
A Triple Relation Network for Joint Entity and Relation Extraction


Abstract
:1. Introduction
- We propose a novel Triple Relation Network framework to extract the relational triples, especially implicit triples existing in raw sentences. This implies that the designed model possesses the power of reasoning to search for comprehensive information in the triples’ extraction task.
- We instantiate the proposed Trn, including an attention-based entity pair encoding module to collect normal entity pairs directly and a triple reasoning module to find the implicit connections among all entities. Finally, a bipartite matching training objective is introduced to update the model parameters.
- The main experiments show that the proposed model outperforms the previous strong baselines on two benchmarks, and analytic experiments verify our motivation in potential relations among the extracted entities.
2. Related Work
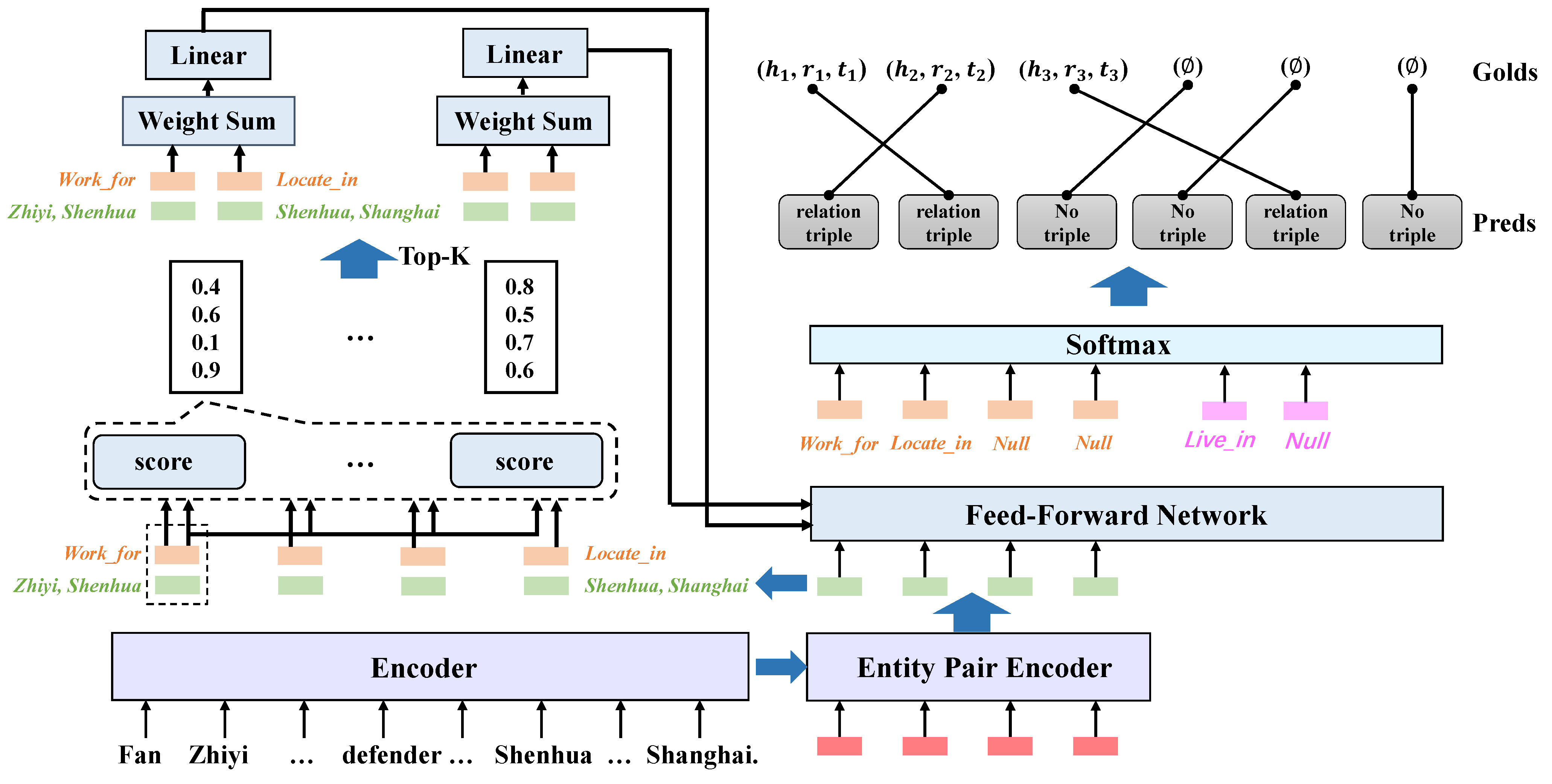
3. Proposed Framework
3.1. Sentence Encoder
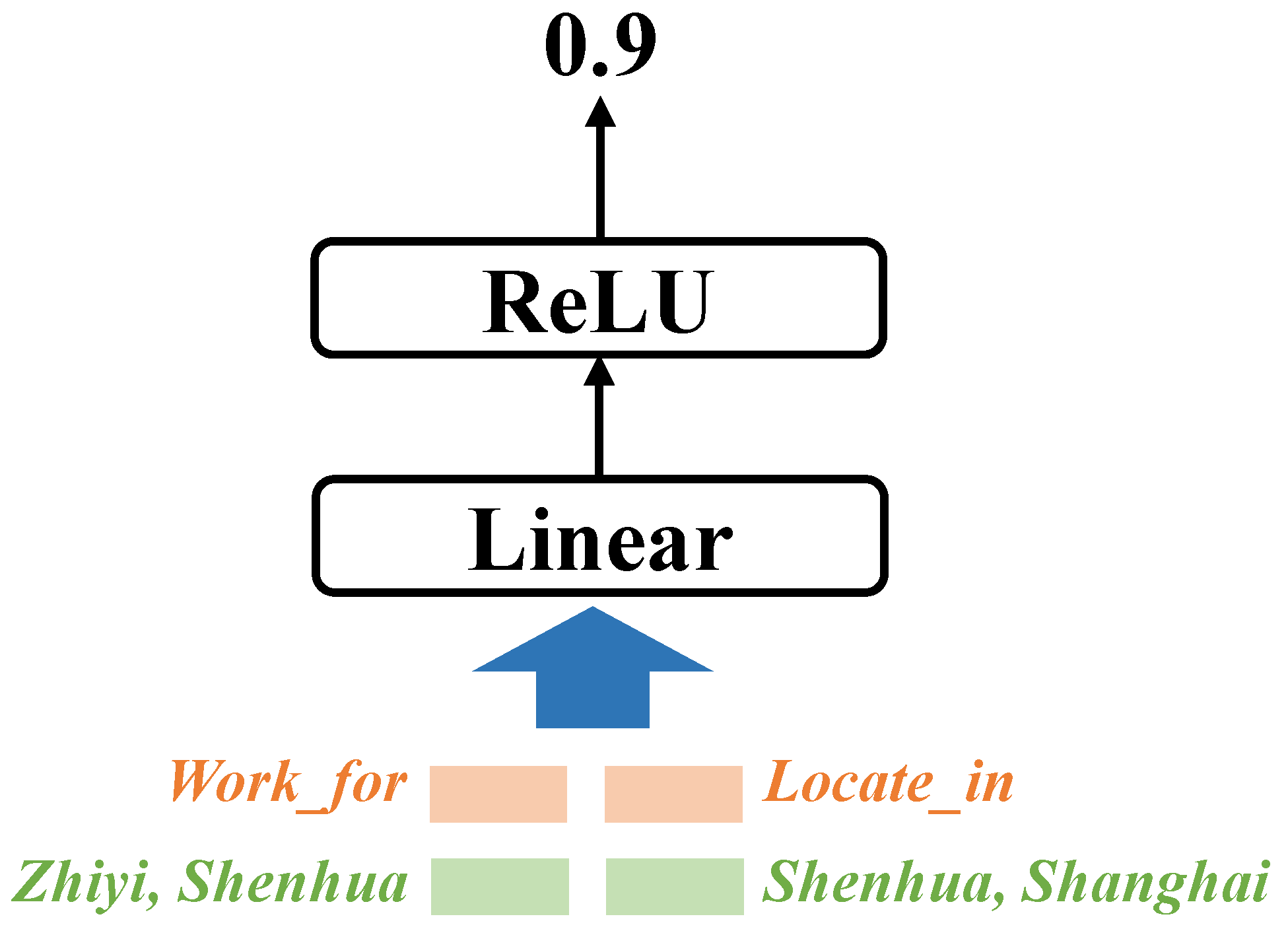
3.2. Entity Pair Encoding
3.3. Triple Reasoning
3.4. Triple Generation
3.5. Training Objective
4. Experiments and Discussion
4.1. Experimental Setup
4.2. Comparative Models
- NovelTagging [8] proposes a novel tagging scheme to transform the task into a sequence labeling problem.
- CopyRE [15] proposes an end-to-end based on sequence-to-sequence learning with a copy mechanism, which jointly extracts triples as the sequence form.
- CopyRE [16] considers the order of the relational facts extracted from the sentence to be also important. They utilized reinforcement learning (RL) in the sequence-to-sequence model to learn the extraction order.
- TME [10] proposes a joint model that is capable of discovering multiple triples in a sentence via ranking with a translation mechanism. They used a tri-part tagging scheme (position, type, entity) to obtain entity features.
- ETL-Span [11] proposes a decomposition-based tagging scheme. They decomposed the joint extraction task into HE extraction and TER extraction, which are interrelated subtasks. Their model can not only capture the semantic interdependency between different steps, but also reduces noise from irrelevant entity pairs.
- CopyMTL [17] proposes a Multi-Task Learning (MTL) framework equipped with a copy mechanism to predict the multi-token entities and accurately differentiate head and tail entities.
- WDec [18] proposes two approaches to use the sequence-to-sequence architecture to jointly extract entities and relations.
