
Deep Learning-Based Multiple Co-Channel Sources Localization Using Bernoulli Heatmap

 ,
,  ,
,
Abstract
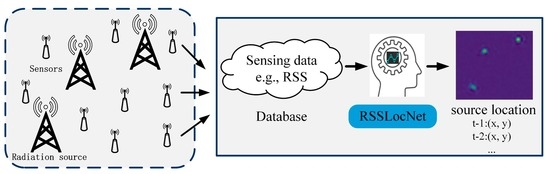
:
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
1. Introduction
2. Problem Formulation
3. Proposed Algorithm
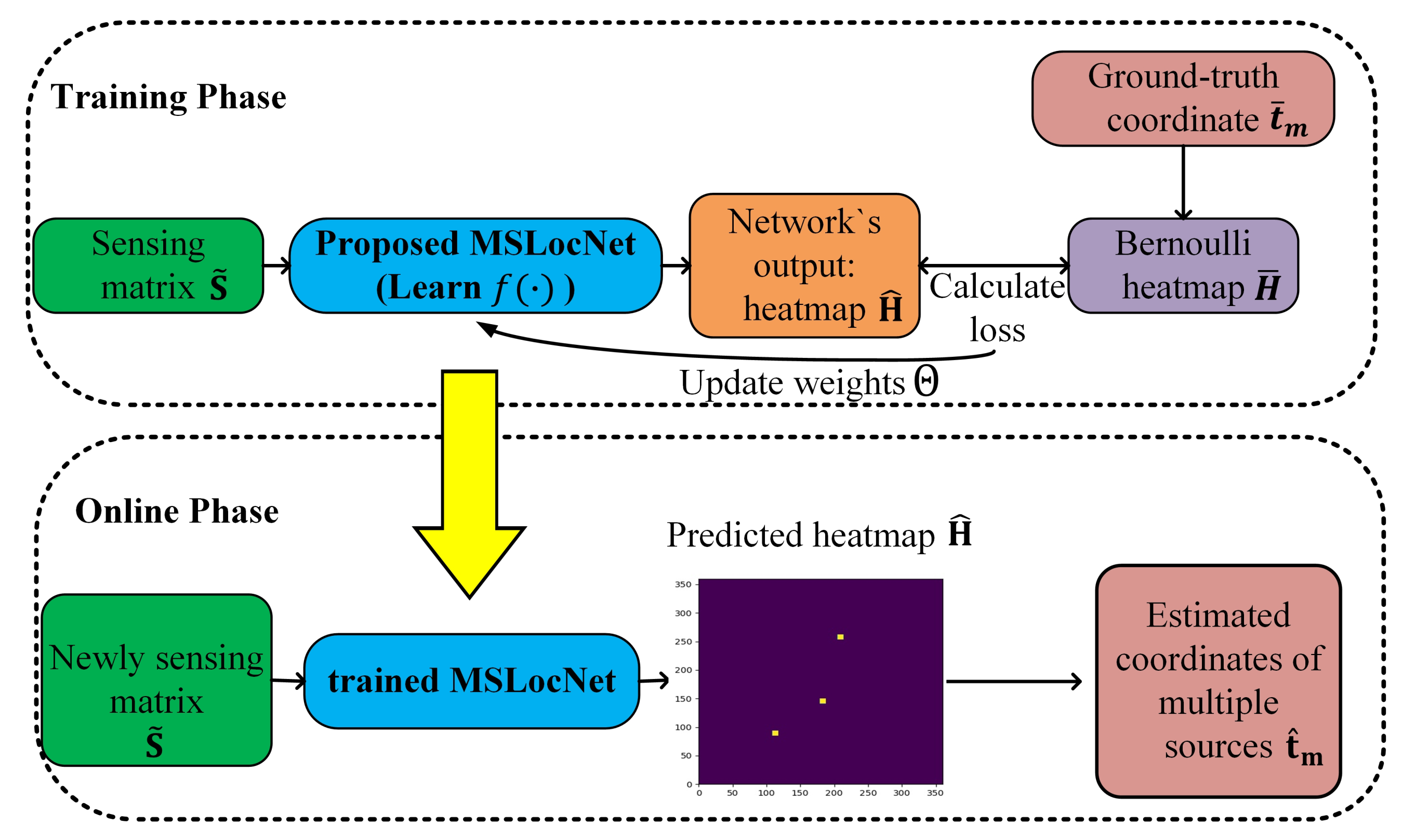
3.1. The Offline Training Phase
3.2. The Online Deployment Phase
3.3. The Structure of the MSLocNet
3.4. Complexity Analysis
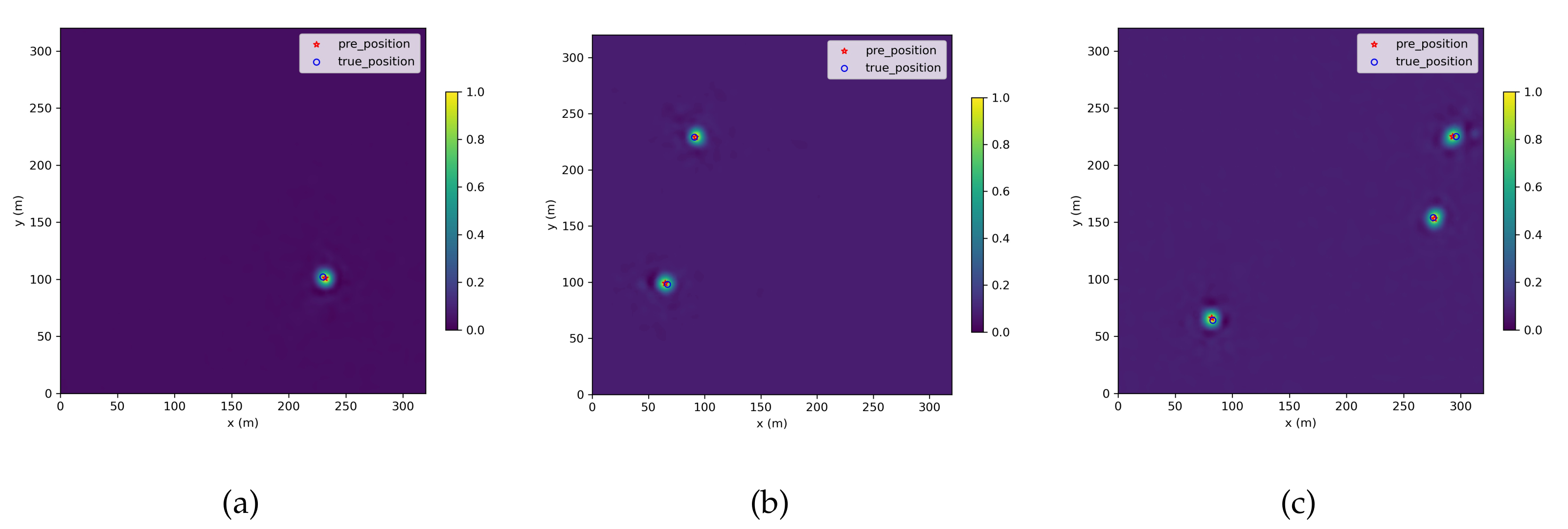
4. Numerical Results
4.1. Simulation under Shadow Fading
4.1.1. Impacts of Shadow Fading Strength
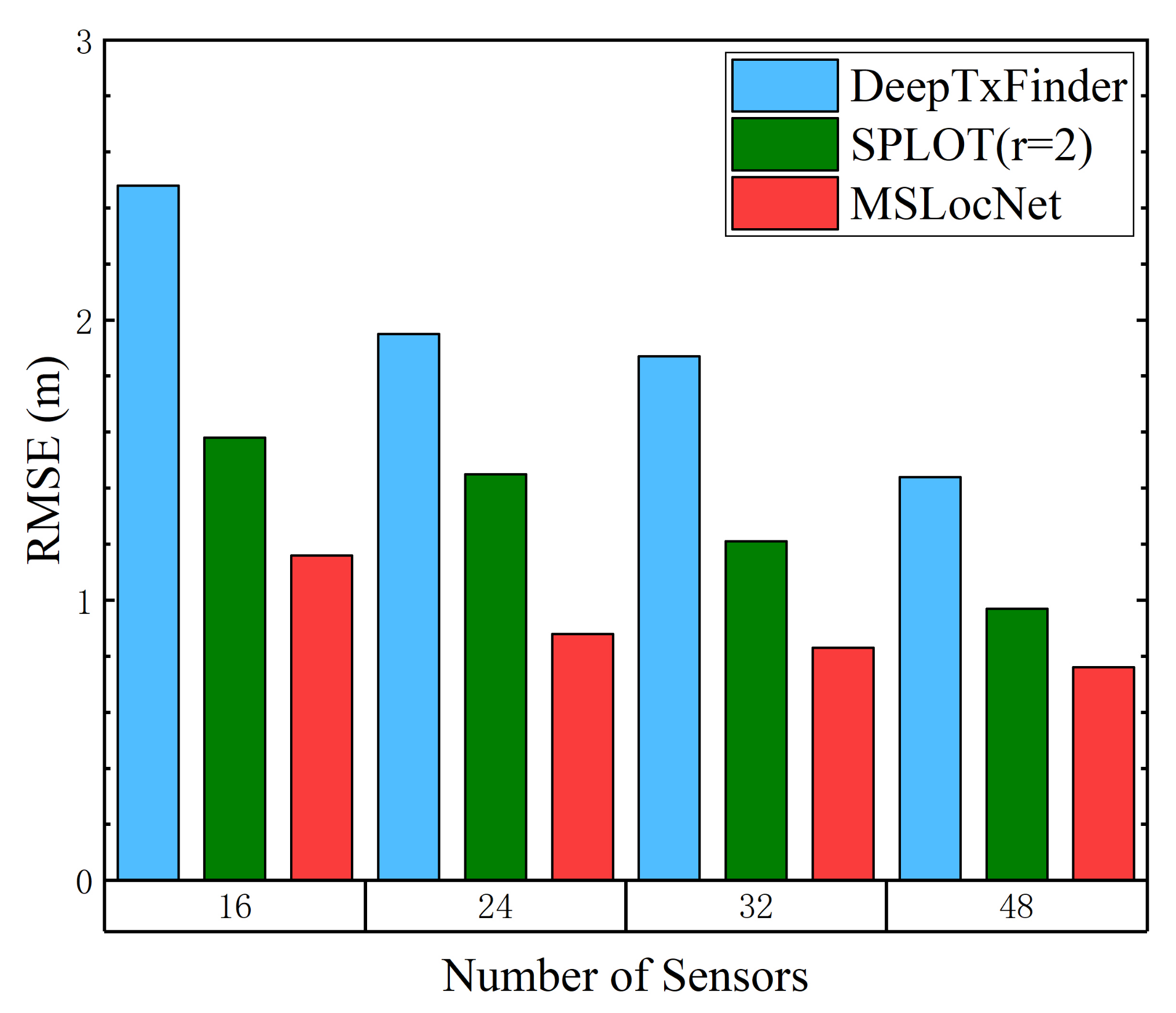
4.1.2. Effects of the Number of Sensors
4.2. Real Experiment
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| MSL | Multiple sources localization |
| RSS | Received signal strength |
| FCN | Fully convolutional network |
| WSN | Wireless sensor network |
| TOA | Time of arrival |
| DOA | Direction of arrival |
| TDOA | Time difference of arrival |
| ROI | Region of interest |
| SSL | Single source localization |
| MLE | Maximum likelihood estimation |
| WLS | Weighted least squares |
| SPLOT | Simultaneous power-based localization of transmitters |
| CNN | Convolution neural network |
| PLE | Path-loss exponent |
| MSE | Mean square error |
| RMSE | Root mean square error |
| BN | Batch normalization |
| ReLU | Rectified linear unit |
| FLOPs | Floating-point operations |
References
- Saeed, N.; Nam, H.; Al-Naffouri, T.Y.; Alouini, M.S. A State-of-the-Art Survey on Multidimensional Scaling-Based Localization Techniques. IEEE Commun. Surv. Tutor. 2019, 21, 3565–3583. [Google Scholar] [CrossRef] [Green Version]
