
Planar-Equirectangular Image Stitching

Abstract
:1. Introduction
- C1.
- TI-based planar-equirectangular stitching pipeline.
- C2.
- HPI-EI ROI detection algorithm.
- C3.
- kNN-based GMS feature matching algorithm.
- C4.
- HVS-based image alignment algorithm.
2. Related Works
2.1. Planar-Planar Image Stitching
2.2. Non-Planar Image Stitching
2.3. Icosahedron to Reduce Equirectangular Image (EI) Distortion
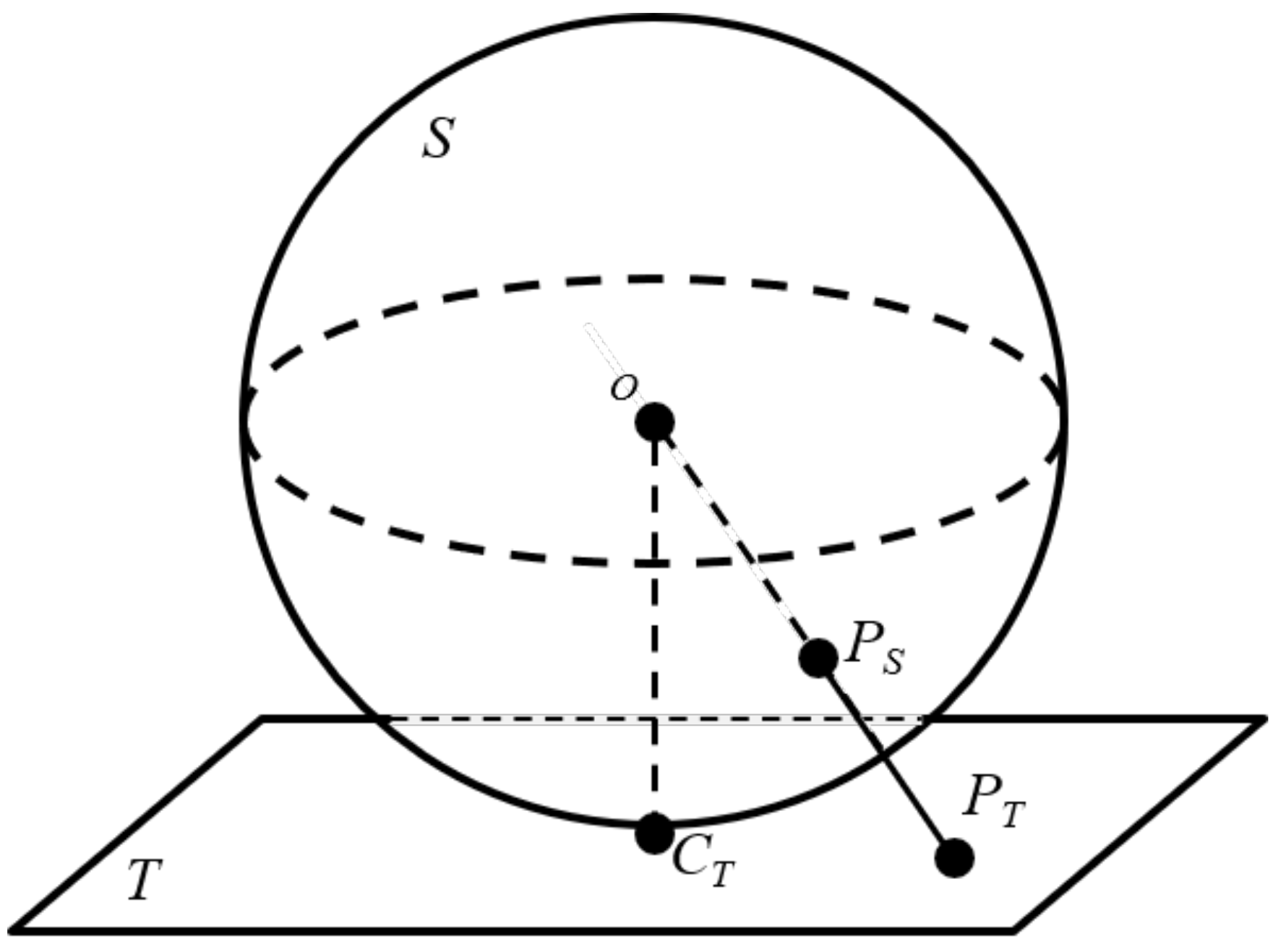
3. Tangent Images (TIs)
3.1. Tangent Images (TIs) Creation
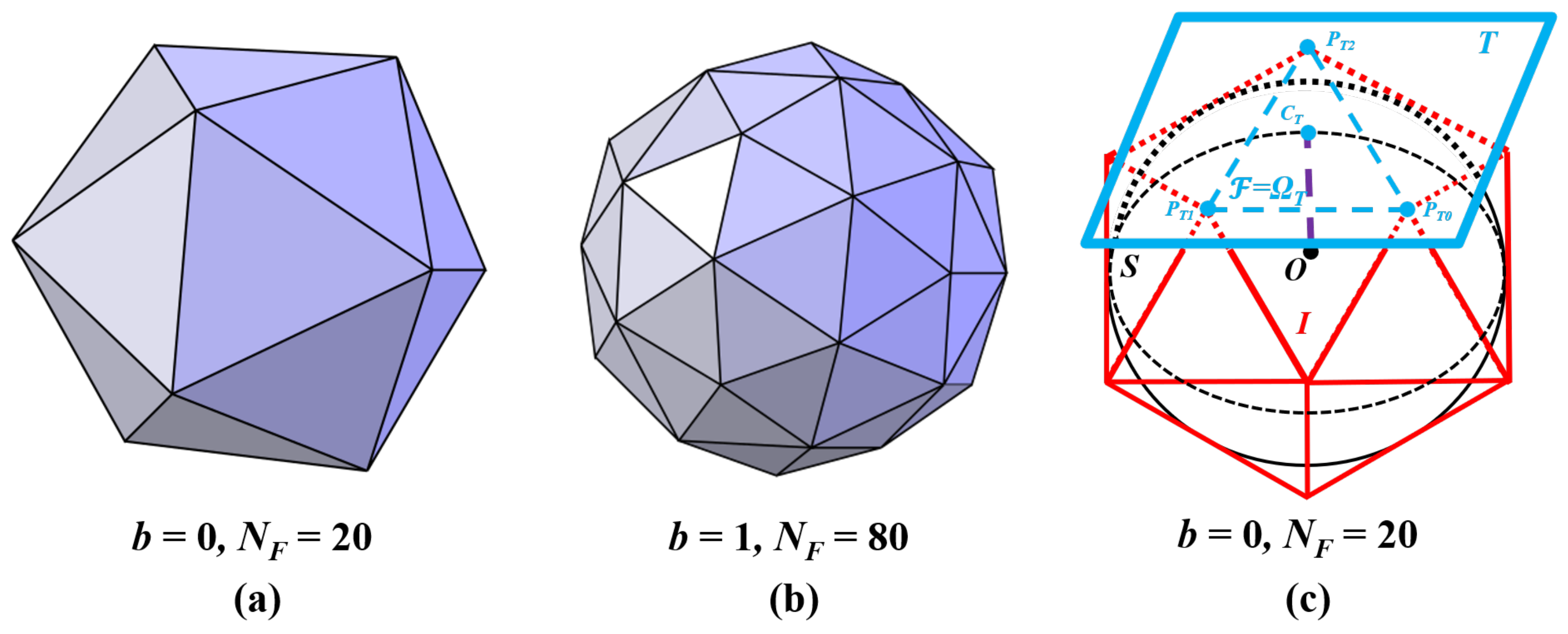
3.2. Icosahedron Subdivision Level
3.3. Tangent Images (TIs) Coordinate Mapping
3.4. Tangent Image (TI)-Based Feature Extraction-Matching
4. Planar-Equirectangular Image Stitching
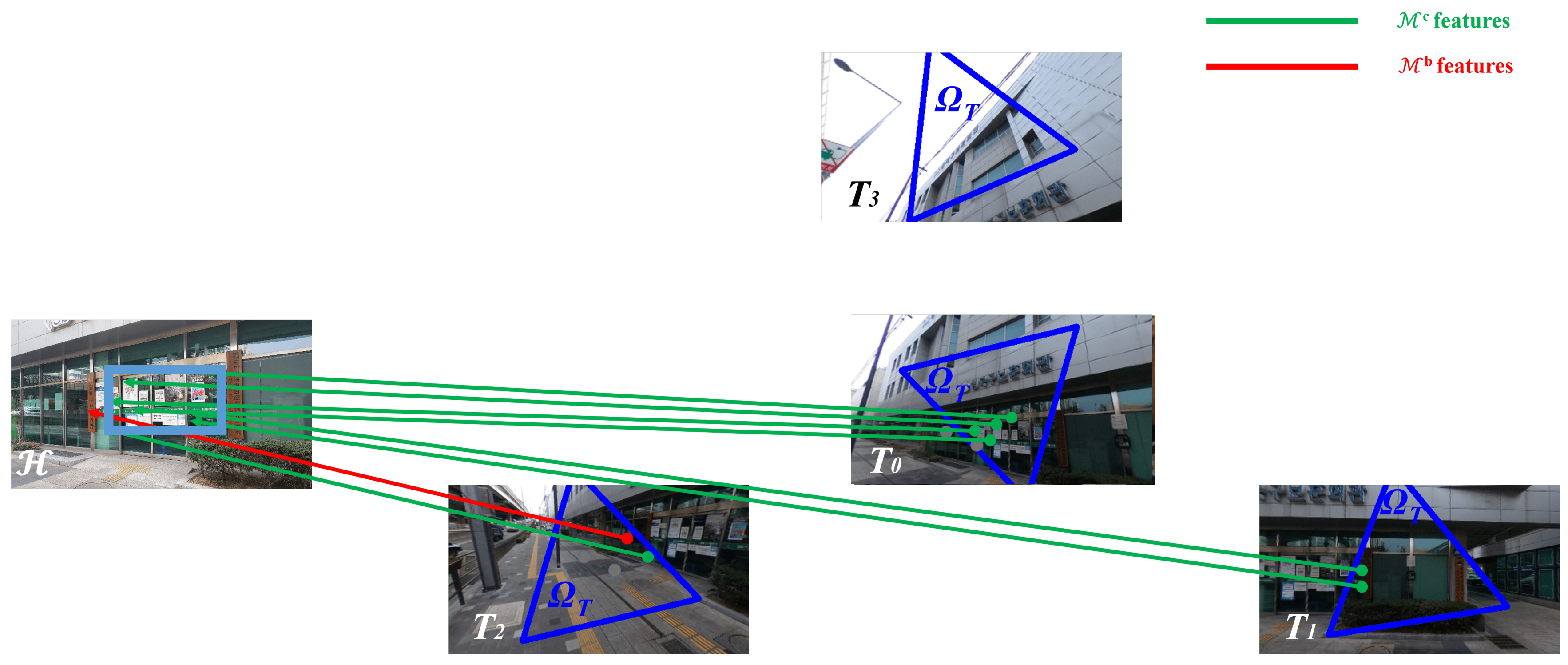
4.1. ROI Detection
4.1.1. ROI Tangent Image (ROI-TI) Searching
4.1.2. ROI Tangent Image (ROI-TI) Refinement
