
Attention Enhanced Serial Unet++ Network for Removing Unevenly Distributed Haze


Abstract
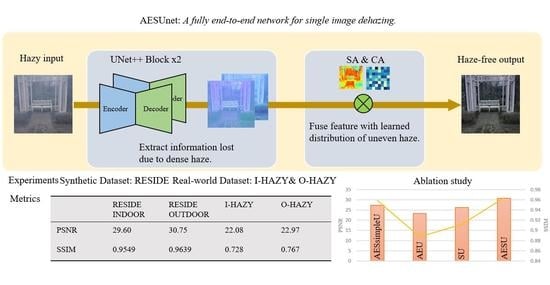
:
1. Introduction
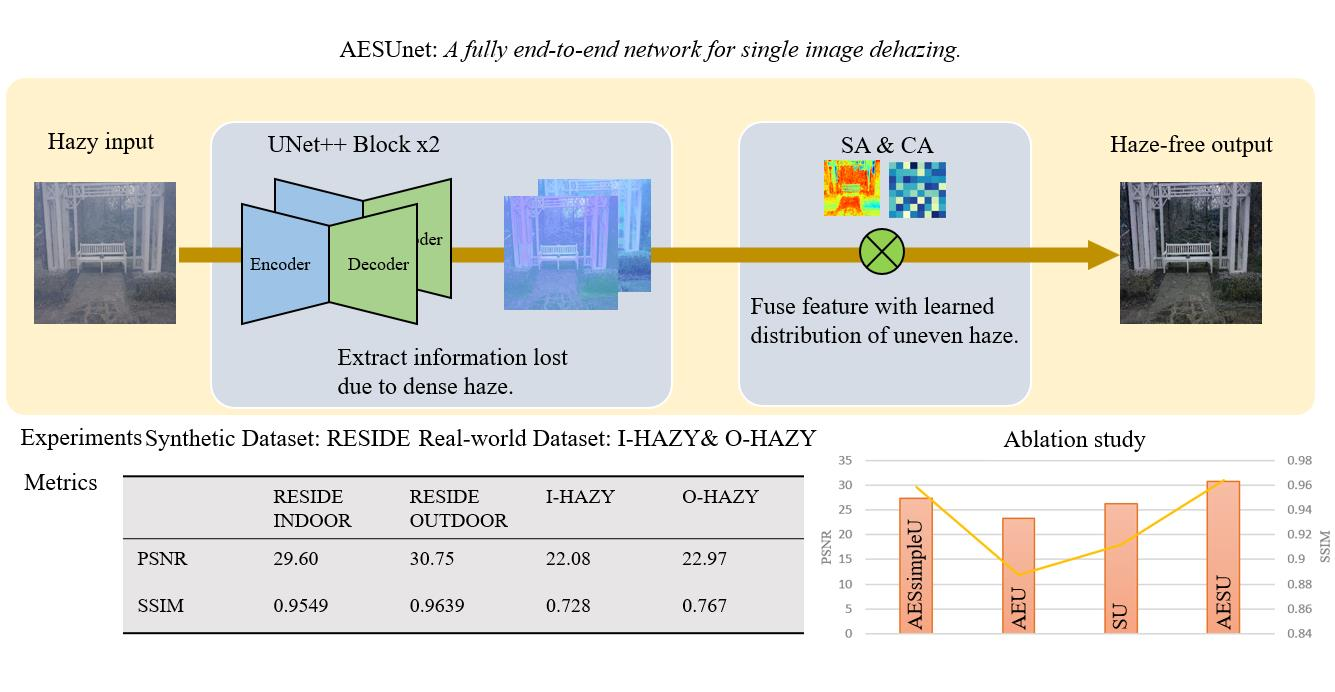
- We propose a novel end-to-end attention enhanced serial Unet++ dehazing network. The serial Unet++ module extracts features in different resolutions and effectively fuses them to restore thick hazy images. An attention mechanism is introduced to pay different levels of attention to haze regions with different concentrations;
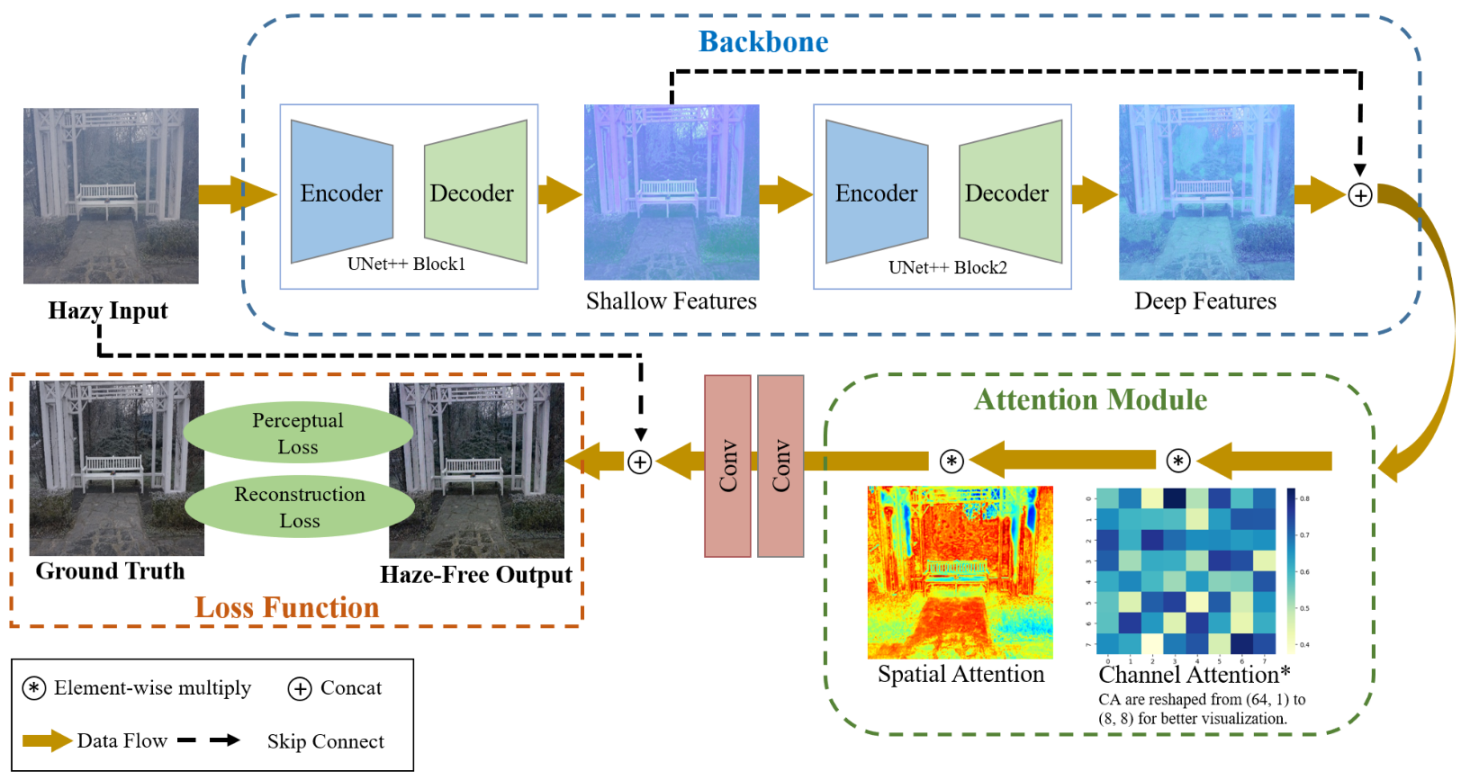