- CasRel [12] proposes a novel cascade binary tagging framework. They treated relations as functions that map subjects to objects in a sentence to solve the overlapping problem.
- PMEI [43] designs a multitask learning architecture to extract relevant features that correlate with entity recognition and relation extraction from the input. They controlled the injection of early predictions to ensure that the extracted task-specific representations were good for classification.
- TPLinker [23] proposes a novel handshaking tagging scheme to perform the one-stage extraction. TPLinker is capable of discovering overlapping relations sharing one or both entities to address the exposure bias problem.
- RMAN [14] proposed a multi-feature fusion sentence representation and decoder sequence annotation to deal with overlapping triples.
- CGT [20] proposes a model, contrastive triple extraction with a generative transformer. They introduced a single shared transformer module for encoder–decoder-based generation.
- RIFRE [13] designs a tagging framework, which first extracts all the candidate head entities and then labels the tail entities with corresponding relations.
4.3. Performance
4.3.1. Main Results
4.3.2. Detailed Results on Different Types of Sentences
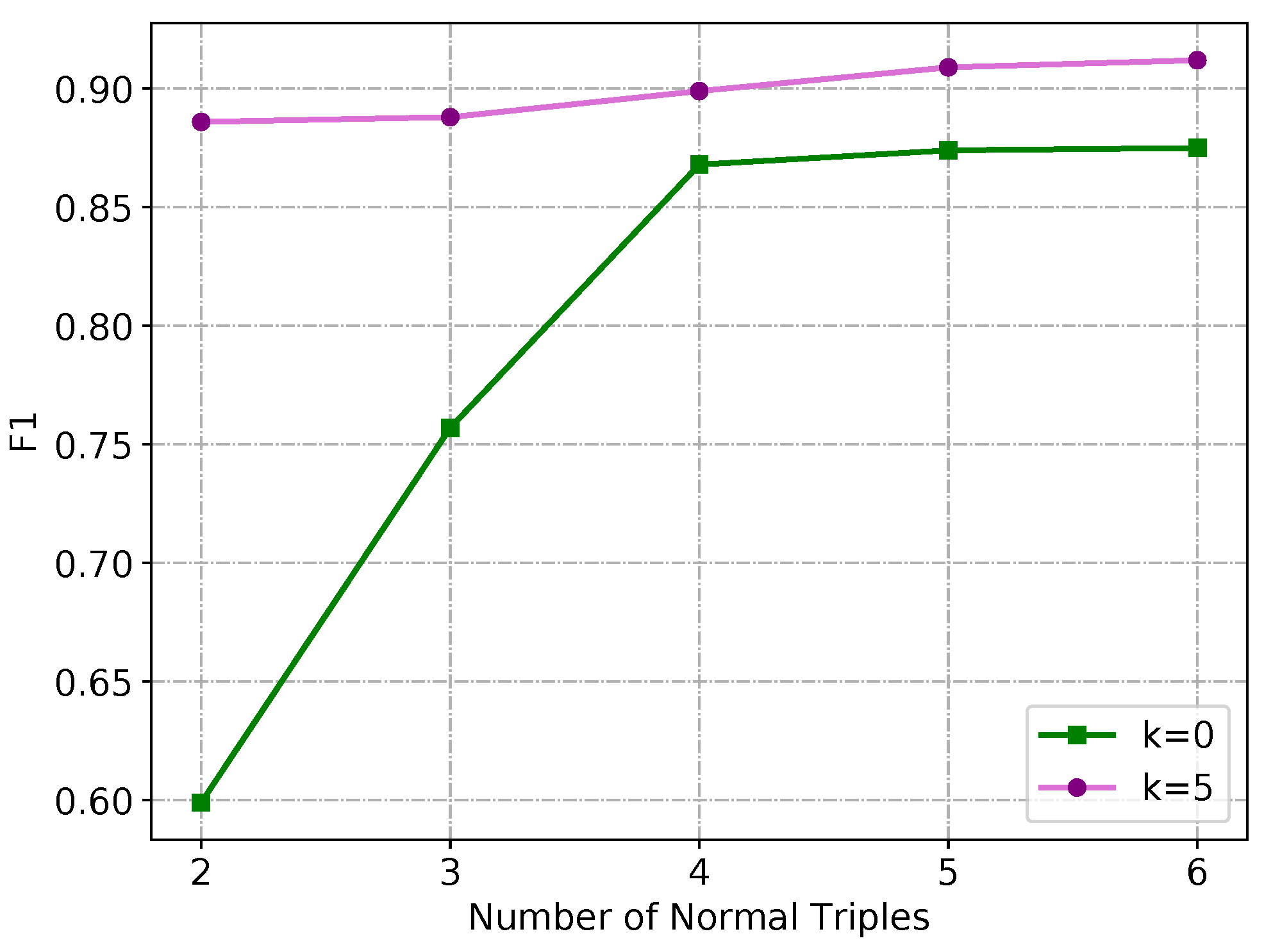
4.4. Ablation Study
- Trn−TRm removes the whole triple reasoning module.
