This section firstly describes the structure and problems to be solved in STIN. Then the proposed solutions are described: The FEM is proposed to pre-evaluate the impact of users on overloading. In the proposed FL-LB, the access algorithm runs in a centralized control cell and determines initial access in order to prevent overloading before it occurs. The offloading algorithm runs in each cell and determines how to offload users in the overloaded cells. The proposed metric and algorithms are described in detail in the following subsections.
2.1. Network Structure
We consider an
area in the STIN network. There are in total
N, cells including
terrestrial cells, and one satellite hanging overhead. Terrestrial cells are modeled with reference to [
24] and distributed sparsely in hexagonal cellular cell mode with the inter site distance (ISD)
D. The satellite is modeled as a geostationary Earth orbit (GEO) satellite [
25]. The coverage diameter of a single beam of the satellite is usually 50 to 250 km, which is very large compared with TN coverage. Therefore, in the system we assume the central beam of the satellite covers the whole TN area. TN and NTN cells differ in bandwidth, defined as
and
.
M users are randomly distributed, requiring data transfer at a random rate with an average of
. Users move at a fixed speed
v and with random angles.
TN channel is modeled as a downlink channel with additive white Gaussian noise and Rayleigh fading. The maximum achievable rate is expressed as
where
is bit rate between user
m and cell
n,
is the number of assigned resource blocks (
),
B is the maximum usable bandwidth of the cell,
is the total number of
,
is the transmission power and
is the target block error rate (BLER).
represents the signal to noise ratio (SNR) margin to meet the desired target BLER with the QAM constellation [
26].
is the channel fading coefficient where
means a Gaussian random number in Equation (
4).
is the distance between user
m and cell
n.
is the noise power.
The altitude of GEO is 35,536 km. It has a typical reflector antenna with a circular aperture [
25]. We consider the simulation area is in the coverage area of the central beam and that the elevation angle of the beam’s center is
. The NTN channel is modeled with reference to [
27], and the inter-beam interference is modeled with reference to [
28], and they are not described in detail due to our being limited in space.