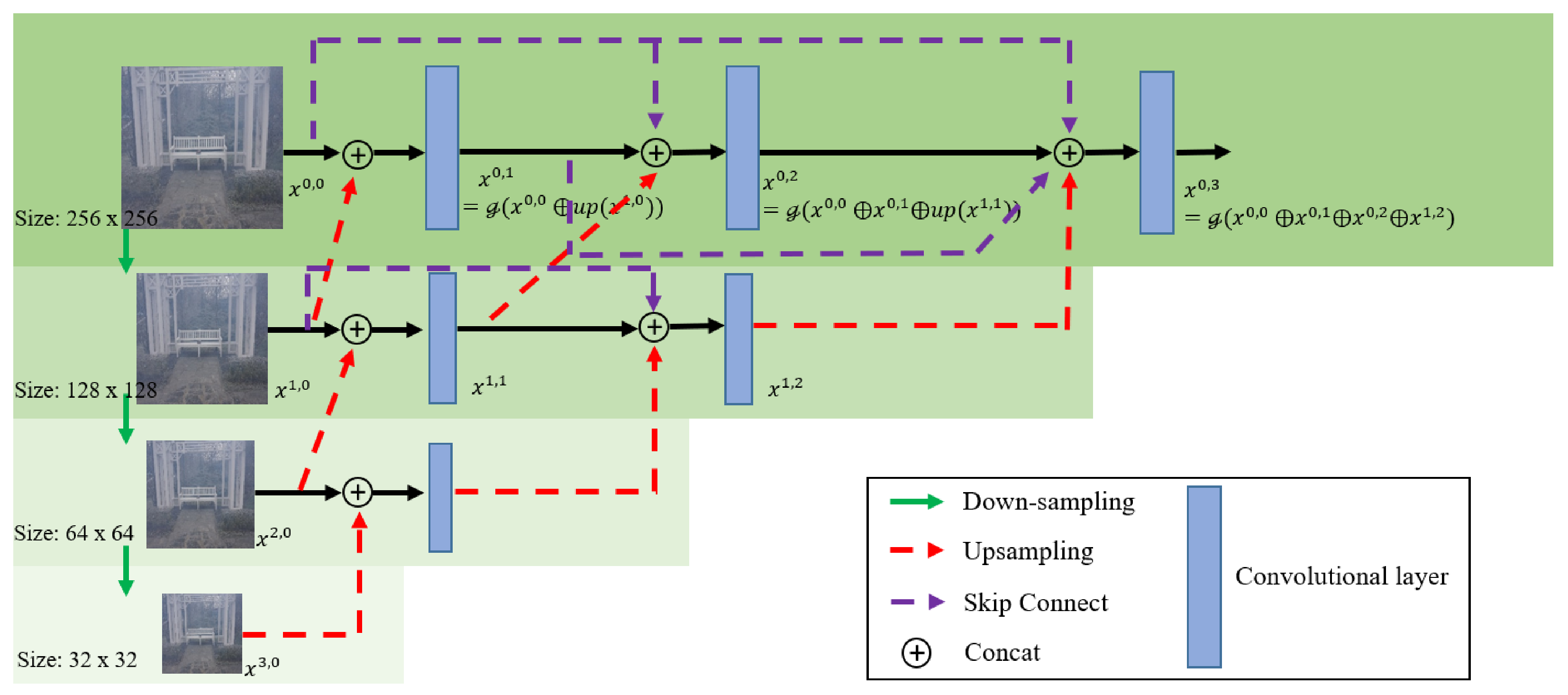
- We build a serial Unet++ structure that is responsible for fully extracting features of different resolutions and reconstructing them on different scales. The serial Unet++ structure directly transmits the original information of the shallow layers to the subsequent deeper layers, so that the deeper layers focus on residual learning while reusing shallow contextual information. Thus, the structure can not only avoid the degradation of the model, but also fuse shallow contextual information