
Diagnostic Evaluation of Policy-Gradient-Based Ranking



Abstract
:1. Introduction
2. Related Work
3. Cranfield Learning-to-Rank
ListMLE
4. Policy-Gradient-Based Ranking
4.1. Expected Utility
4.2. Reinforcement Learning-to-Rank
4.3. Adversarial Learning to Rank
4.3.1. Generator Optimization
4.3.2. Discriminator Optimization
| Algorithm 1 Listwise adversarial learning-to-rank. |
|
4.4. Theoretical Analysis
5. Experimental Setup
5.1. Datasets
5.2. Model Configuration
6. Results and Analysis
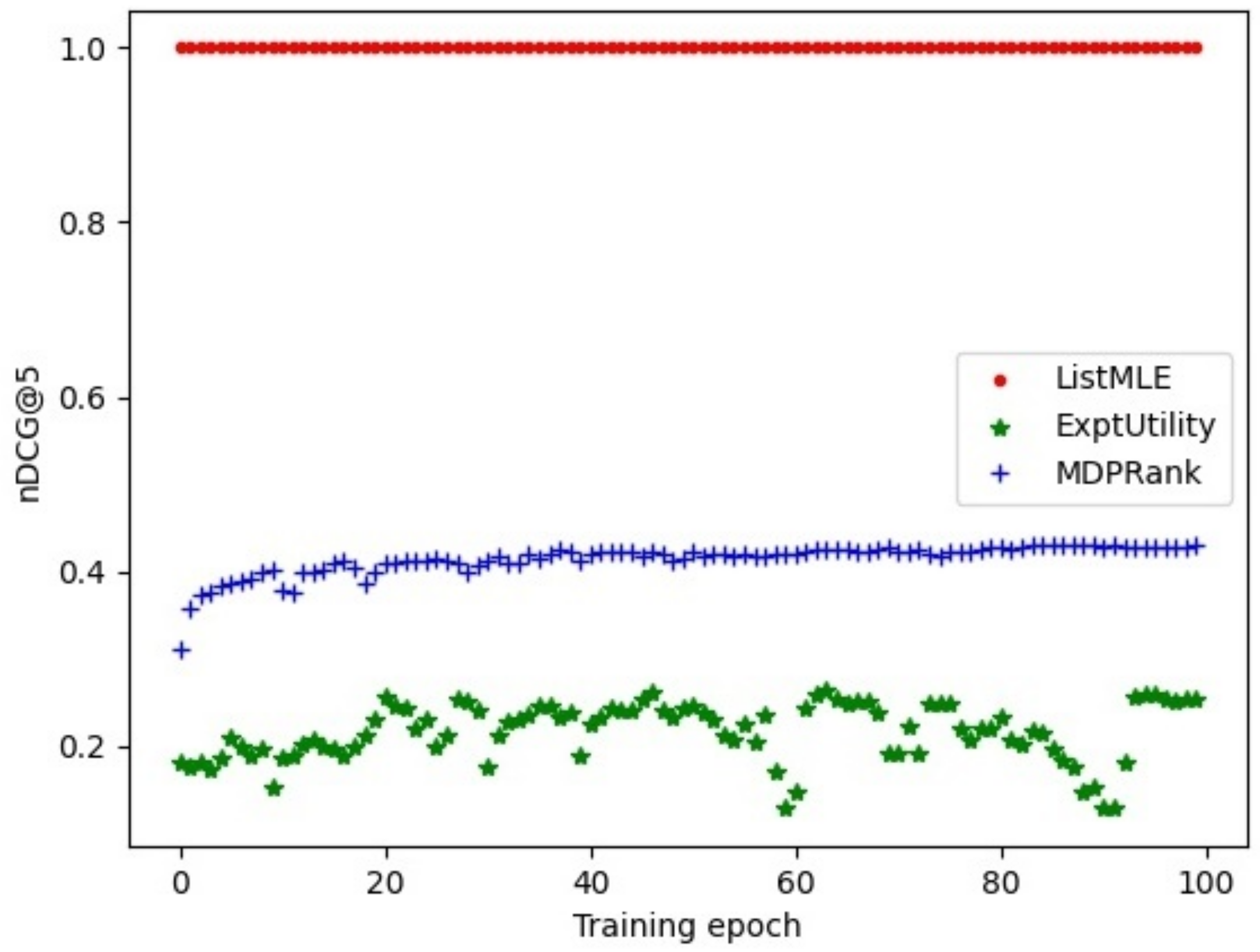
6.1. Performances of Policy-Gradient-Based Ranking Methods
6.2. Policy-Gradient-Based Ranking Methods versus Conventional Ranking Methods
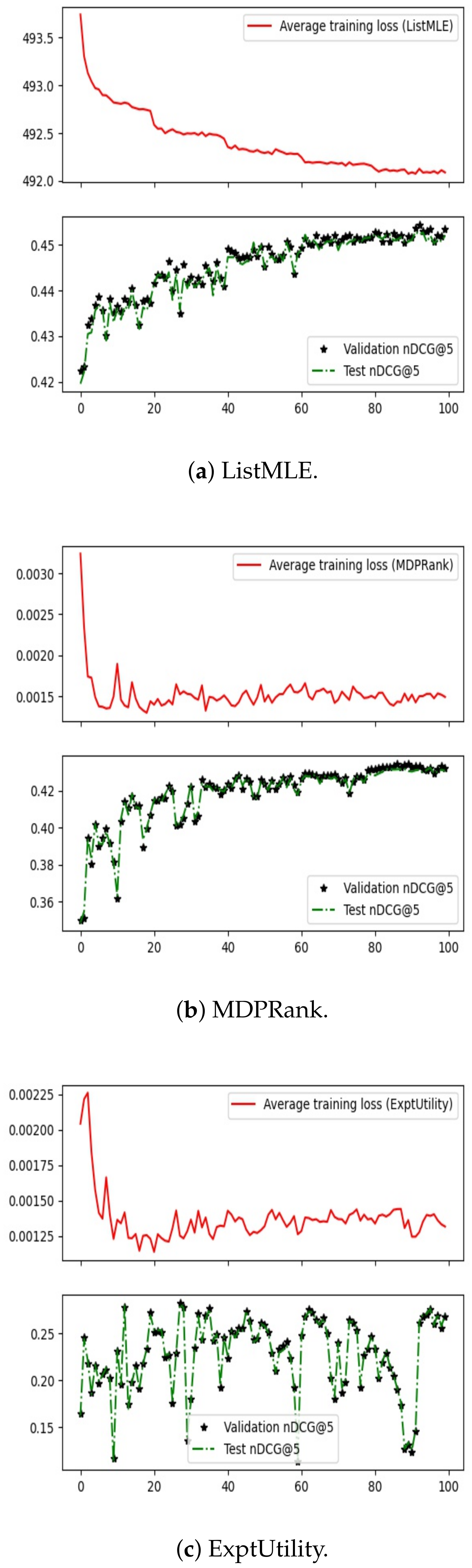
6.3. Examination of Training Process
7. Conclusions
References
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Liu, B.; Chen, J.; Wang, X. Application of learning to rank to protein remote homology detection. Bioinformatics 2015, 31, 3492–3498. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Järvelin, K.; Kekäläinen, J. Cumulated gain-based evaluation of IR techniques. ACM Trans. Inf. Syst. 2002, 20, 422–446. [Google Scholar] [CrossRef]
- Cossock, D.; Zhang, T. Subset Ranking Using Regression. In Proceedings of the 19th Annual Conference on Learning Theory, Pittsburgh, PA, USA, 22–25 June 2006; pp. 605–619. [Google Scholar]