2.2. Problem Description
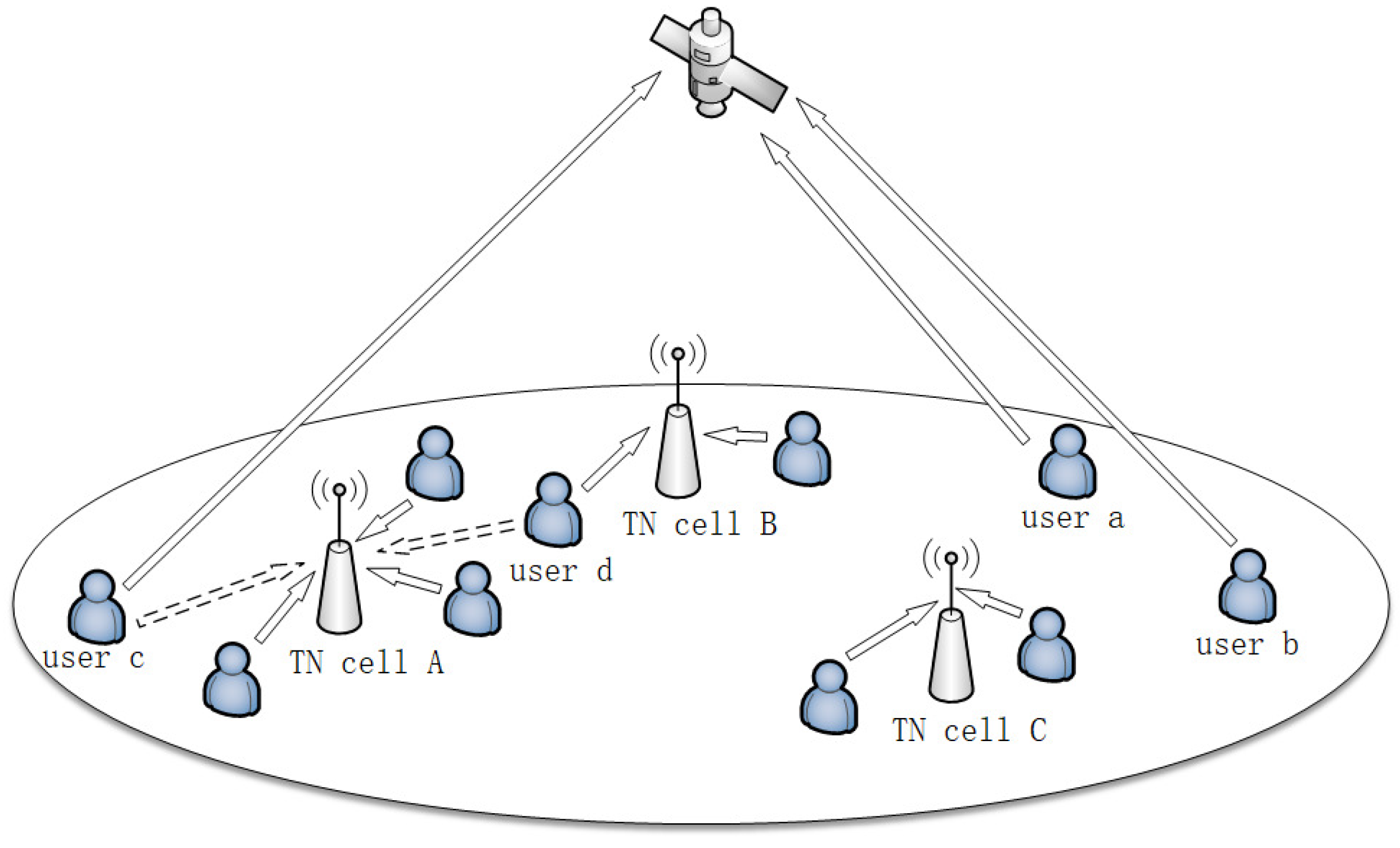
The process of load balancing in STIN with sparsely deployed TN cells is shown in
Figure 1. Some users are on the edge of the area, having poor signal reception and requiring more bandwidth. Some users cannot find a better cell to handover. These make TN cells likely to overload in this network. An example is shown in
Figure 1. The solid arrows point to cells that users are currently accessing. The dashed arrows point to cells that users previously accessed. User
a and user
b are users on the edge of the area that initially accesses the NTN cell. When the TN cell
A suffers overloading, user
c is selected to be offloaded to the NTN cell, and user
d is selected to be offloaded to the adjacent TN cell
B for relatively better QoS. Thus, the problem is split into two sub-problems: the access algorithm decides which cell users initially access, and the offloading algorithm decides which users are offloaded and how to offload them.
For the access algorithm, according to the link budget, in a scenario where cells are sparsely deployed, such as the rural scenario in 3GPP [
24], the average SNR is 9.21 dB. In the coverage range of the central beam of a GEO satellite, the average SNR is only 2.95 dB. If the received signal quality is used to determine initial access, only a few users will access the NTN cell. As a result, NTN resources are not effectively utilized and TN cells are more likely to overload. To limit access to the NTN to suitable users, we aim to consider not only received signal, but also the impact of users on cell overloading. Therefore, fuzzy logic is utilized to propose an overload evaluation metric. Then, to deal with dynamic changes in the environment and determine the appropriate number of users allowed to access the NTN, the FLRL-AC is proposed.
For the offloading algorithm, even if the initial access is optimized, overloading may still occur after a certain period of time due to users’ movements, especially when the user density in the environment is large. Additionally, if the FLRL-AC is utilized to make a global re-access decision at this time, the QoS of users in the cells which are not overload is affected. Therefore, the FL-OL is proposed for those overloaded cells. The FL-OL offloads the most suitable users to the most suitable cells by utilizing FEM.
