
Data Augmentation Based on Generative Adversarial Network with Mixed Attention Mechanism

Abstract
:1. Introduction
- (1)
- Through research and experiments, a mixed attention mechanism was introduced into the generator and discriminator so that the GAN can capture structure, texture, and other details of images. Meanwhile, the geometry and distribution of the image can be captured effectively, and more detailed and realistic images can be depicted.
- (2)
- Spectral Normalization (SN) was applied to the generator and discriminator, respectively, to make the training process more stable.
- (3)
- Compared with the baseline method, data generated by the proposed method can efficaciously improve classification accuracy and convergence, indicating that the DA of small sample data is reliable and effective.
2. Related Work
2.1. Generative Adversarial Network
2.2. Deep Convolution Generative Adversarial Network
3. Proposed Method
3.1. Self-Attention Mechanism
3.2. Channel-Attention Mechanism
3.3. Weight Standard Technique of Spectral Normalization
4. Experimental Process and Analysis
4.1. Experimental Datasets
4.2. Experimental Design
4.3. Sample Quantitative Indicators
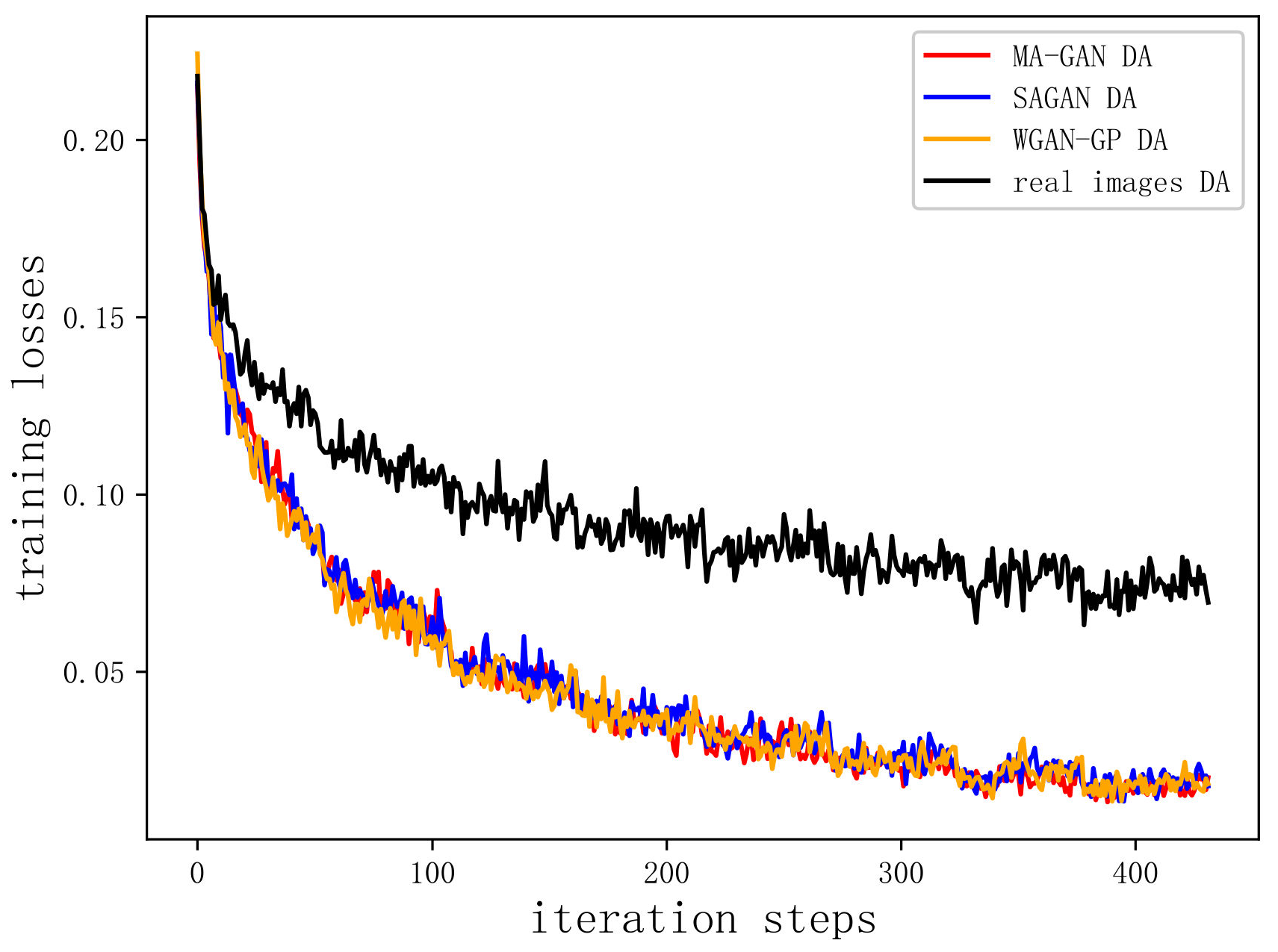
4.4. Experimental Results
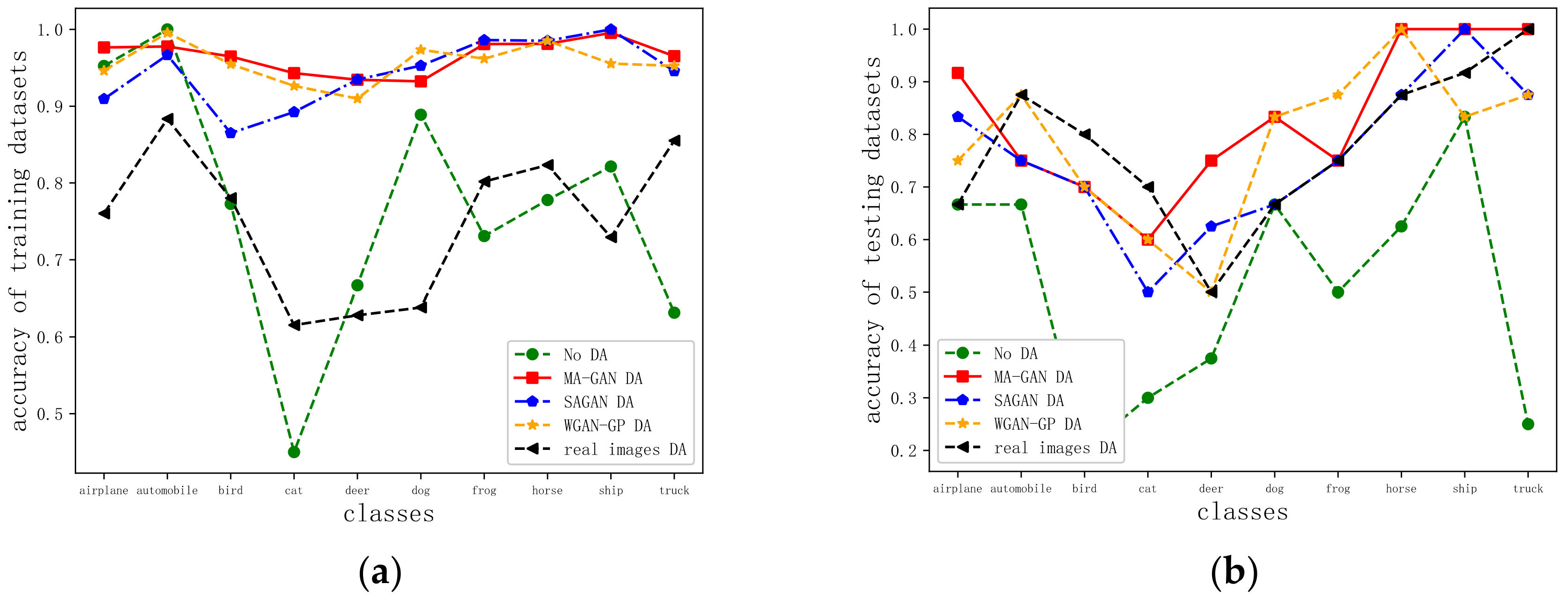
4.5. Classification Performance Analysis
5. Time Efficiency Discussion and Complexity Analysis
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Hong, D.; He, W.; Yokoya, N.; Yao, J.; Gao, L.; Zhang, L.; Chanussot, J.; Zhu, X. Interpretable hyperspectral artificial intelligence: When nonconvex modeling meets hyperspectral remote sensing. IEEE Geosci. Remote Sens. Mag. 2021, 9, 52–87. [Google Scholar] [CrossRef]
- Hong, D.; Gao, L.; Yao, J.; Zhang, B.; Plaza, A.; Chanussot, J. Graph convolutional networks for hyperspectral image classification. IEEE Trans. Geosci. Remote Sens. 2020, 59, 5966–5978. [Google Scholar] [CrossRef]