- Chu, W.; Ghahramani, Z. Gaussian Processes for Ordinal Regression. J. Mach. Learn. Res. 2005, 6, 1019–1041. [Google Scholar]
- Chu, W.; Keerthi, S.S. New Approaches to Support Vector Ordinal Regression. In Proceedings of the 22nd ICML, Bonn, Germany, 7–11 August 2005; pp. 145–152. [Google Scholar]
- Burges, C.; Shaked, T.; Renshaw, E.; Lazier, A.; Deeds, M.; Hamilton, N.; Hullender, G. Learning to rank using gradient descent. In Proceedings of the 22nd ICML, Bonn, Germany, 7–11 August 2005; pp. 89–96. [Google Scholar]
- Freund, Y.; Iyer, R.; Schapire, R.E.; Singer, Y. An Efficient Boosting Algorithm for Combining Preferences. J. Mach. Learn. Res. 2003, 4, 933–969. [Google Scholar]
- Shen, L.; Joshi, A.K. Ranking and Reranking with Perceptron. Mach. Learn. 2005, 60, 73–96. [Google Scholar] [CrossRef] [Green Version]
- Joachims, T. Training Linear SVMs in Linear Time. In Proceedings of the 12th KDD, Philadelphia, PA, USA, 20–23 August 2006; pp. 217–226. [Google Scholar]
- Chapelle, O.; Le, Q.; Smola, A. Large Margin Optimization of Ranking Measures. NIPS Workshop on Machine Learning for Web Search. 2007. Available online: https://fravia.2113.ch/library/Large%20margin%20optimization%20of%20ranking%20measures.pdf (accessed on 15 August 2019).
