
ImbTreeEntropy and ImbTreeAUC: Novel R Packages for Decision Tree Learning on the Imbalanced Datasets


Abstract
:1. Introduction
- We show implementation of large collection of generalized entropy functions including Rényi, Tsallis, Sharma-Mittal, Sharma-Taneja and Kapur as the impurity measures of the node in the ImbTreeEntropy algorithm;
- We employ local, semi-global and global AUC (Area Under the ROC curve) measures to choose the optimal split point for the attribute in the ImbTreeAUC algorithm;
- Both packages support cost-sensitive learning via a misclassification cost matrix, or observation weights;
- Both algorithms enable thresholds’ optimization with posterior probabilities to determine final class labels so the misclassification costs are minimized;
- The algorithms are suitable for the binary and multi-class problems. The package accepts all types of the attributes, including continuous, ordered and nominal.
2. Literature Review
3. Imbalanced Tree Algorithm
3.1. Notations
3.2. Generalized Entropy Measures
3.3. Area Under the ROC Curve
3.4. Cost- and Weight-Sensitive Learning
3.5. Genarating Splits on Attributes
- Calculate the contingency table between the attributes and the target attribute . It is done using either just the number of observations in each intersection or, in the case of the cost sensitive classification, sum of the weights or sum of costs from the cost matrix;
- Convert the contingency table to the class probability matrix ;
- Compute the weighted covariance matrix , where () is the row of the matrix P, is the number (or its weighted form) of observations with category and is the vector of mean class probabilities per target class. This part is performed by the authors of the article using cov.wt() function;
- Calculate the first principal component of and the principal component scores of the variable levels by . This part is done by function prcomp();
- Sort the levels by their principal component scores .
3.6. Learning Phase
| Algorithm 1. ImbTreeEntropy and ImbTreeAUC algorithm. |
| Input: Yname, Xnames, data, depth, levelPositive, minobs, type, entropypar, cp, ncores, weights, AUCweight, cost, Classthreshold, overfit Output: Tree () /1/ StopIfNot()//check if all parameters are correctly specified /2/ AssignProbMatrix()//assign global probability matrix and AUC /3/ AssignInitMeasures()//assign various initial measures /4/ //create root of the Tree /5/ iftype != AUCg then do//call of the main building function /6/ BuildTree()//standard recursive partitioning /7/ else do /8/ BuildTreeAUC()//repeated recursive partitioning for all existing leaves /9/ end /10/ if Classthreshold = tuned then do /11/ AssignClass()//determine class of each observation based on various approaches /12/ UpdateTree()//assign final class /13/ end /14/ if overfit then do /15/ PruneTree()//prune tree if needed /16/ end /17/ return |
| Algorithm 2. BuildTree algorithm. |
| Input: node (), Yname, Xnames, data, depth, levelPositive, minobs, type, entropypar, cp, ncores, weights, AUCweight, cost, Classthreshold, overfit Output: Tree () /1/ node.Count = nrow(data)//number of observations in the node /2/ node.Prob = CalcProb()//assign probabilities to the node /3/ node.Class = ChooseClass()//assign class to the node /4/ splitrule = BestSplitGlobal()//calculate statistics of all possible best local splits; choose the best one /5/ isimpr = IfImprovement(splitrule)//Check if the improvement is greater than the threshold cp /6/ if isimpr = FALSE then do /7/ UpdateProbMatrix()//update global probability matrix /8/ CreateLeaf()//create leaf with various information /9/ return /10/ else do /11/ BuildTree(left )//build recursively tree using left child obtained based on the splitrule /12/ BuildTree(right )//build recursively tree using right child obtained based on the splitrule /13/ end /14/ return |
| Algorithm 3. BuildTreeAUC algorithm. |
| Input: tree (), Yname, Xnames, data, depth, levelPositive, minobs, type, entropypar, cp, ncores, weights, AUCweight, cost, Classthreshold, overfit Output: Tree () /1/ repeat /2/ splitall = TraversTree()//travers recursively all leaves in the tree to find all possible splits /3/ splitpossible = PossibleSplitTravers(splitall)//choose only possible splits based on the cp /4/ if splitpossible = then break repeat//if there is no possible split terminate the program /5/ splitrule = BestSplitTravers(splitpossible)//choose the best split /6/ UpdateProbMatrix()//update global probability matrix /7/ CreateLeaf(left )//create left child obtained based on the splitrule /8/ CreateLeaf(right )//create right child obtained based on the splitrule /9/ /10/ end /11/ return |
- Yname: name of the target variable; character vector of one element.
- Xnames: attribute names used for target modelling; character vector of many elements.
- data: data.frame in which to interpret the variables Yname and Xnames.
- depth: set the maximum depth of any node of the final tree, with the root node counted as depth 0; numeric vector of one element which is greater or equal to 0.
- minobs: the minimum number of observations that must exist in any terminal node (leaf); numeric vector of one element which is greater or equal to 1.
- type: method used for learning; character vector of one element with one of the: “Shannon”, “Renyi”, “Tsallis”,“Sharma-Mittal”, “Sharma-Taneja”, “Kapur”, “AUCl”, “AUCs”, “AUCg”.
- entropypar: numeric vector specifying parameters for the following entropies “Renyi”, “Tsallis”, “Sharma-Mittal”, “Sharma-Taneja”, “Kapur”; For “Renyi”, “Tsallis” is a one-element vector with -value; for “Sharma-Mittal“ or “Sharma-Taneja“ and “Kapura“is a two-element vector with either -value and -value or -value and -value, respectively.
- levelPositive: name of the positive class (label) used in AUC calculation, i.e., predictions being the probability of the positive event; the character vector of one element.