4.2. ROI Feature Extraction-Matching
4.3. HVS-Based Image Alignment
5. Experiment and Discussion
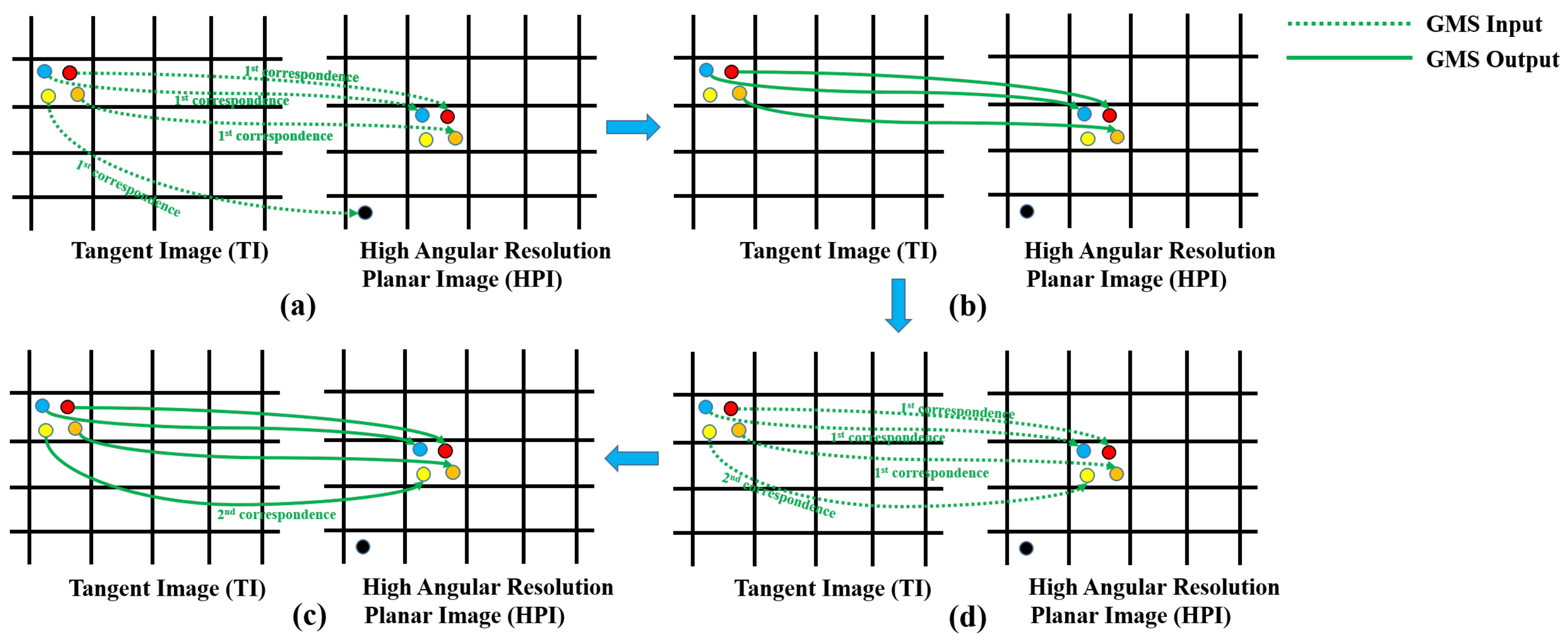
- KNN-Based GMS Feature Matcher.
- ROI detection.
- Tangent image (TI)-based planar-equirectangular image stitching pipeline.
- HVS-based image alignment.
- Computation time.
- Implementation in other 360° image format.
5.1. KNN-Based Gms Feature Matcher
5.2. ROI Detection
5.3. Tangent Image (TI)-Based Planar-Equirectangular Stitching Pipeline
5.4. HVS-Based Image Alignment
5.4.1. Qualitative Measurement
5.4.2. Quantitative Measurement
- on proposed method (V) is lower than affine (F) but higher than APAP (P):
- on proposed method (V) is lower than APAP (P) but higher than affine (F):
- on proposed method (V) is lower than both APAP (P) and affine (F): and
5.5. Computation Time
5.6. Implementation in Other 360° Image Format
