1. Introduction
In recent years, due to the massive increase in the number of unknown attacks, the development of a network intrusion detection system (NIDS) that effectively resists unknown attacks is an important topic for the network administrator [
1]. As shown in
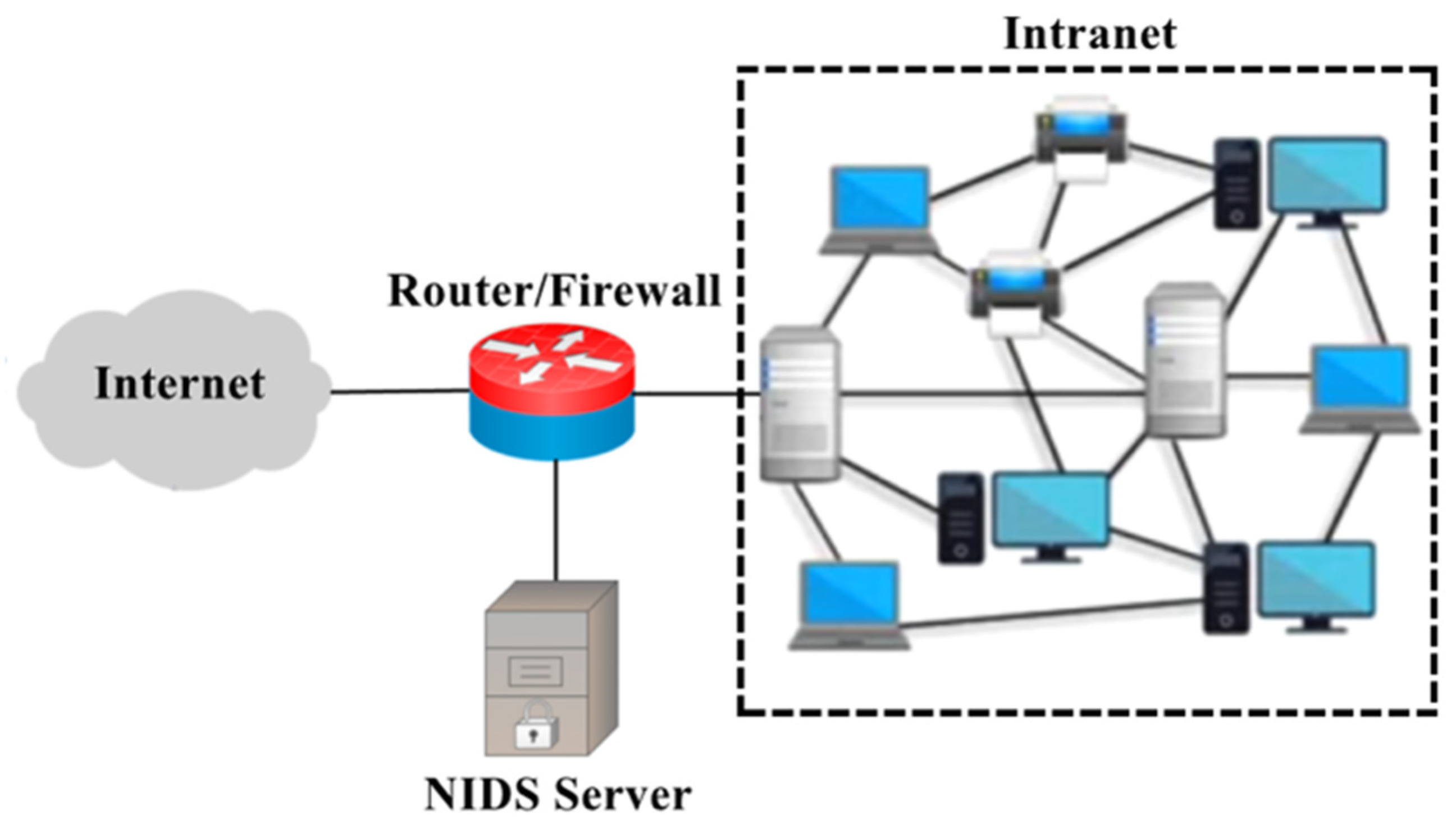
Figure 1, the NIDS server is deployed at the entrance of the connection between the Intranet and the Internet. It monitors the network packets flowing into the Intranet, analyzes statistical data collected from network flows, and uses detection mechanisms to determine if the flows are normal or abnormal. This method can help network managers find abnormal network conditions and then quickly take defensive measures.
The detection scheme of the NIDS can be divided into signature-based intrusion detection and anomaly-based intrusion detection. The former is currently the main detection scheme of commercial NIDS, such as Snort and Suricata. This scheme analyzes the patterns or behaviors of past attack flow samples by experts, writes the analysis results into the flow judging rules, and compares the incoming flow with features to determine whether it conforms to the attack behavior or not. With this scheme, the rate of misjudgment is low, but it is difficult to detect unknown network attacks. The latter uses machine learning or deep learning methods to train a classifier model through a mixture of abnormal and normal flows. This method is easier to detect unknown attacks, but the accuracy is low. On a real network, it is very difficult and time-consuming to label the flow types one by one. Under normal circumstances, most of the available flow samples belong to normal flow. To train the classifier from a small number of abnormal flow samples may cause poor classification results and a high misjudging rate. Unknown attacks easily evade the use of signature-based intrusion detection systems, causing harm to users. Based on the above situations, most researchers use anomaly-based intrusion detection as the detection scheme of NIDS.
V. Chandola et al. [
2] pointed out that according to different learning methods, anomaly detection schemes are divided into three categories, supervised anomaly detection (SAD), semi-supervised anomaly detection (SSAD), and unsupervised anomaly detection (UAD). First, the SAD scheme uses supervised learning to train the detection model with labeled samples (marked with normal or abnormal flow). Typical examples of SAD mechanisms include common convolutional neural networks (CNN) [
3,
4], recurrent neural networks (RNN) [
5], LSTM [
6], decision trees, random forests, Bayesian classifiers, etc. The learning effect of SAD is very good, but due to the limited number of labeled samples, usually only limited abnormal states can be learned. Next, the SSAD scheme is only trained with samples of normal behavior. By learning the behavior patterns of samples with normal flow, it is highly sensitive to unknown abnormal flow. Typical examples of SSAD mechanisms include Auto-Encoder (AE) [
7,
8], One Class-SVM [
9], and Denoising Auto-Encoder (DAE) [
10]. Finally, the UAD mechanism directly trains using unlabeled flow samples. This method must assume that the number of normal flow samples in all flow samples is much larger than abnormal flow samples, and the behavior patterns of abnormal flow samples cannot be too similar to normal flow samples. Without the above premise, the model trained by this method will result in a higher misjudging rate.
As mentioned above, current research tends to use SSAD schemes as the detection model of NIDS. For those SSAD schemes, we perform an experiment and find that the overall accuracy of the DAE model is better than other approaches. We also find that although the overall accuracy of the DAE model is very high, the probability of judging normal flow as abnormal is also higher than that of the supervised model; that is, the precision of the DAE model is lower. To improve the overall accuracy and precision, this paper proposes a two-stage anomaly detection and judging structure by combining SAD and SSAD schemes. To pick our first-stage detection model, we first select two SAD schemes, Gate Recurrent Unit (GRU) [
11] and One-Dimensional Convolutional Neural Network (1DCNN) [
12], together with the DAE model to form a two-stage model and compare them in terms of accuracy. The experimental results show the overall accuracy of the GRU model is better. Therefore, we pick up the GRU model as our first-stage detection model.