- cp: complexity parameter, i.e., any split that does not decrease the overall lack of fit by a factor of cp is not attempted; if cost or weights are specified accuracy measures take these parameters into account; the numeric vector of one element is greater or equal to 0.
- cf: Numeric vector of one element with the number in (0, 0.5] for the optional pessimistic-error-rate-based pruning step.
- ncores: number of cores used for parallel processing; numeric vector of one element which is greater or equal to 1.
- weights: numeric vector of case weights; it should have as many elements as the number of observations in the data.frame passed to the data parameter.
- AUCweight: method used for AUC weighting in multiclass classification problems; character vector of one element with one of: “none”, “bySize”, “byCost”.
- cost: a matrix of costs associated with the possible errors; the matrix should have columns and rows where is the number of class levels; rows contain true classes while columns contain predicted classes, rows and columns names should take all possible categories (labels) of the target variable.
- Classthreshold: method used for determining thresholds based on which final class for each node is derived; if cost is specified it can take one of the following: “theoretical”, “tuned”, otherwise it takes “equal”; character vector of one element.
- overfit: character vector of one element with one of the: “none”, “leafcut”, “prune”, “avoid” specifying which method to overcome overfitting should be used; the “leafcut” method is used when the full tree is built, it reduces the subtree when both siblings choose the same class label; “avoid” method is incorporated during the recursive partitioning, it prohibits the split when both siblings choose the same class; the ”prune” method employs the pessimistic error pruning procedure, and it should be specified along with the cf parameter.
4. Research Framework and Settings
4.1. Experiment Design
4.1.1. Data Sets Characteristics
4.1.2. Benchmarking Methods
- Rpart–package for recursive partitioning for classification, regression and survival trees;
- C50–package which contains an interface to the C5.0 classification trees and rule-based models based on the Shannon entropy;
- CTree–conditional inference trees in the party package.
4.1.3. Accuracy Measures
4.2. Numerical Experiments
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
Appendix A. Comparison of Classification Results

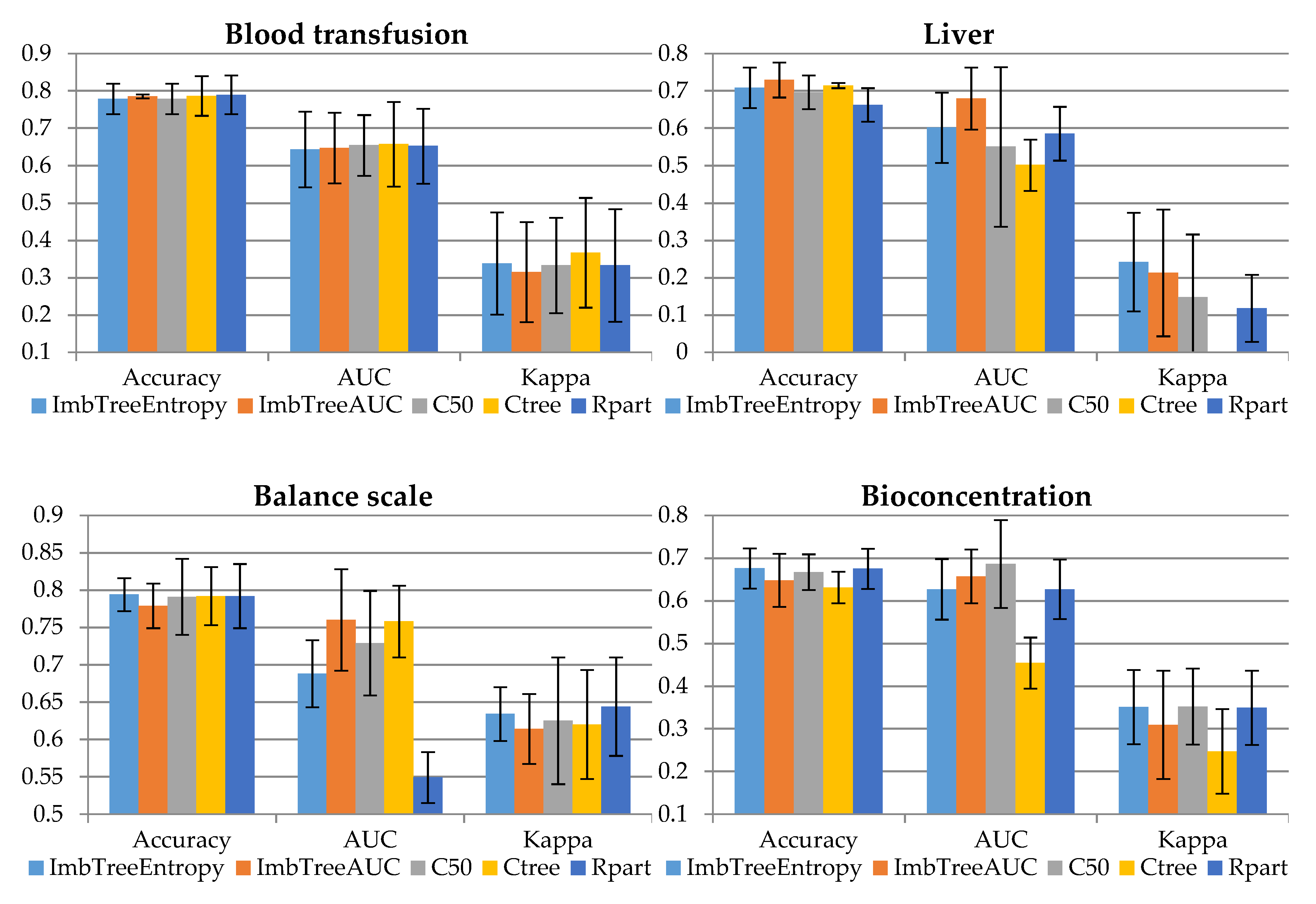{kind=link}
{kind=link}
| Algorithm | Sensitivity | Specificity | Pos Pred Value | Neg Pred Value | Prevalence | Detection Rate |
|---|---|---|---|---|---|---|
| Blood transfusion data | ||||||
| ImbTreeEntropy | 0.886 (∓0.039) | 0.432 (∓0.137) | 0.835 (∓0.034) | 0.541 (∓0.115) | 0.762 (∓0.004) | 0.675 (∓0.03) |
| ImbTreeAUC | 0.921 (∓0.057) | 0.348 (∓0.09) | 0.819 (∓0.023) | 0.616 (∓0.188) | 0.762 (∓0.004) | 0.702 (∓0.042) |
| C50 | 0.891 (∓0.057) | 0.449 (∓0.119) | 0.839 (∓0.032) | 0.581 (∓0.165) | 0.762 (∓0.004) | 0.679 (∓0.042) |
| Ctree | 0.889 (∓0.047) | 0.422 (∓0.137) | 0.832 (∓0.032) | 0.553 (∓0.112) | 0.762 (∓0.004) | 0.678 (∓0.035) |
| Rpart | 0.919 (∓0.055) | 0.371 (∓0.116) | 0.824 (∓0.029) | 0.616 (∓0.178) | 0.762 (∓0.004) | 0.701 (∓0.041) |
| Liver data | ||||||
| ImbTreeEntropy | 0.909 (∓0.058) | 0.281 (∓0.179) | 0.762 (∓0.044) | 0.552 (∓0.266) | 0.714 (∓0.007) | 0.648 (∓0.04) |
| ImbTreeAUC | 0.834 (∓0.077) | 0.395 (∓0.133) | 0.776 (∓0.034) | 0.511 (∓0.124) | 0.714 (∓0.007) | 0.595 (∓0.054) |