into deep features, which contributes to generating more realistic images with less color distortion in the faces of dense daze regions;
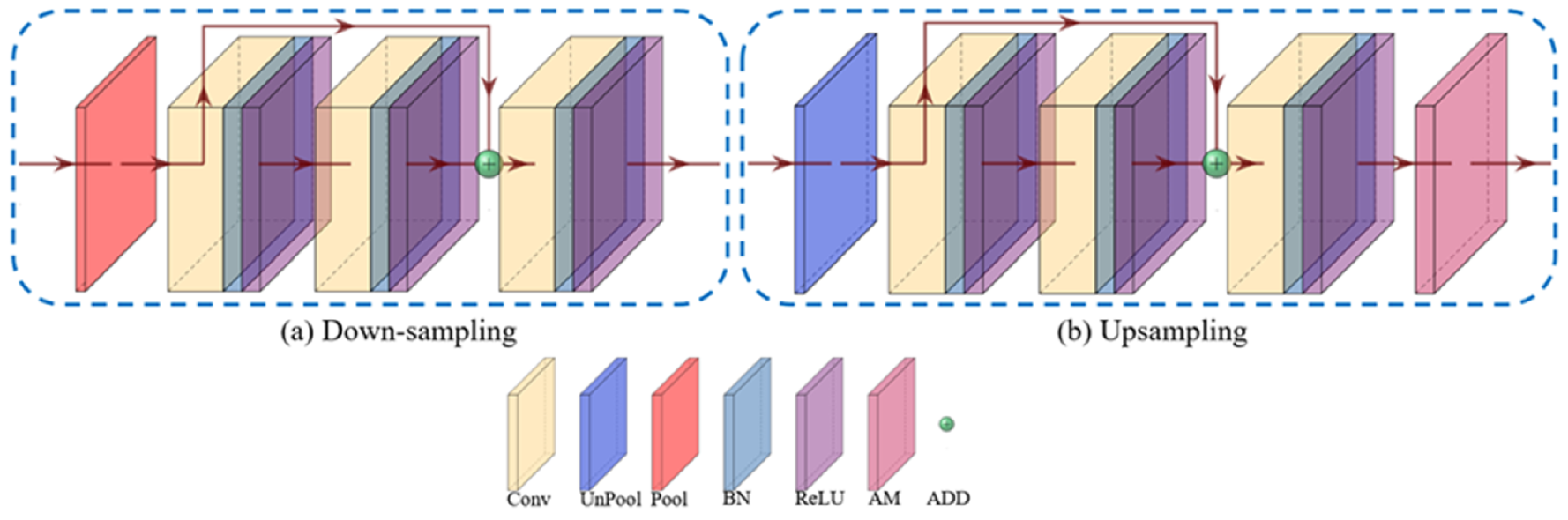
- To remove the haze and restore the image information as much as possible, we take some improvement measures to the Unet++ module. First, the original Unet++ is pruned to avoid expansion of model parameters. Besides, in the down-sampling operation, we replace the simple convolutional layer with the convolutional module with ResNet in order to prevent the loss of original information in the transmission to the deep network;
