
Reducing Parameters of Neural Networks via Recursive Tensor Approximation



Abstract
:1. Introduction
2. Related Work
3. Tensor Factorization
3.1. Existing Methods
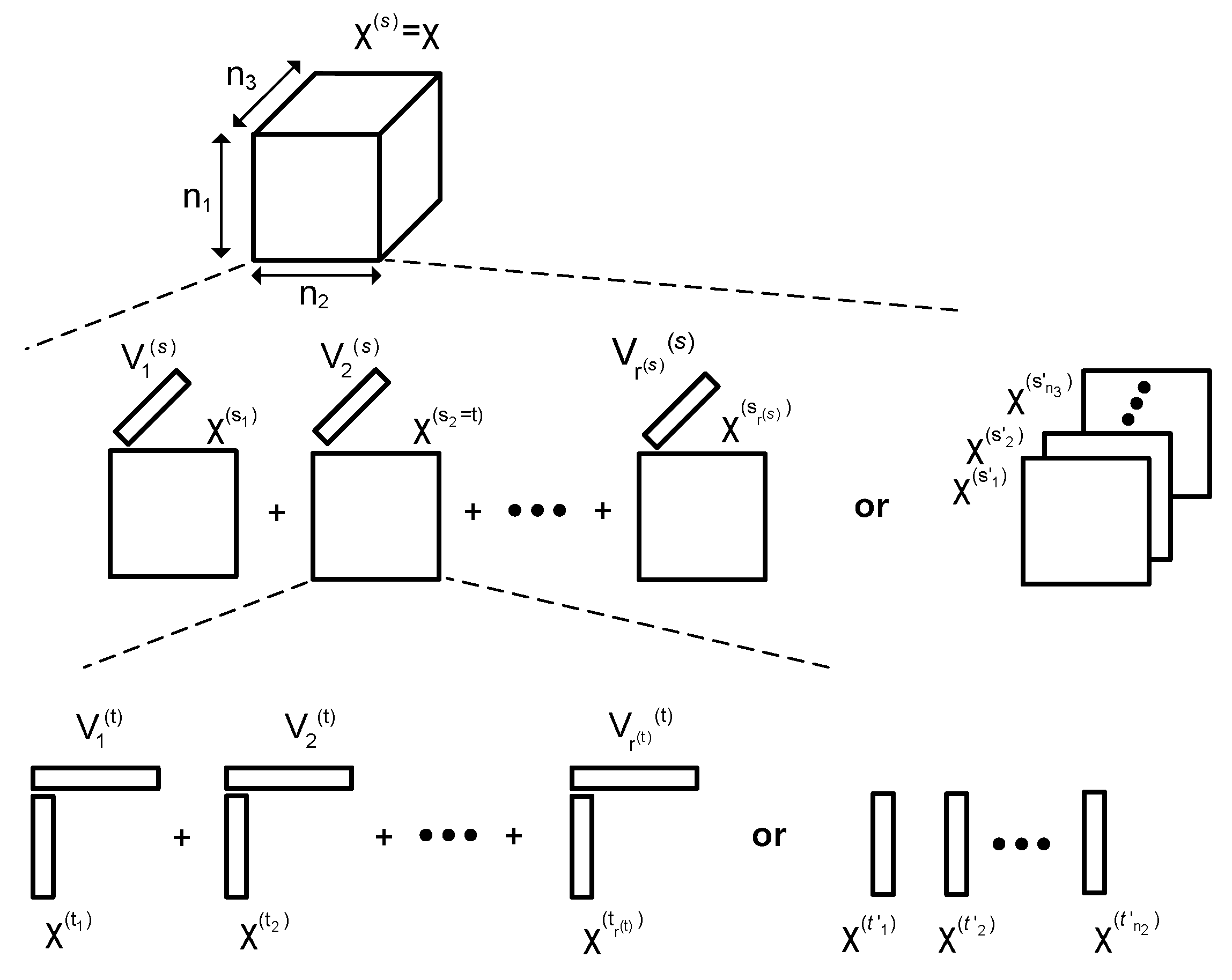
3.2. Proposed Factorization Method
3.3. Low-Rank Tensor Approximation
4. Dual-Objective Optimization
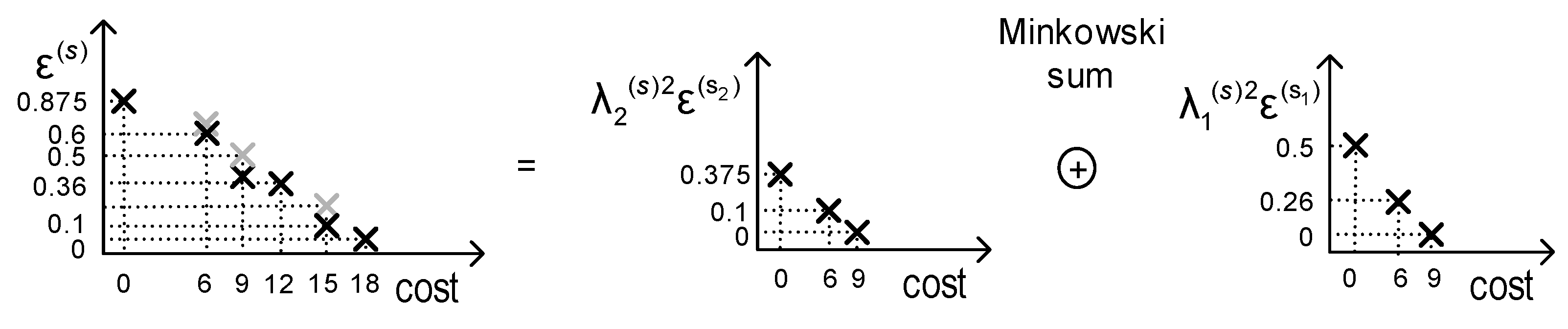
4.1. Pareto Front Method
4.2. Greedy Method
5. Application to Weight Tensors
Fine-Tuning
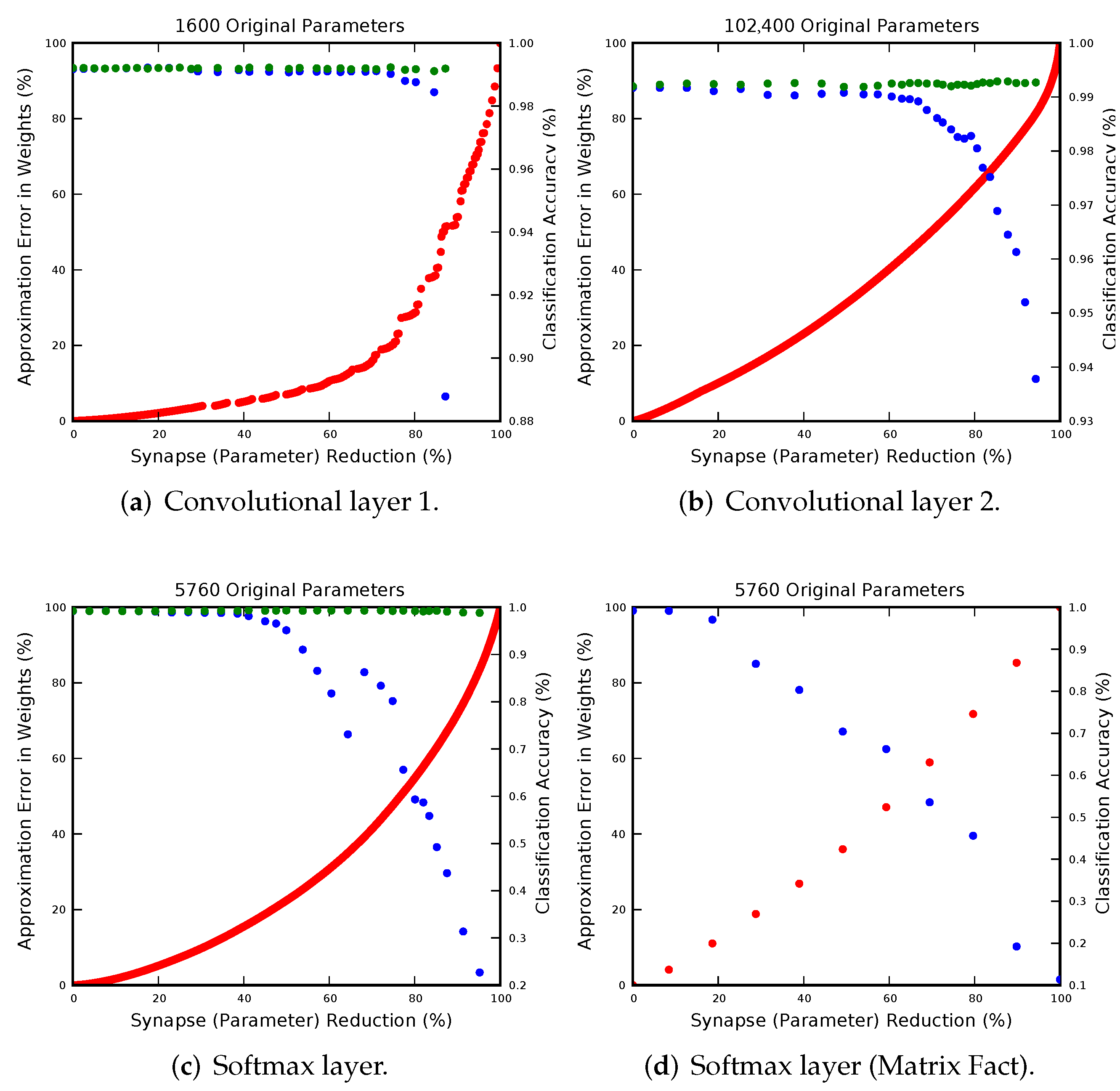
6. Experiments
Comparison with Existing Parameter Reduction Techniques
7. Discussion
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Adv. Neural Inf. Process. Syst. 2012, 25, 1097–1105. [Google Scholar] [CrossRef]
- Alsharif, O.; Pineau, J. End-to-end text recognition with hybrid hmm maxout models. arXiv 2013, arXiv:1310.1811. [Google Scholar]
- Razavian, A.S.; Azizpour, H.; Sullivan, J.; Carlsson, S. CNN Features off-the-shelf: An Astounding Baseline for Recognition. In Proceedings of the Computer Vision and Pattern Recognition Workshops (CVPRW), Columbus, OH, USA, 23–28 June 2014; pp. 512–519. [Google Scholar]
- Taigman, Y.; Yang, M.; Ranzato, M.; Wolf, L. Deepface: Closing the gap to human-level performance in face verification. In Proceedings of the Computer Vision and Pattern Recognition (CVPR), Columbus, OH, USA, 23–28 June 2014; pp. 1701–1708. [Google Scholar]
- Sermanet, P.; Eigen, D.; Zhang, X.; Mathieu, M.; Fergus, R.; LeCun, Y. Overfeat: Integrated recognition, localization and detection using convolutional networks. arXiv 2013, arXiv:1312.6229. [Google Scholar]
