
A Multi-Lingual Speech Recognition-Based Framework to Human-Drone Interaction

 ,
,
Abstract
:1. Introduction
- Faster and more efficient voice control recognition. Other interfaces, such as gesture control, delay the system, thereby limiting its utility.
- Multilingual ASR system (English, Arabic, and Amazigh) that enables a broad spectrum of users to interact with the UAV with simplicity.
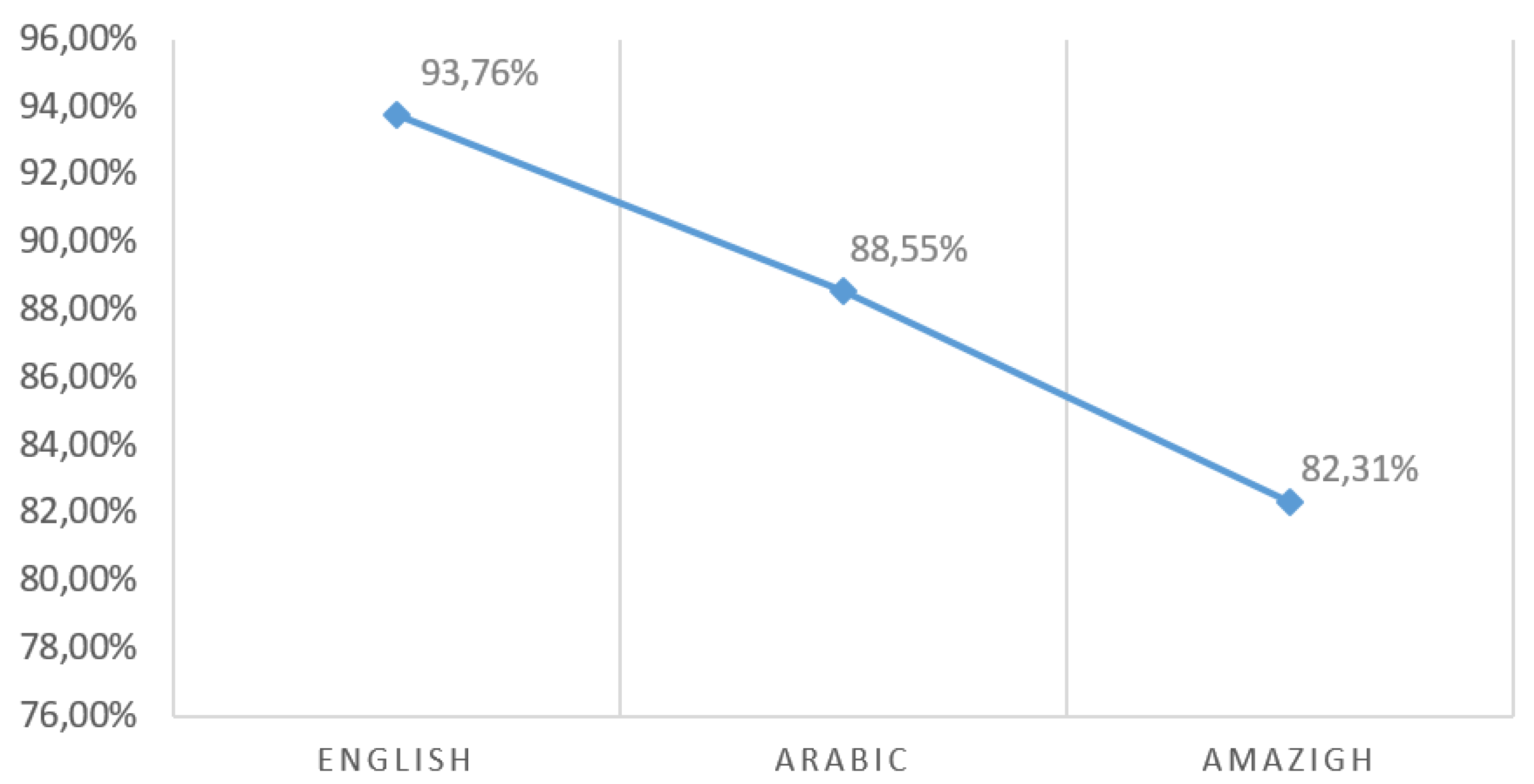
- Voice recognition with high accuracy of over 93% using deep learning.
- Quadrotor UAV hardware implementation and real-time testing of the designed system.
- Graphical user interface to reduce the user’s workload, simplifying the command and interaction with the UAV, and decreasing the impact of background noise on speech recognition.
2. Related Works
