
Abnormal Cockpit Pilot Driving Behavior Detection Using YOLOv4 Fused Attention Mechanism


Abstract
:1. Introduction
2. Overview of the Method
2.1. Convolutional Neural Networks
2.2. YOLO
- (1)
- The features of each grid need B bounding boxes (Bbox) to return. To ensure accuracy, the B box features corresponding to each grid are also the same.
- (2)
- Each Bbox also predicts 5 values: x, y, w, h, and the confidence. The (x, y) is the relative position of the center of the Bbox in the corresponding grid, and (w, h) is the length and width of the Bbox relative to the full image. The range of these 4 values is [0, 1], and these 4 values can be calculated from the features. The confidence is a numerical measure of how accurate a prediction is. Let us set the reliability as C, where I refers to the intersection ratio between the predicted Bbox and the ground-truth box in the image; the probability of containing objects in the corresponding grid of the Bbox is P, and the formula is:
- (3)
- If the grid corresponding to the Bbox contains objects, then P = 1, otherwise it is equal to 0. If there are N prediction categories, plus the confidence of the previous Bbox prediction, the S × S grid requires o output information. The calculation method is as follows:
2.3. YOLOv4
2.3.1. CSPDarkent–53
2.3.2. Prediction Box Selection
3. The Improved Network Model
3.1. Channel Attention Mechanism
3.2. Spatial Attention Mechanism
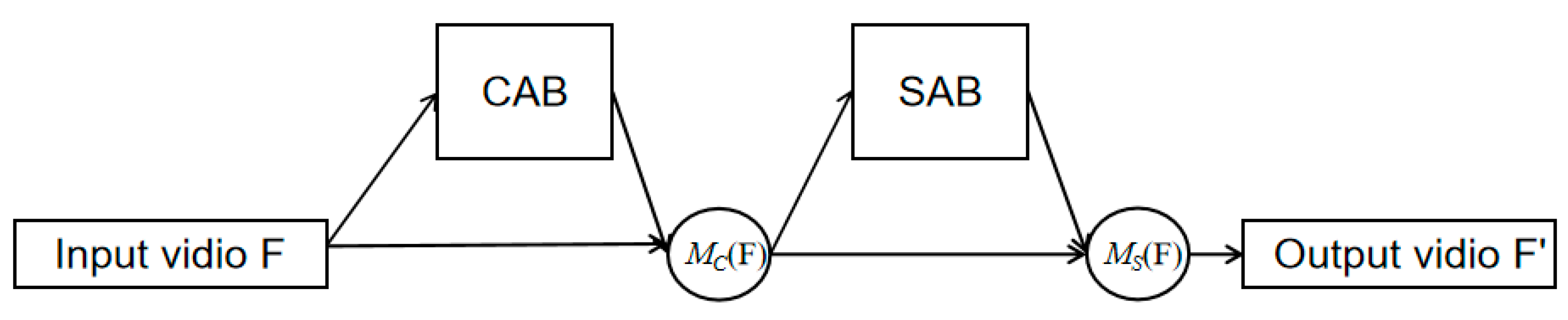
3.3. Attention Mechanism Fusion
4. Test and Analysis
4.1. Environment Settings
4.2. Detection Process
- (1)
- Taking with a camera in the cockpit of an aircraft simulator, capture images in frame units from the live video stream captured by the camera;
- (2)
- Perform abnormal behavior detection on the pilots. Use the model trained by the deep learning YOLO v4 algorithm to locate the pilot area, and when the area is detected, the abnormal behavior can be identified according to the model;
- (3)
- Monitor the video. When there is abnormal behavior, it will give a warning. After the frame detection ends, enter the next frame.
