

Wireless Communication Channel Scenarios: Machine-Learning-Based Identification and Performance Enhancement



Abstract
:1. Introduction
- Reduction of the model response and latency for the preprocessing workflow of each regularization technique instruction used in the previous model [14]. The previous model adopted ElasticNet without studying the time consumption. In this work, the performance and time efficiency results prove that adopting the LASSO is more suitable than ElasticNet. It achieves the same feature-selection performance of ElasticNet but in much less time.
- Calculation of the classification time of KNN, SVM, k-Means, and GMM. The training phase and testing phase runtimes are computed and compared for both supervised algorithms (KNN and SVM). The formulation of clusters and the “fit and predict” runtime for the unsupervised learning k-Means and GMM are revealed.
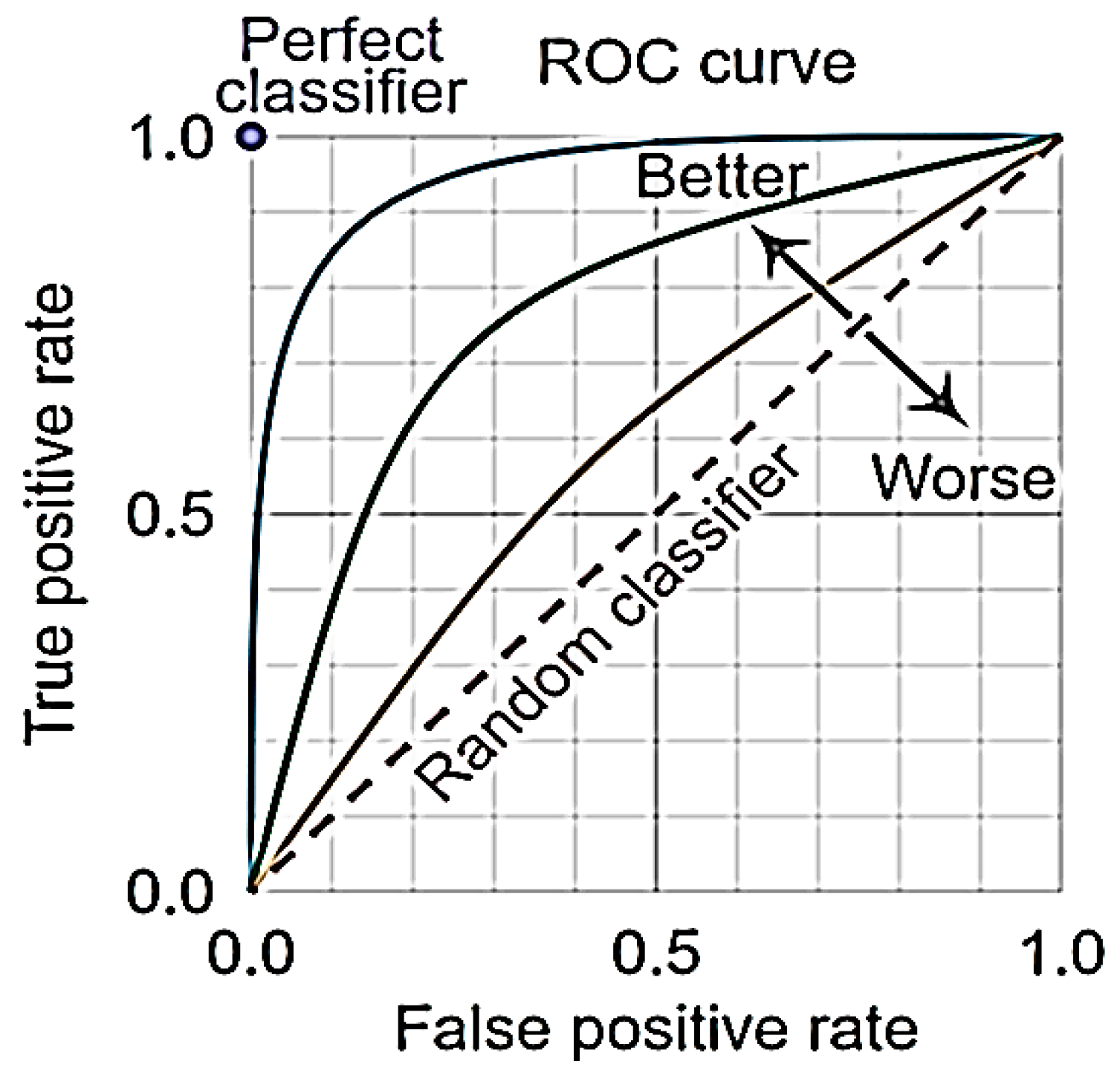
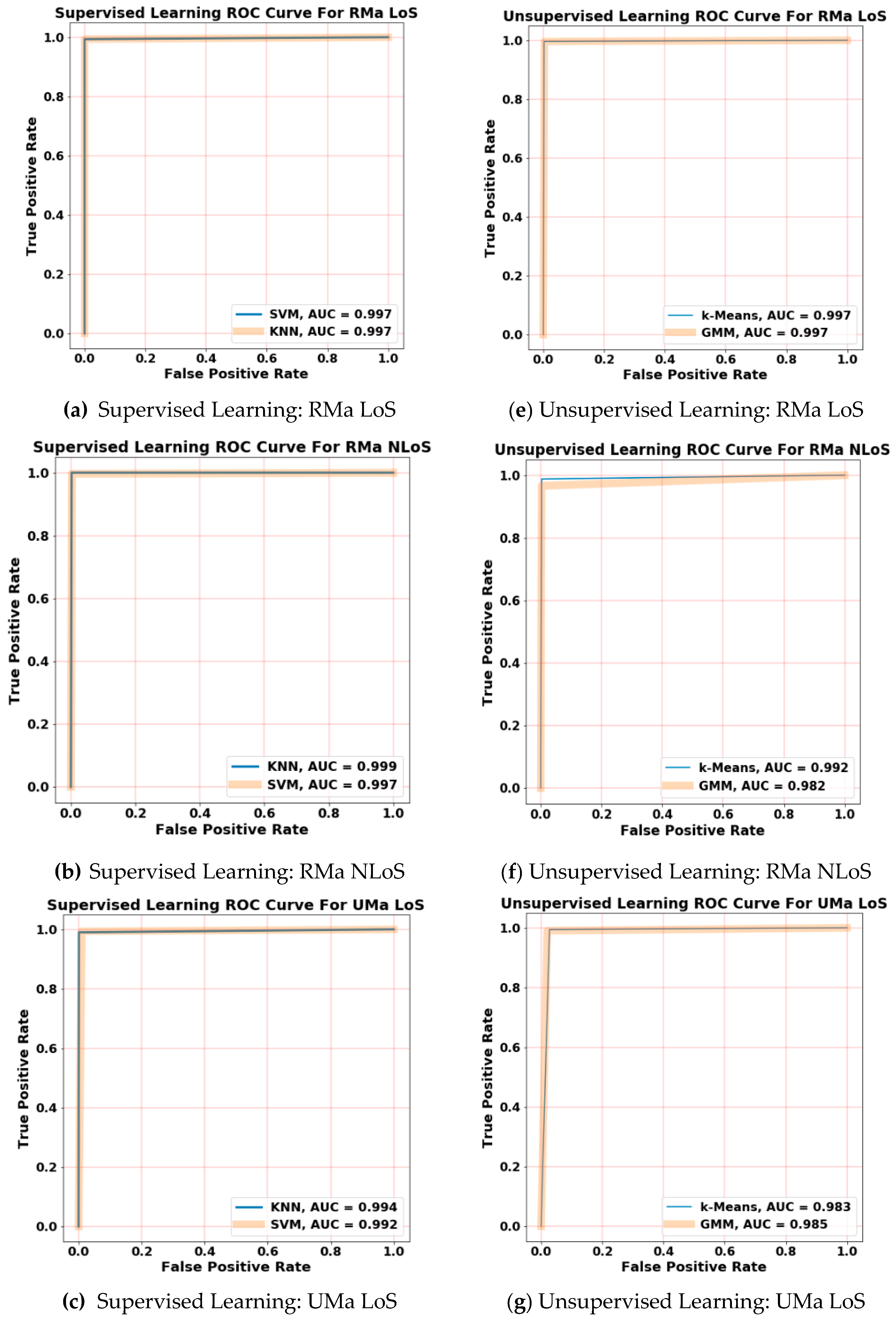
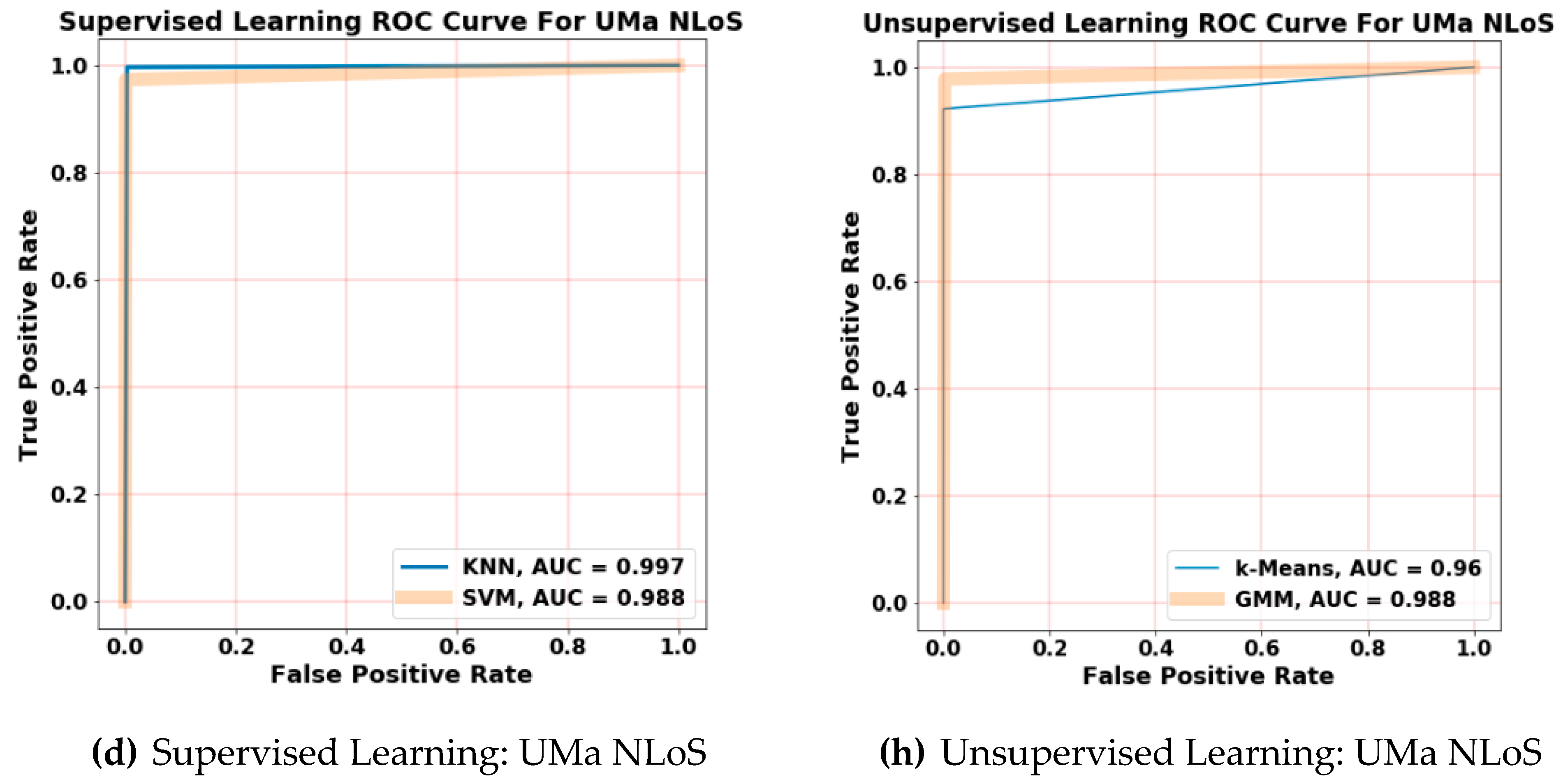
- Calculation and study of the ROC curves and AUC scores for each class in each model. Both ROC curves and AUC scores of the classes are calculated as one over all, where the evaluation is taken as a binary such that every class is distinguished from the others (e.g., the RMa LoS represented as ‘1’ versus the other classes presented as ‘0’).