- Zekavat, R.; Buehrer, R.M. Wireless Positioning Systems: Operation, Application, and Comparison; John Wiley & Sons: Hoboken, NJ, USA, 2019; pp. 3–23. [Google Scholar] [CrossRef]
- Shen, H.; Ding, Z.; Dasgupta, S.; Zhao, C. Multiple Source Localization in Wireless Sensor Networks Based on Time of Arrival Measurement. IEEE Trans. Signal. Process. 2014, 62, 1938–1949. [Google Scholar] [CrossRef]
- Zhang, Y.; Wu, Y.I. Multiple Sources Localization by the WSN Using the Direction-of-Arrivals Classified by the Genetic Algorithm. IEEE Access 2019, 7, 173626–173635. [Google Scholar] [CrossRef]
- Hu, Y.; Abhayapala, T.D.; Samarasinghe, P.N. Multiple Source Direction of Arrival Estimations Using Relative Sound Pressure Based MUSIC. IEEE/ACM Trans. Audio Speech Lang. Process. 2021, 29, 253–264. [Google Scholar] [CrossRef]
- Ye, X.; Rodríguez-Piñeiro, J.; Liu, Y.; Yin, X.; Pérez Yuste, A. A novel experiment-free site-specific TDOA localization performance-evaluation approach. Sensors 2020, 20, 1035. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- You, K.; Guo, W.; Peng, T.; Liu, Y.; Zuo, P.; Wang, W. Parametric Sparse Bayesian Dictionary Learning for Multiple Sources Localization with Propagation Parameters Uncertainty. IEEE Trans. Signal. Process. 2020, 68, 4194–4209. [Google Scholar] [CrossRef]
- Tang, R.; Zhang, Q.; Zhang, W.; Ma, H. Sparse Bayesian multiple sources localization using variational approximation for Laplace priors. Digit. Signal Process. 2022, 126, 103460. [Google Scholar] [CrossRef]
- Mazuelas, S.; Bahillo, A.; Lorenzo, R.M.; Fernandez, P.; Lago, F.A.; Garcia, E.; Blas, J.; Abril, E.J. Robust Indoor Positioning Provided by Real-Time RSSI Values in Unmodified WLAN Networks. IEEE J. Sel. Top. Signal Process. 2009, 3, 821–831. [Google Scholar] [CrossRef]