- Denil, M.; Shakibi, B.; Dinh, L.; de Freitas, N. Predicting parameters in deep learning. Adv. Neural Inf. Process. Syst. 2013, 2, 2148–2156. [Google Scholar]
- Jaderberg, M.; Vedaldi, A.; Zisserman, A. Speeding up convolutional neural networks with low rank expansions. arXiv 2014, arXiv:1405.3866. [Google Scholar]
- Denton, E.L.; Zaremba, W.; Bruna, J.; LeCun, Y.; Fergus, R. Exploiting linear structure within convolutional networks for efficient evaluation. Adv. Neural Inf. Process. Syst. 2014, 1, 1269–1277. [Google Scholar]
- Lebedev, V.; Ganin, Y.; Rakhuba, M.; Oseledets, I.; Lempitsky, V. Speeding-up Convolutional Neural Networks Using Fine-tuned CP-Decomposition. arXiv 2014, arXiv:1412.6553. [Google Scholar]
- Jin, J.; Dundar, A.; Culurciello, E. Flattened Convolutional Neural Networks for Feedforward Acceleration. arXiv 2014, arXiv:1412.5474. [Google Scholar]
- Yang, Z.; Moczulski, M.; Denil, M.; de Freitas, N.; Alex Smola, L.S.; Wang, Z. Deep Fried Convnets. arXiv 2014, arXiv:1412.7149. [Google Scholar]
- Gong, Y.; Liu, L.; Yang, M.; Bourdev, L. Compressing Deep Convolutional Networks using Vector Quantization. arXiv 2014, arXiv:1412.6115. [Google Scholar]
- Merolla, P.A.; Arthur, J.V.; Alvarez-Icaza, R.; Cassidy, A.S.; Sawada, J.; Akopyan, F.; Jackson, B.L.; Imam, N.; Guo, C.; Nakamura, Y.; et al. A million spiking-neuron integrated circuit with a scalable communication network and interface. Science 2014, 345, 668–673. [Google Scholar] [CrossRef] [PubMed]
