1. Introduction
The incidence of brain tumors is increasing in recent years [
1]. As well, the median survival time of glioblastoma with the highest malignancy is only 14.6 months [
2]. Brain tumor segmentation (BTS) technology is an essential basic step with many applications such as quantitative analysis and operational planning. However, the manual segmentation of brain tumors is difficult and time-consuming [
3]. Accurate and automatic BTS technology is urgently needed to minimize human errors.
Automatic BTS methods can roundly fall into three categories [
4], namely, atlas registration-based methods [
5,
6], machine learning-based methods with hand-crafted features [
7,
8,
9], and deep learning-based methods with automatic end-to-end learned features [
10,
11,
12]. Compared with the former two categories of methods which need prior knowledge or complex hand-crafted features, the third category of methods can directly learn knowledge from the given data and usually obtains better segmentation performance. Thus, the methods based on deep learning have become the research hotspot in the field of BTS.
In recent years, deep learning-based methods have greatly promoted the development of various fields of image analysis. Researchers are actively innovating network structures and data application methods to improve the performance of BTS methods by using deep learning. Some methods directly use the structure of UNet [
11] for tasks such as feature extraction or classification [
13,
14]. Other methods [
15,
16,
17] inspired by UNet optimize and improve the structure of UNet, such as changing the number of skip concatenations and the way of concatenation. The basic structure of the aforementioned models is a convolution kernel, which has a fixed size and is used to extract local features, thus helping the models learn detailed knowledge such as the contour and texture of the target, which is important for segmentation tasks, including BTS. In addition, their global features are often different due to different sizes, locations, and nature of brain tumors, even if the local features of brain images are similar. Therefore, global features are highly significant for the BTS task. Although repeating local operations can extract global features, the operation has several limitations, such as causing optimization difficulties and making multi-hop dependency modeling difficult. Adopting attention mechanisms is another popular way to extract global features, which has given significant boosts to various fields of vision. Thus, we applied an attention mechanism to extract global features in this study.
Wang et al. [