- Patwari, N.; Hero, A.; Perkins, M.; Correal, N.; O’Dea, R. Relative location estimation in wireless sensor networks. IEEE Trans. Signal. Process. 2003, 51, 2137–2148. [Google Scholar] [CrossRef] [Green Version]
- Coluccia, A.; Ricciato, F. On ML estimation for automatic RSS-based indoor localization. In Proceedings of the IEEE 5th International Symposium on Wireless Pervasive Computing 2010, Mondena, Italy, 5–7 May 2010; pp. 495–502. [Google Scholar] [CrossRef]
- Tomic, S.; Beko, M.; Dinis, R.; Lipovac, V. RSS-based localization in wireless sensor networks using SOCP relaxation. In Proceedings of the 2013 IEEE 14th Workshop on Signal Processing Advances in Wireless Communications (SPAWC), Darmstadt, Germany, 16–19 June 2013; pp. 749–753. [Google Scholar] [CrossRef]
- Tomic, S.; Beko, M.; Dinis, R. RSS-Based Localization in Wireless Sensor Networks Using Convex Relaxation: Noncooperative and Cooperative Schemes. IEEE Trans. Veh. Technol. 2015, 64, 2037–2050. [Google Scholar] [CrossRef] [Green Version]
- Chu, Y.; You, K.; Guo, W. Multiple Sources Localization with Sparse Recovery under Log-normal Shadow Fading. arXiv 2021, arXiv:2105.15097. [Google Scholar]
- Feng, C.; Valaee, S.; Tan, Z. Multiple target localization using compressive sensing. In Proceedings of the GLOBECOM 2009—2009 IEEE Global Telecommunications Conference, Honolulu, HI, USA, 30 November–4 December 2009; pp. 1–6. [Google Scholar] [CrossRef]
- Heyde, C.C. On a property of the lognormal distribution. J. R. Stat. Soc. Ser. B Methodol. 1963, 25, 392–393. [Google Scholar] [CrossRef]
