1. Introduction
Sentiment classification [
1,
2] aims to interpret the explicit sentiment polarity of a given sentence in a complex context, which is a fundamental natural language processing task that has received much attention in recent years. For instance, in a sentence such as “These MacBooks are encased in a soft rubber enclosure—so you will never know about the razor edge until you buy it”, the sentiment polarities of “rubber enclosure” and “edge” are positive and negative, respectively.
Many existing sentiment classification systems [
3,
4,
5,
6,
7,
8] focus on statistical methods to develop a set of handcrafted features for sentiment classification. However, these handcrafted feature-based methods usually require human involvement. In such a case, the accuracy is questionable. Moreover, it is difficult for these methods to meet the growing application demands. In recent years, deep learning methods [
9,
10] have received increasing attention because such methods are able to automatically learn emotional features and generate useful low-dimensional representations from context; they can also achieve high accuracy in the sentiment classification tasks without requiring complex feature engineering. For example, some studies use the attention mechanism [
11] to extract important sentiment words in sentences in order to improve classification accuracy. Other studies use the LSTM model [
12] to establish long-term dependencies. Recently, graph convolutional networks (GCNs) [
13] have been widely used in sentiment classification tasks, in which an information transfer mechanism is used to extract the node neighborhood information and the local context information. Chen et al. [
14] proposed a multiple attention-based LSTM to capture the relevance between sentiment words and their contexts. Lin et al. [
15] developed a sentiment semantic coding network based on a multi-head self-attention mechanism, which can model the contextual semantics of sentiment words.
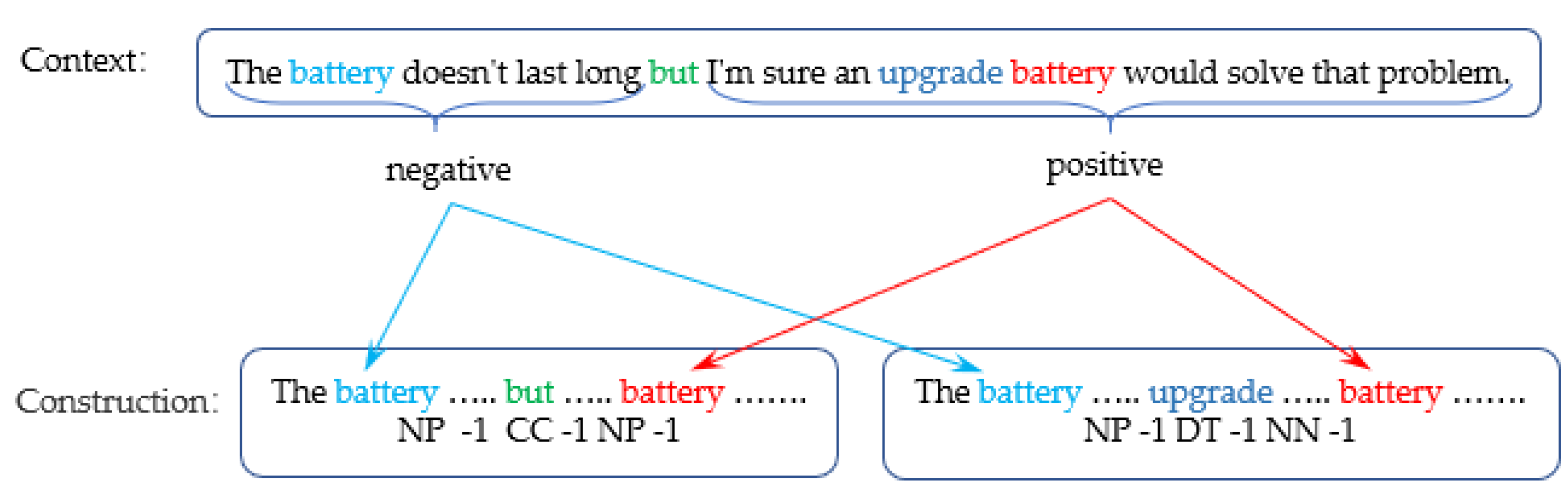
Although the research methods above have made great progress in sentiment classification, most of the existing methods only model the semantics of sentiment words, ignoring the dependencies between emotional words and the semantic relationship between sentiment words. For instance, as shown in
Figure 1, we can see that “battery” has a negative sentiment polarity in the first position. We then guess that the second “battery” may be negative, while the emotional polarity of “battery” after the conjunction “but” and the qualifier “upgrade” may also be positive. Overall, the same sentiment text has multiple constructions that can help us to judge the sentiment polarity of sentiment words.