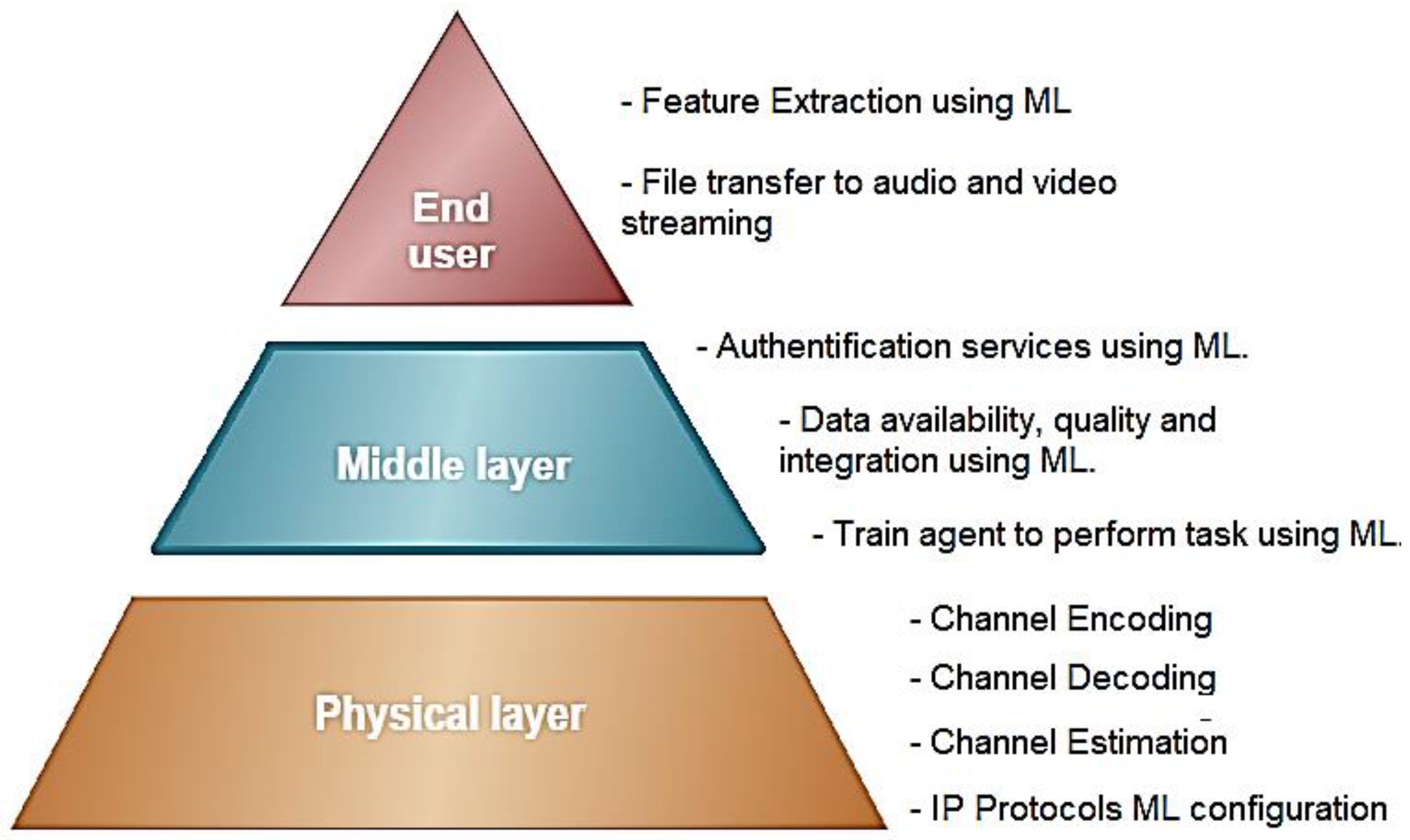
2. Model Planning Procedures
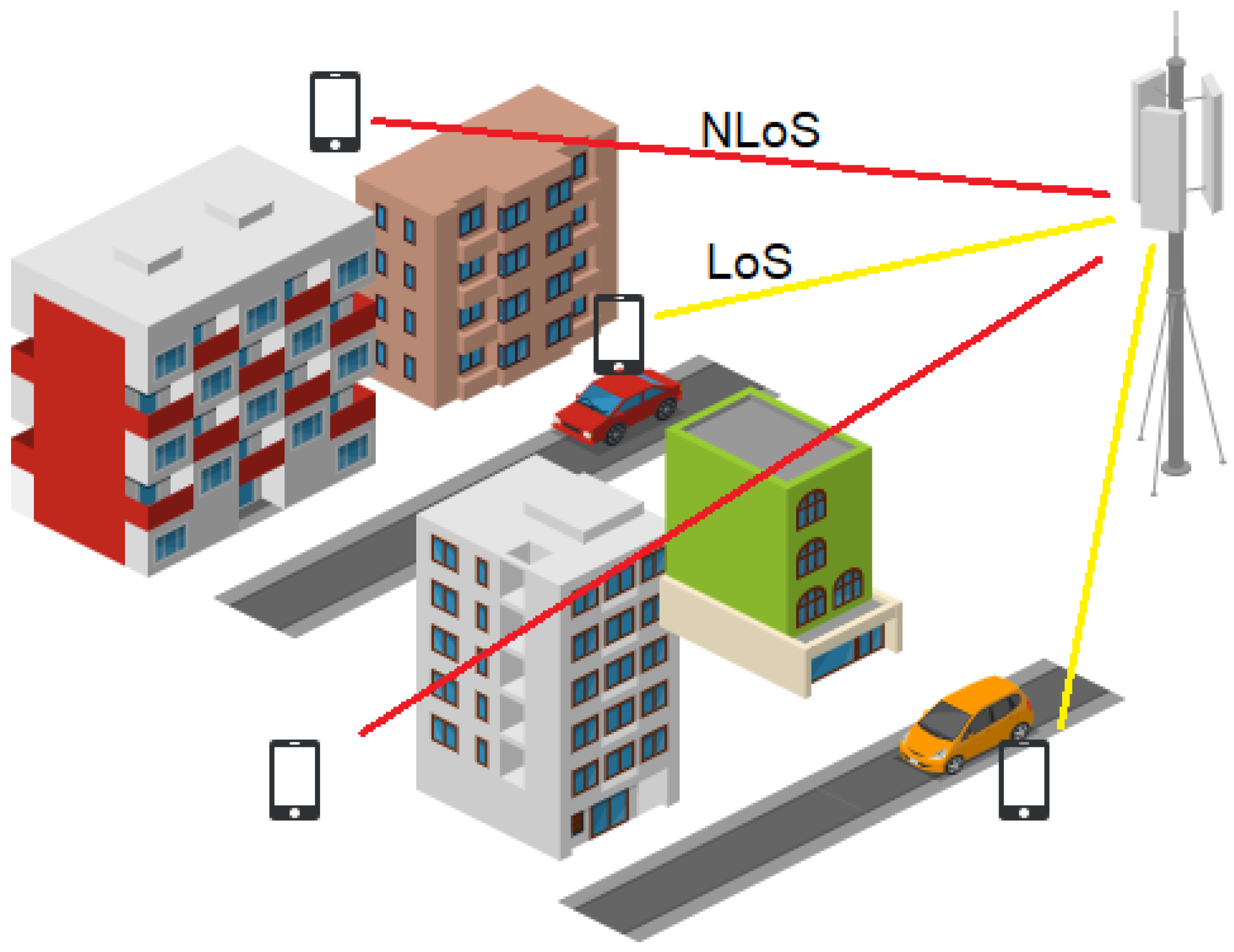
2.1. Dataset Origination and Parameters
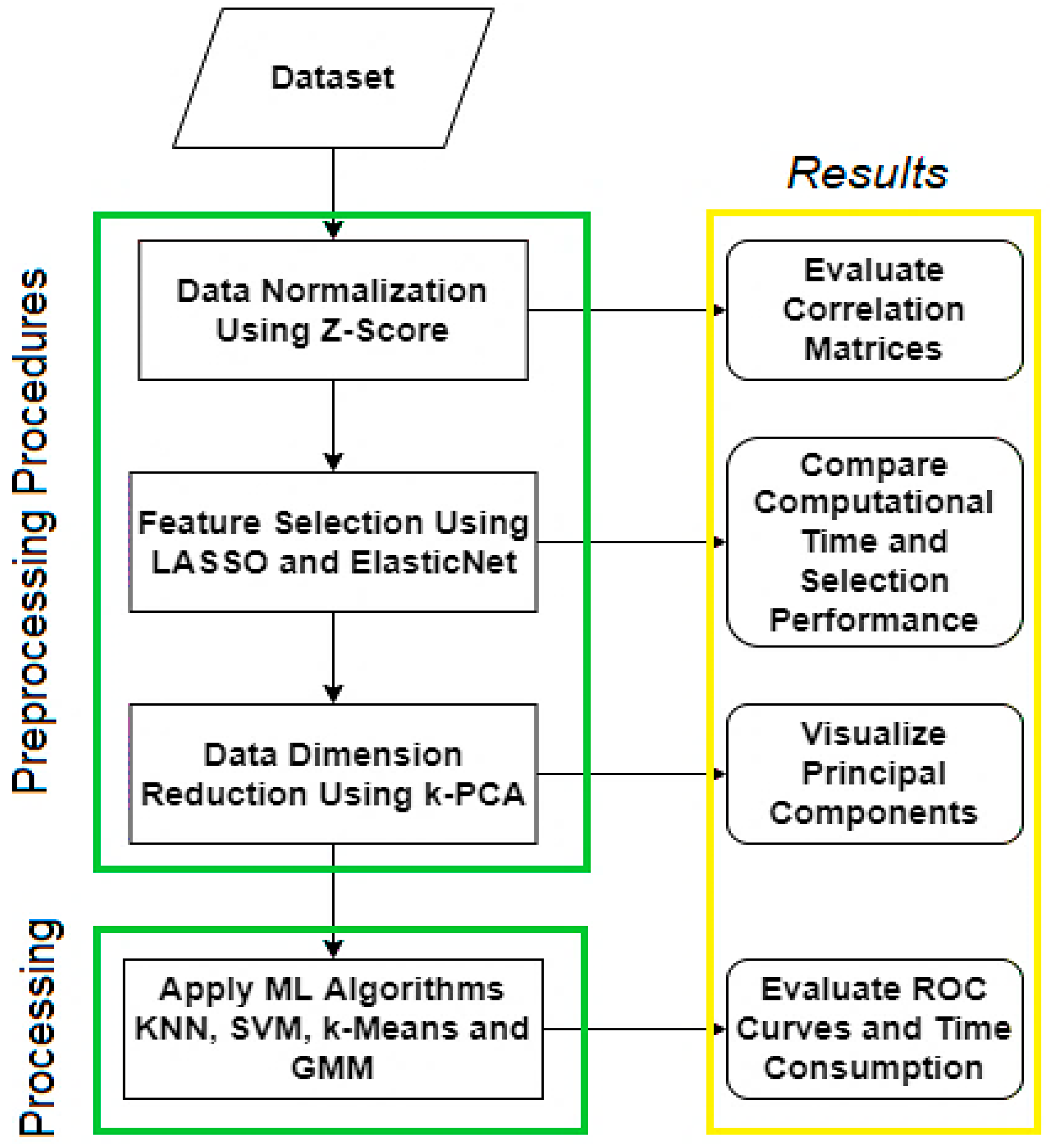
2.2. Preprocessing and Processing Procedures
3. Results and Discussion
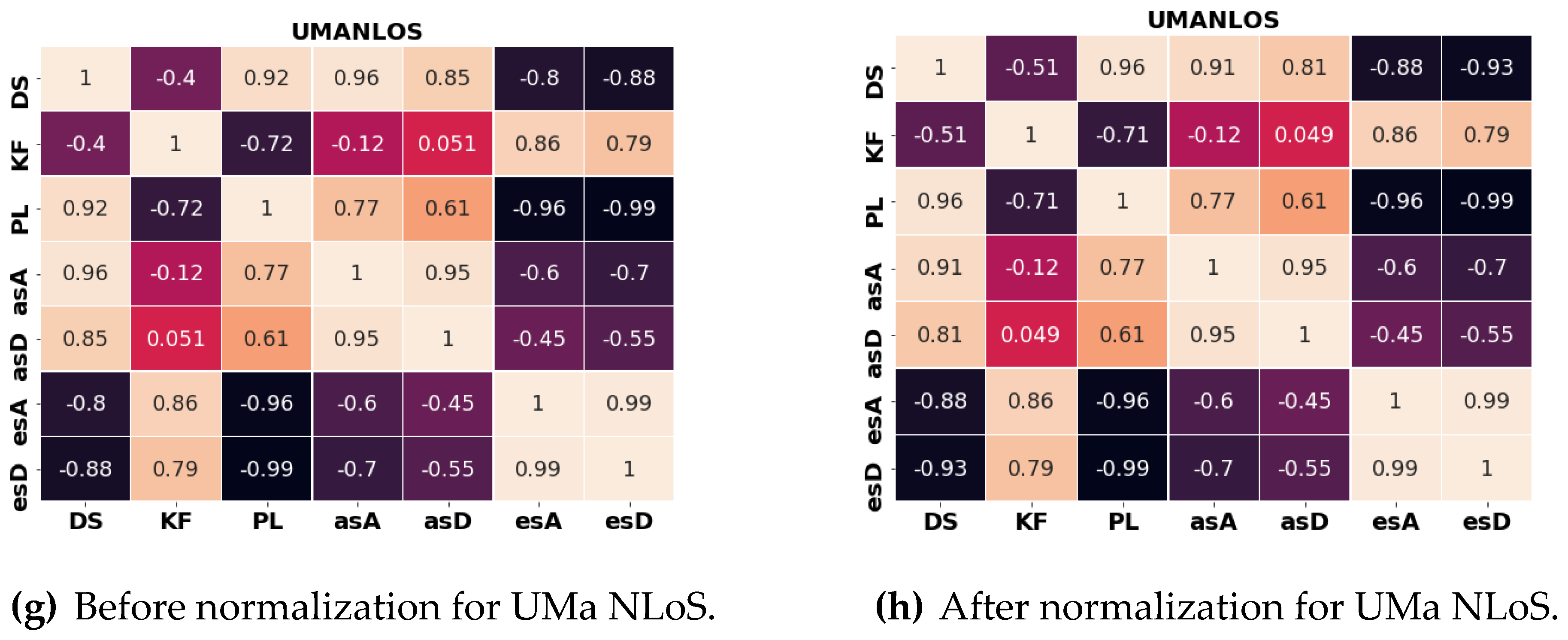
3.1. Z-Score Normalization Impact on Inter-Parameter Correlations
3.2. Regularization Evaluation
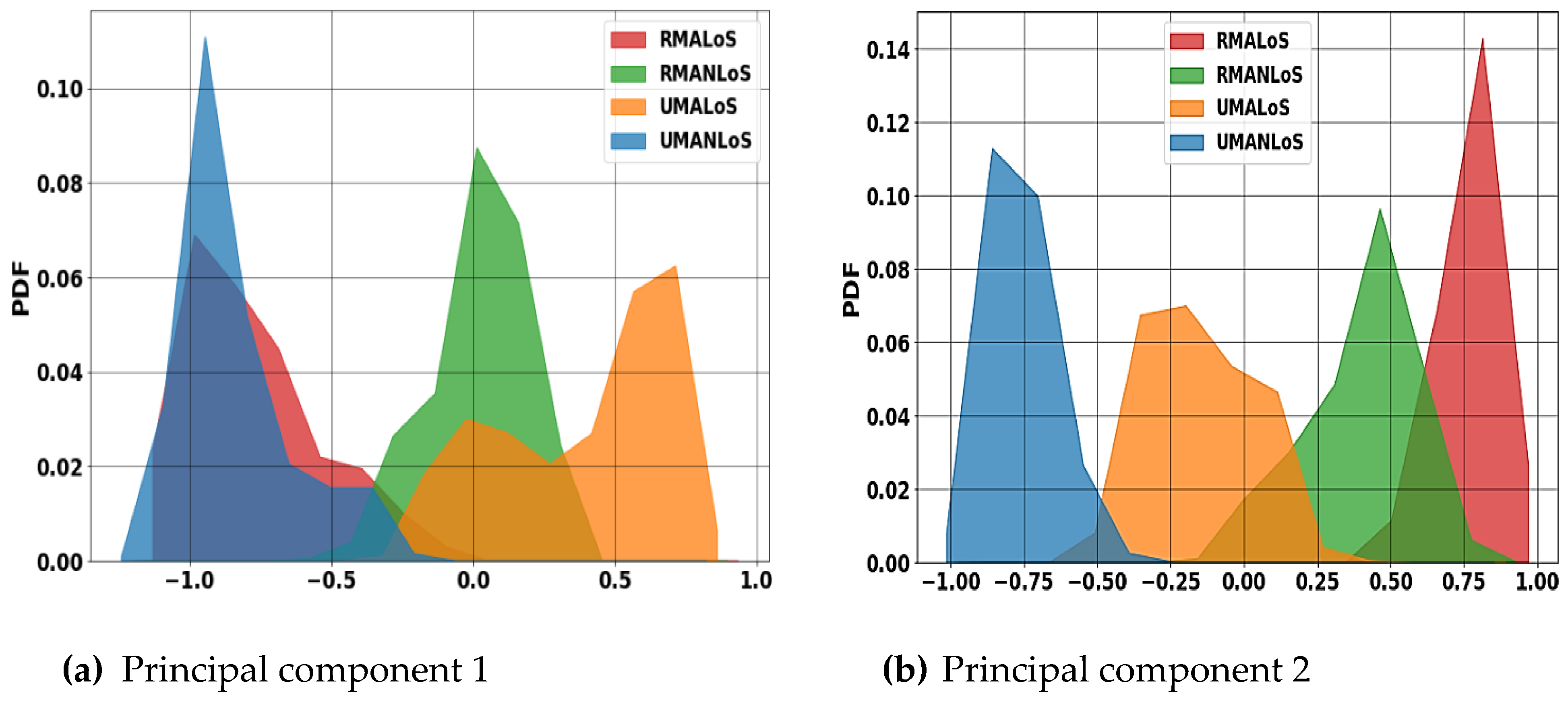
3.3. Dimension Reduction and Data Visualization
3.4. ML Evaluation
4. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Guo, Z.; Liu, P.; Zhang, C.; Luo, J.; Long, Z.; Yang, X. AI-Aided Channel Quality Assessment for Bluetooth Adaptive Frequency Hopping. In Proceedings of the 2021 IEEE 32nd Annual International Symposium on Personal, Indoor and Mobile Radio Communications (PIMRC), Helsinki, Finland, 13–16 September 2021; pp. 934–939. [Google Scholar] [CrossRef]
- Wang, C.-X.; Di Renzo, M.; Stanczak, S.; Wang, S.; Larsson, E.G. Artificial Intelligence Enabled Wireless Networking for 5G and Beyond: Recent Advances and Future Challenges. IEEE Wirel. Commun. 2020, 27, 16–23. [Google Scholar] [CrossRef] [Green Version]