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
Abbreviations
| VR | Virtual reality |
| ROI | Region of interest |
| HPI | High angular resolution planar image |
| EI | Equirectangular image |
| FOV | Field of view |
| TI | Tangent image |
| HVS | Human visual system |
| ROI-TI | ROI tangent image |
| GMS | Grid motion statistics |
| BF | Brute-force |
| KNN | K-Nearest Neighbor |
| APAP | As-projective-as-possible |
| ORB | Oriented FAST and Rotated BRIEF |
| SPHORB | Spherical ORB |
| MTI | Main tangent image |
| NTI | Neighbor tangent image |
| AMF | Accumulated matched features |
| HROI-TI | High angular resolution ROI tangent image |
| HROI-EI | High angular resolution ROI equirectangular image |
| USM | Unified spherical model |
References
- Sumikura, S.; Shibuya, M.; Sakurada, K. OpenVSLAM: A Versatile Visual SLAM Framework. In Proceedings of the 27th ACM International Conference on Multimedia (MM ’19); ACM: New York, NY, USA, 2019; pp. 2292–2295. [Google Scholar] [CrossRef] [Green Version]
- Barmpoutis, P.; Stathaki, T.; Dimitropoulos, K.; Grammalidis, N. Early Fire Detection Based on Aerial 360-Degree Sensors, Deep Convolution Neural Networks and Exploitation of Fire Dynamic Textures. Remote Sens. 2020, 12, 3177. [Google Scholar] [CrossRef]
- Jokela, T.; Ojala, J.; Väänänen, K. How People Use 360-Degree Cameras. In Proceedings of the 18th International Conference on Mobile and Ubiquitous Multimedia (MUM ’19); Association for Computing Machinery: New York, NY, USA, 2019. [Google Scholar] [CrossRef]
- Pelham, S. OHIO Students Use 360-Degree Videos to Document Daily Life during COVID-19. 2020. Available online: https://www.ohio.edu/news/2020/04/ohio-students-use-360-degree-videos-document-daily-life-during-covid-19 (accessed on 9 April 2021).