- Russo, F. An image enhancement technique combining sharpening and noise reduction. IEEE Trans. Instrum. Meas. 2002, 51, 824–828. [Google Scholar] [CrossRef]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial nets. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 7–14 December 2014; pp. 2672–2680. [Google Scholar]
- Arjovsky, M.; Chintala, S.; Bottou, L. Wasserstein generative adversarial networks. In Proceedings of the International Conference on Machine Learning, Sydney, Australia, 6–11 August 2017; pp. 214–223. [Google Scholar]
- Gulrajani, I.; Ahmed, F.; Arjovsky, M.; Dumoulin, V.; Courville, A.C. Improved training of wasserstein gans. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–6 December 2017. [Google Scholar]
- Weaver, N. Lipschitz Algebras; World Scientific: Singapore, 2018. [Google Scholar]
- Miyato, T.; Kataoka, T.; Koyama, M.; Yoshida, Y. Spectral Normalization for Generative Adversarial Networks. In Proceedings of the International Conference on Learning Representations, Vancouver, BC, Canada, 30 April–30 May 2018. [Google Scholar]
- Fukushima, K. A self-organizing neural network model for a mechanism of pattern recognition unaffected by shift in position. Biol. Cybern. 1980, 36, 193–202. [Google Scholar] [CrossRef] [PubMed]
- Radford, A.; Metz, L.; Chintala, S. Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks. In Proceedings of the International Conference on Learning Representations, San Juan, Puerto Rico, 2–4 May 2016. [Google Scholar]
- Karras, T.; Aila, T.; Laine, S.; Lehtinen, J. Progressive Growing of GANs for Improved Quality, Stability, and Variation. In Proceedings of the International Conference on Learning Representations, Toulon, France, 24–26 April 2017. [Google Scholar]
- Karras, T.; Laine, S.; Aila, T. A style-based generator architecture for generative adversarial networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 4401–4410. [Google Scholar]