In this paper, we develop a construction-aided multi-scale graph reasoning network (ConAs-GRNs) to capture the contextual and global semantic information of sentiment texts and to model their sentiment dependencies. More specifically, the graph reasoning networks can obtain interdependent information from rich relational data and enhance interdependent interactivity. For each node in the topological and relational graph, the graph inference network encodes its neighborhood information into a low-dimensional feature vector. As shown in
Figure 1, “battery” is regarded as a node, which can be used to construct a corresponding dependency graph with the adjacent sentiment words. After that, on the basis of the structure, a large-scale topological graph containing all emotional sentences can be constructed by exploiting the relationship between the emotional words and texts. Our model learns the emotional dependencies of these heterogeneous graphs at different scales and aggregates information between heterogeneous nodes to obtain global and contextual semantics. To capture the emotion-specific representations and the important salient information, before using the graph inference network, we adopt a triple attention mechanism with positional encoding, i.e., we focus on key features in three directions: horizontal, vertical, and depth. It is worth noting that in the graph inference network, we adopt a weighted edge reduction strategy to reduce the number of nodes in order to ease the computational complexity. The main contributions of this paper are summarized as follows:
To the best of our knowledge, this work is the first attempt at building a heterogeneous relation graph based on sentiment construction for sentiment words and texts. Moreover, we utilize Graph Reasoning Networks (GRNets) to capture the details of the contextual and global semantics of sentences.
We design an emotional dependency graph and a constructional relationship graph, where the constructive details are used to assist the learning model for sentiment classification.
In the process of constructing heterogeneous graphs, a weighted edge reduction strategy is used to refine the node information and reduce the computational complexity of the model. The extensive experiments conducted on two baseline datasets, SemEval 2014 and ACL-14, demonstrate that our method outperforms other sentiment classification methods.
The rest of this article is organized as follows. We review the related work in
Section 2 and present the sentiment classification framework ConAs-GRNs in
Section 3. The ablation research and experimental results are provided in
Section 4. Finally,
Section 5 presents the conclusion of our paper.
2. Related Work
Sentiment classification has received extensive attention in recent years [
10,
15]. In order to improve the accuracy and efficiency of emotion classification, researchers have developed many classification methods based on traditional handcrafted features [
7] and deep learning [
9]. This section will introduce the related research in detail.
Many existing sentiment classification methods extract the handcrafted features by feature engineering. For instance, Pathik N et al. [
16] discussed the relationship between the Latent Dirichlet Allocation (LDA) and probabilistic modeling. Although LDA can model different topics, it relies too much on statistical models and does not exploit high-dimensional features. Machine learning methods increasingly use visualized text and high-dimensional data as input, which provide more dimensional statistical features. Thakur et al. [
6] developed a Kernel Optimized-Support Vector Machine (KO-SVM) model for sentiment classification. In their scheme, the sentiment features were fed into the classifier. More specifically, they also improved the SVM classifier by replacing the exponential kernel with an optimized kernel and used a self-adaptive lion algorithm to improve the optimizer in order to make it more sensitive to dominant features. Nafis et al. [
7] proposed an improved hybrid feature selection method using Term Frequency-Inverse Document Frequency (TF-IDF) and Support Vector Machine (SVM-RFE) for sentiment classification. Fauzi et al. [
8] used the random forests for Indonesian sentiment classification and explored some variations of the term weights in the classification results. However, this method did not significantly improve the performance of the random forest.
As the network layer of deep learning deepens, features that are more conducive to sentiment analysis can be extracted. The recurrent neural network (RNN) [
17] has been proved to be suitable for language sentiment classification tasks in many methods. Zhang et al. [
10] proposed a Gated Neural Network, which used a gating mechanism to control the importance of the context to the target. In this case, only one target with the highest probability is concerned in a sentence. However, the context relationship of the sentence is difficult to determine according to the target. To address this limitation, Ma et al. [
12] leveraged the object-level and sentence-level attention with commonsense knowledge to enhance the long short-term memory (LSTM) network, thus improving the network’s accuracy.
Due to the control effect of the attention mechanism on the target, many studies combine attention mechanism and RNN. Huddar et al. [
17] proposed a pair-wise attention mechanism to analyze and understand multimodal context and semantics. Chen et al. analyzed a corpus of 3200 English tweets using an attention-based LSTM. Zeng et al. [
18] introduced position-aware vectors to solve the common problem of the attention mechanism being unable to focus on the contextual position. However, the RNN structures still have many limitations. The introduction of graph convolutional networks (GCNs) may give a promising solution for a better sentiment classification. Zhou et al. [
13] combined grammar and knowledge to improve the graph convolution, which could improve the performance of emotion classification. Zhu et al. [
19] used the local and global structure dependency to guide the graph convolutional network and then adaptively fused information with the use of a gate mechanism. Zhang et al. [
20] extracted the sentence structure of the dependency tree and solved the long-term multi-word dependency problem, thus enabling the graph convolutional network to achieve better results in aspect sentiment classification. However, this method does not take full advantage of the label information of edges, and there is still room for further improvement.