- Xu, J.; Li, H. AdaRank: A boosting algorithm for information retrieval. In Proceedings of the 30th SIGIR, Amsterdam, The Netherlands, 23–27 July 2007; pp. 391–398. [Google Scholar]
- Yue, Y.; Finley, T.; Radlinski, F.; Joachims, T. A Support Vector Method for Optimizing Average Precision. In Proceedings of the 30th SIGIR, Amsterdam, The Netherlands, 23–27 July 2007; pp. 271–278. [Google Scholar]
- Guiver, J.; Snelson, E. Learning to Rank with SoftRank and Gaussian Processes. In Proceedings of the 31st SIGIR, Singapore, 20–24 July 2008; pp. 259–266. [Google Scholar]
- Taylor, M.; Guiver, J.; Robertson, S.; Minka, T. SoftRank: Optimizing Non-smooth Rank Metrics. In Proceedings of the 1st WSDM, Palo Alto, CA, USA, 11–12 February 2008; pp. 77–86. [Google Scholar]
- Qin, T.; Liu, T.Y.; Li, H. A general approximation framework for direct optimization of information retrieval measures. J. Inf. Retr. 2010, 13, 375–397. [Google Scholar] [CrossRef]
- Wu, Q.; Burges, C.J.; Svore, K.M.; Gao, J. Adapting Boosting for Information Retrieval Measures. J. Inf. Retr. 2010, 13, 254–270. [Google Scholar] [CrossRef]
- Cao, Z.; Qin, T.; Liu, T.Y.; Tsai, M.F.; Li, H. Learning to Rank: From Pairwise Approach to Listwise Approach. In Proceedings of the 24th ICML, Corvalis, OR, USA, 20–24 June 2007; pp. 129–136. [Google Scholar]
- Xia, F.; Liu, T.Y.; Wang, J.; Zhang, W.; Li, H. Listwise Approach to Learning to Rank: Theory and Algorithm. In Proceedings of the 25th ICML, Helsinki, Finland, 5–9 July 2008; pp. 1192–1199. [Google Scholar]
- Volkovs, M.N.; Zemel, R.S. BoltzRank: Learning to Maximize Expected Ranking Gain. In Proceedings of the ICML, Montreal, QC, Canada, 14–18 June 2009; pp. 1089–1096. [Google Scholar]
- Burges, C.J.C.; Ragno, R.; Le, Q.V. Learning to Rank with Nonsmooth Cost Functions. In Proceedings of the NeurIPS, Vancouver, BC, Canada, 4–7 December 2006; pp. 193–200. [Google Scholar]
- Yu, H.T.; Jatowt, A.; Joho, H.; Jose, J.; Yang, X.; Chen, L. WassRank: Listwise Document Ranking Using Optimal Transport Theory. In Proceedings of the 12th WSDM, Melbourne, Australia, 11–15 February 2019; pp. 24–32. [Google Scholar]
- Wei, Z.; Xu, J.; Lan, Y.; Guo, J.; Cheng, X. Reinforcement Learning to Rank with Markov Decision Process. In Proceedings of the 40th SIGIR, Tokyo, Japan, 7–11 August 2017; pp. 945–948. [Google Scholar]
- Zou, S.; Li, Z.; Akbari, M.; Wang, J.; Zhang, P. MarlRank: Multi-Agent Reinforced Learning to Rank. In Proceedings of the CIKM, Beijing, China, 3–7 November 2019; pp. 2073–2076. [Google Scholar]
- Zeng, W.; Xu, J.; Lan, Y.; Guo, J.; Cheng, X. Multi Page Search with Reinforcement Learning to Rank. In Proceedings of the ICTIR, Tianjin, China, 14–17 September 2018; pp. 175–178. [Google Scholar]
- Feng, Y.; Xu, J.; Lan, Y.; Guo, J.; Zeng, W.; Cheng, X. From Greedy Selection to Exploratory Decision-Making: Diverse Ranking with Policy-Value Networks. In Proceedings of the SIGIR, Ann Arbor, MI, USA, 8–12 July 2018; pp. 125–134. [Google Scholar]
- Singh, A.; Joachims, T. Policy Learning for Fairness in Ranking. In Proceedings of the NeurIPS, Vancouver, BC, Canada, 8–14 December 2019; pp. 5426–5436. [Google Scholar]
- Montazeralghaem, A.; Zamani, H.; Allan, J. A Reinforcement Learning Framework for Relevance Feedback. In Proceedings of the SIGIR, Virtual Event, China, 25–30 July 2020; pp. 59–68. [Google Scholar]