| C50 | 1 (∓0) | 0 (∓0) | 0.714 (∓0.007) | NA (∓NA) | 0.714 (∓0.007) | 0.714 (∓0.007) |
| Ctree | 0.861 (∓0.103) | 0.287 (∓0.242) | 0.756 (∓0.052) | NA (∓NA) | 0.714 (∓0.007) | 0.614 (∓0.073) |
| Rpart | 0.802 (∓0.092) | 0.311 (∓0.134) | 0.745 (∓0.025) | 0.384 (∓0.081) | 0.714 (∓0.007) | 0.573 (∓0.068) |
| Balance scale data | ||||||
| ImbTreeEntropy | 0.579 (∓0.023) | 0.888 (∓0.011) | 0.572 (∓0.024) | 0.893 (∓0.014) | 0.333 (∓0) | 0.265 (∓0.007) |
| ImbTreeAUC | 0.586 (∓0.036) | 0.884 (∓0.014) | 0.588 (∓0.043) | 0.885 (∓0.018) | 0.333 (∓0) | 0.26 (∓0.01) |
| C50 | 0.578 (∓0.033) | 0.876 (∓0.026) | NA (∓NA) | 0.89 (∓0.026) | 0.333 (∓0) | 0.264 (∓0.013) |
| Ctree | 0.572 (∓0.036) | 0.883 (∓0.027) | NA (∓NA) | 0.89 (∓0.03) | 0.333 (∓0) | 0.264 (∓0.017) |
| Rpart | 0.578 (∓0.036) | 0.9 (∓0.017) | 0.599 (∓0.017) | 0.894 (∓0.025) | 0.333 (∓0) | 0.264 (∓0.014) |
| Bioconcentration data | ||||||
| ImbTreeEntropy | 0.514 (∓0.042) | 0.778 (∓0.029) | 0.69 (∓0.128) | 0.799 (∓0.037) | 0.333 (∓0) | 0.225 (∓0.016) |
| ImbTreeAUC | 0.513 (∓0.056) | 0.766 (∓0.044) | 0.567 (∓0.106) | 0.778 (∓0.046) | 0.333 (∓0) | 0.216 (∓0.021) |
| C50 | 0.432 (∓0.041) | 0.747 (∓0.035) | NA (∓NA) | 0.758 (∓0.034) | 0.333 (∓0) | 0.21 (∓0.012) |
| Ctree | 0.553 (∓0.08) | 0.78 (∓0.032) | 0.645 (∓0.098) | 0.79 (∓0.032) | 0.333 (∓0) | 0.222 (∓0.014) |
| Rpart | 0.514 (∓0.043) | 0.778 (∓0.029) | 0.689 (∓0.128) | 0.798 (∓0.037) | 0.333 (∓0) | 0.225 (∓0.016) |
| Hayes–Roth data | ||||||
| ImbTreeEntropy | 0.871 (∓0.062) | 0.913 (∓0.042) | 0.881 (∓0.055) | 0.918 (∓0.038) | 0.333 (∓0) | 0.281 (∓0.025) |
| ImbTreeAUC | 0.822 (∓0.087) | 0.892 (∓0.046) | 0.85 (∓0.064) | 0.899 (∓0.043) | 0.333 (∓0) | 0.268 (∓0.028) |
| C50 | 0.677 (∓0.04) | 0.782 (∓0.032) | NA (∓NA) | 0.842 (∓0.045) | 0.333 (∓0) | 0.204 (∓0.019) |
| Ctree | 0.856 (∓0.055) | 0.903 (∓0.039) | 0.873 (∓0.044) | 0.911 (∓0.031) | 0.333 (∓0) | 0.275 (∓0.024) |
| Rpart | 0.856 (∓0.089) | 0.902 (∓0.061) | NA (∓NA) | 0.928 (∓0.036) | 0.333 (∓0) | 0.274 (∓0.037) |
| Iris data | ||||||
| ImbTreeEntropy | 0.947 (∓0.053) | 0.973 (∓0.026) | 0.955 (∓0.046) | 0.976 (∓0.024) | 0.333 (∓0) | 0.316 (∓0.018) |
| ImbTreeAUC | 0.96 (∓0.047) | 0.98 (∓0.023) | 0.968 (∓0.035) | 0.982 (∓0.02) | 0.333 (∓0) | 0.32 (∓0.016) |
| C50 | 0.96 (∓0.034) | 0.98 (∓0.017) | 0.967 (∓0.029) | 0.982 (∓0.016) | 0.333 (∓0) | 0.32 (∓0.011) |
| Ctree | 0.953 (∓0.055) | 0.977 (∓0.027) | 0.96 (∓0.048) | 0.978 (∓0.026) | 0.333 (∓0) | 0.318 (∓0.018) |
| Rpart | 0.953 (∓0.032) | 0.977 (∓0.016) | 0.961 (∓0.027) | 0.979 (∓0.015) | 0.333 (∓0) | 0.318 (∓0.011) |
| Vertebral column data | ||||||
| ImbTreeEntropy | 0.789 (∓0.061) | 0.921 (∓0.023) | 0.8 (∓0.056) | 0.922 (∓0.025) | 0.333 (∓0) | 0.277 (∓0.017) |
| ImbTreeAUC | 0.77 (∓0.096) | 0.917 (∓0.033) | 0.789 (∓0.1) | 0.919 (∓0.036) | 0.333 (∓0) | 0.274 (∓0.024) |
| C50 | 0.779 (∓0.082) | 0.91 (∓0.039) | 0.79 (∓0.069) | 0.916 (∓0.03) | 0.333 (∓0) | 0.271 (∓0.022) |
| Ctree | 0.798 (∓0.054) | 0.924 (∓0.022) | 0.807 (∓0.063) | 0.926 (∓0.022) | 0.333 (∓0) | 0.278 (∓0.015) |
| Rpart | 0.786 (∓0.072) | 0.916 (∓0.029) | 0.785 (∓0.077) | 0.915 (∓0.03) | 0.333 (∓0) | 0.272 (∓0.021) |
| User knowledge modeling data | ||||||
| ImbTreeEntropy | 0.849 (∓0.099) | 0.956 (∓0.023) | NA (∓NA) | 0.963 (∓0.017) | 0.25 (∓0) | 0.22 (∓0.016) |
| ImbTreeAUC | 0.9 (∓0.036) | 0.968 (∓0.013) | 0.932 (∓0.032) | 0.971 (∓0.012) | 0.25 (∓0) | 0.228 (∓0.009) |
| C50 | 0.92 (∓0.039) | 0.977 (∓0.011) | 0.953 (∓0.024) | 0.979 (∓0.01) | 0.25 (∓0) | 0.234 (∓0.008) |