- Lin, Z.; Lin, M.; de Cola, T.; Wang, J.-B.; Zhu, W.-P.; Cheng, J. Supporting IoT with Rate-Splitting Multiple Access in Satellite and Aerial-Integrated Networks. IEEE Internet Things J. 2021, 8, 11123–11134. [Google Scholar] [CrossRef]
- Islam, M.N.; Inan, T.T.; Rafi, S.; Akter, S.S.; Sarker, I.H.; Islam, A.K.M.N. A Systematic Review on the Use of AI and ML for Fighting the COVID-19 Pandemic. IEEE Trans. Artif. Intell. 2021, 1, 258–270. [Google Scholar] [CrossRef] [PubMed]
- Lin, Z.; Niu, H.; An, K.; Wang, Y.; Zheng, G.; Chatzinotas, S.; Hu, Y. Refracting RIS-Aided Hybrid Satellite-Terrestrial Relay Networks: Joint Beamforming Design and Optimization. IEEE Trans. Aerosp. Electron. Syst. 2022, 58, 3717–3724. [Google Scholar] [CrossRef]
- Lin, Z.; An, K.; Niu, H.; Hu, Y.; Chatzinotas, S.; Zheng, G.; Wang, J. SLNR-based Secure Energy Efficient Beamforming in Multibeam Satellite Systems. IEEE Trans. Aerosp. Electron. Syst. 2022, 1–4. [Google Scholar] [CrossRef]
- An, K.; Lin, M.; Ouyang, J.; Zhu, W.-P. Secure Transmission in Cognitive Satellite Terrestrial Networks. IEEE J. Sel. Areas Commun. 2016, 34, 3025–3037. [Google Scholar] [CrossRef]