- Xu, J.; Wei, Z.; Xia, L.; Lan, Y.; Yin, D.; Cheng, X.; Wen, J.R. Reinforcement Learning to Rank with Pairwise Policy Gradient. In Proceedings of the SIGIR, Virtual Event, China, 25–30 July 2020; pp. 509–518. [Google Scholar]
- Yao, J.; Dou, Z.; Xu, J.; Wen, J.R. RLPer: A Reinforcement Learning Model for Personalized Search. In Proceedings of the Web Conference, Taipei, Taiwan, 20–24 April 2020; pp. 2298–2308. [Google Scholar]
- Wang, J.; Yu, L.; Zhang, W.; Gong, Y.; Xu, Y.; Wang, B.; Zhang, P.; Zhang, D. IRGAN: A Minimax Game for Unifying Generative and Discriminative Information Retrieval Models. In Proceedings of the 40th SIGIR, Tokyo, Japan, 7–11 August 2017; pp. 515–524. [Google Scholar]
- He, X.; He, Z.; Du, X.; Chua, T.S. Adversarial Personalized Ranking for Recommendation. In Proceedings of the SIGIR, Ann Arbor, MI, USA, 8–12 July 2018; pp. 355–364. [Google Scholar]
- Park, D.H.; Chang, Y. Adversarial Sampling and Training for Semi-Supervised Information Retrieval. In Proceedings of the Web Conference, San Francisco, CA, USA, 13–17 May 2019; pp. 1443–1453. [Google Scholar]
- Wang, B.; Yang, Y.; Xu, X.; Hanjalic, A.; Shen, H.T. Adversarial Cross-Modal Retrieval. In Proceedings of the International Conference on Multimedia, Mountain View, CA, USA, 23–27 October 2017; pp. 154–162. [Google Scholar]
- Wang, Z.; Xu, Q.; Ma, K.; Jiang, Y.; Cao, X.; Huang, Q. Adversarial Preference Learning with Pairwise Comparisons. In Proceedings of the International Conference on Multimedia, Nice, France, 21–25 October 2019; pp. 656–664. [Google Scholar]
- Lin, K.; Yang, F.; Wang, Q.; Piramuthu, R. Adversarial Learning for Fine-Grained Image Search. In Proceedings of the ICME, San Diego, CA, USA, 23–27 July 2018; pp. 490–495. [Google Scholar]
- Liu, J.; Dou, Z.; Wang, X.; Lu, S.; Wen, J.R. DVGAN: A Minimax Game for Search Result Diversification Combining Explicit and Implicit Features. In Proceedings of the SIGIR, Virtual Event, China, 25–30 July 2020; pp. 479–488. [Google Scholar]
- Nallapati, R. Discriminative Models for Information Retrieval. In Proceedings of the 27th SIGIR, Sheffield, UK, 25–29 July 2004; pp. 64–71. [Google Scholar]
- Joachims, T. Optimizing search engines using clickthrough data. In Proceedings of the 8th KDD, Edmonton, AB, Canada, 23–26 July 2002; pp. 133–142. [Google Scholar]
- Yuan, F.; Guo, G.; Jose, J.; Chen, L.; Yu, H.T.; Zhang, W. LambdaFM: Learning Optimal Ranking with Factorization Machines Using Lambda Surrogates. In Proceedings of the 25th CIKM, Indianapolis, IN, USA, 24–28 October 2016; pp. 227–236. [Google Scholar]
- Chapelle, O.; Metlzer, D.; Zhang, Y.; Grinspan, P. Expected reciprocal rank for graded relevance. In Proceedings of the 18th CIKM, Hong Kong, China, 2–6 November 2009; pp. 621–630. [Google Scholar]
- Liu, T.Y. Learning to Rank for Information Retrieval; Springer: Berlin/Heidelberg, Germany, 2011. [Google Scholar]
- Li, H. Learning to Rank for Information Retrieval and Natural Language Processing. In Synthesis Lectures on Human Language Technologies; University of Toronto: Toronto, ON, Canada, 2011; Volume 4. [Google Scholar]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef] [PubMed]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 CVPR, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Goodfellow, I.J.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative Adversarial Nets. In Proceedings of the NeurIPS, Montreal, QC, Canada, 8–13 December 2014. [Google Scholar]