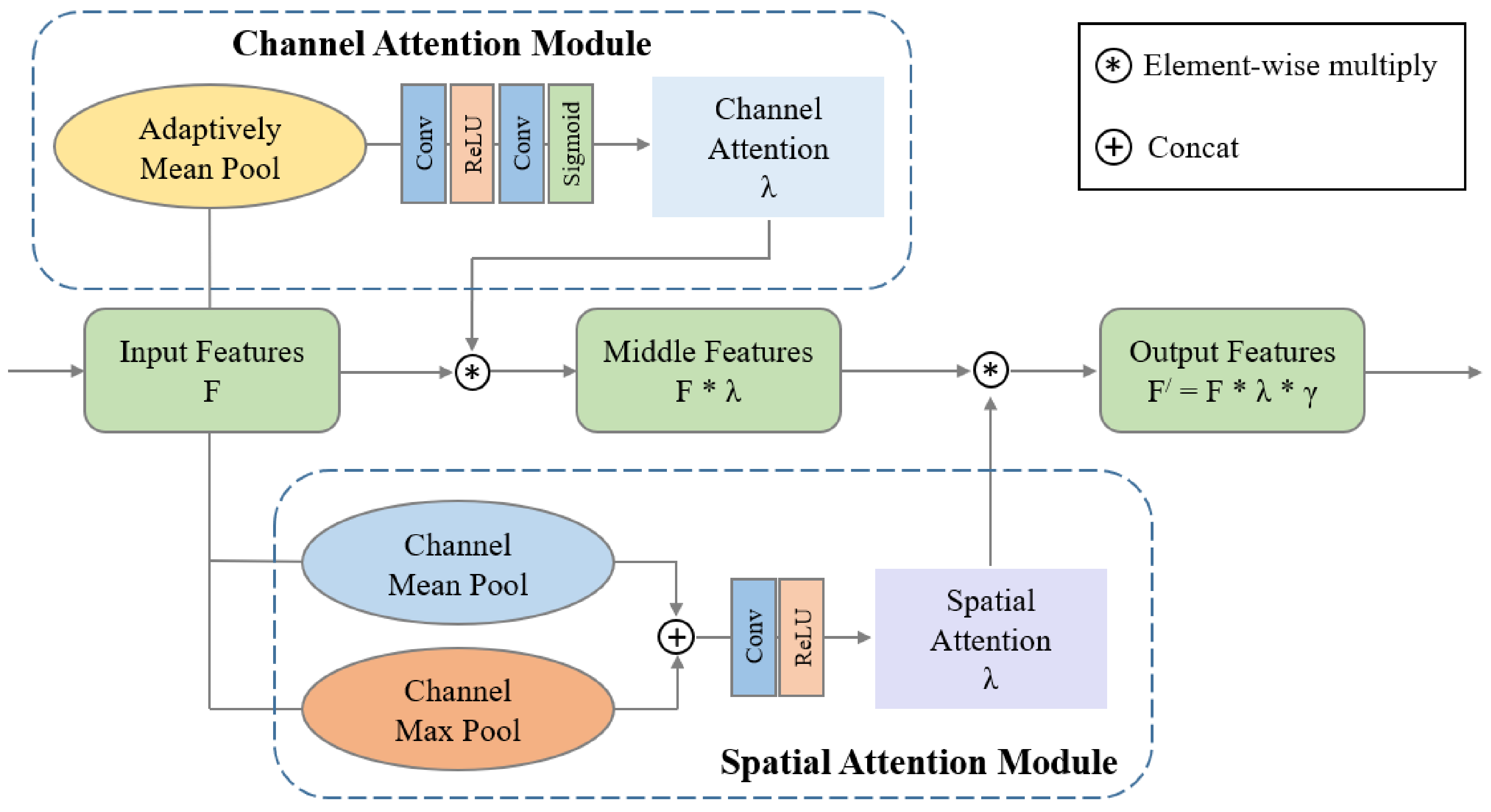
- The different pixel values in the spatial domain and different feature channels show different sensitivities to haze regions with different concentrations. We introduce the attention module at the bottom of the decoder to assign different weights to different spaces and channels, which helps to pay different levels of attention to haze regions with different concentrations and further enables the network to learn the uneven haze in images.
