Signals Recognition by CNN Based on Attention Mechanism


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
2. System Models and Scenatios
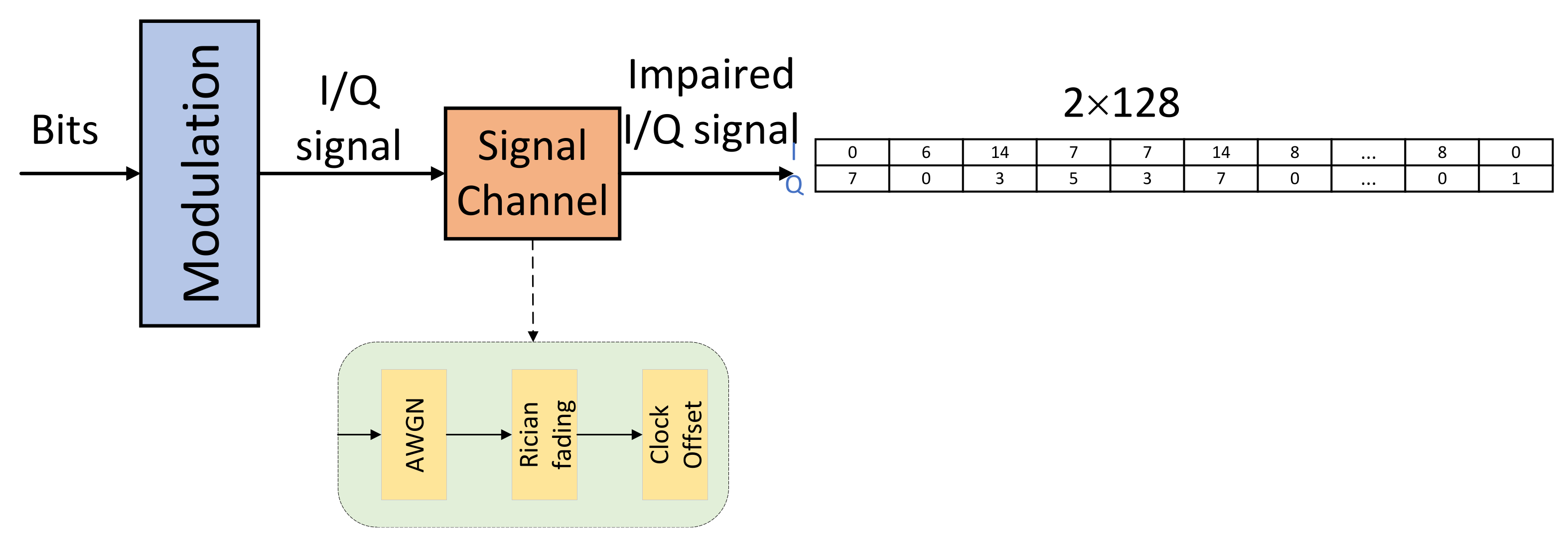
2.1. Signal Model
2.2. Network Model
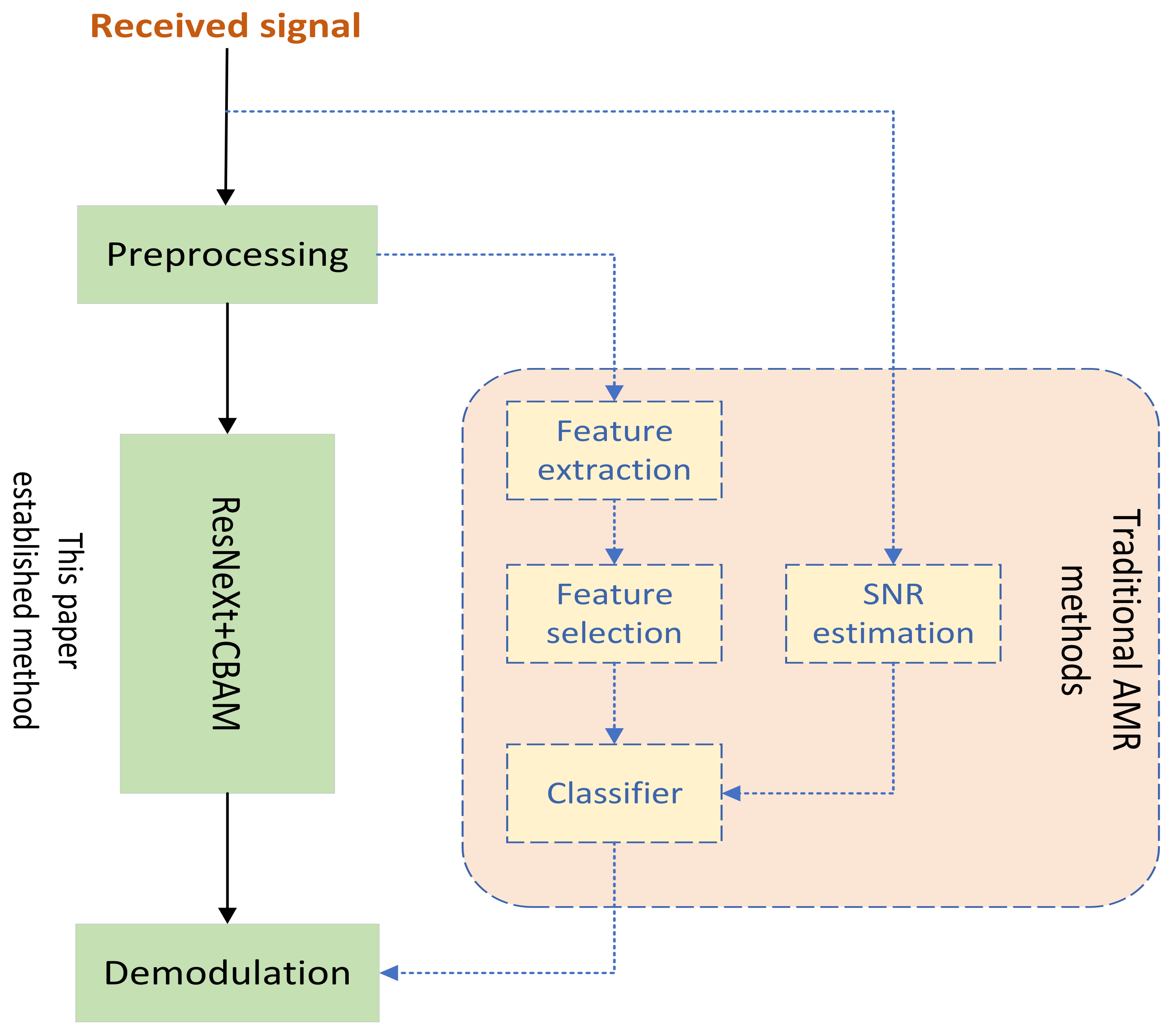
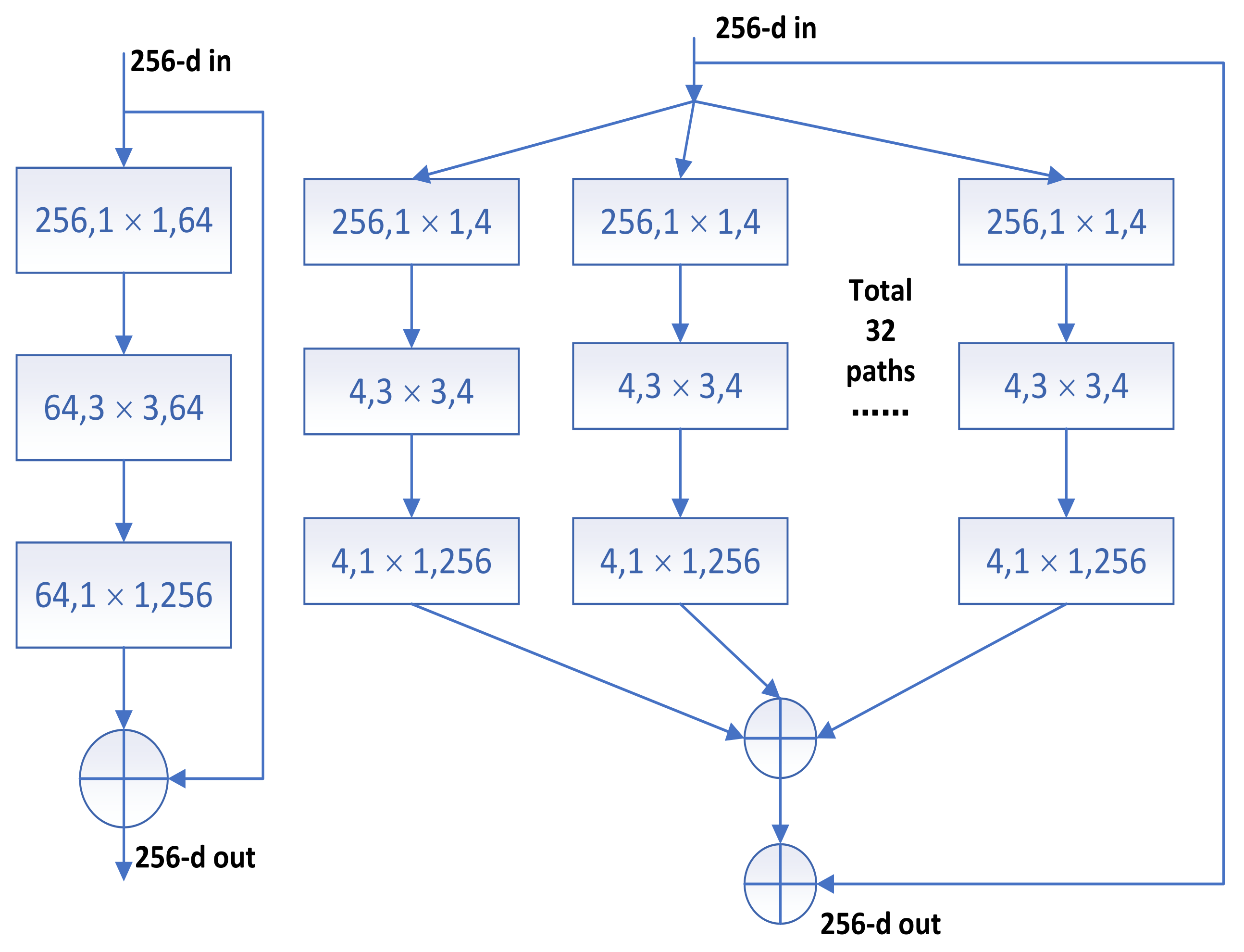
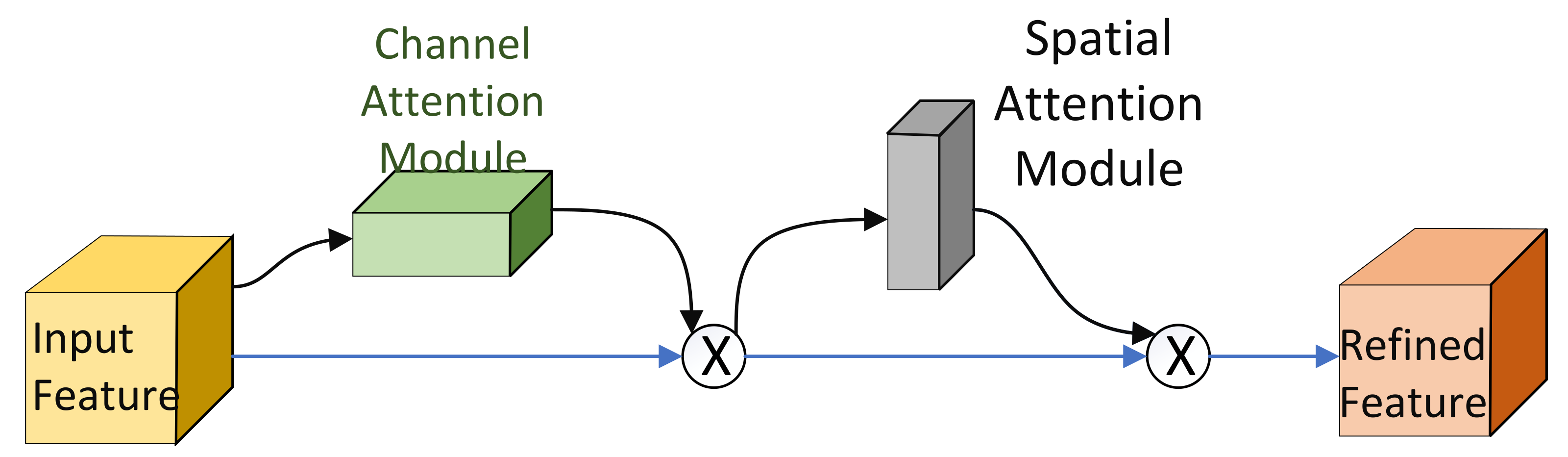
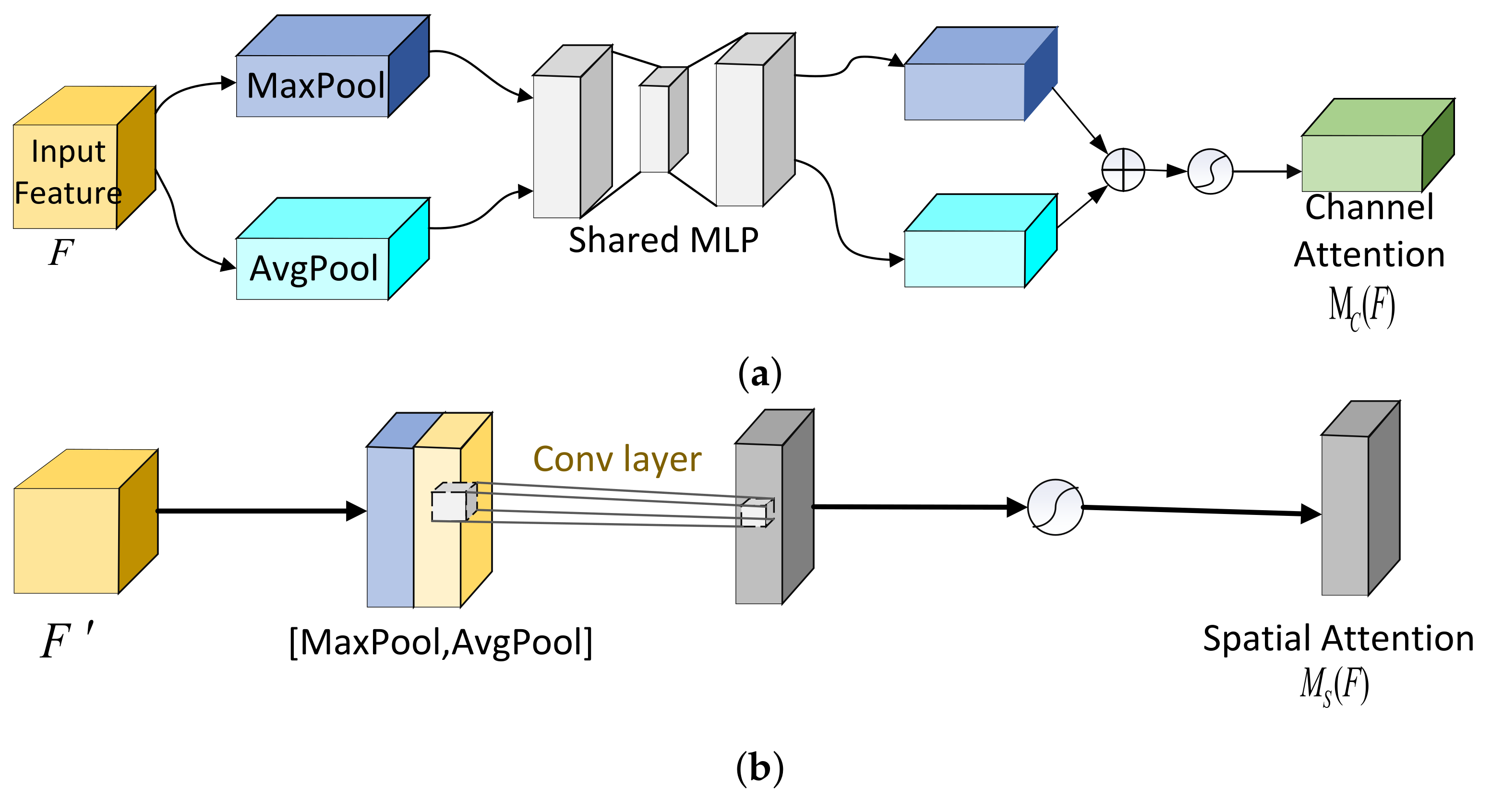
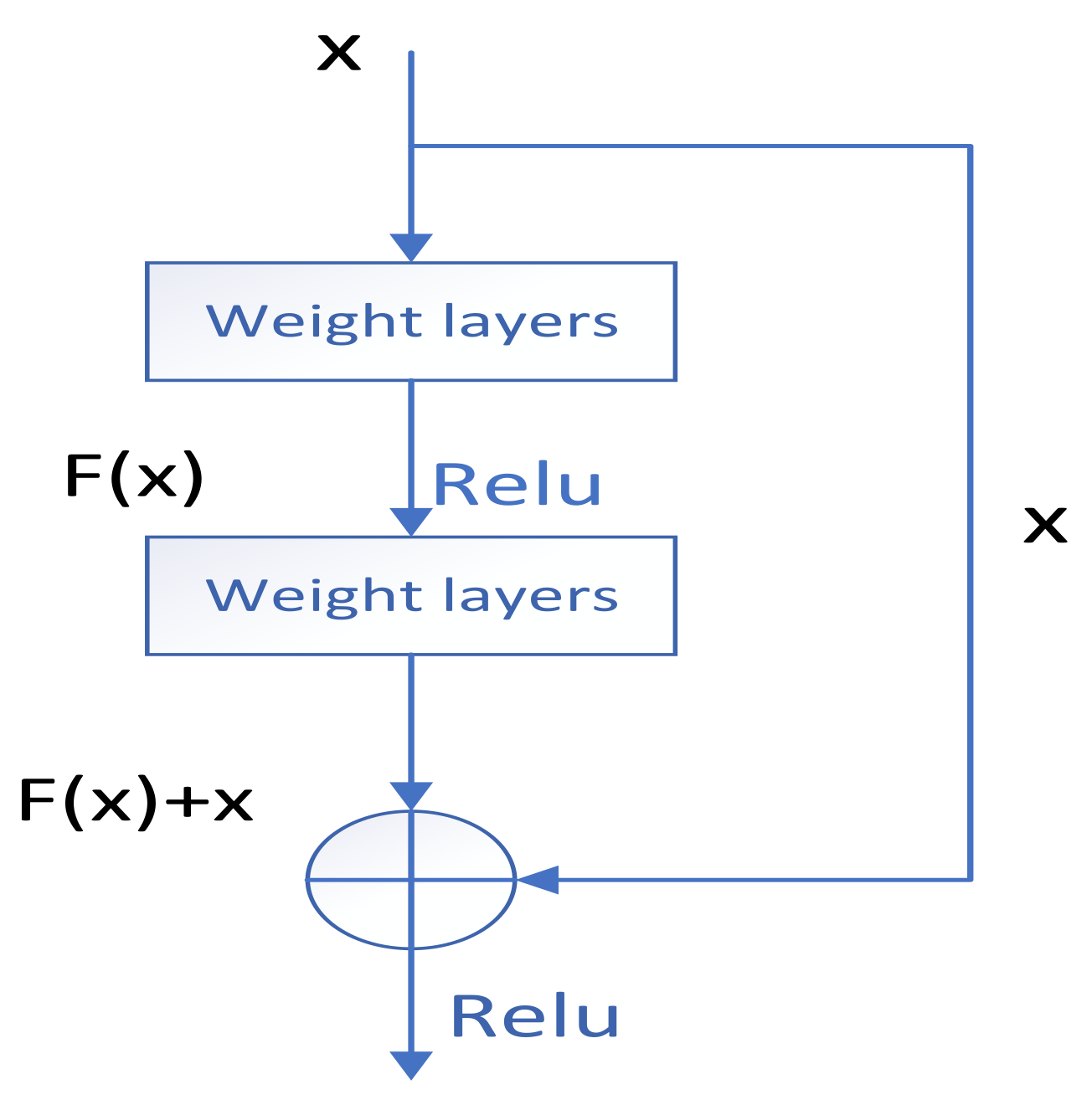
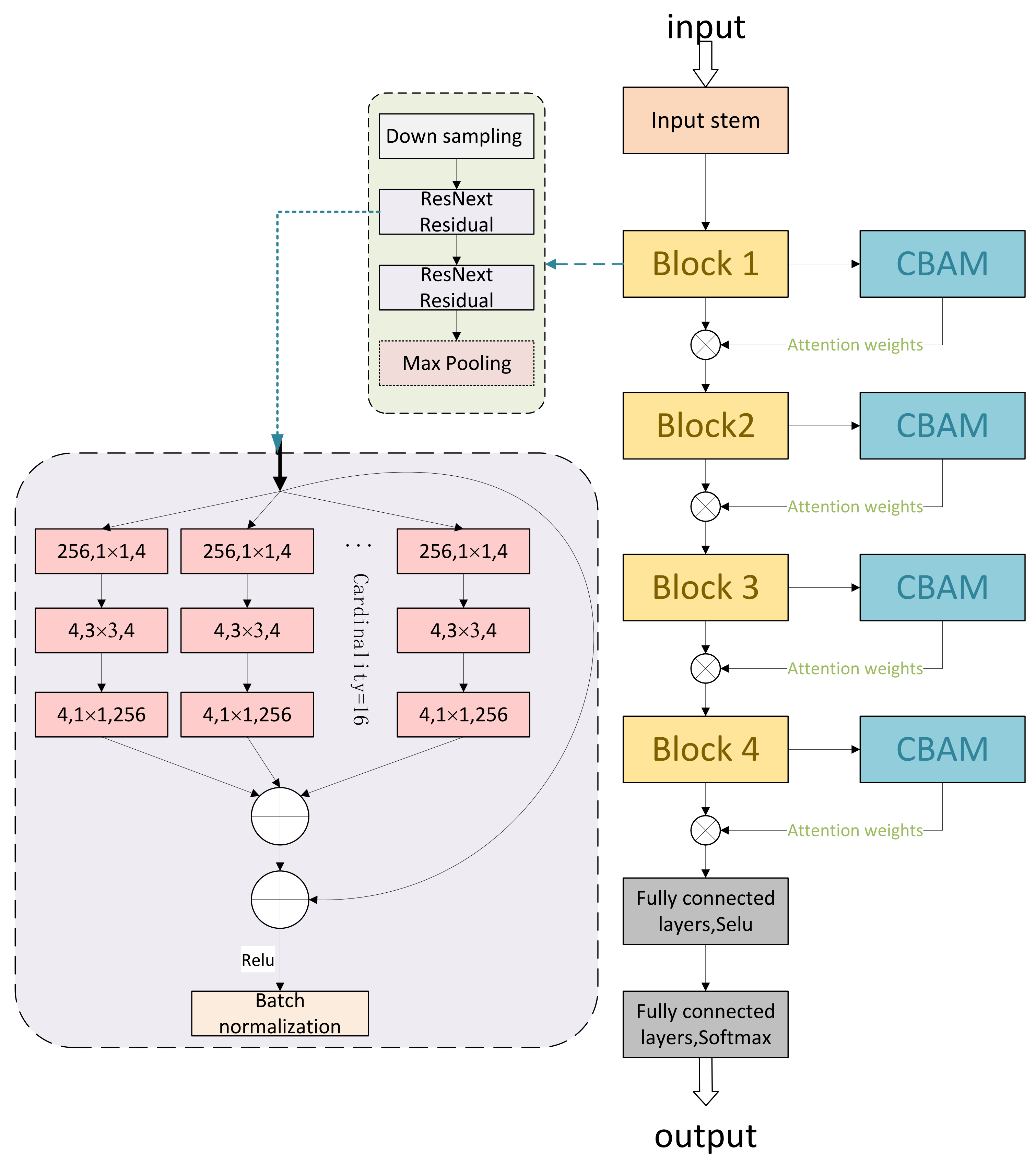
2.3. CNN Signal Recognition Model Based on Attention Mechanism
3. Experiment and Analysis
3.1. Dataset
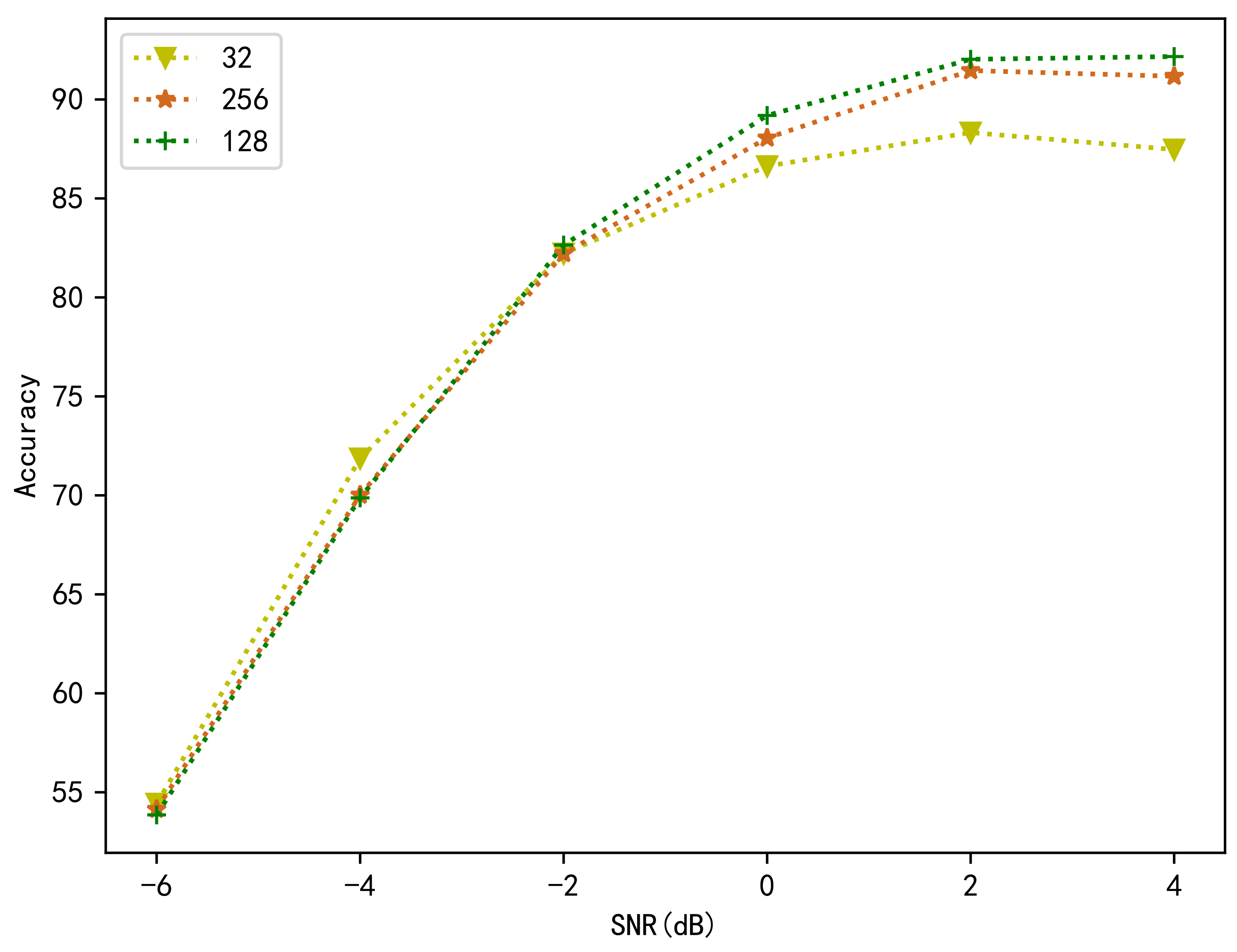
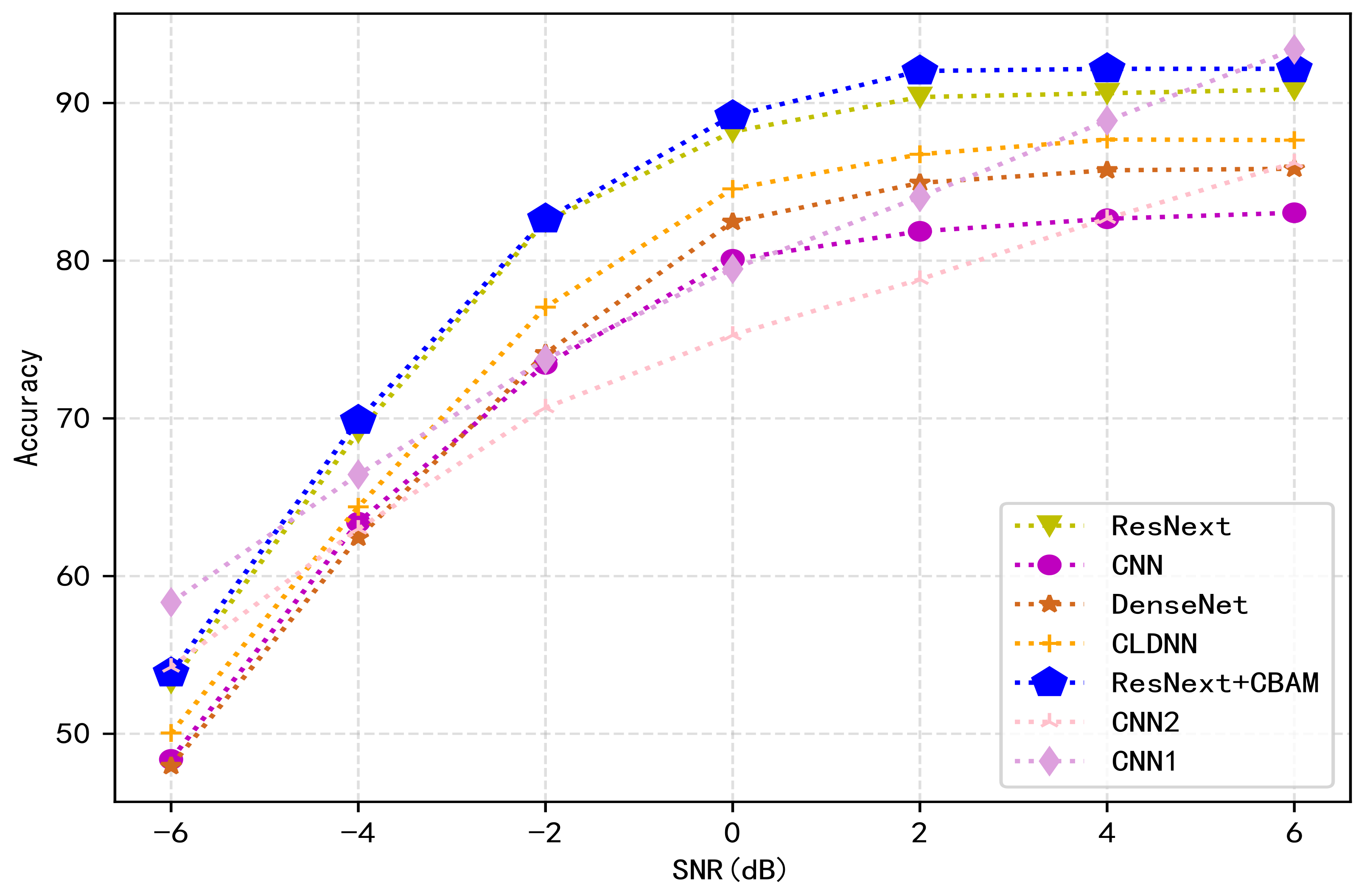
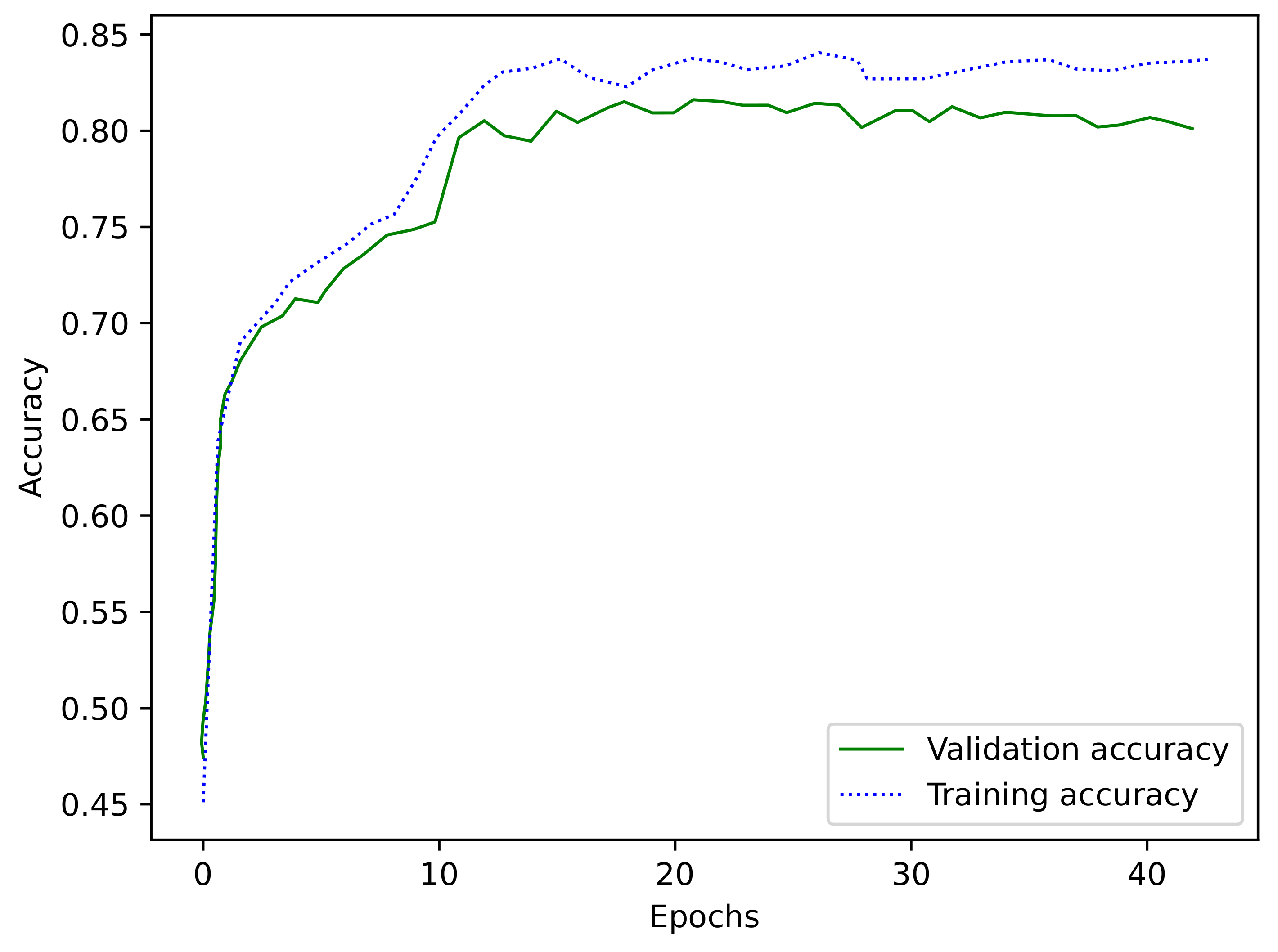
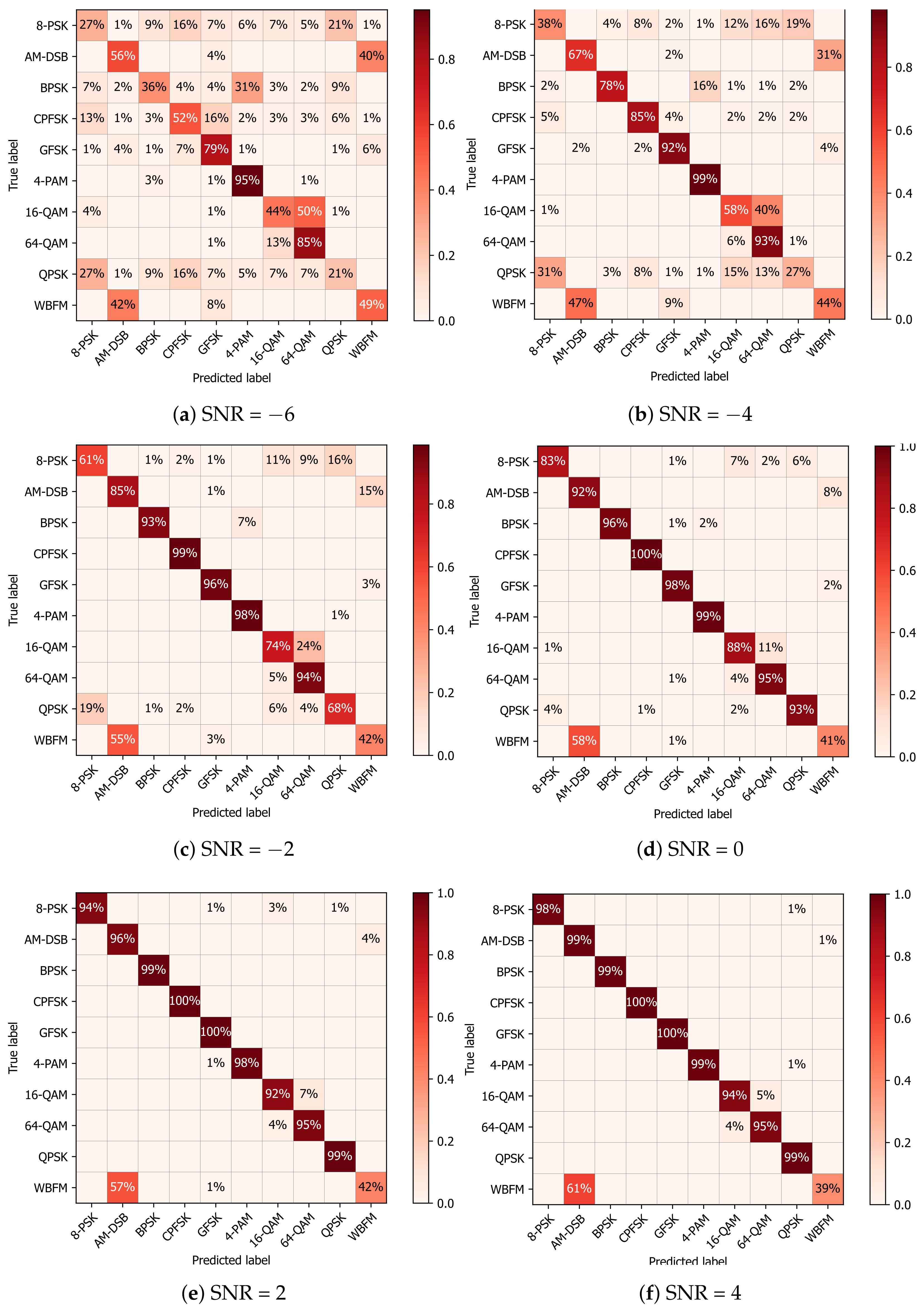
3.2. Performance Comparison Analysis
