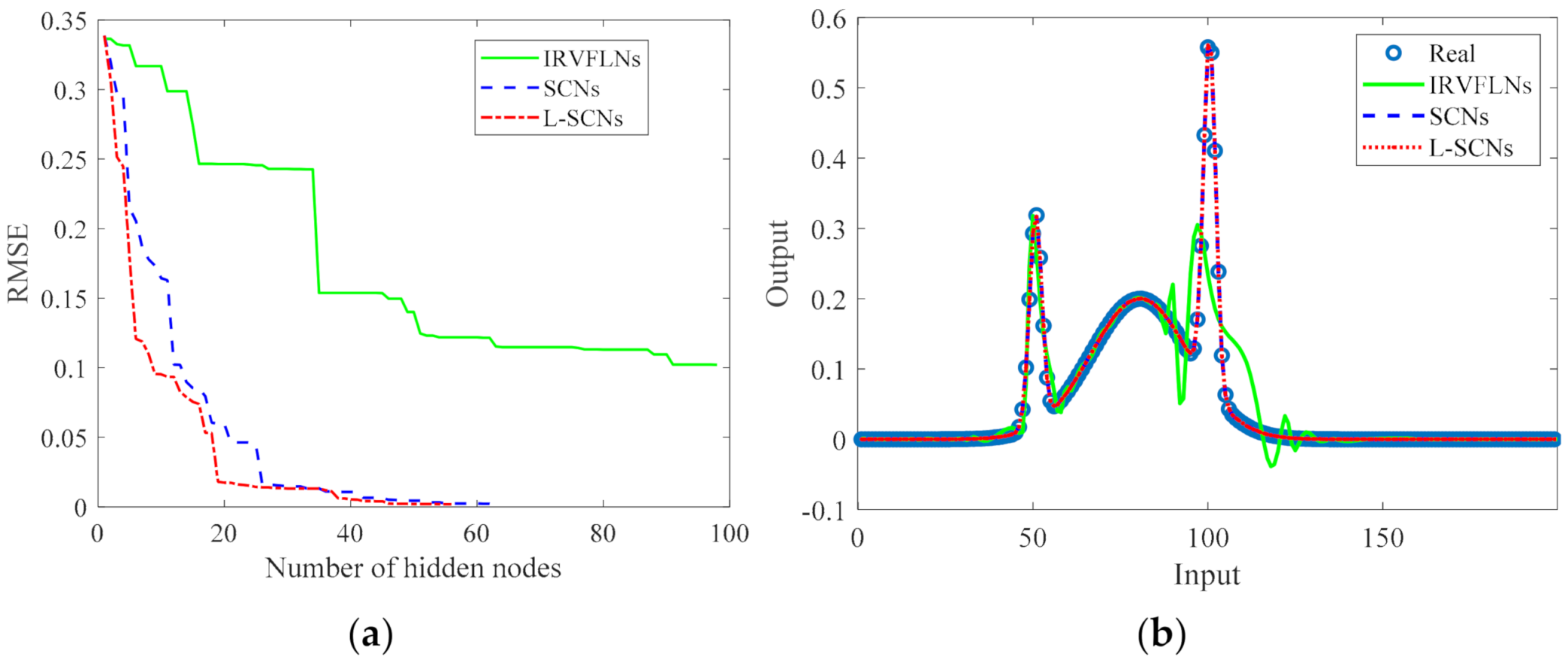
4.3. Performance Comparison
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Han, F.; Jiang, I.; Ling, Q.H.; Su, B.H. A survey on metaheuristic optimization for random single-hidden layer feedforward neural network. Neurocomputing 2019, 335, 261–273. [Google Scholar] [CrossRef]
- Tamura, S.; Tateishi, M. Capabilities of a four-layered feedforward neural network: Four layers versus three. IEEE Trans. Neural Netw. 1997, 8, 251–255. [Google Scholar] [CrossRef] [PubMed]
- Wu, X.; Rozycki, P.; Wilamowski, B.M. A Hybrid Constructive Algorithm for Single-Layer Feedforward Networks Learning. IEEE Trans. Neural Netw. Learn. Syst. 2017, 26, 1659–1668. [Google Scholar] [CrossRef] [PubMed]
- Igelnik, B.; Pao, Y.H. Stochastic choice of basis functions in adaptive function approximation and the functional-link net. IEEE Trans. Neural Netw. 1995, 6, 1320–1329. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Pao, Y.H.; Takefuji, Y. Functional-link net computing: Theory, system architecture, and functionalities. Computer 1992, 25, 76–79. [Google Scholar] [CrossRef]
- Wang, D.H.; Li, M. Stochastic Configuration Networks: Fundamentals and Algorithms. IEEE Trans. Cybern. 2017, 47, 3466–3479. [Google Scholar] [CrossRef] [Green Version]
- Wang, D.H.; Cui, C.H. Stochastic Configuration Networks Ensemble for Large-Scale Data Analytics. Inf. Sci. 2017, 417, 55–71. [Google Scholar] [CrossRef] [Green Version]
- Dai, W.; Li, D.P.; Zhou, P.; Chai, T.Y. Stochastic configuration networks with block increments for data modeling in process industries. Inf. Sci. 2019, 484, 367–386. [Google Scholar] [CrossRef]
- Tian, Q.; Yuan, S.J.; Qu, H.Q. Intrusion signal classification using stochastic configuration network with variable increments of hidden nodes. Opt. Eng. 2019, 58, 026105.1–026105.8. [Google Scholar] [CrossRef]
- Dai, W.; Zhou, X.Y.; Li, D.P.; Zhu, S.; Wang, X.S. Hybrid Parallel Stochastic Configuration Networks for Industrial Data Analytics; IEEE Transactions on Industrial Informatics: Piscataway, NJ, USA, 2021. [Google Scholar] [CrossRef]
- Wang, D.H.; Li, M. Robust Stochastic Configuration Networks with Kernel Density Estimation for Uncertain Data Regression. Inf. Sci. 2017, 412, 210–222. [Google Scholar] [CrossRef]
- Li, M.; Huang, C.Q.; Wang, D.H. Robust stochastic configuration networks with maximum correntropy criterion for uncertain data regression. Inf. Sci. 2018, 473, 73–86. [Google Scholar] [CrossRef]
