
Validating Syntactic Correctness Using Unsupervised Clustering Algorithms


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
2. Related Work
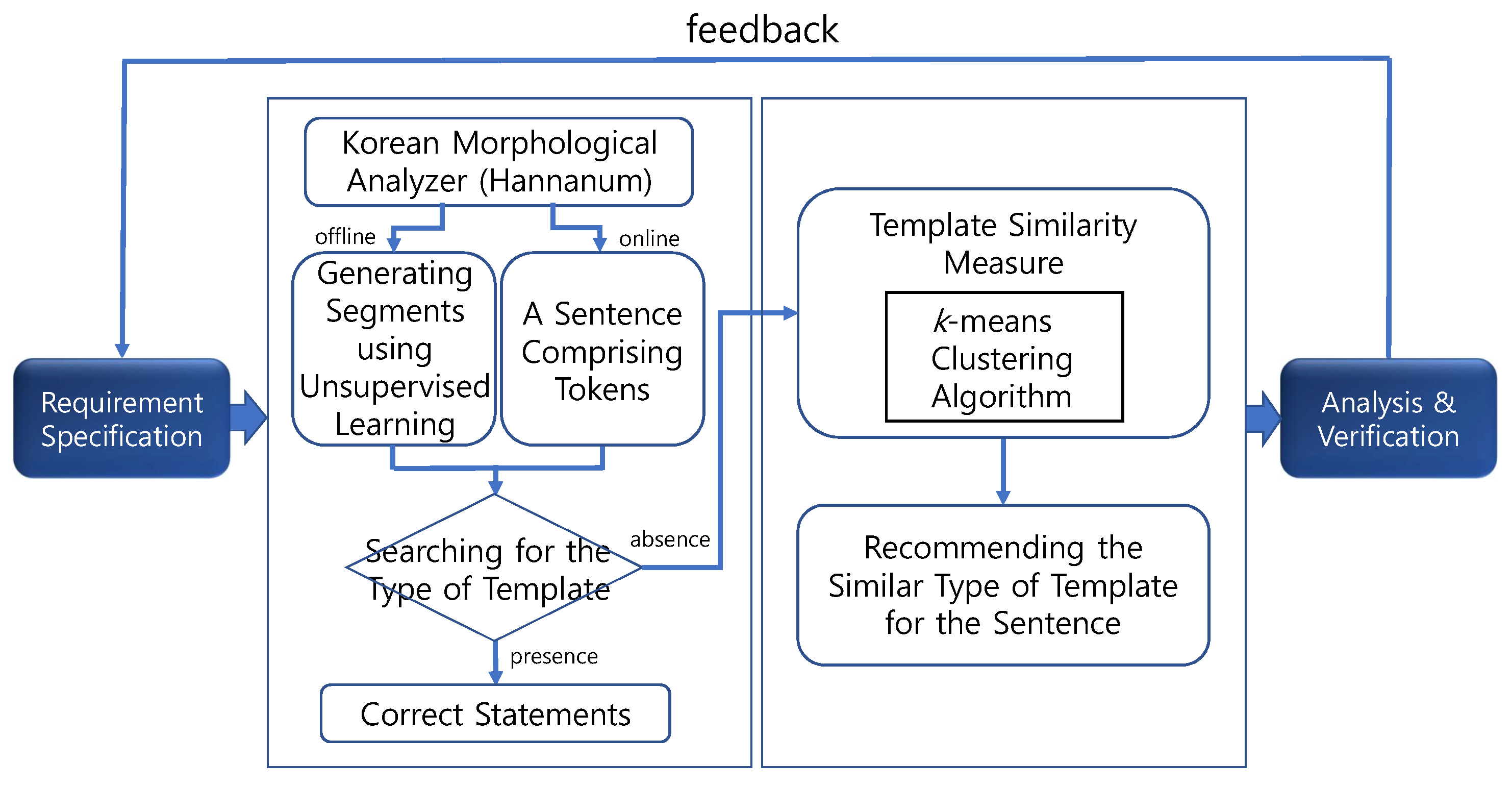
3. Automated Checker for the Statements of Requirement Specifications
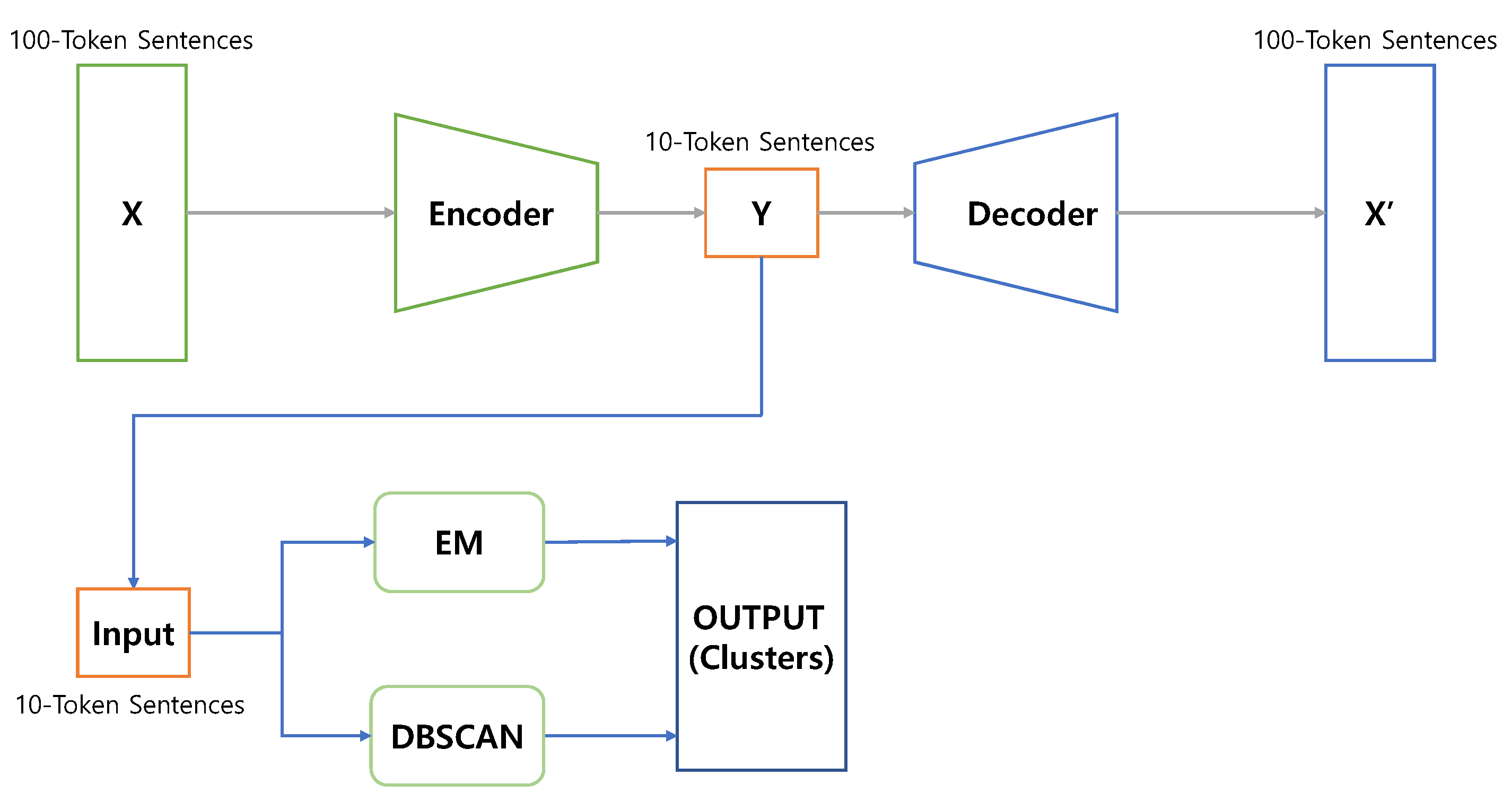
3.1. Design of Automated Checker Using Unsupervised Clustering Techniques
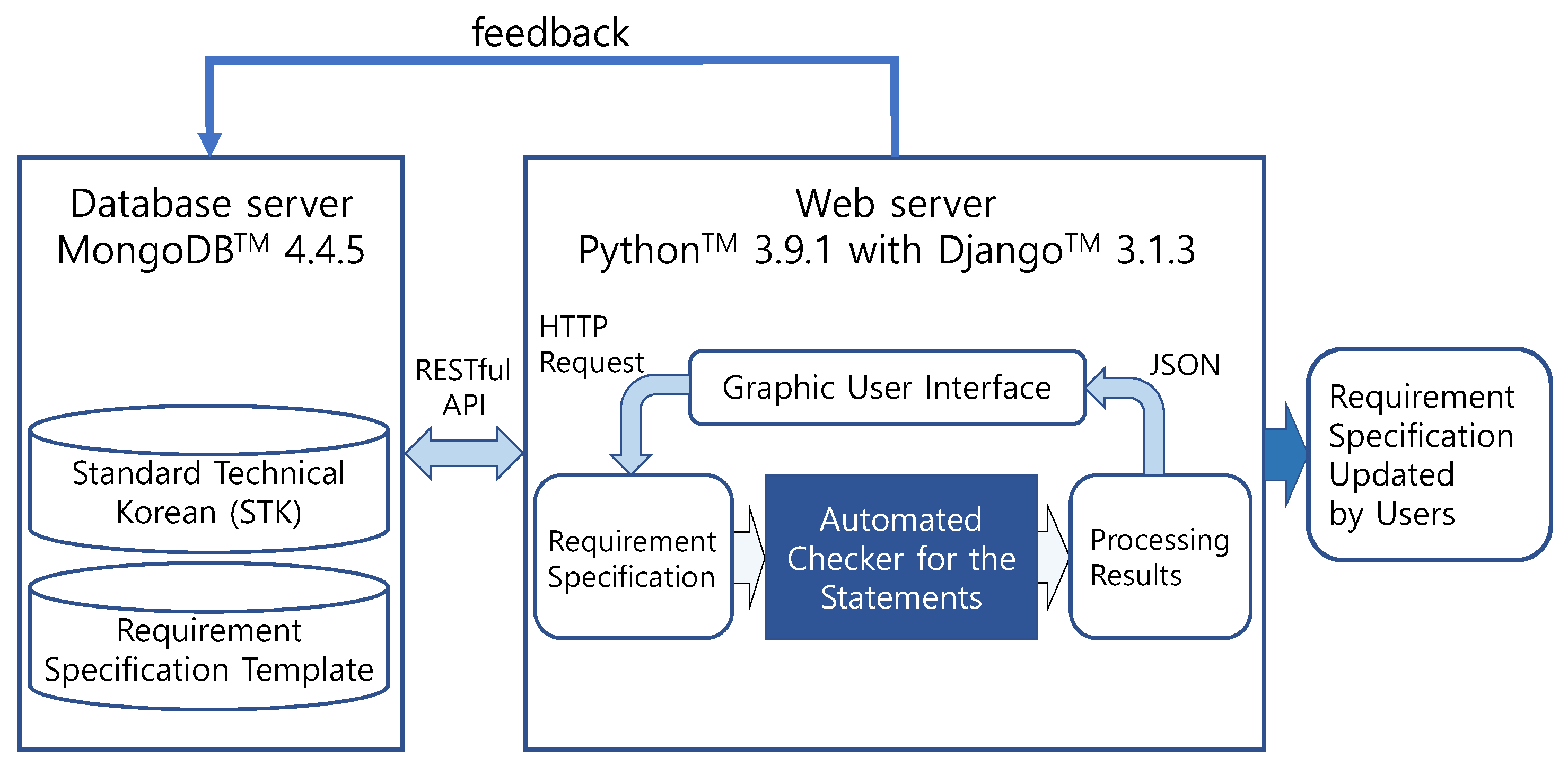
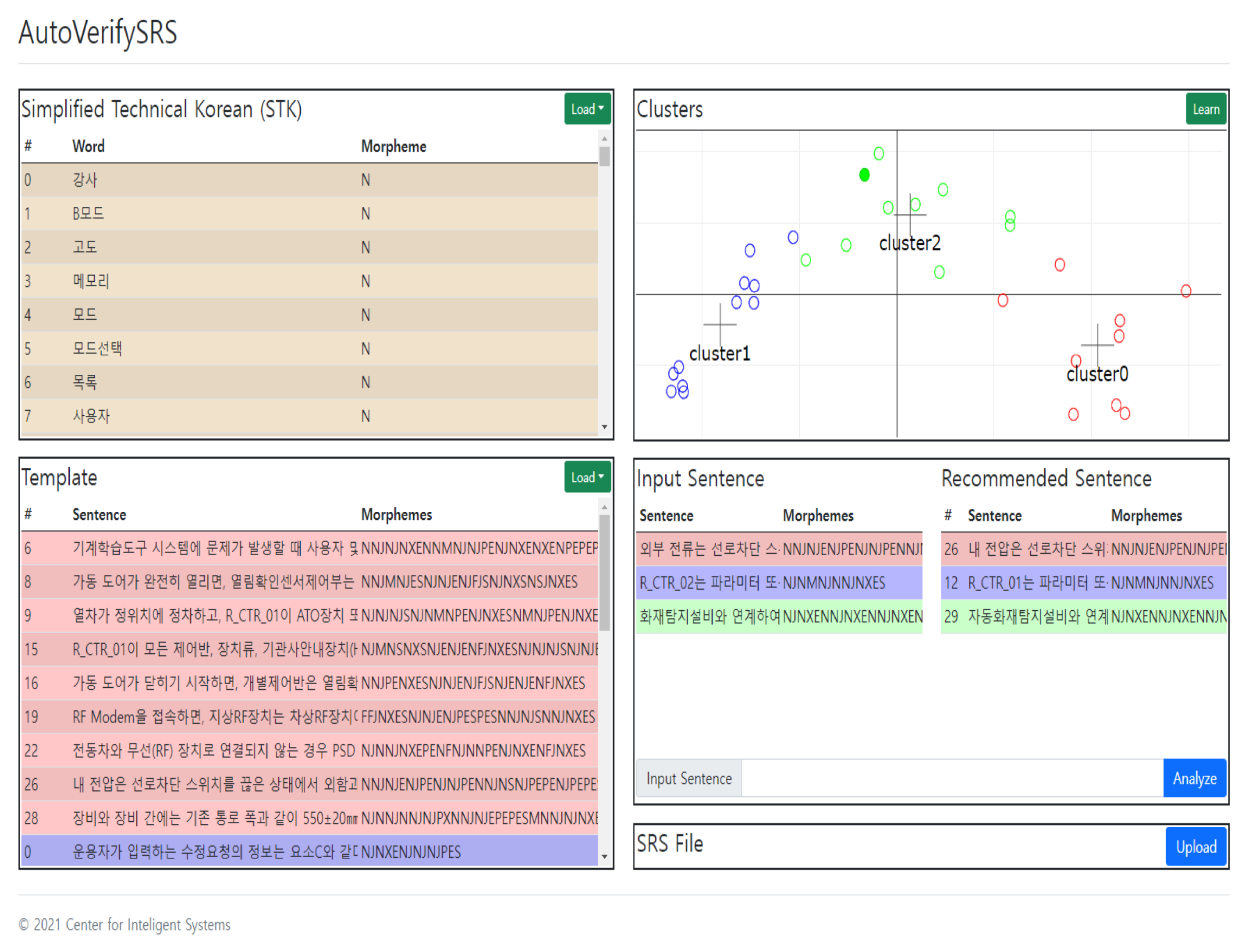