In the proposed structure, we first use the GRU model to analyze the network flow and then take the outcome from the Softmax function as a confidence score. When the score is more than or equal to the predefined confidence threshold, the GRU model outputs the flow as a positive result, no matter whether the flow is classified as normal or abnormal. When the score is less than the confidence threshold, the GRU model outputs the flow as a negative result and passes the flow to the DAE model for flow classification. DAE then determines a reconstruction error threshold by learning the pattern of normal flows. Accordingly, the flow is normal or abnormal depending on whether it is under or over the reconstruction error threshold. We train and test the proposed system by using the benchmark dataset NSL-KDD [
13]. In NSL-KDD dataset, the flow is divided into normal flow and abnormal flow, and 41 features are used for training. On the other hand, due to the rapid development of Software Defined Network (SDN) in recent years, we also apply the proposed structure in the SDN network and compare it with other IDS systems applied to SDN [
14] by using the NSL-KDD dataset as the benchmark. Note that because of the characteristics of SDN environment, only nine features of the NSL-KDD dataset are selected to form the benchmark dataset.
The rest of this paper is organized as follows. Dataset used in this paper and related studies are given in
Section 2. In
Section 3, the proposed scheme is presented. Simulation and performance evaluation are given in
Section 4. Finally, we give a conclusion.
3. Two-Stage Deep Learning Structure for Network Flow Anomaly Detection
In order to improve the accuracy and precision of the DAE model, this paper uses a SAD model to assist the DAE model. Among several SAD models, the accuracy of GRU and 1DCNN models performed better than other approaches. For both models, we performed an experiment on them and found that the GRU model could improve the accuracy and precision simultaneously; thus, we chose the GRU model and DAE to form a two-stage deep learning anomaly detection structure. In the proposed structure, we first used the GRU model to analyze the network flow and then took the outcome from the Softmax function as a confidence score. When the score is more than or equal to the predefined confidence threshold, the GRU model outputs the flow as a positive result, no matter whether the flow is classified as normal or abnormal. When the score is less than the confidence threshold, the GRU model outputs the flow as a negative result and passes the flow to the DAE model for flow classification. DAE then determines a reconstruction error threshold by learning the pattern of normal flows. Accordingly, the flow was normal or abnormal depending on whether it was under or over the reconstruction error threshold. The two models add a hidden layer of two neurons when designing the neural network architecture to facilitate subsequent data visualization actions and facilitate the interpretation of researchers.
3.1. Data Preprocessing
Data preprocessing is a very important stage in machine learning. There are different data preprocessing schemes for the features of different data types. Usually, continuous features use feature scaling to scale different features into the same comparison interval, and discrete features use coding methods to classify different types of data. This paper applies Min-Max normalization for continuous features. It is assumed that a sample contains multiple continuous features, and different features have different numerical ranges. By scaling each feature to a fixed size, the training will not be biased for some features. The equation of Min-Max normalization is shown in Equation (1), where
x is the actual value of a sample in the feature to be calculated; min(
x) and max(
x) are the minimum and maximum values of the features in the overall sample, respectively. The normalized value
x′ is calculated by the Equation (1), which can compress the features of different sizes in the range of 0 to 1. With the Min-Max normalization, the data consistency is improved.
Commonly used encoding methods include label encoding and one hot encoding. The label encoding will sequentially encode the newly emerging categories as integers from small to large. This method is fast and does not increase the number of features, but the labeled types are all in the same feature and presented as integers. The one-hot encoding separates each category in the feature into individual features. The disadvantage of one-hot encoding is that the number of features increases according to the number of types in the original feature, but it is easier to learn the content of the feature compared to label encoding. If the added feature is still within the normal range, it is still the most current machine learning mainstream method used in the research. Therefore, in this paper, one-hot encoding scheme is used for discrete features.
3.2. Operational Process of Training and Judging Mode
Two modes, training mode and judging mode, are included in the proposed structure. Each mode consists of two modules, the GRU module, and the DAE module. The detailed operational processes are presented in the following subsections.
3.2.1. Operational Process of Training Mode
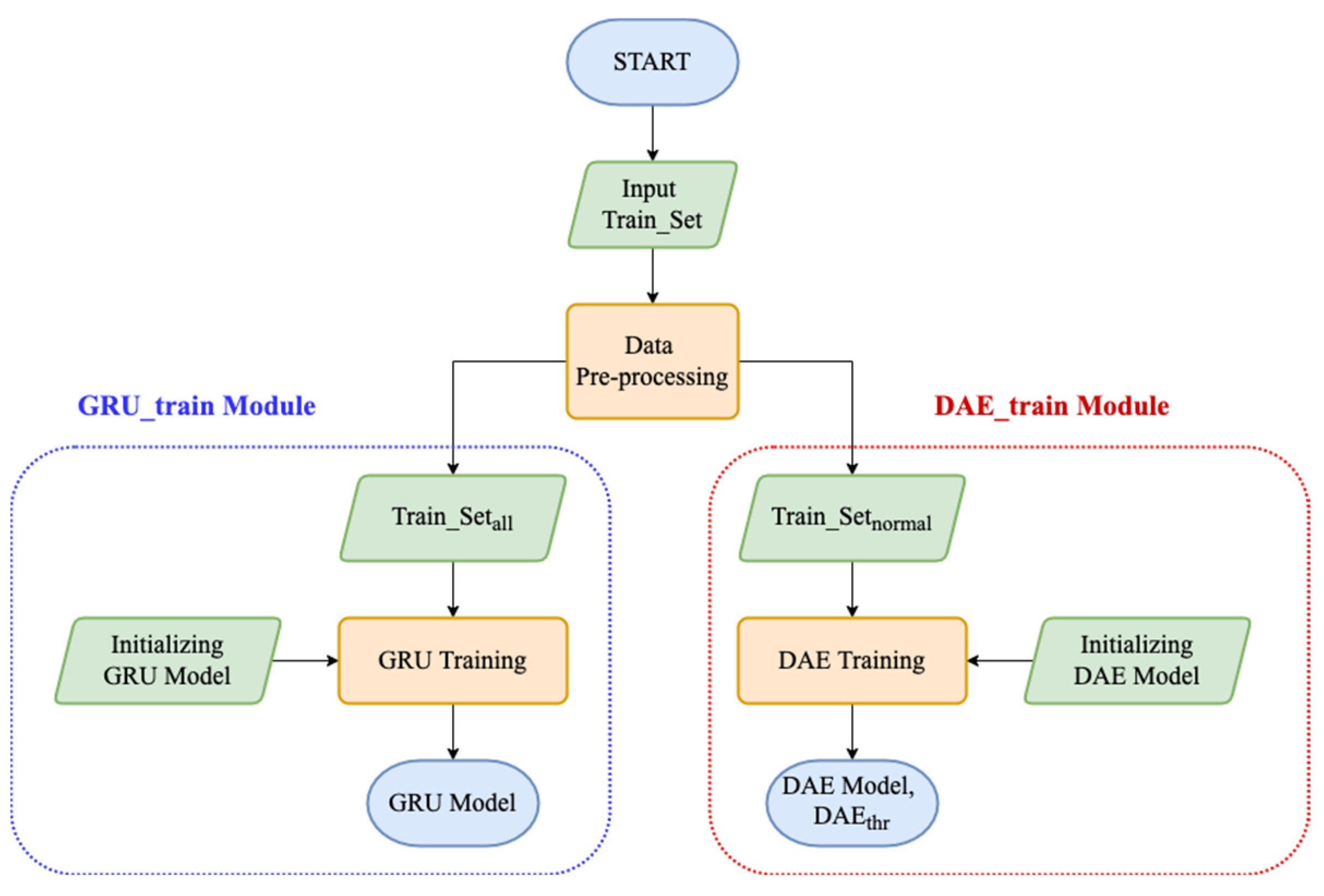
Figure 3 presents the operational process of the training mode.
denote the complete training set flow sample. The data will be preprocessed and converted the features into a format suitable for deep learning. We classified those data into two sets of training samples,
and
where the set of
included all labeled normal and abnormal flow samples and the set of
included labeled normal flow samples. The set of
will be inputted to the GRU_train module as the initialized training sample of GRU model. After the training being completed, the GRU model has learned normal and abnormal flow samples. The set of
will be inputted to the DAE_train module as the initialized training sample of DAE model. After the training is completed, the DAE model has learned normal flow samples. The reconstruction error of the last training epoch will be taken as the DAE reconstruction error threshold Value (
).
