1. Introduction
At the beginning of 2020, the pulmonary infection pandemic caused by the new coronavirus disease (COVID-19) broke out and spread rapidly around the world. This disease poses a huge threat to human health and life safety, making humanity face an unprecedented and devastating global health crisis [
1,
2,
3,
4,
5]. COVID-19 is mainly manifested in the lungs, causing respiratory infections. It can also lead to intestinal infections, causing digestive symptoms including nausea, vomiting, and diarrhea [
6]. As of 6 August 2021, according to world health organization (WHO) statistics, the cumulative number of confirmed cases of new coronary pneumonia in the world has exceeded 200 million, reaching 200,174,883, which means there has been about one COVID-19 patient per 39 people in the world, and the number of deaths has exceed 4.25 million. COVID-19 is highly contagious, and early screening of COVID-19 patients can help stop the spread of the disease. Therefore, the rapid and accurate diagnosis of COVID-19 is very important for the prevention and control of the pandemic. Polymerase chain reaction (PCR) testing is considered to be the gold standard for COVID-19 testing. It can only qualitatively detect COVID-19 using nasal swabs, sputum, and nasopharyngeal aspirates. In addition, PCR testing requires a large number of doctors to perform it manually. At the same time, the progression of COVID-19 can be quantitatively analyzed based on computed tomography (CT). CT images can be used to detect the relevant pathological features of COVID-19 [
7]. A lot of clinical experience shows that CT imaging plays an irreplaceable role in the evaluation [
8] and diagnosis [
9] of COVID-19 lung diseases. In comparison to chest X-rays, chest CT scans have the advantage of not being affected by other chest tissues and have good recognition ability of lung diseases. Therefore, chest CT scans are recommended by radiologists as the main lung clinical diagnostic tool. Some studies [
10,
11] found that typical chest CT slices of COVID-19 showed radioactive features such as ground-glass opacity (GGO) in the early stage and pulmonary consolidation in the advanced stage. Medical image segmentation plays a key role in the analysis of pathological characteristics of medical images. It can help clinicians perform image-guided medical interventions and radiotherapy. Given that doctors’ manual segmentation of lesions is time-consuming and is greatly affected by their own subjective experience, it is of great significance to study and find an automatic and effective medical image segmentation algorithm to assist clinicians to make accurate and rapid diagnosis and treatment plans [
12].
In recent years, with the rapid development of deep learning, semantic segmentation algorithms based on deep learning have made remarkable achievements in medical image segmentation tasks. In particular, the automatic segmentation of the COVID-19 lung infection area based on deep learning is very important for further diagnosis of the disease because it can assist radiologists in quantitative evaluation of the disease quickly [
8]. Some researchers used deep learning [
13,
14,
15,
16,
17,
18,
19] to screen for COVID-19. Wang et al. [
13] used a segmentation method based on deep learning to extract the lesion features of COVID-19. Some frameworks widely used in medical image segmentation were also utilized for COVID-19 segmentation, such as U-Net, V-Net, and U-Net++ [
14,
15,
16]. Wang et al. [
17] designed a segmentation framework to learn distinguishing features from noisy labels, which alleviated the impact of COVID-19 image label quality on segmentation performance and captured the scale and morphological information of COVID-19 lung CT images. Wu et al. [
18] proposed a two-stage COVID-19 segmentation strategy: U-Net was first used to roughly locate the lesion area and then to finely segment the lesion area on the basis of the rough positioning information. Fan et al. [
19] introduced a semi-supervised COVID-19 segmentation method, which can effectively alleviate the impact of the lack of labeled data.
