
Hardware-Based Activation Function-Core for Neural Network Implementations

 , , , , , and
, , , , , and
Abstract
:1. Introduction
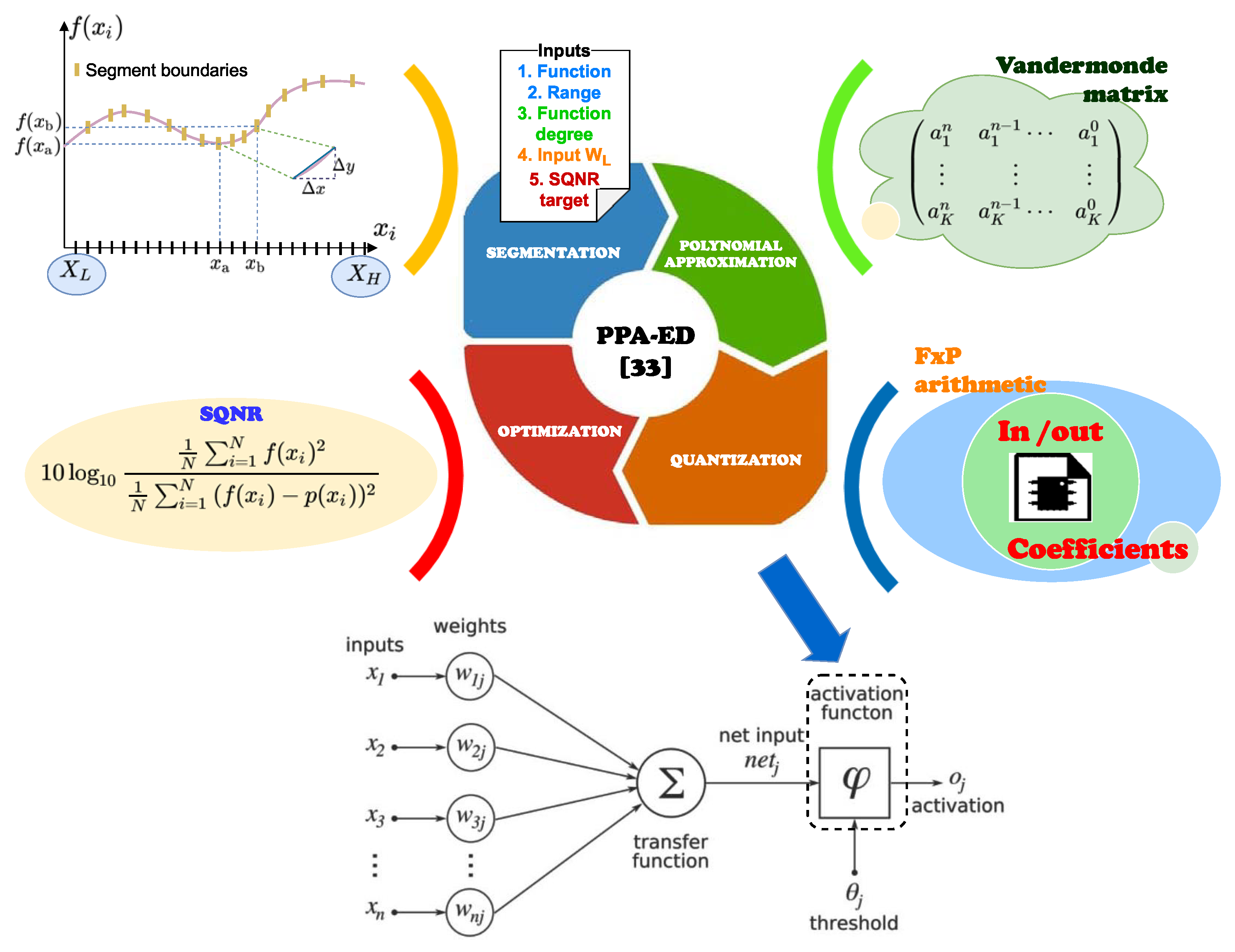
- A Sigmoid, hyperbolic tangent (Tanh), Gaussian, sigmoid linear unit (SILU), ELU, and Softplus AFs in reconfigurable hardware is designed with a piecewise polynomial approximation technique and a novel segmentation strategy.
