
Segmentation of Overlapping Grape Clusters Based on the Depth Region Growing Method

Abstract
:1. Introduction
- (1)
- A semantic segmentation model was trained by our own annotated dataset for the recognition of grapes.
- (2)
- The idea of transfer learning was adopted to improve the segmentation performance of the semantic segmentation model.
- (3)
- Based on the idea of the region growing algorithm, a depth-based region growing method (DRG) was proposed to extract the front cluster of overlapping grape clusters.
2. Motivation
3. Methodology
3.1. Recognition of Grape Clusters Based on DeepLabV3+
3.1.1. DeepLabV3+ Network
3.1.2. Image Annotation
3.1.3. Data Argument
3.1.4. Transfer Learning
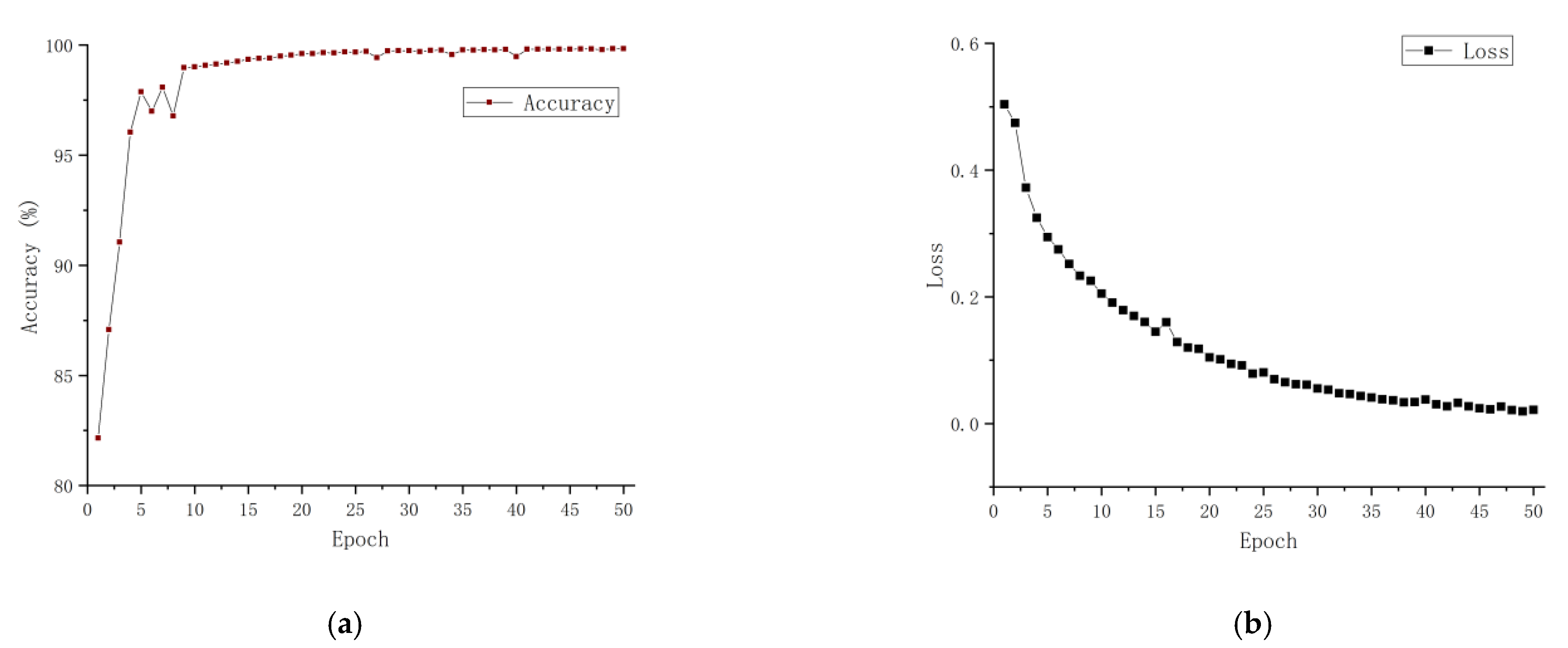
3.1.5. Model Training
3.1.6. Recognition of the Grape Clusters
