
Sarcasm Detection over Social Media Platforms Using Hybrid Auto-Encoder-Based Model




Abstract
:1. Introduction
1.1. Challenges in Sarcasm Detection
1.2. Major Contribution
- Creating a reliable and effective hybrid autoencoder-based model to detect sarcasm on social sites. The model employs a LSTM-based autoencoder for further learning from the results.
- The novelty lies in combining hybrid models from sentence-based embeddings and unsupervised learning utilizing the autoencoder to overcome their limitations. The models are selected by using ablation method and selecting those models which can cover the diverse range of real-time datasets.
- The model is tested against publicly available real-world social media datasets such as Twitter and Reddit. Validation on the real-world datasets is true measure of the metrics for the model. The models can be employed directly over real-world social media contents and can handle diverse contents.
- The model’s application is universal and can be used on diverse social media platforms. Datasets have diversified short tweets from Twitter, short sentence from Reddit, and long sentences from newspaper lines.
2. Related Work
Current Issues
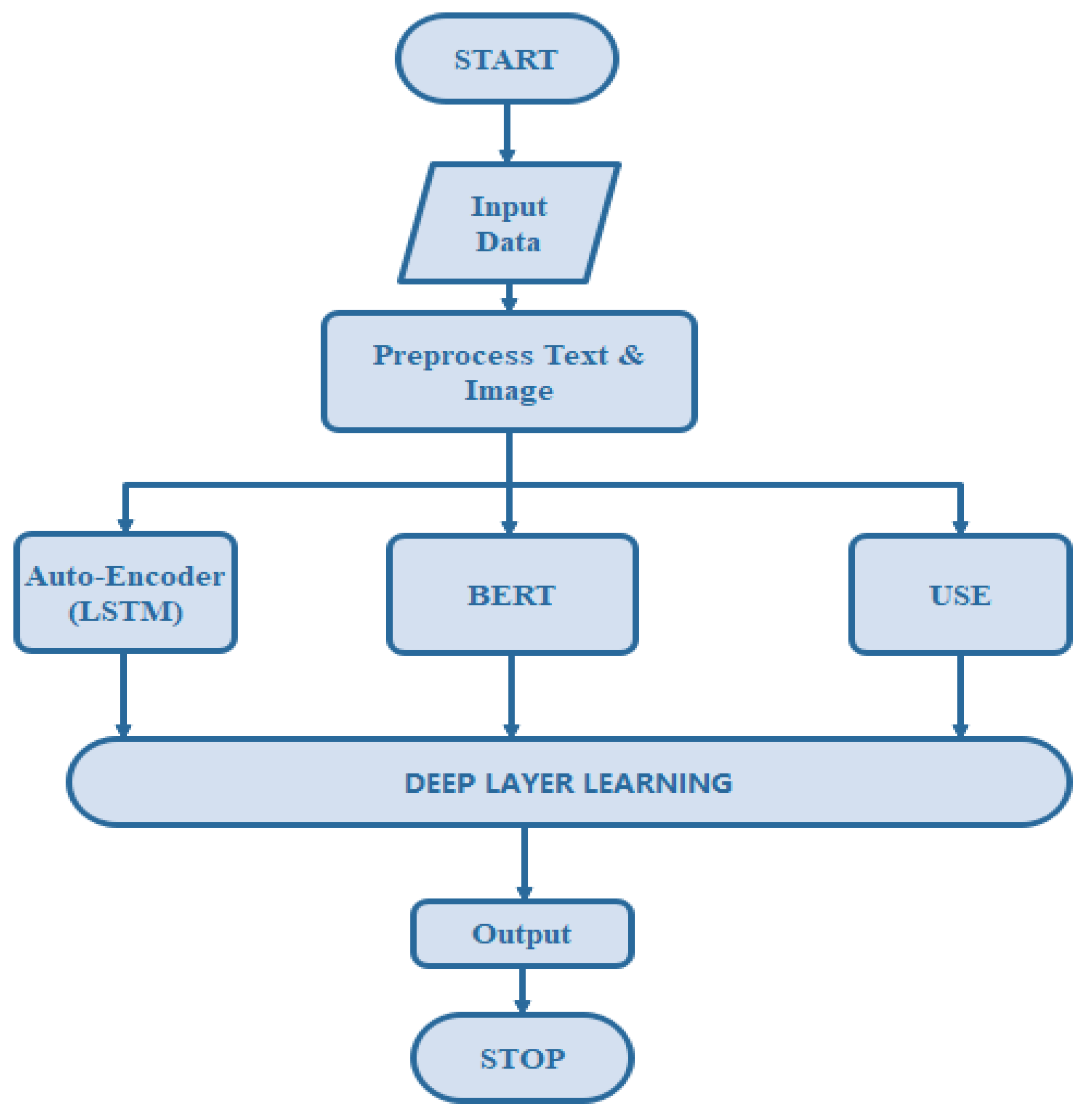
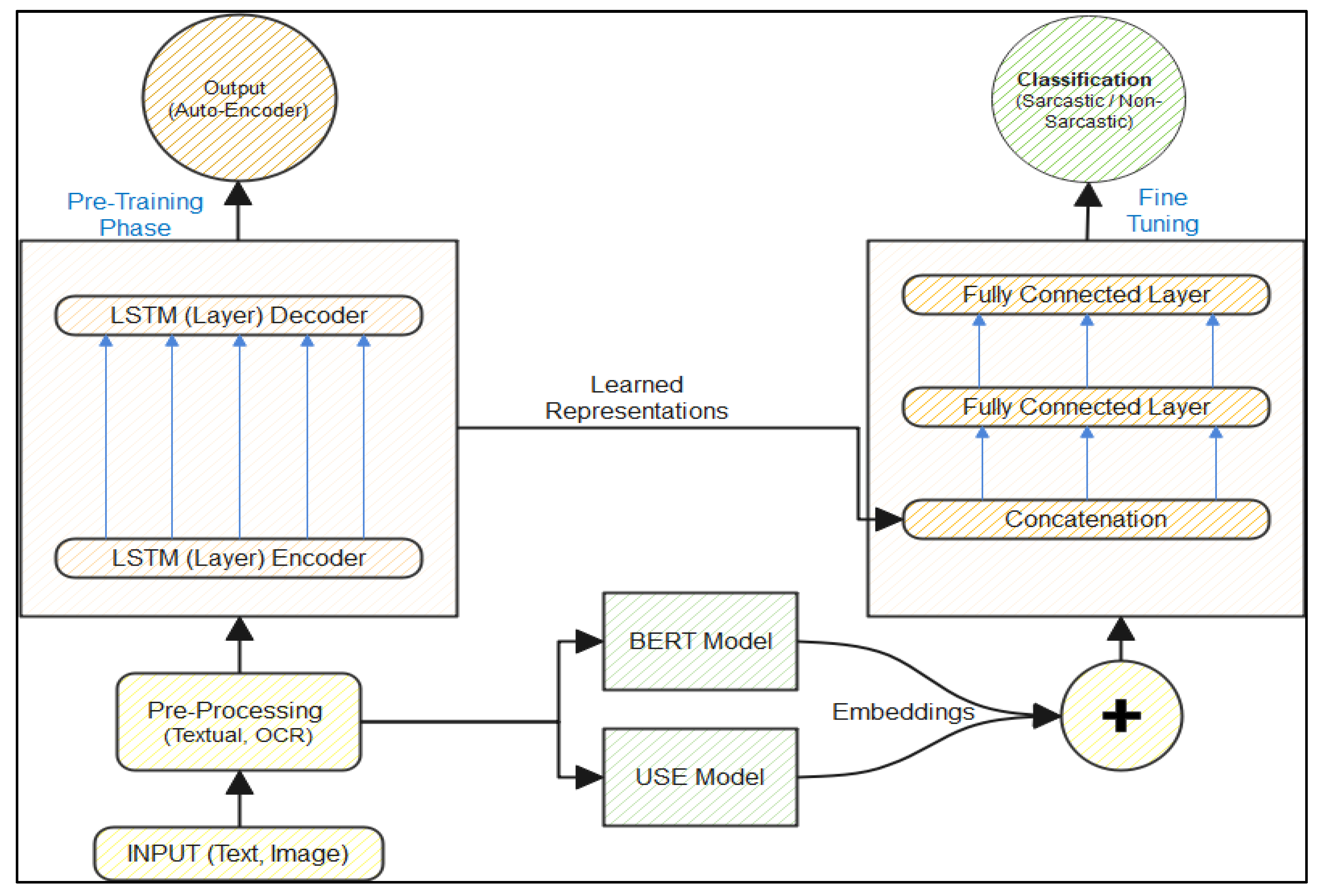
3. Proposed Model
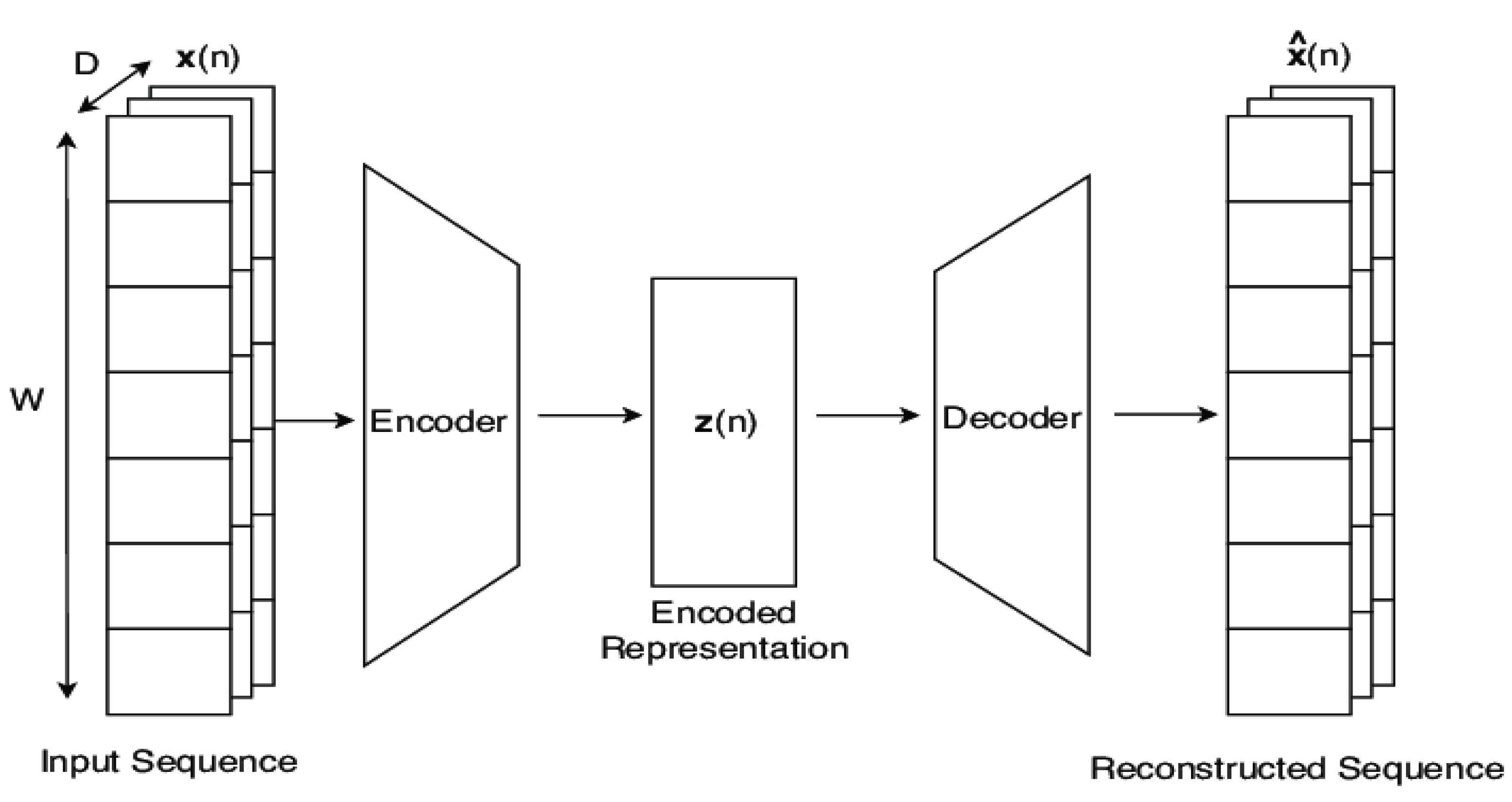
3.1. AutoEncoder
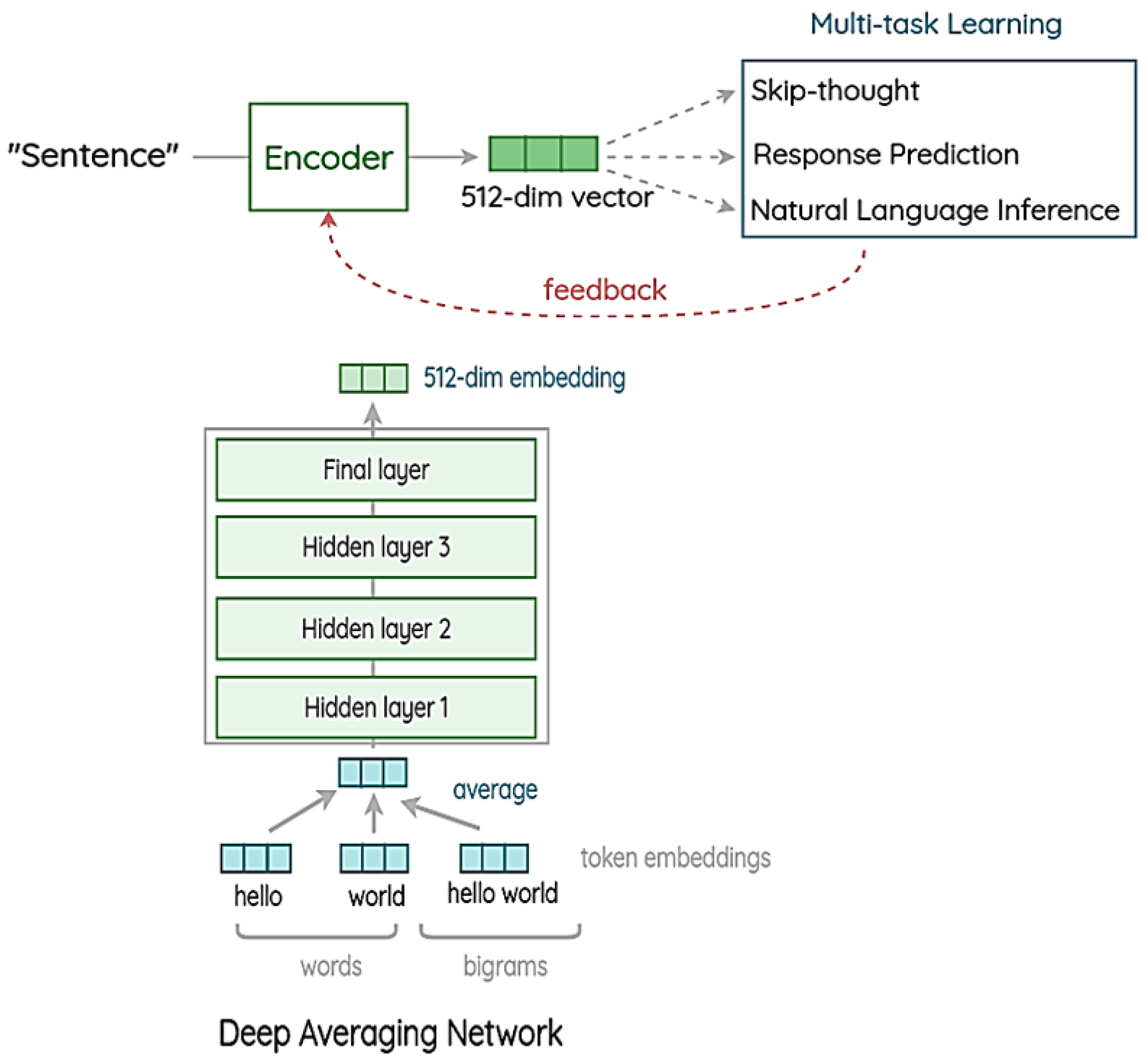
3.2. Universal Sentence Encoder (USE)
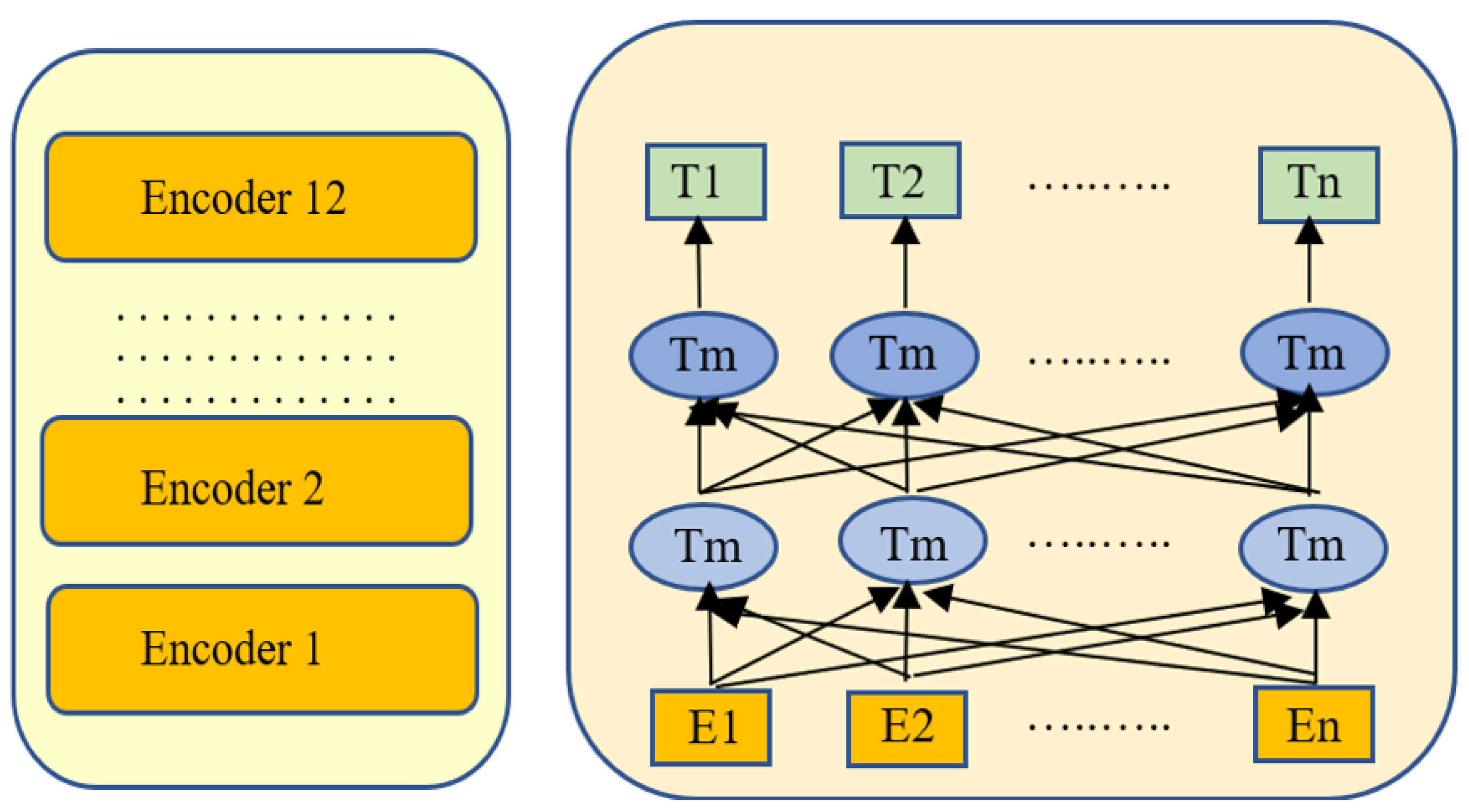
3.3. BERT
4. Experimental Results
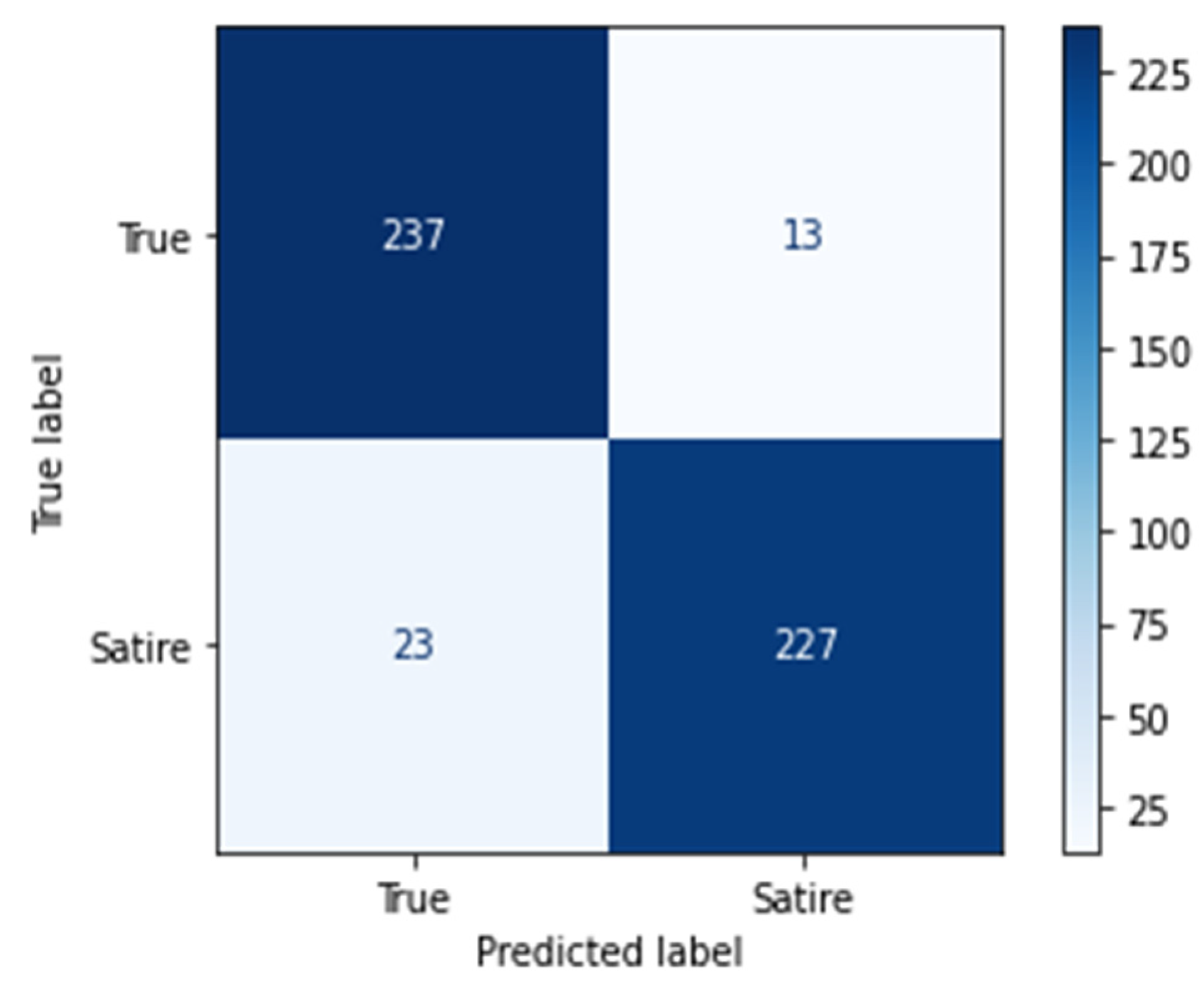
4.1. Datasets
4.1.1. Twitter Dataset
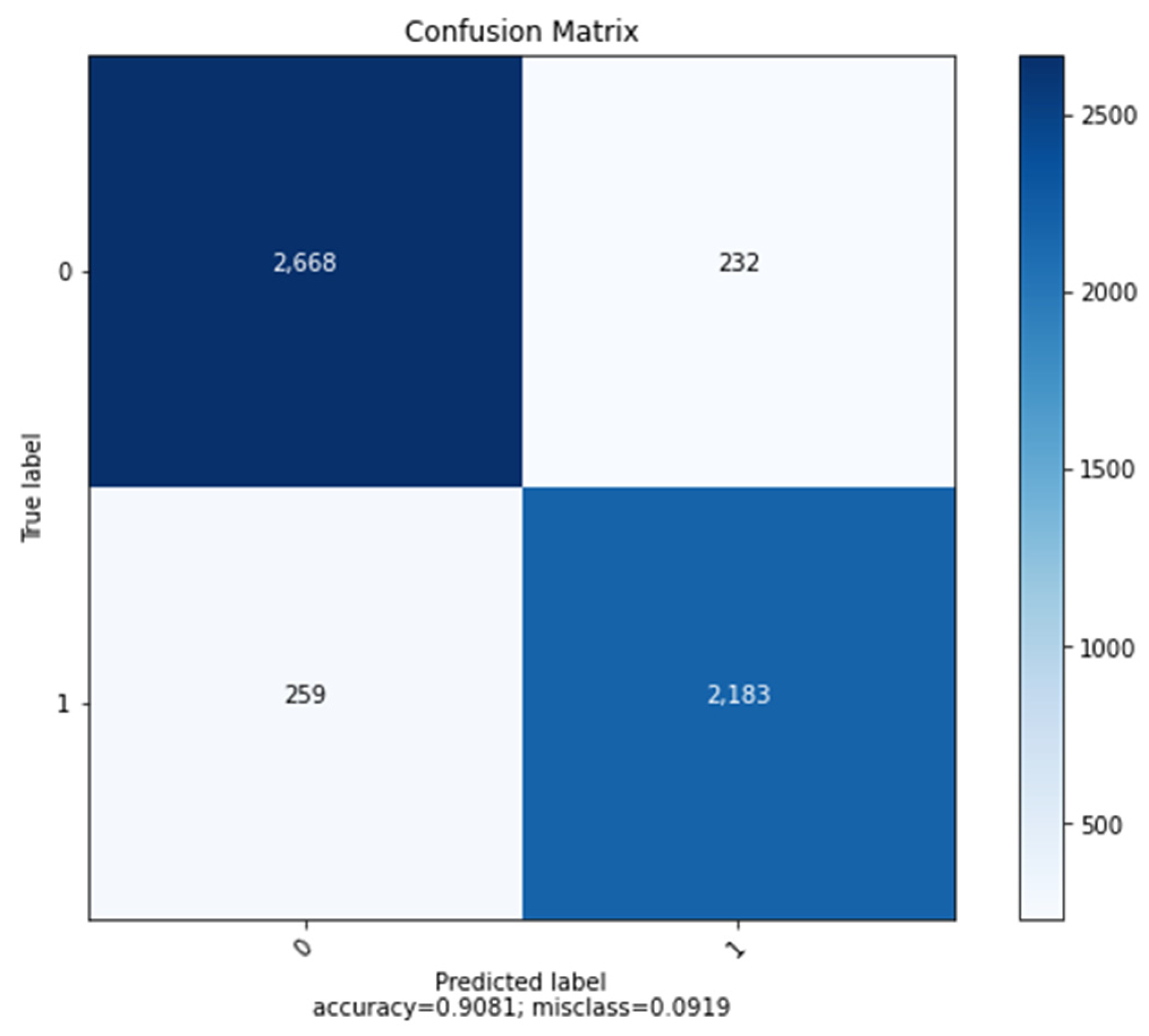
4.1.2. SARC Dataset
4.1.3. Headline Dataset