- Wang, D.H.; Li, M. Deep Stochastic Configuration Networks: Universal Approximation and Learning Representation. In Proceedings of the IEEE International Joint Conference on Neural Networks, Anchorage, AK, USA, 14–19 May 2017. [Google Scholar]
- Pratama, M.; Wang, D.H. Deep Stacked Stochastic Configuration Networks for Non-Stationary Data Streams. Inf. Sci. 2018, 495, 150–174. [Google Scholar] [CrossRef] [Green Version]
- Lu, J.; Ding, J.L. Construction of prediction intervals for carbon residual of crude oil based on deep stochastic configuration networks. Inf. Sci. 2019, 486, 119–132. [Google Scholar] [CrossRef]
- Li, M.; Wang, D.H. 2-D Stochastic Configuration Networks for Image Data Analytics. IEEE Trans. Cybern. 2021, 51, 359–372. [Google Scholar] [CrossRef]
- Lu, J.; Ding, J.L.; Dai, X.W.; Chai, T.Y. Ensemble Stochastic Configuration Networks for Estimating Prediction Intervals: A Simultaneous Robust Training Algorithm and Its Application. IEEE Trans. Neural Netw. Learn. Syst. 2020, 31, 5426–5440. [Google Scholar] [CrossRef] [PubMed]
- Lu, J.; Ding, J.L.; Liu, C.X.; Chai, T.Y. Hierarchical-Bayesianbased sparse stochastic configuration networks for construction of prediction intervals. IEEE Trans. Neural Netw. Learn. Syst. 2021, 1–2. [Google Scholar] [CrossRef]
- Lu, J.; Ding, J.L. Mixed-distribution-based robust stochastic configuration networks for prediction interval construction. IEEE Trans. Ind. Inform. 2020, 16, 5099–5109. [Google Scholar] [CrossRef]
- Sheng, Z.Y.; Zeng, Z.Q.; Qu, H.Q.; Zhang, Y. Optical fiber intrusion signal recognition method based on TSVD-SCN. Opt. Fiber Technol. 2019, 48, 270–277. [Google Scholar] [CrossRef]
- Xie, J.; Zhou, P. Robust Stochastic Configuration Network Multi-Output Modeling of Molten Iron Quality in Blast Furnace Ironmaking. Neurocomputing 2020, 387, 139–149. [Google Scholar] [CrossRef]
- Zhao, J.H.; Hu, T.Y.; Zheng, R.F.; Ba, P.H. Defect Recognition in Concrete Ultrasonic Detection Based on Wavelet Packet Transform and Stochastic Configuration Networks. IEEE Access 2021, 99, 9284–9295. [Google Scholar] [CrossRef]
- Salmerón, M.; Ortega, J.; Puntonet, C.G.; Prieto, A. Improved RAN sequential prediction using orthogonal techniques. Neurocomputing 2001, 41, 153–172. [Google Scholar] [CrossRef]
- Qu, H.Q.; Feng, T.L.; Zhang, Y. Ensemble Learning with Stochastic Configuration Network for Noisy Optical Fiber Vibration Signal Recognition. Sensors 2019, 19, 3293. [Google Scholar] [CrossRef] [Green Version]
- Liu, J.; Hao, R.; Zhang, T.; Wang, X.Z. Vibration fault diagnosis based on stochastic configuration neural networks. Neurocomputing 2021, 434, 98–125. [Google Scholar] [CrossRef]