- A wordlength-efficient hardware decoder for an activation function-core (AFC) with a reduction in power consumption in the order of 13x gains in comparison with state-of-the-art works.
- A design framework with the integration of an AFC to develop HNN applications.
2. PPA Implementation Methodologies
2.1. Minimax Approximation
2.2. Simple Canonical Piecewise Linear
2.3. Piecewise Linear Approximation Computation
2.4. PPA with Wordlength-Efficient Decoder
3. AFC Hardware Implementation
4. Experimental Results and Discussion
5. Hardware Neural Networks: Case Studies
5.1. Digit Classification
5.2. Breast Cancer Detection
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
Sample Availability
Abbreviations
| AAE | mean absolute error |
| AI | Artificial intelligent |
| ANN | Artificial neural network |
| AF | Activation function |
| AFC | Activation function-core |
| CNN | Convolutional neural network |
| dB | Decibels |
| ELU | Exponential linear unit |
| FPGA | Field programmable gate arrays |
| FxP | Fixed point |
| MAE | Maximum absolute error |
| MSE | mean squared error |
| PLAC | Piecewise linear approximation computation |
| PPA | Piecewise polynomial approximation |
| PPA-ED | PPA with wordlength-efficient decoder |
| SILU | Sigmoid linear unit |
| SCPWL | Simple canonical piecewise linear |
| SQNR | Signal to quantization noise ratio |
| Tanh | Hyperbolic tangent |
| HNN | Hardware neural network |
| HW | Hardware |
References
- Viswanath, K.; Gunasundari, R. VLSI Implementation and Analysis of Kidney Stone Detection from Ultrasound Image by Level Set Segmentation and MLP-BP ANN Classification; Advances in Intelligent Systems and Computing; Springer: New Delhi, India, 2016; Volume 394. [Google Scholar] [CrossRef]
- Sarić, R.; Jokić, D.; Beganović, N.; Gurbeta, P.; Badnjević, A. FPGA-based real-time epileptic seizure classification using Artificial Neural Network. Biomed. Signal Process. Control 2020, 62, 102106. [Google Scholar] [CrossRef]
- Tong, D.L.; Mintram, R. Genetic Algorithm-Neural Network (GANN): A study of neural network activation functions and depth of genetic algorithm search applied to feature selection. Int. J. Mach. Learn. Cybern. 2010, 1, 75–87. [Google Scholar] [CrossRef]
- Abdelouahab, K.; Pelcat, M.; Berry, F. Why TanH can be a Hardware Friendly Activation Function for CNNs. In Proceedings of the 11th International Conference on Distributed Smart Cameras, Stanford, CA, USA, 5–7 September 2017. [Google Scholar]
- Medus, L.; Iakymchuk, T.; Frances, V.; Bataller, M.; Rosado, M. A Novel Systolic Parallel Hardware Architecture for the FPGA Acceleration of Feedforward Neural Networks. IEEE Access 2019, 7, 76084–76103. [Google Scholar] [CrossRef]
- Zhang, L. Artificial neural network model-based design and fixed-point FPGA implementation of hénon map chaotic system for brain research. In Proceedings of the 2017 IEEE XXIV International Conference on Electronics, Electrical Engineering and Computing (INTERCON), Cusco, Peru, 15–18 August 2017. [Google Scholar]