- Karras, T.; Laine, S.; Aittala, M.; Hellsten, J.; Lehtinen, J.; Aila, T. Analyzing and improving the image quality of stylegan. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 8110–8119. [Google Scholar]
- Shaham, T.R.; Dekel, T.; Michaeli, T. Singan: Learning a generative model from a single natural image. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Long Beach, CA, USA, 16–20 June 2019; pp. 4570–4580. [Google Scholar]
- Hinz, T.; Fisher, M.; Wang, O.; Wermter, S. Improved techniques for training single-image gans. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Virtual, 5–9 January 2021; pp. 1300–1309. [Google Scholar]
- Menon, S.; Damian, A.; Hu, S.; Ravi, N.; Rudin, C. Pulse: Self-supervised photo upsampling via latent space exploration of generative models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 2437–2445. [Google Scholar]
- Huang, S.W.; Lin, C.T.; Chen, S.P.; Wu, Y.; Hsu, P.; Lai, S. Auggan: Cross domain adaptation with gan-based data augmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 718–731. [Google Scholar]
- Antreas, A.; Amos, S.; Edwards, H. Data Augmentation generative adversarial networks. In Proceedings of the International Conference on Learning Representations, Vancouver, BC, Canada, 16 February 2018. [Google Scholar]
- Frid-Adar, M.; Klang, E.; Amitai, M.; Jacob Goldberger, H.G. Synthetic data augmentation using GAN for improved liver lesion classification. In Proceedings of the 2018 IEEE 15th International Symposium on Biomedical Imaging, Washington, DC, USA, 8 January 2018; pp. 289–293. [Google Scholar]
- Zheng, Z.; Yang, X.; Yu, Z.; Zheng, L.; Yang, Y.; Kaut, j. Joint discriminative and generative learning for person re-identification. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 2138–2147. [Google Scholar]