3.2.2. Operational Process of Judging Mode
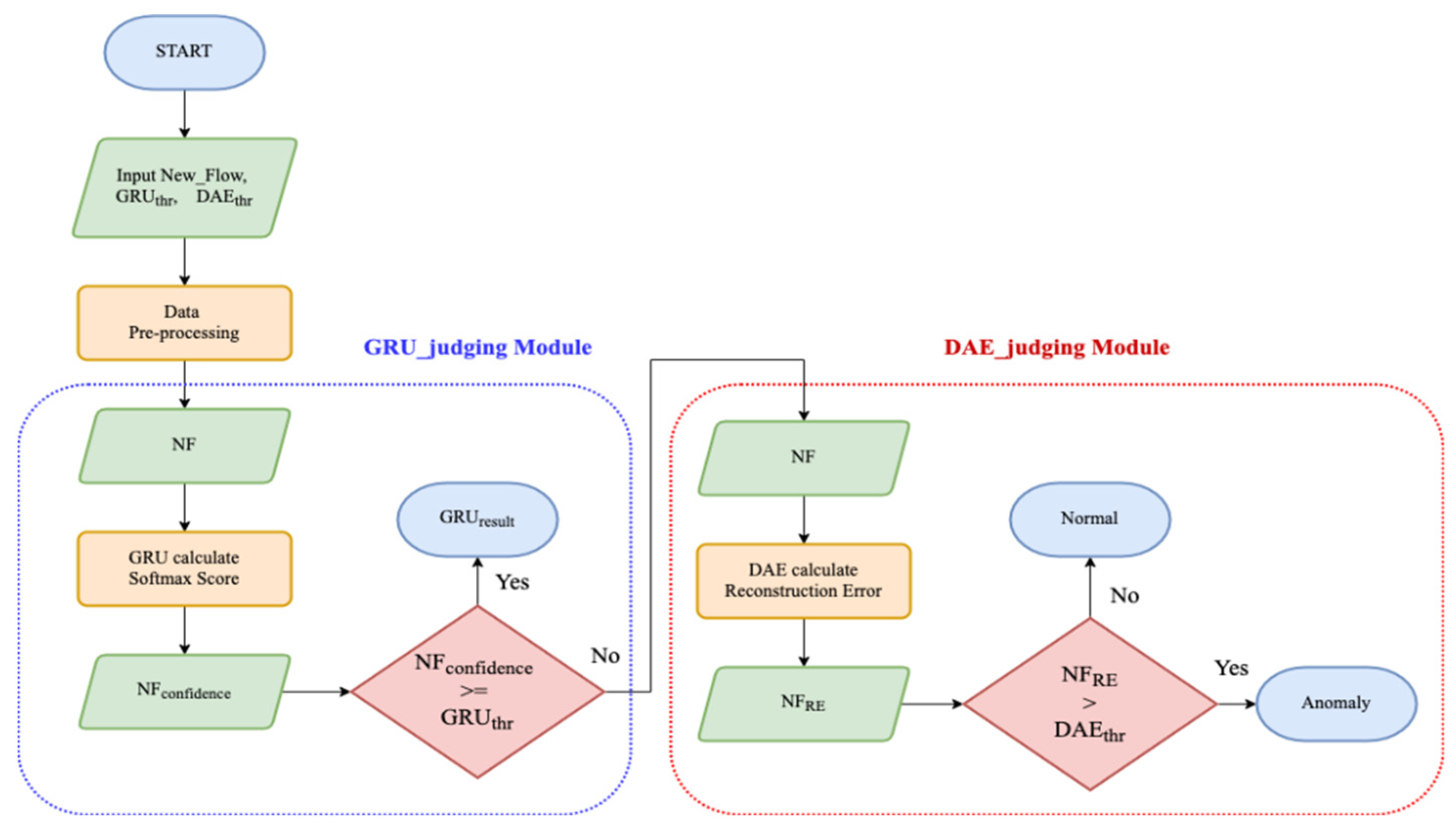
The operational process of the judging mode is shown in
Figure 4. At the beginning of the process, we first have to set the GRU confidence threshold (
) and DAE reconstruction error threshold (
).
can be set by experience, and
is automatically learned by the DAE_train module during training mode. When the judging mode operates, the new flow (New_Flow) will be allowed to enter, and after data is preprocessed, a flow sample (NF) suitable for deep learning is generated. In the first stage, GRU_judging module, the GRU model will calculate the Softmax score for the NF as the confidence score
, and then compare it with the previously set
. If the value of
is greater than or equal to the value of
, it means that the GRU module has sufficient confidence this time. The GRU_judging module will output the result,
, and then end the judgment. If the value of
is lower than value of
, the NF will be passed to the second stage, DAE_judging module, for making a judgment. The DAE_judging module calculates the reconstruction error
for the NF using the DAE model and compares it with
. If the value of
is higher than
, the NF is judged as abnormal flow; otherwise the NF is judged as normal flow.
3.3. Threshold Value Setup and Input Method of GRU
In the GRU model, we used the Softmax score as the confidence score. Softmax is often used in the final output of the classifier model. The Softmax score can be obtained from Equation (2), where exp is the exponential function with Euler numbers e as the base,
is the output of the
th category, and
is divided by all
j-types after exponential function calculation. The sum of the exponential function is to calculate the probability value of the
th category, and the total probability value of all types
j is equal to 1.