- Narvekar, M.; Fargose, P.; Mukhopadhyay, D. Weather Forecasting Using ANN with Error Backpropagation Algorithm, Proceedings of the International Conference on Data Engineering and Communication Technology; Advances in Intelligent Systems and Computing; Springer: Singapore, 2017. [Google Scholar] [CrossRef]
- Libano, F.; Rech, P.; Tambara, L.; Tonfat, J.; Kastensmidt, F. On the Reliability of Linear Regression and Pattern Recognition Feedforward Artificial Neural Networks in FPGAs. IEEE Trans. Nucl. Sci. 2018, 65, 288–295. [Google Scholar] [CrossRef]
- Mahdi, S.Q.; Gharghan, S.K.; Hasan, M.A. FPGA-Based neural network for accurate distance estimation of elderly falls using WSN in an indoor environment. Measurement 2021, 167, 108276. [Google Scholar] [CrossRef]
- Louliej, A.; Jabrane, Y.; Zhu, W.P. Design and FPGA implementation of a new approximation for PAPR reduction. AEU-Int. J. Electron. Commun. 2018, 94, 253–261. [Google Scholar] [CrossRef]
- Hartmann, N.B.; Dos-Santos, R.C.; Grilo, A.P.; Vieira, J.C.M. Hardware Implementation and Real-Time Evaluation of an ANN-Based Algorithm for Anti-Islanding Protection of Distributed Generators. IEEE Trans. Ind. Electron. 2018, 65, 5051–5059. [Google Scholar] [CrossRef]
- Hultmann, A.; Muñoz, D.; Llanos, C.; Dos-Santos, C. Efficient hardware implementation of radial basis function neural network with customized-precision floating-point operations. Control. Eng. Pract. 2017, 60, 124–132. [Google Scholar] [CrossRef]
- Tng, S.S.; Le, N.Q.K.; Yeh, H.Y.; Chua, M.C.H. Improved Prediction Model of Protein Lysine Crotonylation Sites Using Bidirectional Recurrent Neural Networks. J. Proteome Res. 2021. [Google Scholar] [CrossRef]
- Le, N.Q.; Nguyen, B.P. Prediction of FMN Binding Sites in Electron Transport Chains based on 2-D CNN and PSSM Profiles. IEEE/ACM Trans. Comput. Biol. Bioinform. 2019. [Google Scholar] [CrossRef] [PubMed]
- Dong, H. PLAC: Piecewise Linear Approximation Computation for All Nonlinear Unary Functions. IEEE Trans. Very Large Scale Integr. (VLSI) Syst. 2020, 28, 2014–2027. [Google Scholar] [CrossRef]
- Parra, D.; Camargo, C. A Systematic Literature Review of Hardware Neural Networks. In Proceedings of the 2018 IEEE 1st Colombian Conference on Applications in Computational Intelligence (ColCACI), Medellin, Colombia, 16–18 May 2018. [Google Scholar] [CrossRef]
- Raut, G.; Rai, S.; Vishvakarma, S.K.; Kumar, A. A CORDIC Based Configurable Activation Function for ANN Applications. In Proceedings of the 2020 IEEE Computer Society Annual Symposium on VLSI, Limassol, Cyprus, 6–8 July 2020; pp. 78–83. [Google Scholar] [CrossRef]
- Yang, T. Design Space Exploration of Neural Network Activation Function Circuits. IEEE Trans. Comput.-Aided Des. Integr. Circuits Syst. 2019, 38, 1974–1978. [Google Scholar] [CrossRef] [Green Version]
- Xie, Y.; Joseph RA, N.; Hu, Z.; Huang, S.; Fan, Z.; Joler, M. A Twofold Lookup Table Architecture for Efficient. IEEE Trans. Very Large Scale Integr. (VLSI) Syst. 2020, 28, 2540–2550. [Google Scholar] [CrossRef]