| Ctree | 0.923 (∓0.045) | 0.975 (∓0.013) | 0.934 (∓0.045) | 0.976 (∓0.014) | 0.25 (∓0) | 0.232 (∓0.01) |
| Rpart | 0.917 (∓0.048) | 0.974 (∓0.015) | 0.943 (∓0.034) | 0.976 (∓0.014) | 0.25 (∓0) | 0.232 (∓0.01) |
| E. coli protein localization data | ||||||
| ImbTreeEntropy | NA (∓NA) | 0.965 (∓0.01) | NA (∓NA) | NA (∓NA) | 0.125 (∓0) | 0.097 (∓0.008) |
| ImbTreeAUC | NA (∓NA) | 0.967 (∓0.008) | NA (∓NA) | NA (∓NA) | 0.125 (∓0) | 0.099 (∓0.008) |
| C50 | NA (∓NA) | 0.97 (∓0.01) | NA (∓NA) | NA (∓NA) | 0.125 (∓0) | 0.101 (∓0.007) |
| Ctree | NA (∓NA) | 0.97 (∓0.009) | NA (∓NA) | NA (∓NA) | 0.125 (∓0) | 0.102 (∓0.007) |
| Rpart | NA (∓NA) | 0.971 (∓0.015) | NA (∓NA) | NA (∓NA) | 0.125 (∓0) | 0.105 (∓0.01) |
| Yeast data | ||||||
| ImbTreeEntropy | NA (∓NA) | 0.943 (∓0.005) | NA (∓NA) | NA (∓NA) | 0.1 (∓0) | 0.058 (∓0.004) |
| ImbTreeAUC | NA (∓NA) | 0.935 (∓0.005) | NA (∓NA) | NA (∓NA) | 0.1 (∓0) | 0.051 (∓0.005) |
| C50 | NA (∓NA) | 0.938 (∓0.011) | NA (∓NA) | NA (∓NA) | 0.1 (∓0) | 0.055 (∓0.007) |
| Ctree | NA (∓NA) | 0.945 (∓0.007) | NA (∓NA) | NA (∓NA) | 0.1 (∓0) | 0.059 (∓0.005) |
| Rpart | NA (∓NA) | 0.943 (∓0.006) | NA (∓NA) | NA (∓NA) | 0.1 (∓0) | 0.058 (∓0.005) |
| Dataset | KNN | NNET | ||||
|---|---|---|---|---|---|---|
| Accuracy | AUC | Kappa | Accuracy | AUC | Kappa | |
| Blood transfusion data | 0.795 (∓0.037) | 0.746 (∓0.061) | 0.320 (∓0.120) | 0.806 (∓0.035) | 0.767 (∓0.062) | 0.357 (∓0.135) |
| Liver data | 0.649 (∓0.072) | 0.465 (∓0.094) | 0.183 (∓0.132) | 0.727 (∓0.054) | 0.273 (∓0.066) | 0.276 (∓0.168) |
| Balance scale data | 0.902 (∓0.011) | 0.877 (∓0.065) | 0.819 (∓0.022) | 0.978 (∓0.010) | 0.997 (∓0.002) | 0.961 (∓0.017) |
| Bioconcentration data | 0.649 (∓0.049) | 0.599 (∓0.087) | 0.312 (∓0.103) | 0.685 (∓0.047) | 0.738 (∓0.071) | 0.374 (∓0.0109) |
| Hayes–Roth data | 0.698 (∓0.087) | 0.777 (∓0.092) | 0.51 (∓0.148) | 0.806 (∓0.116) | 0.955 (∓0.065) | 0.694 (∓0.183) |
| Iris data | 0.967 (∓0.035) | 0.999 (∓0.003) | 0.950 (∓0.053) | 0.973 (∓0.034) | 0.997 (∓0.006) | 0.960 (∓0.052) |
| Vertebral column data | 0.794 (∓0.065) | 0.896 (∓0.043) | 0.668 (∓0.104) | 0.871 (∓0.070) | 0.949 (∓0.035) | 0.793 (∓0.112) |
| User knowledge modeling data | 0.878 (∓0.067) | 0.956 (∓031) | 0.831 (∓0.094) | 0.960 (∓0.029) | 0.995 (∓0.006) | 0.945 (∓0.040) |
| E. coli protein localization data | 0.872 (∓0.040) | 0.908 (∓0.078) | 0.823 (∓0.054) | 0.887 (∓0.026) | 0.950 (∓0.040) | 0.843 (∓0.034) |
| Yeast data | 0.597 (∓0.049) | 0.826 (∓0.050) | 0.472 (∓0.064) | 0.613 (∓0.033) | 0.856 (∓0.040) | 0.495 (∓0.041) |
References
- Rout, N.; Mishra, D.; Mallick, M.K. Handling Imbalanced Data: A Survey. Int. Proc. Adv. Soft Comput. Intell. Syst. Appl. 2017, 431–443. [Google Scholar] [CrossRef]
- Wang, S.; Yao, X. Multiclass Imbalance Problems: Analysis and Potential Solutions. IEEE Trans. Syst. Mancybern. Part B (Cybern.) 2012, 42, 1119–1130. [Google Scholar] [CrossRef]
- Lakshmi, T.J.; Prasad, C.S.R. A study on classifying imbalanced datasets. In Proceedings of the First International Conference on Networks & Soft Computing (ICNSC2014), Guntur, India, 19–20 August 2014. [Google Scholar] [CrossRef]
- Leevy, J.L.; Khoshgoftaar, T.M.; Bauder, R.A.; Seliya, N. A survey on addressing high-class imbalance in big data. J. Big Data 2018, 5. [Google Scholar] [CrossRef]
- Quinlan, J.R. Induction of decision trees. Mach. Learn. 1986, 1, 81–106. [Google Scholar] [CrossRef] [Green Version]
- Breiman, L.; Friedman, J.H.; Olshen, R.A.; Stone, C.J. Classification and Regression Trees; Wadsworth Statistics/Probability Series; CRC Press: Boca Raton, FL, USA, 1984. [Google Scholar] [CrossRef] [Green Version]