2.3. The Fuzzy Evaluation Metric
Existing load balancing methods are usually performed reactively after the overloading occurs. Active load balancing adapts the network in advance to prevent overloading and improve performance. Therefore, this paper firstly proposes a metric to pre-evaluate the impact of users on overloading, which helps the networks to make further decisions. Considering the differences in carrier frequency and bandwidth between TN and NTN, and the difficulty of explicitly evaluating overload tendency, fuzzy control is utilized [
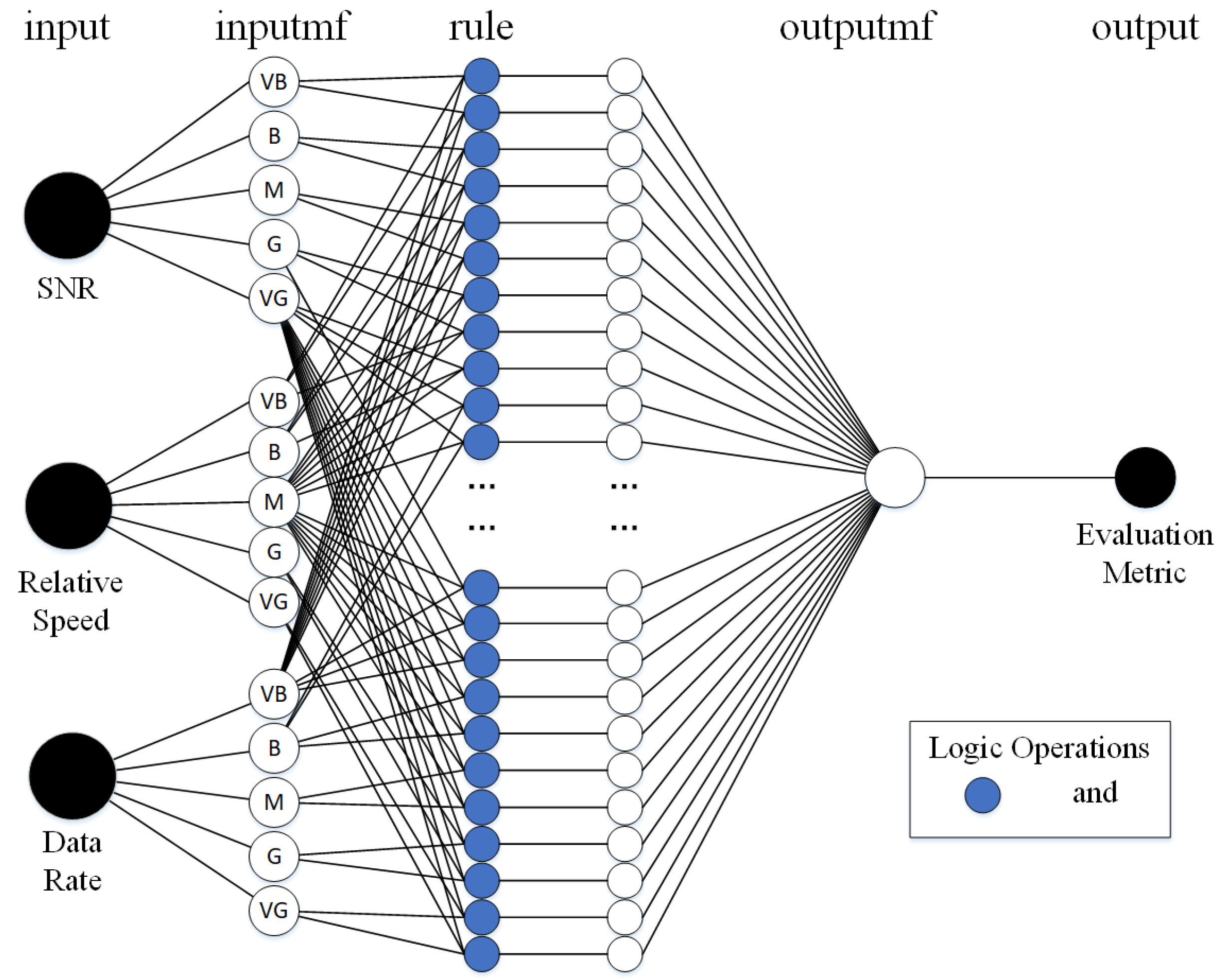
29] for the metric. It provides a unified measurement to evaluate the impact of users on overloading in STIN. An adaptive neuro fuzzy network (ANFN) is utilized to build the fuzzy system. The training network is shown in
Figure 2. In the following, the structure of each layer of the network is described.
