
RECA: Relation Extraction Based on Cross-Attention Neural Network


Abstract
:1. Introduction
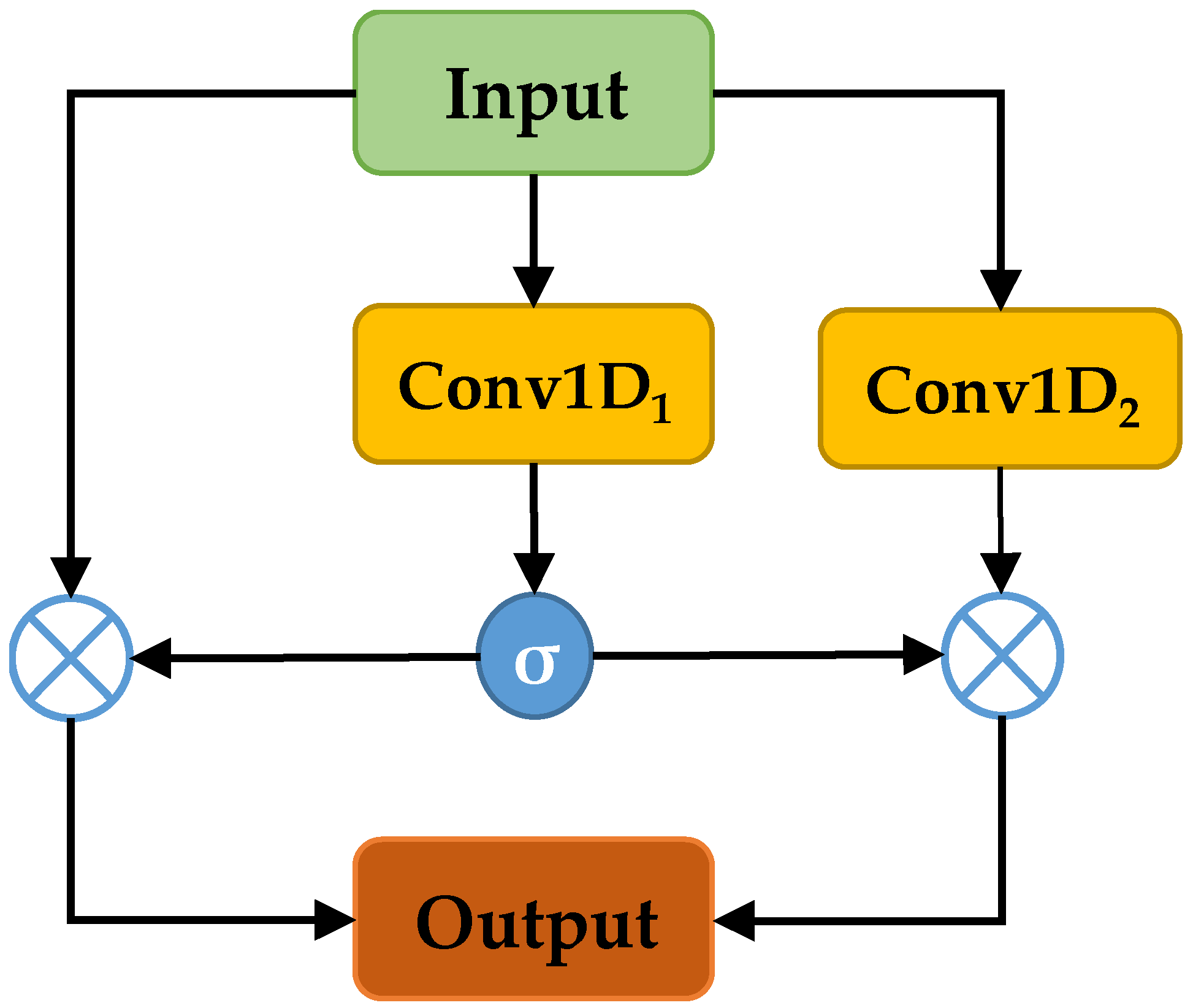
- We introduce a dilated gated convolutional neural network model, which has the advantage of being able to learn long-range information, instead of traditional convolution. In addition, we propose residual gated linear units as an activation function to improve model performance.