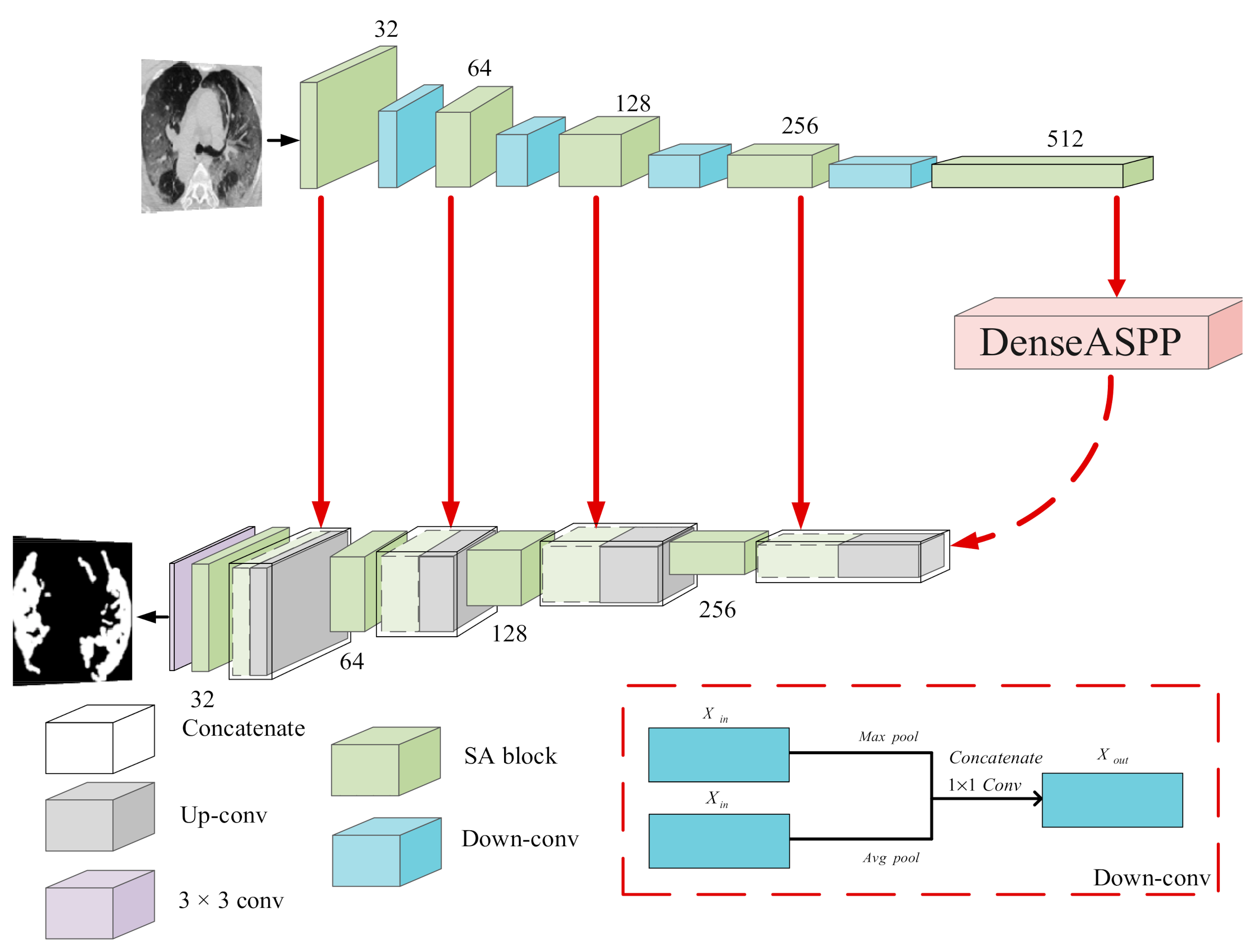
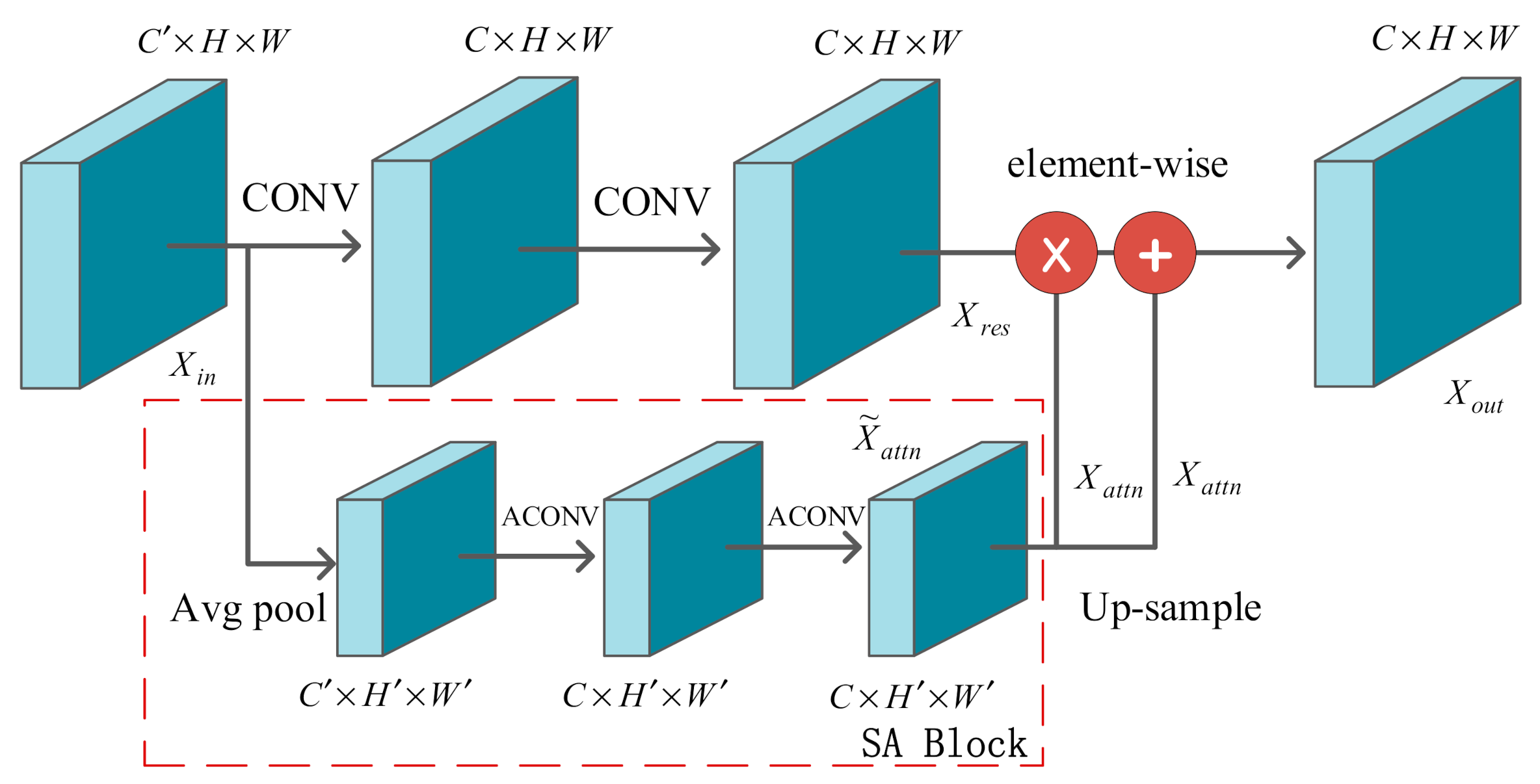
As a particularly effective and robust segmentation model, U-Net is widely used in the field of medical image segmentation, but in this model, each channel of the output feature is given the same weight. It lacks the ability to deal with different types of features and does not take into account the difference of the contribution of each convolution channel to the feature extraction of the network. Compared with the fully-connected layer, convolution adopts a local connection mode, and the weight sharing operation greatly reduces the calculation parameters. Convolution kernel has the characteristic of local perception and is good at capturing the information around pixels. This characteristic makes it difficult to learn the correlation between pixels far away in the image. Because of the local receptive field feature of the convolution kernel, it does not make full use of the global context information of the image. In fact, a lot of previous works focused on the improvement of pixel level segmentation performance, basically ignoring the importance of pixel-grouping in semantic segmentation [
