2.1. MobileNet Network Structure
The network structure of MobileNetV2 [
12] is shown in
Table 1, which consists of convolutional layers, pooling layers, and a series of bottleneck blocks. Among them, Conv2d is a standard two-dimensional convolution operation, Bottleneck is a bottleneck block composed of reverse residual blocks, Avgpool is a global average pooling operation,
t is a channel expansion factor (multiple of channel expansion in Bottleneck),
c is the number of output channels,
n is the number of repeated iterations of Bottleneck, and
s is the step size. Replacing the connection layer of 1280 neurons in the above way can effectively prevent overfitting.
2.2. Depthwise Separable Convolution
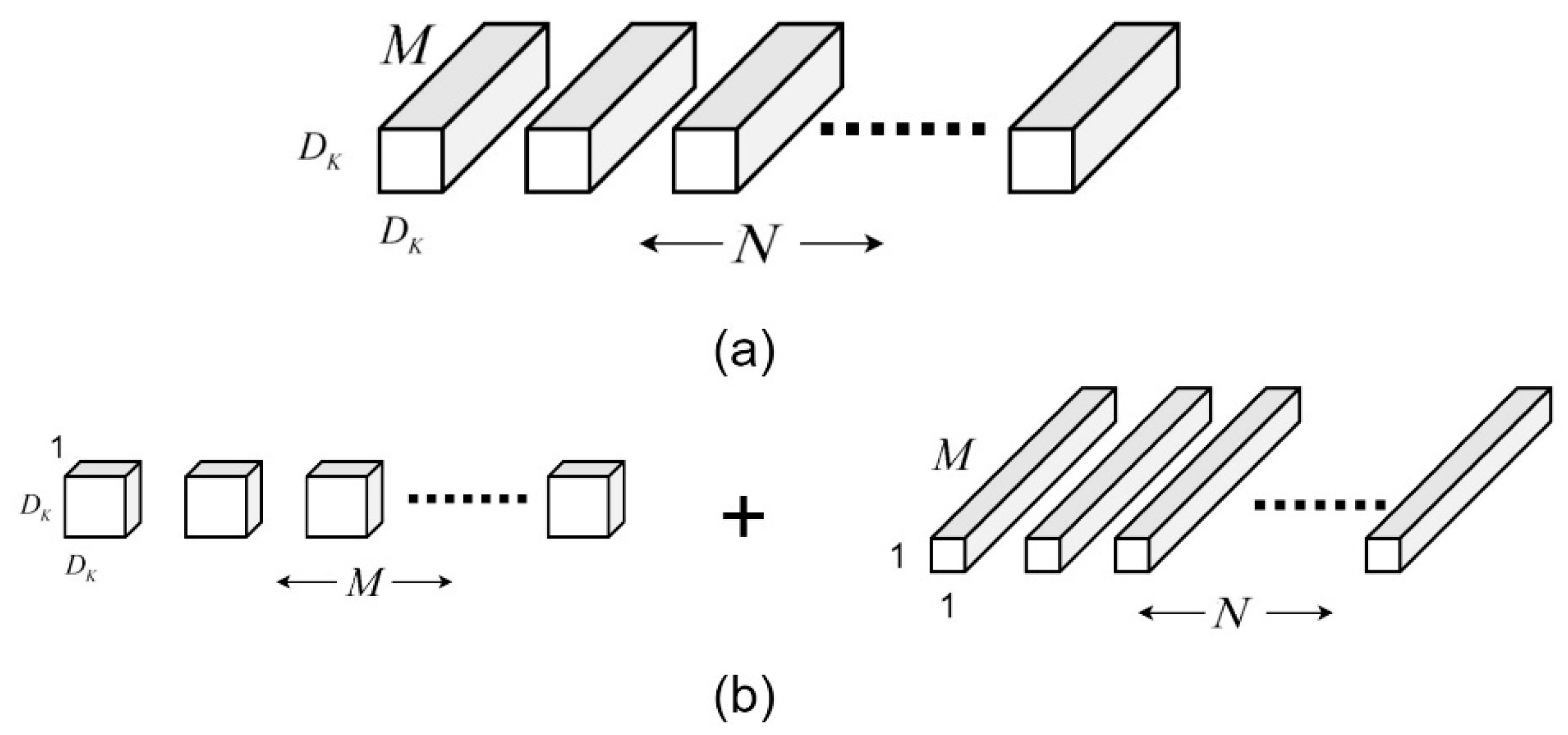
A major feature of the MobileNet network is depthwise separable convolution, which can be disassembled into single-channel convolution and point-by-point convolution. In the concept of traditional convolution, the input image of the network needs to be convolved with each convolution kernel, and the number of channels of the output image is also affected by the number of convolution kernels. In the MobileNet network, the use of single-channel convolution makes each convolution kernel responsible for only one channel of the input image, so the resulting output image has the same number of channels as the input image. There is no essential difference between point-by-point convolution and traditional convolution in operation, but a 1 × 1 convolution kernel is used. The depthwise convolutional separable structure is shown in
Figure 1 below.