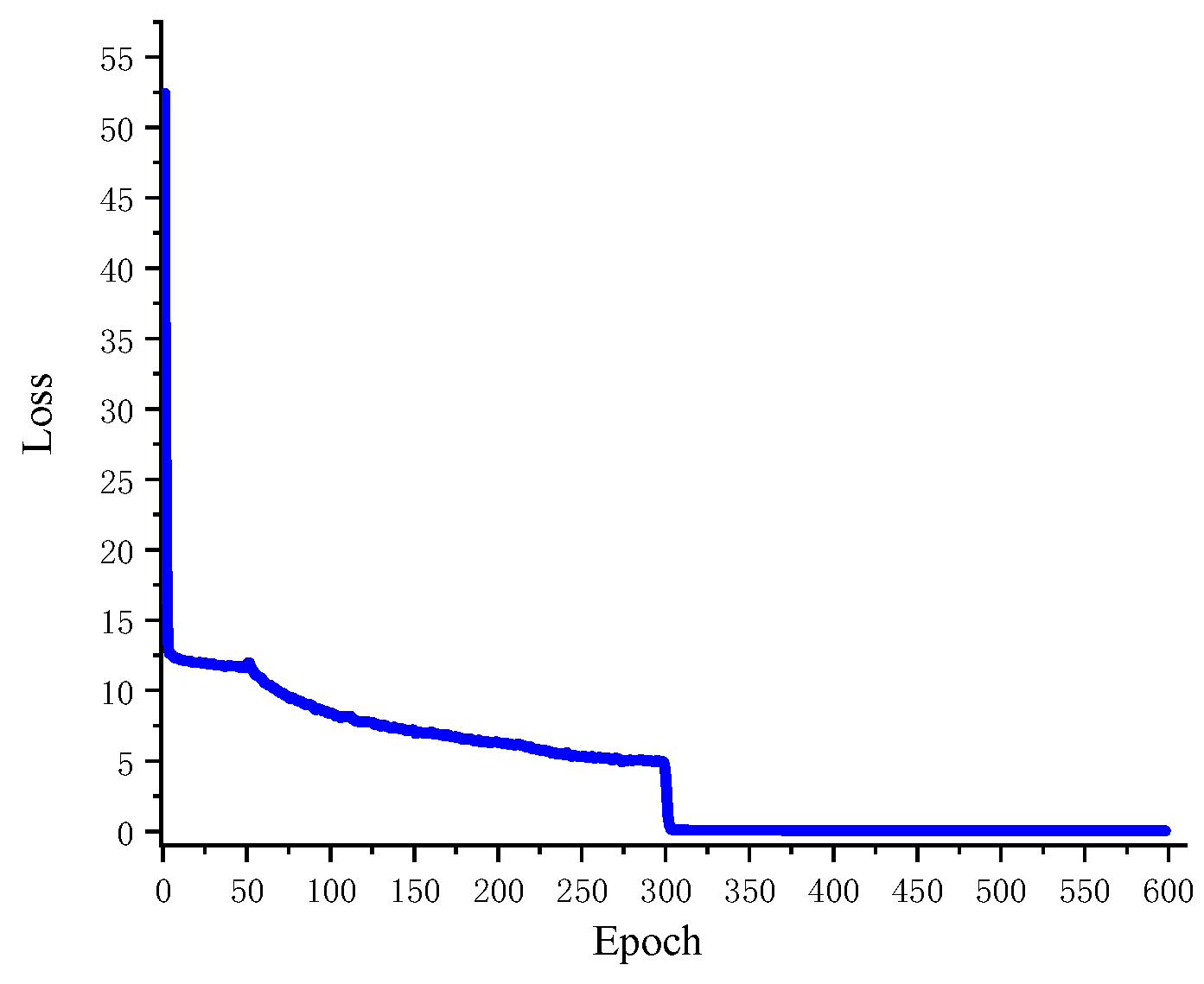
4.3. Model Training
4.4. Evaluation of the Model Performance
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Annual Report on Aviation Safety in China, 2018; Civil Aviation Administration of China: Beijing, China, 2019.