18] introduced a nonlocal operation, computing the response at a position as a weighted sum of the features at all positions, which was similar to the method [
19] called Transformer based on self-attention. An increasing number of studies [
20,
21] adopted Transformer architecture in convolutional neural networks (CNNs) to extract global features and fuse local features and global features to improve the performance of BTS. The self-attention was restricted to a small local area due to the high computation and large memory consumption of the Transformer, which limited the learning ability of the models using the Transformer in many cases. Recently, many efforts have been made to address this problem. Ho et al. [
22] proposed the axial attention module (AAM) composing 2D self-attention into two 1D self-attentions to reduce the computation from
to
, where
H and
W represent the height and width of the input, respectively. Inspired by deformable convolution, Zhu et al. [
23] introduced the deformable attention module (DAM), only focusing on a small set of key sampling points around a reference, and reduced the computation to
. Liu et al. [
24] proposed the Swin Transformer, which calculated self-attention in non-overlapping local windows to reduce the memory consumption and improve computational efficiency. The UTNet model built by Gao et al. [
25] projected key and value into low-dimensional features, which reduced the computation of traditional Transformer. Applying the modules improved based on Transformer, similar to the aforementioned modules to improve the performance of BTS and reduce the computation complexity, is useful and popular. Cao et al. [
26] proposed Swin-Unet, which was a UNet-like pure Transformer for medical image segmentation. Valanarasu et al. [
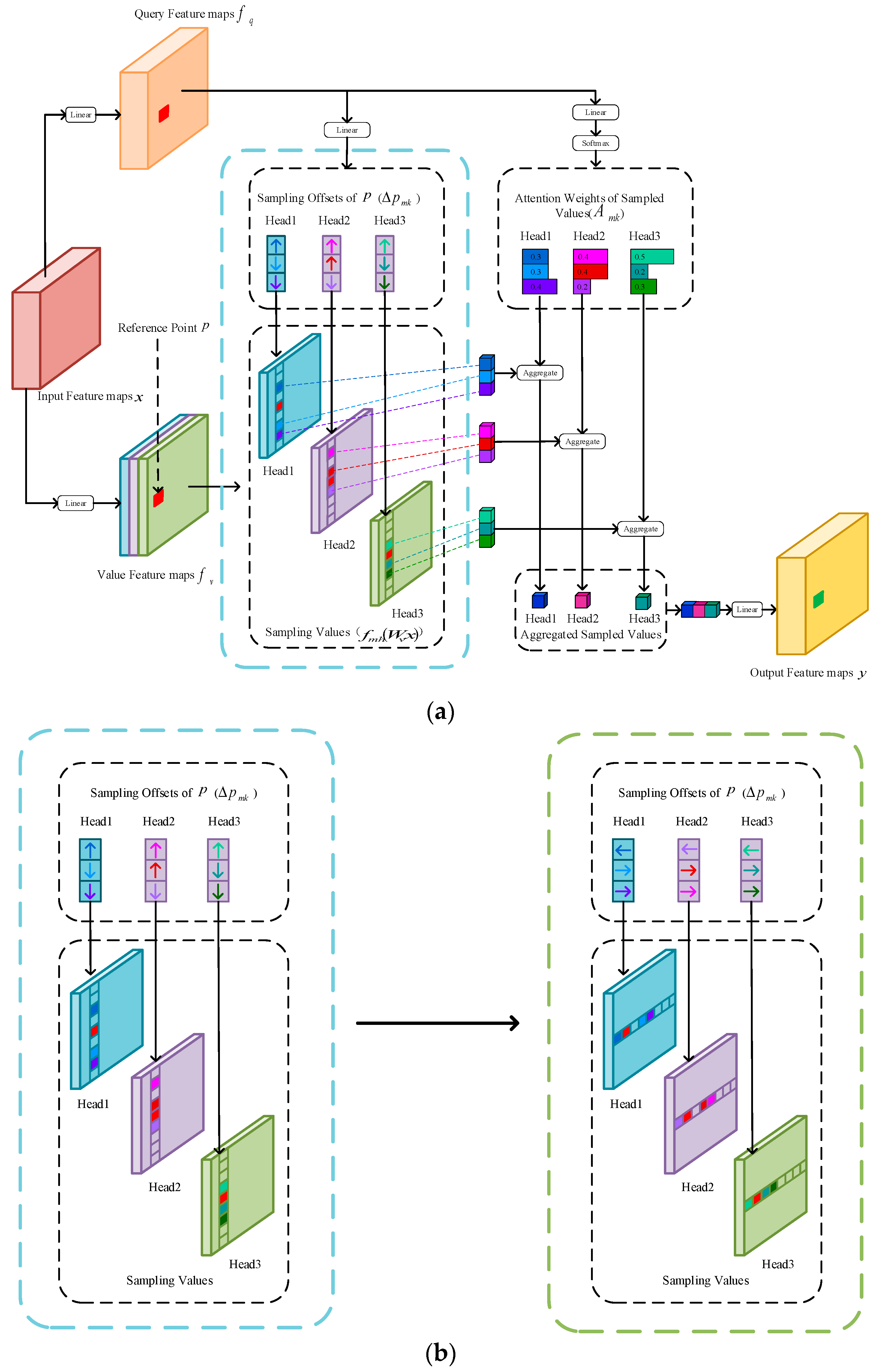
27] introduced a gated AAM adding a control mechanism in the self-attention module to segment medical images including brain images. Inspired by AAM and DAM, we assumed that selecting a small set of key sampling points on a certain axis of the feature map than selecting all points of the certain axis to compute the response at a position might be beneficial to use effective information and discard useless information. Meanwhile, finding relevant positions on a certain axis was easier to obtain the optimal solution than looking for relevant locations on the entire feature map. Thus, we proposed the axial-deformable attention (ADA) module, which sampled a small set of key points in a certain column or a certain row to extract global features, instead of using all points in a column or row like AAM or using points in all regions like DAM. Compared with other self-attention modules, the ADA module had lower computational complexity and more accurate performance.