- Kass, G.V. An Exploratory Technique for Investigating Large Quantities of Categorical Data. Appl. Stat. 1980, 29, 119. [Google Scholar] [CrossRef]
- Available online: https://archive.ics.uci.edu/ml/index.php (accessed on 10 October 2020).
- Galar, M.; Fernandez, A.; Barrenechea, E.; Bustince, H.; Herrera, F. A Review on Ensembles for the Class Imbalance Problem: Bagging-, Boosting-, and Hybrid-Based Approaches. IEEE Trans. Syst. Mancybern. Part C (Appl. Rev.) 2012, 42, 463–484. [Google Scholar] [CrossRef]
- Pérez-Godoy, M.D.; Rivera, A.J.; Carmona, C.J.; del Jesus, M.J. Training algorithms for Radial Basis Function Networks to tackle learning processes with imbalanced data-sets. Appl. Soft Comput. 2014, 25, 26–39. [Google Scholar] [CrossRef]
- Sáez, J.A.; Luengo, J.; Stefanowski, J.; Herrera, F. SMOTE–IPF: Addressing the noisy and borderline examples problem in imbalanced classification by a re-sampling method with filtering. Inf. Sci. 2015, 291, 184–203. [Google Scholar] [CrossRef]
- Błaszczyński, J.; Stefanowski, J. Neighbourhood sampling in bagging for imbalanced data. Neurocomputing 2015, 150, 529–542. [Google Scholar] [CrossRef]
- Majid, A.; Ali, S.; Iqbal, M.; Kausar, N. Prediction of human breast and colon cancers from imbalanced data using nearest neighbor and support vector machines. Comput. Methods Programs Biomed. 2014, 113, 792–808. [Google Scholar] [CrossRef] [PubMed]
- Maratea, A.; Petrosino, A.; Manzo, M. Adjusted F-measure and kernel scaling for imbalanced data learning. Inf. Sci. 2014, 257, 331–341. [Google Scholar] [CrossRef]
- Maldonado, S.; López, J. Imbalanced data classification using second-order cone programming support vector machines. Pattern Recognit. 2014, 47, 2070–2079. [Google Scholar] [CrossRef]
- Datta, S.; Das, S. Near-Bayesian Support Vector Machines for imbalanced data classification with equal or unequal misclassification costs. Neural Netw. 2015, 70, 39–52. [Google Scholar] [CrossRef] [PubMed]
- Alibeigi, M.; Hashemi, S.; Hamzeh, A. DBFS: An effective Density Based Feature Selection scheme for small sample size and high dimensional imbalanced data sets. Data Knowl. Eng. 2012, 81–82, 67–103. [Google Scholar] [CrossRef]
- Domingos, P. MetaCost. In Proceedings of the Fifth ACM SIGKDD International Conference on Knowledge Discovery and Data Mining—KDD ‘99, San Diego, CA, USA, 12–18 August 1999. [Google Scholar] [CrossRef]
- Thai-Nghe, N.; Gantner, Z.; Schmidt-Thieme, L. Cost-sensitive learning methods for imbalanced data. In Proceedings of the 2010 International Joint Conference on Neural Networks (IJCNN), Barcelona, Spain, 18–23 July 2010. [Google Scholar] [CrossRef] [Green Version]
- Gajowniczek, K.; Ząbkowski, T.; Sodenkamp, M. Revealing Household Characteristics from Electricity Meter Data with Grade Analysis and Machine Learning Algorithms. Appl. Sci. 2018, 8, 1654. [Google Scholar] [CrossRef] [Green Version]
- Gajowniczek, K.; Nafkha, R.; Ząbkowski, T. Electricity peak demand classification with artificial neural networks. In Proceedings of the 2017 Federated Conference on Computer Science and Information Systems, Prague, Czech Republic, 3–6 September 2017. [Google Scholar] [CrossRef] [Green Version]
- Gajowniczek, K.; Orłowski, A.; Ząbkowski, T. Entropy Based Trees to Support Decision Making for Customer Churn Management. Acta Phys. Pol. A 2016, 129, 971–979. [Google Scholar] [CrossRef]