- Szegedy, C.; Ioffe, S.; Vanhoucke, V. Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning. In Proceedings of the Thirty-First AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2016; pp. 4278–4284. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the NAACL-HLT 2019, Minneapolis, MN, USA, 2–7 June 2019; pp. 4171–4186. [Google Scholar]
- Hu, B.; Lu, Z.; Li, H.; Chen, Q. Convolutional Neural Network Architectures for Matching Natural Language Sentences. In Proceedings of the 27th NIPS, Montreal, QC, Canada, 8–13 December 2014; pp. 2042–2050. [Google Scholar]
- Huang, P.S.; He, X.; Gao, J.; Deng, L.; Acero, A.; Heck, L. Learning Deep Structured Semantic Models for Web Search Using Clickthrough Data. In Proceedings of the CIKM, San Francisco, CA, USA, 27 October–1 November 2013; pp. 2333–2338. [Google Scholar]
- Shen, Y.; He, X.; Gao, J.; Deng, L.; Mesnil, G. Learning Semantic Representations Using Convolutional Neural Networks for Web Search. In Proceedings of the 23rd WWW, Seoul, Korea, 7–11 April 2014; pp. 373–374. [Google Scholar]
- Guo, J.; Fan, Y.; Ai, Q.; Croft, W.B. A Deep Relevance Matching Model for Ad-hoc Retrieval. In Proceedings of the 25th CIKM, Indianapolis, IN, USA, 24–28 October 2016; pp. 55–64. [Google Scholar]
- Pang, L.; Lan, Y.; Guo, J.; Xu, J.; Wan, S.; Cheng, X. Text Matching As Image Recognition. In Proceedings of the AAAI Conference on Artificial Intelligence, Phoenix, AZ, USA, 12–17 February 2016; pp. 2793–2799. [Google Scholar]
- Wan, S.; Lan, Y.; Xu, J.; Guo, J.; Pang, L.; Cheng, X. Match-SRNN: Modeling the Recursive Matching Structure with Spatial RNN. In Proceedings of the IJCAI Conference, New York, NY, USA, 9–15 July 2016; pp. 2922–2928. [Google Scholar]
- Bello, I.; Kulkarni, S.; Jain, S.; Boutilier, C.; Chi, E.; Eban, E.; Luo, X.; Mackey, A.; Meshi, O. Seq2Slate: Re-ranking and Slate Optimization with RNNs. In Proceedings of the Workshop on Negative Dependence in Machine Learning, Long Beach, CA, USA, 14–15 June 2019. [Google Scholar]
- Onal, K.D.; Zhang, Y.; Altingovde, I.S.; Rahman, M.M.; Karagoz, P.; Braylan, A.; Dang, B.; Chang, H.-L.; Kim, H.; McNamara, Q.; et al. Neural Information Retrieval: At the End of the Early Years. J. Inf. Retr. 2018, 21, 111–182. [Google Scholar] [CrossRef] [Green Version]
- Guo, J.; Fan, Y.; Pang, L.; Yang, L.; Ai, Q.; Zamani, H.; Wu, C.; Croft, W.B.; Cheng, X. A deep look into neural ranking models for information retrieval. Inf. Process. Manag. 2019, 57, 102067. [Google Scholar] [CrossRef] [Green Version]
- Yilmaz, Z.A.; Wang, S.; Yang, W.; Zhang, H.; Lin, J. Applying BERT to Document Retrieval with Birch. In Proceedings of the EMNLP 2019, Hong Kong, China, 3–7 November 2019; pp. 19–24. [Google Scholar]
- Nogueira, R.; Cho, K. Passage Re-ranking with BERT. arXiv 2019, arXiv:1901.04085v4. [Google Scholar]
- MacAvaney, S.; Yates, A.; Cohan, A.; Goharian, N. CEDR: Contextualized Embeddings for Document Ranking. In Proceedings of the 42nd SIGIR, Paris, France, 21–25 July 2019; pp. 1101–1104. [Google Scholar]
- Khattab, O.; Zaharia, M. ColBERT: Efficient and Effective Passage Search via Contextualized Late Interaction over BERT. In Proceedings of the SIGIR, Virtual Event, China, 25–30 July 2020; pp. 39–48. [Google Scholar]