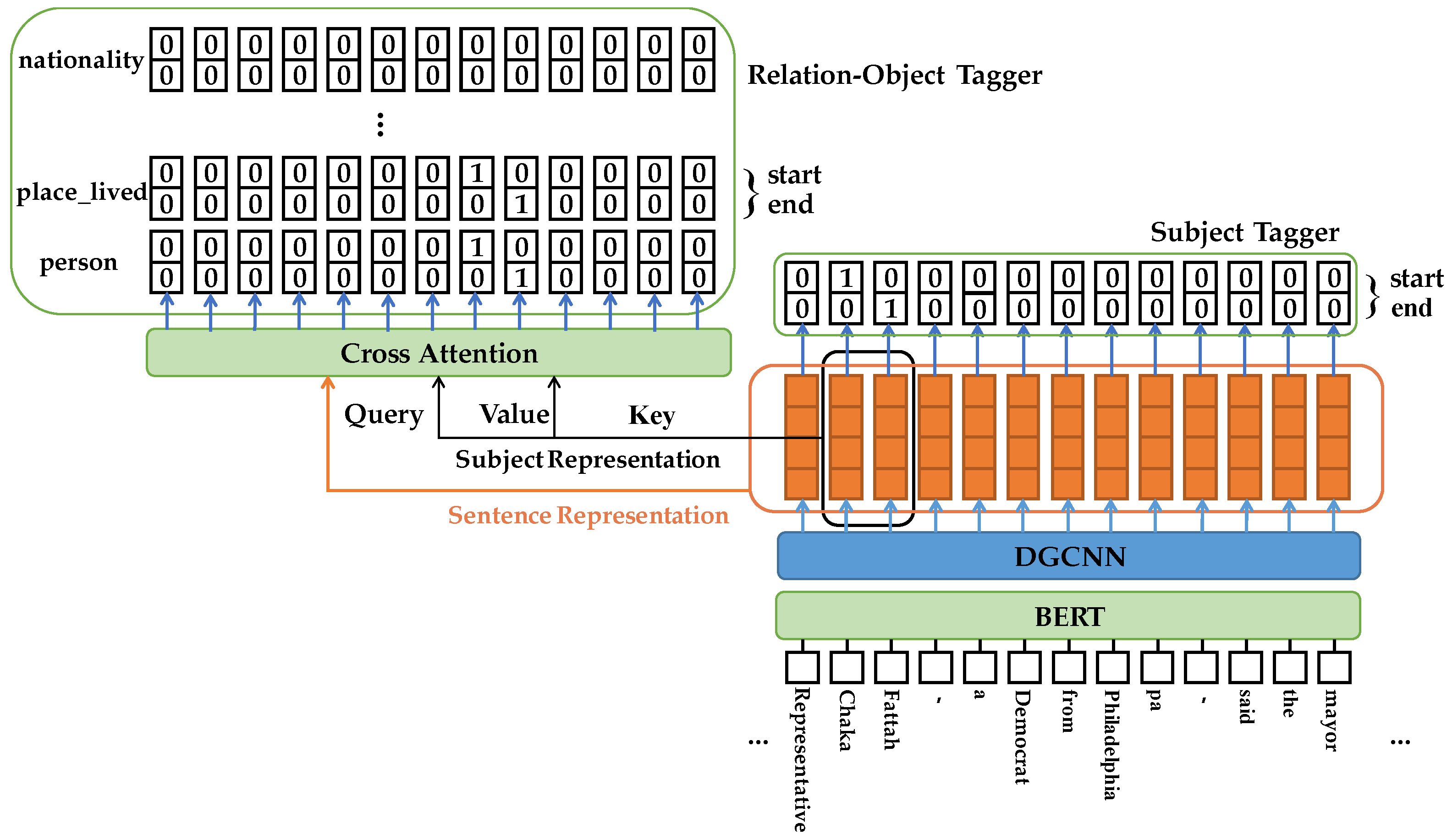
- We propose a cross-attention neural network for the decoder to learn the dependence between subject information and relation-object taggers. This combines subject representation with sentence representation to detect relevant objects and relations.