2. Relate Works
3. Method
3.1. Architecture
3.1.1. Pipeline Overview
3.1.2. Encoder-Decoder of the Serial Unet++ Structure
3.1.3. Attention Mechanism
3.2. Loss Function
4. Experiments
4.1. Datasets and Metrics
4.2. Implement Details
4.3. Experiments Results
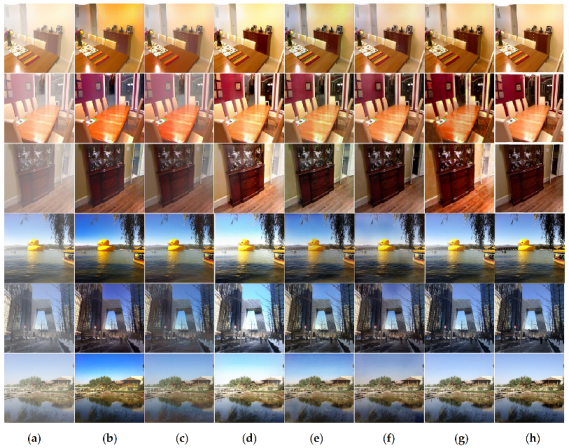
4.3.1. Experiment on Synthetic RESIDE Datasets
4.3.2. Experiment on Real-World I-HAZY and O-HAZY Datasets
5. Ablation Study
- AES-simple-Unet: Serial Unet-based block with attention module;
- AEUnet: Single Unet++ block with attention module;
- SUnet: Serial Unet++ block without attention module.
6. Conclusions and Future Work
Author Contributions
Funding
Conflicts of Interest
References
- Mccartney, E.J. Scattering phenomena. (book reviews: Optics of the atmosphere. scattering by molecules and particles). Science 1977, 196, 1084–1085. [Google Scholar]
- Cartney, E.J. Optics of the Atmosphere: Scattering by Molecules and Particles; John Wiley and Sons, Inc.: New York, NY, USA, 1976; 421p. [Google Scholar]
- He, K.; Sun, J.; Tang, X. Single image haze removal using dark channel prior. IEEE Trans. Pattern Anal. Mach. Intell. 2010, 33, 2341–2353. [Google Scholar] [PubMed]
- Zhu, Q.; Mai, J.; Shao, L. Single image dehazing using color attenuation prior. In BMVC; Citeseer: University Park, PA, USA, 2014. [Google Scholar]
- Berman, D.; Avidan, S. Non-local image dehazing. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, San Juan, PR, USA, 27–30 June 2016; pp. 1674–1682. [Google Scholar]
- He, K.; Sun, J.; Tang, X. Guided Image Filtering[C]//European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2010; pp. 1–14. [Google Scholar]
- Fattal, R. Dehazing using color-lines. ACM Trans. Graph. 2014, 34, 13. [Google Scholar] [CrossRef]
- Jiang, Y.; Sun, C.; Zhao, Y.; Yang, L. Image dehazing using adaptive bi-channel priorson superpixels. Comput. Vis. Image Underst. 2017, 165, 17–32. [Google Scholar] [CrossRef]
- Ju, M.; Gu, Z.; Zhang, D. Single image haze removal based on the improved atmospheric scattering model. Neurocomputing 2017, 260, 180–191. [Google Scholar] [CrossRef]
- Meng, G.; Wang, Y.; Duan, J.; Xiang, S.; Pan, C. Efficient image dehazing with boundary constraint and contextual regularization. In Proceedings of the IEEE International Conference on Computer Vision, Sydney, NSW, Australia, 1–8 December 2013; pp. 617–624. [Google Scholar]
- Riaz, S.; Anwar, M.W.; Riaz, I.; Kim, H.-W.; Nam, Y.; Khan, M.A. Multiscale Image Dehazing and Restoration: An Application for Visual Surveillance. Comput. Mater. Contin. 2021, 70, 1–17. [Google Scholar] [CrossRef]
- Jin, X.; Che, J.; Chen, Y. Weed Identification Using Deep Learning and Image Processing in Vegetable Plantation. IEEE Access 2021, 9, 10940–10950. [Google Scholar] [CrossRef]
- Khan, M.A.; Akram, T.; Zhang, Y.-D.; Sharif, M. Attributes based skin lesion detection and recognition: A mask RCNN and transfer learning-based deep learning framework. Pattern Recognit. Lett. 2021, 143, 58–66. [Google Scholar] [CrossRef]
- Gao, J.; Chen, Y.; Wei, Y.; Li, J. Detection of Specific Building in Remote Sensing Images Using a Novel YOLO-S-CIOU Model. Case: Gas Station Identification. Sensors 2021, 21, 1375. [Google Scholar] [CrossRef] [PubMed]
- Dong, C.; Loy, C.C.; He, K.; Tang, X. Learning a Deep Convolutional Network for Image Super-Resolution[C]//European Conference on Computer Vision; Springer: Cham, Switzerland, 2014; pp. 184–199. [Google Scholar]
- Xie, C.; Liu, Y.; Zeng, W.; Lu, X. An improved method for single image super-resolution based on deep learning. Signal Image Video Process. 2019, 13, 557–565. [Google Scholar] [CrossRef]
- Wang, X.; Yu, K.; Wu, S.; Gu, J.; Liu, Y.; Dong, C.; Loy, C.C.; Qiao, Y.; Tang, X. Esrgan: Enhanced super-resolution generative adversarial networks. In Proceedings of the European Conference on Computer Vision (ECCV) Workshops, Munich, Germany, 8–14 September 2018. [Google Scholar]
