
Lane Line Detection Based on Object Feature Distillation



Abstract
:1. Introduction
2. Related Work
3. Methodology
3.1. Spatial Convolution Neural Network (SCNN)
3.2. Knowledge Distillation (KD) Method
3.3. Methodology Follow in This Paper
3.3.1. The Overall Structure Design of the Target Characteristic Distillation Network
3.3.2. Network Decoder Structure Design of Target Feature Distillation Network
3.3.3. Loss Function of the Target Feature Distillation Network
4. Dataset
5. Experimental Result and Analysis
5.1. Evaluation Standard
5.2. Experimental Environment & Network Parameter Setting
5.3. Experimental Result and Comparative Analysis
5.3.1. Quantitative Analysis
5.3.2. Qualitative Analysis
6. Conclusions and Future Work
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Tran, N. World Health Organization; WHO: Geneva, Switzerland, 2018; pp. 5–11. [Google Scholar]
- National Highway Traffic Safety Administration. Traffic Safety Facts 2017: A Compilation of Motor Vehicle Crash Data. DOT HS 812806. 2019. Available online: https://crashstats.nhtsa.dot.gov/Api/Public/ViewPublication/812806 (accessed on 1 January 2021).
- Song, W.; Yang, Y.; Fu, M.; Li, Y.; Wang, M. Lane Detection and Classification for Forward Collision Warning System Based on Stereo Vision. IEEE Sens. J. 2018, 18, 5151–5163. [Google Scholar] [CrossRef]
- Haris, M.; Hou, J. Obstacle detection and safely navigate the autonomous vehicle from unexpected obstacles on the driving lane. Sensors 2020, 20, 4719. [Google Scholar] [CrossRef] [PubMed]
- Khalifa, O.O.; Assidiq, A.A.M.; Hashim, A.H.A. Vision-based lane detection for autonomous artificial intelligent vehicles. In Proceedings of the ICSC 2009—2009 IEEE International Conference on Semantic Computing, Berkeley, CA, USA, 14–16 September 2009; pp. 636–641. [Google Scholar]
- Zhang, X.; Huang, H.; Meng, W.; Luo, D. Improved lane detection method based on convolutional neural network using self-attention distillation. Sens. Mater. 2020, 32, 4505–4516. [Google Scholar] [CrossRef]
- Homayounfar, N.; Ma, W.C.; Lakshmikanth, S.K.; Urtasun, R. Hierarchical Recurrent Attention Networks for Structured Online Maps. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Sun, T.Y.; Tsai, S.J.; Chan, V. HSI color model based lane-marking detection. In Proceedings of the IEEE Intelligent Transportation Systems Conference (ITSC), Toronto, ON, Canada, 17–20 September 2006; pp. 1168–1172. [Google Scholar]
- Chiu, K.Y.; Lin, S.F. Lane detection using color-based segmentation. In Proceedings of the IEEE Intelligent Vehicles Symposium, Las Vegas, NV, USA, 6–8 June 2005; Volume 2005, pp. 706–711. [Google Scholar]
- Li, Q.; Zheng, N.; Cheng, H. An adaptive approach to lane markings detection. In Proceedings of the IEEE Intelligent Transportation Systems Conference (ITSC), Shanghai, China, 12–15 October 2003; Volume 1, pp. 510–514. [Google Scholar]
- Bertozzi, M.; Broggi, A.; Fascioli, A. Vision-based intelligent vehicles: State of the art and perspectives. Rob. Auton. Syst. 2000, 32, 1–16. [Google Scholar] [CrossRef] [Green Version]
- Jung, C.R.; Kelber, C.R. Lane following and lane departure using a linear-parabolic model. Image Vis. Comput. 2005, 23, 1192–1202. [Google Scholar] [CrossRef]
- Bar Hillel, A.; Lerner, R.; Levi, D.; Raz, G. Recent progress in road and lane detection: A survey. Mach. Vis. Appl. 2014, 25, 727–745. [Google Scholar] [CrossRef]
- Kumar, A.M.; Simon, P. Review of Lane Detection and Tracking Algorithms in Advanced Driver Assistance System. Int. J. Comput. Sci. Inf. Technol. 2015, 7, 65–78. [Google Scholar] [CrossRef]
- Narote, S.P.; Bhujbal, P.N.; Narote, A.S.; Dhane, D.M. A review of recent advances in lane detection and departure warning system. Pattern Recognit. 2018, 73, 216–234. [Google Scholar] [CrossRef]