3.3. Analysis of Results
4. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Zhu, Z.; Nandi, A.K. Automatic Modulation Classification (Principles, Algorithms and Applications); John Wiley & Sons: Hoboken, NJ, USA, 2014. [Google Scholar] [CrossRef]
- Dobre, O.A.; Abdi, A.; Bar-Ness, Y.; Su, W. Survey of automatic modulation classification techniques: Classical approaches and new trends. IET Commun. 2007, 1, 137–156. [Google Scholar] [CrossRef] [Green Version]
- Huang, S.; Yao, Y.; Wei, Z.; Zhang, P. Automatic Modulation Classification of Overlapped Sources Using Multiple Cumulants. IEEE Trans. Veh. Technol. 2017, 66, 6089–6101. [Google Scholar] [CrossRef]
- Tian, J.; Pei, Y.; Huang, Y.D.; Liang, Y.C. Modulation-Constrained Clustering Approach to Blind Modulation Classification for MIMO Systems. IEEE Trans. Cogn. Commun. Netw. 2018, 4, 894–907. [Google Scholar] [CrossRef]
- Polydoros, A.; Kim, K. On the Detection and Classification of Quadrature Digital Modulations in Broad-Band Noise. IEEE Trans. Commun. 1990, 38, 1199–1211. [Google Scholar] [CrossRef]
- Beidas, B.F.; Weber, C.L. Asynchronous classification of MFSK signals using the higher order correlation domain. IEEE Trans. Commun. 1998, 46, 480–493. [Google Scholar] [CrossRef]
- Prokopios, P. Likelihood ratio tests for modulation classification. In Proceedings of the MILCOM 2000 Proceedings, 21st Century Military Communications, Architectures and Technologies for Information Superiority (Cat. No.00CH37155), Los Angeles, CA, USA, 22–25 October 2000. [Google Scholar]