- Times, T.N.Y. Introducing the Daily 360 from The New York Times. The New York Times. 2016. Available online: https://www.nytimes.com/2016/11/01/nytnow/the-daily-360-videos.html (accessed on 9 April 2021).
- Ferdig, R.E.; Kosko, K.W. Implementing 360 Video to Increase Immersion, Perceptual Capacity, and Teacher Noticing. TechTrends 2020, 64, 849–859. [Google Scholar] [CrossRef]
- Syawaludin, M.F.; Lee, M.; Hwang, J.I. Foveation Pipeline for 360° Video-Based Telemedicine. Sensors 2020, 20, 2264. [Google Scholar] [CrossRef] [PubMed]
- Szeliski, R. Image Alignment and Stitching: A Tutorial. Found. Trends Comput. Graph. Vis. 2006, 2, 1–104. [Google Scholar] [CrossRef]
- Lyu, W.; Zhou, Z.; Chen, L.; Zhou, Y. A survey on image and video stitching. Virtual Real. Intell. Hardw. 2019, 1, 55–83. [Google Scholar] [CrossRef]
- Eder, M.; Shvets, M.; Lim, J.; Frahm, J.M. Tangent Images for Mitigating Spherical Distortion. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 14–19 June 2020. [Google Scholar]
- Johnson, J. Chapter 6—Our Peripheral Vision is Poor. In Designing with the Mind in Mind; Johnson, J., Ed.; Morgan Kaufmann: Boston, MA, USA, 2010; pp. 65–77. [Google Scholar] [CrossRef]
- Bian, J.W.; Lin, W.Y.; Liu, Y.; Zhang, L.; Yeung, S.K.; Cheng, M.M.; Reid, I. GMS: Grid-Based Motion Statistics for Fast, Ultra-robust Feature Correspondence. Int. J. Comput. Vis. 2020, 128, 1580–1593. [Google Scholar] [CrossRef] [Green Version]
- Lin, C.; Pankanti, S.U.; Ramamurthy, K.N.; Aravkin, A.Y. Adaptive as-natural-as-possible image stitching. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 1155–1163. [Google Scholar] [CrossRef] [Green Version]
- Zaragoza, J.; Chin, T.; Tran, Q.; Brown, M.S.; Suter, D. As-Projective-As-Possible Image Stitching with Moving DLT. IEEE Trans. Pattern Anal. Mach. Intell. 2014, 36, 1285–1298. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Brown, M.; Lowe, D.G. Recognising Panoramas. In Proceedings of the Ninth IEEE International Conference on Computer Vision, Nice, France, 13–16 October 2003; Volume 2, pp. 1218–1225. [Google Scholar]
- Brown, M.; Lowe, D. Automatic Panoramic Stitching Using Invariant Features. Int. J. Comput. Vis. 2007, 74, 59–73. [Google Scholar] [CrossRef] [Green Version]
- Gao, J.; Kim, S.J.; Brown, M.S. Constructing image panoramas using dual-homography warping. In Proceedings of the CVPR 2011, Colorado Springs, CO, USA, 20–25 June 2011; pp. 49–56. [Google Scholar] [CrossRef]
- Chen, Y.S.; Chuang, Y.Y. Natural Image Stitching with the Global Similarity Prior. In Computer Vision—ECCV 2016; Leibe, B., Matas, J., Sebe, N., Welling, M., Eds.; Springer International Publishing: Cham, Switzerland, 2016; pp. 186–201. [Google Scholar]
- Lin, K.; Jiang, N.; Cheong, L.F.; Do, M.; Lu, J. SEAGULL: Seam-Guided Local Alignment for Parallax-Tolerant Image Stitching. In European Conference on Computer Vision; Springer: Cham, Switzerland, 2016; Volume 9907, pp. 370–385. [Google Scholar] [CrossRef]