3. ConAs-GRNs Frameworks
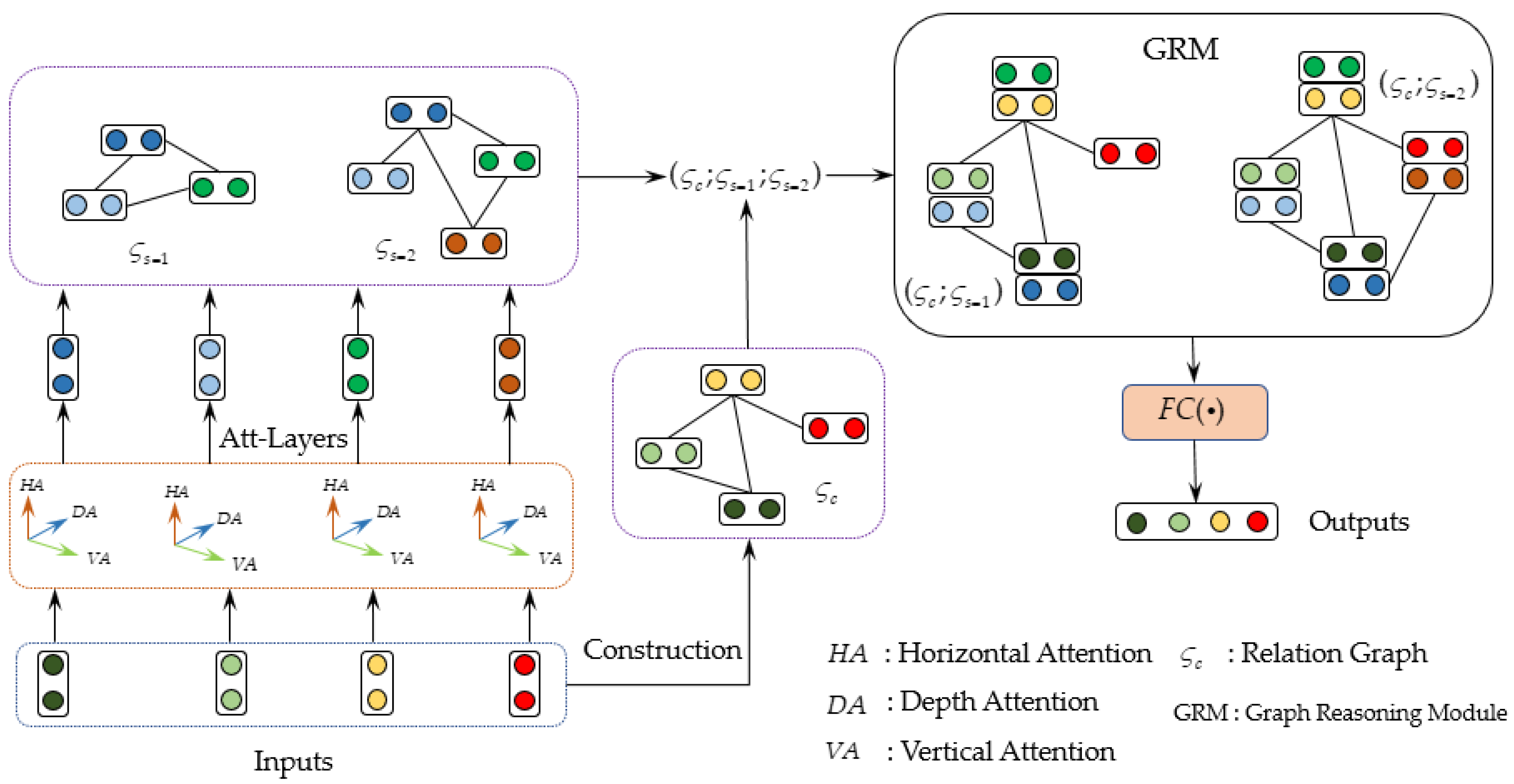
In this section, we elaborate on the proposed ConAs-GRNs framework for sentiment classification. The word feature vectors of emotional sentences are obtained by the BERT method, which are then fed into the fully connected layer to extract the emotional words and related construction information to obtain rich underlying semantic features, i.e., prior knowledge. Secondly, a triple attention mechanism is designed to encode emotional text in order to obtain the position information of emotional words in the directions of horizontal, vertical, and depth and then model the context and global semantics. More specifically, it assigns the corresponding weights to emotional words while paying attention to salient features, which reduces the use of redundant information. Finally, a multi-scale graph reasoning network is used to learn heterogeneous graphs constructed by emotional words and constructions, which can transfer and aggregate the heterogeneous node features from its neighbors. Note that for the emotional dependency graph, the dependencies between the sentiment words in a sentence and the edges between nodes are measured by the cosine similarity. The relationship graph contains emotions. The overall flow of ConAs-GRNs is shown in
Figure 2.
Next, we will introduce the ConAs-GRNs framework, which includes semantic encoding, the construction of heterogeneous graphs, and the reasoning of multi-scale graphs.
