

Face Anti-Spoofing Method Based on Residual Network with Channel Attention Mechanism
Abstract
:1. Introduction
2. Face Anti-Spoofing Model with Channel Attention Mechanism
2.1. Deep Residual Network
2.2. Channel Attention Mechanism
2.3. Deep Residual Network with Channel Attention Mechanism
3. Experiments and Analysis
3.1. Dataset
3.2. Evaluation Metrics
3.3. Experimental Results and Analysis
3.3.1. Comparison Experiment of Different Network Models
3.3.2. Comparative Experiment for the Parameter r of SE Module
3.3.3. Comparison Experiment with Existing Methods
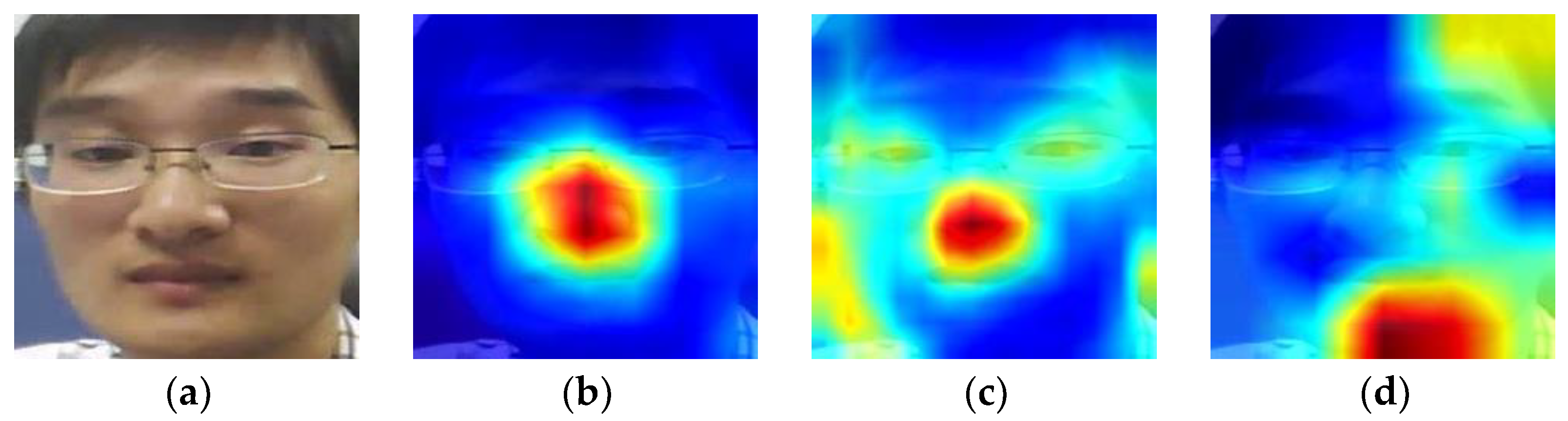
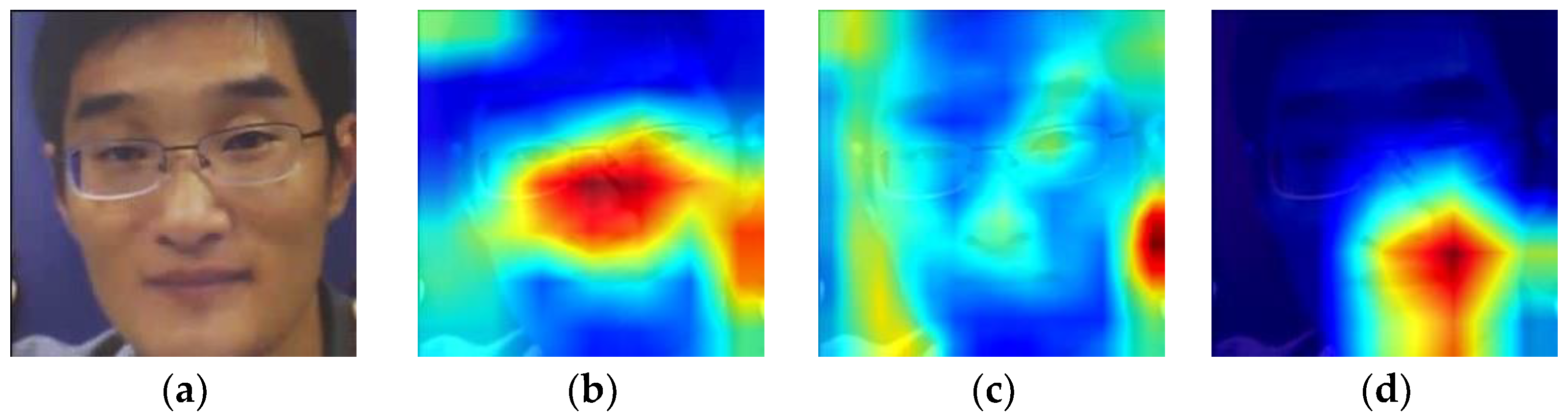
3.3.4. Enhance the Robustness of the Method to Illumination
4. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Costa-Pazo, A.; Bhattacharjee, S.; Vazquez-Fernandez, E.; Marcel, S. The replay-mobile face presentation-attack database. In Proceedings of the 2016 International Conference of the Biometrics Special Interest Group (BIOSIG), Darmstadt, Germany, 21–23 September 2016; pp. 1–7. [Google Scholar]
- Chingovska, I.; Anjos, A.; Marcel, S. On the Effectiveness of Local Binary Patterns in Face Anti-spoofing. In Proceedings of the 2012 BIOSIG Proceedings of the International Conference of Biometrics Special Interest Group (BIOSIG), Darmstadt, Germany, 6–7 September 2012; IEEE: Piscataway, NJ, USA, 2012; pp. 1–7. [Google Scholar]
- Cai, R.; Chen, C. Learning deep forest with multi-scale local binary pattern features for face anti-spoofing. arXiv 2019, arXiv:1910.03850. [Google Scholar]
- Freitas Pereira, T.; Anjos, A.; Martino, J.M.D.; Marcel, S. LBP-TOP based countermeasure against face spoofing attacks. In Proceedings of the Asian Conference on Computer Vision, Daejeon, Korea, 5–9 November 2012; Springer: Berlin/Heidelberg, Germany, 2012; pp. 121–132. [Google Scholar]
- Kong, Y.; Liu, X.; Xie, X.; Li, F. Face Liveness Detection Method Based on Histogram of Oriented Gradient. Laser Optoelectron. Prog. 2018, 55, 237–243. [Google Scholar]
- Boulkenafet, Z.; Komulainen, J.; Hadid, A. Face Spoofing Detection Using Colour Texture Analysis. IEEE Trans. Inf. Forensics Secur. 2017, 11, 1818–1830. [Google Scholar] [CrossRef]
- Yang, J.; Lei, Z.; Li, S.Z. Learn Convolutional Neural Network for Face Anti-Spoofing. Comput. Sci. 2014, 9218, 373–384. [Google Scholar]