The use of the separable structure of the depthwise convolution makes the MobileNet network have the advantage of saving a lot of computation compared to the traditional convolutional network.
This is assuming that the width and height of the network input image are
DF, the number of channels is M, the size of the convolution kernel is
DK ×
DK, and the output image has N channels. In traditional convolution, the calculation amount is:
In the depthwise convolution separable, because single-channel convolution and point-by-point convolution are used, the computation amount is:
Taking the 3 × 3 convolution kernel commonly used in MobileNetV2 as an example (that is, taking DK = 3), when the output is the same size, and after adopting the structure of single-channel convolution and point-by-point convolution (which are used in depthwise convolution separable), it saves about nine times of computation compared to traditional convolution. Therefore, after adopting the depthwise convolutional separable structure, although the number of network layers increases, the operation speed is significantly improved.
2.3. Improve the Network Structure
To better enhance the network’s ability to extract fault features and perform fault diagnosis on bearings, this paper uses a progressive classifier and a cross-local connection network backbone structure on the basis of the MobileNetV2 network, and, finally, builds a network model with strong fault diagnosis ability.
The classification and recognition capability of the original MobileNetV2 is derived from using the network backbone to extract target features, using the classifier to classify and recognize the output of the last bottleneck. In specific use, the classification and recognition of a specific number of targets can be achieved by modifying the last layer of the classifier between different classification tasks, which is a common, simple, and direct use method. However, when the difference in the number of target classifications between different tasks is too large, the current task goal cannot be achieved just by adjusting the number of neurons in the last layer, and the feature recognition ability of the neural network cannot be fully utilized.
Considering that the original MobileNetV2 network is used to identify more than 1000 types of objects on the ImageNet dataset [
13] and that there are six bearing state types involved in this paper, therefore, in order to improve the network’s ability to identify fault states, this paper refers to the paper in [
14] to redesign the network classifier. The new classifier contains two convolutional layers, one global pooling layer, and one output layer. The specific description is shown in
Table 2.
The classifier can convert the features extracted by the network backbone into specific classification results. Because the number of classifications in this paper is far from the dimension of the feature map output by the backbone, two convolution kernels of different sizes are selected to replace the single convolution kernel in the original classifier for feature map compression and conversion.
The structure first has a convolution kernel of size 1 × 1, which is responsible for the channel number compression of the feature map. In this layer, 3/5 of the original number of channels is reserved, that is, 192 layers are reserved to prevent the loss of features caused by a large compression rate. The second convolution kernel is used for feature map size compression. In order to avoid subsequent global pooling fluctuations on larger feature maps, this layer compresses the number of channels to 64 layers. The global pooling layer can extract feature information and output the recognition result in the last layer.
- 2.