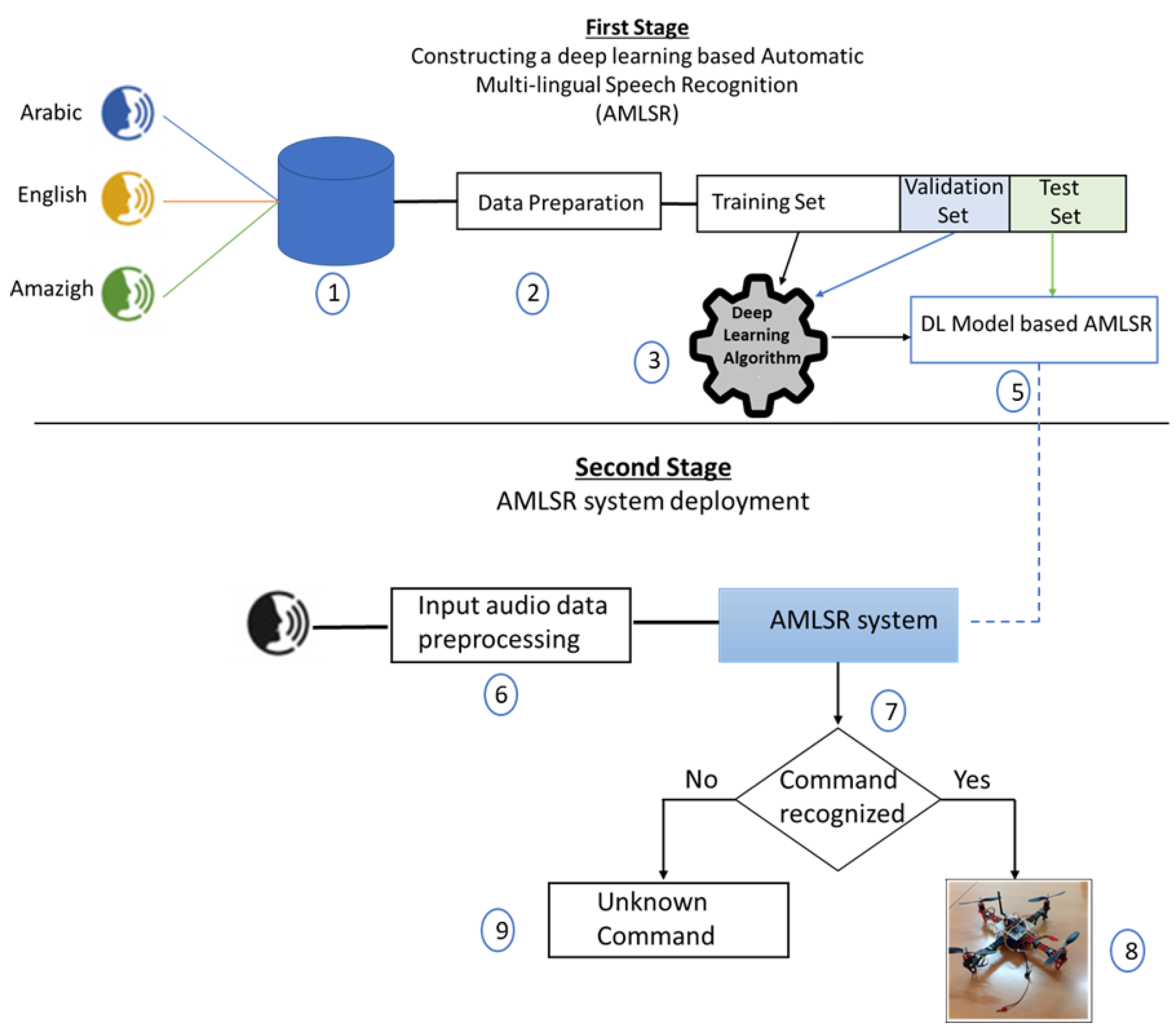
3. Proposed Framework
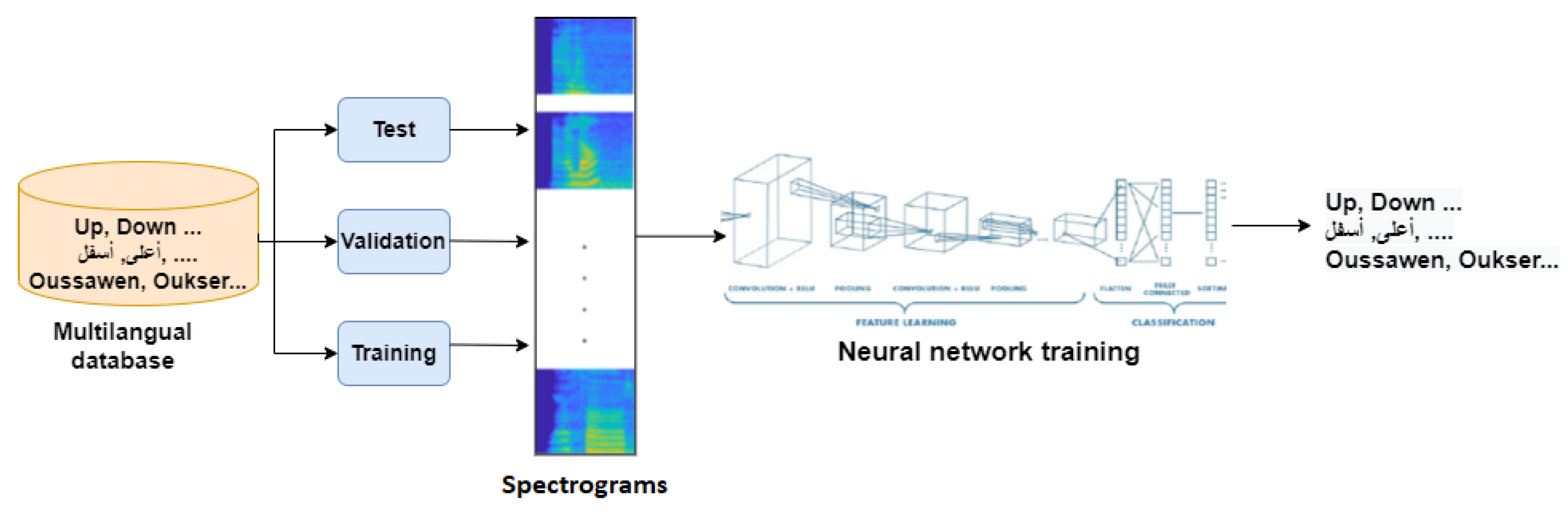
3.1. First Stage: AMLSR System Design
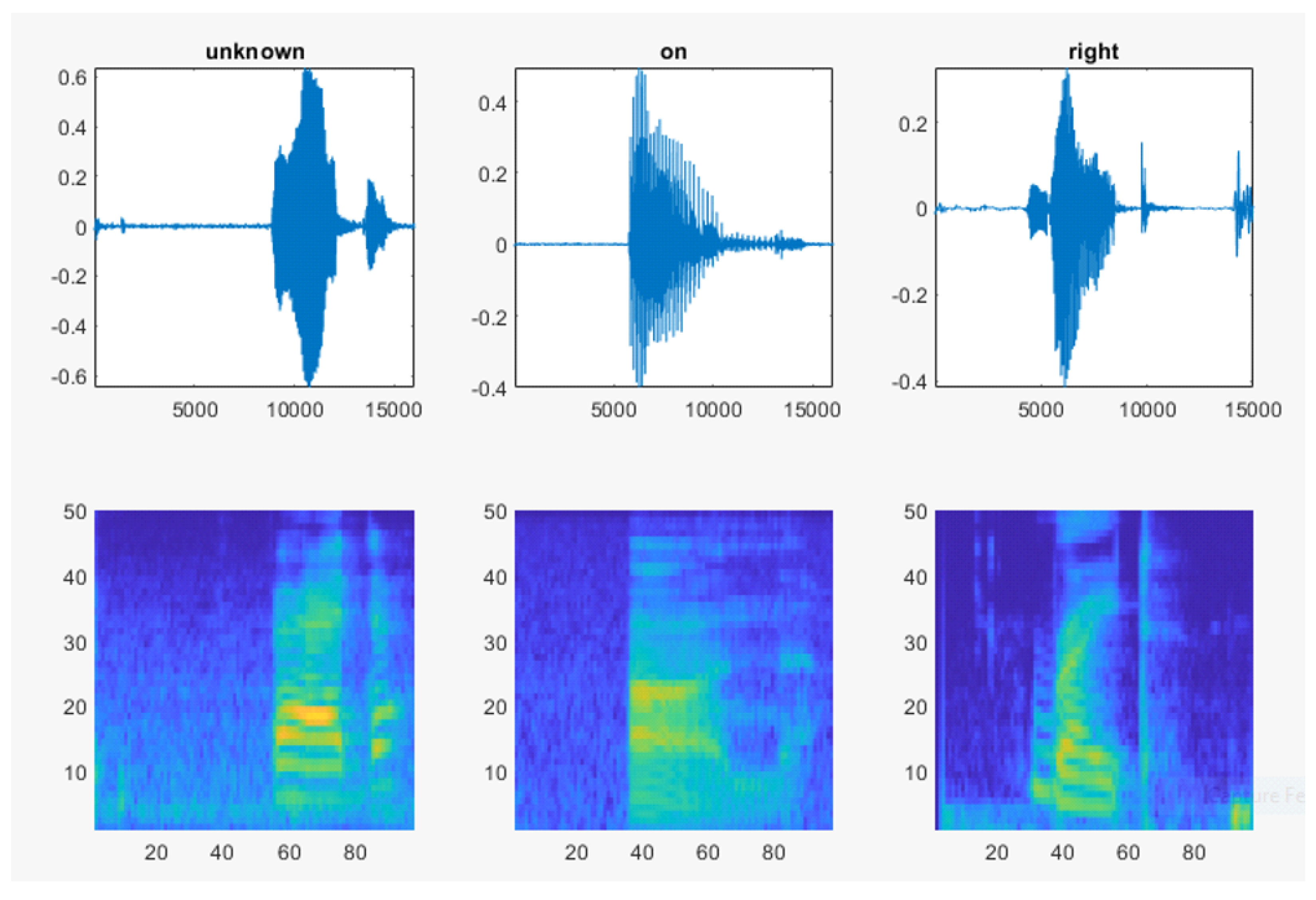
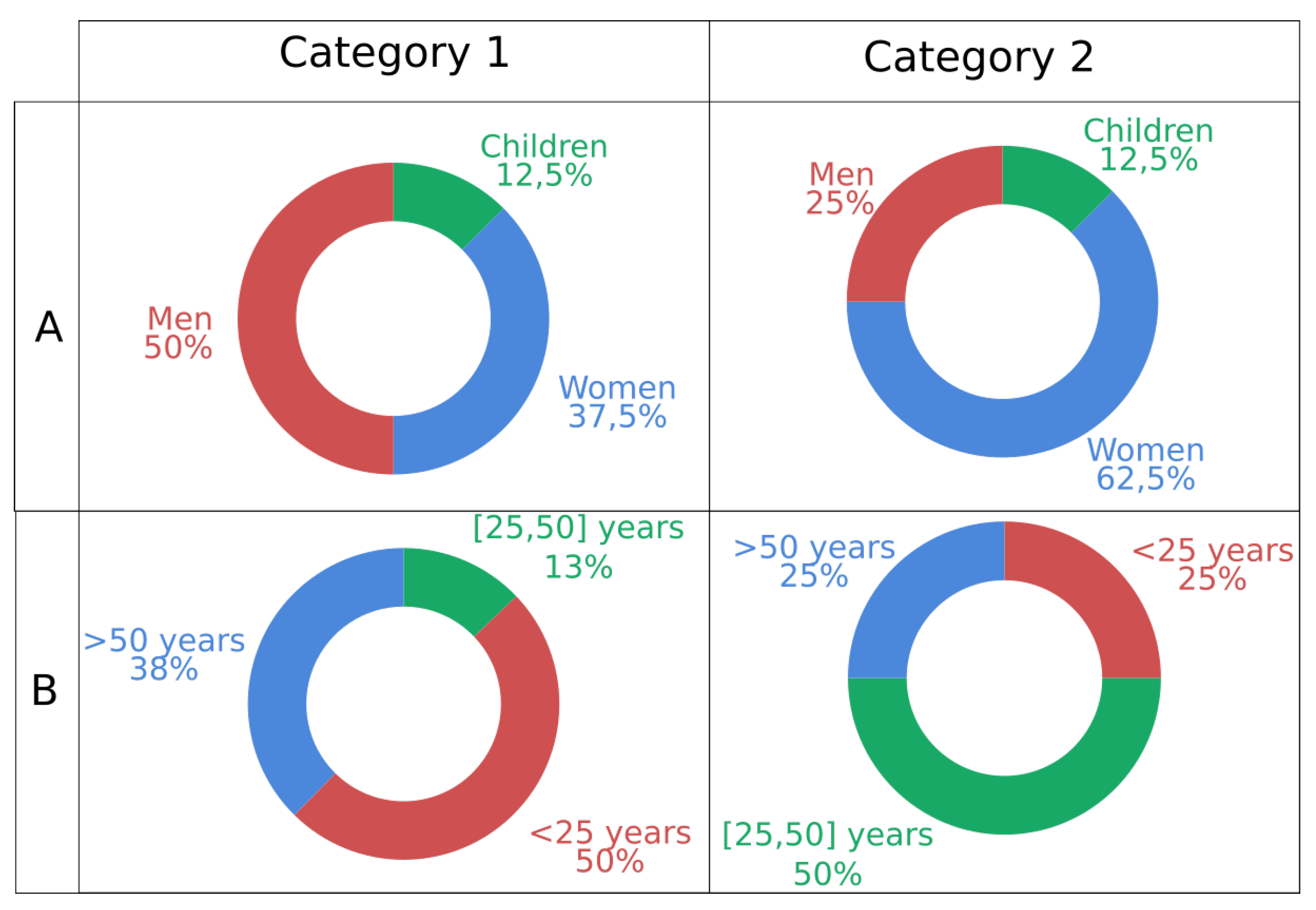
3.1.1. Data Collection and Preparation
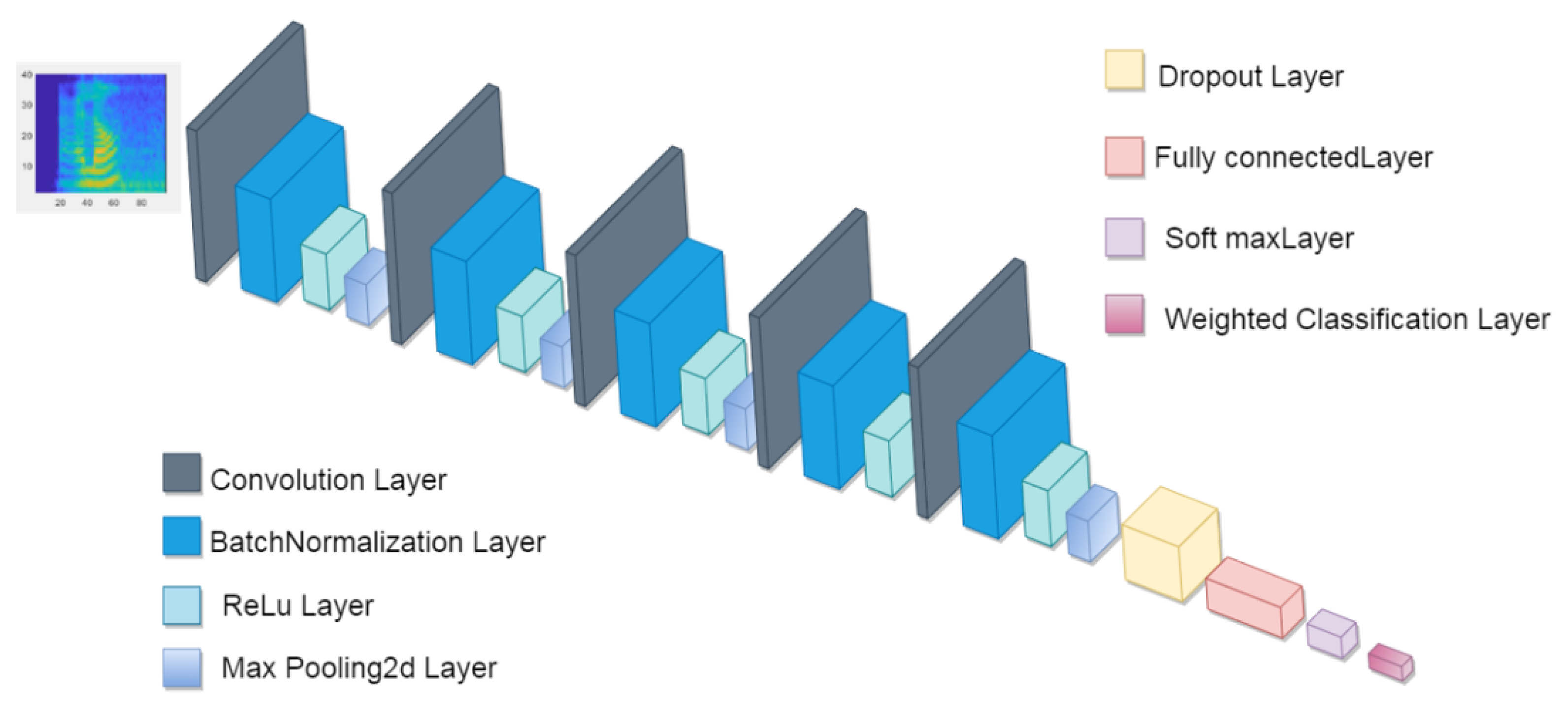
3.1.2. Deep Learning Model for AMLSR
- 5 convolution layers: each layer acts as a feature extractor.
