
Leveraging Deep Features Enhance and Semantic-Preserving Hashing for Image Retrieval


Abstract
:1. Introduction
2. Related Work
3. Proposed Method
3.1. Deep Network Framework
3.1.1. Feature Enhancement Layer
3.1.2. Feature Extractor
3.1.3. Hash Layer
3.1.4. Loss Layer
3.2. Objective Function
3.2.1. Contrastive Loss
3.2.2. Quantization Loss
3.2.3. Balanced Loss
3.2.4. Total Loss
3.3. Optimization
3.4. Image Retrieval
4. Experiments
4.1. Datasets Used in the Experiment
- (1)
- CIFAR-10 [47]. The dataset has 60,000 color images divided into 10 classes in total, each with 6000 pictures. There are 50,000 training batches and 10,000 pictures in each batch. The other 10,000 images are used for testing and form a separate batch.
- (2)
- NUS-WIDE [48]. The dataset is a multilabel dataset containing 269,648 pictures acquired from Flickr. Each picture receives one or more of the 81 category tags. Our experiments selected the most common 21 categories, including 195,834 images, with 5000 images in each category as the training set, and other pictures as the test dataset.
- (3)
- SVHN [49]. The SVHN dataset contains 73,257 32 × 32 digital images, each containing a set of “0–9” Arabic numerals. However, the number of samples per class is very different. To solve this problem, we used class-aware sampling during the training phase and randomly selected 20 images from each class in each iteration.
4.2. Evaluation Index
4.3. Experimental Results
4.4. Ablation Study
4.4.1. Ablation Study On Regularization
4.4.2. Ablation Study on Loss Function
4.4.3. Ablation Study on Deep Network
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| CNN | Convolutional Neural Network |
References
- Shakhnarovich, G.; Darrell, T.; Indyk, P. Nearest-Neighbor Methods in Learning and Vision. IEEE Trans. Neural Netw. 2008, 19, 377. [Google Scholar]
- Dubey, A.; Maaten, L.; Yalniz, Z.; Li, Y.; Mahajan, D. Defense Against Adversarial Images Using Web-Scale Nearest-Neighbor Search. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2020. [Google Scholar]
- Smeulders, A.W.M.; Worring, M. Content-based image retrieval at the end of the early years. IEEE Trans. Pattern Anal. Mach. Intell. 2000, 22, 1349–1380. [Google Scholar] [CrossRef]
- Liu, W.; Wang, J.; Kumar, S.; Chang, S.F. Hashing with Graphs. In Proceedings of the 28th International Conference on Machine Learning, ICML 2011, Bellevue, WA, USA, 28 June–2 July 2011. [Google Scholar]
- Datar, M. Locality-sensitive hashing scheme based on p-stable distributions. In Proceedings of the Twentieth Annual Symposium on Computational Geometry, Brooklyn, NY, USA, 8–11 June 2004. [Google Scholar]
- Arthur, D.; Oudot, S.Y. Reverse Nearest Neighbors Search in High Dimensions using Locality-Sensitive Hashing. arXiv 2010, arXiv:1011.4955. [Google Scholar]
- Weiss, Y.; Torralba, A.; Fergus, R. Spectral Hashing. Int. Conf. Neural Inf. Process. Syst. 2008, 21. [Google Scholar]