- Snider, G. Molecular-Junction-Nanowire Crossbar-Based Neural Network. U.S. Patent 20040150010, 15 April 2008. [Google Scholar]
- Cassidy, A.S.; Merolla, P.; Arthur, J.V.; Esser, S.K.; Jackson, B.; Alvarez-Icaza, R.; Datta, P.; Sawada, J.; Wong, T.M.; Feldman, V.; et al. Cognitive Computing Building Block: A Versatile and Efficient Digital Neuron Model for Neurosynaptic Cores. In Proceedings of the Neural Networks (IJCNN), The 2013 International Joint Conference on. IEEE, Dallas, TX, USA, 4–9 August 2013; pp. 1–10. [Google Scholar]
- Amir, A.; Datta, P.; Risk, W.P.; Cassidy, A.S.; Kusnitz, J.A.; Esser, S.K.; Andreopoulos, A.; Wong, T.M.; Flickner, M.; Alvarez-Icaza, R.; et al. Cognitive computing programming paradigm: A corelet language for composing networks of neurosynaptic cores. In Proceedings of the Neural Networks (IJCNN), The 2013 International Joint Conference on. IEEE, Dallas, TX, USA, 4–9 August 2013; pp. 1–10. [Google Scholar]
- Esser, S.K.; Andreopoulos, A.; Appuswamy, R.; Datta, P.; Barch, D.; Amir, A.; Arthur, J.; Cassidy, A.; Flickner, M.; Merolla, P.; et al. Cognitive computing systems: Algorithms and applications for networks of neurosynaptic cores. In Proceedings of the Neural Networks (IJCNN), The 2013 International Joint Conference on. IEEE, Dallas, TX, USA, 4–9 August 2013; pp. 1–10. [Google Scholar]
- DeBole, M.V.; Taba, B.; Amir, A.; Akopyan, F.; Andreopoulos, A.; Risk, W.P.; Kusnitz, J.; Ortega Otero, C.; Nayak, T.K.; Appuswamy, R.; et al. TrueNorth: Accelerating From Zero to 64 Million Neurons in 10 Years. Computer 2019, 52, 20–29. [Google Scholar] [CrossRef]