- Baeza, V.M.; Lagunas, E.; Al-Hraishawi, H.; Chatzinotas, S. An Overview of Channel Models for NGSO Satellites. In Proceedings of the IEEE 96th Vehicular Technology Conference Fall, London, UK, 26–29 September 2022. [Google Scholar]
- Kaur, J.; Khan, M.A.; Iftikhar, M.; Imran, M.; Haq, Q.E.U. Machine Learning Techniques for 5G and beyond. IEEE Access 2021, 9, 23472–23488. [Google Scholar] [CrossRef]
- Burkhardt, F.; Jaeckel, S.; Eberlein, E.; Prieto-Cerdeira, R. QuaDRiGa: A MIMO channel model for land mobile satellite. In Proceedings of the 8th European Conference on Antennas and Propagation (EuCAP 2014), 6–11 April 2014; pp. 1274–1278. [Google Scholar] [CrossRef]
- Mahmood, T.; Al-Qaysi, H.K.; Hameed, A.S. The Effect of Antenna Height on the Performance of the Okumura/Hata Model Under Different Environments Propagation. In Proceedings of the 2021 International Conference on Intelligent Technologies (CONIT), Hubli, India, 25–27 June 2021; pp. 1–4. [Google Scholar] [CrossRef]
- Huang, C.; Molisch, A.F.; Wang, R.; Tang, P.; He, R.; Zhong, Z. Angular Information-Based NLOS/LOS Identification for Vehicle to Vehicle MIMO System. In Proceedings of the 2019 IEEE International Conference on Communications Workshops (ICC Workshops), Shanghai, China, 20–24 May 2019; pp. 1–6. [Google Scholar] [CrossRef]