20]. In our SD-UNet, a squeeze-and-attention (SA) module was introduced to overcome these challenges by using a not fully-squeezed attention channel mechanism to generate non-local spatial attention to the image and make full use of the global context information to selectively re-weight the channel features. It can also be considered a kind of spatial attention to pixel grouping. Each pixel on the input feature map was scanned by generating attention convolution, and pixels with different spatial positions but belonging to the same class were divided into a group.
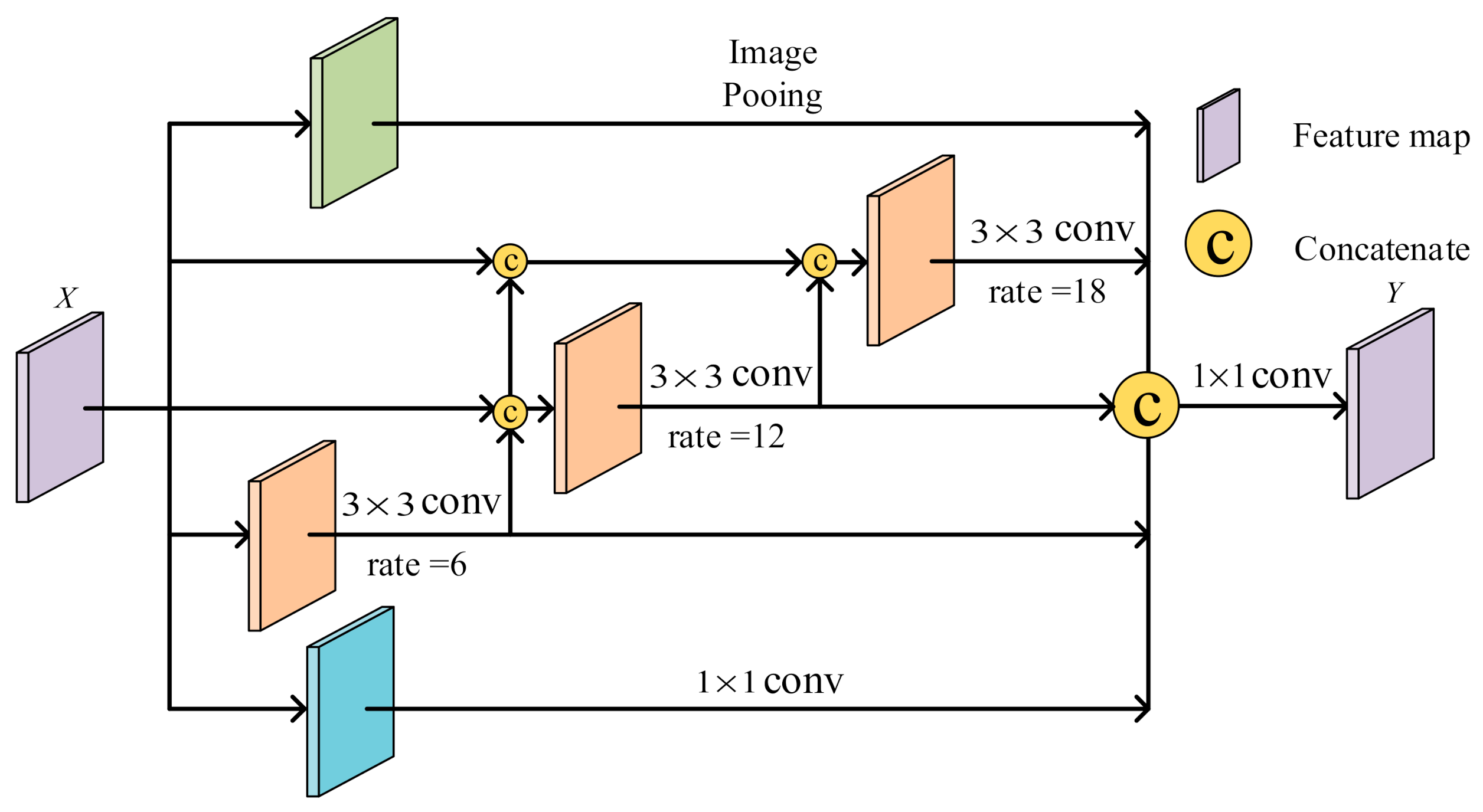
Apart from the above-mentioned lack of global context information, the ability of a convolutional neural network (CNN) to perceive information is largely dependent on the size of its convolution kernel, making it difficult to capture long-distance and multi-scale lesion information. It is worth emphasizing that the detection of COVID-19 usually uses advanced computed tomography technology, which generates high-resolution CT images, but labeling lesions still requires experienced doctors. Due to the lack of medical personnel and efficient medical instruments, the diagnosis of COVID-19 is usually subjective and time-consuming. At the same time, for COVID-19 CT images, computer-aided diagnosis will face great challenges and limitations due to the diversity