However, many researchers employed convolution operations and self-attention mechanisms to fuse local and global features while ignoring multi-scale features that could effectively improve the robustness of the model [
28,
29], which were also essential for BTS. Therefore, we proposed a new network that fused local feature information extracted by convolution operations, global feature information extracted by ADA module, and multi-scale feature information obtained by multi-scale input (MSI) and multi-scale output (MSO) structures to enhance the robustness of the network, effectively improving the performance of BTS task.
This study introduced a novel U-shaped network fusing local features, global features, and multi-scale features (LGMSU-Net) to segment brain tumors. The main contributions of this study were as follows:
- (1)
A new encoder-decoder network was proposed, which reasonably and effectively fused local features representing detailed information, global features representing global information, and multi-scale features enhancing the robustness of the network to significantly improve the performance of BTS with low computational complexity.
- (2)
A novel self-attention module was designed to extract global features, named the ADA module. It sampled a small set of key points in a certain column or a certain row, which could achieve a more accurate performance of BTS with acceptable computation complexity.
- (3)
Positional embeddings were proved in self-attention mechanism could accelerate convergence during training and slightly improve the BTS performance.
- (4)
Extensive experiments had proved that the proposed network achieved excellent performance in the task of BTS, which meant that it would help clinicians to reduce the time spent in BTS tasks and improve the segmentation accuracy. Moreover, it also could be used as an auxiliary tool to provide suggestions on BTS tasks to help junior doctors improve their skills as soon as possible.
We introduce the LGMSU-Net architecture in
Section 2. The experimental results of ablation experiments and contrast experiments are presented and discussed in
Section 3. Finally, we conclude the work in
Section 4.
4. Conclusions and Future Work
Since brain tumors were currently one of the most lethal diseases and different brain tumors may have the same or different shapes, textures, locations, or contours. Therefore, BTS was a task with low fault tolerance and high difficulty. In this paper, we proposed an accurate brain tumor automatic segmentation model that fused multiple feature information. The model we designed had the following advantages.
- (1)
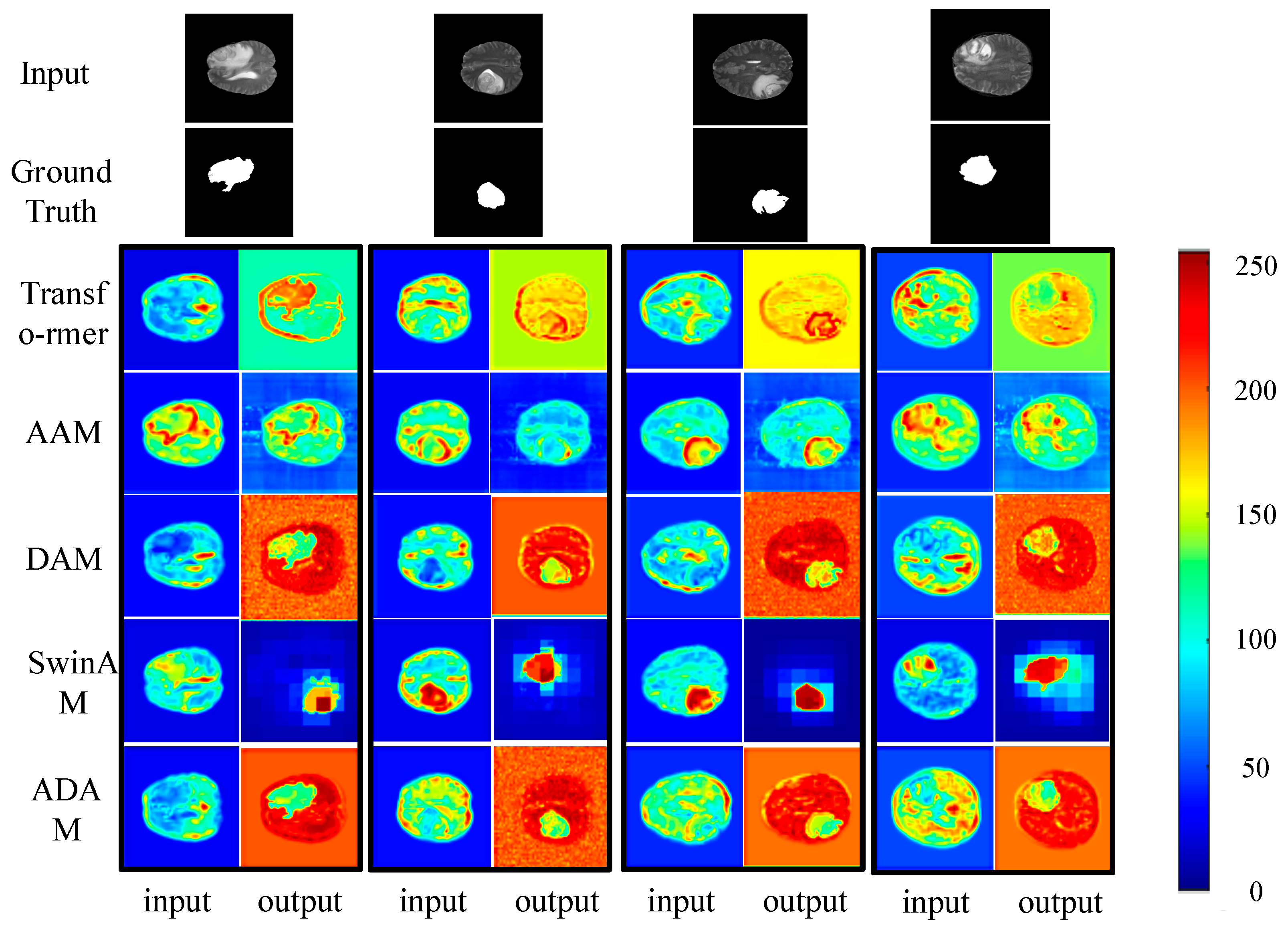
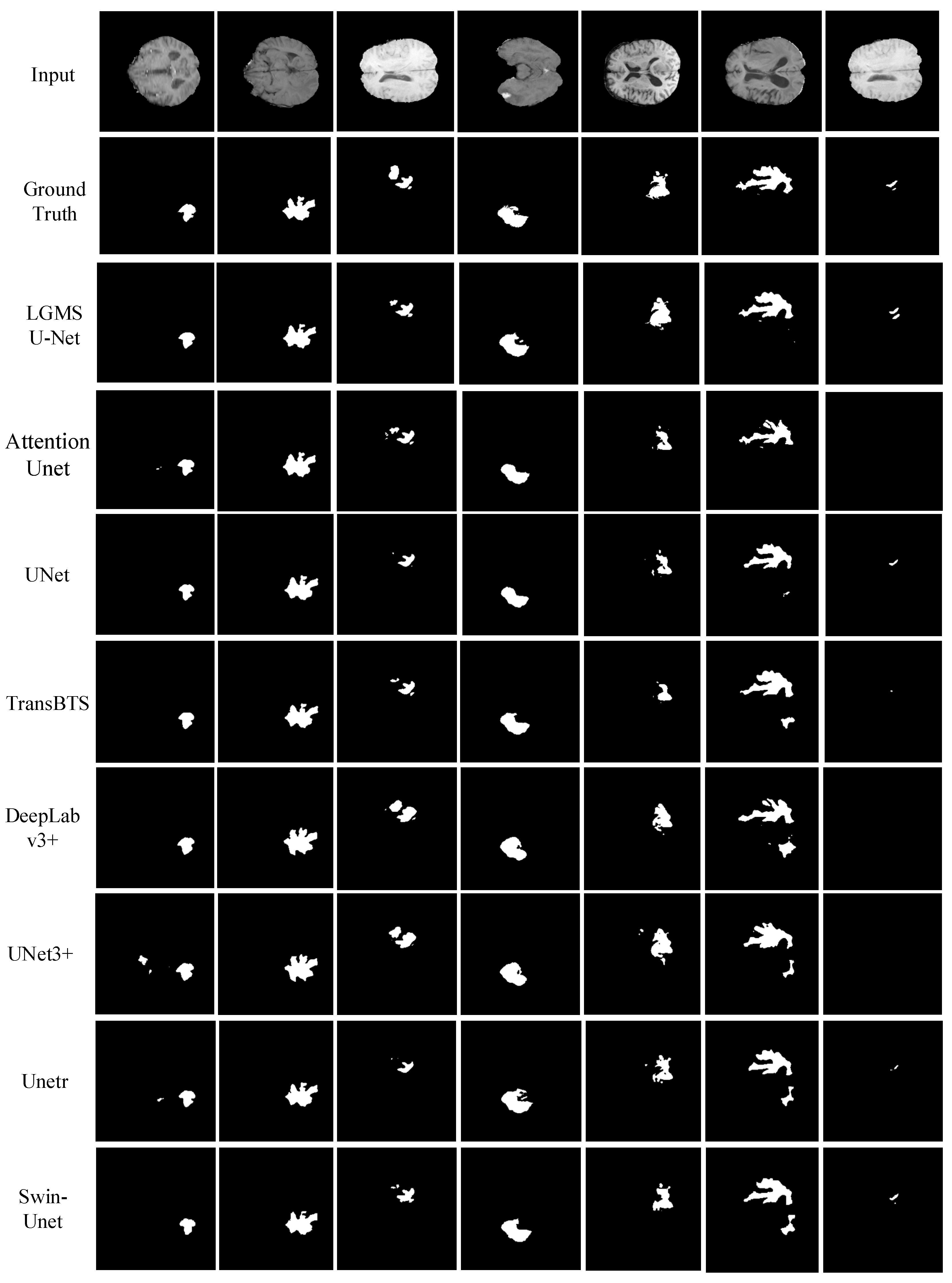
Our network extracted local detailed feature information through convolution operation, multi-scale feature information to enhance the robustness of the network through MSI and MSO, and global feature information through our proposed ADA module, and reasonably fused these features to segment brain tumors automatically and accurately on the Brats2018 dataset, which was superior to the seven state-of-the-art methods, as shown in
Table 4 and
Figure 5. Furthermore, our model was found to be the best robust among eight advanced BTS models by studying the effect of noise on model performance, as shown in
Table 5.
- (2)
The ADA module we proposed was a novel and useful self-attention module for the BTS task. It sampled a small set of key points in a certain column or a certain row, which could achieve a more accurate performance of BTS with acceptable computation complexity, as shown in
Table 3 and
Figure 4.
- (3)
Positional embeddings were proved in self-attention mechanism could accelerate convergence during training and slightly improve the BTS performance, as shown in
Table 2 and
Figure 3.
- (4)
Extensive experiments had proved that the proposed network achieved excellent performance on the task of BTS, which meant that it would help clinicians to reduce the time spent in BTS tasks and improve the segmentation accuracy. Moreover, it also could be used as an auxiliary tool to provide suggestions on BTS tasks to help junior clinicians improve their skills as soon as possible.
In future work, we plan to design a 3D BTS model with a small number of parameters and memory footprint. In addition, finding ways to let the model learn the appropriate
M and
values automatically to further improve the performance and usability of the model is also important. Moreover, inspired by [
39], we will explore the image fusion algorithm to achieve a more accurate segmentation of brain tumors. Last but not least, we still need to further explore the practicality of our proposed method in clinical research.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}