
IMapC: Inner MAPping Combiner to Enhance the Performance of MapReduce in Hadoop



Abstract
:1. Introduction
- (a)
- The map function is customized by the user based on their requirements. This method splits the input into key and value pairs and generates intermediate key and value pairs.
- (b)
- The reduce function accepts the intermediate output results from mappers and combines them to produce a smaller value set.
- The MapReduce execution flow is modified and is implemented on top of TFR. The source code of the mapper class is customized to implement IMapC.
- The following changes are done in the mapper code:
- (a)
- Whenever the map tasks produce the intermediate key-value pairs, a filtering method is used for repeating keys. All key-value pairs are stored in the HashMap array and each generated new keys are compared with the existing key.
- (b)
- The filtered intermediate key-value pairs from the map phase are stored in the redis instances by customizing the input and output formats.
- We evaluated the TFR with DC of IMapC using different benchmarking workloads namely WordCount and Sort. HiBench benchmarking tool is used to perform a comparison between Hadoop, TFR, and previous work, In-node combiner (INC).
2. Literature Survey
3. Methodology
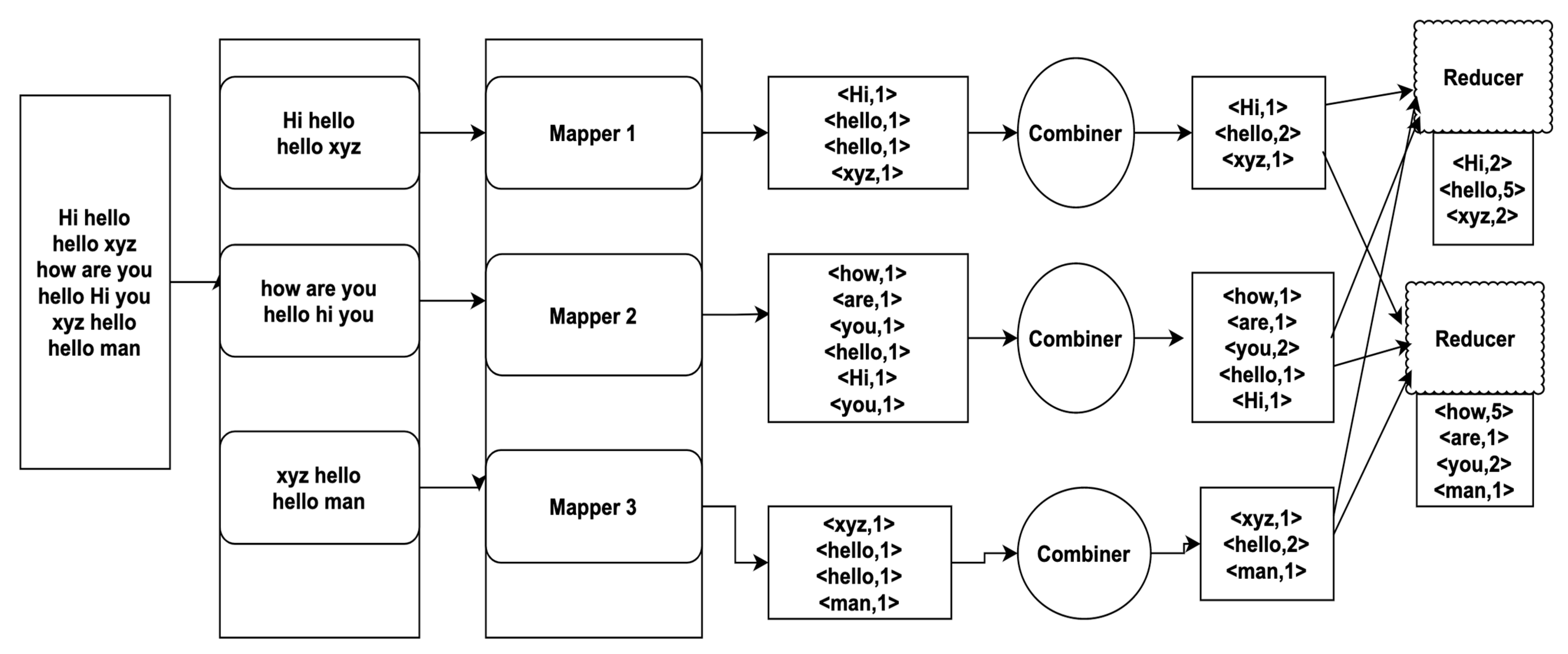
- User submits the job.