of object locations and shapes of lesions as well as the blurred boundaries between infected and non-infected areas. In view of this situation, the dense atrous spatial pyramid pooling (Dense ASPP) module was embedded into our COVID-19 lung lesion segmentation network SD-UNet to help explore multi-scale contextual features [
21], locate lesion boundaries, and refine semantic labels, which facilitates the capture of the size and location information of different lesion targets.
Our contributions are listed in the following three aspects:
We propose a novel framework SD-UNet for segmentation of COVID-19 lesions, which combines the advantages of SA and Dense ASPP modules. The SA module is introduced to strengthen the attention of pixel grouping and fully exploit the global context information, making the network better mine the differences and connections between pixels. Therefore, we added a new path from the output of convolution to learn the weight information and explicitly model the dependency between channels by re-weighting local and global features. This mechanism can better adapt to the task of semantic segmentation. The Dense ASPP module is utilized at the bottleneck of the encoder and decoder of SD-UNet to better capture long-distance and multi-scale lesion information and to avoid the loss of semantic information caused by the down-sampling operation in the encoding process. In summary, the global context and multi-scale information of COVID-19 lesions can be better mined by the fusion of these two modules, so that a more accurate segmentation effect can be achieved.
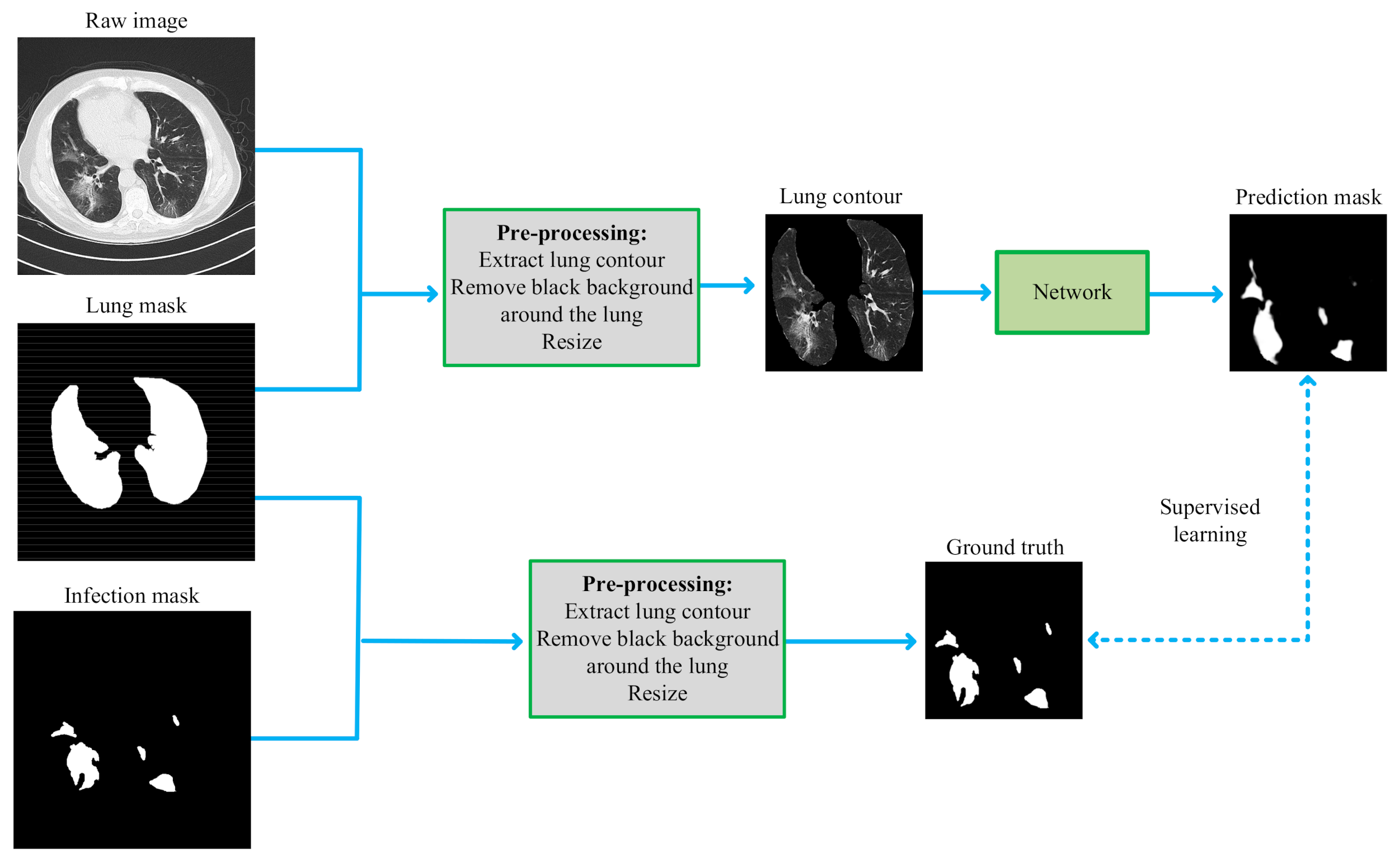
To eliminate the interference of background noise outside the lungs and highlight the texture features of the lung lesion area, we extracted the lung area from the CT images in the pre-processing stage. Specifically, the raw image and infection mask were pre-processed through extraction of the lung contour and removal of the black background around the lung followed by resizing.
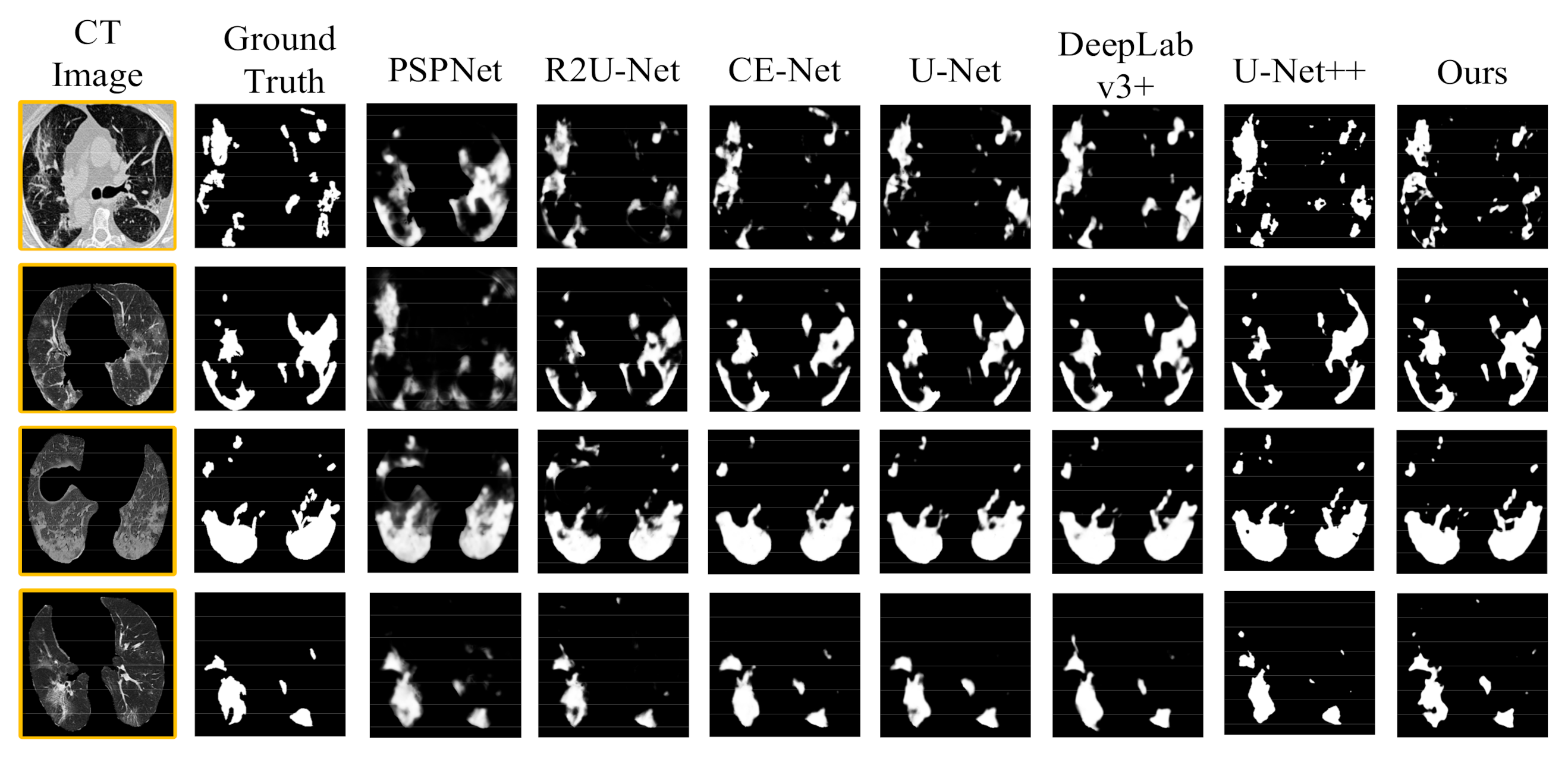
We compared the framework with several existing segmentation methods. The experimental results based on the binary-class and multi-class lesion segmentation datasets demonstrated that SD-UNet is more robust and effective for the COVID-19 lung infection segmentation task. Further, an ablation study was implemented to verify the efficiency of the Dense ASPP and SA components, and 5-fold cross-validation was used to objectively and accurately evaluate the performance of our segmentation model.