- Trn−TRm-Seq removes the triple reasoning module, adds a causal mask to the entity pair encoding module to predict the triples order by order (does not distinguish the difference between normal triples and implicit triples), and uses NLL loss as the training objective.
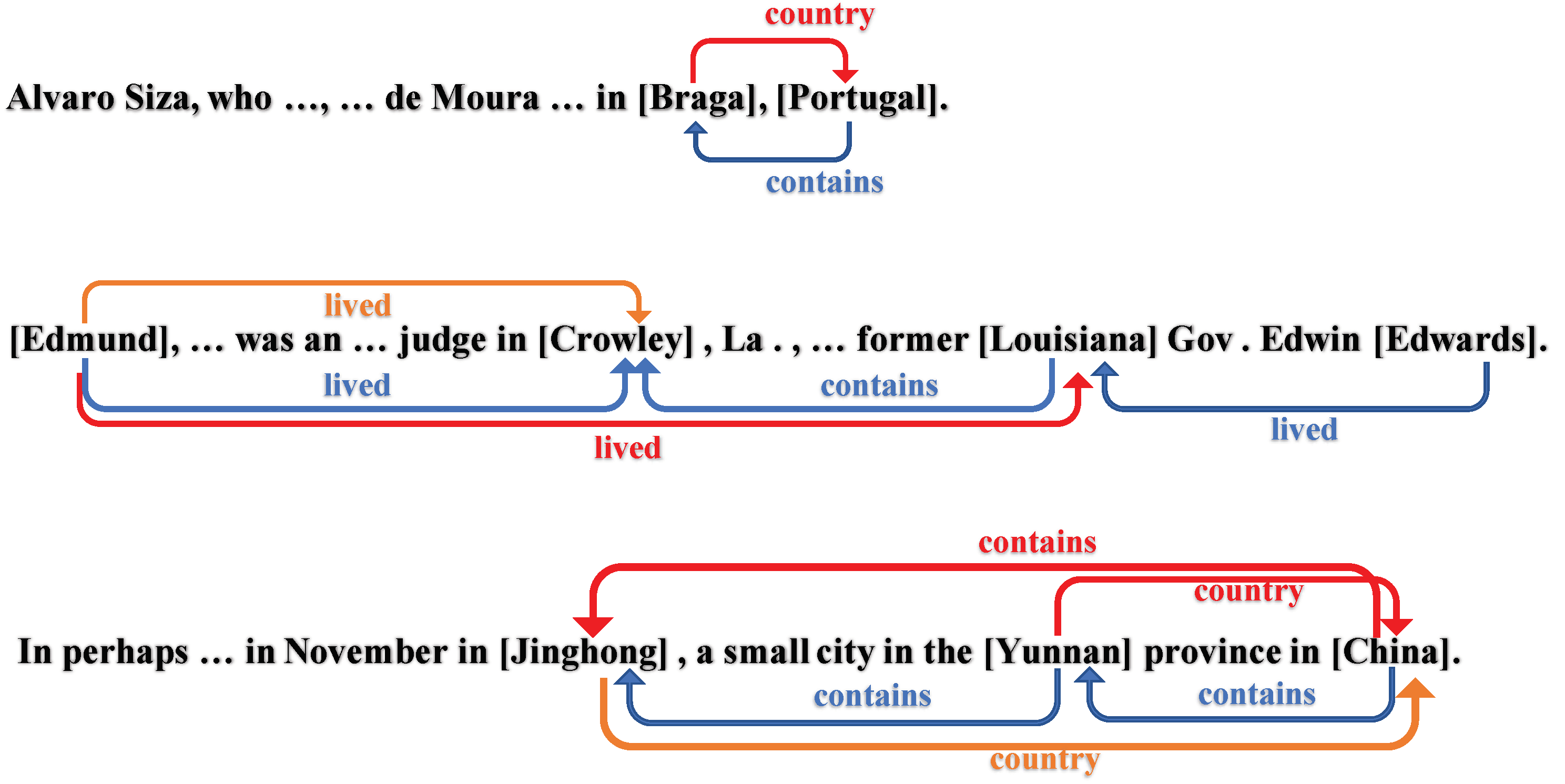
4.5. Case Study
4.6. Error Analysis
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Zelenko, D.; Aone, C.; Richardella, A. Kernel methods for relation extraction. J. Mach. Learn. Res. 2003, 3, 1083–1106. [Google Scholar]
- Chan, Y.S.; Roth, D. Exploiting syntactico-semantic structures for relation extraction. In Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics: Human Language Technologies, Portland, OR, USA, 19–24 June 2011; pp. 551–560. [Google Scholar]
- Yu, X.; Lam, W. Jointly identifying entities and extracting relations in encyclopedia text via a graphical model approach. In Proceedings of the 23rd International Conference on Computational Linguistics: Posters, Beijing, China, 23–27 August 2010; Coling 2010 Organizing Committee: Beijing, China, 2010; pp. 1399–1407. [Google Scholar]
- Li, Q.; Ji, H. Incremental joint extraction of entity mentions and relations. In Proceedings of the 52nd Annual Meeting of the Association for Computational Linguistic, Baltimore, MD, USA, 22–27 June 2014; Volume 1, pp. 402–412. [Google Scholar]
- Miwa, M.; Sasaki, Y. Modeling joint entity and relation extraction with table representation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 25–29 October 2014; pp. 1858–1869. [Google Scholar]
- Ren, X.; Wu, Z.; He, W.; Qu, M.; Voss, C.R.; Ji, H.; Abdelzaher, T.F.; Han, J. Cotype: Joint extraction of typed entities and relations with knowledge bases. In Proceedings of the 26th International Conference on World Wide Web, Perth, Australia, 3–7 April 2017; pp. 1015–1024. [Google Scholar]
- Miwa, M.; Bansal, M. End-to-End Relation Extraction using LSTMs on Sequences and Tree Structures. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics, Berlin, Germany, 7–12 August 2016; Volume 1, pp. 1105–1116. [Google Scholar]
- Zheng, S.; Wang, F.; Bao, H.; Hao, Y.; Zhou, P.; Xu, B. Joint Extraction of Entities and Relations Based on a Novel Tagging Scheme. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics, ACL 2017, Vancouver, BC, Canada, 30 July–4 August 2017; Volume 1, pp. 1227–1236. [Google Scholar]
- Dai, D.; Xiao, X.; Lyu, Y.; Dou, S.; She, Q.; Wang, H. Joint extraction of entities and overlapping relations using position-attentive sequence labeling. Proc. AAAI Conf. Artif. Intell. 2019, 33, 6300–6308. [Google Scholar] [CrossRef] [Green Version]
- Tan, Z.; Zhao, X.; Wang, W.; Xiao, W. Jointly Extracting Multiple Triplets with Multilayer Translation Constraints. In Proceedings of the The Thirty-Third AAAI Conference on Artificial Intelligence, AAAI 2019, The Thirty-First Innovative Applications of Artificial Intelligence Conference, IAAI 2019, The Ninth AAAI Symposium on Educational Advances in Artificial Intelligence, EAAI 2019, Honolulu, HI, USA, 27 January–1 February 2019; AAAI Press: Menlo Park, CA, USA, 2019; pp. 7080–7087. [Google Scholar]
- Yu, B.; Zhang, Z.; Shu, X.; Liu, T.; Wang, Y.; Wang, B.; Li, S. Joint Extraction of Entities and Relations Based on a Novel Decomposition Strategy. In Proceedings of the ECAI 2020—24th European Conference on Artificial Intelligence, including 10th Conference on Prestigious Applications of Artificial Intelligence (PAIS 2020), Santiago de Compostela, Spain, 29 August–8 September 2020; Volume 325, pp. 2282–2289. [Google Scholar]