- The input key-value pairs are split into independent records and are assigned to each map tasks.
- Each mapper generates huge amount of intermediate key-value pairs.
- The output from the mappers is directly sent to the Redis Instances.
- Shuffling and Sorting are performed by fetching from the Redis Instances.
- The sorted results are stored in the Redis Instances.
- Reduce tasks fetch the mappers results from the Redis Instances and performs reducing on the sorted data.
- The final reduced output is stored in HDFS.
- User submits the job. During a MapReduce job, data is stored in input files. HDFS is the storage location for input files.
- Java MR API provide a java class called JobClient that allows the user to interact with the cluster. This class is responsible for creating the task based on input data. InputSplits are created and each map task takes one InputSplit.
- The task is submitted to the MapReduce job controller (MR Job Controller) which is responsible to assign the job to the mappers and reducers.
- Each map task performs the execution and produces intermediate key-value pairs.
- From the generated intermediate key-value pairs, the keys that are recurring inside the map task are identified and are stored inside the mapper in the HashMap array.
- The output results from the filtering method are stored in the Redis instances.
- The reducer node fetches the Mappers output from the Redis instance and performs the sorting operation.
- The sorted data is recorded in the Redis instances.
- The sorted intermediate key-value pairs are applied with the reduce function and produces the final reduced results.
- The output of the reduce tasks are stored in HDFS.
| Algorithm 1: Proposed Map function |
| Input (K1, V1) Output (K2, V2) Begin 1: L <- New HashMap 2: Execute Map function 3: for each (K1, V1) pair do 4: Generate intermediate (K2, V2) 5: if generated K2 ∊ L, then 6: intermediate value V2 of Emitted Key K2 is combined with the previous value 7: else 8: L <- keys and values 9: end if 10: end for 11: End |
- OutputFormat in Hadoop: The output configuration of a MapReduce job is checked. RecordWriter implementation is provided to write the unfiltered mapper’s output results to the filesystem.
- OutputFormat in proposed: RedisHashOutputFormat is used to set up the input job configuration to verify the job configuration, and to specify the Redis instance nodes as well as the Redis hash key to write all output. It creates the RecordWriter to serialize all the output key-value pairs after the job has been submitted. In general, this is a file in HDFS. However, HDFS is not used for storing these intermediate results. To create an instance of a RecordWriter for the map and reduce task, the getRecordWriter method is used on the back end. This record writer is a nested class of the RedisHashOutputFormat class [24,25]. The getOutputCommitter method is used in the Hadoop framework to manage any temporary results before committing in case the task fails or needs re-execution.
- RecordWriter in Hadoop: RecordWriter class writes the intermediate <key, value> pairs to a file system. It takes two functions such as ‘Write’ and ‘Close.’ The ‘write’ function writes the filtered key-value pairs from the map phase to the local disk. The ‘close’ function closes the Hadoop data stream to the output file
- RecordWriter in proposed: A RedisHashRecordWriter class is used to enable data to be written to the Redis cache, and a RedisHashRecordWriter class is used to handle the connections to the Redis server through the Jedis client. In this case, all key-value pairs are evenly distributed across all Redis nodes after the intermediate key-value pairs have been filtered. In order to write to Redis, a constructor is created to store the hash key. Finally, Jedis instance is connected and maps it to an integer. Write method is used to get the assigned Jedis instance. The hash code [26,27] is used as a key which is taken modulo the number of configured Redis instances. The key-value pair is then written to the returned Jedis instance to the configured hash. All Jedis instances are disconnected finally, using the close method.