- Lin, J.; Nogueira, R.; Yates, A. Pretrained Transformers for Text Ranking: BERT and Beyond. arXiv 2020, arXiv:2010.06467. [Google Scholar] [CrossRef]
- Plackett, R.L. The Analysis of Permutations. J. R. Stat. Society. Ser. C 1975, 24, 193–202. [Google Scholar] [CrossRef]
- Ustimenko, A.; Vorobev, A.; Gusev, G.; Serdyukov, P. Learning to select for a predefined ranking. In Proceedings of the ICML, Long Beach, CA, USA, 10–15 June 2019; Volume 97, pp. 6477–64868. [Google Scholar]
- Adams, R.P.; Zemel, R.S. Ranking via Sinkhorn Propagation. arXiv 2011, arXiv:1106.1925v2. [Google Scholar]
- Williams, R.J. Simple statistical gradient-following algorithms for connectionist reinforcement learning. Mach. Learn. 1992, 8, 229–256. [Google Scholar] [CrossRef] [Green Version]
- Bruch, S.; Han, S.; Bendersky, M.; Najork, M. A Stochastic Treatment of Learning to Rank Scoring Functions. In Proceedings of the 13th WSDM, Houston, TX, USA, 3–7 February 2020; pp. 61–69. [Google Scholar]
- Jang, E.; Gu, S.; Poole, B. Categorical Reparameterization with Gumbel-Softmax. In Proceedings of the International Conference on Learning Representations, Toulon, France, 24–26 April 2017. [Google Scholar]
- Maddison, C.J.; Mnih, A.; Teh, Y.W. The Concrete Distribution: A Continuous Relaxation of Discrete Random Variables. In Proceedings of the International Conference on Learning Representations, Toulon, France, 24–26 April 2017. [Google Scholar]
- Harrie, O. Computationally Efficient Optimization of Plackett–Luce Ranking Models for Relevance and Fairness. In Proceedings of the 44th International ACM SIGIR Conference on Research and Development in Information Retrieval, Virtual Event, Canada, 11–15 July 2021; pp. 1023–1032. [Google Scholar]
- Hunter, D.R. MM algorithms for generalized Bradley-Terry models. Ann. Stat. 2004, 32, 384–406. [Google Scholar] [CrossRef]
- Soufiani, H.A.; Chen, W.Z.; Parkes, D.C.; Xia, L. Generalized Method-of-Moments for Rank Aggregation. In Proceedings of the NeurIPS, Lake Tahoe, NV, USA, 5–10 December 2013; pp. 2706–2714. [Google Scholar]
- Soufiani, H.A.; Parkes, D.C.; Xia, L. Computing Parametric Ranking Models via Rank-Breaking. In Proceedings of the ICML, Beijing, China, 21–26 June 2014; Volume 32, pp. 360–368. [Google Scholar]
- Xu, P.; Gao, F.; Gu, Q. An Improved Convergence Analysis of Stochastic Variance-Reduced Policy Gradient. In Proceedings of the 35th UAI conference, Virtual Event, 3–6 August 2020. [Google Scholar]
- Xu, P.; Gao, F.; Gu, Q. Sample Efficient Policy Gradient Methods with Recursive Variance Reduction. In Proceedings of the ICLR, Virtual Event, 26 April–1 May 2020. [Google Scholar]
- Shen, Z.; Ribeiro, A.; Hassani, H.; Qian, H.; Mi, C. Hessian Aided Policy Gradient. In Proceedings of the ICML, Long Beach, CA, USA, 10–15 June 2019; pp. 5729–5738. [Google Scholar]
- Qin, T.; Liu, T.Y.; Xu, J.; Li, H. LETOR: A benchmark collection for research on learning to rank for information retrieval. Inf. Retr. J. 2010, 13, 346–374. [Google Scholar] [CrossRef]
- Chapelle, O.; Chang, Y. Yahoo! Learning to Rank Challenge Overview. In Proceedings of the 2010 International Conference on YLRC, Haifa, Israel, 25 June 2010; pp. 1–24. [Google Scholar]
- Bruch, S.; Zoghi, M.; Bendersky, M.; Najork, M. Revisiting Approximate Metric Optimization in the Age of Deep Neural Networks. In Proceedings of the 42nd SIGIR, Paris, France, 21–25 July 2019; pp. 1241–1244. [Google Scholar]