- Wei, Z.; Su, J.; Wang, Y.; Tian, Y.; Chang, Y. A Novel Cascade Binary Tagging Framework for Relational Triple Extraction. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online, 5–10 July 2020; pp. 1476–1488. [Google Scholar]
- Zhao, K.; Xu, H.; Cheng, Y.; Li, X.; Gao, K. Representation iterative fusion based on heterogeneous graph neural network for joint entity and relation extraction. Knowl. Based Syst. 2021, 219, 106888. [Google Scholar] [CrossRef]
- Lai, T.; Cheng, L.; Wang, D.; Ye, H.; Zhang, W. RMAN: Relational multi-head attention neural network for joint extraction of entities and relations. Appl. Intell. 2022, 52, 3132–3142. [Google Scholar] [CrossRef]
- Zeng, X.; Zeng, D.; He, S.; Liu, K.; Zhao, J. Extracting relational facts by an end-to-end neural model with copy mechanism. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics, Melbourne, Australia, 15–20 July 2018; Volume 1, pp. 506–514. [Google Scholar]
- Zeng, X.; He, S.; Zeng, D.; Liu, K.; Liu, S.; Zhao, J. Learning the extraction order of multiple relational facts in a sentence with reinforcement learning. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), Hong Kong, China, 3–7 November 2019; pp. 367–377. [Google Scholar]
- Zeng, D.; Zhang, H.; Liu, Q. Copymtl: Copy mechanism for joint extraction of entities and relations with multi-task learning. Proc. AAAI Conf. Artif. Intell. 2020, 34, 9507–9514. [Google Scholar] [CrossRef]
- Nayak, T.; Ng, H.T. Effective modeling of encoder–decoder architecture for joint entity and relation extraction. Proc. AAAI Conf. Artif. Intell. 2020, 34, 8528–8535. [Google Scholar] [CrossRef]
- Sui, D.; Chen, Y.; Liu, K.; Zhao, J.; Zeng, X.; Liu, S. Joint Entity and Relation Extraction with Set Prediction Networks. arXiv 2020, arXiv:2011.01675. [Google Scholar]
- Ye, H.; Zhang, N.; Deng, S.; Chen, M.; Tan, C.; Huang, F.; Chen, H. Contrastive Triple Extraction with Generative Transformer. In Proceedings of the Thirty-Fifth AAAI Conference on Artificial Intelligence, AAAI, Virtually, 2–9 February 2021; pp. 14257–14265. [Google Scholar]
- Gupta, P.; Schütze, H.; Andrassy, B. Table filling multi-task recurrent neural network for joint entity and relation extraction. In Proceedings of the COLING 2016, the 26th International Conference on Computational Linguistics: Technical Papers, Osaka, Japan, 11–16 December 2016; pp. 2537–2547. [Google Scholar]
- Zhang, M.; Zhang, Y.; Fu, G. End-to-end neural relation extraction with global optimization. In Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, Copenhagen, Denmark, 9–11 September 2017; pp. 1730–1740. [Google Scholar]
- Wang, Y.; Yu, B.; Zhang, Y.; Liu, T.; Zhu, H.; Sun, L. TPLinker: Single-stage Joint Extraction of Entities and Relations Through Token Pair Linking. In Proceedings of the 28th International Conference on Computational Linguistics, Barcelona, Spain, 8–13 December 2020; pp. 1572–1582. [Google Scholar]
- Yan, Z.; Zhang, C.; Fu, J.; Zhang, Q.; Wei, Z. A Partition Filter Network for Joint Entity and Relation Extraction. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, EMNLP 2021, Virtual Event/Punta Cana, Dominican Republic, 2021, 7–11 November; pp. 185–197.