- Lucena, O.; Junior, A.; Moia, V.; Souza, R.; Valle, E.; Lotufo, R. Transfer learning using convolutional neural networks for face anti-spoofing. In Proceedings of the International Conference Image Analysis and Recognition, Montreal, QU, Canada, 5–7 July 2017; Springer: Cham, Switzerland, 2017; pp. 27–34. [Google Scholar]
- Deng, X.; Wang, H.C. Face liveness detection algorithm based on deep learning and feature fusion. J. Comput. Appl. 2020, 40, 1009–1015. [Google Scholar]
- Luan, X.; Li, X.S. Face anti-spoofing algorithm based on multi-feature fusion. Comput. Sci. 2021, 48, 409–415. [Google Scholar]
- Yu, Z.; Qin, Y.; Li, X.; Wang, Z.; Zhao, C.; Lei, Z.; Zhao, G. Multi-modal face anti-spoofing based on central difference networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Seattle, WA, USA, 13–19 June 2020; pp. 650–651. [Google Scholar]
- Cai, P.; Quan, H. Face anti-spoofing algorithm combined with CNN and brightness equalization. J. Cent. South Univ. 2021, 28, 194–204. [Google Scholar] [CrossRef]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 7132–7141. [Google Scholar]
- He, J.; Jiang, D. Fully automatic model based on SE-resnet for bone age assessment. IEEE Access 2021, 9, 62460–62466. [Google Scholar] [CrossRef]
- Yoo, J.; Jin, Y.; Ko, B.; Kim, M.S. k-Labelsets Method for Multi-Label ECG Signal Classification Based on SE-ResNet. Appl. Sci. 2021, 11, 7758. [Google Scholar] [CrossRef]
- Tian, F.; Wang, L.; Xia, M. Signals Recognition by CNN Based on Attention Mechanism. Electronics 2022, 11, 2100. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 770–778. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the inception architecture for computer vision. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2818–2826. [Google Scholar]
- Zhou, B.; Khosla, A.; Lapedriza, A.; Oliva, A.; Torralba, A. Learning deep features for discriminative localization. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 2921–2929. [Google Scholar]
- Atoum, Y.; Liu, Y.; Jourabloo, A.; Liu, X. Face anti-spoofing using patch and depth-based CNNs. In Proceedings of the 2017 IEEE International Joint Conference on Biometrics (IJCB), Denver, CO, USA, 1–4 October 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 319–328. [Google Scholar]