3.1. Semantic Encoding Module
The semantic encoding module consists of a Bert [
21] layer, a fully connected layer, and a three-directional attention mechanism. First, the mapping vectors extracted by the Bert layer are fed into the fully connected layer (FC) in order to extract the rich low-level semantic information from emotional sentences. Second, the positions and interrelationships of sentiment words in sentiment sentences are encoded by the three-directional attention [
22,
23] mechanism. Then, we can obtain the fine-grained semantic information of different sentiment words.
We define the input sentiment sentence as
X, where each
is composed of
N words. More specifically, the word vector dimension is represented by
D, and the word vector feature of a sentence is represented by
. The encoded features
are obtained by the FC layer. The three-directional attention mechanism is expressed as follows:
where
indicates the output features of fully connected layers;
indicates the fully connected operation;
indicates a convolution operation with a kernel size of
;
indicates the horizontal, vertical, and depth attention operation;
indicates the
emotional sentence in the corpus.
3.2. Establishment of Heterogeneous Graph
In order to obtain the details of the global and contextual semantics, we construct two topological graphs, i.e., the multi-scale affective dependency graphs and the constructional relational graphs , which can be used to explore effective dependencies and constructional relationships that facilitate effective interaction.
According to Equation (
1), we encode the features of sentiment sentences as
, and we calculate the correlation between emotional words in each sentence by their feature similarity, where each sentiment word is regarded as a node
, and the edge
between any two nodes is considered as a dependency. Then, we can construct a dependency topology graph
that contains multiple scales. The corresponding adjacency matrix
of
can be represented by the following equation:
where
can be any two nodes in
,
indicates a self-looping, and
indicates that there is no edge between
and
.
For a connected relational graph
that includes all words, the construction of a sentence (e.g., “The battery doesn’t last long but I’m sure an upgrade battery would solve that problem.”) can be defined as “NP -1 CC -1 NP -1” and “NP -1 DT -1 NN -1”, where “but” is “CC” and “upgrade” is “DT”. The polarity of the first “battery”, represented by “CC”, is opposite to the polarity of the second “battery”, represented by “DT”, i.e., the first “battery” is negative and the second “battery” is positive. This means that the same emotional word may have opposite polarity by some specific modifications. Subsequently, we can infer the polarity of the emotion by using this particular construction. After that, we can build a construction-based relational graph
, with the corresponding aspect word, such as “CC” and “DT” in the construction, as the root node. Then, the adjacency matrix
of graph
can be represented by the following equation:
where,
indicates the node of graph
,
indicates that the node is self-looping, and
indicates the normal formulas.
Based on the weighted edge reduction strategy, the graphs
and
can be used to form the final multi-scale heterogeneous graph
. This process can be represented by the equation below:
where
indicates the operation of weighted edge reduction, and
indicates the scale of sentiment dependency graph
. The adjacency matrix
for the weighted reduction strategy can be described as follows:
where
, and
.
n indicates the number of nodes. Then, the fused adjacency matrix
can be represented by the following equation:
In summary, the heterogeneous graph can capture the dependencies between sentiment words and strengthen their interactions by the sentiment constructions. It helps the graph reasoning networks sense the emotional details in changing statements.
3.3. Graph Reasoning Module
In order to accurately predict the polarity of emotional sentences, we input the constructed heterogeneous graph into the dynamically aggregated graph convolution [
24,
25] for interactive learning. The learning process can be described as follows:
where
and
are the outputs of the
l-th layers.
After that, we feed the detailed semantics obtained by the dynamically aggregated graph convolution into a fully connected layer FC, which can be described as follows:
where
indicates the prediction by the softmax classifier, and
indicates the operation of the full connection layer.
To be able to use weighted loss during training to obtain better performance for our proposed ConAs-GRNs framework during training, we use the weighted loss as follows:
where
indicates multiclass cross-entropy loss,
indicates dice loss,
indicates focal loss, and
indicates the weights factor.
Moreover, we use the “Adam” to optimize the learning model, as shown in Algorithm 1.
| Algorithm 1 Sentiment classification processing by the ConAs-GRNs frameworks. |
![Electronics 11 01825 i001]() |
4. Experimental Results
In our experiments, we use the SemEval 2014 and ACL-14 datasets to verify the validity of ConAS-GRN. Moreover, we discuss the needs of different components used in the proposed ConAS-GRN. In the following sections, we describe the details of our experimental setup.
4.1. Datasets Preparation
SemEval 2014: This dataset includes two parts, “Restaurant” and “Laptop”, where each part consists of three categories: positive, negative, and neutral.
ACL-14: This dataset includes negative, neutral, and positive comments about celebrities, products, and companies. In order to be fair, the negative, neutral, and positive emotion texts in the dataset were divided into 25%, 50%, and 25%. More specifically, the number of training and test samples were set to 6248 and 692, respectively. The details of the dataset are shown in
Table 1.