- 5 By normalizing the outputs of intermediary layers during training, batch normalization attempts to reduce the internal covariate shift in a network. This accelerates the training process and enables faster learning rates without increasing the risk of divergence. Batch normalization does this by normalizing the output of the preceding hidden layer using the mean and variance of the batch (mini-batch). For an input mini-batch we learn parameters and via [34]:
- 5 ReLu Layer: The rectified linear unit (ReLU) is a simple, fast activation function typically found in computer vision. The function is a linear threshold, defined as:
- 4 max pooling layers: As the name suggests, the max pooling operation chooses the maximum value of neurons from its inputs and thus contributes to the invariance property. Formally, for a 2d output from the detection stage, a max pooling layer performs the transformation in order to downsample the feature maps (in time and frequency) [34].where the function h is generally known as a kernel or filter transformation, p and q denote the coordinates of the neuron in its local neighborhood and l represents the layer. In pooling, k values are returned instead of a single value in the max pooling operation.
- Dropout Layers: Applying dropout to a network involves applying a random mask sampled from a Bernoulli distribution with a probability of P. This mask matrix is applied elementwise (multiplication by 0) during the feed-forward operation. During the backpropagation step, the gradients for each parameter and the parameters that were masked in the gradient are set to 0 and other gradients are scaled up by .
