
Sentiment-Target Word Pair Extraction Model Using Statistical Analysis of Sentence Structures


Abstract
:1. Introduction
2. Related Works
3. Materials and Methods
3.1. Sentence Structure Analysis
3.2. Extraction of Word Pairs
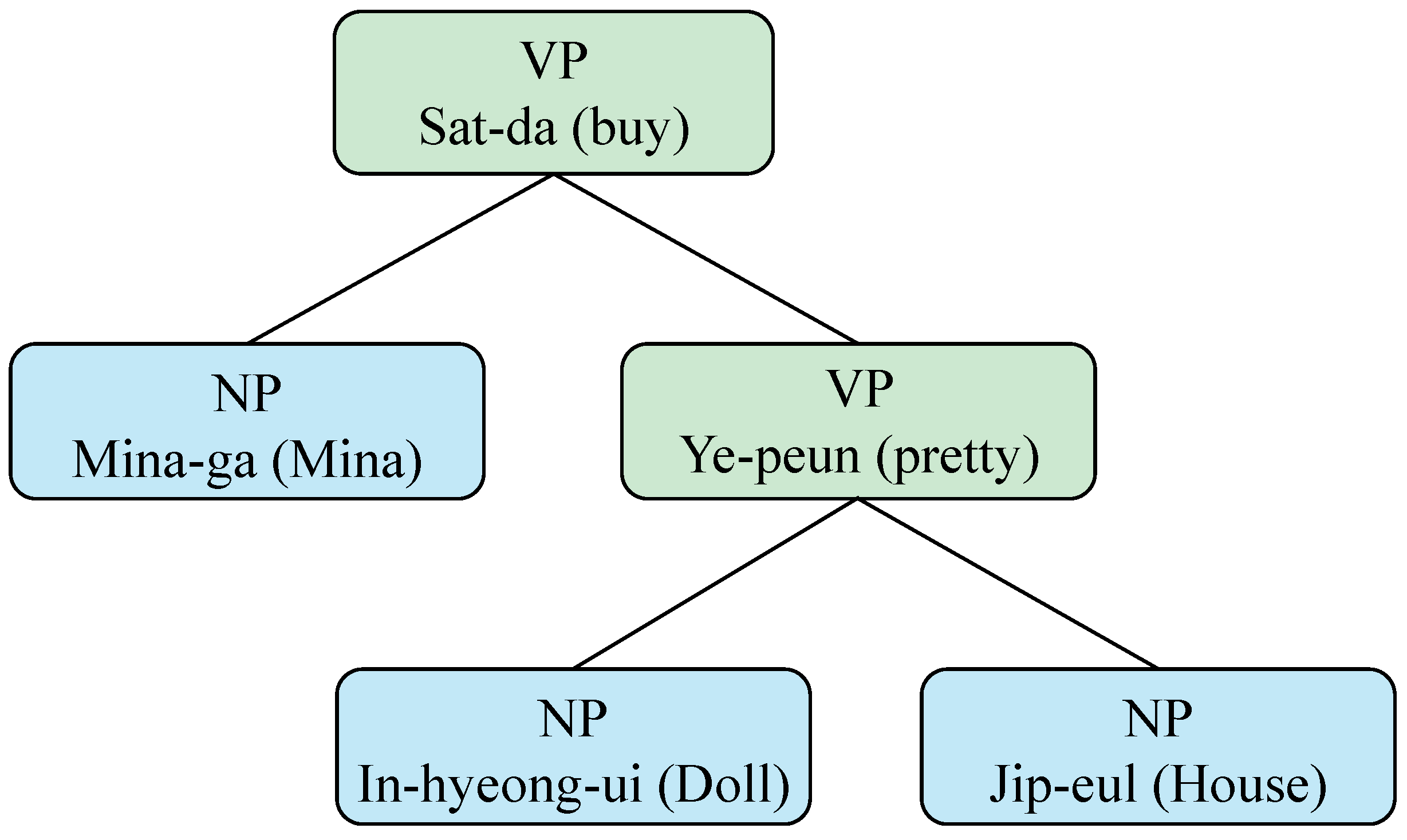
- Step 1: Select the node with the highest dependence in the parse tree (generally, root node).
- Step 2: Register as target word candidates the two nodes close to the root node.
- Step 3: Calculate the distance information with the selected node word from the two candidates, co-concurrence information of words, and co-concurrence information of parts-of-speech.
- Step 4: Select the candidate with higher calculated dependency strength from the two candidates.
- Step 5: Extract the selected two nodes into sentiment word and target word.
- Step 6: If the parse tree can be turned into a sub-tree, then proceed to turn it into a sub-tree and repeat the above steps.
- Dependency strength (“Mina”) = 3 × 2000 × 100,000;
- Dependency strength (“pretty”) = 4 × 4000 × 5000.