- Aly, M. Real time detection of lane markers in urban streets. In Proceedings of the IEEE Intelligent Vehicles Symposium, Eindhoven, The Netherlands, 4–6 June 2008; pp. 7–12. [Google Scholar]
- Kim, J.; Lee, M. Robust lane detection based on convolutional neural network and random sample consensus. In Proceedings of the International Conference on Neural Information Processing, Kuching, Malaysia, 3–6 November 2014; Volume 8834, pp. 454–461. [Google Scholar] [CrossRef]
- Jung, H.; Min, J.; Kim, J. An efficient lane detection algorithm for lane departure detection. In Proceedings of the IEEE Intelligent Vehicles Symposium, Gold Coast, QLD, Australia, 23–26 June 2013; pp. 976–981. [Google Scholar]
- Bottazzi, V.S.; Borges, P.V.K.; Stantic, B.; Jo, J. Adaptive regions of interest based on HSV histograms for lane marks detection. In Advances in Intelligent Systems and Computing; Springer: Berlin/Heidelberg, Germany, 2014; Volume 274, pp. 677–687. [Google Scholar]
- Wu, P.C.; Chang, C.Y.; Lin, C.H. Lane-mark extraction for automobiles under complex conditions. Pattern Recognit. 2014, 47, 2756–2767. [Google Scholar] [CrossRef]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Fei-Fei, L. ImageNet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Huval, B.; Wang, T.; Tandon, S.; Kiske, J.; Song, W.; Pazhayampallil, J.; Andriluka, M.; Rajpurkar, P.; Migimatsu, T.; Cheng-Yue, R.; et al. An Empirical Evaluation of Deep Learning on Highway Driving. arXiv 2015, arXiv:1504.01716. [Google Scholar]
- He, B.; Ai, R.; Yan, Y.; Lang, X. Accurate and robust lane detection based on Dual-View Convolutional Neutral Network. In Proceedings of the IEEE Intelligent Vehicles Symposium, Gothenburg, Sweden, 19–22 June 2016; pp. 1041–1046. [Google Scholar]
- Pan, X.; Shi, J.; Luo, P.; Wang, X.; Tang, X. Spatial as deep: Spatial CNN for traffic scene understanding. In Proceedings of the 32nd AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2 February 2018; pp. 7276–7283. [Google Scholar]
- Wang, Z.; Ren, W.; Qiu, Q. LaneNet: Real-time lane detection networks for autonomous driving. arXiv 2018, arXiv:1807.01726. [Google Scholar]
- Ghafoorian, M.; Nugteren, C.; Baka, N.; Booij, O.; Hofmann, M. EL-GAN: Embedding loss driven generative adversarial networks for lane detection. In Proceedings of the Lecture Notes in Computer Science (Including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics), Munich, Germany, 8–14 September 2018; Volume 11129, pp. 256–272. [Google Scholar]
- Kim, J.; Park, C. End-To-End Ego Lane Estimation Based on Sequential Transfer Learning for Self-Driving Cars. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition Workshops, Honolulu, HI, USA, 21–26 July 2017; Volume 2017, pp. 1194–1202. [Google Scholar]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. SegNet: A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef] [PubMed]
- Zhang, J.; Xu, Y.; Ni, B.; Duan, Z. Geometric Constrained Joint Lane Segmentation and Lane Boundary Detection. In Proceedings of the Lecture Notes in Computer Science (Including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics), Munich, Germany, 8–14 September 2018; Volume 11205, pp. 502–518. [Google Scholar]
- Hsu, Y.C.; Xu, Z.; Kira, Z.; Huang, J. Learning to cluster for proposal-free instance segmentation. In Proceedings of the 2018 International Joint Conference on Neural Networks (IJCNN), Rio de Janeiro, Brazil, 8–13 July 2018. [Google Scholar]
- Neven, D.; De Brabandere, B.; Georgoulis, S.; Proesmans, M.; Van Gool, L. Towards End-to-End Lane Detection: An Instance Segmentation Approach. In Proceedings of the IEEE Intelligent Vehicles Symposium, Rio de Janeiro, Brazil, 8–13 July 2018; Volume 2018, pp. 286–291. [Google Scholar]
- Hinton, G.; Vinyals, O.; Dean, J. Distilling the Knowledge in a Neural Network. arXiv 2015, arXiv:150.00531. [Google Scholar]
- Papamakarios, G. Distilling Model Knowledge. arXiv arXiv:1510.002437, 2015.