To verify the reliability and effectiveness of ConAs-GRNs, we use Accuracy (Acc) and as performance evaluation metrics.
4.2. Experiment Settings
Datasets processing. Firstly, the emotional sentence corresponding to each construction is mapped into a low-dimensional space, and a specific keyword is used as the root node. Then, we construct a large topology map of the entire statement. Finally, all topological graphs are fused with the use of an edge weight reduction strategy to form a heterogeneous graph that can be directly input to the graph reasoning network that learns their emotional relationships.
Training parameters. In our experiments, some important training details are as follows: (i) the learning rate is set to 1e-4, the number of iterations is set to 300; (ii) the batch is set to 32, and (iii) the word vector dimension is set to 300. More specifically, our framework is optimized by the “Adam”.
Environment configuration. We implement our ConAs-GRNs model by using the Pytorch platform, and all codes are developed based on python3.7. To ensure fairness, all experiments were carried out on two RTX3090 GPU cards.
4.3. Comparison with Other Sentiment Classification Methods
Taking SemEval2014 and ACL-14 as evaluation samples, we conducted extensive experiments to demonstrate the effectiveness of the proposed ConAS-GRN sentiment classification framework. The specific evaluation results are shown in
Table 2.
From the evaluation results shown in
Table 2, we can draw the following conclusions:
(1) Compared with other sentiment classification methods, using the graph structure to model sentiment semantics can significantly improve the classification accuracy. For example, in the Laptop dataset, the Acc of Text-GCNs are 3.48% and 1.13% higher than that of BiLSTM and PBAN, respectively. The main reason may be that the graph convolutional network strengthens the dependencies between emotional words (nodes) by aggregating the semantic information from the neighboring nodes. Moreover, the use of three-directional attention reduces the use of redundant information.
(2) The ConAs-GRNs (Glove) method can achieve the best performance on the two baseline datasets, SemEval2014 (Restaurant and Laptop) and ACL-14. For example, the classification performance of the ConAs-GRNs (Glove) method on the ACL-14 dataset is higher than that of the ASGCN (Bert) method. The main reason is that multi-scale information can better represent sentiment words and context nodes. Furthermore, multi-scale structural and heterogeneous information can describe the emotional relationships from multiple levels.
(3) The proposed ConAs-GRNs (Bert) method achieved good performance. As we expected, the ConAs-GRNs (Bert) outperformed the SDGCN (Bert) on the SemEval2014 (Restaurant) datasets. Moreover, ConAs-GRNs (Bert) used the weighted edge reduction strategy to prune the primary graph structure; it also used the triple attention mechanism with a positional encoding module to extract the useful features.
Finally, we can see that ConAs-GRNs (Bert) gives give the best performance and is better than ConAs-GRNs (glove) on the two baseline datasets.
4.4. Ablation Experiments
To demonstrate the effectiveness of different components used in the proposed ConAs-GRNs, we conducted a set of ablation experiments on the two baseline datasets, SemEval2014 and ACL-14. The experiment results are shown in
Table 3, where “BERT” indicates the BERT method that generates the word vectors. Similarly, “Glove” indicates the glove method. For example, ConAs-GRNs (NoAtt, Glove) indicate that ConAs-GRNs do not use the attention mechanism, and “ss” indicates that there is a single-scale heterogeneous graph.
From
Table 3, we can draw the following conclusions:
(1) Different word vectors have different impacts on the classification performance. For example, the Acc and F1 values of GRNs (Bert) are 0.74% and 0.29% higher than those of GRNs (Glove) on the Laptop dataset. Furthermore, the attention mechanism has a great impact on classification performance. For example, the Acc and F values of GRNs (Glove) are 0.97% and 1.31% higher than those of GRNs (NoAtt, Glove) on the Restaurant baseline dataset. This is because the attention mechanism can effectively reduce redundant information by focusing on salient features.
(2) From
Table 3, we can clearly see that the sentiment classification performance is poor when using a single-scale heterogeneous graph. For example, the Acc and F1 values of ConAs-GRNs (ss, Glove) on the ACL-14 dataset are 77.62% and 70.86%, respectively, which are 0.40% and 2.09% lower than those of ConAs-GRNs (NoAtt, Glove). The main reason may be that the heterogeneous graph with a single structure cannot capture the deep multi-scale information in the emotional text, thus resulting in insufficient feature representation. This leads to a lack of emotional dependencies in different aspects within the neighborhood scale. When context semantics and global semantic information are passed across graphs, a lot of detailed information is lost, therefore reducing the interaction between them.
In conclusion, all the components used in the proposed ConAs-GRNs greatly improved the classification performance.