- Yu, Y.; Liu, F.; Mao, S. Fingerprint Extraction and Classification of Wireless Channels Based on Deep Convolutional Neural Networks. Neural Process. Lett. 2018, 48, 1767–1775. [Google Scholar] [CrossRef]
- Zaki, A.; Métwalli, A.; Aly, M.H.; Badawi, W.K. Enhanced feature selection method based on regularization and kernel trick for 5G applications and beyond. Alex. Eng. J. 2022, 61, 11589–11600. [Google Scholar] [CrossRef]
- Zhang, J.; Liu, L.; Fan, Y.; Zhuang, L.; Zhou, T.; Piao, Z. Wireless Channel Propagation Scenarios Identification: A Perspective of Machine Learning. IEEE Access 2020, 8, 47797–47806. [Google Scholar] [CrossRef]
- Fleury, B.; Jourdan, P.; Stucki, A. High-resolution channel parameter estimation for MIMO applications using the SAGE algorithm. In Proceedings of the 2002 International Zurich Seminar on Broadband Communications Access-Transmission-Networking (Cat. No. 02TH8599), Zurich, Switzerland, 19–21 February 2002; p. 30. [Google Scholar] [CrossRef]
- Al-Samman, A.M.; Hindia, M.N.; Rahman, T.A. Path loss model in outdoor environment at 32 GHz for 5G system. In Proceedings of the 2016 IEEE 3rd International Symposium on Telecommunication Technologies (ISTT), Kuala Lumpur, Malaysia, 28–30 November 2016; pp. 9–13. [Google Scholar] [CrossRef]