- Chung, J.; Shin, T. Simplifying deep neural networks for neuromorphic architectures. In Proceedings of the 2016 53nd ACM/EDAC/IEEE Design Automation Conference (DAC), Austin, TX, USA, 5–9 June 2016; pp. 1–6. [Google Scholar] [CrossRef]
- Cormen, T.H.; Leiserson, C.E.; Rivest, R.L.; Stein, C. Introduction to Algorithms; MIT Press: Cambridge, MA, USA, 2009. [Google Scholar]
- Klema, V.; Laub, A. The singular value decomposition: Its computation and some applications. IEEE Trans. Autom. Control 1980, 25, 164–176. [Google Scholar] [CrossRef] [Green Version]
- Oseledets, I.V.; Tyrtyshnikov, E.E. Breaking the curse of dimensionality, or how to use SVD in many dimensions. SIAM J. Sci. Comput. 2009, 31, 3744–3759. [Google Scholar] [CrossRef]
- De Lathauwer, L.; De Moor, B.; Vandewalle, J. A multilinear singular value decomposition. SIAM J. Matrix Anal. Appl. 2000, 21, 1253–1278. [Google Scholar] [CrossRef] [Green Version]
- Oseledets, I.V. Tensor-train decomposition. SIAM J. Sci. Comput. 2011, 33, 2295–2317. [Google Scholar] [CrossRef]
- Grasedyck, L. Hierarchical singular value decomposition of tensors. SIAM J. Matrix Anal. Appl. 2010, 31, 2029–2054. [Google Scholar] [CrossRef] [Green Version]
- Goodfellow, I.J.; Warde-Farley, D.; Lamblin, P.; Dumoulin, V.; Mirza, M.; Pascanu, R.; Bergstra, J.; Bastien, F.; Bengio, Y. Pylearn2: A machine learning research library. arXiv 2013, arXiv:1308.4214. [Google Scholar]