In the input layer, SNR, relative speed and data rate are selected as the inputs by considering the Shannon formula : SNR and the target rate. Channel with low SNR needs more bandwidth to transmit data at the same target rate, which is more likely to cause overload. In addition, if the user is getting closer to the cell, SNR between them will get better, otherwise it will get worse. Additionally, if the SNR is the same, users with higher data rates will require more bandwidth. Measurements of SNR and data rate requirements are in the same way in both RAT. The movement of user could be expressed by the relative speed between user and cell. Since the satellite is far from the Earth, the moved distance of the user in a short period of time can be ignored relative to the satellite height. Thus, the speed relative to the satellite is considered to be 0 in this paper. It is difficult to directly judge whether SNR, relative speed and data rate are high or not. Therefore, we take them as the three inputs in the “input” layer.
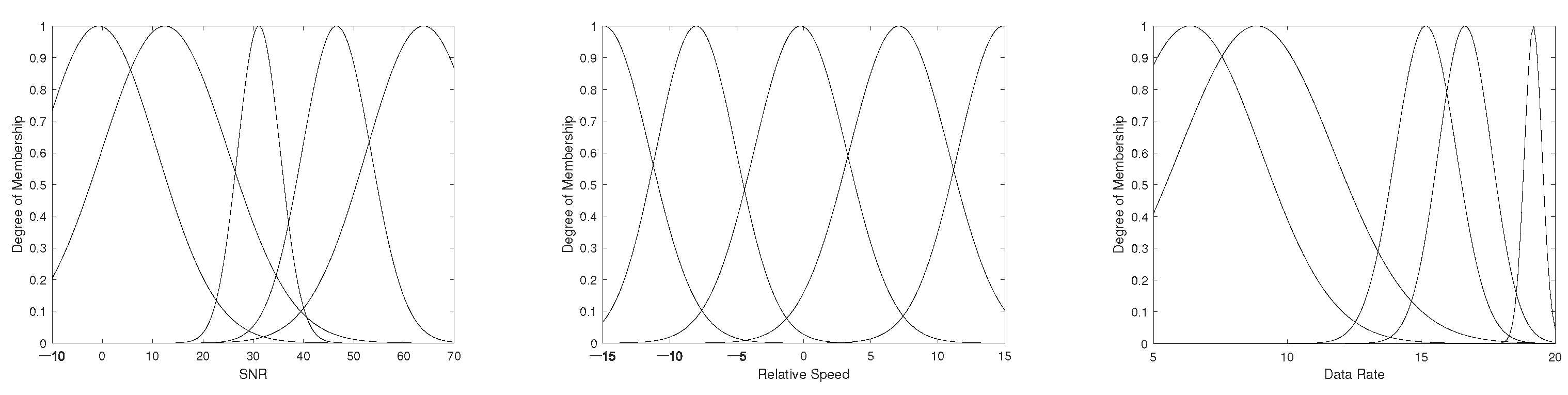
The “inputmf” layer uses membership functions to convert input values into fuzzy values. Commonly utilized membership functions are triangular, trapezoidal, Gaussian and bell-shaped. Since the relationship between inputs and output is not linear, the Gaussian membership function was selected.
where
c determines the center position of the function.
determines the width of the function. Both
c and
are trained by the ANFN. The fuzzy system has three inputs, and there are
P,
Q and
R fuzzy concepts for each input, respectively. The membership degrees of inputs to different fuzzy concepts could be calculated via the membership functions. In this paper, both
P,
Q and
R are set to 5, based on five fuzzy concepts: very bad (VB), bad (B), medium (M), good (G) and very good (VG). For each input, there are five membership functions subjecting to the same distribution with different parameters.
The “rule” layer pairs
P fuzzy concepts of the first input,
Q fuzzy concepts of the second input and
R fuzzy concepts of the third input to obtain
fuzzy rules. T-S fuzzy reasoning is utilized in the proposed fuzzy system. For the
lth rule, the first input
x is
, the second input
y is
and the third input
z is
. The mapping result
is calculated by
where
;
.
,
,
and
are parameters of the
lth rule trained by ANFN;
,
and
are the
ith,
jth and
kth fuzzy concepts of the three inputs;
,
and
are the membership degree values calculated by the corresponding membership functions.