The rest of this paper is organized as follows: In
Section 2, several research works related to the segmentation of COVID-19 pulmonary infection are discussed. In
Section 3, the architecture and key components of the proposed network are illustrated in detail. In
Section 4, some of the details of the experiment are described. The performance evaluation results of our segmentation network are presented in
Section 5, and the conclusion is drawn in
Section 6.
2. Related Work
In this section, we present several works that are relevant to our research in several aspects, including medical image semantic segmentation, attention mechanism, and multi-scale contextual information.
Based on the data-driven deep learning method, the high-level abstract thinking ability similar to the human brain is approximately simulated by building an end-to-end deep feature extraction network. One of the advanced and effective models is a convolutional neural network (CNN) [
22]. Long et al. [
23] designed an end-to-end, pixel-to-pixel fully convolutional neural network (FCN), which was more efficient than traditional CNN-based segmentation networks, but the segmentation result was unsatisfactory because it ignored the global context information of the image and was not sensitive enough to the details of the image. Ronneberger et al. [
24] proposed a U-shaped symmetric network (U-Net) that was good at segmentation of cell images and liver CT images by using a jump connection method that greatly improved the segmentation accuracy and the robustness. Zhou et al. [
25] designed a U-Net++ segmentation network. By modifying the jump connections in U-Net to nested dense jump connections, this can facilitate the integration of different levels of image features. Zhao et al. [
26] designed a novel dilated dual attention network based on U-Net (D2A U-Net) for COVID-19 infection area segmentation in CT images. Xie et al. [
27] constructed a double U-shaped dilated attention network (DUDA-Net), which effectively improved the segmentation ability of subtle lesions of COVID-19.
In recent years, the attention mechanism has been widely used in various fields of deep learning. We can easily find the attention mechanism in various tasks such as natural language processing, speech recognition or image processing, and it can be used to emphasize important feature information and suppress irrelevant information [
28]. The attention mechanism can also enhance the interpretability of the network. Hu et al. [
29] proposed a lightweight channel attention module, “Squeeze-and-Excitation” (SE), which can adaptively learn the interdependence between channels to readjust the characteristic response of the network. Woo et al. [
30] designed an attention module convolutional block attention module (CBAM), which combined channel attention and spatial attention mechanisms, so that the network can simultaneously pay attention to the details of the image from both the channel and space. Fan et al. [
18] proposed an edge attention mechanism for the segmentation of COVID-19 lung CT images, which provided useful constraints on the edge information of the generated feature maps and explicitly improved the feature representation of the boundary area of the object. Han et al. [
31] exploited a self-attention mechanism in generative adversarial networks (GANs) for unsupervised anomaly detection in MRI, helping the network to model the global and long-range dependencies for MRI slices. Schlemper et al. [
32] designed an attention gate (AG) model, which can make the model pay more attention to learn features related to the segmentation target. Yeung et al. [
33] proposed a dual attention (spatial and channel attention) gated CNN for polyp segmentation during colonoscopies, which encouraged the network to selectively mine polyp features and suppress background features, thus effectively deal with the image segmentation task of category imbalance.
