


Implicitly Aligning Joint Distributions for Cross-Corpus Speech Emotion Recognition
 ,
,
Abstract
:1. Introduction
2. The Proposed Method
2.1. Notations
2.2. Formulation of JIASL
2.3. JIASL for Cross-Corpus SER
2.4. Optimization of JIASL
| Algorithm 1 Detailed procedures for solving the optimization problem in Equation (6). |
Repeat the following steps until convergence:
|
3. Experiments
3.1. Speech Emotion Database
3.2. Experimental Setup
3.3. Comparison Methods
- Baseline method:IS09 or IS10 feature sets with the classifier of SVM [5];
- Transfer subspace learning-based methods:Transfer component analysis (TCA) [36];Geodesic flow kernel (GFK) [37];Subspace alignment (SA) [38];Transfer kernel learning (TKL) [13];Domain-adaptive subspace learning method (DoSL) [15];Joint distribution adaptive regression (JDAR) [25].
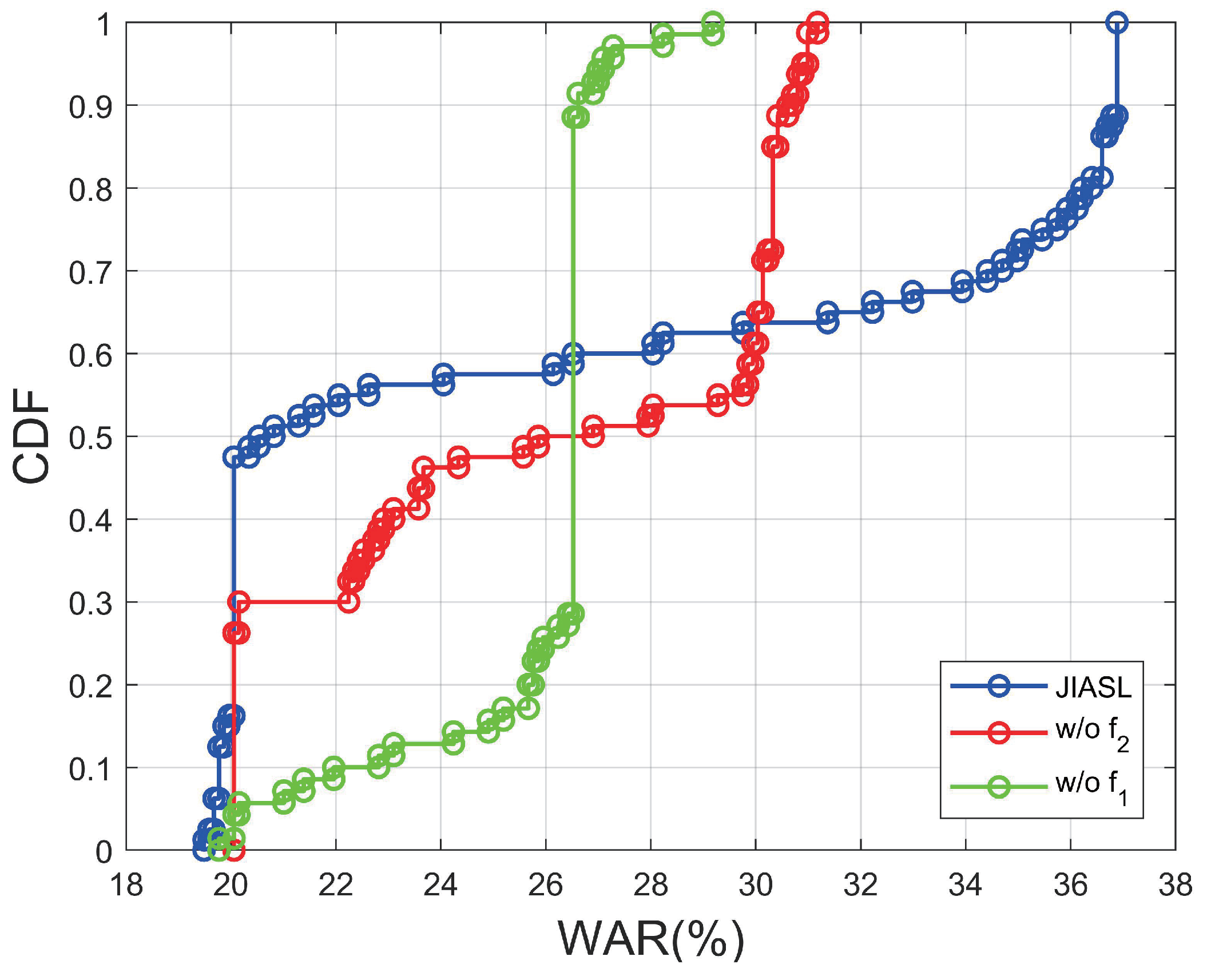
3.4. Results and Discussions
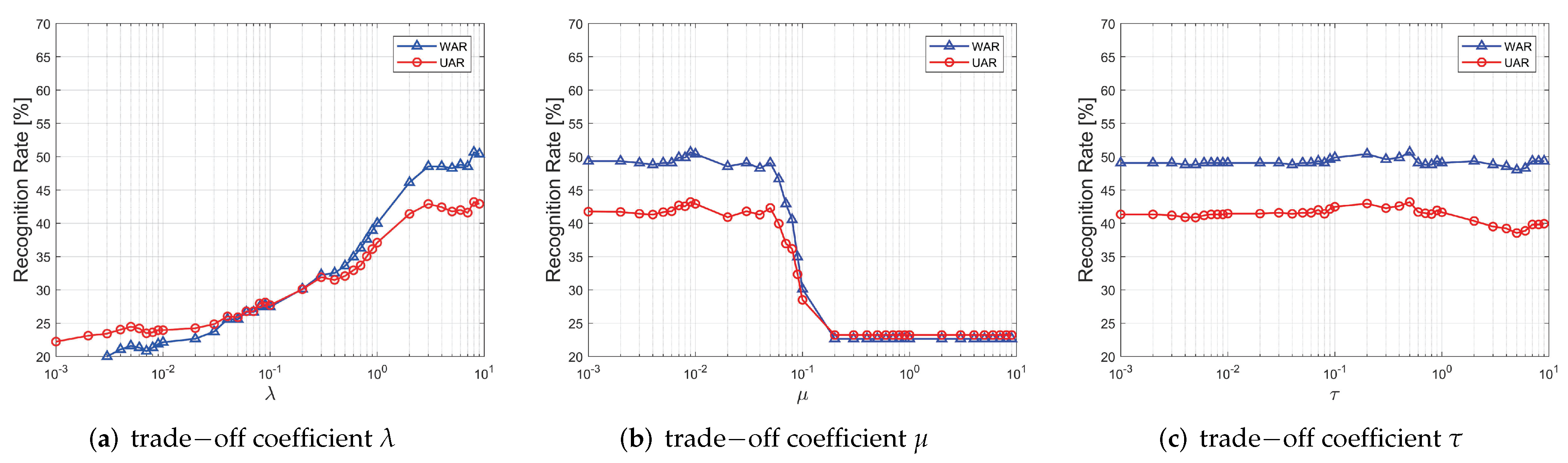
3.5. Parameter Sensitivity Analysis
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| The features of labeled speech samples in the source domain | |
| The feature vector of ith speech sample in the source domain | |
| The features of unlabeled speech samples in the target domain | |
| The feature vector of jth speech sample in the target domain | |
| The emotion labels of speech samples in the source domain | |
| The emotion label of the ith speech sample | |
| The kth entry of one-hot vector | |
| The projection matrix | |
| The reconstruction coefficient matrix | |
| The Frobenius norm | |
| The norm | |
| The norm | |
| The number of source speech samples | |
| The number of target speech samples | |
| d | The dimension of the speech feature vector |
| c | The number of emotions involved in cross-corpus SER tasks |
References
- Schuller, B.; Batliner, A. Computational Paralinguistics: Emotion, Affect and Personality in Speech and Language Processing; John Wiley & Sons: Hoboken, NJ, USA, 2013. [Google Scholar]
- Busso, C.; Bulut, M.; Narayanan, S.; Gratch, J.; Marsella, S. Toward effective automatic recognition systems of emotion in speech. In Social Emotions in Nature and Artifact: Emotions in Human and Human-Computer Interaction; Gratch, J., Marsella, S., Eds.; Oxford University Press: New York, NY, USA, 2013; pp. 110–127. [Google Scholar]