- Krein, S.G. Overdetermined Equations; Birkhäuser: Basel, Switzerland, 1982. [Google Scholar]
- Loboda, A.V. Determination of a Homogeneous Strictly Pseudoconvex Surface from the Coefficients of Its Normal Equation. Math. Notes 2003, 73, 419–423. [Google Scholar] [CrossRef]
- Roverato, A. Cholesky decomposition of a hyper inverse Wishart matrix. Biometrika 2000, 87, 99–112. [Google Scholar] [CrossRef]
- Anguita, S.; Ghio, A.; Oneto, L.; Parra, X. Energy efficient smartphone-based activity recognition using fixed-point arithmetic. J. Univers. Comput. 2013, 19, 1295–1314. [Google Scholar]
- Fdez, J.A.; Fernandez, A.; Luengo, J.; Derrac, J.; Garacia, S.; Herrera, F. KEEL Data-Mining Software Tool: Data Set Repository, Integration of Algorithms and Experimental Analysis Framework. J. Mult.-Valued Log. Soft Comput. 2011, 17, 255–287. [Google Scholar]
- Tyukin, I.Y.; Prokhorov, D.V. Feasibility of random basis function approximators for modeling and control. In Proceedings of the IEEE Control Applications, (CCA) & Intelligent Control, St. Petersburg, Russia, 8–10 July 2009; pp. 1391–1396. [Google Scholar]
- Li, M.; Wang, D.H. Insights into randomized algorithms for neural networks: Practical issues and common pitfalls. Inf. Sci. 2017, 382, 170–178. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
| Data Sets | No. of Sample | Attributes | Classes | ||
|---|---|---|---|---|---|
| Training Data | Test Data | ||||
| Regression | nonlinear function | 800 | 200 | 1 | - |
| Abalone | 2000 | 2177 | 7 | - | |
| Compactiv | 6144 | 2048 | 21 | - | |
| winequality-white | 3428 | 1470 | 12 | - | |
| delta_ail | 4990 | 2139 | 5 | - | |
| california | 14,448 | 6192 | 8 | - | |
| Classification | Iris | 120 | 30 | 4 | 3 |
| HAR | 7352 | 2947 | 561 | 6 | |
| wine | 142 | 36 | 13 | 3 | |
| Data Sets | Expected Error | |||
|---|---|---|---|---|
| IRVFLNs | SCNs | L-SCNs | ||
| nonlinear function | 100, {1}, 1 | 100, {150:10:200}, 20 | 100, {150:10:200}, 20 | |
| Abalone | 100, {1}, 1 | 100, {150:10:200}, 20 | 100, {150:10:200}, 20 | |
| Compactiv | 200, {1}, 1 | 200, {10:1:20}, 20 | 200, {10:1:20}, 20 | |
| winequality-white | 100, {1}, 1 | 100, {10:1:20}, 10 | 100, {10:1:20}, 10 | |
| delta_ail | 100, {0.5}, 1 | 50, {0.5:0.1:10}, 10 | 50, {0.5:0.1:10}, 10 | |
| california | 50, {1}, 1 | 50, {1:1:10}, 10 | 50, {1:1:10}, 10 | |
| Iris | 200, {10}, 1 | 100, {10:0.5:20}, 20 | 100, {10:0.5:20}, 20 | |
| HAR | 500, {50}, 1 | 500, {1:1:10}, 20 | 500, {1:1:10}, 20 | |
| wine | 200, {0.5}, 1 | 100, {0.5:0.5:10}, 20 | 100, {0.5:0.5:10}, 20 | |