- Doukas, A.; Kalivas, G. Rician K Factor Estimation for Wireless Communication Systems. In Proceedings of the 2006 International Conference on Wireless and Mobile Communications (ICWMC’06), Bucharest, Romania, 29–31 July 2006; p. 69. [Google Scholar] [CrossRef]
- Arslan, H.; Yucek, T. Delay spread estimation for wireless communication systems. In Proceedings of the 8th IEEE Symposium on Computers and Communications (ISCC 2003), Kemer-Antalia, Turkey, 30 June–3 July 2003; Volume 1, pp. 282–287. [Google Scholar] [CrossRef]
- Alshammari, A.; Albdran, S.; Ahad, A.R.; Matin, M. Impact of angular spread on massive MIMO channel estimation. In Proceedings of the 2016 19th International Conference on Computer and Information Technology (ICCIT), Dhaka, Bangladesh, 18–20 December 2016; pp. 84–87. [Google Scholar] [CrossRef]
- Raju, V.N.G.; Lakshmi, K.P.; Jain, V.M.; Kalidindi, A.; Padma, V. Study the Influence of Normalization/Transformation process on the Accuracy of Supervised Classification. In Proceedings of the 2020 Third International Conference on Smart Systems and Inventive Technology (ICSSIT), Tirunelveli, India, 20–22 August 2020; pp. 729–735. [Google Scholar] [CrossRef]