- Schuller, B.W. Speech emotion recognition: Two decades in a nutshell, benchmarks, and ongoing trends. Commun. ACM 2018, 61, 90–99. [Google Scholar] [CrossRef]
- Schuller, B.; Arsic, D.; Rigoll, G.; Wimmer, M.; Radig, B. Audiovisual behavior modeling by combined feature spaces. In Proceedings of the 2007 IEEE International Conference on Acoustics, Speech and Signal Processing-ICASSP’07, Honolulu, HI, USA, 15–20 April 2007; Volume 2, pp. 733–736. [Google Scholar]
- Schuller, B.; Vlasenko, B.; Eyben, F.; Rigoll, G.; Wendemuth, A. Acoustic emotion recognition: A benchmark comparison of performances. In Proceedings of the 2009 IEEE Workshop on Automatic Speech Recognition & Understanding, Moreno, Italy, 13 November–17 December 2009; pp. 552–557. [Google Scholar]
- Akçay, M.B.; Oğuz, K. Speech emotion recognition: Emotional models, databases, features, preprocessing methods, supporting modalities, and classifiers. Speech Commun. 2020, 116, 56–76. [Google Scholar] [CrossRef]
- Zhang, S.; Zhang, S.; Huang, T.; Gao, W. Speech emotion recognition using deep convolutional neural network and discriminant temporal pyramid matching. IEEE Trans. Multimed. 2017, 20, 1576–1590. [Google Scholar] [CrossRef]
- Lu, C.; Zong, Y.; Zheng, W.; Li, Y.; Tang, C.; Schuller, B.W. Domain Invariant Feature Learning for Speaker-Independent Speech Emotion Recognition. IEEE/ACM Trans. Audio Speech Lang. Process. 2022, 30, 2217–2230. [Google Scholar] [CrossRef]
- Song, P. Transfer Linear Subspace Learning for Cross-Corpus Speech Emotion Recognition. IEEE Trans. Affect. Comput. 2019, 10, 265–275. [Google Scholar] [CrossRef]
- Schuller, B.; Vlasenko, B.; Eyben, F.; Wöllmer, M.; Stuhlsatz, A.; Wendemuth, A.; Rigoll, G. Cross-corpus acoustic emotion recognition: Variances and strategies. IEEE Trans. Affect. Comput. 2010, 1, 119–131. [Google Scholar] [CrossRef]
- Pan, S.J.; Yang, Q. A survey on transfer learning. IEEE Trans. Knowl. Data Eng. 2009, 22, 1345–1359. [Google Scholar] [CrossRef]
- Zong, Y.; Zheng, W.; Zhang, T.; Huang, X. Cross-corpus speech emotion recognition based on domain-adaptive least-squares regression. IEEE Signal Process. Lett. 2016, 23, 585–589. [Google Scholar] [CrossRef]
- Long, M.; Wang, J.; Sun, J.; Philip, S.Y. Domain invariant transfer kernel learning. IEEE Trans. Knowl. Data Eng. 2014, 27, 1519–1532. [Google Scholar] [CrossRef]