- Wang, X.; Li, C.; Golbandi, N.; Bendersky, M.; Najork, M. The LambdaLoss Framework for Ranking Metric Optimization. In Proceedings of the 27th CIKM, Torino, Italy, 22–26 October 2018; pp. 1313–1322. [Google Scholar]
- Ke, G.; Meng, Q.; Finley, T.; Wang, T.; Chen, W.; Ma, W.; Ye, Q.; Liu, T.Y. LightGBM: A Highly Efficient Gradient Boosting Decision Tree. In Proceedings of the NeurIPS, Long Beach, CA, USA, 4–7 December 2017. [Google Scholar]
- Rahimi, R.; Montazeralghaem, A.; Allan, J. Listwise Neural Ranking Models. In Proceedings of the ICTIR 2019, Santa Clara, CA, USA, 2–5 October 2019; pp. 101–104. [Google Scholar]
- Ai, Q.; Bi, K.; Guo, J.; Croft, W.B. Learning a Deep Listwise Context Model for Ranking Refinement. In Proceedings of the 41st SIGIR, Ann Arbor, MI, USA, 8–12 July 2018; pp. 135–144. [Google Scholar]
- Qin, Z.; Yan, L.; Zhuang, H.; Tay, Y.; Pasumarthi, R.K.; Wang, X.; Bendersky, M.; Najork, M. Are Neural Rankers still Outperformed by Gradient Boosted Decision Trees? In Proceedings of the ICLR, Virtual Event, 3–7 May 2021. [Google Scholar]
- Bradley, R.A.; Terry, M.E. Rank Analysis volume of Incomplete Block Designs: I. The Method of Paired Comparisons. Biometrika 1952, 39, 324–345. [Google Scholar]
- Xiu, Z.; Chen, J.; Henao, R.; Goldstein, B.; Carin, L.; Tao, C. Supercharging Imbalanced Data Learning With Energy-based Contrastive Representation Transfer. In Proceedings of the 35th Conference on Neural Information Processing Systems (NeurIPS 2021), Virtual Event, 7–10 December 2021. [Google Scholar]
- Salazar, A.; Vergara, L.; Safont, G. Generative Adversarial Networks and Markov Random Fields for oversampling very small training sets. Expert Syst. Appl. 2021, 163, 113819. [Google Scholar] [CrossRef]
- Fernández, A.; García, S.; Galar, M.; Prati, R.C.; Krawczyk, B.; Herrera, F. Learning from Imbalanced Data Sets; Springer International Publishing: Berlin/Heidelberg, Germany, 2018. [Google Scholar]



{kind=link}
{kind=link}
| MSLRWEB30K | Yahoo-Set1 | MQ2008 | ||||
|---|---|---|---|---|---|---|
| #Queries | 31,531 | 29,921 | 784 | |||
| #Docs | 3,771,125 | 709,877 | 15,211 | |||
| #Features | 136 | 700 | 46 | |||
| #Avg relevant docs per query | 58.0 | 17.5 | 3.7 | |||
| #Docs per query (Min; Avg; Max) | (1; 119.6; 1251) | (1; 23.7; 139) | (5; 19.4; 121) | |||
| #Ground-truth label distribution | 0 | 1,940,952 | 0 | 185,192 | 0 | 12,279 |
| 1 | 1,225,770 | 1 | 254,110 | 1 | 2001 | |
| 2 | 504,958 | 2 | 202,700 | 2 | 931 | |
| 3 | 69,010 | 3 | 54,473 | |||
| 4 | 30,435 | 4 | 13,402 | |||
| nDCG@1 | nDCG@3 | nDCG@5 | nDCG@10 | nDCG@20 | nDCG@50 | |
|---|---|---|---|---|---|---|
| LambdaMART(GBM) | 0.4949 | 0.4761 | 0.4799 | 0.4972 | 0.5180 | 0.5468 |
| RankNet (R5) | 0.4590 | 0.4488 | 0.4548 | 0.4731 | 0.4958 | 0.5296 |
| LambdaRank (GE4.L) | 0.4875 | 0.4676 | 0.4705 | 0.4859 | 0.5065 | 0.5375 |
| ListNet (R4.L) | 0.4665 | 0.4495 | 0.4534 | 0.4708 | 0.4942 | 0.5279 |
| ListMLE (GE5) | 0.4633 | 0.4498 | 0.4541 | 0.4719 | 0.4935 | 0.5272 |
| WassRank (GE5) | 0.4721 | 0.4497 | 0.4506 | 0.4639 | 0.4843 | 0.5180 |
| ExptUtility (GE4.L) | 0.2619 | 0.2746 | 0.2887 | 0.3200 | 0.3588 | 0.4191 |
| MDPRank (GE5) | 0.4521 | 0.4317 | 0.4346 | 0.4480 | 0.4671 | 0.4986 |