- Lin, K.; Lu, J.; Chen, C.S.; Jie, Z. Learning Compact Binary Descriptors with Unsupervised Deep Neural Networks. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Movshovitz-Attias, Y.; Toshev, A.; Leung, T.K.; Ioffe, S.; Singh, S. No Fuss Distance Metric Learning using Proxies. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017. [Google Scholar]
- Goldberger, J.; Roweis, S.T.; Hinton, G.E.; Salakhutdinov, R.R. Neighbourhood Components Analysis; MIT Press: Cambridge, MA, USA, 2004. [Google Scholar]
- Zheng, L.; Yang, Y.; Tian, Q. SIFT Meets CNN: A Decade Survey of Instance Retrieval. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 40, 1224–1244. [Google Scholar] [CrossRef] [Green Version]
- Gordo, A.; Almazán, J.; Revaud, J.; Larlus, D. Deep Image Retrieval: Learning Global Representations for Image Search. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016. [Google Scholar]
- Zhang, R.; Lin, L.; Zhang, R.; Zuo, W.; Zhang, L. Bit-Scalable Deep Hashing with Regularized Similarity Learning for Image Retrieval and Person Re-identification. IEEE Trans. Image Process. 2015, 24, 4766–4779. [Google Scholar] [CrossRef] [Green Version]
- Shin, H.C.; Roth, H.R.; Gao, M.; Le, L.; Xu, Z.; Nogues, I.; Yao, J.; Mollura, D.; Summers, R.M. Deep Convolutional Neural Networks for Computer-Aided Detection: CNN Architectures, Dataset Characteristics and Transfer Learning. IEEE Trans. Med Imaging 2016, 35, 1285–1298. [Google Scholar] [CrossRef] [Green Version]
- Leonard, J.; Kramer, M.A. Improvement of the backpropagation algorithm for training neural networks. Comput. Chem. Eng. 1990, 14, 337–341. [Google Scholar] [CrossRef]
- Toda-Caraballo, I.; Garcia-Mateo, C.; Capdevila, C. Back propagation algorithm. Rev. Metal. 2010, 46, 499–510. [Google Scholar] [CrossRef] [Green Version]
- Liu, C.; Ma, J.; Tang, X.; Liu, F.; Zhang, X.; Jiao, L. Deep Hash Learning for Remote Sensing Image Retrieval. IEEE Trans. Geosci. Remote Sens. 2021, 59, 3420–3443. [Google Scholar] [CrossRef]
- Xie, Q.; Dai, Z.; Hovy, E.; Luong, T.; Le, Q. Unsupervised data augmentation for consistency training. Adv. Neural Inf. Process. Syst. 2020, 33, 6256–6268. [Google Scholar]
- Jose, A.; Ottlik, E.S.; Rohlfing, C.; Ohm, J.R. Optimized feature space learning for generating efficient binary codes for image retrieval. Signal Process. Image Commun. 2022, 100, 116529. [Google Scholar] [CrossRef]
- Khosla, P.; Teterwak, P.; Wang, C.; Sarna, A.; Tian, Y.; Isola, P.; Maschinot, A.; Liu, C.; Krishnan, D. Supervised contrastive learning. Adv. Neural Inf. Process. Syst. 2020, 33, 18661–18673. [Google Scholar]
- Bickel, P.J.; Li, B.; Tsybakov, A.B.; van de Geer, S.A.; Yu, B.; Valdés, T.; Rivero, C.; Fan, J.; van der Vaart, A. Regularization in statistics. Test 2006, 15, 271–344. [Google Scholar] [CrossRef] [Green Version]
- Tschopp, D.; Diggavi, S. Approximate Nearest Neighbor Search through Comparisons. arXiv 2009, arXiv:0909.2194. [Google Scholar]