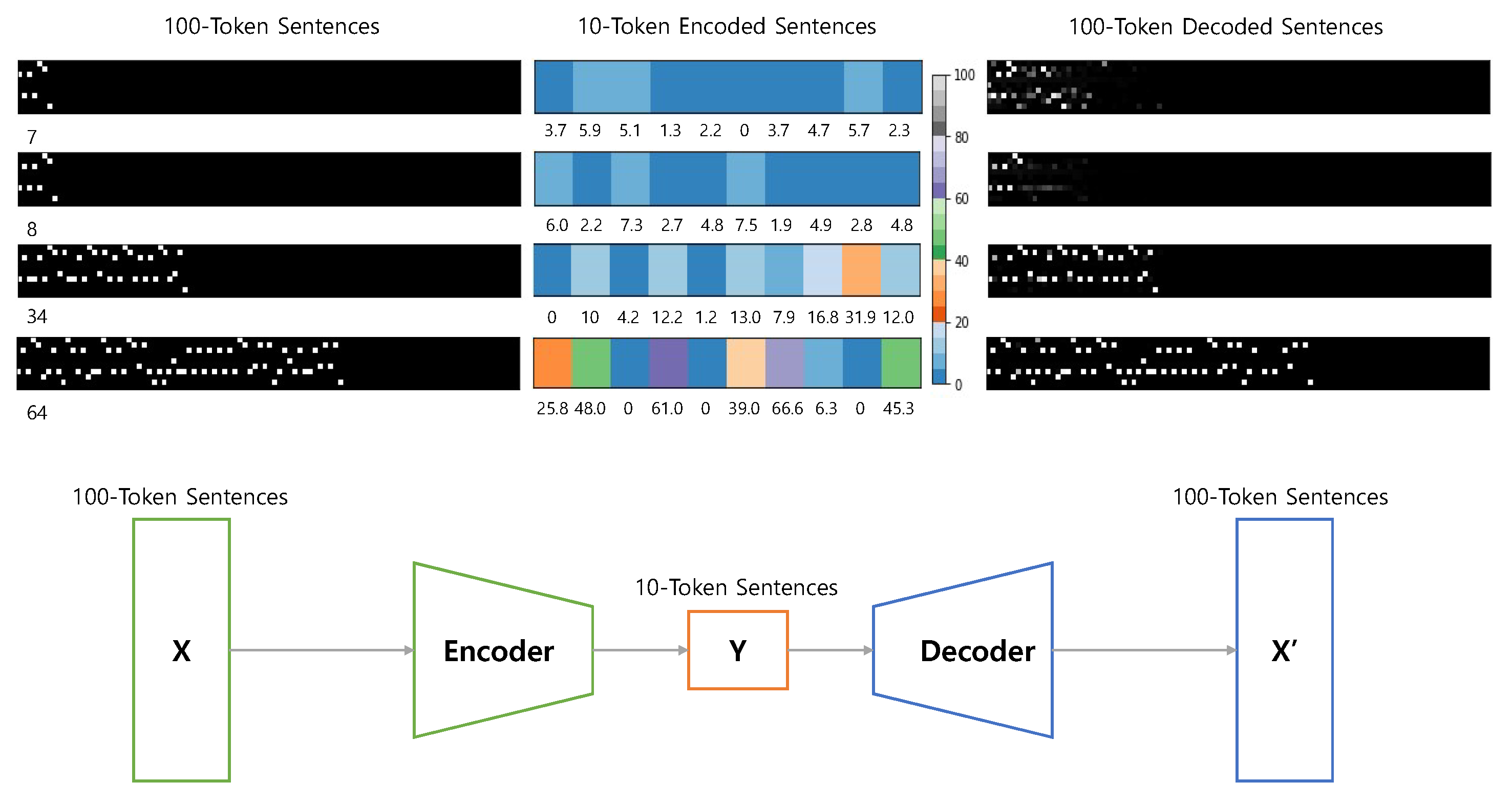
3.2. Implementation of Automated Checker
4. Experimental Results
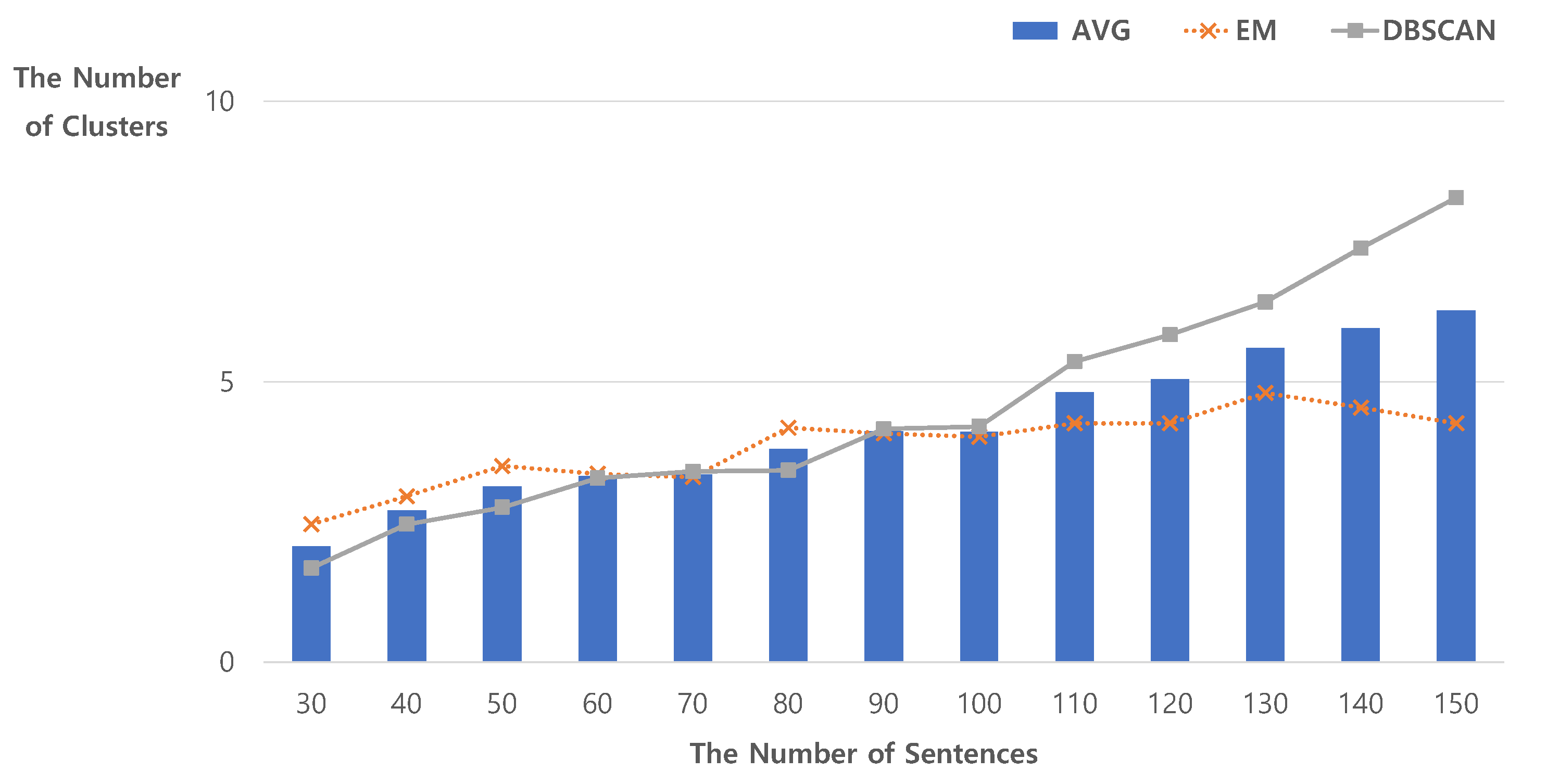
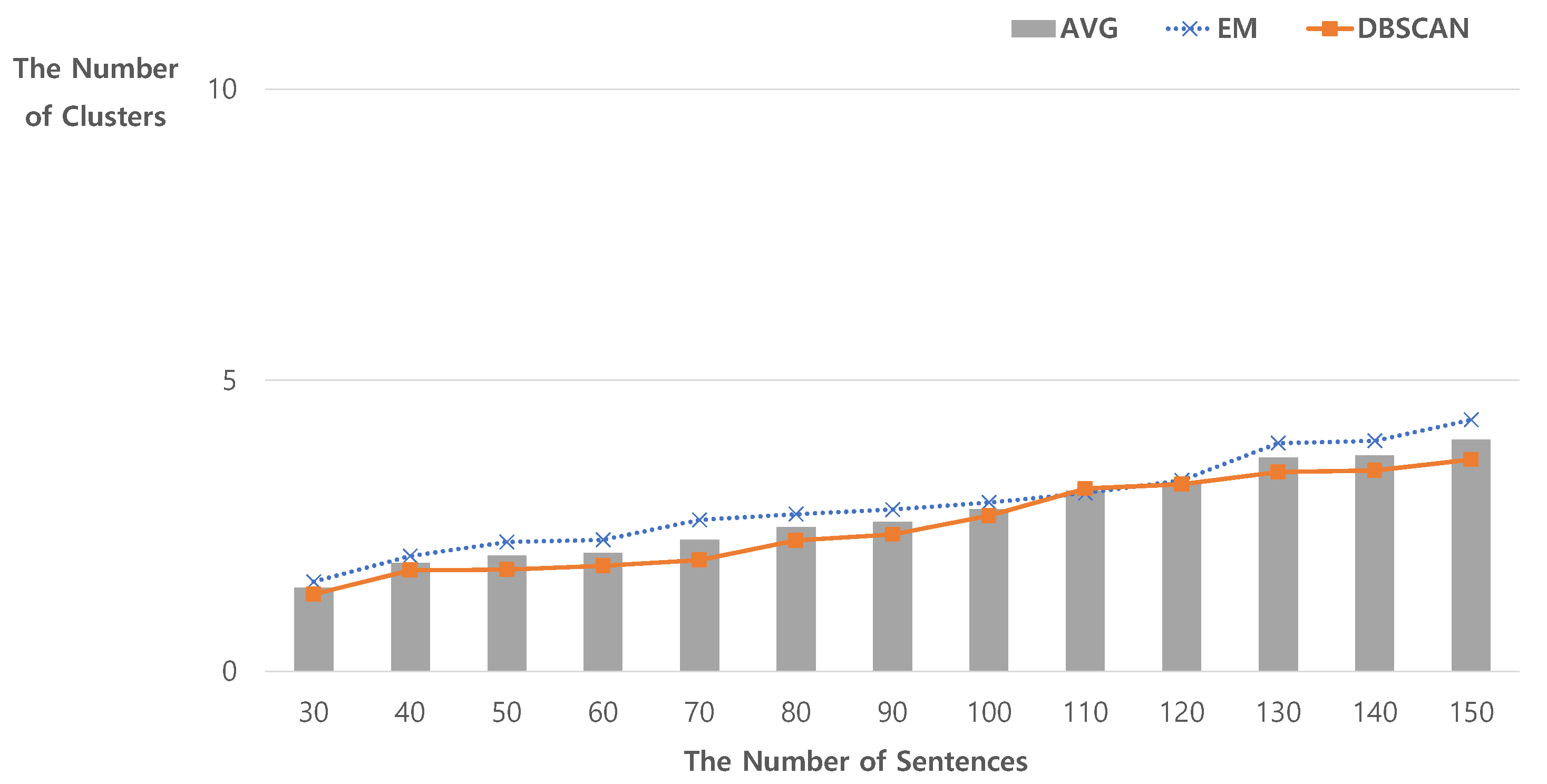
4.1. The Number of Natural Clusters Using Unsupervised Clustering Techniques
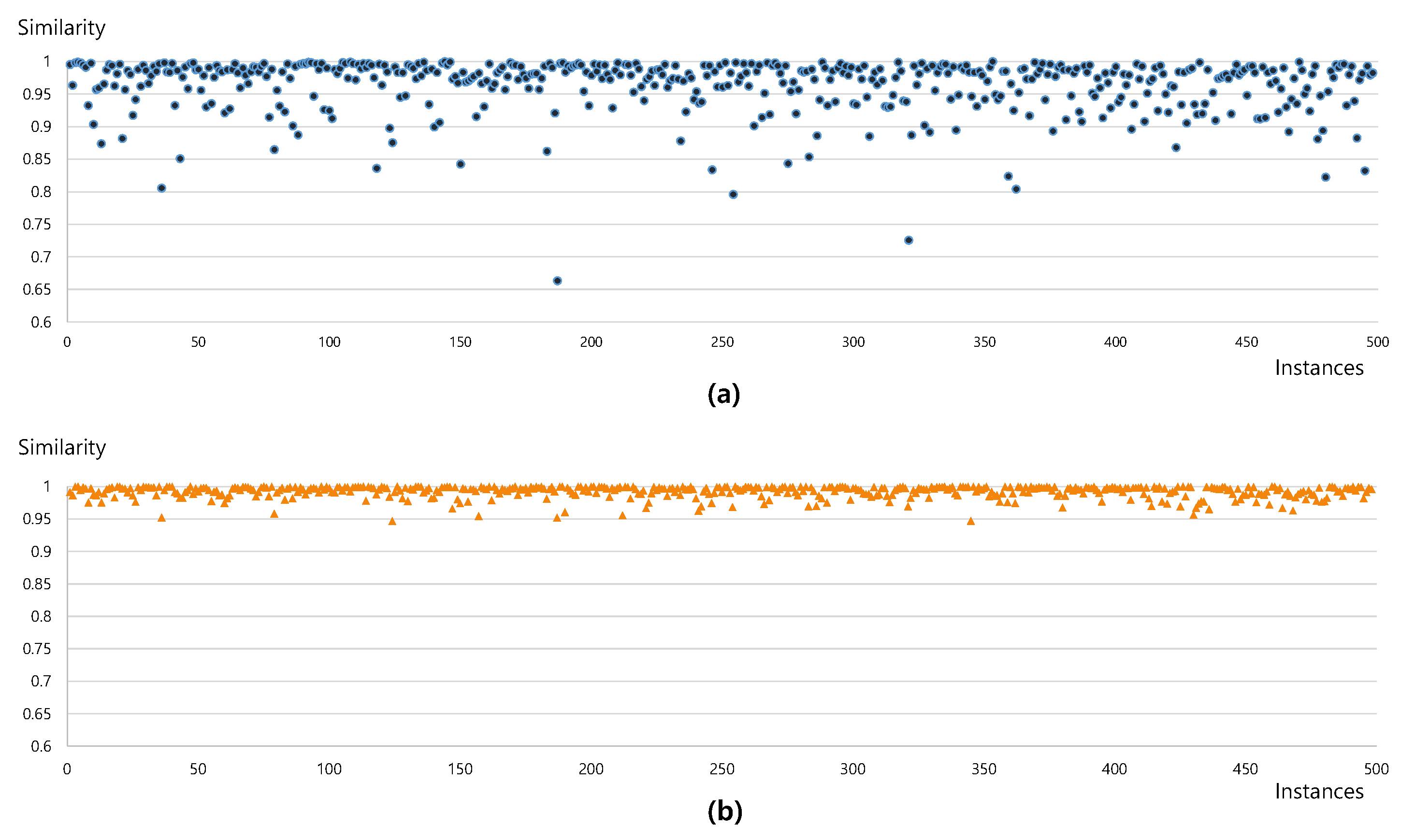
4.2. Recommending Similar Templates Using k-Means Clustering Algorithm
5. Conclusions and Future Research