- Wen, W.; Mendel, J.M. Maximum-likelihood classification for digital amplitude-phase modulations. IEEE Trans. Commun. 2000, 48, 189–193. [Google Scholar] [CrossRef]
- Majhi, S.; Gupta, R.; Xiang, W.; Glisic, S. Hierarchical Hypothesis and Feature based Blind Modulation Classification for Linearly Modulated Signals. IEEE Trans. Veh. Technol. 2017, 66, 11057–11069. [Google Scholar] [CrossRef] [Green Version]
- Swami, A.; Sadler, B.M. Hierarchical digital modulation classification using cumulants. IEEE Trans. Commun. 2000, 48, 416–429. [Google Scholar] [CrossRef]
- Soliman, S.S.; Hsue, S.Z. Signal Classification Using Statistical Moments. IEEE Trans. Commun. 1992, 40, 908–916. [Google Scholar] [CrossRef]
- Mobasseri, B.G. Digital modulation classification using constellation shape. Signal Process. 2000, 80, 251–277. [Google Scholar] [CrossRef]
- Grimaldi, D.; Rapuano, S.; De Vito, L. An Automatic Digital Modulation Classifier for Measurement on Telecommunication Networks. IEEE Trans. Instrum. Meas. 2007, 56, 1711–1720. [Google Scholar] [CrossRef]
- Lecun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436. [Google Scholar] [CrossRef] [PubMed]
- Fenn, P. The Deep Learning Revolution; Sejnowski, T.J., Ed.; The MIT Press: Cambridge, MA, USA, 2018; Volume 352, p. 24. ISBN 978-0-262-03803-4. [Google Scholar]
- Liu, W.; Wang, Z.; Liu, X.; Zeng, N.; Liu, Y.; Alsaadi, F.E. A survey of deep neural network architectures and their applications. Neurocomputing 2017, 234, 11–26. [Google Scholar] [CrossRef]