- Elkan, C. The foundations of cost-sensitive learning. In Proceedings of the International Joint Conference on Artificial Intelligence, Seattle, WA, USA, 4–10 August 2001; Lawrence Erlbaum Associates Ltd.: Mahwah, NJ, USA, 2001; Volume 17, pp. 973–978. [Google Scholar]
- Zadrozny, B.; Langford, J.; Abe, N. Cost-sensitive learning by cost-proportionate example weighting. In Proceedings of the Third IEEE International Conference on Data Mining, Melbourne, FL, USA, 19–22 November 2003. [Google Scholar] [CrossRef] [Green Version]
- Buntine, W. Learning classification trees. Artif. Intell. Front. Stat. 1993, 182–201. [Google Scholar] [CrossRef] [Green Version]
- Taylor, P.C.; Silverman, B.W. Block diagrams and splitting criteria for classification trees. Stat. Comput. 1993, 3, 147–161. [Google Scholar] [CrossRef]
- Mola, F.; Siciliano, R. A fast splitting procedure for classification trees. Stat. Comput. 1997, 7, 209–216. [Google Scholar] [CrossRef]
- Kearns, M.; Mansour, Y. On the Boosting Ability of Top–Down Decision Tree Learning Algorithms. J. Comput. Syst. Sci. 1999, 58, 109–128. [Google Scholar] [CrossRef]
- Rokach, L.; Maimon, O. Decision trees. In Data Mining and Knowledge Discovery Handbook; Springer: Boston, MA, USA, 2005; pp. 165–192. [Google Scholar]
- Fayyad, U.M.; Irani, K.B. The Attribute Selection Problem in Decision Tree Generation; AAAI Press: Palo Alto, CA, USA, 1992; pp. 104–110. [Google Scholar]
- Rounds, E.M. A combined nonparametric approach to feature selection and binary decision tree design. Pattern Recognit. 1980, 12, 313–317. [Google Scholar] [CrossRef]
- Ferri, C.; Flach, P.; Hernández-Orallo, J. Learning decision trees using the area under the ROC curve. In Conference: Machine Learning. In Proceedings of the Nineteenth International Conference (ICML 2002), University of New South Wales, Sydney, Australia, 8–12 July 2002. [Google Scholar]
- Gajowniczek, K.; Liang, Y.; Friedman, T.; Ząbkowski, T.; Van den Broeck, G. Semantic and Generalized Entropy Loss Functions for Semi-Supervised Deep Learning. Entropy 2020, 22, 334. [Google Scholar] [CrossRef] [Green Version]
- Nafkha, R.; Gajowniczek, K.; Ząbkowski, T. Do Customers Choose Proper Tariff? Empirical Analysis Based on Polish Data Using Unsupervised Techniques. Energies 2018, 11, 514. [Google Scholar] [CrossRef] [Green Version]
- Sharma, B.D.; Mittal, B.D. Development of a pressure chemical doser. J. Inst. Eng. Public Health Eng. Div. 1975, 56, 28–32. [Google Scholar]
- Masi, M. A step beyond Tsallis and Rényi entropies. Phys. Lett. A 2005, 338, 217–224. [Google Scholar] [CrossRef] [Green Version]
- Sharma, B.D.; Taneja, I.J. Entropy of type (α, β) and other generalized measures in information theory. Metrika 1975, 22, 205–215. [Google Scholar] [CrossRef]
- Kapur, J.N. Some Properties of Entropy of Order α and Type β; Springer: New Delhi, India, 1969; Volume 69, No. 4; pp. 201–211. [Google Scholar]
- Mann, H.B.; Whitney, D.R. On a Test of Whether one of Two Random Variables is Stochastically Larger than the Other. Ann. Math. Stat. 1947, 18, 50–60. [Google Scholar] [CrossRef]
- Hand, D.J.; Till, R.J. A Simple Generalisation of the Area Under the ROC Curve for Multiple Class Classification Problems. Mach. Learn. 2001, 45, 171–186. [Google Scholar] [CrossRef]
- O’Brien, D.B.; Gupta, M.R.; Gray, R.M. Cost-sensitive multi-class classification from probability estimates. In Proceedings of the 25th International Conference on Machine Learning—ICML, Helsinki, Finland, 5–9 July 2008. [Google Scholar] [CrossRef] [Green Version]
- Ling, C.X.; Sheng, V.S. Cost-Sensitive Learning. Encycl. Mach. Learn. Data Min. 2017, 285–289. [Google Scholar] [CrossRef]