- Romero, A.; Ballas, N.; Kahou, S.E.; Chassang, A.; Gatta, C.; Bengio, Y. FitNets: Hints for Thin Deep Nets. Available online: https://arxiv.org/abs/1412.6550 (accessed on 1 January 2021).
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 834–848. [Google Scholar] [CrossRef] [PubMed]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. Available online: https://arxiv.org/abs/1409.1556 (accessed on 1 January 2021).
- Yu, F.; Koltun, V. Multi-scale context aggregation by dilated convolutions. arXiv 2016, arXiv:1511.07122. [Google Scholar]
- Xie, J.; Shuai, B.; Hu, J.F.; Lin, J.; Zheng, W.S. Improving Fast Segmentation with Teacher-student Learning. arXiv 2018, arXiv:1810.08476. [Google Scholar]
- Jiao, J.; Wei, Y.; Jie, Z.; Shi, H.; Lau, R.; Huang, T.S. Geometry-aware distillation for indoor semantic segmentation. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; 2019, pp. 2864–2873. [Google Scholar]
- Liu, Y.; Chen, K.; Liu, C.; Qin, Z.; Luo, Z.; Wang, J. Structured knowledge distillation for semantic segmentation. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; Volume 2019, pp. 2599–2608. [Google Scholar]
- Hou, Y.; Ma, Z.; Liu, C.; Loy, C.C. Learning lightweight lane detection CNNS by self attention distillation. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Korea, 27 October–3 November 2019; pp. 1013–1021. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely Connected Convolutional Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Fritsch, J.; Kuhnl, T.; Geiger, A. A new performance measure and evaluation benchmark for road detection algorithms. In Proceedings of the IEEE Intelligent Transportation Systems Conference (ITSC), The Hague, The Netherlands, 6–9 October 2013; pp. 1693–1700. [Google Scholar]
- Brostow, G.J.; Shotton, J.; Fauqueur, J.; Cipolla, R. Segmentation and recognition using structure from motion point clouds. In Proceedings of the Lecture Notes in Computer Science (Including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics), Marseille, France, 12–18 October 2008; Volume 5302, pp. 44–57. [Google Scholar]
- Tusimple Benchmark. Available online: https://github.com/%0ATuSimple/tusimple-benchmark (accessed on 1 January 2021).
- Shirke, S.; Udayakumar, R. Lane datasets for lane detection. In Proceedings of the 2019 IEEE International Conference on Communication and Signal Processing (ICCSP), Dalian, China, 20–23 September 2019; pp. 792–796. [Google Scholar]
- Abadi, M.; Agarwal, A.; Barham, P.; Brevdo, E.; Chen, Z.; Citro, C.; Corrado, G.S.; Davis, A.; Dean, J.; Devin, M.; et al. TensorFlow: Large-Scale Machine Learning on Heterogeneous Distributed Systems. arXiv 2016, arXiv:1603.04467. [Google Scholar]
- Chetlur, S.; Woolley, C.; Vandermersch, P.; Cohen, J.; Tran, J.; Catanzaro, B.; Shelhamer, E. cuDNN: Efficient Primitives for Deep Learning. arXiv 2014, arXiv:1410.0759. [Google Scholar]
- Yu, C.; Wang, J.; Peng, C.; Gao, C.; Yu, G.; Sang, N. Learning a Discriminative Feature Network for Semantic Segmentation. Available online: https://openaccess.thecvf.com/content_cvpr_2018/html/Yu_Learning_a_Discriminative_CVPR_2018_paper.html (accessed on 1 January 2021).