- Li, L.; Li, Y.; Wu, C.; Dong, H.; Jiang, P.; Wang, F. Detail Fusion GAN: High-Quality Translation for Unpaired Images with GAN-based Data Augmentation. In Proceedings of the 25th International Conference on Pattern Recognition, IEEE, Milan, Italy, 10–15 January 2021; pp. 1731–1736. [Google Scholar]
- Li, X.; Du, Z.; Huang, Y.; Tan, Z. A deep translation (GAN) based change detection network for optical and SAR remote sensing images. ISPRS J. Photogramm. Remote Sens. 2021, 179, 14–34. [Google Scholar] [CrossRef]
- Yu, X.; Wu, X.; Luo, C.; Ren, P. Deep learning in remote sensing scene classification: A data augmentation enhanced convolutional neural network framework. GIScience Remote Sens. 2017, 54, 741–758. [Google Scholar] [CrossRef] [Green Version]
- Liang, B.; Liu, Q.; Xu, J. Target specific emotion analysis based on multi attention convolutional neural network. Comput. Res. Dev. 2017, 54, 1724–1735. [Google Scholar]
- Zhu, Z.; Rao, Y.; Wu, Y. Research progress of attention mechanism in deep learning. Chin. J. Inf. 2019, 33, 1–11. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention is all you need. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 7132–7141. [Google Scholar]
- Zhang, H.; Goodfellow, I.; Metaxas, D.; Odena, A. Self-attention generative adversarial networks. In Proceedings of the International Conference on Machine Learning, Long Beach, CA, USA, 10–14 June 2019; pp. 7354–7363. [Google Scholar]
- Yang, Y.; Sun, L.; Mao, X.; Dai, L.; Guo, S.; Liu, P. Using Generative Adversarial Networks Based on Dual Attention Mechanism to Generate Face Images. In Proceedings of the 2021 International Conference on Computer Technology and Media Convergence Design IEEE, Sanya, China, 23–25 April 2021; pp. 14–19. [Google Scholar]
- Liu, Z.; Luo, P.; Wang, X.; Tang, X. Large-Scale Celebfaces Attributes (Celeba) Dataset. Available online: https://mmlab.ie.cuhk.edu.hk/projects/CelebA.html (accessed on 21 February 2022).