- Xiao, W.; Liu, H.; Ma, Z.; Chen, W. Attention-based deep neural network for driver behavior recognition. Future Gener. Comput. Syst. 2022, 132, 152–161. [Google Scholar] [CrossRef]
- Zhang, S.; Benenson, R.; Omran, M.; Hosang, J.; Schiele, B. How far are we from solving pedestrian detection? In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; Volume 12, pp. 1259–1267. [Google Scholar]
- Senicic, M.; Matijevic, M.; Nikitovic, M. Teaching the methods of object detection by robot vision. In Proceedings of the IEEE International Convention on Information and Communication Technology, Kansas City, MO, USA, 20–24 May 2018; Volume 7, pp. 558–563. [Google Scholar]
- Nemcová, A.; Svozilová, V.; Bucsuházy, K.; Smíšek, R.; Mezl, M.; Hesko, B.; Belák, M.; Bilík, M.; Maxera, P.; Seitl, M.; et al. Multimodal features for detection of driver stress and fatigue. IEEE Trans. Intell. Transp. Syst. 2021, 22, 3214–3233. [Google Scholar] [CrossRef]
- Popescu, D.; Stoican, F.; Stamatescu, G.; Ichim, L.; Dragana, C. Advanced UAV-WSN system for intelligent monitoring in precision agriculture. Sensors 2020, 20, 817. [Google Scholar] [CrossRef] [PubMed]
- Mneymneh, B.E.; Abbas, M.; Khoury, H. Vision-based framework for intelligent monitoring of hardhat wearing on construction sites. J. Comput. Civ. Eng. 2019, 33, 04018066. [Google Scholar] [CrossRef]
- Wang, T.; Fu, S.; Huang, D.; Cao, J. Pilot action identification in the cockpit. Electron. Opt. Control. 2017, 24, 90–94. [Google Scholar]
- Liu, Y.; Zhang, S.; Li, Z.; Zhang, Y. Abnormal Behavior Recognition Based on Key Points of Human Skeleton. IFAC-PapersOnLine 2020, 53, 441–445. [Google Scholar] [CrossRef]
- Zhou, K.; Hui, B.; Wang, J.; Wang, C.; Wu, T. A study on attention-based LSTM for abnormal behavior recognition with variable pooling. Image Vis. Comput. 2021, 108, 104–120. [Google Scholar] [CrossRef]
- Ji, H.; Zeng, X.; Li, H.; Ding, W.; Nie, X.; Zhang, Y.; Xiao, Z. Human abnormal behavior detection method based on T-TINY-YOLO. In Proceedings of the 5th International Conference on Multimedia and Image Processing, Nanjing, China, 10–12 January 2020; pp. 1–5. [Google Scholar]
- Li, L.; Cheng, J. Research on the relationship between work stress and unsafe behaviors of civil aviation pilots. Ind. Saf. Environ. Prot. 2019, 45, 46–49. [Google Scholar]
- Yang, K.; Wang, H. Pilots use head-up display behavior pattern recognition. Sci. Technol. Eng. 2018, 18, 226–231. [Google Scholar]
- Ullah, W.; Ullah, A.; Hussain, T.; Muhammad, K.; Heidari, A.A.; Del Ser, J.; Baik, S.W.; De Albuquerque, V.H.C. Artificial Intelligence of Things-assisted two-stream neural network for anomaly detection in surveillance Big Video Data. Future Gener. Comput. Syst. 2022, 129, 286–297. [Google Scholar] [CrossRef]
- Li, Q.; Yang, R.; Xiao, F.; Bhanu, B.; Zhang, F. Attention-based anomaly detection in multi-view surveillance videos. Knowl.-Based Syst. 2022, 252, 109348. [Google Scholar] [CrossRef]
- Maqsood, R.; Bajwa, U.; Saleem, G.; Raza, R.H.; Anwar, M.W. Anomaly recognition from surveillance videos using 3D convolution neural network. Multimed. Tools Appl. 2021, 80, 18693–18716. [Google Scholar] [CrossRef]
- Ullah, W.; Ullah, A.; Hussain, T.; Khan, Z.A.; Baik, S.W. An efficient anomaly recognition framework using an attention residual LSTM in surveillance videos. Sensors 2021, 21, 2811. [Google Scholar] [CrossRef]
- Ullah, A.; Muhammad, K.; Haydarov, K.; Haq, I.U.; Lee, M.; Baik, S.W. One-shot learning for surveillance anomaly recognition using siamese 3d. In Proceedings of the International Joint Conference on Neural Networks, Glasgow, UK, 19–24 July 2020; pp. 1–8. [Google Scholar]
- An, Z.; Wang, X.; Li, B.; Xiang, Z.; Zhang, B. Robust visual tracking for UAVs with dynamic feature weight selection. Appl. Intell. 2022, 1–14. [Google Scholar] [CrossRef]