- Andoni, A.; Indyk, P. Near-Optimal Hashing Algorithms for Approximate Nearest Neighbor in High Dimensions. In Proceedings of the 47th Annual IEEE Symposium on Foundations of Computer Science (FOCS 2006), Berkeley, CA, USA, 21–24 October 2006. [Google Scholar]
- Norouzi, M.; Fleet, D.J. Minimal loss hashing for compact binary codes. In Proceedings of the 28th International Conference on Machine Learning (ICML-11), Bellevue, WA, USA, 28 June–2 July 2011. [Google Scholar]
- Wei, L.; Wang, J.; Ji, R.; Jiang, Y.G.; Chang, S.F. Supervised Hashing with Kernels. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012. [Google Scholar]
- Lin, G.; Shen, C.; Shi, Q.; Hengel, A.; Suter, D. Fast Supervised Hashing with Decision Trees for High-Dimensional Data. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014. [Google Scholar]
- Shen, F.; Shen, C.; Liu, W.; Shen, H.T. Supervised Discrete Hashing. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 37–45. [Google Scholar]
- Kang, W.; Li, W.; Zhou, Z.H. Column Sampling Based Discrete Supervised Hashing. In Proceedings of the AAAI Conference on Artificial Intelligence, Phoenix, AZ, USA, 12–17 February 2016. [Google Scholar]
- Wang, J.; Kumar, S.; Chang, S.F. Sequential Projection Learning for Hashing with Compact Codes. In Proceedings of the International Conference on International Conference on Machine Learning, Haifa, Israel, 21–24 June 2010. [Google Scholar]
- Xia, R.; Pan, Y.; Lai, H.; Liu, C.; Yan, S. Supervised hashing for image retrieval via image representation learning. In Proceedings of the Twenty-Eighth AAAI Conference on Artificial Intelligence (AAAI-14), Quebec City, QC, Canada, 27–31 July 2014. [Google Scholar]
- Lai, H.; Pan, Y.; Ye, L.; Yan, S. Simultaneous Feature Learning and Hash Coding with Deep Neural Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 3270–3278. [Google Scholar]
- Zhao, F.; Huang, Y.; Wang, L.; Tan, T. Deep Semantic Ranking Based Hashing for Multi-Label Image Retrieval. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- Cao, Y.; Long, M.; Wang, J.; Zhu, H.; Wen, Q. Deep Quantization Network for Efficient Image Retrieval. In Proceedings of the Thirtieth AAAI Conference on Artificial Intelligence (AAAI-16), Phoenix, AZ, USA, 12–17 February 2016. [Google Scholar]
- Li, W.J.; Wang, S.; Kang, W.C. Feature Learning based Deep Supervised Hashing with Pairwise Labels. arXiv 2015, arXiv:1511.03855. [Google Scholar]
- Liu, H.; Wang, R.; Shan, S.; Chen, X. Deep Supervised Hashing for Fast Image Retrieval. Int. J. Comput. Vis. 2019, 127, 1217–1234. [Google Scholar] [CrossRef]
- Wang, X.; Shi, Y.; Kitani, K.M. Deep Supervised Hashing with Triplet Labels. In Proceedings of the Asian Conference on Computer Vision, Taipei, Taiwan, 20–24 November 2017. [Google Scholar]
- Zhu, H.; Long, M.; Wang, J.; Cao, Y. Deep Hashing Network for efficient similarity retrieval. In Proceedings of the AAAI Conference on Artificial Intelligence, Phoenix, AZ, USA, 12–17 February 2016. [Google Scholar]