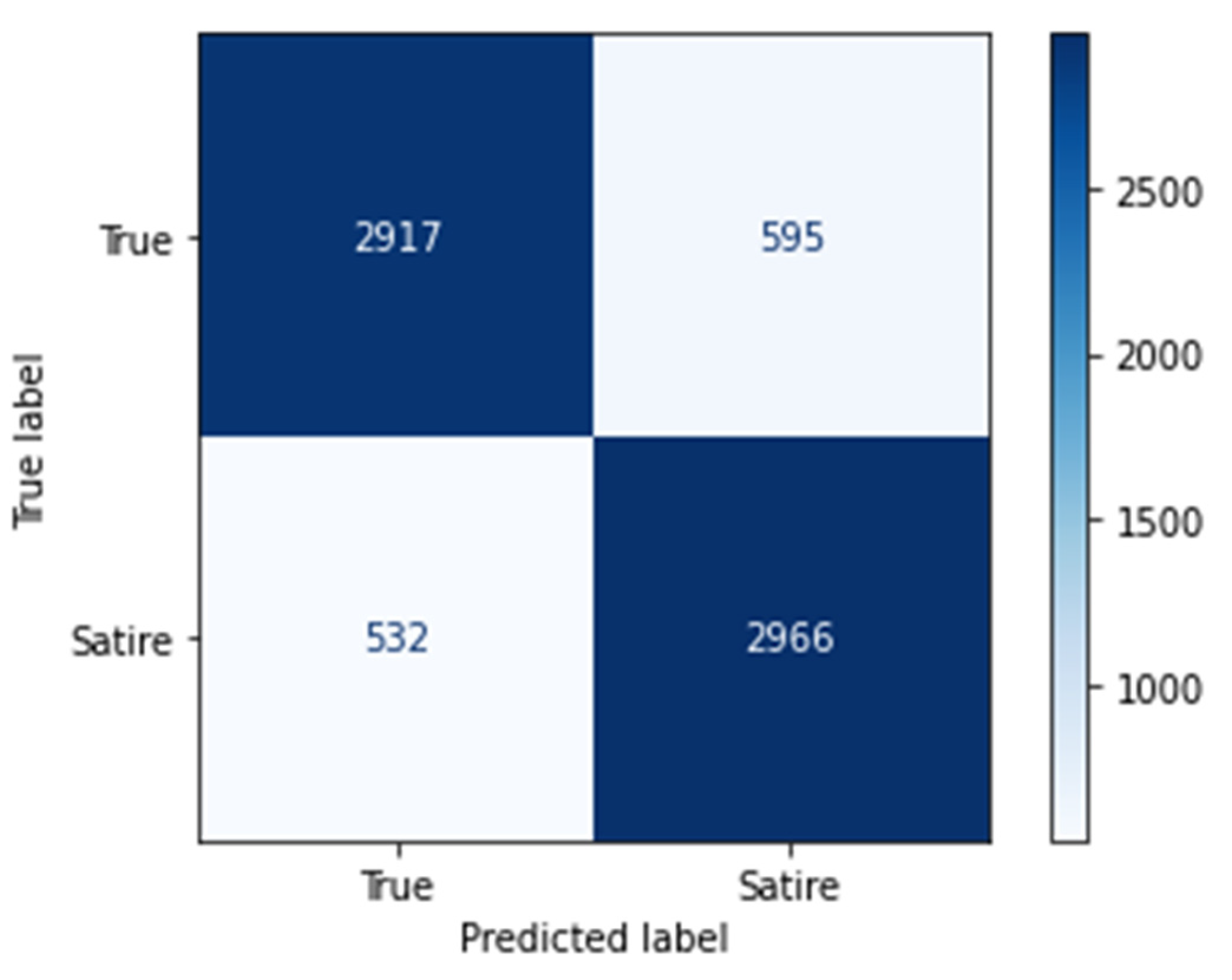
4.2. Performance Measure
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Conflicts of Interest
References
- Rothermich, K.; Ogunlana, A.; Jaworska, N. Change in humor and sarcasm use based on anxiety and depression symptom severity during the COVID-19 pandemic. J. Psychiatr. Res. 2021, 140, 95–100. [Google Scholar] [CrossRef] [PubMed]
- Edwards, V.V. Sarcasm: What It Is and Why It Hurts Us. 2014. Available online: https://www.scienceofpeople.com/sarcasm-why-it-hurts-us/ (accessed on 5 October 2021).