- Fenton, L. The Sum of Log-Normal Probability Distributions in Scatter Transmission Systems. IRE Trans. Commun. Syst. 1960, 8, 57–67. [Google Scholar] [CrossRef]
- Wang, G.; Chen, H.; Li, Y.; Jin, M. On Received-Signal-Strength Based Localization with Unknown Transmit Power and Path Loss Exponent. IEEE Wirel. Commun. Lett. 2012, 1, 536–539. [Google Scholar] [CrossRef]
- Khaledi, M.; Khaledi, M.; Sarkar, S.; Kasera, S.; Patwari, N.; Derr, K.; Ramirez, S. Simultaneous power-based localization of transmitters for crowdsourced spectrum monitoring. In Proceedings of the 23rd Annual International Conference on Mobile Computing and Networking, Snowbird, UT, USA, 16–20 October 2017; pp. 235–247. [Google Scholar]
- Zubow, A.; Bayhan, S.; Gawłowicz, P.; Dressler, F. DeepTxFinder: Multiple transmitter localization by deep learning in crowdsourced spectrum sensing. In Proceedings of the 2020 29th International Conference on Computer Communications and Networks (ICCCN), Honolulu, HI, USA, 3–6 August 2020; pp. 1–8. [Google Scholar] [CrossRef]
- Papandreou, G.; Zhu, T.; Kanazawa, N.; Toshev, A.; Tompson, J.; Bregler, C.; Murphy, K. Towards accurate multi-person pose estimation in the wild. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4903–4911. [Google Scholar]
- Chen, Y.; Wang, Z.; Peng, Y.; Zhang, Z.; Yu, G.; Sun, J. Cascaded pyramid network for multi-person pose estimation. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 7103–7112. [Google Scholar] [CrossRef] [Green Version]
- Zhou, T.; Wang, W.; Liu, S.; Yang, Y.; Van Gool, L. Differentiable multi-granularity human representation learning for instance-aware human semantic parsing. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 1622–1631. [Google Scholar]