- Long, M.; Cao, Y.; Cao, Z.; Wang, J.; Jordan, M.I. Transferable representation learning with deep adaptation networks. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 41, 3071–3085. [Google Scholar] [CrossRef]
- Liu, N.; Zong, Y.; Zhang, B.; Liu, L.; Chen, J.; Zhao, G.; Zhu, J. Unsupervised cross-corpus speech emotion recognition using domain-adaptive subspace learning. In Proceedings of the 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Calgary, AB, Canada, 15–20 April 2018; pp. 5144–5148. [Google Scholar]
- Gretton, A.; Borgwardt, K.M.; Rasch, M.J.; Schölkopf, B.; Smola, A. A kernel two-sample test. J. Mach. Learn. Res. 2012, 13, 723–773. [Google Scholar]
- Borgwardt, K.M.; Gretton, A.; Rasch, M.J.; Kriegel, H.P.; Schölkopf, B.; Smola, A.J. Integrating structured biological data by kernel maximum mean discrepancy. Bioinformatics 2006, 22, e49–e57. [Google Scholar] [CrossRef]
- Mao, Q.; Xue, W.; Rao, Q.; Zhang, F.; Zhan, Y. Domain adaptation for speech emotion recognition by sharing priors between related source and target classes. In Proceedings of the 2016 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Shanghai, China, 20–25 March 2016; pp. 2608–2612. [Google Scholar]
- Deng, J.; Xu, X.; Zhang, Z.; Frühholz, S.; Schuller, B. Universum autoencoder-based domain adaptation for speech emotion recognition. IEEE Signal Process Lett. 2017, 24, 500–504. [Google Scholar] [CrossRef]
- Abdelwahab, M.; Busso, C. Domain adversarial for acoustic emotion recognition. IEEE/ACM Trans. Audio Speech Lang. Process. 2018, 26, 2423–2435. [Google Scholar] [CrossRef]
- Gideon, J.; McInnis, M.G.; Provost, E.M. Improving cross-corpus speech emotion recognition with adversarial discriminative domain generalization (ADDoG). IEEE Trans. Affect. Comput. 2019, 12, 1055–1068. [Google Scholar] [CrossRef] [PubMed]
- Parry, J.; Palaz, D.; Clarke, G.; Lecomte, P.; Mead, R.; Berger, M.; Hofer, G. Analysis of Deep Learning Architectures for Cross-Corpus Speech Emotion Recognition. In Proceedings of the Interspeech, Graz, Austria, 15–19 September 2019; pp. 1656–1660. [Google Scholar]
- Long, M.; Wang, J.; Ding, G.; Sun, J.; Yu, P.S. Transfer feature learning with joint distribution adaptation. In Proceedings of the IEEE International Conference on Computer Vision, Sydney, NSW, Australia, 1–8 December 2013; pp. 2200–2207. [Google Scholar]