- Lv, J.; Wang, X.; Shao, C. TMIF: Transformer-based multimodal interactive fusion for automatic rumor detection. Multimed. Syst. 2022. [Google Scholar] [CrossRef]
- Dutta, P.; Bhattacharyya, C.K. Multi-Modal Sarcasm Detection in Social Networks: A Comparative Review. In Proceedings of the 6th International Conference on Computing Methodologies and Communication (ICCMC), Erode, India, 29–31 March 2022; pp. 207–214. [Google Scholar] [CrossRef]
- Ezaiza, H.; Humayoun, S.R.; AlTarawneh, R.; Ebert, A. Person-vis: Visualizing personal social networks (ego networks). In Proceedings of the 2016 CHI Conference Extended Abstracts on Human Factors in Computing Systems, San Jose, CA, USA, 7–12 May 2016; pp. 1222–1228. [Google Scholar] [CrossRef]
- Akula, R.; Garibay, I. Viztract: Visualization of complex social networks for easy user perception. Big Data Cogn. Comput. 2019, 3, 17. [Google Scholar] [CrossRef]
- Kumar, A.; Sachdeva, N. Multi-input integrative learning using deep neural networks and transfer learning for cyberbullying detection in real-time code-mix data. Multimed. Syst. 2022. [Google Scholar] [CrossRef]
- Akhter, M.P.; Jiangbin, Z.; Naqvi, I.R.; AbdelMajeed, M.; Zia, T. Abusive language detection from social media comments using conventional machine learning and deep learning approaches. Multimed. Syst. 2020. [Google Scholar] [CrossRef]
- Govindan, V.; Balakrishnan, V. A machine learning approach in analysing the effect of hyperboles using negative sentiment tweets for sarcasm detection. J. King Saud Univ.—Comput. Inf. Sci. 2022, 34, 5110–5120. [Google Scholar] [CrossRef]
- Frontlist. Indian Twitter Says Will Boycott Spiderman. Available online: https://www.frontlist.in/indian-twitter-says-will-boycott-spiderman (accessed on 8 October 2021).
- Gabulaitė, V. Twitter Burns That Definitely Left a Mark. Available online: https://www.boredpanda.com/funny-twitter-burns-comebacks/?utm_source=google&utm_medium=organic&utm_campaign=organic (accessed on 8 October 2021).
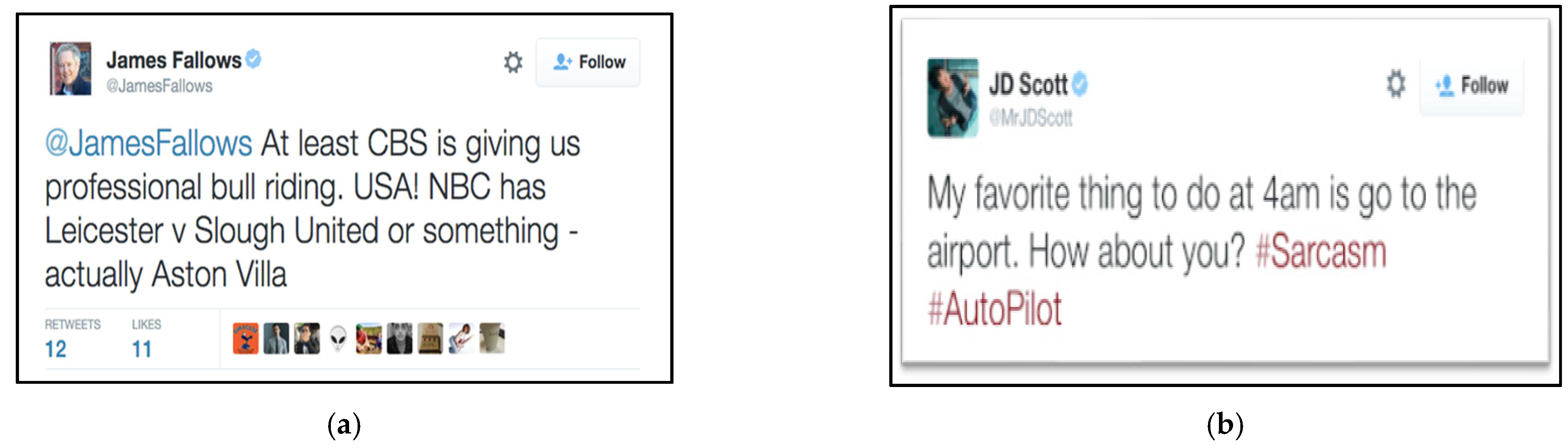
- Fallows, J. Why Twitter Doesn’t Work with Sarcasm, Chap. 823. Available online: https://www.theatlantic.com/technology/archive/2016/01/why-twitter-doesnt-work-with-sarcasm-chap-823/625245/ (accessed on 8 October 2021).
- Bamman, D.; Smith, N. Contextualized Sarcasm Detection on Twitter. In Proceedings of the International AAAI Conference on Web and Social Media, Atlanta, GA, USA, 6–9 June 2022; Available online: https://ojs.aaai.org/index.php/ICWSM/article/view/14655 (accessed on 5 October 2021).
- Singh, B.; Sharma, D.K.; Garg, A. An Ensemble Model for detecting Sarcasm on Social Media. In Proceedings of the 2022 9th International Conference on Computing for Sustainable Global Development (INDIACom), Delhi, India, 23–25 March 2022. [Google Scholar]
- Wallace, B.C. Computational irony: A survey and new perspectives. Artif. Intell. Rev. 2015, 43, 467–483. [Google Scholar] [CrossRef]
- Eke, C.I.; Norman, A.A.; Shuib, L.; Nweke, H.F. Sarcasm identification in textual data: Systematic review, research challenges and open directions. Artif. Intell. Rev. 2020, 53, 4215–4258. [Google Scholar] [CrossRef]
- Sarsam, S.M.; Al-Samarraie, H.; Alzahrani, A.I.; Wright, B. Sarcasm detection using machine learning algorithms in Twitter: A systematic review. Int. J. Mark. Res. 2020, 62, 578–598. [Google Scholar] [CrossRef]
- Khodak, M.; Saunshi, N.; Vodrahalli, K. A large self-annotated corpus for sarcasm. In Proceedings of the Eleventh International Conference on Language Resources and Evaluation (LREC), Miyazaki, Japan, 7–12 May 2018. [Google Scholar]
- Keerthi Kumar, H.M.; Harish, B.S. Sarcasm classification: A novel approach by using Content Based Feature Selection Method. Procedia Comput. Sci. 2018, 143, 378–386. [Google Scholar] [CrossRef]
- Pawar, N.; Bhingarkar, S. Machine Learning based Sarcasm Detection on Twitter Data. In Proceedings of the 5th International Conference on Communication and Electronics Systems (ICCES), Coimbatore, India, 10–12 June 2020. [Google Scholar] [CrossRef]
- Ghosh, A.; Veale, T. Magnets for sarcasm: Making sarcasm detection timely, contextual and very personal. In Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, Copenhagen, Denmark, 10 September 2017; pp. 482–491. [Google Scholar] [CrossRef]
- Ghosh, D.; Fabbri, A.S.; Muresan, S. Sarcasm analysis using conversation context. Comput. Linguist. 2018, 44, 755–792. [Google Scholar] [CrossRef]
- Xiong, T.; Zhang, P.; Zhu, H.; Yang, Y. Sarcasm detection with self-matching networks and low-rank bilinear pooling. In Proceedings of the World Wide Web Conference, San Francisco, CA, USA, 2019, May 13–17; pp. 2115–2124. [CrossRef]
- Liu, L.; Priestley, J.L.; Zhou, Y.; Ray, H.E.; Han, M. A2text-net: A novel deep neural network for sarcasm detection. In Proceedings of the IEEE First International Conference on Cognitive Machine Intelligence (CogMI), Los Angeles, CA, USA, 12–14 December 2019; pp. 118–126. [Google Scholar] [CrossRef]
- Misra, R.; Arora, P. Sarcasm detection using hybrid neural network. arXiv 2019, arXiv:1908.07414. [Google Scholar]
- Akula, R.; Garibay, I. Interpretable Multi-Head Self-Attention Model for Sarcasm Detection in Social Media. Entropy 2021, 23, 394. [Google Scholar] [CrossRef] [PubMed]
- Kamal, A.; Abulaish, M. CAT-BiGRU: Convolution and Attention with Bi-Directionoval Gated Recurrent Unit for Self-Deprecating Sarcasm Detection. Cogn. Comput. 2022, 14, 91–109. [Google Scholar] [CrossRef]
- Babanejad, N.; Davoudi, H.; An, A.; Papagelis, M. Affective and Contextual Embedding for Sarcasm Detection. In Proceedings of the 28th International Conference on Computational Linguistics, Barcelona, Spain, 12 December 2020. [Google Scholar] [CrossRef]
- Potamias, R.A.; Siolas, G.; Stafylopatis, A. A transformer-based approach to irony and sarcasm detection. Neural Comput. Appl. 2020, 32, 17309–17320. [Google Scholar] [CrossRef]
- Sundararajan, K.; Palanisamy, A. Multi-Rule Based Ensemble Feature Selection Model for Sarcasm Type Detection in Twitter. Comput. Intell. Neurosci. 2020, 2020, e2860479. [Google Scholar] [CrossRef]
- Goel, P.; Jain, R.; Nayyar, A.; Singhal, S.; Srivastava, M. Sarcasm detection using deep learning and ensemble learning. Multimed. Tools Appl. 2022. [Google Scholar] [CrossRef]
- Du, Y.; Li, T.; Pathan, M.S.; Teklehaimanot, H.K.; Yang, Z. An Effective Sarcasm Detection Approach Based on Sentimental Context and Individual Expression Habits. Cogn. Comput. 2022, 14, 78–90. [Google Scholar] [CrossRef]
- Parameswaran, P.; Trotman, A.; Liesaputra, V.; Eyers, D. Detecting the target of sarcasm is hard: Really? Inf. Process. Manag. 2021, 58, 102599. [Google Scholar] [CrossRef]
- Garcia, C.; Țurcan, A.; Howman, H.; Filik, R. Emoji as a tool to aid the comprehension of written sarcasm: Evidence from younger and older adults. Comput. Hum. Behav. 2022, 126, 106971. [Google Scholar] [CrossRef]
- Yao, F.; Sun, X.; Yu, H.; Zhang, W.; Liang, W.; Fu, K. Mimicking the Brain’s Cognition of Sarcasm from Multidisciplines for Twitter Sarcasm Detection. IEEE Trans. Neural Netw. Learn. Syst. 2021, 1–15. [Google Scholar] [CrossRef] [PubMed]
- Hazarika, D.; Poria, S.; Gorantla, S.; Cambria, E.; Zimmermann, R.; Mihalcea, R. Cascade: Contextual sarcasm detection in online discussion forums. In Proceedings of the 27th International Conference on Computational Linguistics, Santa Fe, NM, USA, 20–26 August 2018; pp. 837–1848. Available online: https://aclanthology.org/C18-1156 (accessed on 12 May 2020).