Improve the network backbone
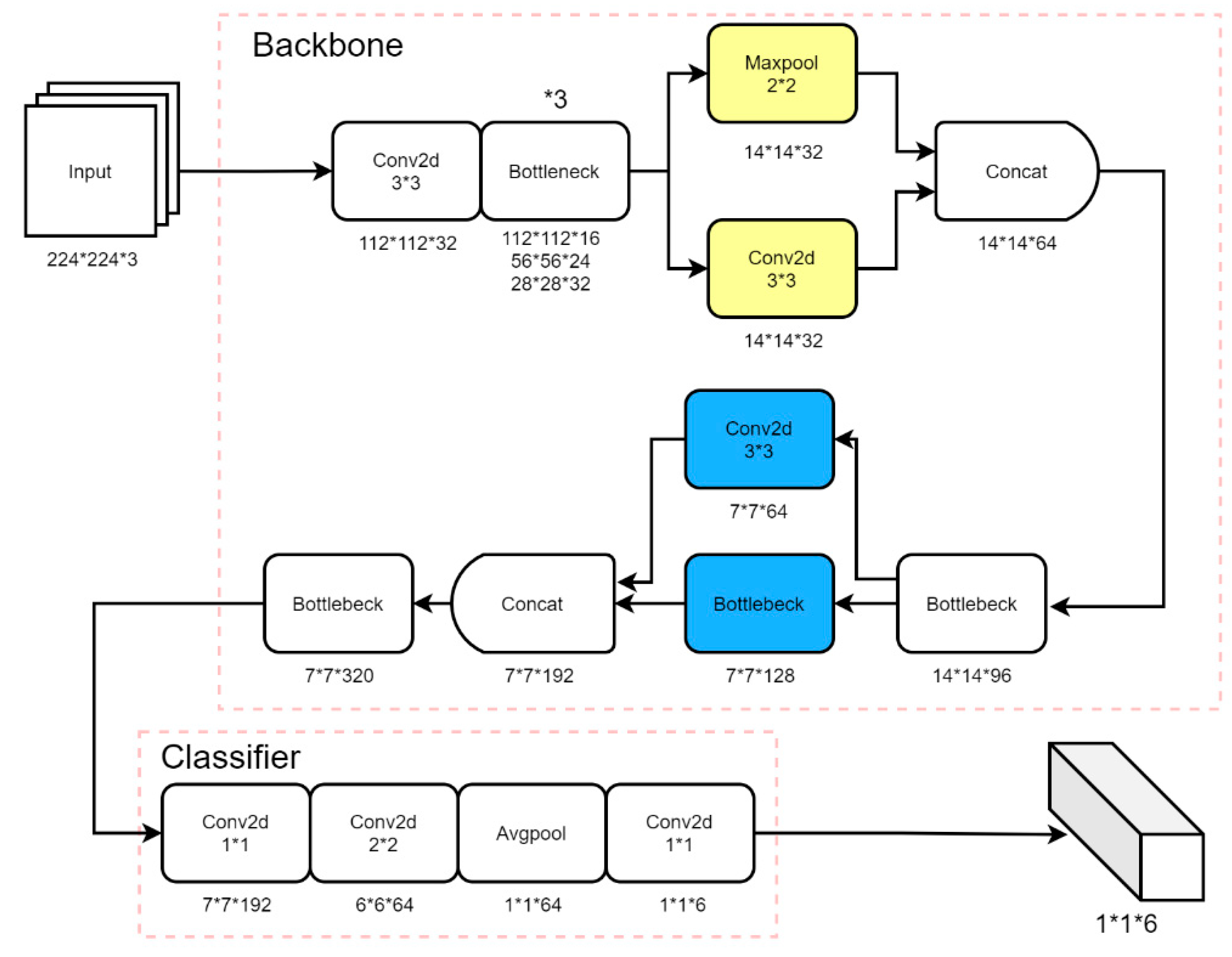
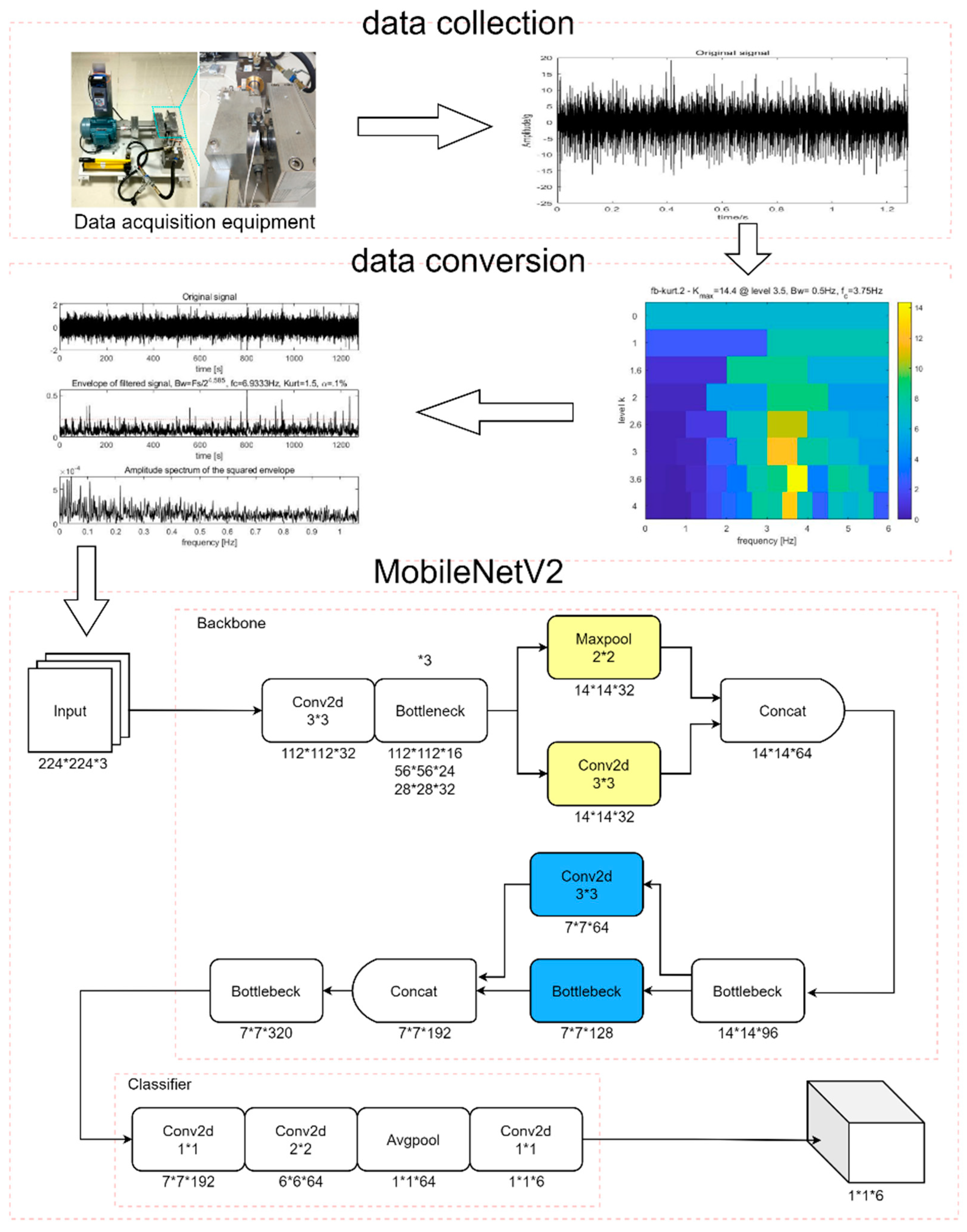
The underlying structure of the neural network mostly extracts common features, such as shape, color, etc. Bottleneck uses the residual structure, but if the Bottleneck is used for the entire network backbone, the network will save less basic features due to the deep depth, which will affect the recognition effect. To enhance the fault diagnosis capability of the network for bearings, this paper uses a cross-local-link-network backbone. Based on the original network structure, the design changes the fourth and sixth Bottlenecks, uses convolution and pooling operations to replace the fourth Bottleneck, and adds a cross-local link at the sixth Bottleneck. The improved network consists of two parts: backbone and classifier. The specific structure is shown in
Figure 2.
In
Figure 2, there is a mark of *3 on the first Bottleneck. This means that there are three Bottleneck operations there. Each operation in the figure has data to mark the current feature map size, and Conv2d boxes refer to convolution kernels. In the figure, the background colors of the squares are marked as yellow and blue, which are the fourth and sixth Bottleneck structures that were replaced, as mentioned above.
After passing through the first three Bottlenecks, convolution and pooling operations are performed on the output of the previous layer. The extracted features of the two are combined and passed to the fourth Bottleneck. At the same time, the number of channels of the fifth Bottleneck are reduced from 160 to 128. The input features are combined with the output through a single-layer convolution to form a local link, so that the input features in the final Bottleneck have different scale information to further enhance the network’s ability to identify and classify different targets.




















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}