| IRGAN-List-5-G (GE4.L) | 0.1419 | 0.1559 | 0.1697 | 0.1989 | 0.2393 | 0.3183 |
| IRGAN-List-5-D (GE4.L) | 0.3853 | 0.3667 | 0.3709 | 0.3923 | 0.4230 | 0.4701 |
| IRGAN-Pair-5-G (GE4.L) | 0.2334 | 0.2457 | 0.2568 | 0.2790 | 0.3041 | 0.3583 |
| IRGAN-Pair-5-D (GE4.L) | 0.4183 | 0.4008 | 0.4029 | 0.4167 | 0.4377 | 0.4793 |
| IRGAN-Point-10-G (GE5) | 0.3357 | 0.3264 | 0.3305 | 0.3428 | 0.3615 | 0.3937 |
| IRGAN-Point-10-D (GE5) | 0.2807 | 0.2765 | 0.2822 | 0.3002 | 0.3250 | 0.3649 |
| nDCG@1 | nDCG@3 | nDCG@5 | nDCG@10 | nDCG@20 | nDCG@50 | |
|---|---|---|---|---|---|---|
| LambdaMART(GBM) | 0.7078 | 0.6985 | 0.7112 | 0.7520 | 0.5068 | 0.1017 |
| RankNet (GE4.L) | 0.6614 | 0.6497 | 0.6655 | 0.7131 | 0.4841 | 0.0984 |
| LambdaRank (GE4.L) | 0.6731 | 0.6643 | 0.6769 | 0.7223 | 0.4886 | 0.0985 |
| ListNet (GE4.L) | 0.6699 | 0.6597 | 0.6734 | 0.7193 | 0.4874 | 0.0982 |
| ListMLE (R5) | 0.6609 | 0.6516 | 0.6661 | 0.7156 | 0.4863 | 0.0983 |
| WassRank (GE4.L) | 0.6714 | 0.6593 | 0.6726 | 0.7188 | 0.4873 | 0.0988 |
| ExptUtility (GE5) | 0.5397 | 0.5532 | 0.5760 | 0.6394 | 0.4329 | 0.0891 |
| MDPRank (GE4.L) | 0.6547 | 0.6405 | 0.6543 | 0.7037 | 0.4768 | 0.0968 |
| IRGAN-List-5-G (R5) | 0.3268 | 0.3682 | 0.4054 | 0.4913 | 0.3440 | 0.0761 |
| IRGAN-List-5-D (R5) | 0.6559 | 0.6452 | 0.6613 | 0.7072 | 0.4769 | 0.0963 |
| IRGAN-Pair-10-G (R5) | 0.4821 | 0.5145 | 0.5457 | 0.6143 | 0.4207 | 0.0884 |
| IRGAN-Pair-10-D (R5) | 0.5637 | 0.5860 | 0.6120 | 0.6705 | 0.4585 | 0.0953 |
| IRGAN-Point-10-G (R5) | 0.5383 | 0.5678 | 0.5942 | 0.6567 | 0.4508 | 0.0942 |
| IRGAN-Point-10-D (R5) | 0.2912 | 0.3351 | 0.3767 | 0.4663 | 0.3279 | 0.0714 |
| nDCG@1 | nDCG@3 | nDCG@5 | nDCG@10 | nDCG@20 | nDCG@50 | |
|---|---|---|---|---|---|---|
| LambdaMART(GBM) | 0.4756 | 0.4884 | 0.5331 | 0.6086 | 0.3254 | 0.1422 |
| RankNet (L) | 0.4846 | 0.4964 | 0.5362 | 0.6157 | 0.3245 | 0.1410 |
| LambdaRank (L) | 0.4695 | 0.4854 | 0.5304 | 0.6182 | 0.3220 | 0.1427 |
| ListNet (L) | 0.4732 | 0.4926 | 0.5333 | 0.6101 | 0.3253 | 0.1412 |
| ListMLE (L) | 0.4675 | 0.4905 | 0.5316 | 0.6128 | 0.3228 | 0.1419 |
| WassRank (L) | 0.4772 | 0.4919 | 0.5374 | 0.6154 | 0.3212 | 0.1407 |
| ExptUtility (GE5) | 0.3765 | 0.4017 | 0.4442 | 0.5218 | 0.2763 | 0.1209 |
| MDPRank (GE5) | 0.4569 | 0.4695 | 0.5148 | 0.5946 | 0.3120 | 0.1385 |
| IRGAN-List-1-G( GE5) | 0.2352 | 0.2647 | 0.2891 | 0.3655 | 0.1888 | 0.0812 |
| IRGAN-List-1-D (GE5) | 0.4586 | 0.4889 | 0.5183 | 0.6038 | 0.3127 | 0.1358 |
| IRGAN-Pair-10-G (R5) | 0.3851 | 0.4069 | 0.4623 | 0.5493 | 0.2859 | 0.1279 |
| IRGAN-Pair-10-D (R5) | 0.4169 | 0.4549 | 0.4980 | 0.5803 | 0.3029 | 0.1377 |
| IRGAN-Point-5-G (GE5) | 0.4469 | 0.4815 | 0.5196 | 0.6053 | 0.3134 | 0.1384 |
| IRGAN-Point-5-D (GE5) | 0.4295 | 0.4474 | 0.4989 | 0.5756 | 0.3010 | 0.1325 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yu, H.-T.; Huang, D.; Ren, F.; Li, L. Diagnostic Evaluation of Policy-Gradient-Based Ranking. Electronics 2022, 11, 37. https://doi.org/10.3390/electronics11010037
Yu H-T, Huang D, Ren F, Li L. Diagnostic Evaluation of Policy-Gradient-Based Ranking. Electronics. 2022; 11(1):37. https://doi.org/10.3390/electronics11010037
Chicago/Turabian StyleYu, Hai-Tao, Degen Huang, Fuji Ren, and Lishuang Li. 2022. "Diagnostic Evaluation of Policy-Gradient-Based Ranking" Electronics 11, no. 1: 37. https://doi.org/10.3390/electronics11010037