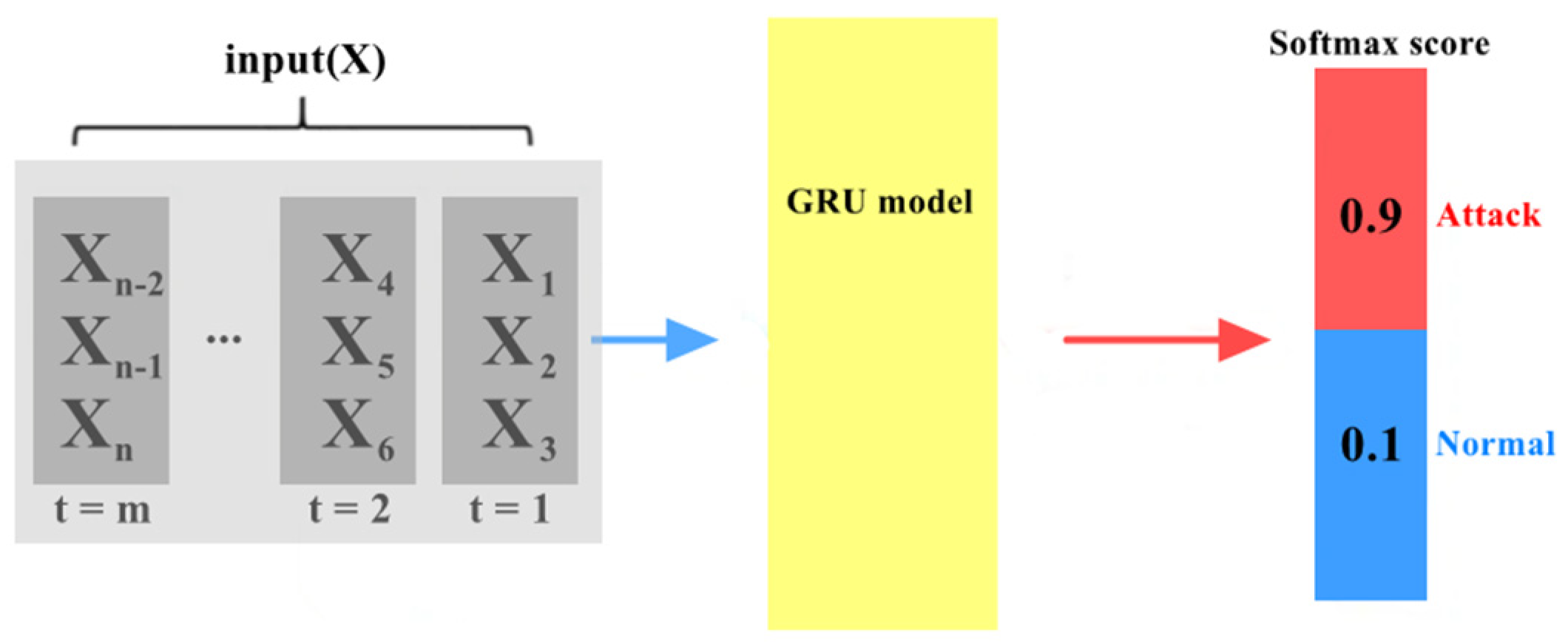
Figure 5 is an example of the GRU model outputting the Softmax score. Because the goal is to separate abnormal flow and normal flow, the GRU model will output a set of two-dimensional vectors, as shown in
Figure 5. In
Figure 5, the values of 0.9 and 0.1 represent that the GRU model believes that the flow is attack flow with a probability of 0.9 and is normal flow with the probability of 0.1. The larger the probability value, the more confident the model is in the judgment. Therefore, when the confidence threshold is not set, the GRU model will directly output the judging result as abnormal flow. In this paper, once a Softmax score is generated, it has to be compared with the confidence threshold. When the confidence score is greater than or equal to the confidence threshold, the GRU model outputs the result; otherwise, it will be handed over to the next stage of the DAE model for judgment.
Due to the Softmax score outputted by the model will have different output results according to different training cycles, model parameters, and other variables, it is difficult to directly set a fixed confidence threshold. In this paper, the confidence threshold setting is adjusted artificially. We actually test the confidence threshold ranging between 0.99900 and 0.99999 on the NSL-KDD data set. It was found that the confidence threshold of the GRU module in this study was between 0.99984 and 0.99996, which has a good performance on the overall structure. Therefore, we set the confidence threshold as 0.99990.
3.4. Threshold Value Setup of DAE
This paper uses the DAE model as the second-stage detection model. DAE creates the effect of missing values by adding noise to the input data. Let the DAE model learn to restore the original data without missing values from the input data with missing values; thus that the trained model is less likely to overfit. This allows the DAE model to learn the really important features from the data, thereby improving generalization capabilities.
In this paper, we use only one hidden layer in the DAE model, which can also be called the bottleneck layer of the autoencoder. In addition, as shown in
Figure 6, we add Dropout [
26] between the input layer and the hidden layer. Through Dropout, different input features can be randomly discarded in each batch of training instead of adding noise to the input. The advantage is that it can achieve the effect of training DAE without changing the original data.
The DAE model uses the Mean-Square Error (MSE) loss function to calculate the reconstruction error, as shown in Equation (3). After training, DAE has learned the normal flow behavior pattern and reconstruction error. We use the MSE of the last training period as the reconstruction error threshold. If the calculated MSE of the new flow is higher than the threshold, this new flow will be judged as abnormal.
3.5. Data Visualization for Softmax Score Selection
Because the network flow data are usually a combination of numerical values and discrete features, observers cannot intuitively understand the results of the model. Therefore, to help observers select and adjust the model, this paper uses the data visualization method to present the neural network model in two-dimensional or even three-dimensional graphics. To conduct that, the bottleneck layer in DAE is set to two neurons. During the prediction, the values of the two neurons in the bottleneck layer of each sample are recorded, and the reconstruction error forms a set of three-dimensional vectors, which are projected on the 3D graphics.
In addition, we also see the last hidden layer of two neurons in the GRU model. The two-dimensional output values of the Softmax score are the probabilities
and
where
represents that the probability of the GRU model considers the flow is normal and
represents that the probability of GRU model considers the flow is abnormal. We convert the two-dimensional output values of the Softmax score into a one-dimensional output value
. When the value of
is greater than the value of
, the value of
is equal to the value of
otherwise, the value of
is equal to the value of
. Through the process of data visualization, the original two-dimensional outputs are converted into one-dimensional outputs, and finally form a three-dimensional vector with the hidden layer of two neurons and project it on the 3D graphics. The process of data visualization for Softmax score selection is shown is Algorithm 1.
| Algorithm 1 Softmax score selection |
Inputs:,
Output: |
| 1: | if > then |
| 2: | = |
| 3: | else = |
| 4: | return |
4. Simulation and Performance Evaluation
To verify the feasibility of the proposed scheme, several experiments are carried out on the Google Colab online platform. The Colab development environment and kits are shown in
Table 3. We first performed 10 times of training experiments on each of the DAE model and the GRU model using the NSL-KDD dataset and calculated the average accuracy. For those 10 DAE models, we selected the DAE model, in which the accuracy was closed to the average accuracy, to be an exemplary model for presenting data visualization, confusion matrix, and the threshold value. One of the GRU models was selected using a similar way. Finally, we made a comparison between the proposed structure and other approaches in terms of accuracy and precision.
The data distribution of NSL-KDD dataset is shown in
Table 4. All four attack types of NSL-KDD dataset were classified as anomalies. The NSL-KDD dataset consists of training set and test set. The total number of samples in the training set was 125,973, in which the number of normal flow samples was 67,343, and the number of abnormal flow samples was 58,630. The total number of samples in the test set was 22,544, in which the number of normal flow samples was 9711, and the number of abnormal flow samples was 12,833. Only normal flow sample in the dataset was used for DAE training and the entire training set was used for GRU training. The discrete data in the NSL-KDD dataset was encoded by one-hot encoding method. After encoding, the total number of features increased from 41 to 126 features.