- Zhu, Y.; Zhuang, F.; Wang, J.; Ke, G.; Chen, J.; Bian, J.; Xiong, H.; He, Q. Deep subdomain adaptation network for image classification. IEEE Trans. Neural Netw. Learn. Syst. 2020, 32, 1713–1722. [Google Scholar] [CrossRef]
- Zhang, J.; Jiang, L.; Zong, Y.; Zheng, W.; Zhao, L. Cross-Corpus Speech Emotion Recognition Using Joint Distribution Adaptive Regression. In Proceedings of the ICASSP 2021–2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Toronto, ON, Canada, 6–11 June 2021; pp. 3790–3794. [Google Scholar]
- Burkhardt, F.; Paeschke, A.; Rolfes, M.; Sendlmeier, W.F.; Weiss, B. A database of German emotional speech. In Proceedings of the Interspeech, Lisboa, Portugal, 4–8 September 2005; Volume 5, pp. 1517–1520. [Google Scholar]
- Martin, O.; Kotsia, I.; Macq, B.; Pitas, I. The eNTERFACE’05 audio-visual emotion database. In Proceedings of the 22nd International Conference on Data Engineering Workshops (ICDEW’06), Atlanta, GA, USA, 3–7 April 2006; p. 8. [Google Scholar]
- Tao, J.; Liu, F.; Zhang, M.; Jia, H. Design of speech corpus for mandarin text to speech. In Proceedings of the the Blizzard Challenge 2008 Workshop, Brisbane, Australia, 1 February 2008; pp. 1–4. [Google Scholar]
- Kan, M.; Wu, J.; Shan, S.; Chen, X. Domain adaptation for face recognition: Targetize source domain bridged by common subspace. Int. J. Comput. Vis. 2014, 109, 94–109. [Google Scholar] [CrossRef]
- Lin, Z.; Liu, R.; Su, Z. Linearized alternating direction method with adaptive penalty for low-rank representation. Adv. Neural Inf. Process. Syst. 2011, 24, 612–620. [Google Scholar]
- Zheng, W.; Xin, M.; Wang, X.; Wang, B. A novel speech emotion recognition method via incomplete sparse least square regression. IEEE Signal Process. Lett. 2014, 21, 569–572. [Google Scholar] [CrossRef]
- Liu, J.; Ji, S.; Ye, J. SLEP: Sparse learning with efficient projections. Ariz. State Univ. 2009, 6, 7. [Google Scholar]
- Schuller, B.; Steidl, S.; Batliner, A. The interspeech 2009 emotion challenge. In Proceedings of the Interspeech 2009, 10th Annual Conference of the International Speech Communication Association, Brighton, UK, 6–10 September 2009; pp. 312–315. [Google Scholar]
- Schuller, B.; Steidl, S.; Batliner, A.; Burkhardt, F.; Devillers, L.; Müller, C.; Narayanan, S. The INTERSPEECH 2010 paralinguistic challenge. In Proceedings of the INTERSPEECH 2010, Makuhari, Japan, 26–30 September 2010; pp. 2794–2797. [Google Scholar]