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
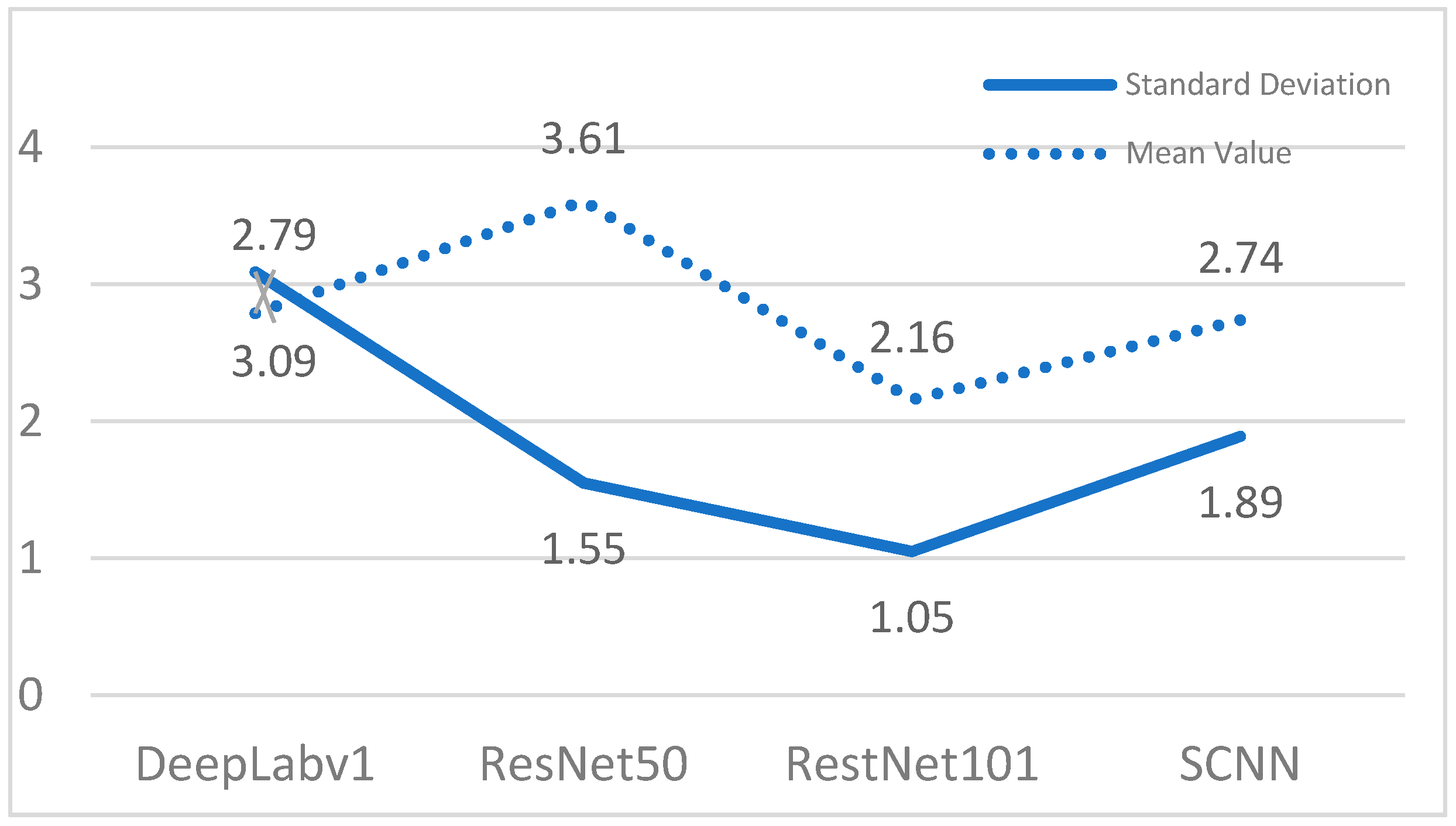{kind=link}
{kind=link}
{kind=link}
| Dataset | Training | Frame | Sequences | M. Weather | M. Time | Attributes |
|---|---|---|---|---|---|---|
| Caltech Lanes | - | 1224 | 4 | Yes | No | 2 |
| Road Marking | - | 1443 | 29 | Yes | Yes | 10 |
| KITTI Road | 289 | 579 | - | No | No | 2 |
| TuSimple | 3626 | 7000 | 7000 | No | No | 2 |
| VPGNet | 14,783 | 21,097 | - | Yes | Yes | 17 |
| BDD100K | 70,000 | 100,000 | 100,000 | Yes | Yes | 11 |
| CuLane | 88,880 | 133,235 | 55 h Video | Yes | Yes | 9 |
| Method | Scenario | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Normal | Crowded | Dazzle Light | Shadow | No Line | Arrow | Curve | Crowded | Night | Total | |
| SCNN [24] | 90.6 | 69.7 | 58.5 | 66.9 | 43.4 | 84.1 | 64.4 | 69.7 | 66.1 | 71.6 |
| GCJ [29] | 89.7 | 76.5 | 67.4 | 65.5 | 35.1 | 82.2 | 63.2 | 76.5 | 68.7 | 73.1 |
| SAD [41] | 90.7 | 70.0 | 59.9 | 67.0 | 43.5 | 84.4 | 65.7 | 70.0 | 66.3 | 71.8 |
| Our Smooth | 92.1 | 72.6 | 61.6 | 71.7 | 46.0 | 86.9 | 68.9 | 72.6 | 69.4 | 74.1 |
| Scenario | Methods | |||||||
|---|---|---|---|---|---|---|---|---|
| DeepLabv1 [25] | ResNet50 [25] | ResNet101 [25] | SCNN [25] | DeepLabv1 + OFD | ResNet50 + OFD | ResNet101 + OFD | SCNN + OFD | |
| Arrow | 74.0 | 79.0 | 84.0 | 84.1 | 76.8 | 82.5 | 86.2 | 86.8 |