- Ilic’, S.; Marrese-Taylor, E.; Balazs, J.A.; Matsuo, Y. Deep contextualized word representations for detecting sarcasm and irony. In Proceedings of the 9th Workshop on Computational Approaches to Subjectivity, Sentiment and Social Media Analysis, Brussels, Belgium, 31 October 2018; pp. 2–7. [Google Scholar] [CrossRef]
- Agrawal, A.; An, A.; Papagelis, M. Leveraging Transitions of Emotions for Sarcasm Detection. In Proceedings of the 43rd International ACM SIGIR Conference on Research and Development in Information Retrieval, Virtual, China, 25–30 July 2020; pp. 1505–1508. [Google Scholar] [CrossRef]
- Malave, N.; Dhage, S.N. Sarcasm Detection on Twitter: User Behavior Approach. In Advances in Intelligent Systems and Computing; Springer: Singapore, 2020; Volume 910. [Google Scholar] [CrossRef]
- Sykora, M.; Elayan, S.; Jackson, T.W. A qualitative analysis of sarcasm, irony and related #hashtags on Twitter. Big Data Soc. 2020. [Google Scholar] [CrossRef]
- Ding, N.; Tian, S.W.; Yu, L. A multimodal fusion method for sarcasm detection based on late fusion. Multimed. Tools Appl. 2022, 81, 8597–8616. [Google Scholar] [CrossRef]
- Wen, Z.; Gui, L.; Wang, Q.; Guo, M.; Yu, X.; Du, J.; Xu, R. Sememe knowledge and auxiliary information enhanced approach for sarcasm detection. Inf. Processing Manag. 2022, 59, 102883. [Google Scholar] [CrossRef]
- Techentin, C.; Cann, D.R.; Lupton, M.; Phung, D. Sarcasm detection in native English and English as a second language speakers. Can. J. Exp. Psychol./Rev. Can. De Psychol. Expérimentale 2021, 75, 133–138. [Google Scholar] [CrossRef] [PubMed]
- Farha, I.A.; Magdy, W. From Arabic Sentiment Analysis to Sarcasm Detection: The ArSarcasm Dataset. In Proceedings of the 4th Workshop on Open-Source Arabic Corpora and Processing Tools, with a Shared Task on Offensive Language Detection, Marseille, France; Available online: https://aclanthology.org/2020.osact-1.5 (accessed on 12 May 2020).
- Al-Hassan, A.; Al-Dossari, H. Detection of hate speech in Arabic tweets using deep learning. Multimed. Syst. 2021. [Google Scholar] [CrossRef]
- Swami, S.; Khandelwal, A.; Singh, V.; Akhtar, S.S.; Shrivastava, M. A Corpus of English-Hindi Code-Mixed Tweets for Sarcasm Detection. arXiv 2018, arXiv:1805.11869v1. [Google Scholar]
- Trinh, H.Y.; Zeydan, E.; Giupponi, L.; Dini, P. Detecting Mobile Traffic Anomalies Through Physical Control Channel Fingerprinting: A Deep Semi-Supervised Approach. IEEE Access 2019, 7, 152187–152201. [Google Scholar] [CrossRef]
- Iyyer, M.; Manjunatha, V.; Boyd-Graber, J.; Daumé, H. Deep Unordered Composition Rivals Syntactic Methods for Text Classification. In Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing (Volume 2: Short Papers), Beijing, China, 26–31 July 2015; Association for Computational Linguistics: Stroudsburg, PA, USA, 2015; pp. 1681–1691. [Google Scholar]
- Devlin, J.; Chang, M.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. arXiv 2019, arXiv:1810.04805v2. [Google Scholar]
- Goyal, C. Part 6: Step by Step Guide to Master NLP—Word2Vec. Available online: https://www.analyticsvidhya.com/blog/2021/06/part-6-step-by-step-guide-to-master-nlp-word2vec/ (accessed on 8 October 2021).