4.5. The Effectiveness of Different Scales and Dimensionality
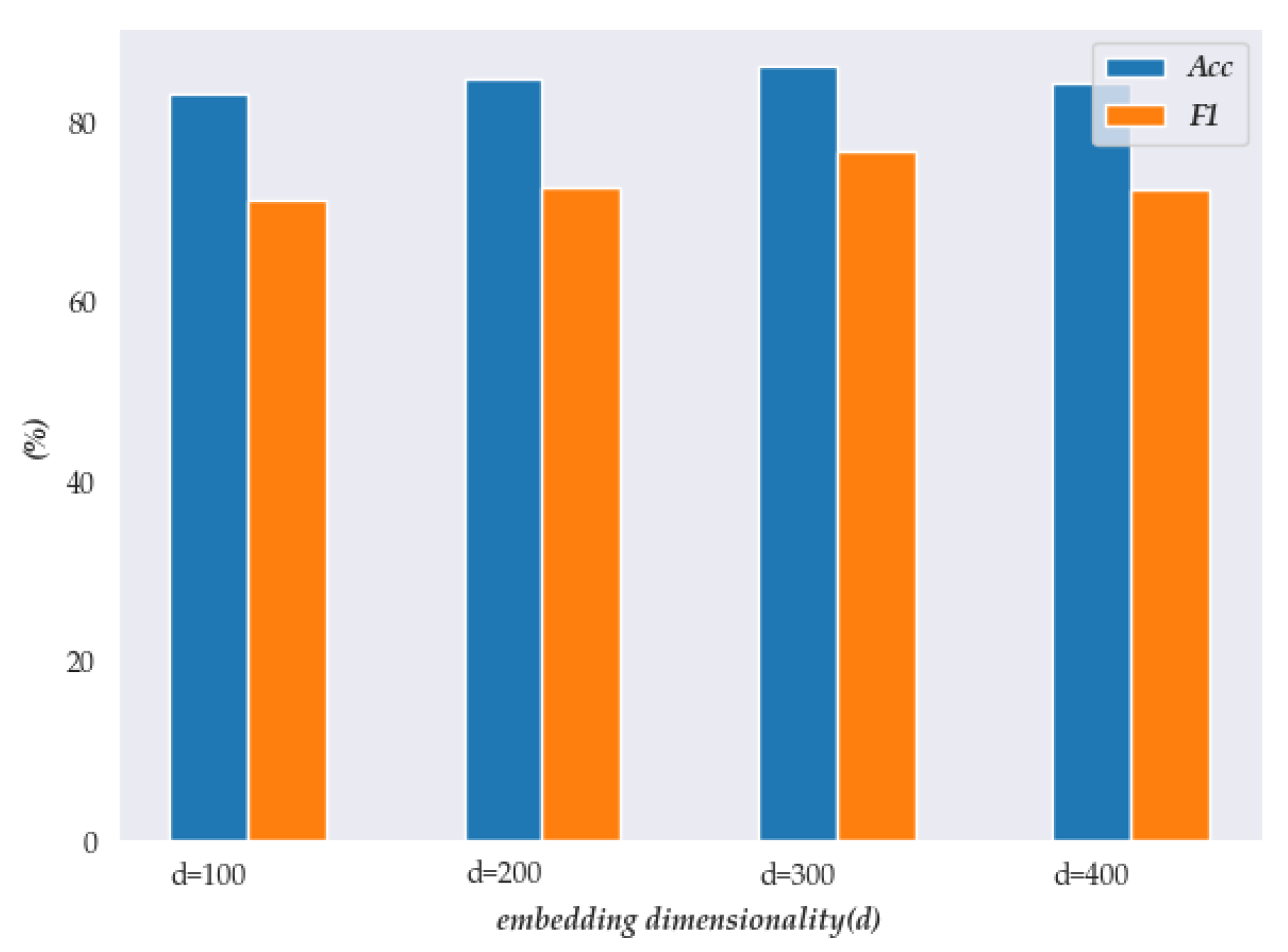
To verify the effectiveness of heterogeneous graphs and embedding dimensions (Bert), we evaluated the proposed ConAs-GRNs on the ACL-14 dataset. The results are shown in
Figure 3, where
indicates the embedding dimensions of a word vector.
In
Figure 3, we can clearly see that as the number of embedding dimensionalities increases, and the classification performance of ConAs-GRNs has a rising trend. For instance,
outperforms
by 1.54% on the two datasets. However, the accuracy is reduced when
. The main reason is that when the dimension of the word vector is large, the features are sparse, and the correlation between emotional words is reduced, which makes it difficult to describe the emotional semantics.