4.1. Experimental Parameters Setting of DAE Model and GRU Model
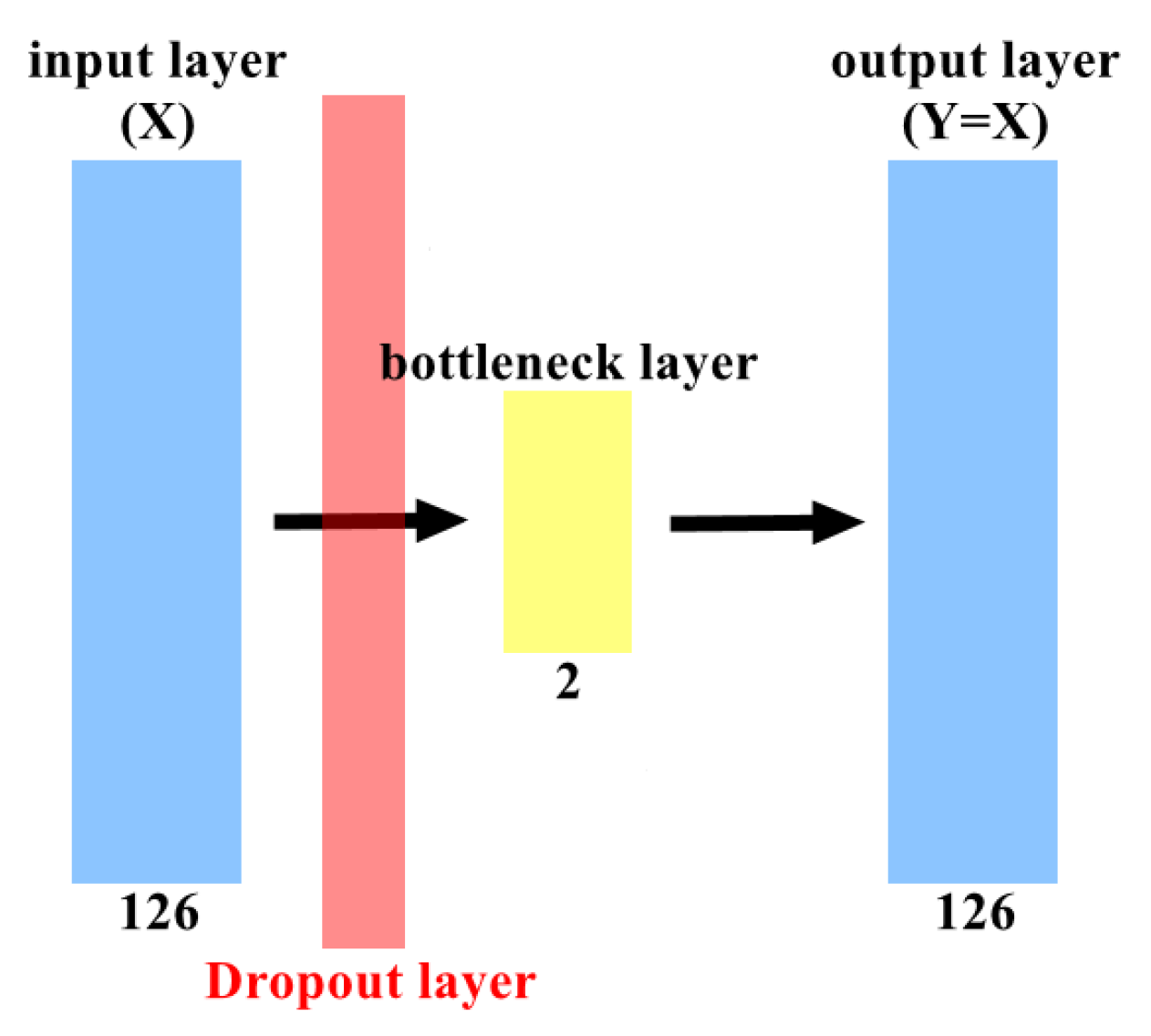
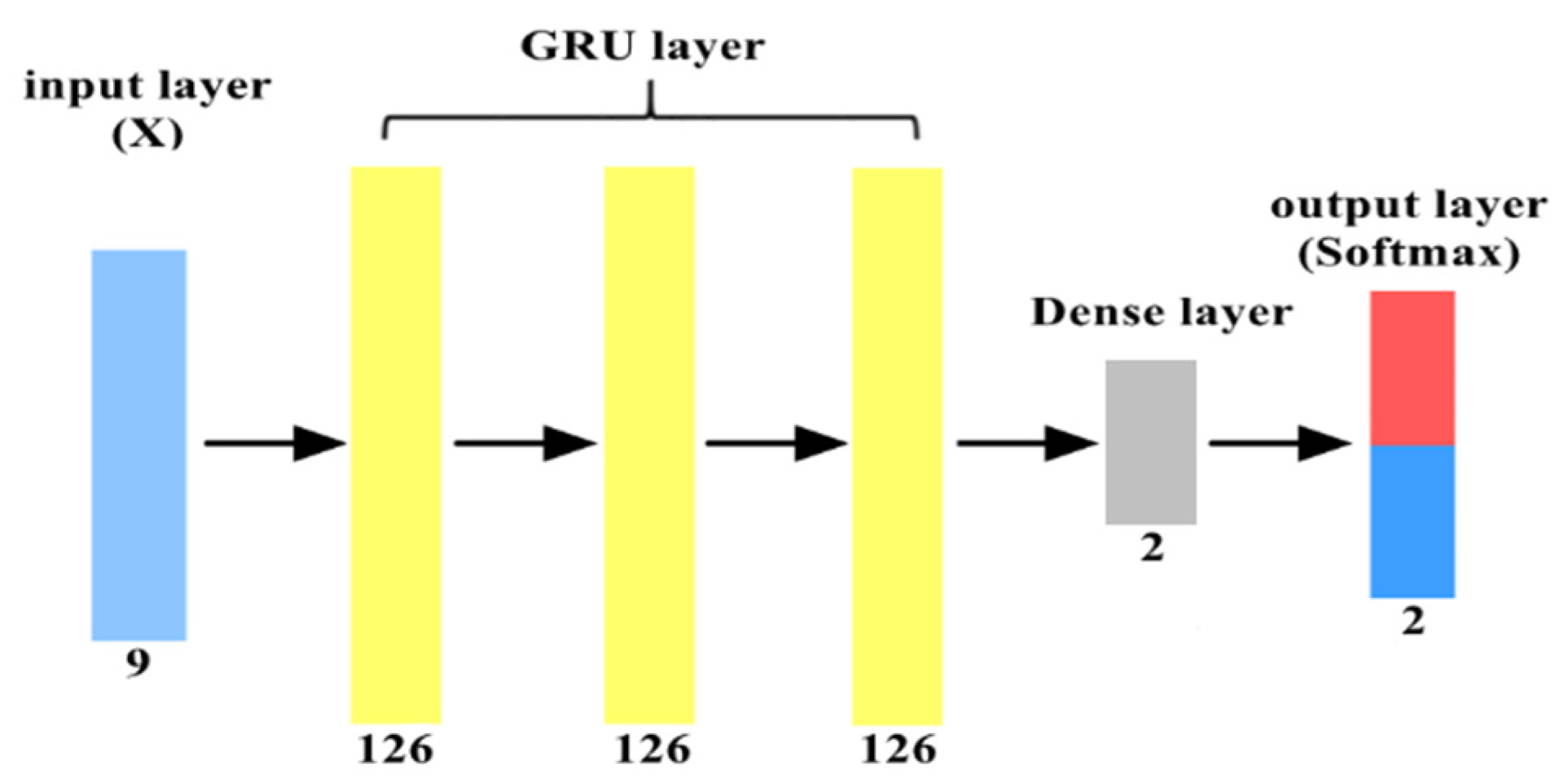
Both DAE and GRU models are shown in
Figure 7 and
Figure 8, respectively. Note that in both figures, the numbers at the bottom of the layer are the number of neurons used in this layer. In
Figure 7, the DAE′s dropout rate is 0.5, which means that half of the features of each batch of input data will be randomly discarded during training. In addition, L2 regularization was added to the bottleneck layer to avoid overfitting. In
Figure 8, 126 features were cut into 14-time steps and input in batches, and 9 features were inputted into each time step. This is because, under the input shape of GRU set to (14, 9), the performance of the GRU model was better. The parameters used are shown in
Table 5. In order to improve the fairness of this research, except for the training period, which is a better value selected after testing, the other parameters were commonly used in the two models. Two models were trained 10 times using the NSL-KDD dataset and numbered 1 to 10. In order to facilitate the presentation of experimental results, we calculated the average accuracy of each model and picked the model in which the accuracy was closest to the average accuracy.