- Christian, L.; Lucas, T.; Ferenc, H.; Jose, C.; Andrew, C.; Alejandro, A.; Andrew, A.; Alykhan, T.; Johannes, T.; Zehan, W.; et al. Photo-realistic single image super-resolution using a generative adversarial network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Cai, B.; Xu, X.; Jia, K.; Qing, C.; Tao, D. Dehazenet: An end-to-end system for single image haze removal. IEEE Trans. Image Process. 2016, 25, 5187–5198. [Google Scholar] [CrossRef] [Green Version]
- Li, B.; Peng, X.; Wang, Z.; Xu, J.; Feng, D. Aod-net: All-in-one dehazing network. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 4770–4778. [Google Scholar]
- Zhang, H.; Patel, V.M.; Patel, V.M.; Patel, V.M. Densely connected pyramid dehazing network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 3194–3203. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015. [Google Scholar]
- Zhou, Z.; Siddiquee, M.M.R.; Tajbakhsh, N.; Liang, J. Unet++: A nested u-net architecture for medical image segmentation. In Deep Learning in Medical Image Analysis and Multimodal Learning for Clinical Decision Support; Springer: Cham, Switzerland, 2018; pp. 3–11. [Google Scholar]
- Dong, H.; Pan, J.; Xiang, L.; Hu, Z.; Zhang, X.; Wang, F.; Yang, M.H. Multi-scale boosted dehazing network with dense feature fusion. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Chen, D.; He, M.; Fan, Q.; Liao, J.; Zhang, L.; Hou, D.; Yuan, L.; Hua, G. Gated context aggregation network for image dehazing and deraining. In Proceedings of the 2019 IEEE Winter Conference on Applications of Computer Vision (WACV), Waikoloa Village, HI, USA, 7–11 January 2019. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018. [Google Scholar]
- Narasimhan, S.G.; Nayar, S.K. Chromatic framework for vision in bad weather. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Hilton Head, SC, USA, 15 June 2000; CVPR 2000 (Cat. No.PR00662). Volume 1, pp. 598–605. [Google Scholar]
- Narasimhan, S.G.; Nayar, S.K. Vision and the atmosphere. Int. J. Comput. Vis. 2002, 48, 233–254. [Google Scholar] [CrossRef]
- Ren, W.; Liu, S.; Zhang, H.; Pan, J.; Cao, X.; Yang, M.H. Single image dehazing via multi-scale convolutional neural networks. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016. [Google Scholar]
- Ren, W.; Ma, L.; Zhang, J.; Pan, J.; Cao, X.; Liu, W.; Yang, M.H. Gated fusion network for single image dehazing. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Zhu, H.; Peng, X.; Chandrasekhar, V.; Li, L.; Lim, J.-H. DehazeGAN: When Image Dehazing Meets Differential Programming. In Proceedings of the International Joint Conference on Artificial Intelligence (IJCAI), Stockholm, Sweden, 13–19 July 2018; pp. 1234–1240. [Google Scholar]
- Pang, Y.; Nie, J.; Xie, J.; Han, J.; Li, X. BidNet: Binocular image dehazing without explicit disparity estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Suarez, P.L.; Sappa, A.D.; Vintimilla, B.X.; Hammoud, R.I. Deep learning based single image dehazing. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar]
- Qu, Y.; Chen, Y.; Huang, J.; Xie, Y. Enhanced pix2pix dehazing network. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Dong, Y.; Liu, Y.; Zhang, H.; Chen, S.; Qiao, Y. FD-GAN: Generative adversarial networks with fusion-discriminator for single image dehazing. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 10729–10736. [Google Scholar]
- Wu, H.; Liu, J.; Xie, Y.; Qu, Y.; Ma, L. Knowledge transfer dehazing network for nonhomogeneous dehazing. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Seattle, WA, USA, 14–19 June 2020; pp. 478–479. [Google Scholar]
- Shao, Y.; Li, L.; Ren, W.; Gao, C.; Sang, N. Domain adaptation for image dehazing. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Goodfellow, I.J.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, W.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial nets. Adv. Neural Inf. Process. Syst. 2014, 27. Available online: https://proceedings.neurips.cc/paper/2014/file/5ca3e9b122f61f8f06494c97b1afccf3-Paper.pdf (accessed on 26 October 2021).