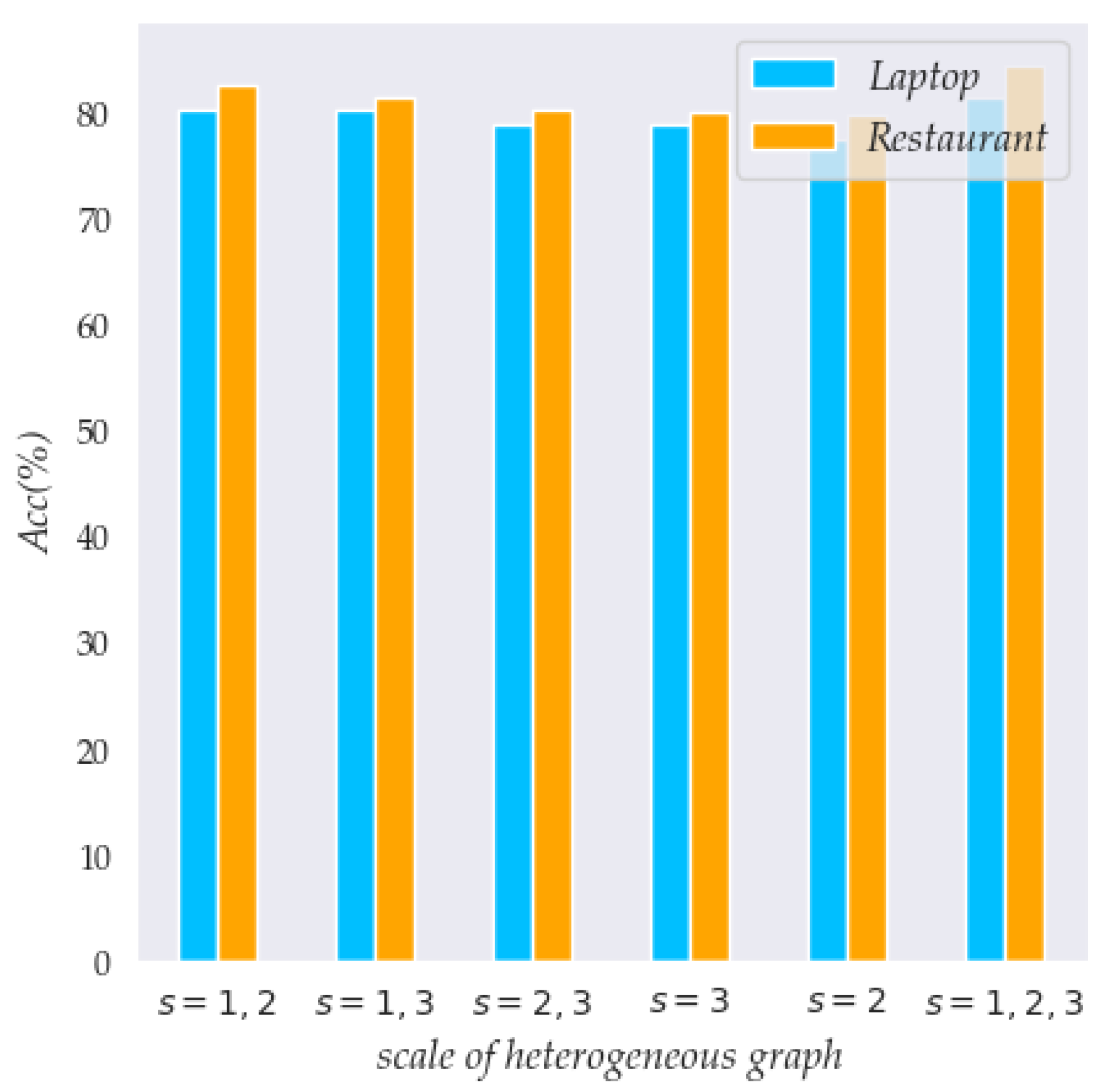
Moreover, we selected the values to investigate the influence on the scale of the heterogeneous graphs.
In
Figure 4, we can clearly see that as the number of heterogeneous graph scales increases, the classification accuracy is significantly improved. For example, the Acc of
significantly outperforms that of
,
, and
on the Laptop dataset, which improved by 1.12%, 1.24%, and 2.49%, respectively. When the scale of the heterogeneous graph is small, it is difficult to obtain rich contextual semantics. Moreover, when the scale is larger, more redundant information is utilized, thus reducing the correlation between different sentiment words.
In addition, we can see that ConAs-GRNs achieved the best performance on the Restaurant datasets when using . This means that multi-scale heterogeneous graphs can strengthen the dependencies between features with different sentiment words and contexts. The experimental results demonstrate the effectiveness of our method.
4.6. The Effectiveness of Different Loss
To demonstrate the effectiveness of our model, we consider the impact of different loss functions on classification performance. The results are shown in
Figure 3, where
represents the multi-class cross-entropy,
aims to suppress the impact of data imbalance,
represents the multi-class dice loss, and
indicates the loss used in our ConAs-GRNs. Then, we can draw the following conclusions:
According to the experimental results of different losses in
Table 4, we can see that:
(1) Compared with and , achieved the best performance on the Laptop and Restaurant datasets. For the Laptop dataset, outperforms by 0.39% and 0.11% respectively. The main reason is that effectively suppresses the imbalance of samples. As a result, the proposed ConAs-GRNs can focus on the difficult-to-classify sentiment samples during training.