- Uko, M.C.; Ukommi, U.S.; Ekpo, S.C.; Kharel, R. Area spectral efficiency of a macro-femto heterogeneous network for cell-edge users under shadowing and fading effects. Appl. Comput. Electromagn. Soc. J. 2016, 31, 1043–1047. [Google Scholar]
- Cui, M.; Cha, H.; Tian, B. A propagation model for rough sea surface conditions using the parabolic equation with the shadowing effect. Appl. Comput. Electromagn. Soc. J. 2018, 33, 683–689. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 770–778. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. In Proceedings of the International Conference on Machine Learning (ICML), Lille, France, 6–11 July 2015; pp. 448–456. [Google Scholar]
- Hinton, G.; Srivastava, N.; Swersky, K. Neural Networks for Machine Learning Lecture 6a Overview of Mini-Batch Gradient Descent. 2012. Available online: https://www.cs.toronto.edu/~tijmen/csc321/slides/lecture_slides_lec6.pdf (accessed on 5 May 2022).









Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lin, M.; Huang, Y.; Li, B.; Huang, Z.; Zhang, Z.; Zhao, W. Deep Learning-Based Multiple Co-Channel Sources Localization Using Bernoulli Heatmap. Electronics 2022, 11, 1551. https://doi.org/10.3390/electronics11101551
Lin M, Huang Y, Li B, Huang Z, Zhang Z, Zhao W. Deep Learning-Based Multiple Co-Channel Sources Localization Using Bernoulli Heatmap. Electronics. 2022; 11(10):1551. https://doi.org/10.3390/electronics11101551
Chicago/Turabian StyleLin, Meiyan, Yonghui Huang, Baozhu Li, Zhen Huang, Zihan Zhang, and Wenjie Zhao. 2022. "Deep Learning-Based Multiple Co-Channel Sources Localization Using Bernoulli Heatmap" Electronics 11, no. 10: 1551. https://doi.org/10.3390/electronics11101551