4. Results
- Standard WordCount/Sort without combiners
- WordCount/Sort with inner mapping combiner method
- Standard WordCount/Sort with default combiner
- WordCount/Sort with both inner mapping combiner and default combiner
4.1. Performance comparison of IMapC in Standard Hadoop
4.2. Performance Comparison of IMapC in TFR
4.3. Computational Complexity
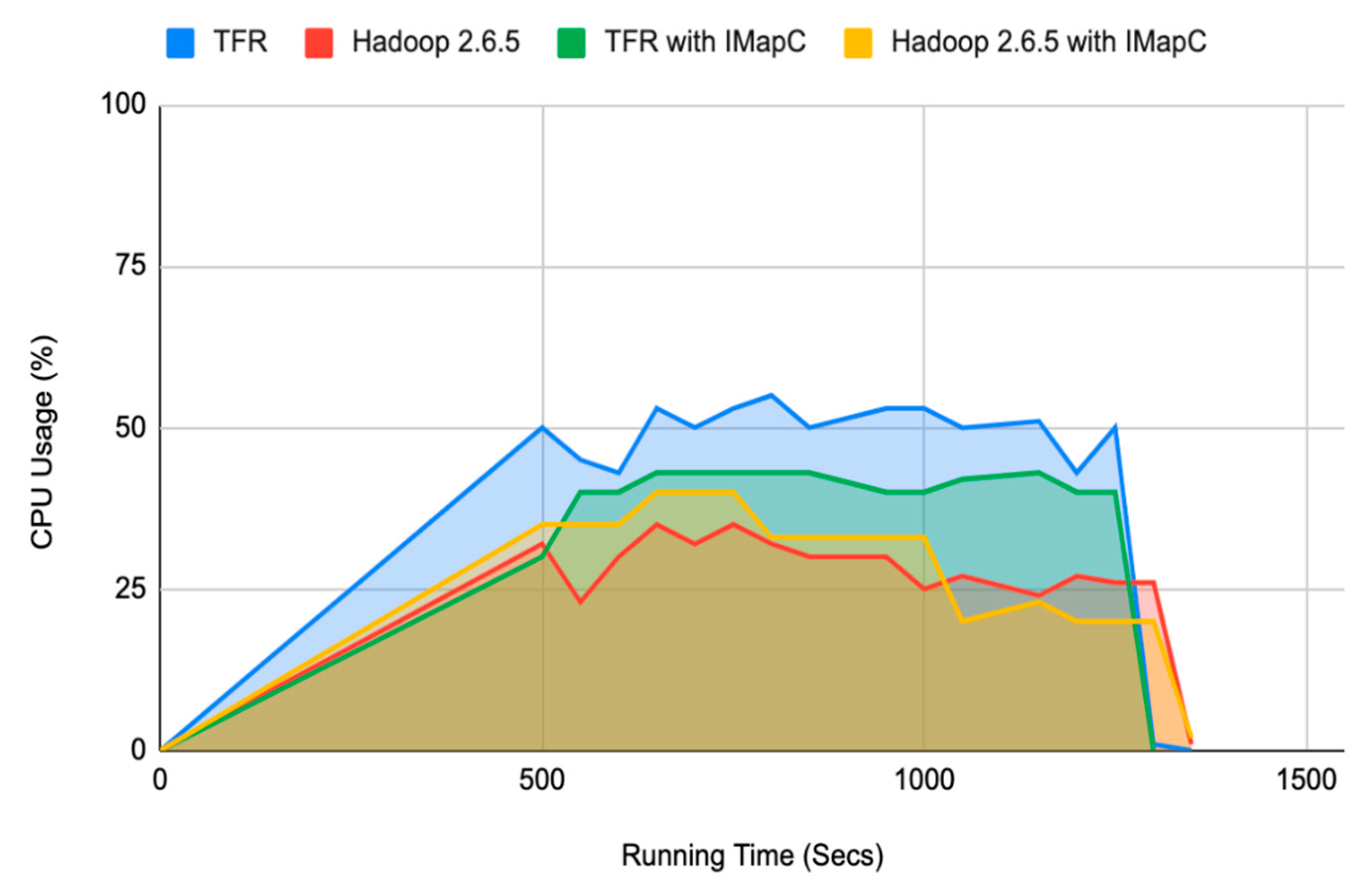
4.3.1. CPU Usage
4.3.2. Memory Usage
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Jeyaraj, R.; Ananthanarayana, V.S. Multi-level per node combiner (MLPNC) to minimize MapReduce job latency on virtualized environment. In Proceedings of the ACM Symposium on Applied Computing, Pau, France, 9–13 April 2018; pp. 167–174. [Google Scholar]
- Vinutha, D.C.; Raju, G.T. In-Memory Cache and Intra-Node Combiner Approaches for Optimizing Execution Time in High-Performance Computing. SN Comput. Sci. 2020, 1, 98. [Google Scholar] [CrossRef] [Green Version]
- Shishir, M.N.S.; Yousuf, M.A. Performance Enhancement of Hadoop MapReduce by Combining Data Inside the Mapper. In Proceedings of the International Conference on Robotics, Electrical and Signal Processing Techniques (ICREST), Dhaka, Bangladesh, 5–7 January 2021. [Google Scholar]
- Kavitha, C.; Anita, X. Task failure resilience technique for improving the performance of MapReduce in Hadoop. ETRI J. 2020, 42, 748–760. [Google Scholar] [CrossRef]
- Zhang, Y.; Liu, D. Improving the efficiency of storing for small files in hdfs. In Proceedings of the 2012 International Conference on Computer Science and Service System, CSSS, Nanjing, China, 11–13 August 2012; pp. 2239–2242. [Google Scholar]
- Zhang, H.; Wang, L.; Huang, H. SMARTH: Enabling multi-pipeline data transfer in HDFS. In Proceedings of the International Conference on Parallel Processing, Minneapolis, MN, USA, 9–12 September 2014; pp. 30–39. [Google Scholar]
- Dean, J.; Ghemawat, S. MapReduce: Simplified Data Processing on Large Clusters. In Proceedings of the OSDI’04: Sixth Symposium on Operating System Design and Implementation, San Francisco, CA, USA, 6–8 December 2004; pp. 137–150. [Google Scholar]