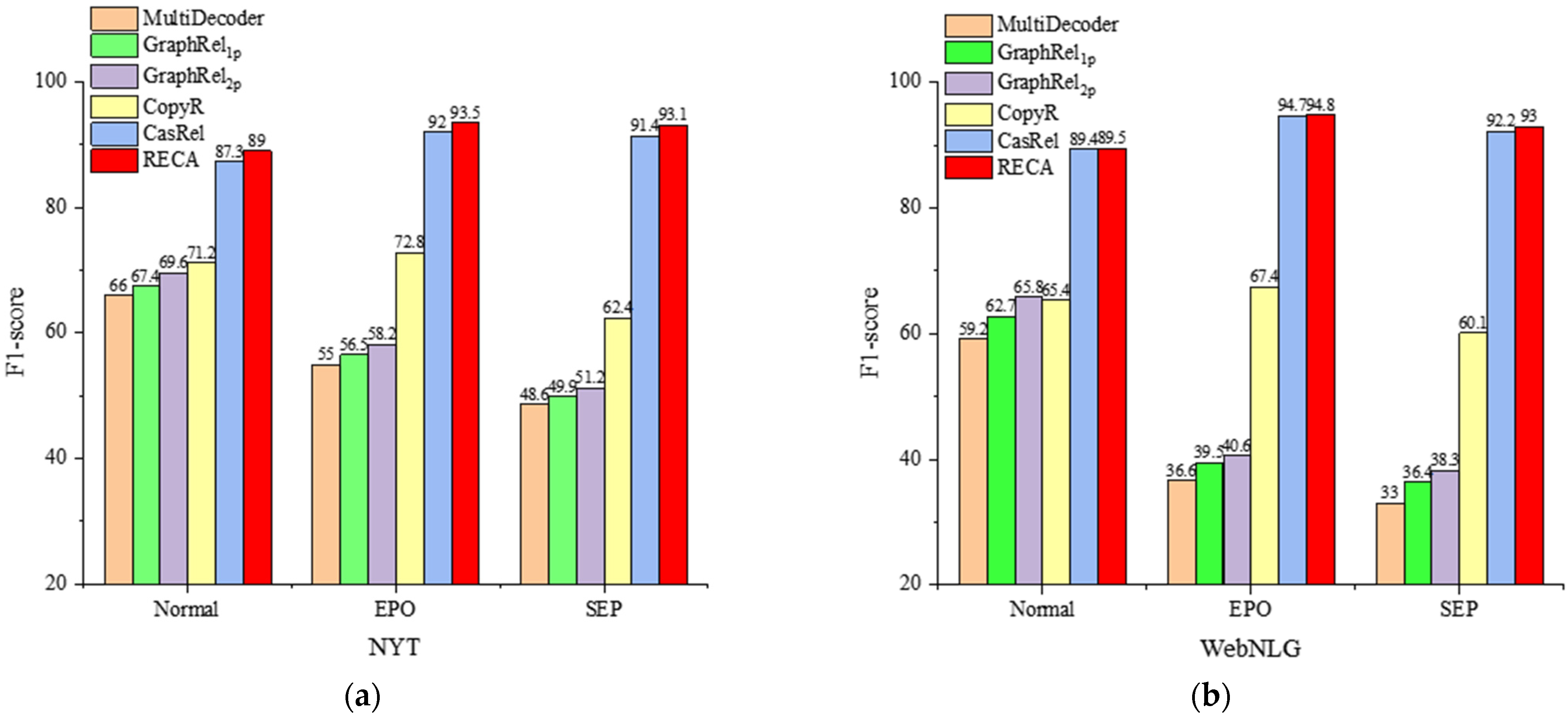
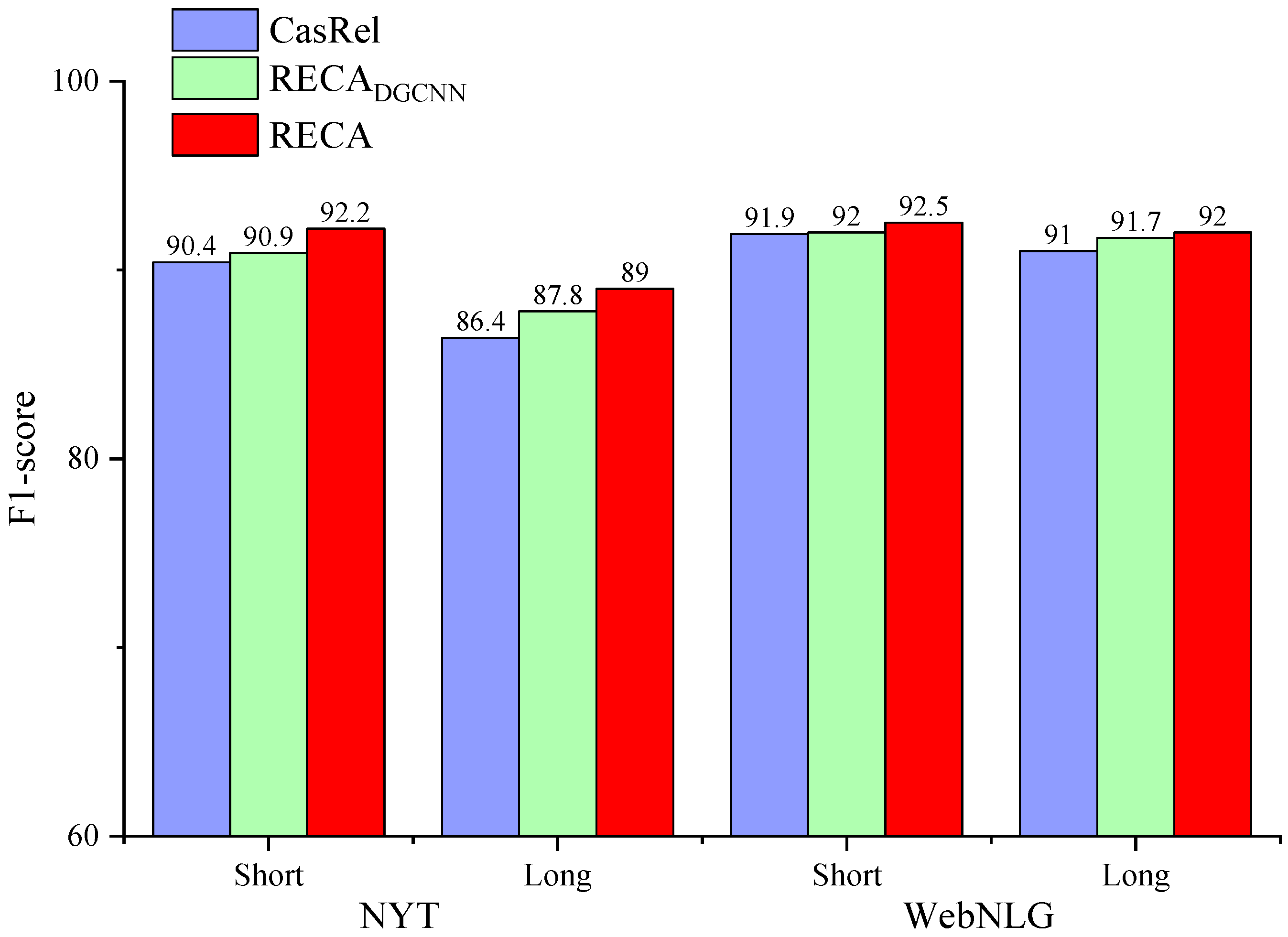
- We describe a series of experiments in which we compared the proposed model with the CasRel [11] model and show that our model achieved 1.9% and 0.7% absolute gain in terms of F1-score for two datasets. The ablation experiment demonstrates that each part we propose improves network performance.