- Fully connected Layer: allows us to perform classification on the dataset.
- Softmax Layer: we find it just after the fully connected layer in order to predict classes. The output unit activation function is the softmax function [35]:where and
- Weighted Classification Layer: For typical classification networks, the classification layer usually follows a softmax layer. In the classification layer, trainNetwork takes the values from the softmax function and assigns each input to one of the K mutually exclusive classes using the cross entropy function for a 1-of-K coding scheme [35]:where N is the number of samples, K is the number of classes, is the weight for class i, is the indicator that the nth sample belongs to the ith class, and is the output for sample n for class i, which in this case, is the value from the softmax function. In other words, is the probability that the network associates the nth input with class i.
- numC: controls the number of channels in the convolutional layers. It’s worth mentioning at this stage that the network’s accuracy is linked to its depth. Increasing the number of filters (numC) or adding identical blocks of convolutional, batch normalization, and ReLu layers may improve overall performance. Once the network is created, its training can be started.
3.2. Second Stage: AMLSR System Deployment
4. Implementation Setup, Results and Discussion
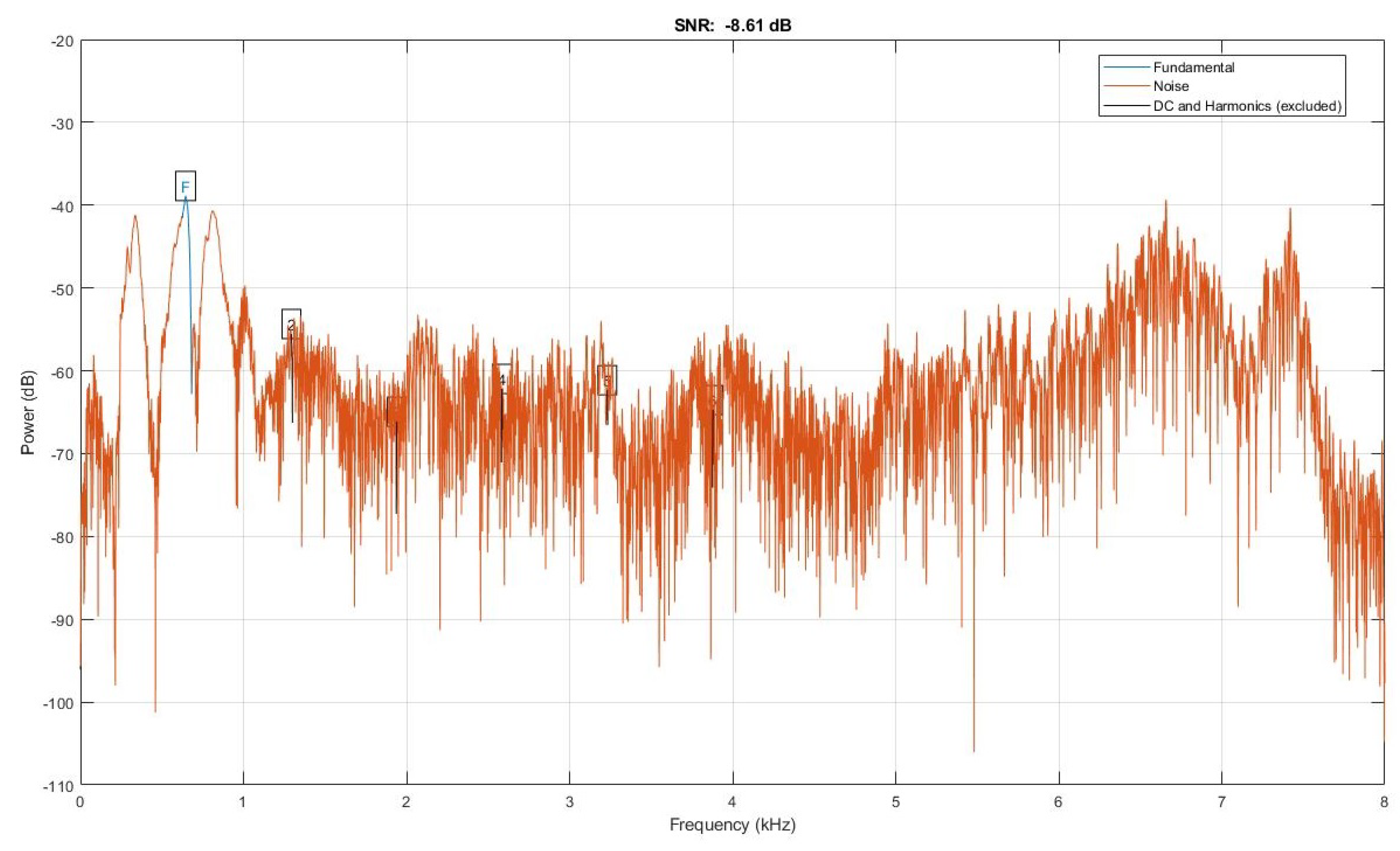
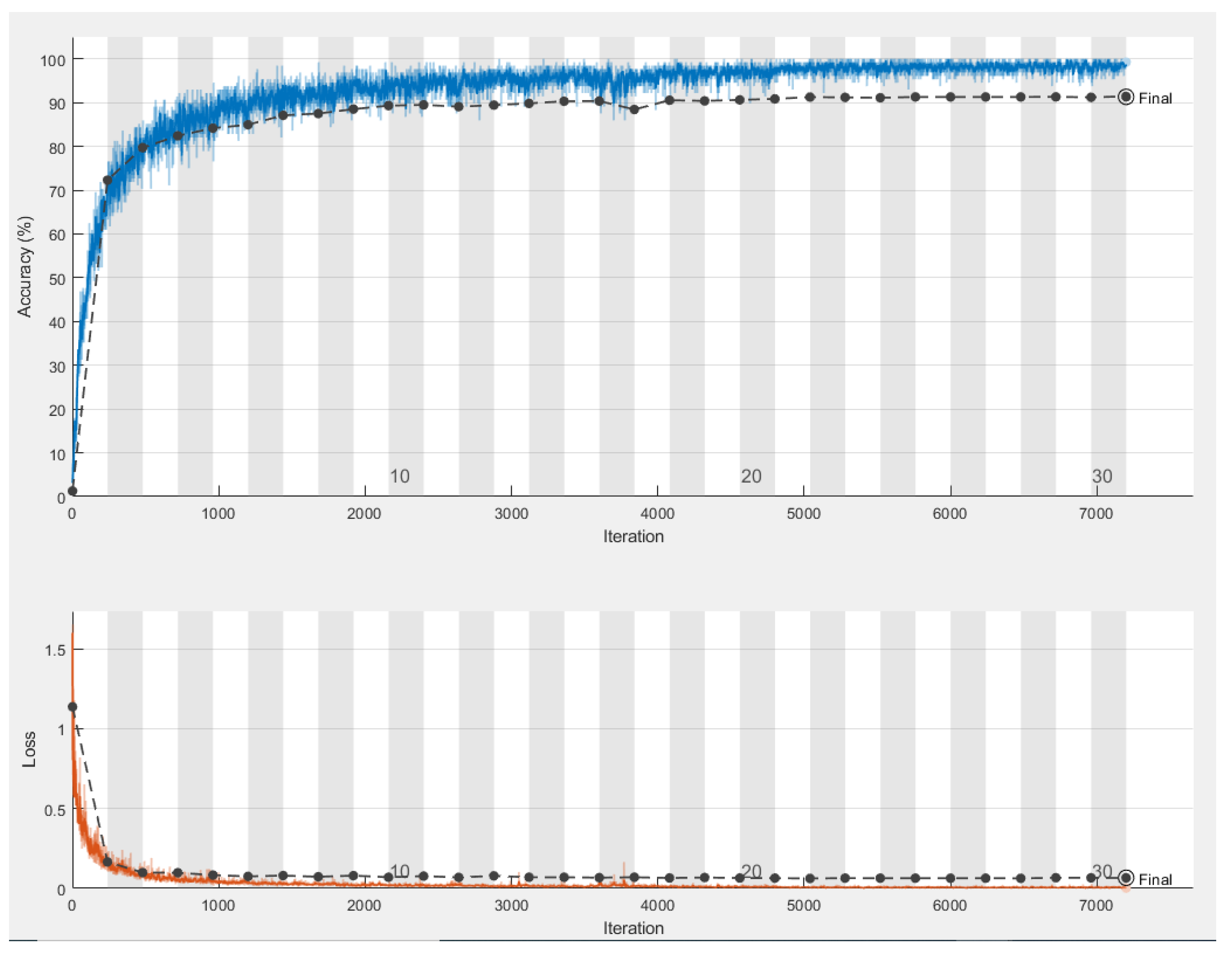
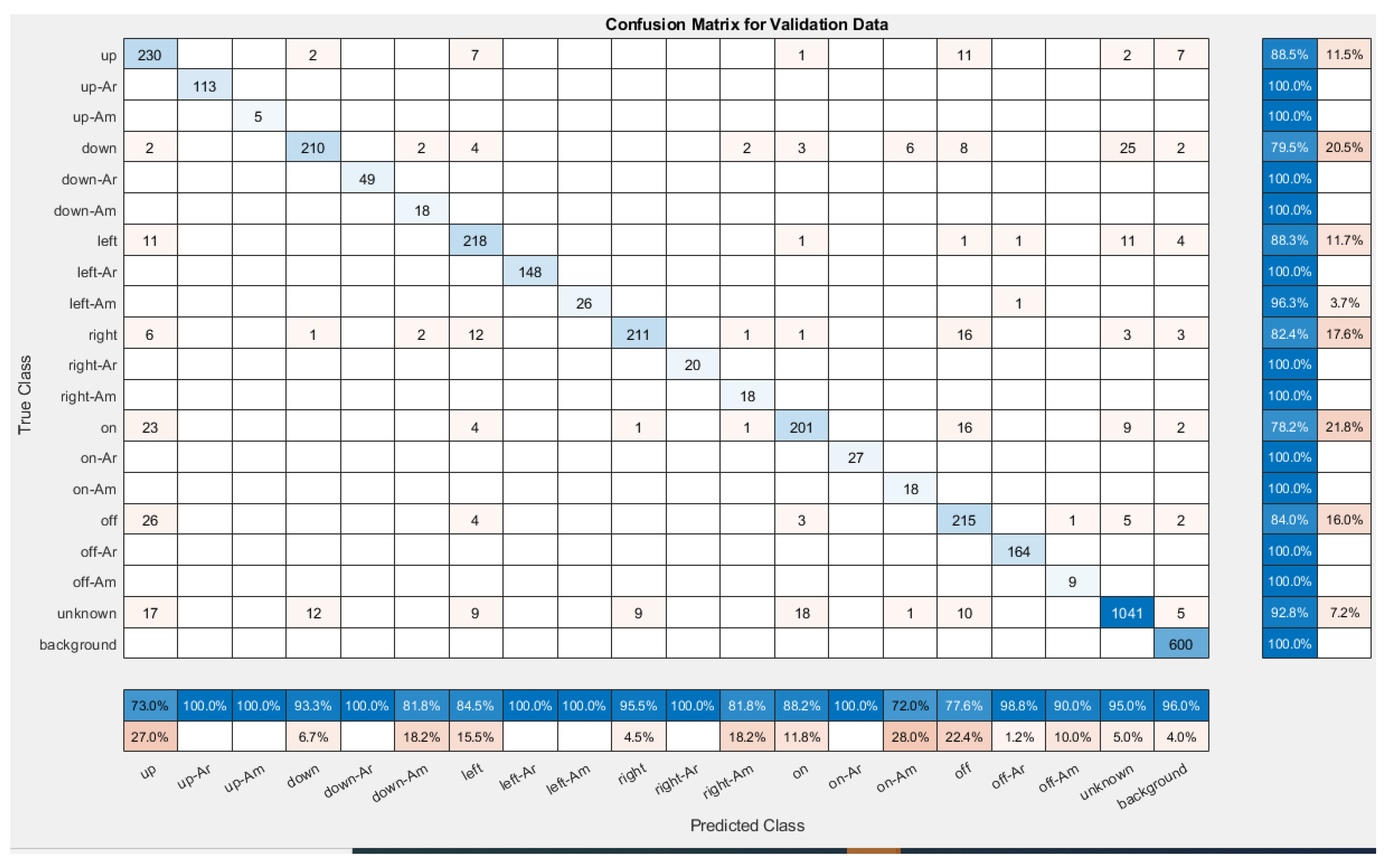
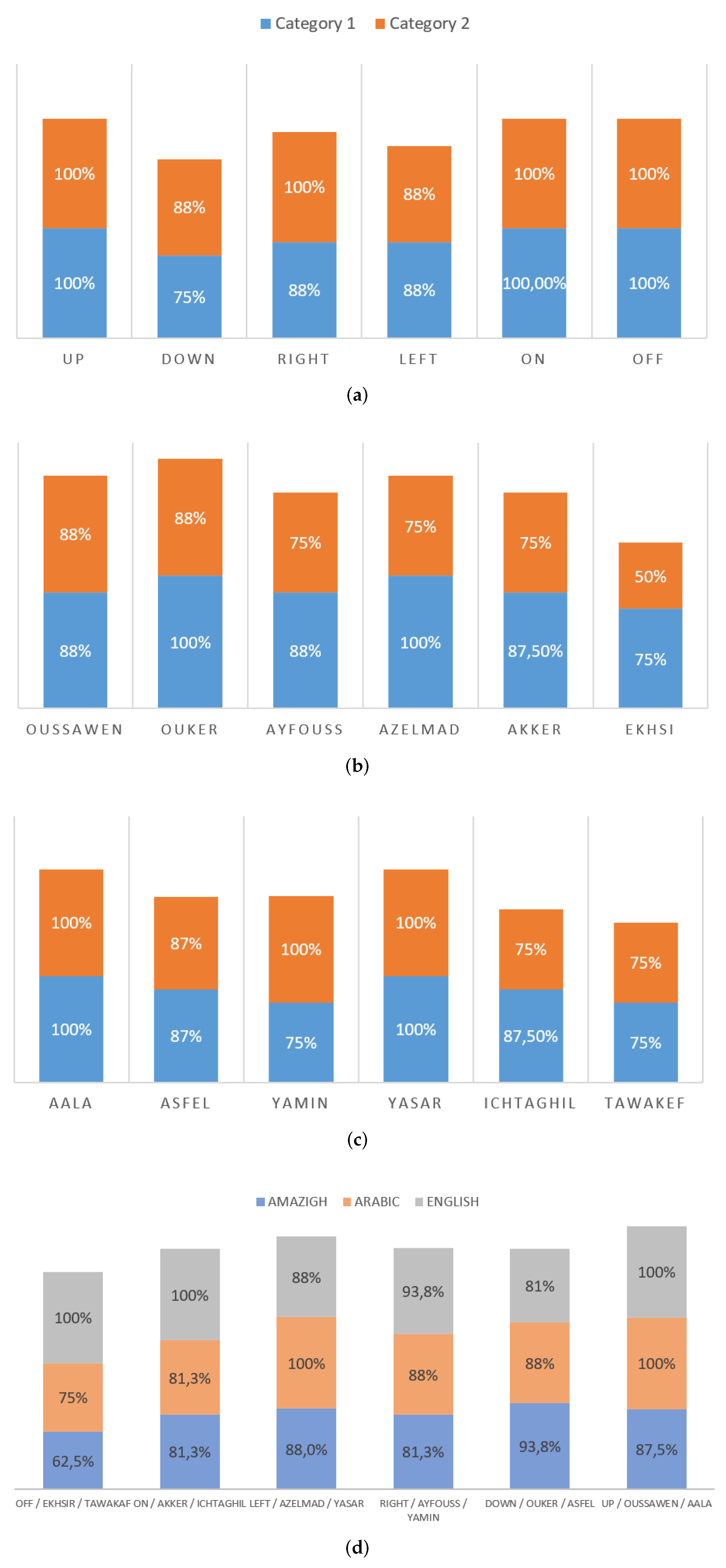
4.1. AMLSR System Testing Results
- Training set: 80% of the data set was used to fit the model by identifying the set of weights and biases that, on average, cause the least loss across all input examples. The most difficult step in building any machine learning model, particularly a deep learning model, is training the model, which necessitates massive data sets and computational power. It is, indeed, an optimization task as it seeks to minimize the loss associated with incorrect predictions.
- Validation set: 10% of the data examples was used to fine tune the model’s hyperparameters and provide an unbiased evaluation of the model fit on the training set.
- Test set: 10% of the data examples was used to evaluate the model performance.
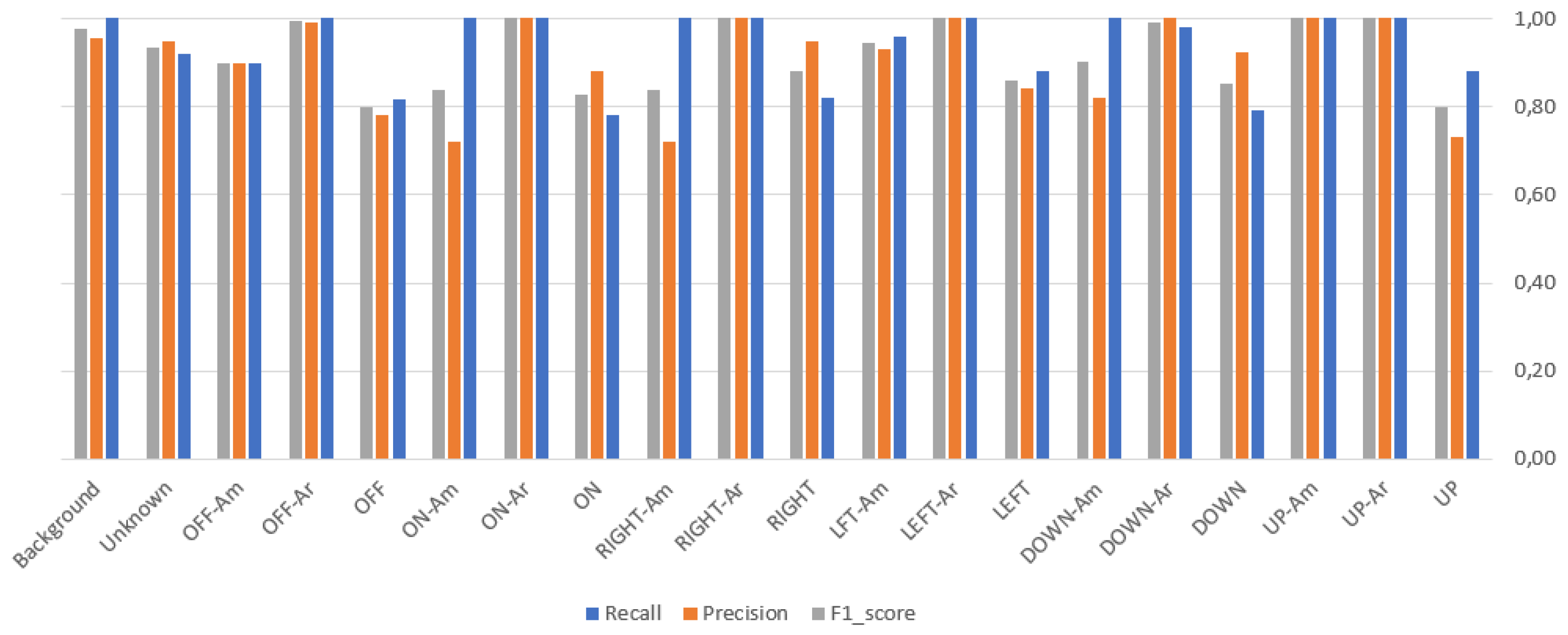
4.2. Performance Measures and Evaluation
- Recall: This metric assesses how confident we can be that the model will find all spoken words related to the selected positive class. In other words, it indicates the proportion of true positives that are correctly classified. Recall is calculated for each target level () as follows:
- Precision: This metric helps in assessing how confident we can be that a spoken command identified as having a positive target level actually has that level. In other words, it indicates the proportion of predicted positives that are actually positive.