- Lee, S.; Jo, J.Y.; Kim, Y. Performance improvement of MapReduce process by promoting deep data locality. In Proceedings of the IEEE International Conference on Data Science and Advanced Analytics, DSAA 2016, Montreal, Canada, 17–19 October 2016; pp. 292–301. [Google Scholar]
- Kavitha, C.; Lakshmi, R.S.; Devi, J.A.; Pradheeba, U. Evaluation of worker quality in crowdsourcing system on Hadoop platform. Int. J. Reason.-Based Intell. Syst. 2019, 11, 181–185. [Google Scholar] [CrossRef]
- Guo, Y.; Rao, J.; Cheng, D.; Zhou, X. iShuffle: Improving hadoop performance with shuffle-on-write. IEEE Trans. Parallel Distrib. Syst. 2017, 28, 1649–1662. [Google Scholar] [CrossRef]
- Lee, W.H.; Jun, H.; Kim, H.J. Hadoop MapReduce Performance Enhancement Using In-Node Combiners. Int. J. Comput. Sci. Inf. Technol. 2015, 7, 1–17. [Google Scholar] [CrossRef]
- Lu, X.; Islam, N.S.; Wasi-Ur-Rahman, M.; Jose, J.; Subramoni, H.; Wang, H.; Panda, D.K. High-Performance design of Hadoop RPC with RDMA over InfiniBand. In Proceedings of the International Conference on Parallel Processing, Lyon, France, 1–4 October 2013; pp. 641–650. [Google Scholar]
- Zhang, J.; Wu, G.; Hu, X.; Wu, X. A distributed cache for hadoop distributed fle system in real-time cloud services. In 2012 ACM/IEEE 13th International Conference on Grid Computing; IEEE: Piscataway, NJ, USA, 2012; pp. 12–21. [Google Scholar]
- Pinto, V.F. In Trend Analysis using Hadoop’s MapReduce Framework. In Proceedings of the 2017 2nd International Conference on Computational Systems and Information Technology for Sustainable Solution (CSITSS), Bangalore, India, 21–23 December 2017; pp. 1–5. [Google Scholar]
- Ananthanarayanan, G.; Ghodsi, A.; Warfield, A.; Borthakur, D.; Kandula, S.; Shenker, S.; Stoica, I. PACMan: Coordinated memory caching for parallel jobs. In Proceedings of the 9th USENIX Conference on Networked Systems Design and Implementation; USENIX Association: Berkeley, CA, USA; pp. 1–14.