- Xiang, Y.; Gubian, S.; Suomela, B.; Hoeng, J. Generalized Simulated Annealing for Global Optimization: The GenSA Package. R. J. 2013, 5, 13. [Google Scholar] [CrossRef] [Green Version]
- Wright, M.N.; König, I.R. Splitting on categorical predictors in random forests. PeerJ 2019, 7, e6339. [Google Scholar] [CrossRef] [PubMed]
- Fisher, W.D. On Grouping for Maximum Homogeneity. J. Am. Stat. Assoc. 1958, 53, 789–798. [Google Scholar] [CrossRef]
- Mehta, M.; Agrawal, R.; Rissanen, J. SLIQ: A fast scalable classifier for data mining. Lect. Notes Comput. Sci. 1996, 18–32. [Google Scholar] [CrossRef]
- Gnanadesikan, R. Methods for Statistical Data Analysis of Multivariate Observations; John Wiley & Sons: New York, NY, USA, 2011; Volume 321. [Google Scholar]
- Coppersmith, D.; Hong, S.J.; Hosking, J.R. Partitioning nominal attributes in decision trees. Data Min. Knowl. Discov. 1999, 3, 197–217. [Google Scholar] [CrossRef]
- Yeh, I.C.; Yang, K.J.; Ting, T.M. Knowledge discovery on RFM model using Bernoulli sequence. Expert Syst. Appl. 2009, 36, 5866–5871. [Google Scholar] [CrossRef]
- Ramana, B.V.; Babu, M.S.P.; Venkateswarlu, N.B. A critical comparative study of liver patients from USA and INDIA: An exploratory analysis. Int. J. Comput. Sci. Issues 2012, 9, 506–516. [Google Scholar]
- Klahr, D.; Siegler, R.S. The representation of children’s knowledge. Adv. Child Dev. Behav. 1978, 12, 61–116. [Google Scholar]
- Grisoni, F.; Consonni, V.; Vighi, M.; Villa, S.; Todeschini, R. Investigating the mechanisms of bioconcentration through QSAR classification trees. Env. Int. 2016, 88, 198–205. [Google Scholar] [CrossRef]
- Hayes-Roth, B.; Hayes-Roth, F. Concept learning and the recognition and classification of exemplars. J. Verbal Learn. Verbal Behav. 1977, 16, 321–338. [Google Scholar] [CrossRef]
- Duda, R.O.; Hart, P.E.; Stork, D.G. Pattern Classification. J. Classif. 2001, 24, 305–307. [Google Scholar] [CrossRef]
- Rocha Neto, A.R.; Alencar Barreto, G. On the application of ensembles of classifiers to the diagnosis of pathologies of the vertebral column: A comparative analysis. IEEE Lat. Am. Trans. 2009, 7, 487–496. [Google Scholar] [CrossRef]
- Kahraman, H.T.; Sagiroglu, S.; Colak, I. The development of intuitive knowledge classifier and the modeling of domain dependent data. Knowl. Based Syst. 2013, 37, 283–295. [Google Scholar] [CrossRef]
- Horton, P.; Nakai, K. A probabilistic classification system for predicting the cellular localization sites of proteins. ISMB 1996, 4, 109–115. [Google Scholar] [PubMed]
- Nakai, K.; Kanehisa, M. A knowledge base for predicting protein localization sites in eukaryotic cells. Genomics 1992, 14, 897–911. [Google Scholar] [CrossRef]
- Fawcett, T. Introduction to ROC analysis. Pattern Recognit. Lett. 2008, 27, 861–874. [Google Scholar] [CrossRef]
- Cohen, J. A Coefficient of Agreement for Nominal Scales. Educ. Psychol. Meas. 1960, 20, 37–46. [Google Scholar] [CrossRef]


| Data Set Name | Reference | Number of Observations | Number of Classes | Class Distribution |
|---|---|---|---|---|
| Blood transfusion | [49] | 748 | 2 | 23.8–76.2% |
| Liver | [50] | 583 | 2 | 28.6–71.4% |
| Balance scale | [51] | 625 | 3 | 7.8–46.1–46.1% |
| Bioconcentration | [52] | 779 | 3 | 8.2–32.7–59.1% |
| Hayes-Roth | [53] | 160 | 3 | 19.4–40.0–40.6% |
| Iris | [54] | 150 | 3 | 33.(3)–33.(3)–33.(3)% |
| Vertebral column | [55] | 310 | 3 | 19.3–32.3–48.4% |
| User Knowledge Modeling | [56] | 403 | 4 | 12.4–25.3–30.3–32.0% |