- Zhu, H.; Lin, Y.; Liu, Z.; Fu, J.; Chua, T.S.; Sun, M. Graph Neural Networks with Generated Parameters for Relation Extraction. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Florence, Italy, 28 July–2 August 2019; pp. 1331–1339. [Google Scholar]
- Angeli, G.; Manning, C.D. Philosophers are mortal: Inferring the truth of unseen facts. In Proceedings of the Seventeenth Conference on Computational Natural Language Learning, Sofia, Bulgaria, 8–9 August 2013; pp. 133–142. [Google Scholar]
- Jia, N.; Cheng, X.; Su, S. Improving knowledge graph embedding using locally and globally attentive relation paths. Adv. Inf. Retr. 2020, 12035, 17–32. [Google Scholar]
- Liang, Z.; Yang, J.; Liu, H.; Huang, K.; Cui, L.; Qu, L.; Li, X. HRER: A New Bottom-Up Rule Learning for Knowledge Graph Completion. Electronics 2022, 11, 908. [Google Scholar] [CrossRef]
- Peng, G.; Chen, X. Entity–Relation Extraction—A Novel and Lightweight Method Based on a Gate Linear Mechanism. Electronics 2020, 9, 1637. [Google Scholar] [CrossRef]
- Auer, S.; Bizer, C.; Kobilarov, G.; Lehmann, J.; Cyganiak, R.; Ives, Z. Dbpedia: A nucleus for a web of open data. In The Semantic Web; Springer: Manhattan, New York City, USA, 2007; pp. 722–735. [Google Scholar]
- Bollacker, K.; Evans, C.; Paritosh, P.; Sturge, T.; Taylor, J. Freebase: A collaboratively created graph database for structuring human knowledge. In Proceedings of the 2008 ACM SIGMOD International Conference on Management of Data, Vancouver, BC, Canada, 10–12 June 2008; pp. 1247–1250. [Google Scholar]
- Dong, X.; Gabrilovich, E.; Heitz, G.; Horn, W.; Lao, N.; Murphy, K.; Strohmann, T.; Sun, S.; Zhang, W. Knowledge vault: A web-scale approach to probabilistic knowledge fusion. In Proceedings of the 20th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, New York, NY, USA, 24–27 August 2014; pp. 601–610. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Minneapolis, MN, USA, 2–7 June 2019; Volume 1, pp. 4171–4186. [Google Scholar]
- Gu, J.; Bradbury, J.; Xiong, C.; Li, V.O.K.; Socher, R. Non-Autoregressive Neural Machine Translation. In Proceedings of the 6th International Conference on Learning Representations, ICLR 2018, Conference Track Proceedings, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Proceedings of the 31st Conference on Neural Information Processing Systems (NIPS 2017), Long Beach, CA, USA, 4–9 December 2017; pp. 5998–6008. [Google Scholar]
- Bahdanau, D.; Cho, K.; Bengio, Y. Neural Machine Translation by Jointly Learning to Align and Translate. In Proceedings of the 3rd International Conference on Learning Representations, ICLR 2015, Conference Track Proceedings, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Kuhn, H.W. The Hungarian method for the assignment problem. Nav. Res. Logist. Q. 1955, 2, 83–97. [Google Scholar] [CrossRef] [Green Version]
- Riedel, S.; Yao, L.; McCallum, A. Modeling relations and their mentions without labeled text. In Proceedings of the Joint European Conference on Machine Learning and Knowledge Discovery in Databases, Würzburg, Germany, 16–20 September 2010; pp. 148–163. [Google Scholar]
- Gardent, C.; Shimorina, A.; Narayan, S.; Perez-Beltrachini, L. Creating Training Corpora for NLG Micro-Planners. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics, Vancouver, BC, Canada, 30 July–4 August 2017; Volume 1, pp. 179–188. [Google Scholar]