- Senthilkumar, K.; Satheeshkumar, K.; Chandrasekaran, S. Performance enhancement of data processing using multiple intelligent cache in hadoop. Int. J. Inf. Educ. Technol. 2014, 159–164. Available online: http://citeseerx.ist.psu.edu/viewdoc/summary?doi=10.1.1.647.320 (accessed on 28 March 2022).
- Crume, A.; Buck, J.; Maltzahn, C.; Brandt, S. Compressing intermediate keys between mapper and reducers in scihadoop. In IEEE SC Companion: High Performance Computing, Networking Storage and Analysis; IEEE: Piscataway, NJ, USA, 2013; pp. 1–6. [Google Scholar]
- Lin, J.; Schatz, M. Design patterns for efficient graph algorithms in MapReduce. In Proceedings of the Eighth Workshop on Mining and Learning with Graphs, Washington, DC, USA, 24–25 July 2010; pp. 78–85. [Google Scholar]
- Ke, H.; Li, P.; Guo, S.; Stojmenovic, I. Aggregation on the fy: Reducing trafc for big data in the cloud. IEEE Netw. 2015, 29, 17–23. [Google Scholar] [CrossRef]
- Dean, J.; Ghemawat, S. MapReduce: Simplifed data processing on large clusters. Commun. ACM 2008, 51, 107–113. [Google Scholar] [CrossRef]
- Dev, K.; Maddikunta, P.K.R.; Gadekallu, T.R.; Bhattacharya, S.; Hegde, P.; Singh, S. Energy Optimization for Green Communication in IoT Using Harris Hawks Optimization. In IEEE Transactions on Green Communications and Networking; IEEE: Piscataway, NJ, USA, 2019. [Google Scholar] [CrossRef]
- Roy, A.K.; Nath, K.; Srivastava, G.; Gadekallu, T.R.; Lin, J.C.-W. Privacy Preserving Multi-Party Key Exchange Protocol for Wireless Mesh Networks. Sensors 2022, 22, 1958. [Google Scholar] [CrossRef] [PubMed]
- Alazab, M.; Lakshmanna, K.; Reddy, T.; Pham, Q.V.; Maddikunta, P.K.R. Multi-objective cluster head selection using fitness averaged rider optimization algorithm for IoT networks in smart cities. Sustain. Energy Technol. Assess. 2021, 43, 100973. [Google Scholar] [CrossRef]