- Eyben, F.; Wöllmer, M.; Schuller, B. Opensmile: The munich versatile and fast open-source audio feature extractor. In Proceedings of the 18th ACM International Conference on Multimedia, Firenze, Italy, 25–29 October 2010; pp. 1459–1462. [Google Scholar]
- Pan, S.J.; Tsang, I.W.; Kwok, J.T.; Yang, Q. Domain adaptation via transfer component analysis. IEEE Trans. Neural Netw. 2010, 22, 199–210. [Google Scholar] [CrossRef] [PubMed]
- Gong, B.; Shi, Y.; Sha, F.; Grauman, K. Geodesic flow kernel for unsupervised domain adaptation. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 2066–2073. [Google Scholar]
- Fernando, B.; Habrard, A.; Sebban, M.; Tuytelaars, T. Unsupervised visual domain adaptation using subspace alignment. In Proceedings of the IEEE International Conference on Computer Vision, Sydney, NSW, Australia, 1–8 December 2013; pp. 2960–2967. [Google Scholar]
- Liu, S.; Sinha, R.S.; Hwang, S.H. Clustering-based noise elimination scheme for data pre-processing for deep learning classifier in fingerprint indoor positioning system. Sensors 2021, 21, 4349. [Google Scholar] [CrossRef] [PubMed]



{kind=link}
{kind=link}
| Tasks | Speech Corpus (# Samples from Each Emotion) | # Total |
|---|---|---|
| B→E E→B | E (AN: 211, SA: 211, FE: 211, HA: 208, DI: 211) | 1052 |
| B (AN: 127, SA: 62, FE: 69, HA: 71, DI: 46) | 375 | |
| B→C C→B | C (AN: 200, SA: 200, FE: 200, HA: 200, NE: 200) | 1000 |
| B (AN: 127, SA: 62, FE: 69, HA: 71, NE: 79) | 408 | |
| C→E E→C | E (AN: 211, SA: 211, FE: 211, HA: 208, SU: 211) | 1052 |
| C (AN: 200, SA: 200, FE: 200, HA: 200, SU: 200) | 1000 |
| Feature | Method | B → E | E → B | B → C | C → B | C → E | E → C | Average |
|---|---|---|---|---|---|---|---|---|
| IS09 Feature Set | SVM | 28.90 | 18.93 | 29.60 | 34.07 | 25.10 | 26.10 | 27.12 |
| TCA | 30.51 | 45.07 | 33.40 | 42.65 | 32.32 | 31.10 | 35.84 | |
| GFK | 32.13 | 44.53 | 33.10 | 46.57 | 28.14 | 32.80 | 36.21 | |
| SA | 36.06 | 38.93 | 34.40 | 42.16 | 31.65 | 30.40 | 35.60 | |
| DoSL | 33.56 | 40.53 | 35.80 | 45.10 | 28.04 | 32.60 | 35.94 | |
| JDAR | 36.41 | 40.27 | 31.10 | 43.63 | 31.56 | 32.40 | 35.90 | |
| JIASL (Ours) | 36.88 | 50.40 | 36.50 | 53.68 | 33.17 | 30.50 | 40.19 | |