- Cococcioni, M.; Rossi, F.; Ruffaldi, E.; Saponara, S. Fast Approximations of Activation Functions in Deep Neural Networks when using Posit Arithmetic. Sensors 2020, 20, 1515. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Bouguezzi, S.; Fredj, H.B.; Belabed, T.; Valderrama, C.; Faiedh, H.; Souani, C. An Efficient FPGA-Based Convolutional Neural Network for Classification: Ad-MobileNet. Electronics 2021, 10, 2272. [Google Scholar] [CrossRef]
- Papavasileiou, E.; Jansen, B. The importance of the activation function in NeuroEvolution with FS-NEAT and FD-NEAT. In Proceedings of the 2017 IEEE Symposium Series on Computational Intelligence (SSCI), Honolulu, HI, USA, 27 November–1 December 2017. [Google Scholar] [CrossRef]
- Qian, S.; Liu, H.; Liu Ch Wu, S.; Wong, H. Adaptive activation functions in convolutional neural networks. Neurocomputing 2018, 272, 204–212. [Google Scholar] [CrossRef]
- Mitra, S.; Chattopadhyay, P. Challenges in implementation of ANN in embedded system. In Proceedings of the 2016 International Conference on Electrical, Electronics, and Optimization Techniques (ICEEOT), Chennai, India, 3–5 March 2016; pp. 1794–1798. [Google Scholar]
- Kim, J.; Kim, J.; Kim, T.H. AERO: A 1.28 MOP/s/LUT Reconfigurable Inference Processor for Recurrent Neural Networks in a Resource-Limited FPGA. Electronics 2021, 10, 1249. [Google Scholar] [CrossRef]
- Dlugosz, Z.; Dlugosz, R. Nonlinear Activation Functions for Artificial Neural Networks Realized in Hardware. In Proceedings of the 25th International Conference “Mixed Design of Integrated Circuits and Systems”, Gdynia, Poland, 21–23 June 2018. [Google Scholar] [CrossRef]
- Armato, A.; Fanucci, L.; Scilingo, E.; De Rossi, D. Low-error digital hardware implementation of artificial neuron activation functions and their derivative. Microprocess. Microsyst. 2011, 35, 557–567. [Google Scholar] [CrossRef]
- Tsmots, I.; Skorokhoda, O.; Rabyk, V. Hardware Implementation of Sigmoid Activation Functions using FPGA. In Proceedings of the 2019 IEEE 15th International Conference on the Experience of Designing and Application of CAD Systems (CADSM), Polyana, Ukraine, 26 February–2 March 2019; pp. 34–38. [Google Scholar] [CrossRef]
- Larkin, D.; Kinane, A.; Muresan, V.; O’Connor, N. An Efficient Hardware Architecture for a Neural Network Activation Function Generator. Adv. Neural Netw. 2006, 3973, 1319–1327. [Google Scholar] [CrossRef] [Green Version]
- Zhang, L. Implementation of Fixed-point Neuron Models with Threshold, Ramp and Sigmoid Activation Functions. IOP Conf. Ser. Mater. Sci. Eng. 2017, 224, 012054. [Google Scholar] [CrossRef] [Green Version]
- Nguyen, V.; Luong, T.; Le Duc, H.; Hoang, V. An Efficient Hardware Implementation of Activation Using Stochastic Computing for Deep Neural Networks. In Proceedings of the 2018 IEEE 12th International Symposium on Embedded Multicore/Many-core Systems-on-Chip, Hanoi, Vietnam, 12–14 September 2018; pp. 233–236. [Google Scholar] [CrossRef]
- Hussein, M.H.; Al-Rikabi Mohannad, A.M.; Al-Ja’afari Ameer, H.A.; Saif, H.A. Generic model implementation of deep neural network activation functions using GWO-optimized SCPWL model on FPGA. Microprocess. Microsyst. 2020, 77, 103141. [Google Scholar] [CrossRef]