- Kavitha, C.; Anita, X.; Selvan, S. Improving the efficiency of speculative execution strategy in hadoop using amazon elasticache for redis. J. Eng. Sci. Technol. 2021, 16, 4864–4878. [Google Scholar]
- Mani, V.; Kavitha, C.; Band, S.S.; Mosavi, A.; Hollins, P.; Palanisamy, S. A Recommendation System Based on AI for Storing Block Data in the Electronic Health Repository. Front. Public Health 2022, 9, 831404. [Google Scholar] [CrossRef] [PubMed]
- Kavitha, C.; Mani, V.; Srividhya, S.R.; Khalaf, O.I.; Romero, C.A.T. Early-Stage Alzheimer’s Disease Prediction Using Machine Learning Models. Front. Public Health 2022, 10, 853294. [Google Scholar] [CrossRef] [PubMed]
- Vidhya, S.R.S.; Arunachalam, A.R. Automated Detection of False positives and false negatives in Cerebral Aneurysms from MR Angiography Images by Deep Learning Methods. In Proceedings of the 2021 International Conference on System, Computation, Automation and Networking (ICSCAN), Puducherry, India, 30–31 July 2021. [Google Scholar]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| No of Nodes | 10 |
|---|---|
| CPU | AMD Processor |
| No. of Cores | 8 |
| Frequency | 3.5 GHZ |
| Memory | 16 GB |
| OS version | CentOS |
| Interface | SATA 3.0 |
| Speed of Interface | 6 Gbps |
| No. of map tasks | 5 |
| No. of reduce tasks | 5 |
| Hadoop | Hadoop 3.3.0 |
| HDFS Block size | 256 MB |
| Replication factor size | 3 |
| JVM | JDK 2.8 |
| Program | 5 GB | 10 GB | 15 GB | 20 GB |
|---|---|---|---|---|
| Standard WordCount without combiner | 200 | 533 | 754 | 1276 |
| Inner Mapping Combiner (IMapC) | 150 | 370 | 600 | 1050 |
| Default combiner | 200 | 460 | 680 | 1115 |
| Inner Mapping Combiner with Default Combiner | 120 | 300 | 590 | 1000 |
| Program | 5 GB | 10 GB | 15 GB | 20 GB |
|---|---|---|---|---|
| Sort without combiner | 140 | 300 | 500 | 927 |
| Inner Mapping Combiner (IMapC) | 110 | 200 | 420 | 780 |