- Muthukrishnan, R.; Rohini, R. LASSO: A feature selection technique in predictive modeling for machine learning. In Proceedings of the 2016 IEEE International Conference on Advances in Computer Applications (ICACA), Coimbatore, India, 24 October 2016; pp. 84–87. [Google Scholar] [CrossRef]
- Soleymani, F.; Akgül, A. Improved numerical solution of multi-asset option pricing problem: A localized RBF-FD approach. Chaos Solitons Fractals 2019, 119, 298–309. [Google Scholar] [CrossRef]
- Taunk, K.; De, S.; Verma, S.; Swetapadma, A. A Brief Review of Nearest Neighbor Algorithm for Learning and Classification. In Proceedings of the 2019 International Conference on Intelligent Computing and Control Systems (ICCS), Madurai, India, 15–17 May 2019; pp. 1255–1260. [Google Scholar]
- Badawi, W.K.; Osman, Z.M.; Sharkas, M.A.; Tamazin, M. A classification technique for condensed matter phases using a combination of PCA and SVM” Progress. In Proceedings of the Electromagnetics Research Symposium (PIERS), St. Petersburg, Russia, 22–25 May 2017; pp. 326–331. [Google Scholar]
- Chang, C.-I. An Effective Evaluation Tool for Hyperspectral Target Detection: 3D Receiver Operating Characteristic Curve Analysis. IEEE Trans. Geosci. Remote Sens. 2020, 59, 5131–5153. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Features | esA | KF | PL | asA | esD | asD | DS |