- Singh, B.; Sharma, D.K. Predicting image credibility in fake news over social media using multimodal approach. Neural Comput. Appl. 2021. [Google Scholar] [CrossRef]
- Kumar, A.; Narapareddy, V.T.; Srikanth, V.A.; Malapati, A.; Neti, L.B.M. Sarcasm Detection Using Multi-Head Attention Based Bidirectional LSTM. IEEE Access 2020, 8, 6388–6397. [Google Scholar] [CrossRef]
- Agarwal, R.; Jalal, A.S.; Agrawal, S.C.; Arya, K.V. Fake and Live Fingerprint Detection Using Local Diagonal Extrema Pattern and Local Phase Quantization. In Conference Proceedings of ICDLAIR2019; Lecture Notes in Networks and Systems; Tripathi, M., Upadhyaya, S., Eds.; Springer: Cham, Switzerland, 2019; Volume 175. [Google Scholar] [CrossRef]
- Pradhan, R.; Agarwal, G.; Singh, D. Comparative Analysis for Sentiment in Tweets Using LSTM and RNN. In International Conference on Innovative Computing and Communications; Advances in Intelligent Systems and, Computing; Khanna, A., Gupta, D., Bhattacharyya, S., Hassanien, A.E., Anand, S., Jaiswal, A., Eds.; Springer: Singapore, 2022; Volume 1387. [Google Scholar] [CrossRef]
- Pradhan, R. Extracting Sentiments from YouTube Comments. In Proceedings of the 2021 Sixth International Conference on Image Information Processing (ICIIP), Shimla, India, 26–28 November 2021; pp. 1–4. [Google Scholar] [CrossRef]
- Jain, V.; Agrawal, M.; Kumar, A. Performance Analysis of Machine Learning Algorithms in Credit Cards Fraud Detection. In Proceedings of the 2020 8th International Conference on Reliability, Infocom Technologies and Optimization (Trends and Future Directions) (ICRITO), Noida, India, 4–5 June 2020; pp. 86–88. [Google Scholar] [CrossRef]

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
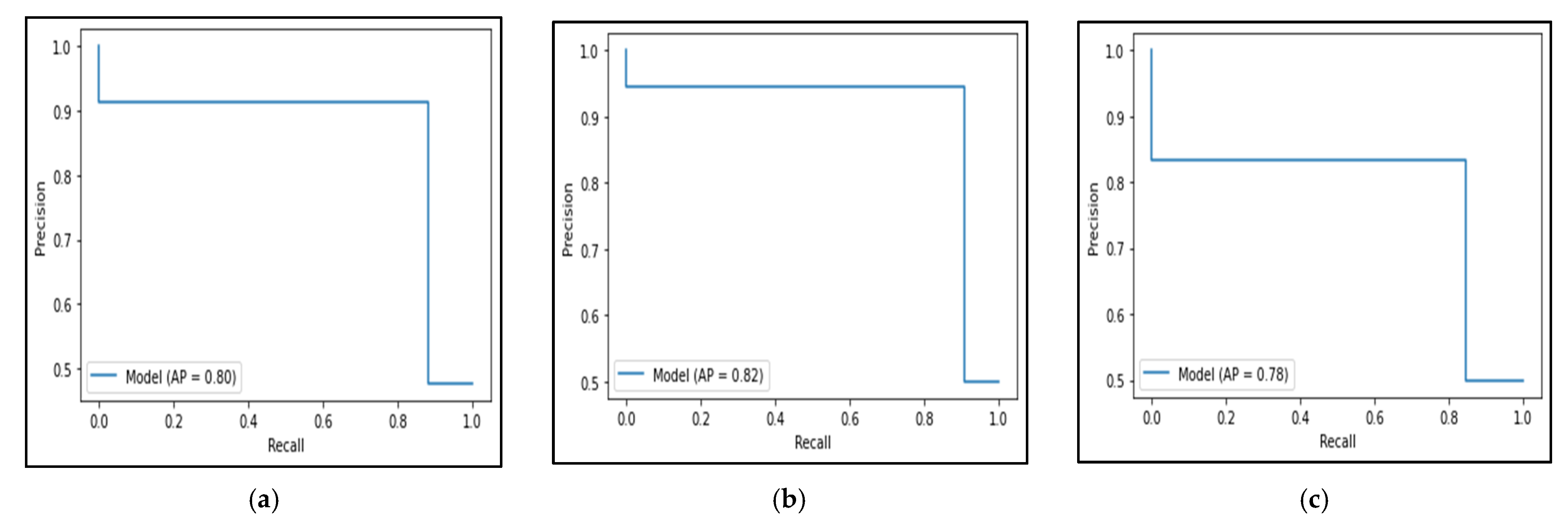{kind=link}
| Dataset | SARC | Headlines | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Models | Acc. | Prec. | Recall | MCC | Acc. | Prec. | Recall | MCC | Acc. | Prec. | Recall | MCC |
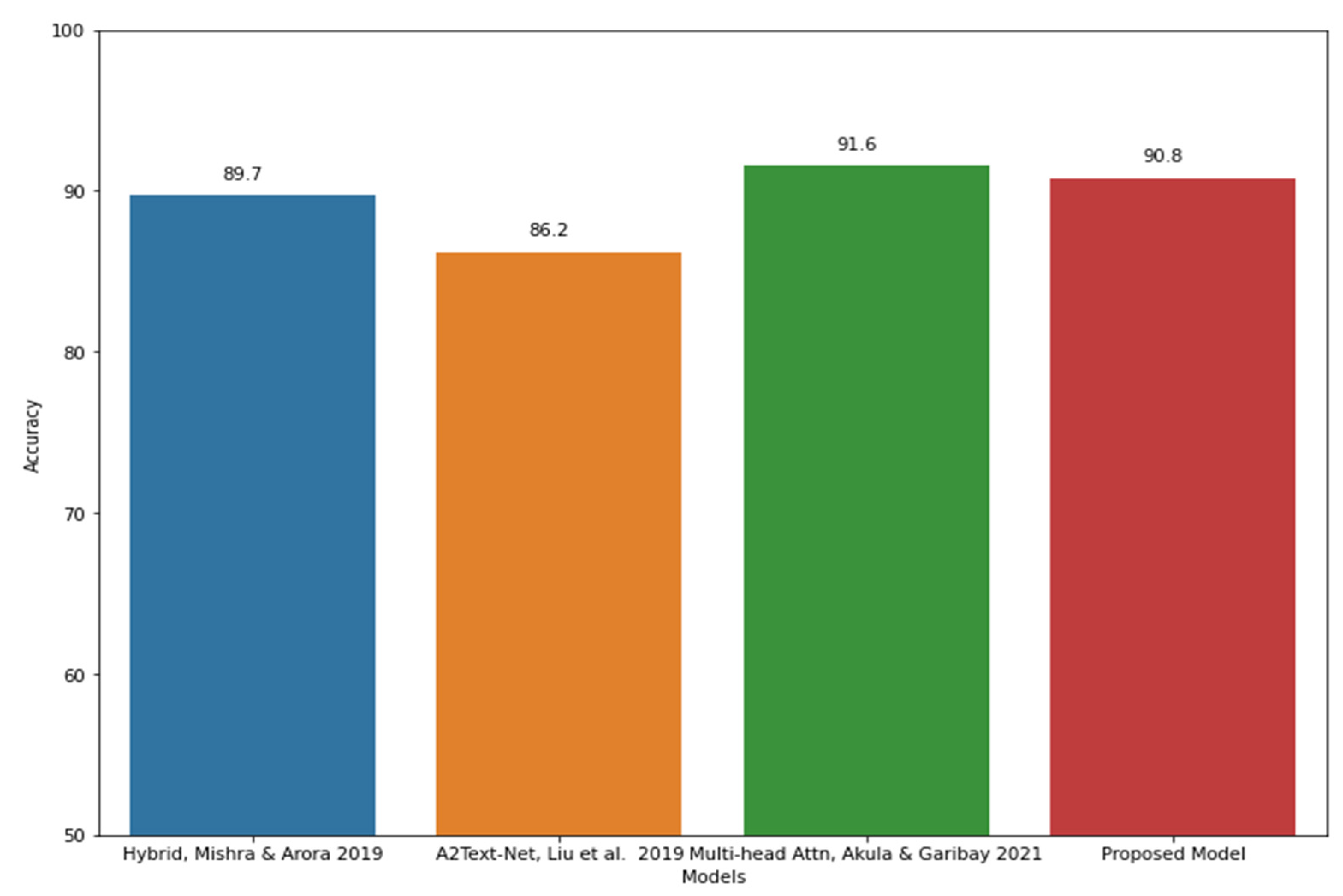