2. Related Works
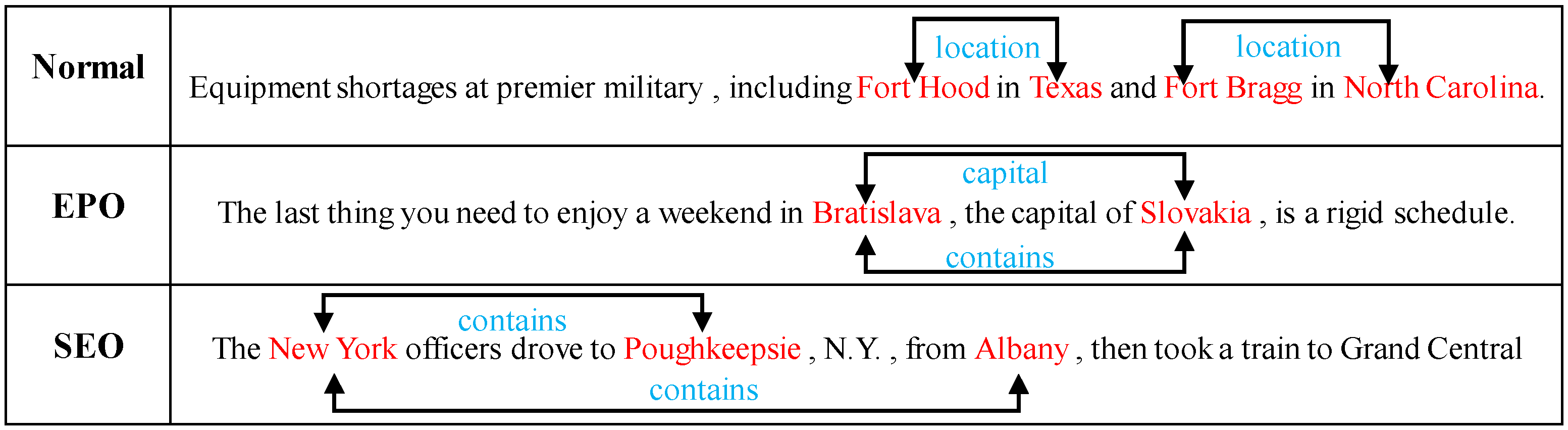
3. Model
3.1. Encoder
3.1.1. BERT
3.1.2. Dilated Gated Convolutional Neural Network
3.2. Decoder
3.2.1. Subject Tagger
3.2.2. Cross-Attention Neural Network
3.2.3. Relation-Object Tagger
4. Experiment
4.1. Experiment Datasets and Evalution Metrics
4.2. Setting Training Parameters
4.3. Experimental Result
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Young, G.O. Synthetic Structure of Industrial Plastics, 2nd ed.; Peters, J., Ed.; McGraw-Hill: New York, NY, USA, 1964; Volume 3, pp. 15–64. [Google Scholar]
- Chan, Y.S.; Roth, D. Exploiting syntactico-semantic structures for relation extraction. In Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics: Human Language Technologies, Portland, OR, USA, 19–24 June 2011; Volume 1, pp. 551–560. [Google Scholar]
- Zelenko, D.; Aone, C.; Richardella, A. Kernel methods for relation extraction. J. Mach. Learn. Res. 2002, 10, 71–78. [Google Scholar]
- Li, Q.; Ji, H. Incremental joint extraction of entity mentions and relations. In Proceedings of the 52nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Baltimore, MD, USA, 22–27 June 2014; Volume 1, pp. 402–412. [Google Scholar]
- Ren, X.; Wu, Z.; He, W.; Qu, M.; Voss, C.R.; Ji, H.; Abdelzaher, T.F.; Han, J. Cotype: Joint extraction of typed entities and relations with knowledge bases. In Proceedings of the 26th International Conference on World Wide Web, Perth, Australia, 3–7 April 2017; pp. 1015–1024. [Google Scholar]
- Katiyar, A.; Cardie, C. Going out on a limb: Joint extraction of entity mentions and relations without dependency trees. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Vancouver, BC, Canada, 30 July–4 August 2017; pp. 917–928. [Google Scholar]
- Yu, X.; Lam, W. Jointly identifying entities and extracting relations in encyclopedia text via a graphical model approach. In Proceedings of the 23rd International Conference on Computational Linguistics, Beijing, China, 23–27 August 2010; pp. 1399–1407. [Google Scholar]
- Zeng, X.; Zeng, D.; He, S.; Liu, K.; Zhao, J. Extracting relational facts by an end to end neural model with copy mechanism. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Melbourne, Australia, 15–20 July 2018; Volume 1, pp. 506–514. [Google Scholar]
- Ye, H.; Zhang, N.; Deng, S.; Chen, M.; Tan, C.; Huang, F.; Chen, H. Contrastive Triple Extraction with Generative Transformer. In Proceedings of the Thirty-Fifth AAAI Conference on Artificial Intelligence, AAAI, Virtually, 2–9 February 2021; pp. 14257–14265. [Google Scholar]