- Sennrich, R.; Haddow, B.; Birch, A. Neural Machine Translation of Rare Words with Subword Units. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics, ACL 2016, Berlin, Germany, 7–12 August 2016; Volume 1. [Google Scholar]
- Srivastava, N.; Hinton, G.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R. Dropout: A simple way to prevent neural networks from overfitting. J. Mach. Learn. Res. 2014, 15, 1929–1958. [Google Scholar]
- Loshchilov, I.; Hutter, F. Decoupled Weight Decay Regularization. In Proceedings of the 7th International Conference on Learning Representations, ICLR 2019, New Orleans, LA, USA, 6–9 May 2019. [Google Scholar]
- Sun, K.; Zhang, R.; Mensah, S.; Mao, Y.; Liu, X. Progressive multitask learning with controlled information flow for joint entity and relation extraction. Assoc. Adv. Artif. Intell. 2021, 35, 13851–13859. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | NYT | WebNLG | ||
|---|---|---|---|---|
| Train | Test | Train | Test | |
| Normal | 37,013 | 3266 | 1596 | 246 |
| SEO | 14,735 | 1297 | 3406 | 457 |
| EPO | 9782 | 978 | 227 | 26 |
| ALL | 56,195 | 5000 | 5019 | 703 |
| Models | NYT | WebNLG | ||||
|---|---|---|---|---|---|---|
| Precision | Recall | F1 | Precision | Recall | F1 | |
| NovelTagging [8] | 62.4 | 31.7 | 42.0 | 52.5 | 19.3 | 28.3 |
| CopyRE [15] | 61.0 | 56.6 | 58.7 | 37.7 | 36.4 | 37.1 |
| CopyRE [16] | 77.9 | 67.2 | 72.1 | 63.3 | 59.9 | 61.6 |
| TME [10] | 69.6 | 47.8 | 56.7 | - | - | - |
| ETL-Span [11] | 84.9 | 72.3 | 78.1 | 84.0 | 91.5 | 87.6 |
| CopyMTL [17] | 75.7 | 68.7 | 72.0 | 58.0 | 54.9 | 56.4 |
| WDec [18] | 94.5 | 76.2 | 84.4 | - | - | - |
| CasRel [12] | 89.7 | 89.5 | 89.6 | 93.4 | 90.1 | 91.8 |
| PMEI [43] | 90.5 | 89.8 | 90.1 | 91.0 | 92.9 | 92.0 |
| TPLinker [23] | 91.3 | 92.5 | 91.9 | 91.8 | 92.0 | 91.9 |
| RMAN [14] | 87.1 | 83.8 | 85.4 | 83.6 | 85.3 | 84.5 |
| CGT [20] | 94.7 | 84.2 | 89.1 | 92.9 | 75.6 | 83.4 |
| RIFRE [13] | 93.6 | 90.5 | 92.0 | 93.3 | 92.0 | 92.6 |
| Trn (Our method) | 93.0 | 92.3 | 92.6 | 93.5 | 92.7 | 93.1 |
| Trn−TRm | 92.4 | 92.1 | 92.2 | 93.4 | 92.4 | 92.8 |
| Models | NYT | WebNLG | ||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Normal | SEO | EPO | N = 1 | N = 2 | N = 3 | N = 4 | N ≥ 5 | Normal | SEO | EPO | N = 1 | N = 2 | N = 3 | N = 4 | N ≥ 5 | |
| CopyRE | 66.0 | 48.6 | 55.0 | 67.1 | 58.6 | 52.0 | 53.6 | 30.0 | 59.2 | 33.0 | 36.6 | 59.2 | 42.5 | 31.7 | 24.2 | 30.0 |
| CopyRE | 71.2 | 69.4 | 72.8 | 71.7 | 72.6 | 72.5 | 77.9 | 45.9 | 65.4 | 60.1 | 67.4 | 63.4 | 62.2 | 64.4 | 57.2 | 55.7 |
| CasRel | 87.3 | 91.4 | 92.0 | 88.2 | 90.3 | 91.9 | 94.2 | 83.7 | 89.4 | 92.2 | 94.7 | 89.3 | 90.8 | 94.2 | 92.4 | 90.9 |
| TPLinker | 90.1 | 93.4 | 94.0 | 90.0 | 92.9 | 93.1 | 96.1 | 90.0 | 87.9 | 92.5 | 95.3 | 88.0 | 90.1 | 94.6 | 93.3 | 91.6 |
| RIFRE | 90.7 | 93.2 | 93.5 | 90.7 | 92.8 | 93.4 | 94.8 | 89.6 | 90.1 | 93.1 | 94.7 | 90.2 | 92.0 | 94.8 | 93.0 | 92.0 |
| Trn | 90.5 | 94.6 | 94.6 | 90.6 | 93.5 | 94.1 | 96.4 | 91.9 | 90.4 | 93.6 | 90.3 | 90.0 | 91.7 | 94.5 | 94.8 | 94.0 |
| Model | Precision | Recall | F1 |
|---|---|---|---|
| TPLinker | 97.6 | 94.3 | 96.0 |
| Trn | 95.5 | 85.7 | 90.3 |
| Model | F1 Score |
|---|---|
| CGT | 79.1 |
| TPLinker | 84.9 |
| RIFRE | 85.3 |
| Trn−TRm-Seq | 82.2 |
| Trn−TRm | 87.6 |
| Trn | 91.4 |
| Dataset | Element | EPO | SEO | Overall | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Pre. | Rec. | F1 | Pre. | Rec. | F1 | Pre. | Rec. | F1 | ||