Some previous studies [
34,
35,
36,
37,
38] showed that multi-scale context information was beneficial for semantic segmentation of image pixels. Farabet et al. [
34] used the Laplacian pyramid to transform the image at multiple scales, inputting each scale into the network and merging the feature maps of different scales. Lin et al. [
35] simply adjusted the input image at several different scales and then aggregated the output feature maps of all these scales. The disadvantage of this method was its very high number of parameters from extracting multi-scale features [
34,
35]. Considering the performance of GPU, it is not suitable for larger and deeper networks. Chen et al. [
36] introduced atrous spatial pyramid pooling (ASPP), which captured the multi-scale context with parallel dilated convolution at multiple dilated rates for a given input, greatly increasing the receptive field at the cost of increasing the number of parameters. This captured the long-distance and multi-scale information of the image as well. Huang et al. [
37] designed a jump connection structure that can extract full-scale information from each convolutional layer of the encoder and decoder and can capture the context information of the image from multiple scale ranges for more precise segmentation. To solve the problem of multiple lesion shapes and positions of COVID-19 pneumonia, Pei et al. [
38] designed a network with multi-scale feature extraction capabilities, which used multiple sizes of receptive fields to obtain multiple-scale lesion features so as to strengthen the ability of segmenting COVID-19-infected regions with different sizes.
6. Conclusions
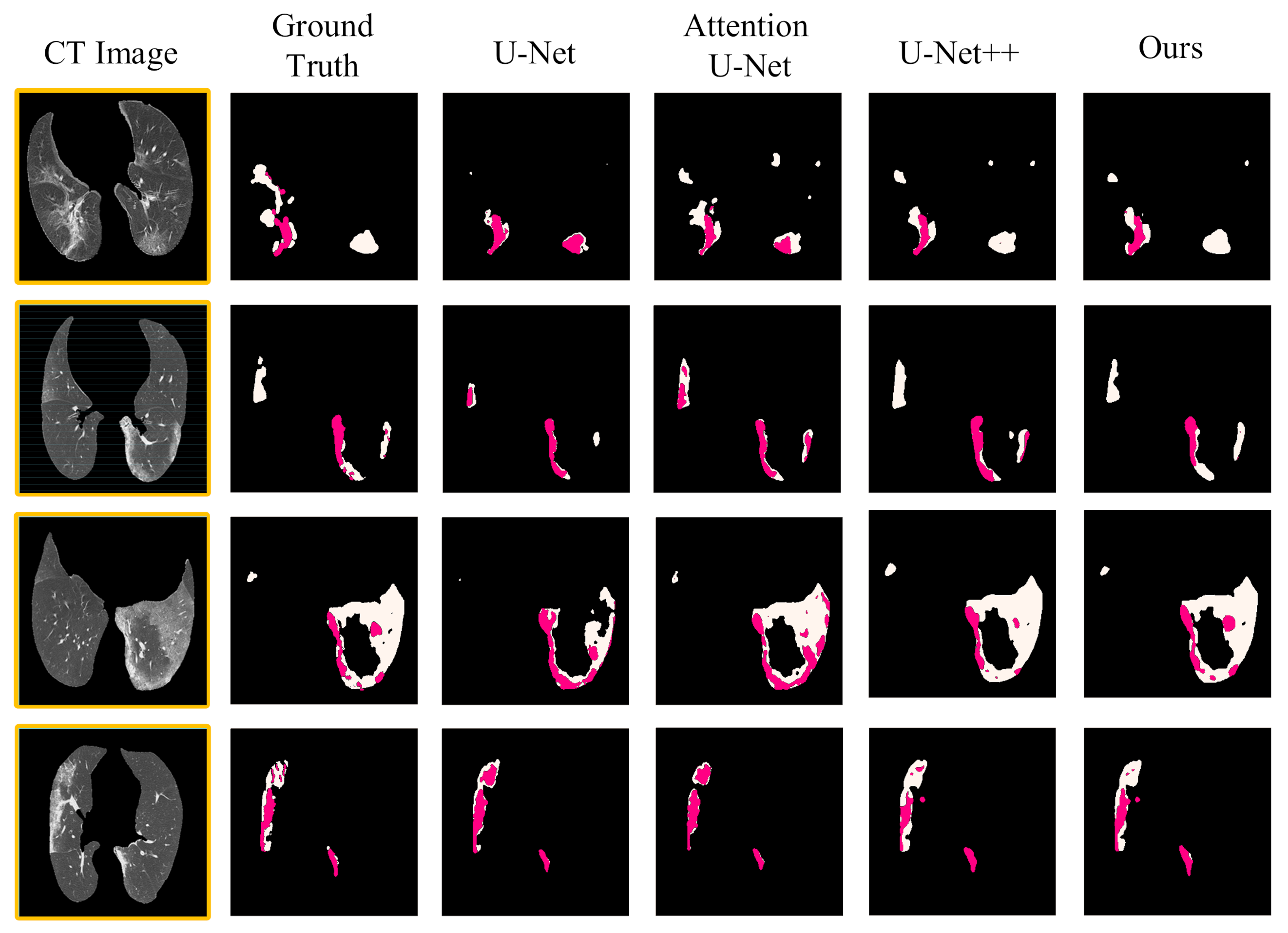
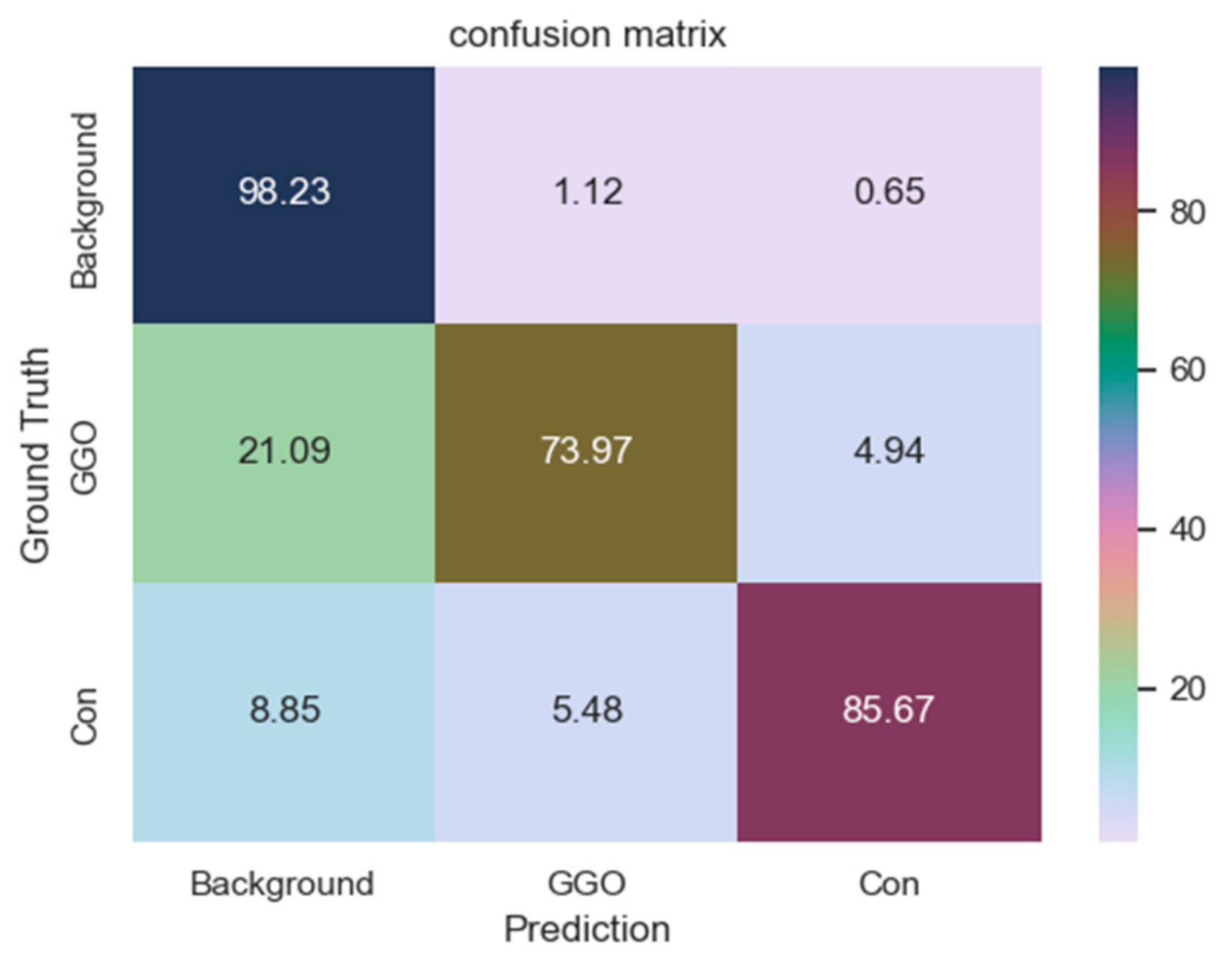