- Huang, H.; Lin, L.; Tong, R.; Hu, H.; Zhang, Q.; Iwamoto, Y.; Han, X.; Chen, Y.-W.; Wu, J. Unet 3+: A full-scale connected Unet for medical image segmentation. In Proceedings of the ICASSP 2020–2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, 4–8 May 2020. [Google Scholar]
- Li, X.; Chen, H.; Qi, X.; Dou, Q.; Fu, C.W.; Heng, P.A. H-DenseUnet: Hybrid densely connected Unet for liver and tumor segmentation from CT volumes. IEEE Trans. Med Imaging 2018, 37, 2663–2674. [Google Scholar] [CrossRef] [Green Version]
- Yan, W.; Wang, Y.; Gu, S.; Huang, L.; Yan, F.; Xia, L.; Tao, Q. The domain shift problem of medical image segmentation and vendor-adaptation by Unet-GAN. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Shenzhen, China, 13–17 October 2019. [Google Scholar]
- Guo, S.; Yan, Z.; Zhang, K.; Zuo, W.; Zhang, L. Toward convolutional blind denoising of real photographs. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Jiang, K.; Wang, Z.; Yi, P.; Chen, C.; Huang, B.; Luo, M.; Ma, Y.; Jiang, J. Multi-scale progressive fusion network for single image deraining. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, San Juan, PR, USA, 27–30 June 2016. [Google Scholar]
- Li, C.; Tan, Y.; Chen, W.; Luo, X.; Gao, Y.; Jia, X.; Wang, Z. Attention Unet++: A Nested Attention-Aware U-Net for Liver CT Image Segmentation. In Proceedings of the 2020 IEEE International Conference on Image Processing (ICIP), Abu Dhabi, United Arab Emirates, 25–28 October 2020. [Google Scholar]
- Khanh, T.L.B.; Dao, D.-P.; Ho, N.-H.; Yang, H.-J.; Baek, E.-T.; Lee, G.; Kim, S.-H.; Yoo, S.B. Enhancing u-net with spatial-channel attention gate for abnormal tissue segmentation in medical imaging. Appl. Sci. 2020, 10, 5729. [Google Scholar] [CrossRef]
- Oktay, O.; Schlemper, J.; Le Folgoc, L.; Lee, M.; Heinrich, M.; Misawa, K.; Mori, K.; McDonagh, S.; Hammerla, N.Y.; Kainz, B.; et al. Attention u-net: Learning where to look for the pancreas. arXiv 2018, arXiv:1804.03999. [Google Scholar]
- Qin, X.; Wang, Z.; Bai, Y.; Xie, X.; Jia, H. Ffa-net: Feature fusion attention network for single image dehazing. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 11908–11915. [Google Scholar]
- Zhang, Y.; Li, K.; Li, K.; Wang, L.; Zhong, B.; Fu, Y. Image super-resolution using very deep residual channel attention networks. In Proceedings of the European Conference on Computer Vision (ECCV) Munich, Germany, 8–14 September 2018; pp. 286–301. [Google Scholar]
- Glorot, X.; Bordes, A.; Bengio, Y. Deep sparse rectifier neural networks. In Proceedings of the Fourteenth International Conference on Artificial Intelligence and Statistics, Ft. Lauderdale, FL, USA, 11–13 April 2011; pp. 315–323. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Li, B.; Ren, W.; Fu, D.; Tao, D.; Feng, D.; Zeng, W.; Wang, Z. Reside: A benchmark for single image dehazing. arXiv 2017, arXiv:1712.04143, 1. [Google Scholar]
- Ancuti, C.; Ancuti, C.O.; Timofte, R.; De Vleeschouwer, C. I-HAZE: A dehazing benchmark with real hazy and haze-free indoor images. In Proceedings of the International Conference on Advanced Concepts for Intelligent Vision Systems, Poitiers, France, 24–27 September 2018; pp. 620–631. [Google Scholar]
- Ancuti, C.O.; Ancuti, C.; Timofte, R.; De Vleeschouwer, C. O-haze: A dehazing benchmark with real hazy and haze-free outdoor imag-es. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Salt Lake City, UT, USA, 18–22 June 2018; pp. 754–762. [Google Scholar]