4.2. Experimental Results
The experimental results of deep learning usually have a certain degree of randomness, and most studies use accuracy, recall, precision, and F-measure to compare performance. However, few studies show that the final experimental result is obtained after how many experiments or the overall average. In this paper, the final results are obtained based on the average results of 10 experiments.
4.2.1. GRU and DAE Models Training Results
We first performed 10 times of training experiments on each of the GRU model and the DAE model using the NSL-KDD dataset as a benchmark and calculated the average accuracy, the average recall, the average precision, and the average F-measure. The results are shown in
Table 6 and
Table 7, respectively. From both tables, one can see that the accuracy of GRU_3 model and DAE_1 model was closest to the average accuracy. Therefore, both models were selected as exemplary models for presenting data visualization, confusion matrix, and the threshold value.
4.2.2. Data Visualization Results
Both the GRU_3 model and the DAE_1 model are visualized with 22544 samples using the complete NSL-KDD test dataset.
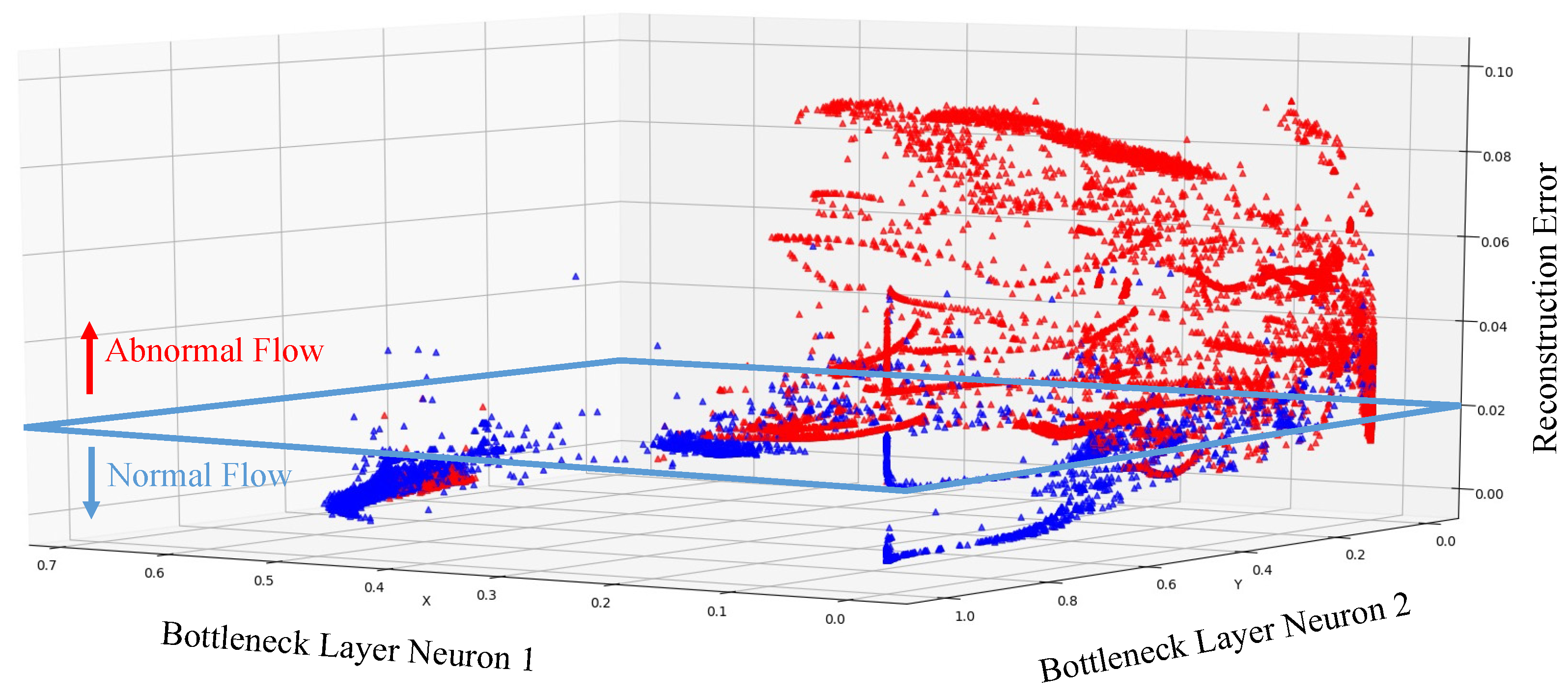
Figure 9 is the visualization result of the DAE_1 model’s reconstruction error. The red sample is the actual abnormal flow, and the blue sample is the actual normal flow. The x and y axes are the output of two neurons in the bottleneck layer in the DAE, and the z-axis is the reconstruction error of each sample. The DAE_1 model was trained, and then the reconstruction error threshold value was obtained, as shown in the blue frame of
Figure 9. Above this threshold, it was judged as abnormal flow, and below the threshold value was judged as normal flow. As seen in
Figure 9, the reconstruction error of most abnormal flow will be very high. The reconstruction error of normal flow was relatively low, and we could obtain good results from a pure DAE model. However, in the lower-left corner of
Figure 9, there are still a small number of abnormal flow reconstruction errors that are almost the same as the normal samples. Moreover, it is difficult to judge the normal flow and abnormal flow at the junction of the reconstruction error threshold, which leads to the misjudgment of the model. Therefore, we need to use other models to assist the judgment of the DAE model.