In this paper, we propose a novel framework dedicated to COVID-19 segmentation: SD-UNet. It integrates the Dense ASPP and SA modules into our segmentation framework to better mine the multi-scale context and global context information in COVID-19 lung CT infection slices. Pre-processing operations are also performed on COVID-19 samples to eliminate irrelevant background information and enhance information related to COIVD-19 lesion segmentation. During training, to accelerate the convergence of the network and alleviate the problem of gradient disappearance in the process of back propagation and the impact of category imbalance of mall datasets, we also deployed a combo loss function for segmentation supervision. The experimental results show that compared with the baseline U-Net and other cutting-edge segmentation methods, SD-UNet can achieve a more accurate segmentation effect for COVID-19. In addition, not only can we segment COVID-19 lung infections globally in our segmentation framework, we can also segment different types of infections (GGO and Consolidation) in detail. Moreover, the good segmentation performance also proves that our method has great practical significance for the development of computer-aided diagnosis technology for COVID-19. It is expected to assist doctors in making diagnosis and treatment plans more accurately and quickly and to improve the segmentation effect. However, there are some deficiencies in the experiment, e.g., the predicted COVID-19 lesion contours are not elaborate enough. The main reason is the relatively limited COVID-19 lesion segmentation data labeled by the experts, resulting in the insufficient training sample sizes of the model. In the future, we will further expand our research in the following aspects: increase the amount of data, use more image enhancement technology, explore various loss functions suitable for medical image segmentation, continue to optimize our segmentation framework, and apply our segmentation framework to other segmentation tasks such as blood vessel segmentation, liver segmentation, and pancreas segmentation.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}