- Zhang, R.; Isola, P.; Efros, A.A.; Shechtman, E.; Wang, O. The unreasonable effectiveness of deep features as a perceptual metric. In Proceedings of the IEEE conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Loshchilov, I.; Hutter, F. Sgdr: Stochastic gradient descent with warm restarts. arXiv 2016, arXiv:1608.03983. [Google Scholar]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. Mobilenets: Efficient convolutional neural networks for mobile vision applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Zhou, Y.; Jing, W.; Wang, J.; Chen, G.; Scherer, R.; Damaševičius, R. MSAR-DefogNet: Lightweight cloud removal network for high resolution remote sensing images based on multi scale convolution. IET Image Process. 2021, 1–10. [Google Scholar] [CrossRef]
- Bai, Z.; Li, Y.; Chen, X.; Yi, T.; Wei, W.; Wozniak, M.; Damasevicius, R. Real-time video stitching for mine surveillance using a hybrid image registration method. Electronics 2020, 9, 1336. [Google Scholar] [CrossRef]
- Zhu, X.; Wang, Y.; Dai, J.; Yuan, L.; Wei, Y. Flow-guided feature aggregation for video object detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017. [Google Scholar]
- Deng, J.; Pan, Y.; Yao, T.; Zhou, W.; Li, H.; Mei, T. Relation distillation networks for video object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Indoor | Outdoor | ||||||
|---|---|---|---|---|---|---|---|---|
| PSNR (dB) ↑ | SSIM ↑ | LPIPS ↓ | NIQE ↓ | PSNR (dB) ↑ | SSIM ↑ | LPIPS ↓ | NIQE ↓ | |
| DCP | 16.62 | 0.8179 | 0.268 | \ | 19.13 | 0.8148 | 0.257 | \ |
| AODNet | 19.06 | 0.8504 | 0.228 | 13.5746 | 20.29 | 0.8765 | 0.243 | 12.6212 |
| DCPDN | 19.98 | 0.8565 | 0.243 | 13.9711 | 20.67 | 0.9098 | 0.239 | 13.2775 |
| FDGAN | 23.15 | 0.9207 | 0.203 | 13.7742 | 23.43 | 0.9285 | 0.212 | 14.0714 |
| GCANet | 30.23 | 0.9800 | 0.176 | 13.8669 | 28.13 | 0.9450 | 0.184 | 12.4203 |
| Ours | 29.60 | 0.9549 | 0.200 | 11.6144 | 30.75 | 0.9639 | 0.191 | 10.9311 |
| Method | I-HAZY | O-HAZY | ||||||
|---|---|---|---|---|---|---|---|---|
| PSNR (dB) ↑ | SSIM ↑ | LPIPS ↓ | NIQE ↓ | PSNR (dB) ↑ | SSIM ↑ | LPIPS ↓ | NIQE ↓ | |
| DCP | 14.43 | 0.752 | 0.333 | \ | 16.78 | 0.653 | 0.411 | \ |
| AODNet | 13.98 | 0.732 | 0.374 | 10.7116 | 15.03 | 0.539 | 0.445 | 12.6648 |
| DCPDN | 16.21 | 0.755 | 0.274 | 15.3483 | 15.16 | 0.673 | 0.377 | 18.3160 |
| FDGAN | 17.82 | 0.757 | 0.224 | 13.9222 | 18.38 | 0.682 | 0.289 | 14.2454 |
| GCANet | 14.95 | 0.719 | 0.207 | 11.3894 | 16.28 | 0.645 | 0.259 | 12.2723 |
| Ours | 22.08 | 0.728 | 0.197 | 10.8302 | 22.97 | 0.767 | 0.206 | 12.0232 |
| Flops (G) | Params (M) | PSNR (dB) | SSIM | |
|---|---|---|---|---|
| AES-simple-Unet | 173.417 | 14.10 | 27.39 | 0.9586 |
| AEUnet | 263.218 | 15.79 | 23.26 | 0.8873 |
| SUnet | 234.478 | 14.05 | 26.20 | 0.9117 |
| AESUnet | 234.216 | 14.05 | 30.74 | 0.9639 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhao, W.; Zhao, Y.; Feng, L.; Tang, J. Attention Enhanced Serial Unet++ Network for Removing Unevenly Distributed Haze. Electronics 2021, 10, 2868. https://doi.org/10.3390/electronics10222868
Zhao W, Zhao Y, Feng L, Tang J. Attention Enhanced Serial Unet++ Network for Removing Unevenly Distributed Haze. Electronics. 2021; 10(22):2868. https://doi.org/10.3390/electronics10222868
Chicago/Turabian StyleZhao, Wenxuan, Yaqin Zhao, Liqi Feng, and Jiaxi Tang. 2021. "Attention Enhanced Serial Unet++ Network for Removing Unevenly Distributed Haze" Electronics 10, no. 22: 2868. https://doi.org/10.3390/electronics10222868