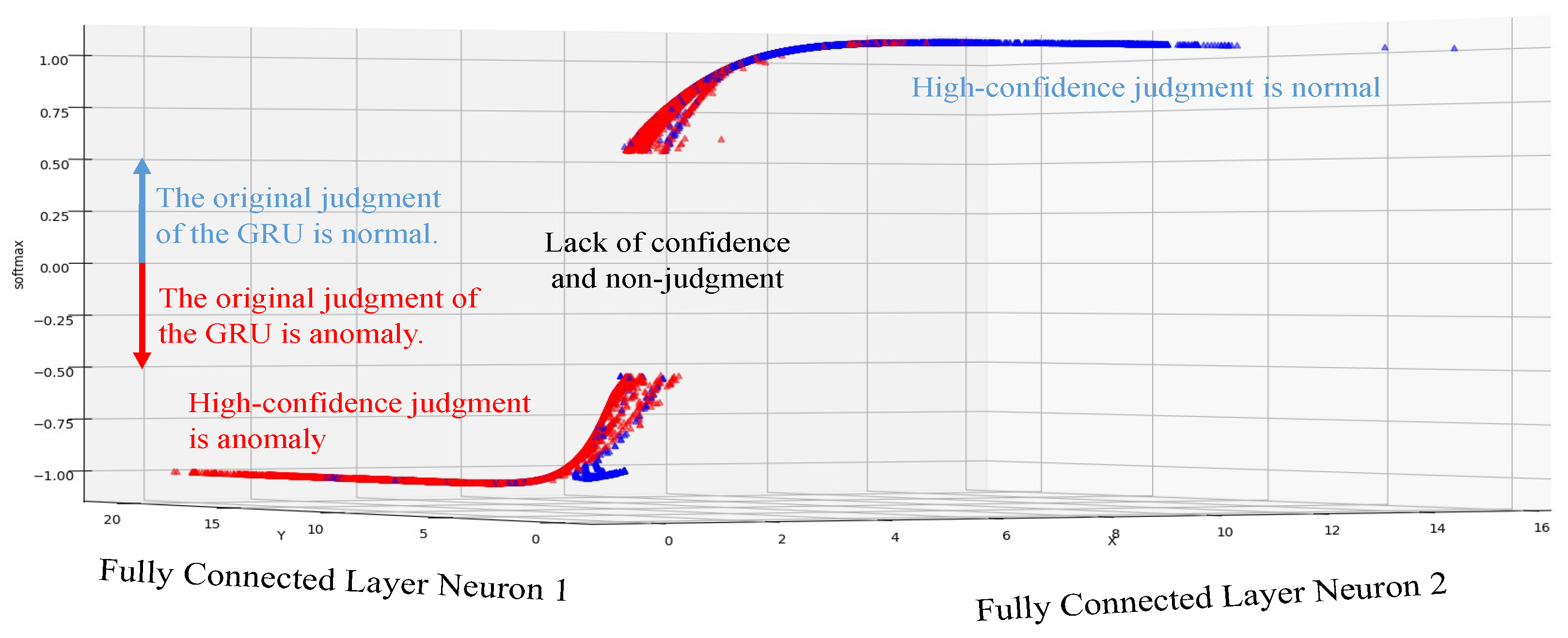
Figure 10 shows the visualization result of the GRU_3 model’s confidence judgment. The red samples and the blue samples are the actual attacks and the actual normal sample, respectively. The x and y axes are the output of two hidden layer neurons, and the z-axis is the Softmax confidence score, in which the value is between 1 and −1. The Softmax confidence score greater than 0 means that the original GRU_3 model’s judgment is normal, and the Softmax confidence score less than 0 means the judgment is abnormal. It can be found that there are many judging errors (gray blocks) in the GRU as a whole. The overall accuracy of the GRU_3 model is 78.85%, but when the confidence score is close to 1 and −1 (blue block and red block), the judging result is obviously much better. Therefore, according to the confidence threshold we set, GRU will output the samples with high confidence score, and the remaining samples with insufficient confidence will be handed over to DAE for processing. Through the data visualization in
Figure 10, it can be understood that the overall under-performing model may still perform well in the judging accuracy of the high confidence interval.
4.2.3. GRU Model’s Confidence Threshold Setup
This paper tested different thresholds for the GRU model’s confidence threshold setting. We intend to observe how the adjustment of the GRU model’s confidence threshold affects the number of flows passing thresholds and how much accuracy can be improved by comparing the results of only the DAE model used. The results are shown in
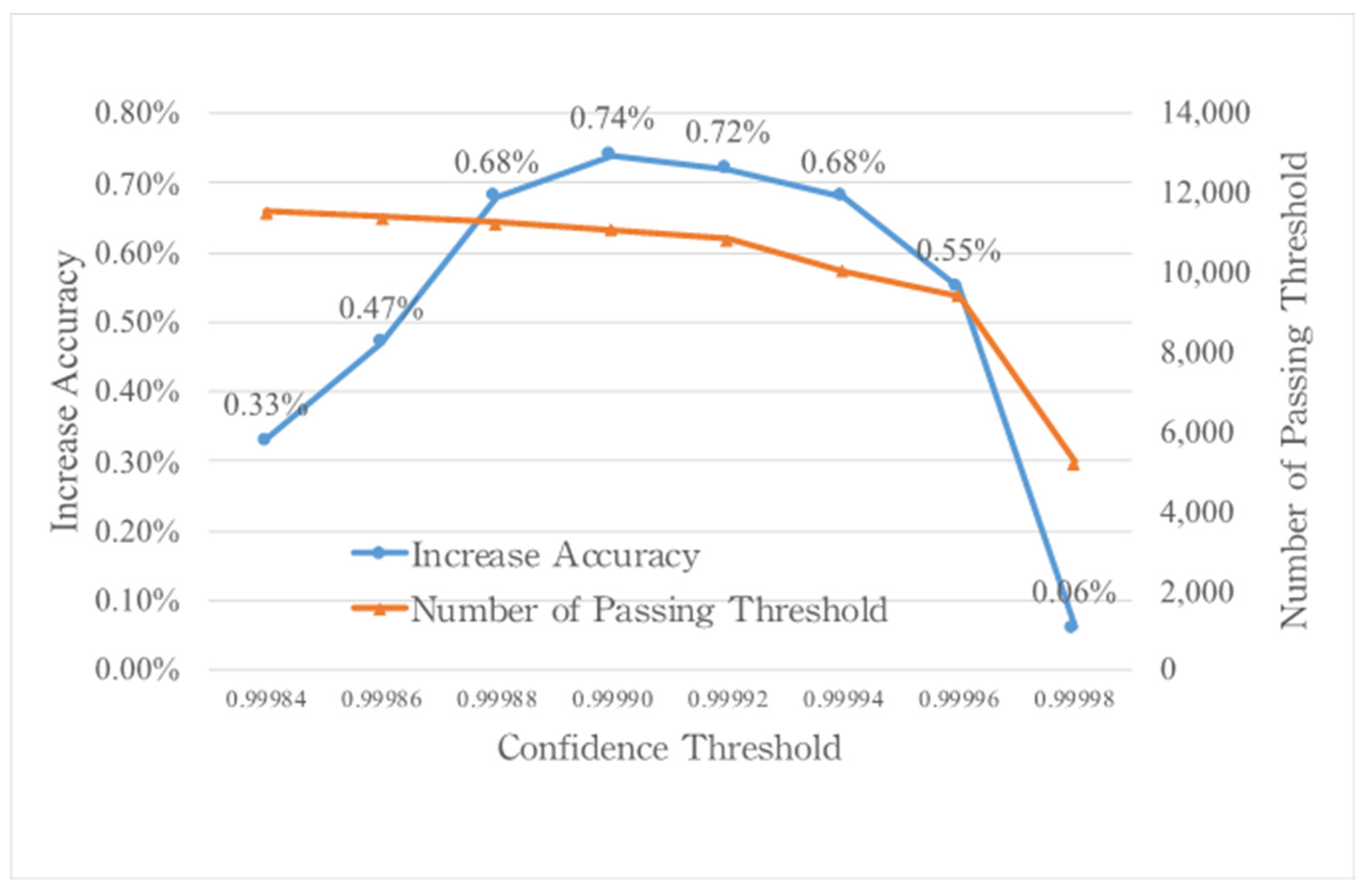
Figure 11. From
Figure 11, we can find that when the confidence threshold is from 0.99984 to 0.99996, the accuracy of the overall structure is improved by at least 0.3%, of which 0.99990 has the best effect. The level of the threshold also directly affects the number of flows passing through the confidence threshold. The higher the threshold, the less the number of flows passes, resulting in the accuracy increasing. However, if the threshold is set too high, the number of flows passing will be reduced, and the effect of improving the accuracy will be reduced. The other extreme is that the threshold is too low. For the above reasons, we believe that the confidence threshold must be adjusted slowly from high to low in order to find an appropriate threshold.