- Cao, Z.; Long, M.; Wang, J.; Yu, P.S. HashNet: Deep Learning to Hash by Continuation. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017. [Google Scholar]
- Yang, H.F.; Lin, K.; Chen, C.S. Supervised Learning of Semantics-Preserving Hash via Deep Convolutional Neural Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 40, 437–451. [Google Scholar] [CrossRef] [Green Version]
- Gionis, A. Similarity Search in High Dimensions via Hashing. In Proceedings of the Vldb, Edinburgh, UK, 7–10 September 1999; Volume 99, pp. 518–529. [Google Scholar]
- Kulis, B.; Darrell, T. Learning to Hash with Binary Reconstructive Embeddings. In Proceedings of the International Conference on Neural Information Processing Systems, Bangkok, Thailand, 1–5 December 2009. [Google Scholar]
- Zhang, C.; Zheng, W.S. Semi-Supervised Multi-View Discrete Hashing for Fast Image Search. IEEE Trans. Image Process. 2017, 26, 2604–2617. [Google Scholar] [CrossRef]
- Wang, J.; Kumar, S.; Chang, S.F. Semi-Supervised Hashing for Large-Scale Search. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 34, 2393–2406. [Google Scholar] [CrossRef] [Green Version]
- Liu, W.; Mu, C.; Kumar, S.; Chang, S.F. Discrete Graph Hashing. Adv. Neural Inf. Process. Syst. 2014, 4, 3419–3427. [Google Scholar]
- Luo, X.; Wang, H.; Wu, D.; Chen, C.; Deng, M.; Huang, J.; Hua, X.S. A Survey on Deep Hashing Methods. ACM Trans. Knowl. Discov. Data, 2022; Just Accepted. [Google Scholar] [CrossRef]
- Liu, B.; Cao, Y.; Long, M.; Wang, J.; Wang, J. Deep triplet quantization. In Proceedings of the 26th ACM International Conference on Multimedia, Seoul, Korea, 22–26 October 2018; pp. 755–763. [Google Scholar]
- Krizhevsky, A.; Hinton, G. Learning multiple layers of features from tiny images. In Handbook of Systemic Autoimmune Diseases; Elsevier: Amsterdam, The Netherlands, 2009; Volume 1. [Google Scholar]
- Chua, T.S.; Tang, J.; Hong, R.; Li, H.; Luo, Z. NUS-WIDE: A real-world web image database from National University of Singapore. In Proceedings of the Acm International Conference on Image & Video Retrieval, Santorini Island, Greece, 8–10 July 2009. [Google Scholar]
- Netzer, Y.; Wang, T.; Coates, A.; Bissacco, A.; Ng, A.Y. Reading Digits in Natural Images with Unsupervised Feature Learning. In Proceedings of the Deep Learning and Unsupervised Feature Learning Workshop, Granada, Spain, 16–17 December 2011. [Google Scholar]
- Zhang, P.; Su, W. Statistical inference on recall, precision and average precision under random selection. In Proceedings of the 2012 9th International Conference on Fuzzy Systems and Knowledge Discovery, Chongqing, China, 29–31 May 2012; pp. 1348–1352. [Google Scholar] [CrossRef]
- Gong, Y.; Lazebnik, S.; Gordo, A.; Perronnin, F. Iterative quantization: A procrustean approach to learning binary codes for large-scale image retrieval. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 35, 2916–2929. [Google Scholar] [CrossRef] [Green Version]