| IS10 Feature Set | SVM | 34.54 | 24.53 | 35.30 | 35.29 | 26.79 | 24.30 | 30.13 |
| TCA | 32.64 | 46.78 | 40.50 | 54.56 | 29.75 | 33.20 | 39.57 | |
| GFK | 36.03 | 38.67 | 40.00 | 47.55 | 29.09 | 33.00 | 37.39 | |
| SA | 36.88 | 41.87 | 36.80 | 49.75 | 33.94 | 35.60 | 39.14 | |
| DoSL | 35.63 | 45.00 | 37.50 | 48.31 | 30.52 | 32.10 | 38.18 | |
| JDAR | 38.02 | 48.80 | 42.70 | 52.21 | 37.64 | 35.60 | 42.50 | |
| JIASL (Ours) | 38.12 | 49.60 | 38.10 | 54.66 | 37.83 | 36.00 | 42.39 |
| Feature | Method | B → E | E → B | B → C | C → B | C → E | E → C | Average |
|---|---|---|---|---|---|---|---|---|
| IS09 Feature Set | SVM | 28.93 | 23.58 | 29.60 | 35.01 | 25.14 | 26.10 | 28.06 |
| TCA | 30.52 | 44.03 | 33.40 | 45.07 | 32.32 | 31.10 | 36.07 | |
| GFK | 32.11 | 42.48 | 33.10 | 48.08 | 28.13 | 32.80 | 36.17 | |
| SA | 36.12 | 38.95 | 34.40 | 45.75 | 31.59 | 30.40 | 36.20 | |
| DoSL | 33.50 | 43.89 | 35.80 | 49.03 | 28.17 | 32.60 | 36.33 | |
| JDAR | 36.33 | 39.97 | 31.10 | 46.29 | 31.50 | 32.40 | 36.27 | |
| JIASL (Ours) | 36.87 | 44.11 | 36.50 | 49.30 | 33.19 | 30.50 | 38.42 | |
| IS10 Feature Set | SVM | 34.50 | 28.13 | 35.30 | 35.29 | 26.81 | 24.30 | 30.73 |
| TCA | 32.60 | 44.53 | 40.50 | 51.47 | 29.77 | 33.20 | 38.68 | |
| GFK | 36.01 | 40.11 | 40.00 | 45.93 | 29.09 | 33.00 | 37.35 | |
| SA | 36.82 | 43.33 | 36.80 | 48.45 | 33.91 | 35.60 | 39.15 | |
| DoSL | 35.65 | 43.92 | 37.50 | 47.06 | 30.61 | 32.10 | 37.80 | |
| JDAR | 37.95 | 47.80 | 42.70 | 48.97 | 37.58 | 35.60 | 41.77 | |
| JIASL (Ours) | 38.05 | 48.35 | 38.10 | 53.64 | 37.76 | 36.00 | 41.98 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lu, C.; Zong, Y.; Tang, C.; Lian, H.; Chang, H.; Zhu, J.; Li, S.; Zhao, Y. Implicitly Aligning Joint Distributions for Cross-Corpus Speech Emotion Recognition. Electronics 2022, 11, 2745. https://doi.org/10.3390/electronics11172745
Lu C, Zong Y, Tang C, Lian H, Chang H, Zhu J, Li S, Zhao Y. Implicitly Aligning Joint Distributions for Cross-Corpus Speech Emotion Recognition. Electronics. 2022; 11(17):2745. https://doi.org/10.3390/electronics11172745
Chicago/Turabian StyleLu, Cheng, Yuan Zong, Chuangao Tang, Hailun Lian, Hongli Chang, Jie Zhu, Sunan Li, and Yan Zhao. 2022. "Implicitly Aligning Joint Distributions for Cross-Corpus Speech Emotion Recognition" Electronics 11, no. 17: 2745. https://doi.org/10.3390/electronics11172745