- Wu, D.; Wu, C. Research on the Time-Dependent Split Delivery Green Vehicle Routing Problem for Fresh Agricultural Products with Multiple Time Windows. Agriculture 2022, 12, 793. [Google Scholar] [CrossRef]
- Chen, H.; Miao, F.; Chen, Y.; Xiong, Y.; Chen, T. A hyperspectral image classification method using multifeatured vectors and optimized KELM. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 2781–2795. [Google Scholar] [CrossRef]
- Zhou, X.; Ma, H.; Gu, J.; Chen, H.; Deng, W. Parameter adaptation-based ant colony optimization with dynamic hybrid mechanism. Eng. Appl. Artif. Intell. 2022, 114, 105139. [Google Scholar] [CrossRef]
- Yao, R.; Guo, C.; Deng, W.; Zhao, H. A novel mathematical morphology spectrum entropy based on scale-adaptive techniques. ISA Trans. 2022, 126, 691–702. [Google Scholar] [CrossRef]
- Sherstinsky, A. Fundamentals of recurrent neural network (RNN) and long short-term memory (LSTM) network. Phys. D Nonlinear Phenom. 2020, 404, 132306. [Google Scholar] [CrossRef]
- Kattenborn, T.; Leitloff, J.; Schiefer, F.; Hinz, S. Review on Convolutional Neural Networks (CNN) in vegetation remote sensing. ISPRS J. Photogramm. Remote Sens. 2021, 173, 24–49. [Google Scholar] [CrossRef]
- Girshick, R. Fast R–CNN. Computer Science. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. Adv. Neural Inf. Processing Syst. 2015, 28, 1137–1149. [Google Scholar] [CrossRef] [PubMed]
- Deng, W.; Ni, H.; Liu, Y.; Chen, H.; Zhao, H. An adaptive differential evolution algorithm based on belief space and generalized opposition-based learning for resource allocation. Appl. Soft Comput. 2022, 127, 109419. [Google Scholar] [CrossRef]
- Huang, Z.; Huang, L.; Gong, Y.; Huang, C.; Wang, X. Mask scoring r-cnn. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 6409–6418. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1904–1916. [Google Scholar] [CrossRef]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. SSD: Single shot multibox detector. In Lecture Notes in Computer Science; Springer: Cham, Swizerland, 2016; Volume 9905, pp. 21–37. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Chen, B.; Wang, X.; Bao, Q.; Jia, B.; Li, X.; Wang, Y. An Unsafe Behavior Detection Method Based on Improved YOLO Framework. Electronics 2022, 11, 1912. [Google Scholar] [CrossRef]
- Kumar, T.; Rajmohan, R.; Pavithra, M.; Ajagbe, S.A.; Hodhod, R.; Gaber, T. Automatic face mask detection system in public transportation in smart cities using IoT and deep learning. Electronics 2022, 11, 904. [Google Scholar] [CrossRef]
- Wahyutama, A.; Hwang, M. YOLO-Based Object Detection for Separate Collection of Recyclables and Capacity Monitoring of Trash Bins. Electronics 2022, 11, 1323. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Operating System | Windows 10 |
|---|---|
| CPU | i7-10750H |
| RAM | 16G |
| GPU | RTX 2060Ti |
| Language | Python 3.6 |
| Backbone Network | CSPDarkent–53 |
| Type | Calling | Smoking |
|---|---|---|
| Number | 500 | 500 |
| YOLOv4/% | Improved YOLOv4/% | |
|---|---|---|
| Smoking | 71 | 82 |
| Calling | 50 | 82 |
| Abnormal Behavior | P/% | R/% | mAP/% |
|---|---|---|---|
| Smoking | 85.54 | 85.54 | 89.23 |
| Calling | 75.76 | 87.36 | 87.35 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, N.; Man, Y.; Sun, Y. Abnormal Cockpit Pilot Driving Behavior Detection Using YOLOv4 Fused Attention Mechanism. Electronics 2022, 11, 2538. https://doi.org/10.3390/electronics11162538
Chen N, Man Y, Sun Y. Abnormal Cockpit Pilot Driving Behavior Detection Using YOLOv4 Fused Attention Mechanism. Electronics. 2022; 11(16):2538. https://doi.org/10.3390/electronics11162538
Chicago/Turabian StyleChen, Nongtian, Yongzheng Man, and Youchao Sun. 2022. "Abnormal Cockpit Pilot Driving Behavior Detection Using YOLOv4 Fused Attention Mechanism" Electronics 11, no. 16: 2538. https://doi.org/10.3390/electronics11162538