The “outputmf” layer uses weighted average method to consider the influence of each fuzzy rule comprehensively. The output fuzzy evaluation metric
f is calculated by
where
,
.
is the weight of the
lth rule calculated by the product method.
In order to train the ANFN, multiple groups of user trajectories; SNR; relative speeds and data rate requirements at each time and location; and the average required bandwidth for a period of time, were generated via simulation. The ANFN was trained with these simulation data. The smaller the value is, the greater the impact is.
2.4. The Fuzzy-Logic- and Reinforcement-Learning-Based Access Algorithm
Traditionally, users access the cell with the best reference signal receiving power (RSRP) [
30]. According to the link budget, this may not work well in the STIN studied in this paper. In order to reduce the occurrence of overloading, to reduce the frequency of calling offloading algorithms and ensure QoS, the intelligence of reinforcement learning is introduced to make access decisions. In the following, the proposed FLRL-AC is described.
Reinforcement learning is a common method for intelligent decision. It obtains learning information and updates model parameters by calculating the rewards for actions in the current state of the environment. Reinforcement learning is divided into two categories: One is value learning, which uses a neural network to approximate the optimal action value function, such as Q-Learning or a deep Q-network. The other is policy learning, which uses a neural network to approximate the policy function, such as the actor–critic method. In this paper, reinforcement learning is used to select the initial access cell for each user so that the action dimensions are
. Due to exponential expansion and large dimensions of action space, a deep deterministic policy gradient (DDPG) [
31] which is compatible with a large dimension state and actions is utilized in the proposed algorithm. FEM is utilized in DDPG in order to further reduce the difficulty of training and enable the decision to have a better impact on the future state, which is called fuzzy deep deterministic policy gradient (FDDPG) in this paper. In the following, we will describe the Markov decision process of the problem and the FDDPG training process.
(1) State space: The sate space describes the environment. It reflects the relative positions, relative motions and channel states between cells and users. Thus, the state at time
t is defined as
where
means the FEM between user
m and cell
n at time
t.
(2) Action space: To make better access decisions, the index of cell is set as the action. In Equation (
9),
means the index of cell which user
m accesses at time
t.
(3) Reward function: The proposed access decision method aims at maximizing the total reward of the access selections for all users. The discounted total reward is
where
is the reward discount and
is the per-time reward. In this paper, the per-time reward is composed of three parts,
,
and
. For the first part,
the design goal is to reduce the overloading tendency in the future. Thus,
equals the average value of the FEM of all users. At meanwhile, for the second part,
we hope to keep load balanced at the current time by minimizing the number of overloaded cells.
equals the overload penalty for all cells, where
indicates whether cell
n is overloaded at time
t.
is the radio resource utilization ratio (RRUR) of cell
n at time
t, where
is the occupied portion of the bandwidth of cell
n and
is the total bandwidth resources of the cell. For terrestrial cells,
is equal to
. Additionally, for the satellite,
is equal to
.
is the overload threshold. For TN cells, the threshold is
. Additionally, for the NTN cell, the threshold is
. In order to minimize the resource utilization ratio and balance the resource utilization, the third part of the reward is defined as
where the weighted value of the sum and the variance of RRUR is included in
. Due to the large bandwidth, the NTN resources are enough to load many users. If there is no additional limit on accessing NTN, the agent will tend to let as many users as possible access the NTN to avoid overloading in TN cells. In order to prevent the transmission delay of users from being affected, we use the additional weight
to increase the impact of resource utilization of the NTN cell.