4. Experiment And Results
4.1. Evaluation Metric
4.2. Experimental Results
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Conflicts of Interest
References
- Lipsman, A. Online Consumer-Generated Reviews Have Significant Impact on Offline Purchase Behavior; Comscore, Inc. Industry Analysis: Reston, VA, USA, 2007; pp. 2–28. [Google Scholar]
- Horrigan, J.B. Internet Users Like the Convenience but Worry About the Security of Their Financial Information; PEW Internet & American Life Project: Washington, DC, USA, 2008; pp. 1–32. [Google Scholar]
- Bakshi, R.K.; Kaur, N.; Kaur, R.; Kaur, G. Opinion mining and sentiment analysis. In Proceedings of the 2016 3rd International Conference on Computing for Sustainable Global Development (INDIACom), New Delhi, India, 16–18 March 2016; pp. 452–455. [Google Scholar]
- Devika, M.; Sunitha, C.; Ganesh, A. Sentiment analysis: A comparative study on different approaches. Procedia Comput. Sci. 2016, 87, 44–49. [Google Scholar] [CrossRef] [Green Version]
- Sadredini, E.; Guo, D.; Bo, C.; Rahimi, R.; Skadron, K.; Wang, H. A scalable solution for rule-based part-of-speech tagging on novel hardware accelerators. In Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, London, UK, 19–23 August 2018; pp. 665–674. [Google Scholar]
- Kang, H.; Yoo, S.; Han, D. Design and Implementation of System for Classifying Review of Product Attribute to Positive/Negative. In Proceedings of the 36th KIISE Fall Conference, Boston, MA, USA, 2–7 August 2009; Volume 36, pp. 1–6. [Google Scholar]
- Jiang, L.; Yu, M.; Zhou, M.; Liu, X.; Zhao, T. Target-dependent twitter sentiment classification. In Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics: Human Language Technologies, Portland, OR, USA, 19–24 June 2011; pp. 151–160. [Google Scholar]
- Liu, B. Web Data Mining: Exploring Hyperlinks, Contents, and Usage Data; Springer: Berlin/Heidelberg, Germany, 2011; Volume 1. [Google Scholar]
- Liu, B.; Hu, M.; Cheng, J. Opinion observer: Analyzing and comparing opinions on the web. In Proceedings of the 14th International Conference on World Wide Web, Chiba, Japan, 10–14 May 2005; pp. 342–351. [Google Scholar]
- Popescu, A.M.; Etzioni, O. Extracting product features and opinions from reviews. In Natural Language Processing and Text Mining; Springer: Berlin/Heidelberg, Germany, 2007; pp. 9–28. [Google Scholar]
- Smith, G.G.; Haworth, R.; Žitnik, S. Computer science meets education: Natural language processing for automatic grading of open-ended questions in ebooks. J. Educ. Comput. Res. 2020, 58, 1227–1255. [Google Scholar] [CrossRef]
- Emadi, M.; Rahgozar, M. Twitter sentiment analysis using fuzzy integral classifier fusion. J. Inf. Sci. 2020, 46, 226–242. [Google Scholar] [CrossRef]
- Wen, S.; Wan, X. Emotion classification in microblog texts using class sequential rules. In Proceedings of the Twenty-Eighth AAAI Conference on Artificial Intelligence, Québec City, QC Canada, 27–31 July 2014. [Google Scholar]
- Yang, J.y.; Myung, J.S.; Lee, S.G. A sentiment classification method using context information in product review summarization. J. KIISE Databases 2009, 36, 254–262. [Google Scholar]
- Joshi, A.; Prabhu, A.; Shrivastava, M.; Varma, V. Towards sub-word level compositions for sentiment analysis of hindi-english code mixed text. In Proceedings of the Coling 2016, the 26th International Conference on Computational Linguistics: Technical Papers, Osaka, Japan, 11–16 December 2016; pp. 2482–2491. [Google Scholar]
- Van De Mieroop, D.; Miglbauer, M.; Chatterjee, A. Mobilizing master narratives through categorical narratives and categorical statements when default identities are at stake. Discourse Commun. 2017, 11, 179–198. [Google Scholar] [CrossRef]
- Lee, S.; Potter, R.F. The impact of emotional words on listeners’ emotional and cognitive responses in the context of advertisements. Commun. Res. 2020, 47, 1155–1180. [Google Scholar] [CrossRef] [Green Version]
- Jindal, N.; Liu, B. Mining comparative sentences and relations. AAAI 2006, 22, 9. [Google Scholar]
- Zhao, N.; Wu, M.; Chen, J. Android-based mobile educational platform for speech signal processing. Int. J. Electr. Eng. Educ. 2017, 54, 3–16. [Google Scholar] [CrossRef]