- Zhengbo, C.; Lei, T.; Zuoning, C. Research and design of activation function hardware implementation methods. J. Phys. Conf. Ser. 2020, 1684, 012111. [Google Scholar] [CrossRef]
- Guoxin, W.; Xiuli, L.; Zhanglei, J.; Ruxiang, H. Dongba classical ancient books image classification method based on ReN-Softplus convolution residual neural network. In Proceedings of the 14th IEEE International Conference on Electronic Measurement & Instruments (ICEMI), Changsha, China, 1–3 November 2019; pp. 398–404. [Google Scholar] [CrossRef]
- González, G.; Longoria, O.; Carrasco, R. An Optimization Methodology for Designing Hardware-Based Function Evaluation Modules with Reduced Complexity. Circuits Syst. Signal Process. 2021, in press. [Google Scholar] [CrossRef]
- Muller, J.-M. Elementary Functions: Algorithms and Implementation, 3rd ed.; Birkhäuser: Boston, MA, USA, 2016. [Google Scholar]
- Lancaster, P.; Tismenetsky, M. The Theory of Matrices: With Applications, 2nd ed.; Elsevier: San Diego, CA, USA, 1985. [Google Scholar] [CrossRef]
- Ahlawat, S.; Choudhary, A.; Nayyar, A.; Singh, S.; Yoon, B. Improved Handwritten Digit Recognition Using Convolutional Neural Networks (CNN). Sensors 2020, 20, 3344. [Google Scholar] [CrossRef]
- Alwzwazy, H.A.; Albehadili, H.M.; Alwan, Y.S.; Islam, N.E. Handwritten digit recognition using convolutional neural networks. Int. J. Innov. Res. Comput. Commun. Eng. 2016, 4, 1101–1106. [Google Scholar]
- Ali, S.; Shaukat, Z.; Azeem, M. An efficient and improved scheme for handwritten digit recognition based on convolutional neural network. SN Appl. Sci. 2019, 1, 1125. [Google Scholar] [CrossRef] [Green Version]
- Ting, F.F.; Tan, Y.J.; Sim, K.S. Convolutional neural network improvement for breast cancer classification. Expert Syst. Appl. 2019, 120, 103–115. [Google Scholar] [CrossRef]
- Alom, M.Z.; Yakopcic, C.; Nasrin, M.S. Breast Cancer Classification from Histopathological Images with Inception Recurrent Residual Convolutional Neural Network. J. Digit. Imaging 2019, 32, 605–617. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Toğaçar, M.; Özkurt, K.B.; Ergen, B.; Cömert, Z. BreastNet: A novel convolutional neural network model through histopathological images for the diagnosis of breast cancer. Phys. A Stat. Mech. Appl. 2020, 545, 123592. [Google Scholar] [CrossRef]
- Langelaar, J. MNIST Neural Network Training and Testing; MATLAB Central File Exchange; Available online: https://www.mathworks.com/matlabcentral/fileexchange/73010-mnist-neural-network-training-and-testing (accessed on 20 September 2021).
- Murphy, P.M.; Aha, D.W. UCI Repository of Machine Learning Databases. Available online: http://www.ics.uci.edu/~mlearn/MLRepository.html (accessed on 25 September 2021).








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| AF | Mathematical Description | Symmetry | Evaluation Range |
|---|---|---|---|
| 1. Sigmoid | |||
| 2. Tanh | |||
| 3. Gaussian | |||
| 4. SILU | - | ||
| 5. ELU | - | ||
| 6. Softplus | - |