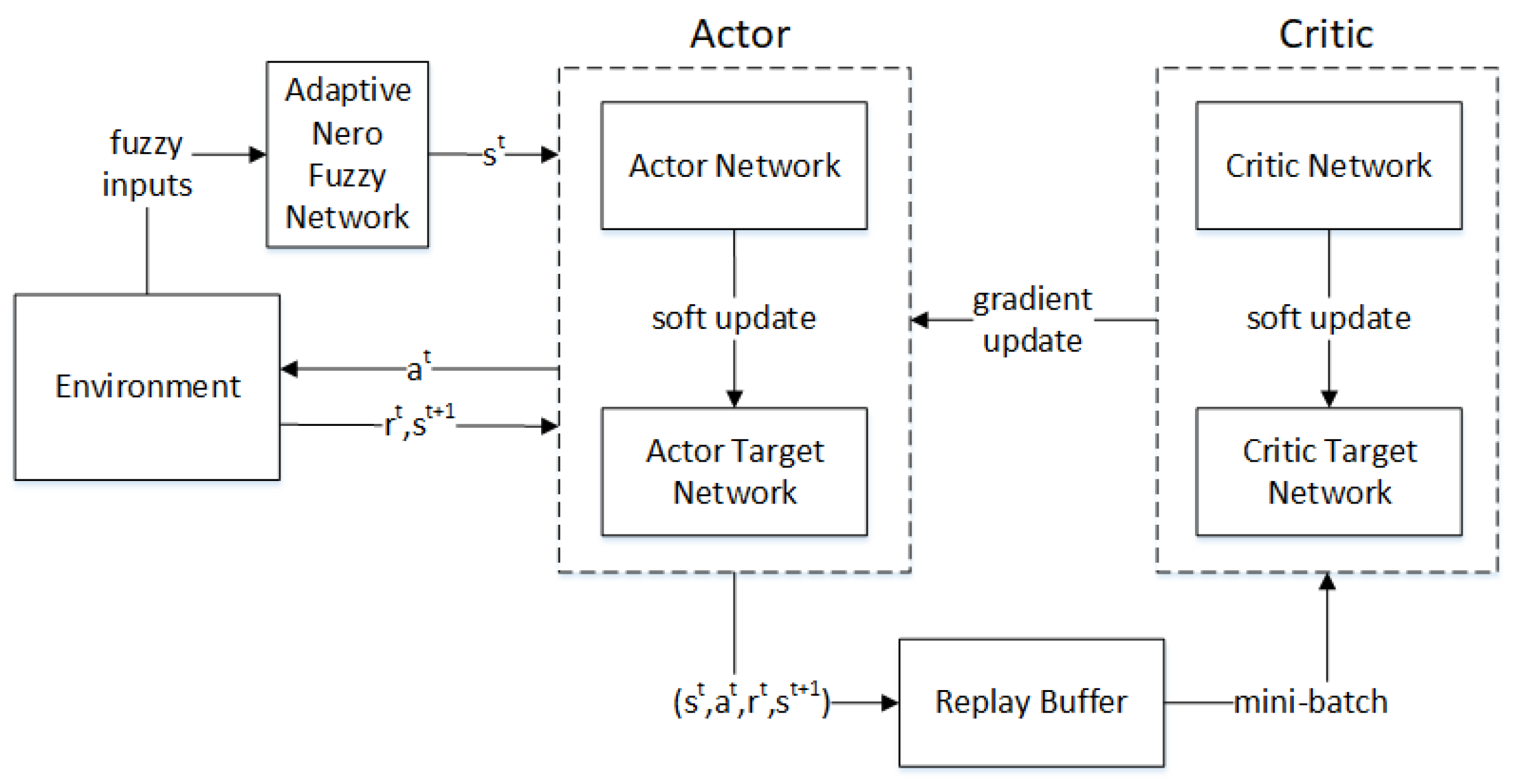
(4) The training process of the FDDPG algorithm: As in DDPG, FDDPG has two components, actor and critic. The actor network defined as
takes
as input and returns action
. The critic network defined as
returns long-term reward based on states and actions.
can be expressed as
according to the Bellman equation, where
means expectation and
means the reward discount.
DDPG combines actor–critic and DQN, so there are four networks in total. The actor network and actor target network have the same structure, but different parameters and and different update frequencies. The critic network and critic target network have the same structure, but different parameters and and different update frequencies. For the activation function, the linear rectification function (ReLU) is utilized in hidden layers and the hyperbolic tangent function is utilized in output layers.
Figure 3 shows the training structure of the proposed fuzzy reinforcement learning. In each episode during the training process, users’ positions and velocities are randomly reset to reset the environment. In each training step, the three fuzzy inputs are obtained from the environment and the state
is obtained based on Equation (
8). In order to speed up training,
is normalized to get
with the normalization coefficient
, where
.