| Cross Road | 2060 | 2505 | 2183 | 1990 | 2445 | 2229 | 2004 | 2222 |
| Crowded | 61.0 | 64.1 | 68.2 | 69.7 | 62.8 | 67.1 | 69.8 | 71.5 |
| Curve | 61.0 | 59.8 | 65.5 | 64.4 | 61.8 | 64.5 | 68.5 | 67.0 |
| Dazzle Light | 49.9 | 54.1 | 59.8 | 58.5 | 55.3 | 58.6 | 63.3 | 64.3 |
| Night | 56.9 | 60.6 | 65.9 | 66.1 | 57.57 | 63.6 | 67.1 | 67.6 |
| No Line | 34.0 | 38.1 | 41.7 | 43.4 | 35.4 | 40.6 | 43.8 | 45.0 |
| Normal | 83.1 | 87.4 | 90.2 | 90.6 | 84.5 | 89.1 | 90.9 | 91.6 |
| Shadow | 54.7 | 60.7 | 64.6 | 66.9 | 64.7 | 67.6 | 68.3 | 73.0 |
| Total | 63.2 | 66.7 | 70.8 | 71.6 | 64.7 | 69.4 | 72.2 | 73.2 |
| Method | Total (%) |
|---|---|
| SCNN | 71.6 |
| SCNN (3 Stage) | 72.4 |
| SCNN (5 Stage) | 73.2 |
| SCNN (Smooth) | 74.1 |
| Method | Total (%) |
|---|---|
| SCNN | 71.6 |
| SCNN_5Stage_MSE | 73.2 |
| SCNN_5Stage_KL | 73.6 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Haris, M.; Glowacz, A. Lane Line Detection Based on Object Feature Distillation. Electronics 2021, 10, 1102. https://doi.org/10.3390/electronics10091102
Haris M, Glowacz A. Lane Line Detection Based on Object Feature Distillation. Electronics. 2021; 10(9):1102. https://doi.org/10.3390/electronics10091102
Chicago/Turabian StyleHaris, Malik, and Adam Glowacz. 2021. "Lane Line Detection Based on Object Feature Distillation" Electronics 10, no. 9: 1102. https://doi.org/10.3390/electronics10091102