| Activation Function | Input/Output FxP Format Q(,QFW,s) | Coefficients FxP Format Q(,QFC,s) |
|---|---|---|
| 1. Sigmoid | (16,10,s) | (16,15,s) |
| 2. Tanh | (16,10,s) | (16,14,s) |
| 3. Gaussian | (16,10,s) | (16,14,s) |
| 4. SILU | (16,11,s) | (16,13,s) |
| 5. ELU | (16,12,s) | (16,15,s) |
| 6. Softplus | (16,12,s) | (16,15,s) |
| Segment Number | Segment Boundaries | Format | |||
|---|---|---|---|---|---|
| 1 | [0 1.5) | ★ | 0.2685 | 0.4981 | |
| ☐ | 0xfb55 | 0x225f | 0x3fc2 | ||
| 2 | [1.5 3.5) | ★ | 0.2243 | 0.551 | |
| ☐ | 0xfc29 | 0x1cb4 | 0x4687 | ||
| 3 | [3.5 4.5) | ★ | 0.0873 | 0.7712 | |
| ☐ | 0xfee4 | 0x0b2b | 0x62b8 | ||
| 4 | [4.5 8.0) | ★ | 0.0174 | 0.9356 | |
| ☐ | 0xffd9 | 0x023b | 0x77c0 |
| Segment Number | Segment Boundaries | Format | |||
|---|---|---|---|---|---|
| 1 | [0 1) | ★ | 1.0968 | ||
| ☐ | 0xeb14 | 0x4631 | 0xffa5 | ||
| 2 | [1 2) | ★ | 0.7027 | 0.2318 | |
| ☐ | 0xf52d | 0x2cf8 | 0x0ed5 | ||
| 3 | [2 3.5) | ★ | 0.1242 | 0.7933 | |
| ☐ | 0xfeca | 0x07f2 | 0x32c4 | ||
| 4 | [3.5 8) | ★ | 0.0019 | 0.9939 | |
| ☐ | 0xfffd | 0x001f | 0x3f9b |
| Segment Number | Segment Boundaries | Format | |||
|---|---|---|---|---|---|
| 1 | [0 0.50) | ★ | 1.0001 | ||
| ☐ | 0xc378 | 0xff96 | 0x4001 | ||
| 2 | [0.50 1.00) | ★ | 1.0377 | ||
| ☐ | 0xdfa9 | 0xef23 | 0x426a | ||
| 3 | [1.00 1.25) | ★ | 0.1554 | 1.2914 | |
| ☐ | 0x09f2 | 0xbae8 | 0x52a5 | ||
| 4 | [1.25 1.75) | ★ | 0.4353 | 1.5452 | |
| ☐ | 0x1bdc | 0x98ca | 0x62e5 | ||
| 5 | [1.75 2.50) | ★ | 0.3366 | 1.3409 | |
| ☐ | 0x158a | 0xaafc | 0x55d1 | ||
| 6 | [2.50 3.75) | ★ | 0.1318 | 0.7035 | |
| ☐ | 0x0870 | 0xd932 | 0x2d05 | ||
| 7 | [3.75 5.25) | ★ | 0.0157 | 0.1281 | |
| ☐ | 0x0100 | 0xfa45 | 0x0833 | ||
| 8 | [5.25 8.00) | ★ | 0 | 0.0002 | |
| ☐ | 0x0000 | 0xffff | 0x0002 |
| Segment Number | Segment Boundaries | Format | |||
|---|---|---|---|---|---|
| 1 | [−8 −4.5) | ★ | −0.0045 | −0.0686 | −0.2641 |
| ☐ | 0xffda | 0xfdcd | 0xf78c | ||
| 2 | [−4.5 −2) | ★ | −0.0149 | −0.174 | −0.53002 |
| ☐ | 0xff86 | 0xfa6e | 0xef09 | ||
| 3 | [−2 −1) | ★ | 0.0798 | 0.2053 | −0.1453 |
| ☐ | 0x028d | 0x0691 | 0xfb5a | ||
| 4 | [−1 0.5) | ★ | 0.2329 | 0.4997 | 0.0015 |
| ☐ | 0x0773 | 0x0ffd | 0x000c | ||
| 5 | [0.5 2) | ★ | 0.115 | 0.6885 | −0.0689 |
| ☐ | 0x03ae | 0x1608 | 0xfdcb | ||
| 6 | [2 3.5) | ★ | −0.0095 | 1.1447 | −0.4912 |
| ☐ | 0xffb1 | 0x24a1 | 0xf047 | ||
| 7 | [3.5 6) | ★ | −0.0115 | 1.1431 | −0.4611 |
| ☐ | 0xffa1 | 0x2494 | 0xf13e | ||
| 8 | [6 8] | ★ | −0.0024 | 1.039 | −0.1635 |
| ☐ | 0xffec | 0x213f | 0xfac4 |
| Segment Number | Segment Boundaries | Format | |||
|---|---|---|---|---|---|
| 1 | [−4 −2.5) | ★ | 0.004 | 0.0345 | −0.1227 |
| ☐ | 0x0084 | 0x046c | 0xf04a | ||
| 2 | [−2.5 −1.5) | ★ | 0.0138 | 0.0831 | −0.0621 |
| ☐ | 0x01c4 | 0x0aa1 | 0xf80e | ||
| 3 | [−1.5 −0.5) | ★ | 0.0375 | 0.1507 | −0.0133 |
| ☐ | 0x04cd | 0x134a | 0xfe4d | ||
| 4 | [−0.5 0) | ★ | 0.0783 | 0.1961 | −0.0001 |
| ☐ | 0x0a05 | 0x191a | 0xfffc |
| Segment Number | Segment Boundaries | Format | |||
|---|---|---|---|---|---|
| 1 | [−4 −2) | ★ | 0.0238 | 0.1948 | 0.4184 |
| ☐ | 0x030c | 0x18ef | 0x358e | ||