| Auto-Encoder | 80.91% | 0.81 | 0.8 | 0.66 | 89.75% | 0.9 | 0.88 | 0.8 | 91.89% | 0.92 | 0.89 | 0.85 |
| USE + Auto-Encoder | 82.46% | 0.82 | 0.82 | 0.67 | 89.90% | 0.91 | 0.86 | 0.81 | 92.32% | 0.93 | 0.92 | 0.85 |
| BERT + Auto-Encoder | 82.42% | 0.83 | 0.81 | 0.67 | 90.35% | 0.91 | 0.88 | 0.81 | 92.40% | 0.94 | 0.91 | 0.85 |
| USE + BERT + Auto-Encoder (Proposed) | 83.92% | 0.83 | 0.85 | 0.68 | 90.81% | 0.92 | 0.912 | 0.81 | 92.80% | 0.95 | 0.91 | 0.86 |
| Models | Accuracy | Precision | Recall | F1 |
|---|---|---|---|---|
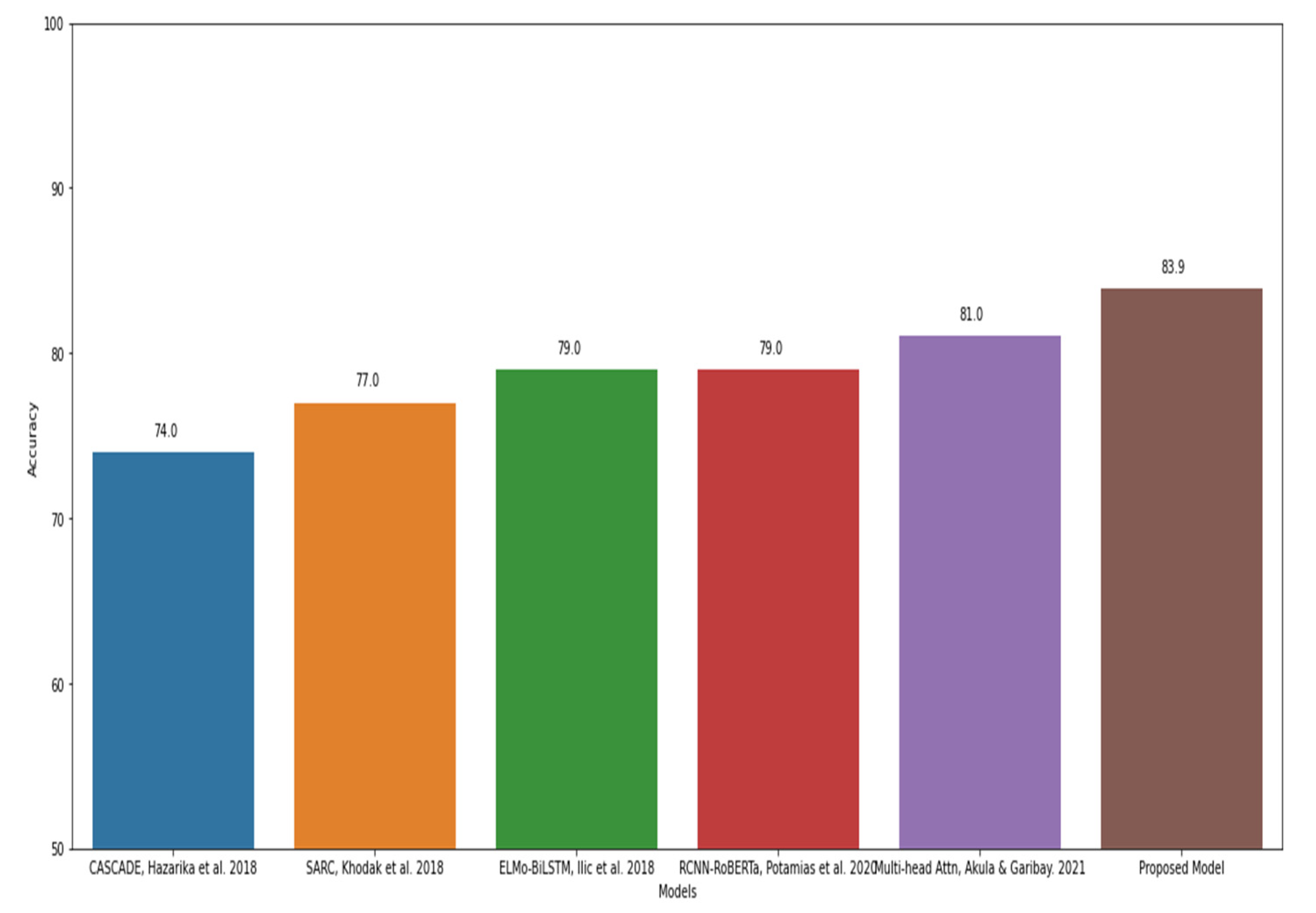
| CASCADE [36] | 74.00% | - | - | 0.75 |
| SARC [18] | 77.00% | - | - | - |
| Elmo-BiLSTM [37] | 79.00% | - | - | - |
| RCNN-RoBERTa [29] | 79.00% | 0.78 | 0.78 | 0.78 |
| Multi-Head Attn [26] | 81.00% | - | - | - |
| Proposed Model | 83.92% | 0.83 | 0.85 | 0.84 |
| Models | Accuracy | Precision | Recall | F1 |
|---|---|---|---|---|
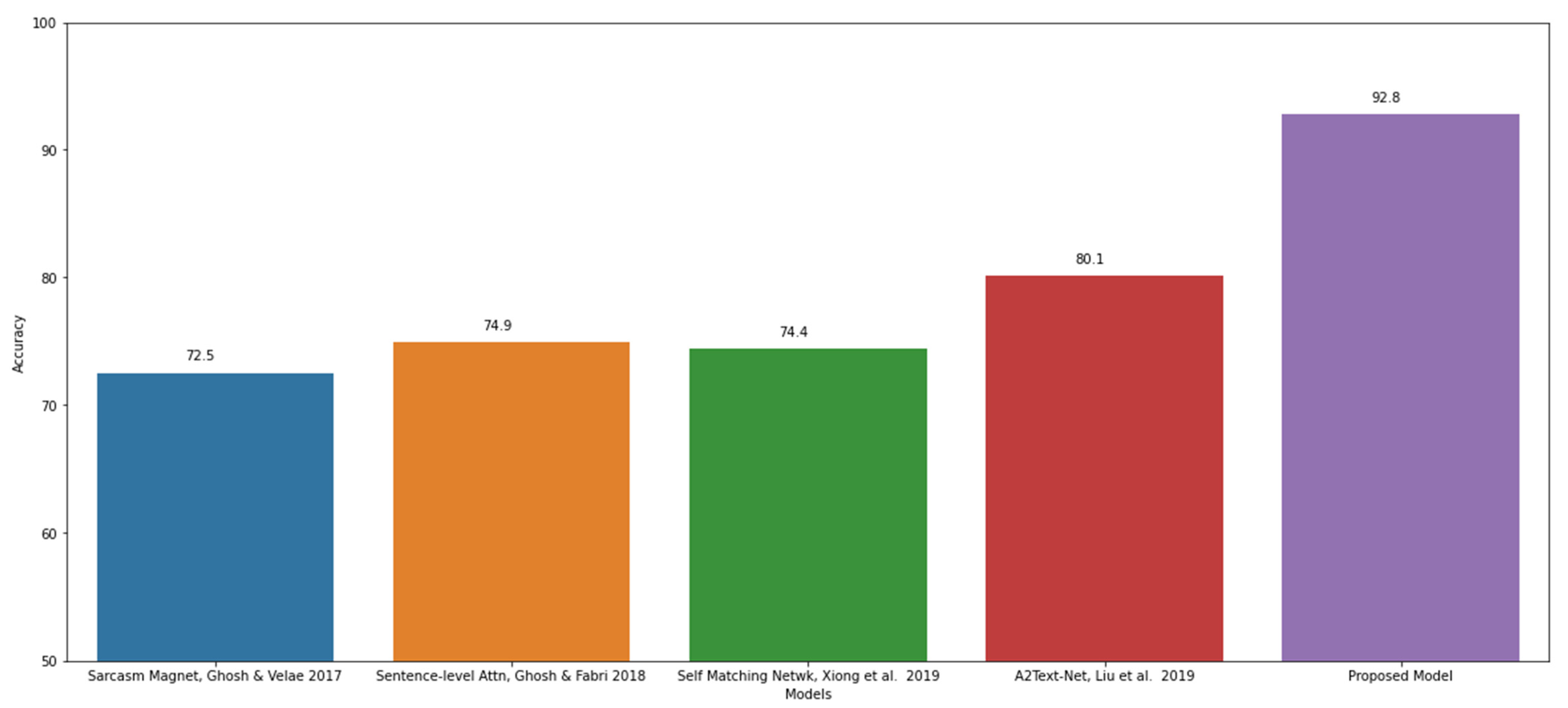
| Sarcasm Magnet [21] | - | 0.90 | 0.89 | 0.90 |
| Sentence-level Attn [22] | 74.90% | 0.749 | 0.75 | 749 |
| Self Matching Netwk [23] | 74.40% | 0.763 | 0.725 | 0.744 |
| A2Text-Net [24] | 80.10% | 0.83 | 0.802 | 0.801 |
| Multi-Head Attn [26] | 81.20% | 0.809 | 0.818 | 0.812 |
| Proposed Model | 92.80% | 0.95 | 0.91 | 0.93 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sharma, D.K.; Singh, B.; Agarwal, S.; Kim, H.; Sharma, R. Sarcasm Detection over Social Media Platforms Using Hybrid Auto-Encoder-Based Model. Electronics 2022, 11, 2844. https://doi.org/10.3390/electronics11182844
Sharma DK, Singh B, Agarwal S, Kim H, Sharma R. Sarcasm Detection over Social Media Platforms Using Hybrid Auto-Encoder-Based Model. Electronics. 2022; 11(18):2844. https://doi.org/10.3390/electronics11182844
Chicago/Turabian StyleSharma, Dilip Kumar, Bhuvanesh Singh, Saurabh Agarwal, Hyunsung Kim, and Raj Sharma. 2022. "Sarcasm Detection over Social Media Platforms Using Hybrid Auto-Encoder-Based Model" Electronics 11, no. 18: 2844. https://doi.org/10.3390/electronics11182844