- Igarashi, T.; Moscovich, T.; Hughes, J.F. As-Rigid-as-Possible Shape Manipulation. ACM Trans. Graph. 2005, 24, 1134–1141. [Google Scholar] [CrossRef]
- Dornaika, F.; Elder, J.H. Image Registration for Foveated Panoramic Sensing. ACM Trans. Multimed. Comput. Commun. Appl. 2012, 8. [Google Scholar] [CrossRef]
- Dong, Y.; Pei, M.; Zhang, L.; Xu, B.; Wu, Y.; Jia, Y. Stitching Videos from a Fisheye Lens Camera and a Wide-Angle Lens Camera for Telepresence Robots. arXiv 2019, arXiv:1903.06319. [Google Scholar]
- Eder, M.; Frahm, J.M. Convolutions on Spherical Images. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, Long Beach, CA, USA, 16–20 June 2019. [Google Scholar]
- Zhao, Q.; Feng, W.; Wan, L.; Zhang, J. SPHORB: A Fast and Robust Binary Feature on the Sphere. Int. J. Comput. Vis. 2015, 113, 143–159. [Google Scholar] [CrossRef]
- Rublee, E.; Rabaud, V.; Konolige, K.; Bradski, G. ORB: An efficient alternative to SIFT or SURF. In Proceedings of the 2011 International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011; pp. 2564–2571. [Google Scholar] [CrossRef]
- Coxeter, H.S.M. Introduction to Geometry; Wiley: New York, NY, USA, 1969. [Google Scholar]
- Mackay, A.L. To find the largest sphere which can be inscribed between four others. Acta Crystallogr. Sect. A 1973, 29, 308–309. [Google Scholar] [CrossRef]
- Heinly, J.; Dunn, E.; Frahm, J.M. Comparative Evaluation of Binary Features. In Computer Vision—ECCV 2012; Fitzgibbon, A., Lazebnik, S., Perona, P., Sato, Y., Schmid, C., Eds.; Springer: Berlin/Heidelberg, Germany, 2012; pp. 759–773. [Google Scholar]
- Chang, C.; Sato, Y.; Chuang, Y. Shape-Preserving Half-Projective Warps for Image Stitching. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 3254–3261. [Google Scholar] [CrossRef] [Green Version]
- RICOH. Product | RICOH THETA. 2018. Available online: https://theta360.com/en/about/theta/ (accessed on 9 April 2021).
- Logitech. Enable Every Room. Enable Every Person. Available online: https://www.logitech.com/assets/64494/vc-whitepaper.pdf (accessed on 9 April 2021).
- Samsung Galaxy Note 5—The Official Samsung Galaxy Site. Available online: https://www.samsung.com/global/galaxy/galaxy-note5/ (accessed on 9 April 2021).
- Herrmann, C.; Wang, C.; Bowen, R.S.; Keyder, E.; Zabih, R. Object-Centered Image Stitching. In Computer Vision—ECCV 2018; Ferrari, V., Hebert, M., Sminchisescu, C., Weiss, Y., Eds.; Springer: Cham, Switzerland, 2018; pp. 846–861. [Google Scholar]
- Xiang, T.Z.; Xia, G.S.; Bai, X.; Zhang, L. Image stitching by line-guided local warping with global similarity constraint. Pattern Recognit. 2018, 83, 481–497. [Google Scholar] [CrossRef] [Green Version]
- Mei, C.; Rives, P. Single view point omnidirectional camera calibration from planar grids. In Proceedings of the IEEE International Conference on Robotics and Automation, Rome, Italy, 10–14 April 2007; pp. 3945–3950. [Google Scholar] [CrossRef] [Green Version]