| (E1, E2) | 96.3 | 93.3 | 94.8 | 97.1 | 92.5 | 94.7 | 93.7 | 93.0 | 93.4 | |
| NYT | R | 98.4 | 95.4 | 96.9 | 99.4 | 94.8 | 97.0 | 96.9 | 96.2 | 96.6 |
| (E1, R, E2) | 96.1 | 93.1 | 94.6 | 96.9 | 92.4 | 94.6 | 93.0 | 92.3 | 92.6 | |
| (E1, E2) | 97.7 | 87.8 | 92.5 | 96.4 | 94.9 | 95.7 | 95.8 | 94.9 | 95.3 | |
| WebNLG | R | 96.6 | 86.7 | 91.4 | 96.9 | 95.5 | 96.2 | 96.1 | 95.2 | 95.6 |
| (E1, R, E2) | 95.5 | 85.7 | 90.3 | 94.3 | 92.9 | 93.6 | 93.5 | 92.7 | 93.1 | |
| Instances |
|---|
| Sentence #1: He said he had brought in one bomber called Imran from Pakistan’s |
| North - West Frontier Province, who blew himself up on the road near the |
| Kandahar airport. |
| Gold: (Pakistan, administrative_divisions, Province), (Province, country, Pakistan), |
| (Pakistan, contains, Province) |
| Pred: (Pakistan, administrative_divisions, Province), (Province, country, Pakistan), |
| (Pakistan, contains, Province), (Pakistan, contains, Kandahar) |
| Sentence #2: The vision for this sort of thing has existed in China for a very long |
| time,” said Wu Yongyi, deputy dean of the International College of Chinese Studies |
| at East China Normal University in Shanghai, who has been involved in overseas |
| language instruction missions since the 1980’s. |
| Gold: (Shanghai, country, China), (China, contains, Shanghai), |
| (China, administrative_divisions, Shanghai), (Shanghai, contains, University) |
| Pred: (Shanghai, country, China), (China, contains, Shanghai), |
| (China, administrative_divisions, Shanghai), (Shanghai, no_relation, University) |
| Sentence #3: Jeffrey R. Immelt, chairman and chief executive of General Electric, |
| bounced a $2000 check to the failed New York gubernatorial campaign of William |
| F. Weld, according to a campaign finance filing released Monday. |
| Gold: (Weld, place_lived, York), (Immelt, company, Electric), |
| (Immelt, major_shareholder_of, Electric), (Electric, major_shareholders, Immelt) |
| Pred: (Immelt, place_lived, York), (Immelt, company, Electric), |
| (Immelt, major_shareholder_of, Electric), (Electric, major_shareholders, Immelt) |
| Sentence #4: It is also adding flights on existing routes to several cities, including |
| Kiev and Odessa in Ukraine, and Dubrovnik and Split in Croatia. |
| Gold: (Kiev, country, Ukraine), (Ukraine, capital, Kiev), |
| (Ukraine, administrative_divisions, Kiev), (Croatia, contains, Dubrovnik), |
| (Ukraine, contains, Odessa), (Ukraine, contains, Kiev) |
| Pred: (Kiev, country, Ukraine), (Ukraine, capital, Kiev), |
| (Ukraine, administrative_divisions, Kiev), (Croatia, contains, Dubrovnik), |
| (Ukraine, contains, Odessa), (Croatia, contains, Split), (Ukraine, contains, Kiev) |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, Z.; Yang, L.; Yang, J.; Li, T.; He, L.; Li, Z. A Triple Relation Network for Joint Entity and Relation Extraction. Electronics 2022, 11, 1535. https://doi.org/10.3390/electronics11101535
Wang Z, Yang L, Yang J, Li T, He L, Li Z. A Triple Relation Network for Joint Entity and Relation Extraction. Electronics. 2022; 11(10):1535. https://doi.org/10.3390/electronics11101535
Chicago/Turabian StyleWang, Zixiang, Liqun Yang, Jian Yang, Tongliang Li, Longtao He, and Zhoujun Li. 2022. "A Triple Relation Network for Joint Entity and Relation Extraction" Electronics 11, no. 10: 1535. https://doi.org/10.3390/electronics11101535