- Krizhevsky, A. Learning Multiple Layers of Features from Tiny Images. Master’s Thesis, The Pennsylvania State University, State College, PA, USA, 2009. [Google Scholar]
- Kingma, P.; Ba, J. Adam: A method for stochastic optimization. In Proceedings of the International Conference on Learning Representations, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Barratt, S.; Sharma, R. A note on the inception score. arXiv 2018, arXiv:1801.01973. [Google Scholar]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Input | Operation | Output |
|---|---|---|
| — | ConvTranspose2d (100, 512, k = 4 × 4, s = 1) SN + BN + channel-attention + ReLU | 4 × 4 × 512 |
| 4 × 4 × 512 | ConvTranspose2d (512, 256, k = 4 × 4, s = 2) SN + BN + channel-attention + ReLU | 8 × 8 × 256 |
| 8 × 8 × 256 | ConvTranspose2d (256, 128, k = 4 × 4, s = 2) SN + BN + ReLU | 16 × 16 × 128 |
| 16 × 16 × 128 | +self-attention | 16 × 16 × 128 |
| 16 × 16 × 128 | ConvTranspose2d (128, 64, k = 4 × 4, s = 2) SN + BN + ReLU | 32 × 32 × 64 |
| 32 × 32 × 64 | +self-attention | 32 × 32 × 64 |
| 32 × 32 × 64 | ConvTranspose2d (64, 3, k = 4 × 4, s = 2) Tanh | 64 × 64 × 3 |
| Input | Operation | Output |
|---|---|---|
| 64 × 64 × 3 | Conv2d (3, 64, k = 4 × 4, s = 2) SN + channel-attention + LeakyReLU | 32 × 32 × 64 |
| 32 × 32 × 64 | Conv2d (64, 128, k = 4 × 4, s = 2) SN + channel-attention + LeakyReLU | 16 × 16 × 128 |
| 16 × 16 × 128 | Conv2d (128, 256, k = 4 × 4, s = 2) SN + LeakyReLU | 8 × 8 × 256 |
| 8 × 8 × 256 | +self-attention | 8 × 8 × 256 |
| 8 × 8 × 256 | Conv2d (256, 512, k = 4 × 4, s = 2) SN + LeakyReLU | 4 × 4 × 512 |
| 4 × 4 × 512 | +self-attention | 4 × 4 × 512 |
| 4 × 4 × 512 | Conv2d (512, 1, k = 4 × 4, s = 1) | — |
| Input | Operation | Output |
|---|---|---|
| — | ConvTranspose2d (100, 256, k = 4 × 4, s = 1) SN + BN + channel-attention + ReLU | 4 × 4 × 256 |
| 4 × 4 × 256 | ConvTranspose2d (256, 128, k = 4 × 4, s = 2, p = 1) SN + BN + channel-attention + ReLU | 8 × 8 × 128 |
| 8 × 8 × 128 | +self-attention | 8 × 8 × 128 |
| 8 × 8 × 128 | ConvTranspose2d (128, 64, k = 4 × 4, s = 2, p = 1) SN + BN + ReLU | 16 × 16 × 64 |
| 16 × 16 × 64 | +self-attention | 16 × 16 × 64 |
| 16 × 16 × 64 | ConvTranspose2d (64, 3, k = 4 × 4, s = 2, p = 1) Tanh | 32 × 32 × 3 |
| Input | Operation | Output |
|---|---|---|
| 32 × 32 × 3 | Conv2d (3, 64, k = 4 × 4, s = 2, p = 1) SN + channel-attention + LeakyReLU | 16 × 16 × 64 |
| 16 × 16 × 64 | Conv2d (64, 128, k = 4 × 4, s = 2, p = 1) SN + channel-attention + LeakyReLU | 8 × 8 × 128 |
| 8 × 8 × 128 | +Self-Attention | 8 × 8 × 128 |
| 8 × 8 × 128 | Conv2d (128, 256, k = 4 × 4, s = 2, p = 1) SN + LeakyReLU | 4 × 4 × 256 |
| 4 × 4 × 256 | +self-attention | 4 × 4 × 256 |
| 4 × 4 × 256 | Conv2d (256, 1, k = 4 × 4) | — |
| Input | Operation | Output |