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| CNL | Controlled Natural Language |
| STK | Standard Technical Korean |
| EM | Expectation-Maximization algorithm |
| DBSCAN | Density-Based Spatial Clustering of Applications with Noise algorithm |
| RESTful API | REpresentational State Transfer Application Programming Interface |
| JSON | JavaScript Object Notation |
| MSE | Mean Squared Error |
References
- Kuhn, T. A survey and classification of controlled natural languages. Comput. Linguist. 2014, 40, 121–170. [Google Scholar] [CrossRef]
- ASD (AeroSpace and Defence Industries, Association of Europe). Simplified Technical English. In Specification ASD-STE100; European community trade mark No. 017966390; European Community: Brussels, Belgium, 2021; 382p. [Google Scholar]
- Congree Language ©. Machine-Aided Author Assistance for Simplified Technical English. Karlsbad, Germany, 2019. Available online: www.congree.com (accessed on 1 July 2022).
- MacKay, D. Chapter 20—An Example Inference Task: Clustering. In Information Theory, Inference and Learning Algorithms; Cambridge University Press: Cambridge, UK, 2003; pp. 284–292. [Google Scholar]
- Pourrajabi, M.; Moulavi, D.; Campello, R.J.G.B.; Zimek, A.; Sander, J.; Goebel, R. Model Selection for Semi-Supervised Clustering. In Proceedings of the 17th International Conference on Extending Database Technology (EDBT), Athens, Greece, 24–28 March 2014; pp. 331–342. [Google Scholar]
- Amorim, R.C.; Hennig, C. Recovering the number of clusters in data sets with noise features using feature rescaling factors. Inf. Sci. 2015, 324, 126–145. [Google Scholar] [CrossRef] [Green Version]
- Goodfellow, I.; Bengio, Y.; Courville, A. Chapter 14. Autoencoders. In Deep Learning; MIT Press: Cambridge, MA, USA, 2016; pp. 499–523. Available online: http://www.deeplearningbook.org (accessed on 1 July 2022).
- European Commission, Directorate-General for Translation. How to Write Clearly. Publications Office, 2011. Available online: https://data.europa.eu/doi/10.2782/29211 (accessed on 15 June 2022).
- Waller, R. What Makes a Good Document? The Criteria We Use; Simplification Centre, University of Reading: Reading, UK, 2011; 35p, Available online: www.simplificationcentre.org.uk (accessed on 1 July 2022).