- Farooq, U.; Mansoor, H.; Nongaillard, A.; Ouzrout, Y.; Qadir, M.A. Negation Handling in Sentiment Analysis at Sentence Level. J. Comput. 2017, 12, 470–478. [Google Scholar] [CrossRef]
- Kim, J.D.; Lim, H.S.; Rim, H.C. Twoply hidden Markov model: A Korean POS tagging model based on morpheme-unit with Eojeol-unit context. In Proceedings of the 1997 International Conference on Computer Processing of Oriental Languages, Ulm, Germany, 18–20 August 1997; pp. 144–148. [Google Scholar]
- DeRose, S.J. Stochastic Methods for Resolution of Grammatical Category Ambiguity in Inflected and Uninflected Languages; Brown University: Providence, RI, USA, 1989. [Google Scholar]
- Kim, Y.; Dyer, C.; Rush, A.M. Compound probabilistic context-free grammars for grammar induction. arXiv 2019, arXiv:1906.10225. [Google Scholar]
- Raghavan, S.; Kovashka, A.; Mooney, R. Authorship attribution using probabilistic context-free grammars. In Proceedings of the ACL 2010 Conference Short Papers, Uppsala, Sweden, 11–16 July 2010; pp. 38–42. [Google Scholar]
- Charniak, E. Immediate-head parsing for language models. In Proceedings of the 39th Annual Meeting of the Association for Computational Linguistics, Toulouse, France, 6–11 July 2001; pp. 124–131. [Google Scholar]
- Massung, S.; Zhai, C.; Hockenmaier, J. Structural parse tree features for text representation. In Proceedings of the 2013 IEEE Seventh International Conference on Semantic Computing, Irvine, CA, USA, 16–18 September 2013; pp. 9–16. [Google Scholar]
- Liu, Z.; Chen, G. Remote sensing image landmark segmentation algorithm based on improved GSA and PCNN combination. Int. J. Electr. Eng. Educ. 2020. [Google Scholar] [CrossRef]
- Yu, S.E.; Kim, D. Landmark vectors with quantized distance information for homing navigation. Adapt. Behav. 2011, 19, 121–141. [Google Scholar] [CrossRef]
- Brunellière, A.; Perre, L.; Tran, T.; Bonnotte, I. Co-occurrence frequency evaluated with large language corpora boosts semantic priming effects. Q. J. Exp. Psychol. 2017, 70, 1922–1934. [Google Scholar] [CrossRef] [PubMed]
- Li, Y.; Jin, Q.; Zuo, M.; Li, H.; Yang, X.; Zhang, Q.; Liu, X. Multi-neural network-based sentiment analysis of food reviews based on character and word embeddings. Int. J. Electr. Eng. Educ. 2020. [Google Scholar] [CrossRef]


{kind=link}
| My SLR is on the shelf |
| by camerafun4. Aug 09’04 |
| Pros: Great photos, easy to use, very small |
| Cons: Battery usage; included memory is stingy. |
| I had never used a digital camera prior to purchasing this Canon A70. I have … |
| Read the full review |
| great photos -> 〈photo〉 |
| easy to use -> 〈use〉 |
| very small -> 〈small〉 ⇒ 〈size〉 |
| Korean POS | English POS |
|---|---|
| Mina-ga | Mina: personal pronoun, ga: a subjective case |
| Ye-peun | pretty: adjective |
| In-hyeong-ui | In-hyeong: doll, ui: a noun modifier |
| Jip-eul | Jip: house, eul: an objective case |
| Sat-da | Sat: buy, da: a finishing final ending |
| Sentiment Word | Target Word |
|---|---|
| Buy | House |
| Buy | Doll |
| Buy | Mina |
| Pretty | House |
| Pretty | Doll |
| Pretty | Mina |
| Models | Accuracy | Recall | Precision | F1-Score (%) |
|---|---|---|---|---|
| Long Jiang’s Model | 78.80 | 76.27 | 81.89 | 78.98 |
| Proposed Model | 93.25 (+14.45) | 75.92 (−0.35) | 89.84 (+7.95) | 82.29 (+3.31) |
| Example 1 | Example 2 | |
|---|---|---|
| Original Sentence | Of the recent movies seen, this is most fun | Movie that doesn’t quite satisfy |
| Accurate Analysis | Movie-is fun | Movie-not satisfying |
| System Analysis | Movie-is fun | - |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jo, J.; Kim, G.; Park, K. Sentiment-Target Word Pair Extraction Model Using Statistical Analysis of Sentence Structures. Electronics 2021, 10, 3187. https://doi.org/10.3390/electronics10243187
Jo J, Kim G, Park K. Sentiment-Target Word Pair Extraction Model Using Statistical Analysis of Sentence Structures. Electronics. 2021; 10(24):3187. https://doi.org/10.3390/electronics10243187
Chicago/Turabian StyleJo, Jaechoon, Gyeongmin Kim, and Kinam Park. 2021. "Sentiment-Target Word Pair Extraction Model Using Statistical Analysis of Sentence Structures" Electronics 10, no. 24: 3187. https://doi.org/10.3390/electronics10243187