- Hinton, G.; Deng, L.; Yu, D.; Dahl, G.E.; Mohamed, A.R.; Jaitly, N.; Senior, A.; Vanhoucke, V.; Nguyen, P.; Sainath, T.N.; et al. Deep Neural Networks for Acoustic Modeling in Speech Recognition: The Shared Views of Four Research Groups. IEEE Signal Process. Mag. 2012, 29, 82–97. [Google Scholar] [CrossRef]
- Le, L.; Zheng, Y.; Carneiro, G. Deep Learning and Convolutional Neural Networks for Medical Image Computing; Springer: Cham, Switzerland, 2017. [Google Scholar]
- Al-Ayyoub, M.; Nuseir, A.; Alsmearat, K.; Jararweh, Y.; Gupta, B. Deep learning for Arabic NLP: A survey. J. Comput. Sci. 2017, 26, 522–531. [Google Scholar] [CrossRef]
- OâShea, T.; Hoydis, J. An Introduction to Deep Learning for the Physical Layer. IEEE Trans. Cogn. Commun. Netw. 2017, 3, 563–575. [Google Scholar] [CrossRef] [Green Version]
- O’Shea, T.J.; Corgan, J.; Clancy, T.C. Convolutional Radio Modulation Recognition Networks. In Proceedings of the International Conference on Engineering Applications of Neural Networks, Aberdeen, UK, 2–5 September 2016. [Google Scholar]
- Huang, G.; Liu, Z.; Laurens, V.; Weinberger, K.Q. Densely Connected Convolutional Networks. IEEE Comput. Soc. 2016. [Google Scholar] [CrossRef]
- Sainath, T.N.; Vinyals, O.; Senior, A.; Sak, H. Convolutional, Long Short-Term Memory, fully connected Deep Neural Networks. In Proceedings of the ICASSP 2015â2015 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), South Brisbane, QLD, Australia, 19–24 April 2015. [Google Scholar]
- Zheng, S.; Qi, P.; Chen, S.; Yang, X. Fusion Methods for CNN-Based Automatic Modulation Classification. IEEE Access 2019, 7, 66496–66504. [Google Scholar] [CrossRef]











Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tian, F.; Wang, L.; Xia, M. Signals Recognition by CNN Based on Attention Mechanism. Electronics 2022, 11, 2100. https://doi.org/10.3390/electronics11132100
Tian F, Wang L, Xia M. Signals Recognition by CNN Based on Attention Mechanism. Electronics. 2022; 11(13):2100. https://doi.org/10.3390/electronics11132100
Chicago/Turabian StyleTian, Feng, Li Wang, and Meng Xia. 2022. "Signals Recognition by CNN Based on Attention Mechanism" Electronics 11, no. 13: 2100. https://doi.org/10.3390/electronics11132100