| E. coli protein localization | [57] | 336 | 8 | 0.6–0.6–1.5–5.9% |
| 10.4–15.5–22.9–42.6% | ||||
| Yeast | [58] | 1484 | 10 | 0.3–1.4–2.0–2.4–3.0–3.4–11.0–16.4–28.9–31.2% |
| Features | Packages | |||
|---|---|---|---|---|
| ImbTreeEntropy & ImbTreeAUC | Rpart | C5.0 | CTree/party | |
| Impurity measure | ImbTreeEntropy (Shannon, Rényi, Tsallis, Sharma–Mittal, Sharma–Taneja, Kapura) | Gini index | Shannon entropy | - |
| ImbTreeAUC (local AUC, semi-global AUC, global AUC) | ||||
| Cost sensitive classification | Yes | Yes | Yes | No |
| Weight sensitive classification | Yes | Yes | Yes | Yes |
| Parallel processing | Yes | No | No | No |
| Pruning method | During growing, after growing | During growing | After growing | No |
| Threshold optimization | Yes | No | No | No |
| Data Set Name | Metrics | Algorithm | ||||
|---|---|---|---|---|---|---|
| ImbTreeEntropy | ImbTreeAUC | C50 | Ctree | Rpart | ||
| Blood transfusion | NLeaves | 7.0 (∓2.309) | 4.0 (∓0.000) | 5.8 (∓1.476) | 4.9 (∓0.316) | 4.0 (∓0.000) |
| NClass | 2.0 (∓0.000) | 2.0 (∓0.000) | 2.0 (∓0.000) | 2.0 (∓0.000) | 2.0 (∓0.000) | |
| Liver | NLeaves | 7.2 (∓3.084) | 11.7 (∓2.312) | 18.1 (∓10.300) | 2.0 (∓0.000) | 45.3 (∓7.875) |
| NClass | 2.0 (∓0.000) | 2.0 (∓0.000) | 1.8 (∓0.422) | 1.0 (∓0.000) | 2.0 (∓0.000) | |
| Balance scale | NLeaves | 39.9 (∓2.470) | 34.1 (∓1.792) | 42.8 (∓6.321) | 17.1 (∓2.079) | 126.8 (∓5.116) |
| NClass | 3.0 (∓0.000) | 3.0 (∓0.000) | 3.0 (∓0.000) | 2.6 (∓0.516) | 3.0 (∓0.000) | |
| Bioconcentration | NLeaves | 13.8 (∓1.033) | 16.2 (∓2.658) | 52.6 (∓13.418) | 2.0 (∓0.000) | 13.6 (∓0.966) |
| NClass | 3.0 (∓0.000) | 3.0 (∓0.000) | 3.0 (∓0.000) | 2.0 (∓0.000) | 3.0 (∓0.000) | |
| Hayes-Roth | NLeaves | 12.8 (∓0.632) | 12.0 (∓1.414) | 11.1 (∓0.568) | 4.0 (∓0.943) | 9.0 (∓0.000) |
| NClass | 3.0 (∓0.000) | 3.0 (∓0.000) | 3.0 (∓0.000) | 2.4 (∓0.516) | 3.0 (∓0.000) | |
| Iris | NLeaves | 3.0 (∓0.000) | 3.9 (∓0.316) | 4.1 (∓0.316) | 3.3 (∓0.483) | 4.0 (∓0.000) |
| NClass | 3.0 (∓0.000) | 3.0 (∓0.000) | 3.0 (∓0.000) | 3.0 (∓0.000) | 3.0 (∓0.000) | |
| Vertebral column | NLeaves | 5.5 (∓0.85) | 8.7 (∓0.675) | 11.5 (∓2.369) | 5.6 (∓0.699) | 4.1 (∓0.316) |
| NClass | 3.0 (∓0.000) | 3.0 (∓0.000) | 3.0 (∓0.000) | 3.0 (∓0.000) | 3.0 (∓0.000) | |
| User Knowledge Modeling | NLeaves | 8.8 (∓0.422) | 7.0 (∓1.054) | 13.9 (∓1.792) | 8.8 (∓1.033) | 12.0 (∓1.418) |
| NClass | 4.0 (∓0.000) | 4.0 (∓0.000) | 4.0 (∓0.000) | 4.0 (∓0.000) | 4.0 (∓0.000) | |
| E. coli protein localization | NLeaves | 19.7 (∓1.947) | 18.5 (∓1.434) | 13.7 (∓2.359) | 8.2 (∓1.033) | 12.9 (∓0.876) |
| NClass | 7.5 (∓0.527) | 8.0 (∓0.000) | 6.0 (∓0.000) | 6.7 (∓0.483) | 5.7 (∓0.823) | |
| Yeast | NLeaves | 58.4 (∓4.45) | 18.8 (∓1.304) | 93.4 (∓13.091) | 14.1 (∓5.152) | 15.4 (∓2.503) |
| NClass | 10.0 (∓0.000) | 9.6 (∓0.548) | 9.9 (∓0.316) | 8.0 (∓1.633) | 7.9 (∓0.316) | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gajowniczek, K.; Ząbkowski, T. ImbTreeEntropy and ImbTreeAUC: Novel R Packages for Decision Tree Learning on the Imbalanced Datasets. Electronics 2021, 10, 657. https://doi.org/10.3390/electronics10060657
Gajowniczek K, Ząbkowski T. ImbTreeEntropy and ImbTreeAUC: Novel R Packages for Decision Tree Learning on the Imbalanced Datasets. Electronics. 2021; 10(6):657. https://doi.org/10.3390/electronics10060657
Chicago/Turabian StyleGajowniczek, Krzysztof, and Tomasz Ząbkowski. 2021. "ImbTreeEntropy and ImbTreeAUC: Novel R Packages for Decision Tree Learning on the Imbalanced Datasets" Electronics 10, no. 6: 657. https://doi.org/10.3390/electronics10060657