- Lin, K.; Yang, H.F.; Hsiao, J.H.; Chen, C.S. Deep learning of binary hash codes for fast image retrieval. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Boston, MA, USA, 7–12 June 2015; pp. 27–35. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | CIFAR-10 | NUS-WIDE | SVHN |
|---|---|---|---|
| DFEH | 2389.211 | 9362.316 | 11,043.457 |
| Method | 12 bit | 24 bit | 36 bit | 48 bit |
|---|---|---|---|---|
| LSH [7] | 0.1319 | 0.1367 | 0.1407 | 0.1492 |
| SH [7] | 0.1319 | 0.1278 | 0.1364 | 0.1320 |
| ITQ [51] | 0.1080 | 0.1088 | 0.1117 | 0.1184 |
| CCA-ITQ [51] | 0.1653 | 0.1960 | 0.2085 | 0.2176 |
| MLH [24] | 0.1844 | 0.1994 | 0.2053 | 0.2094 |
| BRE [41] | 0.1576 | 0.1624 | 0.1684 | 0.1717 |
| KSH [25] | 0.2956 | 0.3732 | 0.4019 | 0.4167 |
| CNNH [30] | 0.5326 | 0.5613 | 0.5631 | 0.5563 |
| DLBHC [52] | 0.5504 | 0.5810 | 0.5769 | 0.5883 |
| DNNH [31] | 0.5711 | 0.5868 | 0.5892 | 0.5911 |
| DPSH [34] | 0.6534 | 0.6546 | 0.6610 | 0.6632 |
| DSH [35] | 0.6776 | 0.7213 | 0.7465 | 0.7568 |
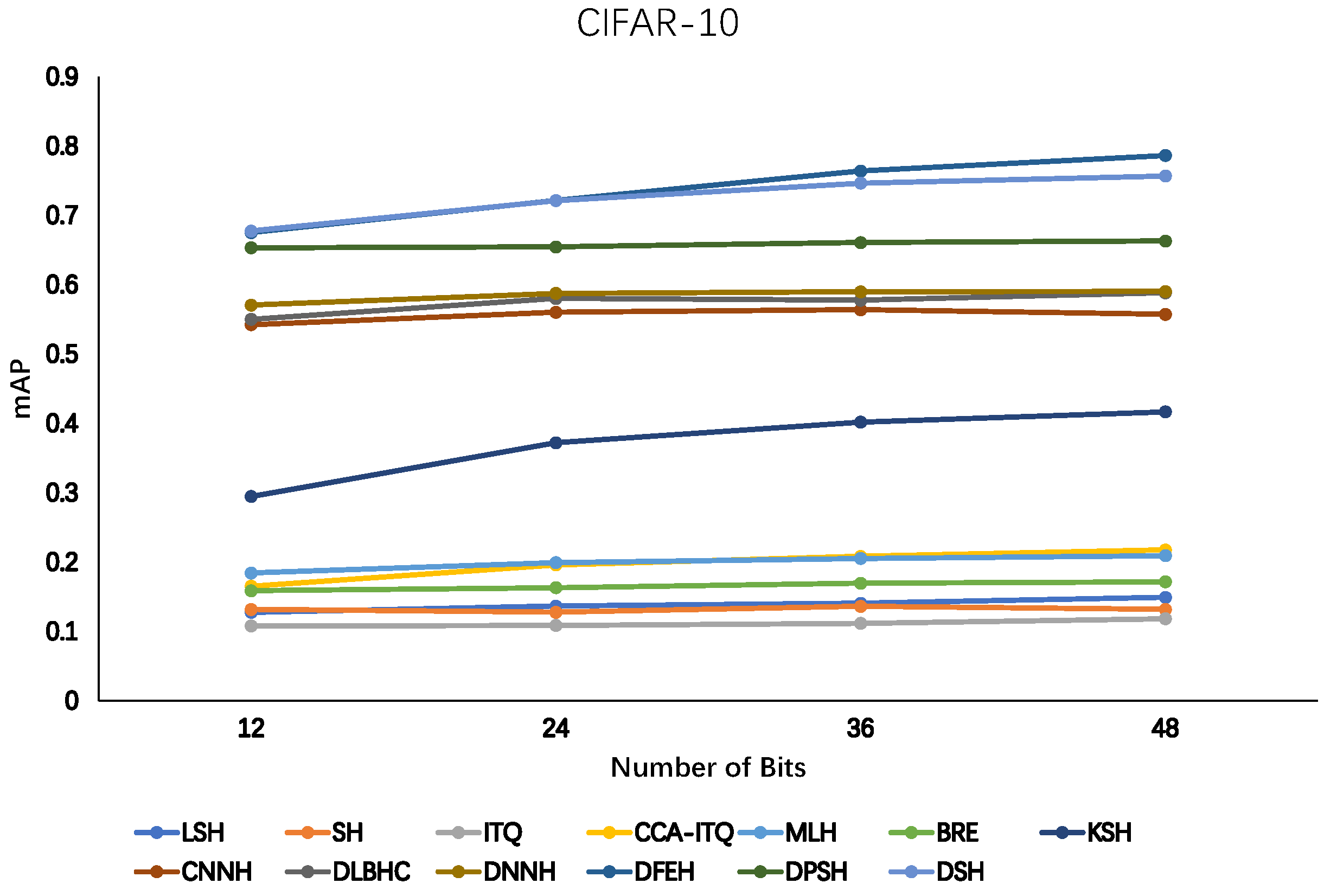
| DFEH | 0.6753 | 0.7216 | 0.7641 | 0.7864 |
| Method | 12 bit | 24 bit | 36 bit | 48 bit |
|---|---|---|---|---|
| LSH [7] | 0.3329 | 0.3392 | 0.3450 | 0.3474 |
| SH [7] | 0.3401 | 0.3374 | 0.3343 | 0.3332 |
| ITQ [51] | 0.3425 | 0.3464 | 0.3522 | 0.3576 |
| CCA-ITQ [51] | 0.3874 | 0.3977 | 0.4146 | 0.4188 |
| MLH [24] | 0.3829 | 0.3930 | 0.3959 | 0.3990 |
| BRE [41] | 0.3556 | 0.3581 | 0.3549 | 0.3592 |
| KSH [25] | 0.4331 | 0.4592 | 0.4695 | 0.4692 |
| CNNH [30] | 0.4315 | 0.4358 | 0.4451 | 0.4332 |
| DLBHC [52] | 0.4663 | 0.4728 | 0.4921 | 0.4916 |
| DNNH [31] | 0.5471 | 0.5367 | 0.5258 | 0.5248 |
| DPSH [34] | 0.5652 | 0.5743 | 0.5876 | 0.5881 |
| DSH [35] | 0.5601 | 0.5783 | 0.5814 | 0.5877 |
| DFEH | 0.5674 | 0.5788 | 0.5863 | 0.5921 |
| CIFAR-10 | NUS-WIDE | SVHN | |
|---|---|---|---|
| 0 | 0.5436 | 0.5371 | 0.7966 |
| 0.1 | 0.2543 | 0.4376 | 0.7841 |
| 0.01 | 0.6874 | 0.5763 | 0.8624 |
| 0.001 | 0.6047 | 0.5576 | 0.8362 |
| Loss | CIFAR-10 | NUS-WIDE | SVHN |
|---|---|---|---|
| 0.6253 | 0.5174 | 0.7862 | |
| 0.6654 | 0.5534 | 0.8068 | |
| 0.6546 | 0.5364 | 0.7934 | |
| 0.6774 | 0.5604 | 0.8242 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhao, X.; Liu, J. Leveraging Deep Features Enhance and Semantic-Preserving Hashing for Image Retrieval. Electronics 2022, 11, 2391. https://doi.org/10.3390/electronics11152391
Zhao X, Liu J. Leveraging Deep Features Enhance and Semantic-Preserving Hashing for Image Retrieval. Electronics. 2022; 11(15):2391. https://doi.org/10.3390/electronics11152391
Chicago/Turabian StyleZhao, Xusheng, and Jinglei Liu. 2022. "Leveraging Deep Features Enhance and Semantic-Preserving Hashing for Image Retrieval" Electronics 11, no. 15: 2391. https://doi.org/10.3390/electronics11152391