- F1-measure (or F1 score): The F1 measure, which is the harmonic mean of precision and recall, provides an alternative to assessing the misclassification rate and aids in concentrating on minimizing both false positives and false negatives equally.
- Average class accuracy (ACA): Because the data set is imbalanced, using raw classification accuracy to evaluate overall performance can be misleading. Instead, we propose using the harmonic mean to calculate the average class accuracy, as shown in the equation below:
4.3. Real Time Tests of the Proposed AMLSR
5. Hardware Implementation for AMLSR Deployment
- The interface is able to automatically detect the available UAVs.
- The interface displays the information related to the motors rotation speed as PWM signals. This information is displayed with different-colored text in order to help the operator to avoid overload.
- The detected command is displayed as ‘Text’ with the language of the user.
- The interface is offered in a variety of languages depending on the user’s language. English is primarily suggested.
- The interface displays visual alerts in reaction to various events that may occur during the system’s functioning.
6. Comparative Study and Discussion
7. Conclusions
Author Contributions
Funding
Informed Consent Statement
Acknowledgments
Conflicts of Interest
References
- Castrillo, V.U.; Manco, A.; Pascarella, D.; Gigante, G. A Review of Counter-UAS Technologies for Cooperative Defensive Teams of Drones. Drones 2022, 6, 65. [Google Scholar] [CrossRef]
- Mirri, S.; Prandi, C.; Salomoni, P. Human-Drone Interaction: State of the art, open issues and challenges. In Proceedings of the ACM SIGCOMM 2019 Workshop on Mobile AirGround Edge Computing, Systems, Networks, and Applications, Beijing, China, 19 August 2019; pp. 43–48. [Google Scholar]
- Contreras, R.; Ayala, A.; Cruz, F. Unmanned aerial vehicle control through domain-based automatic speech recognition. Computers 2020, 9, 75. [Google Scholar] [CrossRef]
- Park, J.S.; Na, H.J. Front-end of vehicle-embedded speech recognition for voice-driven multi-UAVs control. Appl. Sci. 2020, 10, 6876. [Google Scholar] [CrossRef]
- Wojciechowska, A.; Frey, J.; Sass, S.; Shafir, R.; Cauchard, J.R. Collocated human–drone interaction: Methodology and approach strategy. In Proceedings of the 2019 14th ACM/IEEE International Conference on Human-Robot Interaction (HRI), Daegu, Korea, 11–14 March 2019; pp. 172–181. [Google Scholar]
- Cauchard, J.R.; Khamis, M.; Garcia, J.; Kljun, M.; Brock, A.M. Toward a roadmap for human–drone interaction. Interactions 2021, 28, 76–81. [Google Scholar] [CrossRef]
- Christ, P.F.; Lachner, F.; Hösl, A.; Menze, B.; Diepold, K.; Butz, A. Human-drone-interaction: A case study to investigate the relation between autonomy and user experience. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8–10 October 2016; pp. 238–253. [Google Scholar]
- Liu, C.; Szirányi, T. Real-Time Human Detection and Gesture Recognition for On-Board UAV Rescue. Sensors 2021, 21, 2180. [Google Scholar] [CrossRef]
- Nan, Z.; Jianliang, A. Speech Control Scheme Design and Simulation for UAV Based on HMM and RNN. J. Syst. Simul. 2020, 32, 464. [Google Scholar]
- Kim, D.; Oh, P.Y. Human-drone interaction for aerially manipulated drilling using haptic feedback. In Proceedings of the 2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Las Vegas, NV, USA, 25–29 October 2020; pp. 9774–9780. [Google Scholar]
- Tezza, D.; Garcia, S.; Hossain, T.; Andujar, M. Brain eRacing: An exploratory study on virtual brain-controlled drones. In Proceedings of the International Conference on Human-Computer Interaction, Orlando, FL, USA, 26–31 July 2019; pp. 150–162. [Google Scholar]
- Tezza, D.; Andujar, M. The state-of-the-art of human–drone interaction: A survey. IEEE Access 2019, 7, 167438–167454. [Google Scholar] [CrossRef]
- Jie, L.; Jian, C.; Lei, W. Design of multi-mode UAV human-computer interaction system. In Proceedings of the 2017 IEEE International Conference on Unmanned Systems (ICUS), Beijing, China, 27–29 October 2017; pp. 353–357. [Google Scholar]
- Malik, M.; Malik, M.K.; Mehmood, K.; Makhdoom, I. Automatic speech recognition: A survey. Multimed. Tools Appl. 2021, 80, 9411–9457. [Google Scholar] [CrossRef]
- Nassif, A.B.; Shahin, I.; Attili, I.; Azzeh, M.; Shaalan, K. Speech recognition using deep neural networks: A systematic review. IEEE Access 2019, 7, 19143–19165. [Google Scholar] [CrossRef]
- Izbassarova, A.; Duisembay, A.; James, A.P. Speech recognition application using deep learning neural network. In Deep Learning Classifiers with Memristive Networks; Springer: Cham, Switzerland, 2020; pp. 69–79. [Google Scholar]
- Indolia, S.; Goswami, A.K.; Mishra, S.P.; Asopa, P. Conceptual understanding of convolutional neural network-a deep learning approach. Procedia Comput. Sci. 2018, 132, 679–688. [Google Scholar] [CrossRef]
- Song, Z. English speech recognition based on deep learning with multiple features. Computing 2020, 102, 663–682. [Google Scholar] [CrossRef]
- Veisi, H.; Mani, A.H. Persian speech recognition using deep learning. Int. J. Speech Technol. 2020, 23, 893–905. [Google Scholar] [CrossRef]
- El Ouahabi, S.; Atounti, M.; Bellouki, M. Toward an automatic speech recognition system for amazigh-tarifit language. Int. J. Speech Technol. 2019, 22, 421–432. [Google Scholar] [CrossRef]
- Alsayadi, H.A.; Abdelhamid, A.A.; Hegazy, I.; Fayed, Z.T. Arabic speech recognition using end-to-end deep learning. IET Signal Process. 2021, 15, 521–534. [Google Scholar] [CrossRef]