|---|---|---|
| — | ConvTranspose2d (100, 512, k = 3 × 3, s = 1, p = 0) SN + BN + Channel-Attention + ReLU | 3 × 3 × 512 |
| 3 × 3 × 512 | ConvTranspose2d (512, 256, k = 5 × 5, s = 2, p = 1) SN + BN + Channel-Attention + ReLU | 7 × 7 × 256 |
| 7 × 7 × 256 | +Self-Attention | 7 × 7 × 256 |
| 7 × 7 × 256 | ConvTranspose2d (256, 128, k = 5 × 5, s = 2, outpadding = 1) SN + BN + ReLU | 14 × 14 × 128 |
| 14 × 14 × 128 | +Self-Attention | 14 × 14 × 128 |
| 14 × 14 × 128 | ConvTranspose2d (128, 1, k = 5 × 5, s = 2, p = 2, outpadding = 1) Tanh | 28 × 28 × 1 |
| Input | Operation | Output |
|---|---|---|
| 28 × 28 × 1 | Conv2d (1, 128, k = 5 × 5, s = 2, p = 2) SN + channel-attention + LeakyReLU | 14 × 14 × 128 |
| 14 × 14 × 128 | Conv2d (128, 256, k = 5 × 5, s = 2, p = 2) SN + channel-attention + LeakyReLU | 7 × 7 × 256 |
| 7 × 7 × 256 | +self-attention | 7 × 7 × 256 |
| 7 × 7 × 256 | Conv2d (256, 512, k = 5 × 5, s = 2, p = 1) SN + LeakyReLU | 3 × 3 × 512 |
| 3 × 3 × 512 | +self-attention | 3 × 3 × 512 |
| 3 × 3 × 512 | Conv2d (512, 1, k = 3 × 3, s = 1, p = 0) | — |
| Item | Configuration |
|---|---|
| CPU | Intel (R) Core (TM) i7-10700K CPU@3.80 GHz |
| GPU | NVIDIA GeForce RTX 2080 SUPER |
| GPU memory | 8 G |
| OS | Windows 10 64 bits |
| Language | Python 3.6 |
| Framework | PyTorch |
| IDE | PyCharm |
| Model | IS |
|---|---|
| WGAN-GP | 2.189 |
| SAGAN | 2.238 |
| MA-GAN | 2.315 |
| Class | WGAN-GP | SAGAN | MA-GAN |
|---|---|---|---|
| air-plane | 3.738 | 3.756 | 3.958 |
| automobile | 3.156 | 3.273 | 3.552 |
| bird | 3.018 | 3.042 | 3.374 |
| cat | 2.990 | 2.971 | 3.066 |
| deer | 2.491 | 2.627 | 2.920 |
| dog | 3.354 | 3.523 | 3.635 |
| frog | 2.496 | 2.506 | 2.594 |
| horse | 3.426 | 3.619 | 3.755 |
| ship | 3.206 | 3.073 | 3.273 |
| truck | 2.853 | 3.099 | 3.200 |
| Class | No DA | Real Images DA | WGAN-GP DA | SAGAN DA | MA-GAN DA |
|---|---|---|---|---|---|
| 0 | 100.00 | 100.00 | 100.00 | 99.12 | 100.00 |
| 1 | 96.00 | 100.00 | 100.00 | 100.00 | 100.00 |
| 2 | 100.00 | 98.17 | 99.11 | 99.07 | 100.00 |
| 3 | 96.30 | 99.08 | 100.00 | 99.04 | 100.00 |
| 4 | 95.45 | 99.08 | 96.97 | 100.00 | 100.00 |
| 5 | 100.00 | 98.21 | 98.52 | 97.98 | 98.33 |
| 6 | 100.00 | 100.00 | 99.07 | 100.00 | 100.00 |
| 7 | 100.00 | 100.00 | 96.12 | 99.00 | 100.00 |
| 8 | 86.96 | 98.39 | 99.12 | 100.00 | 100.00 |
| 9 | 100.00 | 96.58 | 100.00 | 99.04 | 100.00 |
| average accuracy | 97.06 | 98.51 | 99.02 | 99.64 | 99.71 |
| Class | No DA | Real Images DA | WGAN-GP DA | SAGAN DA | MA-GAN DA |
|---|---|---|---|---|---|
| 0 | 91.67 | 100.00 | 100.00 | 100.00 | 100.00 |
| 1 | 100.00 | 100.00 | 100.00 | 100.00 | 100.00 |
| 2 | 90.00 | 100.00 | 100.00 | 90.00 | 90.00 |
| 3 | 90.00 | 90.00 | 90.00 | 100.00 | 90.00 |
| 4 | 100.00 | 100.00 | 100.00 | 100.00 | 100.00 |