| 2 | [−2 0 ) | ★ | 0.0969 | 0.472 | 0.68844 |
| ☐ | 0x0c67 | 0x3c68 | 0x581e | ||
| 3 | [0 2) | ★ | 0.0969 | 0.528 | 0.68844 |
| ☐ | 0x0c67 | 0x4397 | 0x581e | ||
| 4 | [2 4] | ★ | 0.0238 | 0.8052 | 0.4184 |
| ☐ | 0x030c | 0x6710 | 0x358e |
| ∈ Q(14,10,s), ∈ Q(12,10,s) | ||||||
|---|---|---|---|---|---|---|
| Function | Proposal | Segments | SQNR [dB] | Range | MAE | AAE |
| Sigmoid | Larkin * [29] | 4 | NA | |||
| 6 | NA | |||||
| PPA-ED ** | 4 | 59.49 | ||||
| Tanh | Larkin * [29] | 4 | NA | |||
| PPA-ED ** | 4 | 53.40 | ||||
| 3 | 50.60 | |||||
| , ∈ Q(16,10,s) | ||||||
|---|---|---|---|---|---|---|
| Function | Proposal | Segments | SQNR [dB] | Range | MAE | MSE |
| Sigmoid | Hussein * [32] | 9 | NA | |||
| PPA-ED ** | 4 | 56.76 | ||||
| Tanh | Hussein * [32] | 9 | NA | |||
| PPA-ED ** | 4 | 53.55 | ||||
| Gaussian | Hussein * [32] | 9 | NA | |||
| PPA-ED ** | 8 | 49.48 | ||||
| PPA-ED | 6 | 41.96 | ||||
| , ∈ Q(8,8,ns) | |||||
|---|---|---|---|---|---|
| Function | Proposal * | Segments | Range | SQNR [dB] | MAE |
| Sigmoid | Dong [15] | 2 | [0,1) | NA | |
| PPA-ED | 2 | 48.22 | |||
| Tanh | Dong [15] | 4 | [0,1) | NA | |
| PPA-ED | 4 | 46.03 | |||
| Function | Range | SQNR | MAE | AAE | Power Consumption [mW] |
|---|---|---|---|---|---|
| Sigmoid | 56.76 | 0.82 | |||
| Tanh | 53.55 | 0.88 | |||
| Gaussian | 53.55 | 0.88 | |||
| ELU | 78.73 | 0.53 | |||
| SILU | 60.14 | 0.96 | |||
| Softplus | 59.50 | 0.66 |
| Proposal | Segments | MAE | AAE | Frequency [MHz] | Average Power [mW] |
|---|---|---|---|---|---|
| Larkin [29] | 8 | 40 | 17 | ||
| PPA-ED-based | 5 | 40 | 1.02 | ||
| AFC | 50 | 1.27 |
| HW Resources | Consumption by Function | Available | Utilization | ||||||
|---|---|---|---|---|---|---|---|---|---|
| Sigmoid | Tanh | Gaussian | ELU | SILU | Softplus | % | |||
| Slice register | 1 | 1 | 0 | 16 | 0 | 0 | Out of | 126,800 | 0% |
| Slice LUTs | 76 | 78 | 93 | 28 | 54 | 22 | Out of | 63,400 | 0% |
| IOBs | 33 | Out of | 210 | 15% | |||||
| BUFG/ | |||||||||
| BUFGCTRLs | 1 | Out of | 32 | 3% | |||||
| DSP48E1s | 2 | Out of | 240 | 0% | |||||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
González-Díaz_Conti, G.; Vázquez-Castillo, J.; Longoria-Gandara, O.; Castillo-Atoche, A.; Carrasco-Alvarez, R.; Espinoza-Ruiz, A.; Ruiz-Ibarra, E. Hardware-Based Activation Function-Core for Neural Network Implementations. Electronics 2022, 11, 14. https://doi.org/10.3390/electronics11010014
González-Díaz_Conti G, Vázquez-Castillo J, Longoria-Gandara O, Castillo-Atoche A, Carrasco-Alvarez R, Espinoza-Ruiz A, Ruiz-Ibarra E. Hardware-Based Activation Function-Core for Neural Network Implementations. Electronics. 2022; 11(1):14. https://doi.org/10.3390/electronics11010014
Chicago/Turabian StyleGonzález-Díaz_Conti, Griselda, Javier Vázquez-Castillo, Omar Longoria-Gandara, Alejandro Castillo-Atoche, Roberto Carrasco-Alvarez, Adolfo Espinoza-Ruiz, and Erica Ruiz-Ibarra. 2022. "Hardware-Based Activation Function-Core for Neural Network Implementations" Electronics 11, no. 1: 14. https://doi.org/10.3390/electronics11010014