- Rameau, F.; Demonceaux, C.; Sidibé, D.; Fofi, D. Control of a PTZ Camera in a Hybrid Vision System. In Proceedings of the International Conference on Computer Vision Theory and Applications (VISAPP), Lisbon, Portugal, 5–8 January 2014; Volume 3, pp. 397–405. [Google Scholar]
- Courbon, J.; Mezouar, Y.; Martinet, P. Evaluation of the unified model of the sphere for fisheye cameras in robotic applications. Adv. Robot. 2012, 26, 947–967. [Google Scholar] [CrossRef] [Green Version]
- Zhang, F.; Liu, F. Parallax-Tolerant Image Stitching. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 3262–3269. [Google Scholar] [CrossRef] [Green Version]
- Lin, K.; Jiang, N.; Cheong, L.; Do, M.N.; Lu, J. SEAGULL: Seam-Guided Local Alignment for Parallax-Tolerant Image Stitching. In Computer Vision—ECCV 2016—14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016, Proceedings, Part III; Leibe, B., Matas, J., Sebe, N., Welling, M., Eds.; Lecture Notes in Computer Science; Springer: Cham, Switzerland, 2016; Volume 9907, pp. 370–385. [Google Scholar] [CrossRef]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| ID | # Inliers | Entropy | Accuracy (%) | |||
|---|---|---|---|---|---|---|
| Original | Proposed | Original | Proposed | Original | Proposed | |
| 1 | 4127 | 5107 | 5.36 | 5.40 | 97.9 | 97.1 |
| 2 | 2755 | 3625 | 5.41 | 5.46 | 99.6 | 98.9 |
| 3 | 3112 | 3971 | 5.25 | 5.33 | 99.5 | 98.2 |
| 4 | 5249 | 6497 | 5.70 | 5.73 | 98.4 | 97.9 |
| 5 | 1228 | 1784 | 5.21 | 5.26 | 97.7 | 95.5 |
| 6 | 3009 | 3922 | 5.28 | 5.34 | 99.2 | 98.0 |
| 7 | 1698 | 2294 | 5.15 | 5.23 | 96.8 | 97.1 |
| 8 | 2432 | 3234 | 5.16 | 5.22 | 98.9 | 98.3 |
| 9 | 847 | 1165 | 4.10 | 4.08 | 97.6 | 97.7 |
| 10 | 2330 | 3170 | 5.09 | 5.11 | 96.3 | 95.2 |
| 11 | 2410 | 3097 | 4.88 | 4.92 | 99.8 | 99.5 |
| 12 | 2365 | 3155 | 5.49 | 5.53 | 99.7 | 99.2 |
| 13 | 2049 | 2845 | 5.25 | 5.32 | 90.3 | 86.3 |
| 14 | 3193 | 3959 | 5.41 | 5.47 | 92.3 | 89.5 |
| 15 | 2502 | 3160 | 5.18 | 5.23 | 98.7 | 98.5 |
| 16 | 4633 | 5717 | 5.35 | 5.39 | 98.9 | 98.7 |
| Avg | 2746 | 3544 (29.0%)1 | 5.20 | 5.25 | 97.6 | 96.6 |
| ID | Angular Error (°) | ID | Angular Error (°) | ||
|---|---|---|---|---|---|
| Initial | Refined | Initial | Refined | ||
| 1 | 32.8 | 8.37 | 9 | 10.7 | 3.24 |
| 2 | 32.8 | 5.51 | 10 | 2.48 | 1.34 |
| 3 | 6.74 | 1.18 | 11 | 33.1 | 15.5 |
| 4 | 18.6 | 0.942 | 12 | 17.3 | 12.6 |
| 5 | 9.94 | 1.54 | 13 | 19.1 | 9.16 |
| 6 | 18.2 | 5.45 | 14 | 10.0 | 6.22 |
| 7 | 14.9 | 3.29 | 15 | 20.6 | 6.54 |
| 8 | 16.8 | 5.01 | 16 | 13.4 | 5.58 |
| Avg | 17.3 | 5.72 | |||
| ID | APAP | Affine | Proposed | Hypotheses | ID | APAP | Affine | Proposed | Hypotheses |
|---|---|---|---|---|---|---|---|---|---|
| Alignment Error (pixel) | |||||||||
| 1 | 3.54 | 4.95 | 3.59 | TRUE | 9 | 5.68 | 6.91 | 6.15 | TRUE |