- Rehman, Y.A.U.; Po, L.M.; Liu, M. LiveNet: Improving features generalization for face liveness detection using convolution neural networks. Expert Syst. Appl. 2018, 108, 159–169. [Google Scholar] [CrossRef]
- Chen, H.; Hu, G.; Lei, Z.; Chen, Y.; Robertson, N.M.; Li, S.Z. Attention-based two-stream convolutional networks for face spoofing detection. IEEE Trans. Inf. Forensics Secur. 2019, 15, 578–593. [Google Scholar] [CrossRef] [Green Version]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Network Model | Replay-Attack | CASIA-FASD |
|---|---|---|
| VGG16 | 0.9408 | 0.9305 |
| InceptionV3 | 0.9381 | 0.9232 |
| ResNet50 | 0.9694 | 0.9555 |
| r | Replay-Attack | CASIA-FASD | Model Parameters (Ten Million) | ||
|---|---|---|---|---|---|
| EER | ACC | EER | ACC | ||
| - | 0.46 | 0.9694 | 2.84 | 0.9555 | - |
| 4 | 0.22 | 0.9978 | 2.40 | 0.9697 | 2637 |
| 8 | 0.09 | 0.9991 | 1.76 | 0.9783 | 2498 |
| 16 | 0.02 | 0.9998 | 2.02 | 0.9775 | 2428 |
| 32 | 0.14 | 0.9986 | 2.28 | 0.9717 | 2393 |
| Method | Replay-Attack | CASIA-FASD | ||
|---|---|---|---|---|
| EER | HTER | EER | HTER | |
| LBP | 14.41 | 15.45 | 24.63 | 23.19 |
| LBP-TOP | 7.9 | 7.6 | - | - |
| CNN | 4.414 | 2.53 | 6.98 | 6.99 |
| FASNet | 0.16 | 0.04 | 5.25 | 11.34 |
| Patch + depthCNN | 0.79 | 0.72 | 2.67 | 2.27 |
| LiveNet | - | 5.74 | - | 4.59 |
| MSR-Attention | 0.21 | 0.39 | 3.15 | - |
| SE-ResNet50 | 0.20 | 0.02 | 2.02 | 1.84 |
| Ambient Light Conditions | EER | ACC |
|---|---|---|
| High light | 1.32 | 0.9792 |
| Normal light | 1.13 | 0.9798 |
| Dark light | 1.71 | 0.9773 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kong, Y.; Li, X.; Hao, G.; Liu, C. Face Anti-Spoofing Method Based on Residual Network with Channel Attention Mechanism. Electronics 2022, 11, 3056. https://doi.org/10.3390/electronics11193056
Kong Y, Li X, Hao G, Liu C. Face Anti-Spoofing Method Based on Residual Network with Channel Attention Mechanism. Electronics. 2022; 11(19):3056. https://doi.org/10.3390/electronics11193056
Chicago/Turabian StyleKong, Yueping, Xinyuan Li, Guangye Hao, and Chu Liu. 2022. "Face Anti-Spoofing Method Based on Residual Network with Channel Attention Mechanism" Electronics 11, no. 19: 3056. https://doi.org/10.3390/electronics11193056