(2) Compared with and , the proposed ConAs-GRNs uses the special designed loss function to achieve the best classification performance. For example, the F values are 1.4% and 1.82% higher than and on the Restaurant dataset, respectively. The main reason may be that the weighted loss function can suppress the data imbalance and keep the loss value in a relatively stable range, thus enabling the network to better learn complex emotional text data.
4.7. Experimental Results on Different Amounts of Datasets
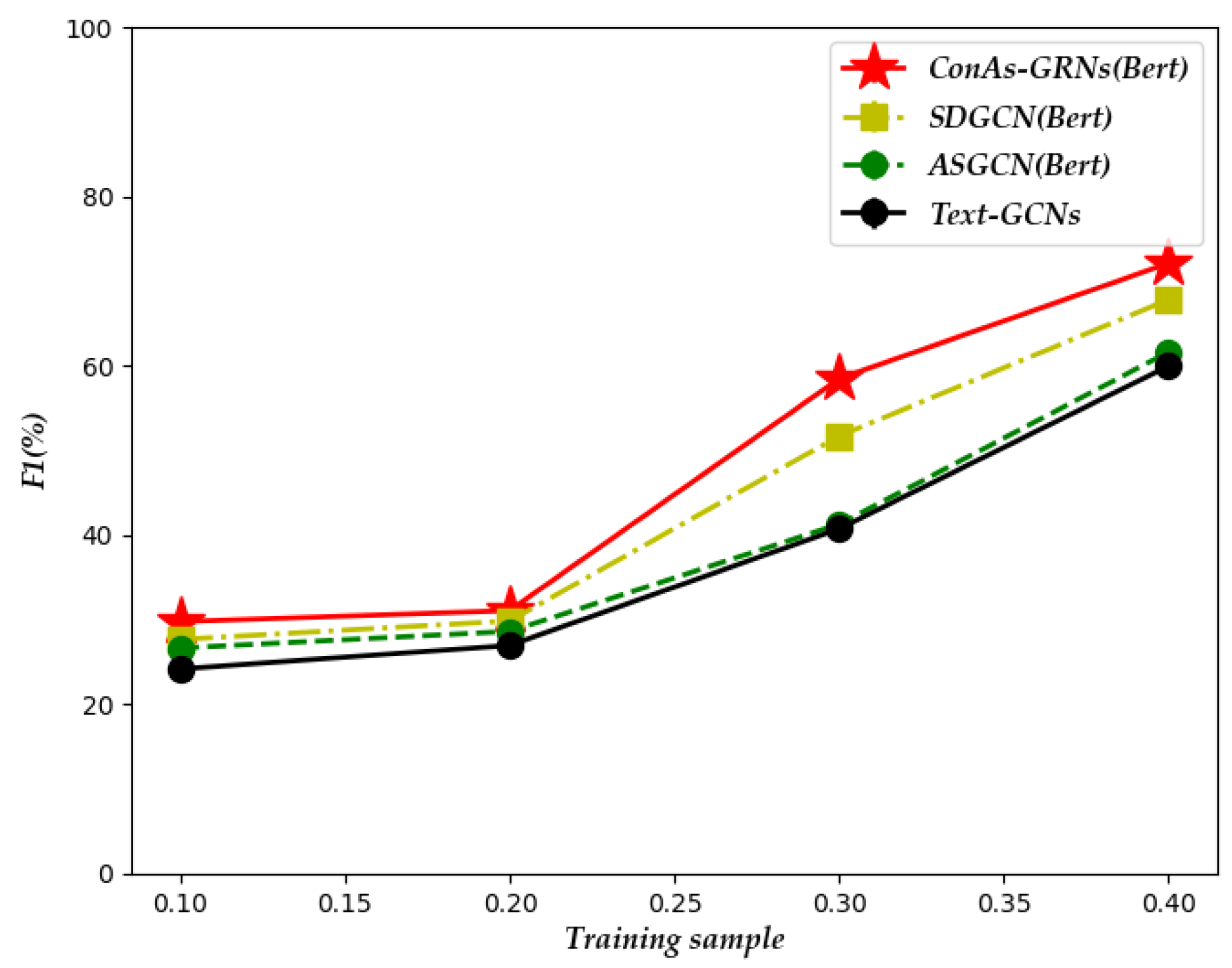
We also conducted an additional study to investigate the impact of the number of training samples. More specifically, for simplicity, all examples were taken from the ACL-14 dataset. We divided the training sample sizes into 10%, 20%, 30%, and 40%.
Figure 5 illustrates the accuracy of ConAs-GRNs with respect to the number of training samples.
As can be seen in
Figure 5, with the increase in the number of training samples, the classification accuracy of all models also improves. The main reason may be that when the number of training samples is large, the classification model can learn more useful knowledge from the samples to obtain more powerful discriminative features. Note that our ConAS-GRNs can achieve the best classification performance even on 10% of the training samples, which indicates that ConAS-GRNs has a strong competitive advantage on small-sample datasets.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}