| 5 | 91.67 | 100.00 | 100.00 | 100.00 | 91.67 |
| 6 | 87.50 | 100.00 | 87.50 | 87.50 | 87.50 |
| 7 | 87.50 | 87.50 | 75.00 | 87.50 | 100.00 |
| 8 | 75.00 | 100.00 | 100.00 | 91.67 | 91.67 |
| 9 | 100.00 | 100.00 | 100.00 | 100.00 | 100.00 |
| average accuracy | 94.07 | 97.87 | 96.27 | 96.27 | 96.73 |
| Class | No DA | Real Images DA | WGAN-GP DA | SAGAN DA | MA-GAN DA |
|---|---|---|---|---|---|
| airplane | 95.24 | 76.72 | 94.63 | 90.95 | 97.65 |
| automobile | 100.00 | 88.35 | 99.56 | 96.67 | 97.78 |
| bird | 77.27 | 78.02 | 95.48 | 86.50 | 96.48 |
| cat | 45.00 | 61.54 | 92.65 | 89.24 | 94.31 |
| deer | 66.67 | 62.82 | 90.99 | 93.47 | 93.44 |
| dog | 88.89 | 63.84 | 97.35 | 95.28 | 93.24 |
| frog | 73.08 | 80.18 | 96.19 | 98.61 | 98.10 |
| horse | 77.78 | 82.33 | 98.52 | 98.52 | 98.12 |
| ship | 82.14 | 72.94 | 95.55 | 100.00 | 99.55 |
| truck | 63.16 | 85.51 | 95.26 | 94.57 | 96.52 |
| average accuracy | 72.31 | 76.34 | 95.27 | 94.80 | 96.15 |
| Class | No DA | Real Images DA | WGAN-GP DA | SAGAN DA | MA-GAN DA |
|---|---|---|---|---|---|
| airplane | 66.67 | 66.67 | 75.00 | 83.33 | 91.67 |
| automobile | 66.67 | 87.50 | 87.50 | 75.00 | 75.00 |
| bird | 20.00 | 80.00 | 70.00 | 70.00 | 70.00 |
| cat | 30.00 | 70.00 | 60.00 | 50.00 | 60.00 |
| deer | 37.50 | 50.00 | 50.00 | 62.50 | 75.00 |
| dog | 66.67 | 66.67 | 83.33 | 66.67 | 83.33 |
| frog | 50.00 | 75.00 | 87.50 | 75.00 | 75.00 |
| horse | 62.50 | 87.50 | 100.00 | 87.50 | 100.00 |
| ship | 83.33 | 91.67 | 83.33 | 100.00 | 100.00 |
| truck | 25.00 | 100.00 | 87.50 | 87.50 | 100.00 |
| average accuracy | 51.20 | 75.93 | 74.33 | 76.20 | 79.47 |
| Dataset | WGAN-GP | SAGAN | MA-GAN | |
|---|---|---|---|---|
| CelebA | epoch | 200,000 | 200,000 | 200,000 |
| data size | 100,000 | 100,000 | 100,000 | |
| training time (hour) | 5.2 | 8 | 12 | |
| CIFAR-10 | epoch | 200,000 | 200,000 | 200,000 |
| data size (each class) | 500 | 500 | 500 | |
| training time (hour) | 11.9 | 15.1 | 16 | |
| MNIST | epoch | 2000 | 2000 | 2000 |
| data size (each class) | 500 | 500 | 500 | |
| training time (hour) | 0.13 | 0.17 | 0.2 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yang, Y.; Sun, L.; Mao, X.; Zhao, M. Data Augmentation Based on Generative Adversarial Network with Mixed Attention Mechanism. Electronics 2022, 11, 1718. https://doi.org/10.3390/electronics11111718
Yang Y, Sun L, Mao X, Zhao M. Data Augmentation Based on Generative Adversarial Network with Mixed Attention Mechanism. Electronics. 2022; 11(11):1718. https://doi.org/10.3390/electronics11111718
Chicago/Turabian StyleYang, Yu, Lei Sun, Xiuqing Mao, and Min Zhao. 2022. "Data Augmentation Based on Generative Adversarial Network with Mixed Attention Mechanism" Electronics 11, no. 11: 1718. https://doi.org/10.3390/electronics11111718