| Models | L | t (s) | Training Error | Testing Error |
|---|---|---|---|---|
| IRVFLNs | 100 | 0.3657 | 0.0720 | 0.0714 |
| SCNs | 63.20 | 0.1500 | 0.0016 | 0.0016 |
| L-SCNs | 56.17 | 0.1218 | 0.0015 | 0.0014 |
| Data Sets | Models | L | t (s) | Training Error | Testing Error |
|---|---|---|---|---|---|
| Abalone | IRVFLNs | 100 | 0.2711 | 0.1895 | 0.1977 |
| SCNs | 32.33 | 0.1874 | 0.1599 | 0.1641 | |
| L-SCNs | 8.67 | 0.1391 | 0.1590 | 0.1601 | |
| Compactiv | IRVFLNs | 200 | 0.6385 | 0.1770 | 0.1862 |
| SCNs | 27 | 0.2216 | 0.1465 | 0.1541 | |
| L-SCNs | 16.67 | 0.1856 | 0.1418 | 0.1501 | |
| winequality-white | IRVFLNs | 100 | 0.5604 | 0.2325 | 0.2472 |
| SCNs | 100 | 0.94 | 0.2276 | 0.2536 | |
| L-SCNs | 100 | 0.89 | 0.2264 | 0.2487 | |
| california | IRVFLNs | 23.57 | 0.12 | 0.1088 | 0.1101 |
| SCNs | 16.33 | 0.14 | 0.1178 | 0.1171 | |
| L-SCNs | 10.33 | 0.14 | 0.1144 | 0.1155 | |
| delta_ail | IRVFLNs | 27.67 | 0.09 | 0.2098 | 0.2163 |
| SCNs | 11.33 | 0.10 | 0.2095 | 0.2113 | |
| L-SCNs | 9.33 | 0.12 | 0.2029 | 0.2107 |
| Data Sets | Models | L | t (s) | Training Error | Testing Error |
|---|---|---|---|---|---|
| Iris | IRVFLNs | 107.2 | 0.1947 | 0 | 0.1667 |
| SCNs | 74.33 | 0.1424 | 0 | 0.0667 | |
| L-SCNs | 71.67 | 0.1237 | 0 | 0.0556 | |
| HAR | IRVFLNs | 1000 | 59.36 | 0.0350 | 0.0763 |
| SCNs | 264.5 | 26.72 | 0.0322 | 0.0747 | |
| L-SCNs | 251.5 | 16.02 | 0.0322 | 0.0658 | |
| wine | IRVFLNs | 117.8 | 0.3871 | 0 | 0.1611 |
| SCNs | 97.33 | 0.2615 | 0 | 0.0695 | |
| L-SCNs | 90.00 | 0.1722 | 0 | 0.0667 |
| Methods | 100 | 200 | 300 | 400 | 500 |
|---|---|---|---|---|---|
| SVD | 6.33 s | 16.61 s | 35.47 s | 64.79 s | 107.78 s |
| LDL | 5.78 s | 14.00 s | 30.96 s | 49.54 s | 76.22 s |
| QR | 5.59 s | 13.69 s | 26.17 s | 44.03 s | 69.12 s |
| Cholesky | 5.53 s | 13.48 s | 25.83 s | 43.67 s | 68.27 s |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Nan, J.; Jian, Z.; Ning, C.; Dai, W. A Lightweight Learning Method for Stochastic Configuration Networks Using Non-Inverse Solution. Electronics 2022, 11, 262. https://doi.org/10.3390/electronics11020262
Nan J, Jian Z, Ning C, Dai W. A Lightweight Learning Method for Stochastic Configuration Networks Using Non-Inverse Solution. Electronics. 2022; 11(2):262. https://doi.org/10.3390/electronics11020262
Chicago/Turabian StyleNan, Jing, Zhonghua Jian, Chuanfeng Ning, and Wei Dai. 2022. "A Lightweight Learning Method for Stochastic Configuration Networks Using Non-Inverse Solution" Electronics 11, no. 2: 262. https://doi.org/10.3390/electronics11020262