The performance result of the GRU model with and without the confidence threshold is shown in
Table 8, where the confidence threshold of the GRU model is 0.99990. From the table, one can see that the accuracy of the GRU model with confidence threshold screening (GRU-CT) is better than the accuracy of the GRU model without confidence threshold screening.
4.2.4. Comparisons
Table 9 shows the comparison between the GRU-DAE model and other approaches in terms of accuracy. The accuracy of our proposed structure is 90.21%, which is better than most current methods. In addition, the best-performing of GRU-DAE model (GRU-DAE (best)) in 10 experiments can achieve 90.56% accuracy.
5. Application to SDN-Based Network Flow Anomaly Detection
Software Defined Network (SDN) is a new form of network architecture to improve the shortcomings of traditional networks, such as low scalability. The main difference between the SDN network and the traditional network is the separation of the control plane (Control Plane) and the data plane (Data Plane) of the network. The SDN controller (Controller) uses the OpenFlow protocol [
27] and the OpenFlow switch (OpenFlow Switch) to communicate to manage the entire SDN network. Because the SDN network is centralized management, it is easy to collect overall network information, and it has better security than traditional networks. TATang et al. [
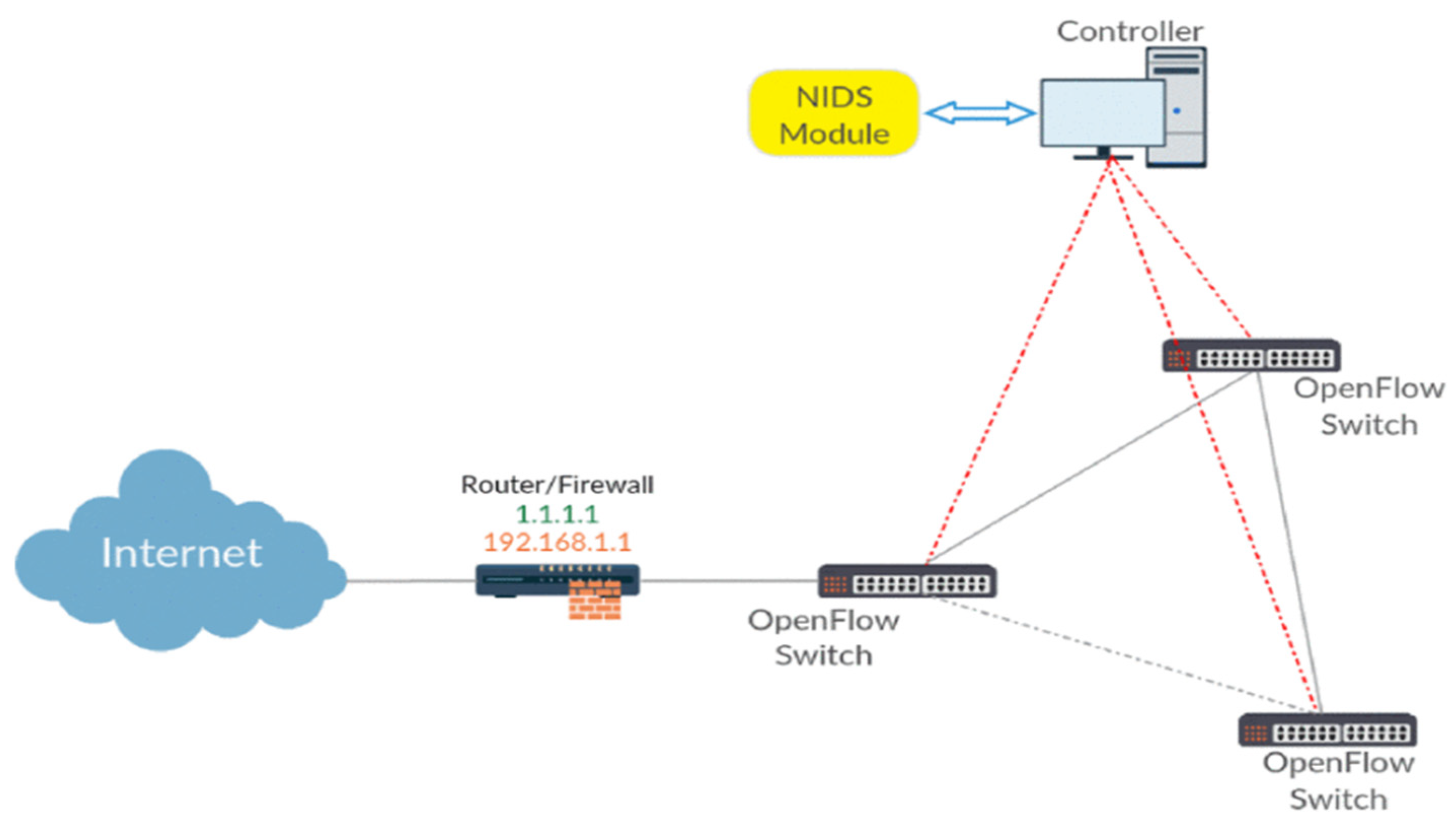
28] proposed a NIDS based on the SDN architecture as shown in
Figure 12. The network intrusion detection system module is installed on the controller side, and the SDN controller sends the ofp_flow_stats_request command to the SDN at a fixed time. All OpenFlow switches in the network request statistics about network flow characteristics. After receiving the request, the OpenFlow switch will send the ofp_flow_stats_reply command containing statistical flow characteristics information to the SDN controller for unified processing. In order to avoid the SDN controller consuming a lot of computing resources to count the characteristics of network flow, M. Latah et al. [
14] selected the most suitable features for SDN by applying principal component analysis (PCA) to the NSL-KDD dataset. The selected features are shown in
Table 10.
By using SDN-related features on the NSL-KDD dataset as a benchmark, we compared the experimental result of our approach applied to SDN network with several schemes experimented by M. Latah et al. [
14]. The result is shown in
Table 11. Although the accuracy of GRU-DAE was slightly lower than the decision tree scheme, our approach performed better than the decision tree on precision and F-measure. In particular, the precision was far ahead of other approaches.
6. Conclusions
We propose a two-stage deep learning anomaly detection structure by combining the schemes of the GRU model and DAE model. By using supervised anomaly detection with a selection mechanism to assist semi-supervised anomaly detection, the precision and accuracy of the anomaly detection system are improved. We also used the method of data visualization to understand the reasons for the insufficient accuracy of the GRU model. Moreover, we used the confidence threshold screening method to make better flow judgments. With the proposed structure, we improved the accuracy of 0.54% and precision of 0.83% of the DAE model using the NSL-KDD dataset as a benchmark, reaching an overall accuracy of 90.21%. We also applied the proposed system in the SDN environment and compared it with other IDS systems applied to the SDN environment. The results revealed that the proposed method could achieve precision of 88.8% and F-measure of 89.87%, which is better than Support Vector Machine, K-Nearest Neighbors algorithm, Decision Tree, etc. At present, this research is only tested using the NSL-KDD dataset as a benchmark. Additionally, we also found that recently several papers used UNSW-NB15 as the benchmark dataset. In the future, we will use UNSW-NB15 dataset as the benchmark dataset in our proposed structure or use the data of real network environments and make a comparison between them.
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}