To explore new states, the output of the actor network is added by random noise. The action
is obtained by
in which the noise is a Gaussian random number with mean value of 0 and variance of
. After performing
on the environment,
and the next state
can be obtained from the output of the environment. To break the association between data,
is stored in a replay buffer.
,
,
and
are updated by sampling a mini-batch with size
K from the replay buffer. The loss function of the critic network is defined as
which is the temporal difference error between the outputs of
and
. Thus, the gradient of critic network is calculated by
By applying the chain rule to the expected return from the start distribution
J with respect to the actor parameters [
31], the actor is updated by Equation (
20).
and
can be updated via gradient descent method.
The weights of target networks
and
are updated based on the weights of
and
, as in Equations (
21) and (
22). The detailed training process is shown in Algorithm 1.
| Algorithm 1. Fuzzy reinforcement learning training algorithm. |
- Require:
Training episodes , training steps for each episode , learning rate of actor network , learning rate of critic network , initial exploration rate , exploration discount , minimum exploration rate , replay buffer size G, mini-batch size K, reward discount , update rate .
- 1:
Randomly initialize the weights of actor network and critic network as and , the initial weight of actor target network is same as and the initial weight of critic target network is same as actor network - 2:
Initialize the empty replay buffer, initialize exploration rate as - 3:
for each episode in range do - 4:
Randomly set users’ positions and speeds and data requirements to reset environment - 5:
for each step t in range do - 6:
Get fuzzy inputs from the environment, get and from Equations ( 8) and ( 16) - 7:
Get from Equation ( 17) - 8:
Perform to the environment and get from Equations ( 11)–( 14) - 9:
Get and from Equations ( 8) and ( 16) - 10:
Store in replay buffer - 11:
if the replay buffer is full then - 12:
Replace a data randomly by - 13:
Update exploration rate, - 14:
Sample a mini-batch of size K from the replay buffer - 15:
Update by Equation ( 19) - 16:
Update by Equation ( 20) - 17:
Update target networks by Equations ( 21) and ( 22) - 18:
end if - 19:
end for - 20:
end for - 21:
Training completed, save the actor network
|
2.5. The Fuzzy-Logic-Based Offloading Algorithm
The algorithm above provides the access policy for all users to prevent cells from overloading. However, with the irregular movements of users, some cells could still overload after a long enough period of time. At this moment, to ensure the service quality both at the time of offloading and in the future, FL-OL is proposed to select appropriate users to be offloaded. In the following, the proposed FL-OL is described.
Consider a set of cells
. Whenever the resource utilization rate
of the TN cell
is higher than the threshold
, it is considered as an overloaded TN cell. Consider a set of users
which are served by cell
.
is the total number of users served by the cell
.
is the FEM between cell
and user
;
.
is the user with the minimum value of the evaluation metric
. Calculate the FEM
between cell
and user
. Due to the long distance between users and the GEO satellite, relative speed can be ignored for the NTN cell
. Thus,
is only influenced by user’s position and the randomness of the channel. If there is any
higher than
, select the cell
with the maximum value of the evaluation metric. If
, check whether
is higher than
after offloading
to
. If not,
is selected as the target cell. Otherwise, it means that user
is at the outer edge of the area and there is no more suitable TN cell for this user. Thus,
is offloaded to the NTN cell on the premise that
is not higher than
. The algorithm will continue to find new
with new
and offload until the current cell
is no longer overloaded. The whole process is summarized by Algorithm 2 as follows.
| Algorithm 2. The fuzzy logic offloading algorithm. |
Require: Resource utilization rate of cells in - 1:
whiledo - 2:
Get users severed by - 3:
for in do - 4:
Get by FEM and save in a set F - 5:
end for - 6:
Sort F in ascending order and get the first user with - 7:
for do - 8:
Calculate assuming is offloaded to - 9:
if and then - 10:
Save in a set - 11:
end if - 12:
end for - 13:
if is not empty then - 14:
Sort in descending order and get the first cell - 15:
Offload to - 16:
else if then - 17:
Offload to NTN cell - 18:
else - 19:
break; - 20:
end if - 21:
Update - 22:
end while
|















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}