| 2 | 5.96 | 11.2 | 7.65 | TRUE | 10 | 6.85 | 9.78 | 6.70 | FALSE |
| 3 | 6.26 | 8.63 | 6.93 | TRUE | 11 | 8.73 | 15.4 | 9.80 | TRUE |
| 4 | 5.76 | 6.13 | 5.47 | FALSE | 12 | 6.06 | 14.3 | 7.66 | TRUE |
| 5 | 6.95 | 10.3 | 7.25 | TRUE | 13 | 7.83 | 24.6 | 8.83 | TRUE |
| 6 | 6.73 | 11.7 | 6.96 | TRUE | 14 | 7.05 | 18.7 | 9.52 | TRUE |
| 7 | 6.16 | 7.70 | 6.04 | FALSE | 15 | 3.76 | 4.20 | 3.76 | FALSE |
| 8 | 3.33 | 3.77 | 3.28 | FALSE | 16 | 4.99 | 5.98 | 5.02 | TRUE |
| Avg | 5.98 | 10.3 | 6.54 | 11 of 16 | |||||
| Distortion Error (pixel) | |||||||||
| 1 | 0.98 | 0.78 | 0.82 | TRUE | 9 | 2.80 | 2.49 | 2.65 | TRUE |
| 2 | 0.79 | 0.73 | 0.75 | TRUE | 10 | 1.23 | 0.99 | 1.01 | TRUE |
| 3 | 1.52 | 1.12 | 1.23 | TRUE | 11 | 1.32 | 0.47 | 0.91 | TRUE |
| 4 | 0.46 | 0.67 | 0.56 | FALSE | 12 | 0.92 | 0.60 | 0.73 | TRUE |
| 5 | 0.63 | 0.43 | 0.42 | FALSE | 13 | 1.52 | 0.91 | 1.00 | TRUE |
| 6 | 1.11 | 0.52 | 0.72 | TRUE | 14 | 1.59 | 1.58 | 1.70 | FALSE |
| 7 | 0.78 | 0.77 | 0.70 | FALSE | 15 | 0.36 | 0.31 | 0.32 | TRUE |
| 8 | 0.67 | 0.37 | 0.43 | TRUE | 16 | 1.08 | 0.56 | 0.66 | TRUE |
| Avg | 1.11 | 0.83 | 0.91 | 12 of 16 | |||||
| Alignment-Distortion Error | |||||||||
| 1 | 0.67 | 0.71 | 0.62 | TRUE | 9 | 0.66 | 0.68 | 0.66 | FALSE |
| 2 | 0.59 | 0.78 | 0.64 | FALSE | 10 | 0.68 | 0.72 | 0.60 | TRUE |
| 3 | 0.68 | 0.68 | 0.64 | TRUE | 11 | 0.75 | 0.63 | 0.62 | TRUE |
| 4 | 0.61 | 0.75 | 0.64 | FALSE | 12 | 0.62 | 0.78 | 0.60 | TRUE |
| 5 | 0.71 | 0.71 | 0.58 | TRUE | 13 | 0.63 | 0.86 | 0.50 | TRUE |
| 6 | 0.74 | 0.68 | 0.58 | TRUE | 14 | 0.53 | 0.85 | 0.62 | FALSE |
| 7 | 0.66 | 0.73 | 0.62 | TRUE | 15 | 0.68 | 0.67 | 0.65 | TRUE |
| 8 | 0.78 | 0.61 | 0.61 | TRUE | 16 | 0.78 | 0.62 | 0.60 | TRUE |
| Avg | 0.67 | 0.72 | 0.61 | 12 of 16 | |||||
| ID | ROI Detection (s) | ROI Extraction-Matching (s) | Alignment (s) |
|---|---|---|---|
| 1 | 3.47 | 0.84 | 2.60 |
| 2 | 3.71 | 1.12 | 2.99 |
| 3 | 2.06 | 1.26 | 2.94 |
| 4 | 4.81 | 1.03 | 4.16 |
| 5 | 3.25 | 0.78 | 2.56 |
| 6 | 2.84 | 0.59 | 2.82 |
| 7 | 2.95 | 1.61 | 2.42 |
| 8 | 2.12 | 1.69 | 2.19 |
| 9 | 1.98 | 2.30 | 1.64 |
| 10 | 3.06 | 1.54 | 2.55 |
| 11 | 1.39 | 1.09 | 2.03 |
| 12 | 2.05 | 1.50 | 3.57 |
| 13 | 3.08 | 1.01 | 2.75 |
| 14 | 4.90 | 1.01 | 3.52 |
| 15 | 4.92 | 0.69 | 2.76 |
| 16 | 2.57 | 1.09 | 2.87 |
| Avg | 3.07 (43.6%) | 1.20 (17.0%) | 2.77 (39.4%) |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Syawaludin, M.-F.; Kim, S.; Hwang, J.-I. Planar-Equirectangular Image Stitching. Electronics 2021, 10, 1126. https://doi.org/10.3390/electronics10091126
Syawaludin M-F, Kim S, Hwang J-I. Planar-Equirectangular Image Stitching. Electronics. 2021; 10(9):1126. https://doi.org/10.3390/electronics10091126
Chicago/Turabian StyleSyawaludin, Muhammad-Firdaus, Seungwon Kim, and Jae-In Hwang. 2021. "Planar-Equirectangular Image Stitching" Electronics 10, no. 9: 1126. https://doi.org/10.3390/electronics10091126