- Hloch, M.; Kubek, M.; Unger, H. A Survey on Innovative Graph-Based Clustering Algorithms. In The Autonomous Web; Springer: Cham, Switzerland, 2022; Volume 101, pp. 95–110. [Google Scholar]
- Al-jabery, K.K.; Obafemi-Ajayi, T.; Olbricht, G.R.; Wunsch, D.C., II. Clustering algorithms. In Computational Learning Approaches to Data Analytics in Biomedical Applications; Academic Press, Elsevier Inc.: Cambridge, MA, USA, 2020; pp. 29–100. [Google Scholar]
- Balakrishnan, N.; Balas, V.E.; Rajendran, A. Chapter 2—Computational intelligence in healthcare and biosignal processing. In Handbook of Computational Intelligence in Biomedical Engineering and Healthcare; Academic Press, Elsevier Inc.: Cambridge, MA, USA, 2021; pp. 31–64. [Google Scholar]
- Zhang, H.; Li, H.; Chen, N.; Chen, S.; Liu, J. Novel fuzzy clustering algorithm with variable multi-pixel fitting spatial information for image segmentation. Pattern Recognit. 2022, 121, 108201. [Google Scholar] [CrossRef]
- Kumar, S.N.; Ahilan, A.; Fred, A.L.; Kumar, H.A. ROI extraction in CT lung images of COVID-19 using Fast Fuzzy C means clustering. In Biomedical Engineering Tools for Management for Patients with COVID-19; Academic Press, Elsevier Inc.: Cambridge, MA, USA, 2021; pp. 103–119. [Google Scholar] [CrossRef]
- Lei, Y. 4 – Clustering algorithm-based fault diagnosis. In Intelligent Fault Diagnosis and Remaining Useful Life Prediction of Rotating Machinery; Butterworth-Heinemann: Oxford, UK, 2017; pp. 175–229. [Google Scholar]
- Pons-Vives, P.J.; Morro-Ribot, M.; Mulet-Forteza, C.; Valero, O. An Application of Ordered Weighted Averaging Operators to Customer Classification in Hotels. Mathematics 2022, 10, 1987. [Google Scholar] [CrossRef]
- Michis, A.A. Multiscale Partial Correlation Clustering of Stock Market Returns. J. Risk Financ. Manag. 2022, 15, 24. [Google Scholar] [CrossRef]
- Catania, L.J. The science and technologies of artificial intelligence (AI). In Foundations of Artificial Intelligence in Healthcare and Bioscience; Academic Press, Elsevier Inc.: Cambridge, MA, USA, 2021; pp. 29–72. [Google Scholar]
- Dempster, A.P.; Laird, N.M.; Rubin, D.B. Maximum Likelihood from Incomplete Data via the EM Algorithm. J. R. Stat. Soc. 1977, 39, 1–38. [Google Scholar]
- Do, C.; Batzoglou, S. What is the expectation maximization algorithm? Nat. Biotechnol. 2008, 26, 897–899. [Google Scholar] [CrossRef] [PubMed]
- Ester, M.; Kriegel, H.P.; Sander, J.; Xu, X. A density-based algorithm for discovering clusters in large spatial databases with noise. In Proceedings of the Second International Conference on Knowledge Discovery and Data Mining (KDD-96), Portland, OR, USA, 2–4 August 1996; Simoudis, E., Han, J., Fayyad, U.M., Eds.; AAAI Press: Palo Alto, CA, USA, 1996; pp. 226–231. [Google Scholar]
- MacQueen, J. Some methods for classification and analysis of multivariate observations. In Proceedings of the 5th Berkeley Symposium on Mathematical Statistics and Probability, University of California, Berkeley, CA, USA, 1 January 1967; Volume 1, pp. 281–297. [Google Scholar]
- Franti, P.; Sieranoja, S. K-means properties on six clustering benchmark datasets. Appl. Intell. 2018, 48, 4743–4759. [Google Scholar] [CrossRef]
- Javed, A.; Lee, B.S.; Rizzo, D.M. A benchmark study on time series clustering. Mach. Learn. Appl. 2020, 1, 100001. [Google Scholar] [CrossRef]
- Sheng, X.; Zhang, Q.; Gao, R.; Guo, D.; Jing, Z.; Xin, X. K-means Cluster Algorithm Applied for Geometric Shaping Based on Iterative Polar Modulation in Inter-Data Centers Optical Interconnection. Electronics 2021, 10, 2417. [Google Scholar] [CrossRef]
- Semantic Web Research Center. Korean Morphological Analyzer: Hannanum. KAIST, Republic of Korea. 2016. Available online: http://swrc.kaist.ac.kr/hannanum/ (accessed on 1 July 2022).
- Witten, I.; Frank, E.; Hall, M.; Pal, C. Appendix B—The WEKA Workbench. In Data Mining: Practical Machine Learning Tools and Techniques, 4th ed.; Morgan Kaufmann Publishers: Burlington, MA, USA, 2017; pp. 553–571. [Google Scholar]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine Learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Gupta, V.; Sachdeva, S.; Dohare, N. Chapter 8—Deep similarity learning for disease prediction. In Hybrid Computational Intelligence for Pattern Analysis, Trends in Deep Learning Methodologies; Academic Press, Elsevier Inc.: Cambridge, MA, USA, 2021; pp. 183–206. [Google Scholar]








Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Noh, S.; Chung, K.; Shim, J. Validating Syntactic Correctness Using Unsupervised Clustering Algorithms. Electronics 2022, 11, 2113. https://doi.org/10.3390/electronics11142113
Noh S, Chung K, Shim J. Validating Syntactic Correctness Using Unsupervised Clustering Algorithms. Electronics. 2022; 11(14):2113. https://doi.org/10.3390/electronics11142113
Chicago/Turabian StyleNoh, Sanguk, Kihyun Chung, and Jaebock Shim. 2022. "Validating Syntactic Correctness Using Unsupervised Clustering Algorithms" Electronics 11, no. 14: 2113. https://doi.org/10.3390/electronics11142113