- Zhou, Y.; Hou, J.; Gong, Y. Research and Application of Human-computer Interaction Technology based on Voice Control in Ground Control Station of UAV. In Proceedings of the 2020 IEEE 6th International Conference on Computer and Communications (ICCC), Chengdu, China, 11–14 December 2020; pp. 1257–1262. [Google Scholar]
- Yamazaki, Y.; Tamaki, M.; Premachandra, C.; Perera, C.; Sumathipala, S.; Sudantha, B. Victim detection using UAV with on-board voice recognition system. In Proceedings of the 2019 Third IEEE International Conference on Robotic Computing (IRC), Naples, Italy, 25–27 February 2019; pp. 555–559. [Google Scholar]
- Meszaros, E.L.; Chandarana, M.; Trujillo, A.; Allen, B.D. Speech-based natural language interface for UAV trajectory generation. In Proceedings of the 2017 International Conference on Unmanned Aircraft Systems (ICUAS), Miami, FL, USA, 13–16 June 2017; pp. 46–55. [Google Scholar]
- Galangque, C.M.J.; Guirnaldo, S.A. Speech Recognition Engine using ConvNet for the development of a Voice Command Controller for Fixed Wing Unmanned Aerial Vehicle (UAV). In Proceedings of the 2019 12th International Conference on Information & Communication Technology and System (ICTS), Surabaya, Indonesia, 18 July 2019; pp. 93–97. [Google Scholar]
- Kumaar, S.; Bazaz, T.; Kour, S.; Gupta, D.; Vishwanath, R.M.; Omkar, S. A Deep Learning Approach to Speech Based Control of Unmanned Aerial Vehicles (UAVs). CS & IT Conf. Proc. 2018, 8. [Google Scholar] [CrossRef]
- Oneata, D.; Cucu, H. Kite: Automatic speech recognition for unmanned aerial vehicles. arXiv 2019, arXiv:1907.01195. [Google Scholar]
- Mięsikowska, M. Discriminant Analysis of Voice Commands in the Presence of an Unmanned Aerial Vehicle. Information 2021, 12, 23. [Google Scholar] [CrossRef]
- Nicolson, A.; Paliwal, K.K. Deep Xi as a front-end for robust automatic speech recognition. In Proceedings of the 2020 IEEE Asia-Pacific Conference on Computer Science and Data Engineering (CSDE), Gold Coast, Australia, 16–18 December 2020; pp. 1–6. [Google Scholar]
- LeCun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef] [Green Version]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. In Proceedings of the Advances in Neural Information Processing Systems 25, Lake Tahoe, NV, USA, 3–6 December 2012. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- Kamath, U.; Liu, J.; Whitaker, J. Deep Learning for NLP and Speech Recognition; Springer: Cham, Switzerland, 2019; Volume 84. [Google Scholar]
- Bishop, C.M.; Nasrabadi, N.M. Pattern Recognition and Machine Learning; Springer: New York, NY, USA, 2006; Volume 4. [Google Scholar]
- Nassif, A.B.; Shahin, I.; Elnagar, A.; Velayudhan, D.; Alhudhaif, A.; Polat, K. Emotional Speaker Identification using a Novel Capsule Nets Model. Expert Syst. Appl. 2022, 193, 116469. [Google Scholar] [CrossRef]
- Jing, L.; Tian, Y. Self-supervised visual feature learning with deep neural networks: A survey. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 43, 4037–4058. [Google Scholar] [CrossRef] [PubMed]
- Samant, R.M.; Bachute, M.; Gite, S.; Kotecha, K. Framework for Deep Learning-Based Language Models using Multi-task Learning in Natural Language Understanding: A Systematic Literature Review and Future Directions. IEEE Access 2022, 10, 17078–17097. [Google Scholar] [CrossRef]
- Joshi, G.; Walambe, R.; Kotecha, K. A review on explainability in multimodal deep neural nets. IEEE Access 2021, 9, 59800–59821. [Google Scholar] [CrossRef]
- Kotecha, K.; Garg, D.; Mishra, B.; Narang, P.; Mishra, V.K. Background Invariant Faster Motion Modeling for Drone Action Recognition. Drones 2021, 5, 87. [Google Scholar] [CrossRef]
- Walambe, R.; Marathe, A.; Kotecha, K. Multiscale object detection from drone imagery using ensemble transfer learning. Drones 2021, 5, 66. [Google Scholar] [CrossRef]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameters | Arabic Database | Amazigh Database |
|---|---|---|
| Sampling Frequency | 16 KHz | 16 KHz |
| Audio Format | .wav | .wav |
| Speakers | 12 (5 M + 7 F) | 12 (5 M + 7 F) |
| Number of commands | 6 | 6 |
| Number of unknown words | 20 | 20 |
| Size of commands | 5220 | 960 |
| English Commands | Arabic Commands | Amazigh Commands | Actions |
|---|---|---|---|
| Up | Aala (Up-Ar) | Oussawen (Up-Am) | Increase altitude |
| Down | Asfal (Down-Ar) | Oukser (Down-Am) | Decrease altitude |
| Right | Yamine (Right-Ar) | Ayfouss (Right-Am) | Move to the right |
| center | Yassar (center-Ar) | Azelmad (center-Am) | Move to the center |
| On | Ichtaghil (On-Ar) | Akker (On-Am) | Turn motors on |
| Off | Tawakef (Off-Ar) | Ekhsi (Off-Am) | Turn motors off |
| Criteria | [36] | [28] | [3] | [4] | AMSLR |
|---|---|---|---|---|---|
| Used Languages | En, Ar | En | En, Sp | En | En, Ar, Am |
| Used representation | MFCC | MFCC | GCS API | Spectrograms | Spectrograms |
| Average Accuracy | 89.85% | 76.2% | 96.67% | 79% | 93.76% |
| Robustness | Not Considered | Considered | Considered | Considered | Considered |
| System Hardware Implementation | No | Yes | Simulation | Yes | Yes |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Choutri, K.; Lagha, M.; Meshoul, S.; Batouche, M.; Kacel, Y.; Mebarkia, N. A Multi-Lingual Speech Recognition-Based Framework to Human-Drone Interaction. Electronics 2022, 11, 1829. https://doi.org/10.3390/electronics11121829
Choutri K, Lagha M, Meshoul S, Batouche M, Kacel Y, Mebarkia N. A Multi-Lingual Speech Recognition-Based Framework to Human-Drone Interaction. Electronics. 2022; 11(12):1829. https://doi.org/10.3390/electronics11121829
Chicago/Turabian StyleChoutri, Kheireddine, Mohand Lagha, Souham Meshoul, Mohamed Batouche, Yasmine Kacel, and Nihad Mebarkia. 2022. "A Multi-Lingual Speech Recognition-Based Framework to Human-Drone Interaction" Electronics 11, no. 12: 1829. https://doi.org/10.3390/electronics11121829