- Fu, T.; Li, P.; Ma, W. Graphrel: Modeling text as relational graphs for joint entity and relation extraction. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Florence, Italy, 28 July–2 August 2019; pp. 1409–1418. [Google Scholar]
- Wei, Z.; Su, J.; Wang, Y.; Tian, Y.; Chang, Y. A novel cascade binary tagging framework for relational triple extraction. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online, 5–10 July 2020; pp. 1476–1488. [Google Scholar]
- Sun, K.; Zhang, R.; Mensah, S.; Mao, Y.; Liu, X. Progressive multitask learning with controlled information flow for joint entity and relation extraction. Assoc. Adv. Artif. Intell. 2021, 35, 13851–13859. [Google Scholar]
- Brauwers, G.; Frasincar, F. A General Survey on Attention Mechanisms in Deep Learning. IEEE Trans. Knowl. Data Eng. 2021. [Google Scholar] [CrossRef]
- Lai, T.; Cheng, L.; Wang, D.; Ye, H.; Zhang, W. RMAN: Relational multi-head attention neural network for joint extraction of entities and relations. Appl. Intell. 2021, 52, 3132–3142. [Google Scholar] [CrossRef]
- Zheng, S.; Wang, F.; Bao, H.; Hao, Y.; Zhou, P.; Xu, B. Joint extraction of entities and relations based on a novel tagging scheme. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Vancouver, BC, Canada, 30 July–4 August 2017; Volume 1, pp. 1227–1236. [Google Scholar]
- Peters, M.E.; Neumann, M.; Iyyer, M.; Gardner, M.; Clark, C.; Lee, K.; Zettlemoyer, L. Deep contextualized word representations. Proc. Conf. N. Am. Chapter Assoc. Comput. Linguist. Hum. Lang. Technol. 2018, 1, 2227–2237. [Google Scholar]
- Devlin, J.; Chang, M.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), Minneapolis, MN, USA, 2–7 January 2019; pp. 4171–4186. [Google Scholar]
- Huang, W.; Cheng, X.; Wang, T.; Chu, W. BERT-Based Multi-head Selection for Joint Entity-Relation Extraction. In Natural Language Processing and Chinese Computing. NLPCC 2019. Lecture Notes in Computer Science; Tang, J., Kan, M.Y., Zhao, D., Li, S., Zan, H., Eds.; Springer: Berlin/Heidelberg, Germany, 2019; Volume 11839. [Google Scholar] [CrossRef] [Green Version]
- Wadden, D.; Wennberg, U.; Luan, Y.; Hajishirzi, H. Entity, Relation, and Event Extraction with Contextualized Span Representations. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), Hong Kong, China, 3–7 November 2019; Volume 2, pp. 5788–5793. [Google Scholar] [CrossRef] [Green Version]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Proceedings of the 31st Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 5998–6008. [Google Scholar]
- Zhong, P.; Wang, D.; Miao, C. Knowledge-enriched transformer for emotion detection in textual conversations. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), Hong Kong, China, 3–7 November 2019; Volume 1, pp. 165–176. [Google Scholar]