| Default combiner | 122 | 250 | 482 | 810 |
| Inner Mapping Combiner with Default Combiner | 99 | 180 | 400 | 730 |
| Program | 5 GB | 10 GB | 15 GB | 20 GB |
|---|---|---|---|---|
| Standard WordCount without combiner (s) | 150 | 368 | 500 | 1019 |
| Inner Mapping Combiner (IMapC) (s) | 110 | 280 | 380 | 760 |
| Default combiner (s) | 130 | 300 | 440 | 810 |
| Inner Mapping Combiner with Default Combiner (s) | 93 | 210 | 322 | 700 |
| Program | 5 GB | 10 GB | 15 GB | 20 GB |
|---|---|---|---|---|
| Sort without combiner (s) | 100 | 220 | 370 | 690 |
| Inner Mapping Combiner (IMapC) (s) | 88 | 180 | 230 | 488 |
| Default combiner (s) | 96 | 200 | 280 | 552 |
| Inner Mapping Combiner with Default Combiner (s) | 80 | 120 | 200 | 365 |
| Algorithm | 5 GB | 10 GB | 15 GB | 20 GB |
|---|---|---|---|---|
| TFR (s) | 150 | 368 | 500 | 1019 |
| TFR with DC of IMapC (s) | 93 | 210 | 322 | 700 |
| Hadoop with IMapC (s) | 120 | 300 | 590 | 1000 |
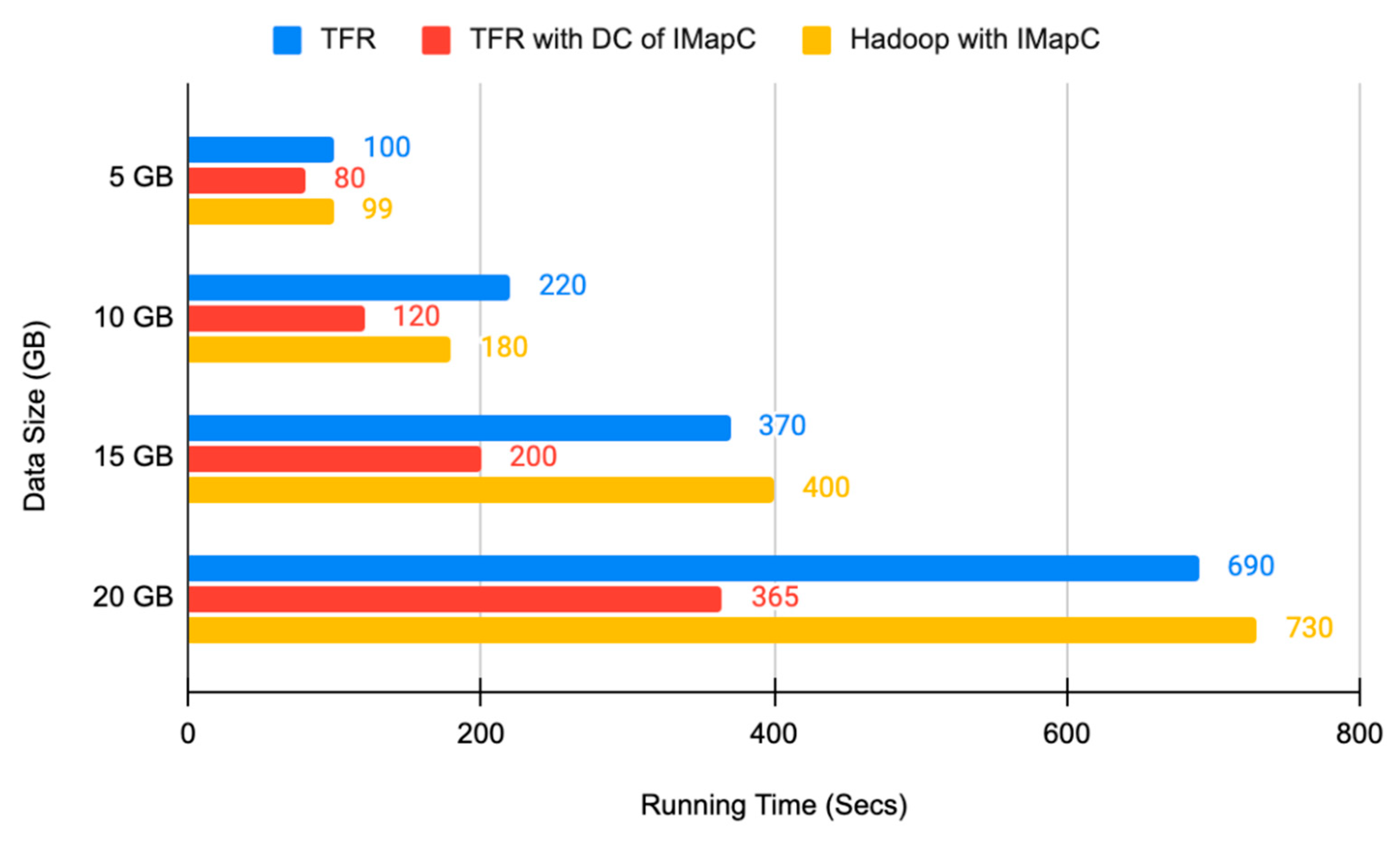
| Algorithm | 5 GB | 10 GB | 15 GB | 20 GB |
|---|---|---|---|---|
| TFR (s) | 100 | 220 | 370 | 690 |
| TFR with DC of IMapC (s) | 80 | 120 | 200 | 365 |
| Hadoop with IMapC (s) | 99 | 180 | 400 | 730 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kavitha, C.; Srividhya, S.R.; Lai, W.-C.; Mani, V. IMapC: Inner MAPping Combiner to Enhance the Performance of MapReduce in Hadoop. Electronics 2022, 11, 1599. https://doi.org/10.3390/electronics11101599
Kavitha C, Srividhya SR, Lai W-C, Mani V. IMapC: Inner MAPping Combiner to Enhance the Performance of MapReduce in Hadoop. Electronics. 2022; 11(10):1599. https://doi.org/10.3390/electronics11101599
Chicago/Turabian StyleKavitha, C., S. R. Srividhya, Wen-Cheng Lai, and Vinodhini Mani. 2022. "IMapC: Inner MAPping Combiner to Enhance the Performance of MapReduce in Hadoop" Electronics 11, no. 10: 1599. https://doi.org/10.3390/electronics11101599