|---|---|---|---|---|---|---|---|
| Method | |||||||
| LASSO (Present Work) | Kept | Kept | Kept | Kept | Dropped | Dropped | Dropped |
| ElasticNet Ref. [14] | Kept | Kept | Kept | Kept | Dropped | Dropped | Dropped |
| Model | Runtime (s) |
|---|---|
| LASSO (Present Work) | 0.33 |
| ElasticNet (Ref. [14]) | 0.67 |
| Algorithms | KNN | SVM | k-Means | GMM |
|---|---|---|---|---|
| Accuracy | 99% | 99% | 97% | 98% |
| Fit & Predict Time (s) | 0.181 | 0.155 | 0.26 | 0.087 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zaki, A.; Métwalli, A.; Aly, M.H.; Badawi, W.K. Wireless Communication Channel Scenarios: Machine-Learning-Based Identification and Performance Enhancement. Electronics 2022, 11, 3253. https://doi.org/10.3390/electronics11193253
Zaki A, Métwalli A, Aly MH, Badawi WK. Wireless Communication Channel Scenarios: Machine-Learning-Based Identification and Performance Enhancement. Electronics. 2022; 11(19):3253. https://doi.org/10.3390/electronics11193253
Chicago/Turabian StyleZaki, Amira, Ahmed Métwalli, Moustafa H. Aly, and Waleed K. Badawi. 2022. "Wireless Communication Channel Scenarios: Machine-Learning-Based Identification and Performance Enhancement" Electronics 11, no. 19: 3253. https://doi.org/10.3390/electronics11193253