- Gehring, J.; Auli, M.; Grangier, D.; Yarats, D.; Dauphin, Y.N. Convolutional sequence to sequence learning. In Proceedings of the 34th International Conference on Machine Learning (Proceedings of Machine Learning Research), Sydney, NSW, Australia, 6–11 August 2017; Volume 70, pp. 1243–1252. [Google Scholar]
- Yu, F.; Koltun, V. Multi-Scale Context Aggregation by Dilated Convolutions. In Proceedings of the 4th International Conference on Learning Representations (ICLR), Caribe Hilton, San Juan, Puerto Rico, 2–4 May 2016; pp. 1–13. [Google Scholar]
- Dauphin, Y.N.; Fan, A.; Auli, M.; Grangier, D. Language modeling with gated convolutional networks. In Proceedings of the 34th International Conference on Machine Learning, Sydney, NSW, Australia, 6–11 August 2017; Volume 70, pp. 933–941. [Google Scholar]
- Luong, M.; Pham, H.; Manning, C.D. Effective approaches to attention-based neural machine translation. arXiv 2015, arXiv:1508.04025. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26 July–1 August 2016; pp. 770–778. [Google Scholar] [CrossRef] [Green Version]
- Ba, J.L.; Kiros, J.R.; Hinton, G.E. Layer normalization. arXiv 2016, arXiv:1607.06450. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2017, arXiv:1412.6980. [Google Scholar]
- Riedel, S.; Yao, L.; McCallum, A. Modeling relations and their mentions without labeled text. In Proceedings of the Joint European Conference on Machine Learning and Knowledge Discovery in Databases, Barcelona, Spain, 19–23 September 2010; pp. 148–163. [Google Scholar]
- Gardent, C.; Shimorina, A.; Narayan, S.; Perez-Beltrachini, L. Creating training corpora for nlg micro-planners. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Vancouver, BC, Canada, 30 July–4 August 2017; pp. 179–188. [Google Scholar]
- Zeng, X.; He, S.; Zeng, D.; Liu, K.; Liu, S.; Zhao, J. Learning the extraction order of multiple relational facts in a sentence with reinforcement learning. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), Hong Kong, China, 3–7 November 2019; Volume 1, pp. 367–377. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Category | NYT | WebNLG | |||
|---|---|---|---|---|---|
| Training | Testing | Training | Testing | ||
| Overlap | Normal | 37,013 | 3266 | 1596 | 246 |
| EPO | 9782 | 978 | 227 | 26 | |
| SEO | 14,735 | 1297 | 3406 | 457 | |
| Number | n = 1 | 36,868 | 3244 | 1716 | 266 |
| n = 2 | 12,058 | 1045 | 1264 | 171 | |
| n = 2 | 3663 | 312 | 1043 | 131 | |
| n = 4 | 2618 | 291 | 648 | 90 | |
| n ≥ 5 | 988 | 108 | 348 | 45 | |
| Length | Short | 45,821 | 4054 | 4882 | 667 |