- Goodfellow, I.; Warde-Farley, D.; Mirza, M.; Courville, A.; Bengio, Y. Maxout Networks. In Proceedings of the 30th International Conference on Machine Learning, Atlanta, GA, USA, 16–21 June 2013; pp. 1319–1327. [Google Scholar]
- Ding, W.; Wang, R.; Mao, F.; Taylor, G. Theano-based Large-Scale Visual Recognition with Multiple GPUs. arXiv 2014, arXiv:1412.2302. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
| Methods | Layer | Baseline | Reduced Model | ||
|---|---|---|---|---|---|
| Params | Error | Params | Error | ||
| [11] | Conv. layers | 25,500 | 0.87% | 25,500 | 0.83% |
| FC layer | 405,000 | 13,321 | |||
| [10] | Conv. layer 1 | 7200 | 0.38% | 7200 | 0.44% |
| Conv. layer 2 | 307,200 | 30,912 | |||
| Conv. layer 3 | 819,200 | 102,144 | |||
| FC layers | NA | NA | |||
| CP-decomp. | Conv. layer 1 | 1600 | 0.82% | 600 | 1.14% |
| Conv. layer 2 | 102,400 | 828 | |||
| FC layer | 5760 | 1920 | |||
| This work | Conv. layer 1 | 1600 | 0.82% | 588 | 0.81% |
| Conv. layer 2 | 102,400 | 824 | |||
| FC layer | 5760 | 1858 | |||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kwon, K.; Chung, J. Reducing Parameters of Neural Networks via Recursive Tensor Approximation. Electronics 2022, 11, 214. https://doi.org/10.3390/electronics11020214
Kwon K, Chung J. Reducing Parameters of Neural Networks via Recursive Tensor Approximation. Electronics. 2022; 11(2):214. https://doi.org/10.3390/electronics11020214
Chicago/Turabian StyleKwon, Kyuahn, and Jaeyong Chung. 2022. "Reducing Parameters of Neural Networks via Recursive Tensor Approximation" Electronics 11, no. 2: 214. https://doi.org/10.3390/electronics11020214