| Long | 10,374 | 946 | 137 | 36 | |
| ALL | 56,195 | 5000 | 5019 | 703 | |
| Method | NYT | WebNLG | ||||
|---|---|---|---|---|---|---|
| Prec. | Rec. | F1 | Prec. | Rec. | F1 | |
| NovelTagging [15] | 62.4 | 31.7 | 42.0 | 52.5 | 19.3 | 28.3 |
| CopyROneDecoder [8] | 59.4 | 53.1 | 56.0 | 32.2 | 28.9 | 30.5 |
| CopyRMultiDecoder [8] | 61.0 | 56.6 | 58.7 | 37.7 | 36.4 | 37.1 |
| GraphRel1p [10] | 62.9 | 57.3 | 60.0 | 42.3 | 39.2 | 42.9 |
| GraphRel2p [10] | 63.9 | 60.0 | 61.9 | 44.7 | 41.1 | 42.9 |
| CopyRRL [31] | 77.9 | 67.2 | 72.1 | 63.3 | 59.9 | 61.6 |
| CasRel * BiLSTM | 79.4 | 68.8 | 73.6 | 89.6 | 78.4 | 83.6 |
| CasRel [11] | 89.7 | 89.5 | 89.6 | 93.4 | 90.1 | 91.8 |
| PMEI [12] | 90.5 | 89.8 | 90.1 | 91.0 | 92.9 | 92 |
| RMAN [14] | 87.1 | 83.8 | 85.4 | 83.6 | 85.3 | 84.5 |
| CGT [9] | 94.7 | 84.2 | 89.1 | 92.9 | 75.6 | 83.4 |
| RECABiLSTM | 78.9 | 76.5 | 77.6 | 91.3 | 84.5 | 87.8 |
| RECA | 91.2 | 91.9 | 91.5 | 90.9 | 94.1 | 92.5 |
| Method | NYT | WebNLG | ||||
|---|---|---|---|---|---|---|
| Prec. | Rec. | F1 | Prec. | Rec. | F1 | |
| CasRel [11] | 89.7 | 89.5 | 89.6 | 93.4 | 90.1 | 91.8 |
| RECA | 91.2 | 91.9 | 91.5 | 90.9 | 94.1 | 92.5 |
| RECADGCNN | 89.8 | 90.7 | 90.3 | 91.7 | 92.1 | 91.9 |
| RECACA | 90.3 | 92.4 | 91.3 | 92.5 | 92.0 | 92.3 |
| Method | NYT | WebNLG | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| n = 1 | n = 2 | n = 3 | n = 4 | n ≥ 5 | n = 1 | n = 2 | n = 3 | n = 4 | n ≥ 5 | |
| CopyROneDecoder [8] | 66.6 | 52.6 | 49.7 | 48.7 | 20.3 | 65.2 | 33.0 | 22.2 | 14.2 | 13.2 |
| CopyRMultiDecoder [8] | 67.1 | 58.6 | 52.0 | 53.6 | 30.0 | 59.2 | 42.5 | 31.7 | 24.2 | 30.0 |
| GraphRel1p [10] | 69.1 | 59.5 | 54.4 | 53.9 | 37.5 | 63.8 | 46.3 | 34.7 | 30.8 | 29.4 |
| GraphRel2p [10] | 71.0 | 61.5 | 57.4 | 55.1 | 41.1 | 66.0 | 48.3 | 37.0 | 32.1 | 32.1 |
| CasRel [11] | 88.2 | 90.3 | 91.9 | 94.2 | 83.7 | 89.3 | 90.8 | 94.2 | 92.4 | 90.9 |
| RECA | 89.5 | 92.1 | 93.3 | 95.8 | 90.4 | 89.1 | 92.1 | 94.8 | 93.3 | 91.3 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Huang, X.; Guo, Z.; Zhang, J.; Cao, H.; Yang, J. RECA: Relation Extraction Based on Cross-Attention Neural Network. Electronics 2022, 11, 2161. https://doi.org/10.3390/electronics11142161
Huang X, Guo Z, Zhang J, Cao H, Yang J. RECA: Relation Extraction Based on Cross-Attention Neural Network. Electronics. 2022; 11(14):2161. https://doi.org/10.3390/electronics11142161
Chicago/Turabian StyleHuang, Xiaofeng, Zhiqiang Guo, Jialiang Zhang, Hui Cao, and Jie Yang. 2022. "RECA: Relation Extraction Based on Cross-Attention Neural Network" Electronics 11, no. 14: 2161. https://doi.org/10.3390/electronics11142161