3.2. Extraction of the Front Cluster
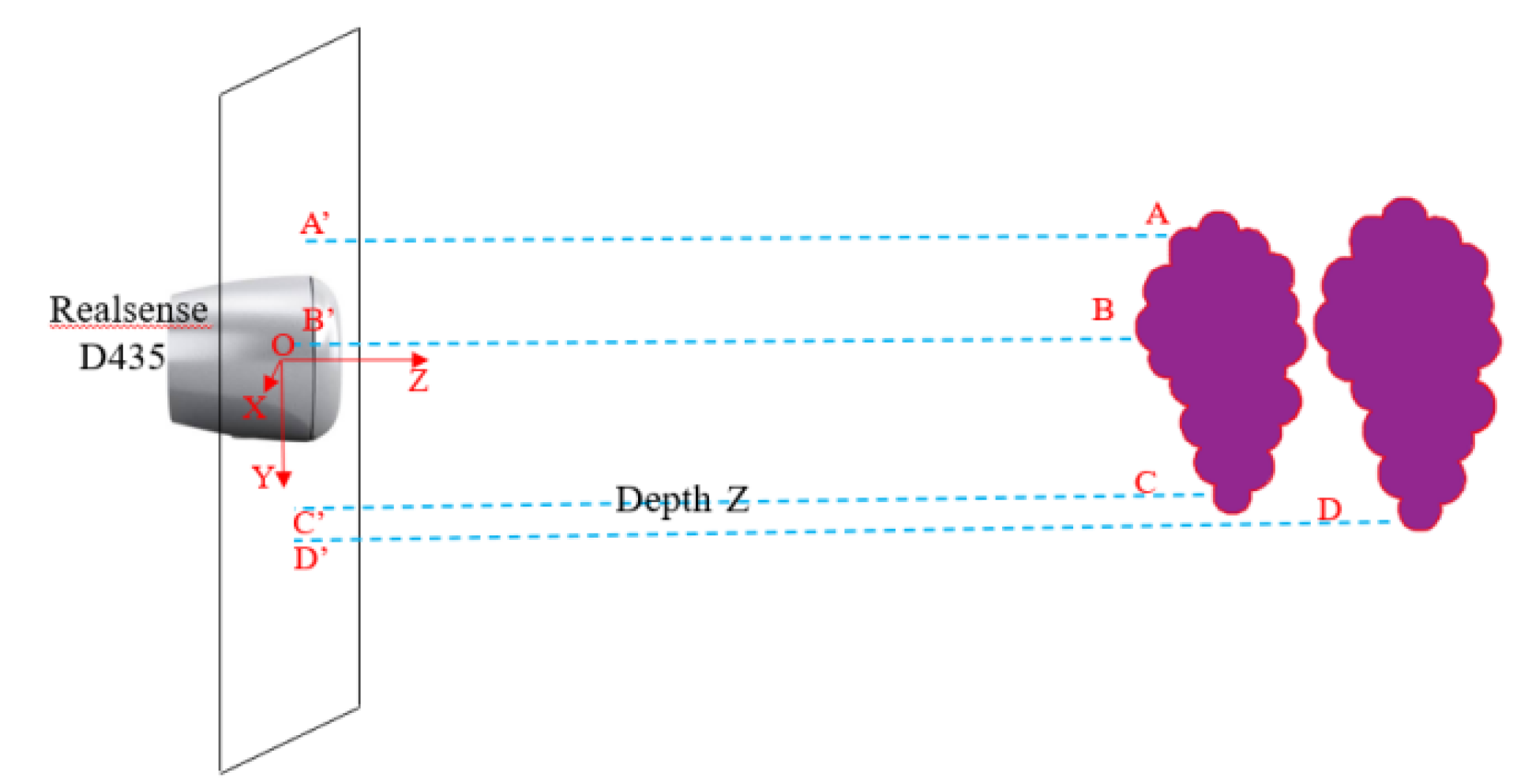
3.2.1. Preprocessing of the Depth Map
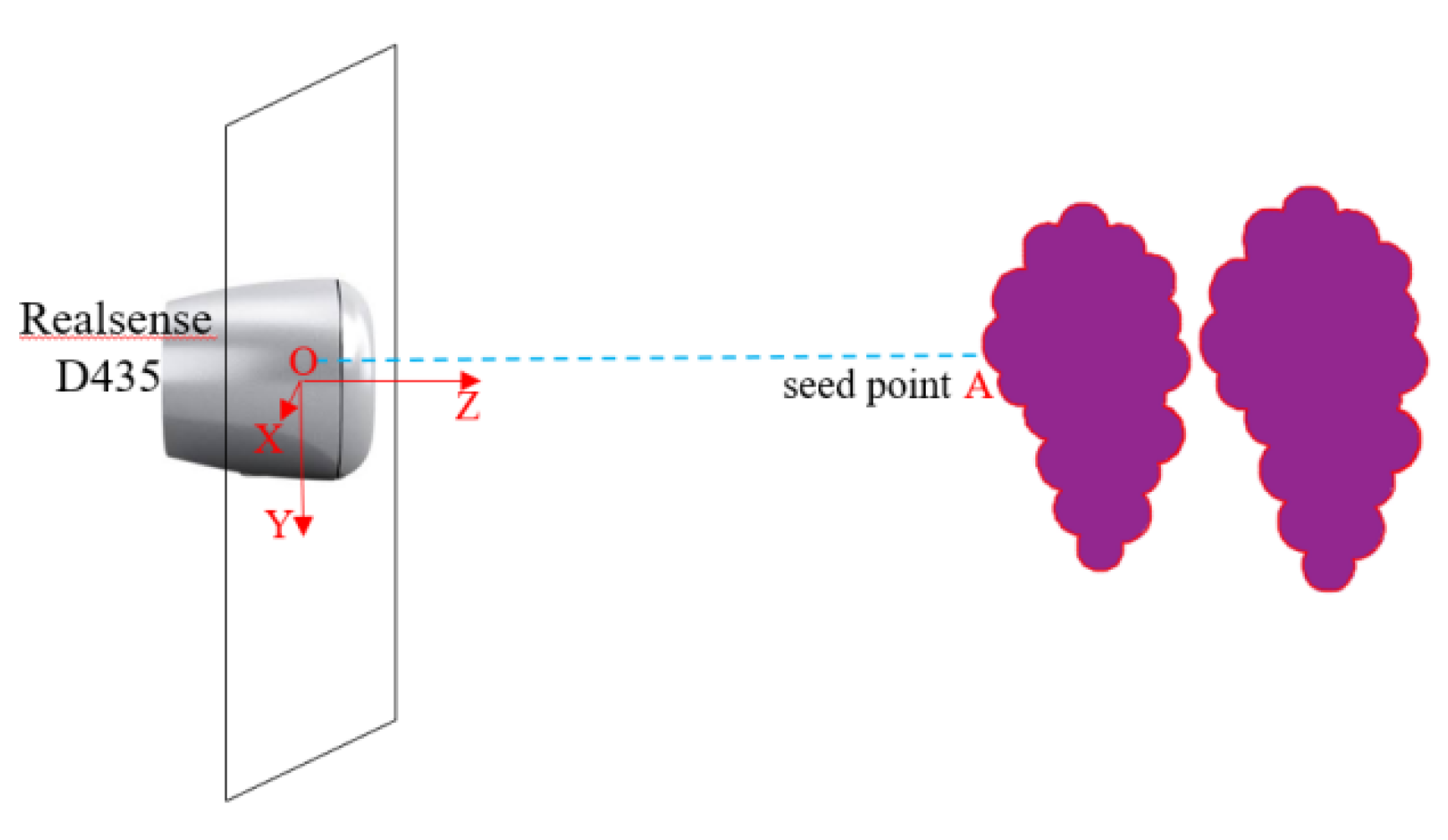
3.2.2. Selection of the Seed Point
3.2.3. Selection of the Similarity Threshold
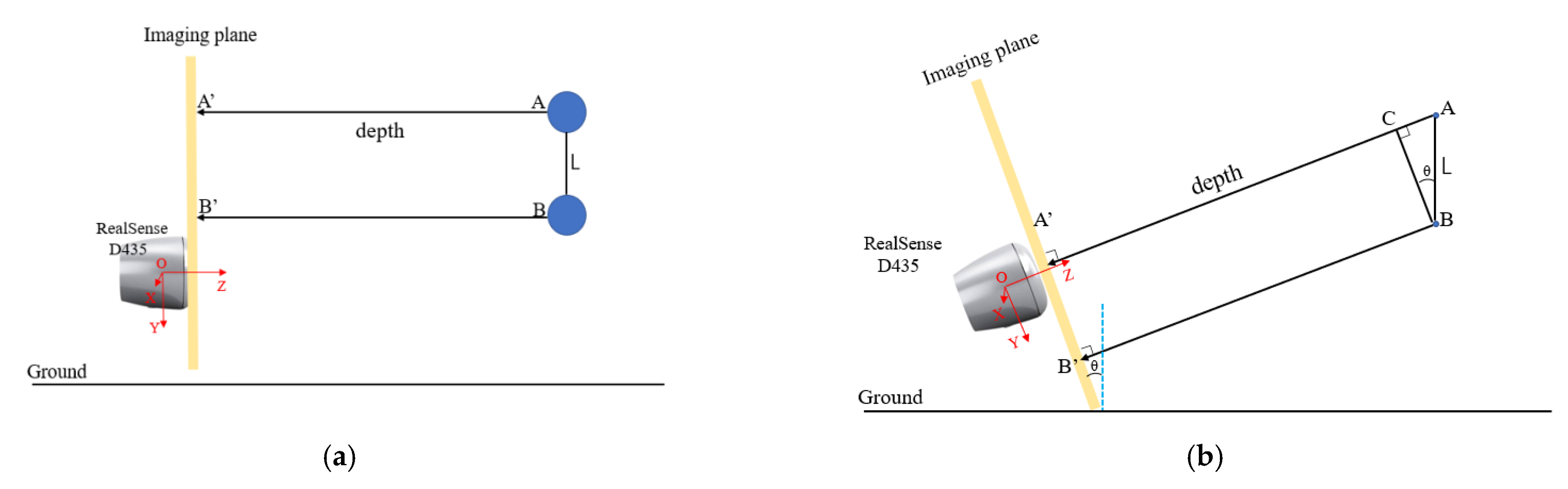
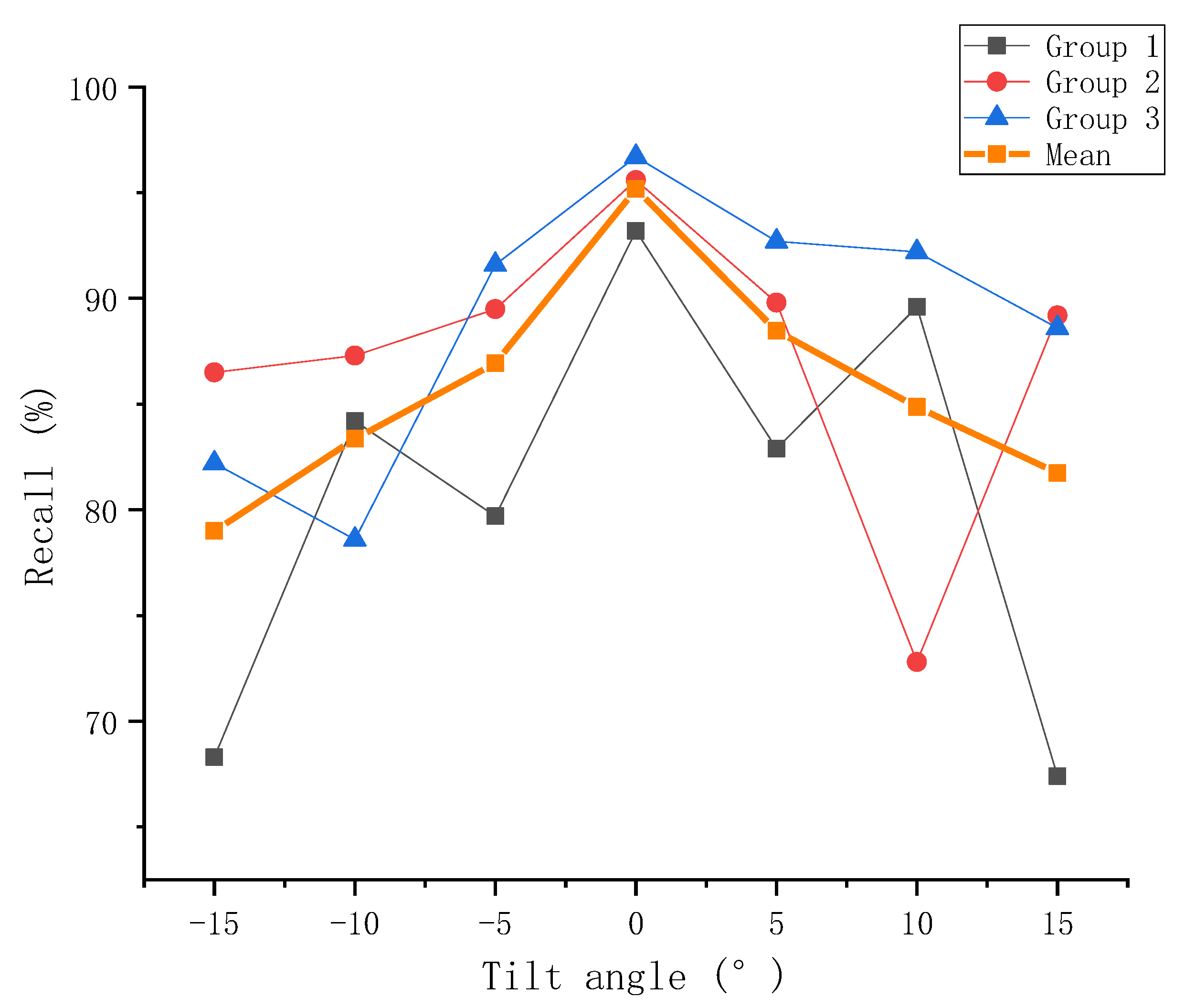
3.2.4. The Effect of Camera Tilt Angle
3.2.5. The Extraction of the Front Grape Cluster
3.2.6. The Extraction of the Contour
4. Experiments Result and Discussion
4.1. Data-Acquisition Materials and Method
4.2. Dataset and Evaluation Metrics
4.2.1. The Performance of DeepLabV3+ to Segment Grapes
4.2.2. The Performance of Extracting the Front Grape Cluster
4.2.3. The Effect of the Tilt Angle of the Camera
4.2.4. The Performance of Extracting the Front Grape Cluster
5. Conclusions and Future Work
Author Contributions
Funding
Conflicts of Interest
References
- Chamelat, R.; Rosso, E.; Choksuriwong, A.; Rosenberger, C.; Laurent, H.; Bro, P. Grape detection by image processing. In Proceedings of the IECON 2006—32nd Annual Conference on IEEE Industrial Electronics, Paris, France, 6–10 November 2006; pp. 3697–3702. [Google Scholar]
- Reis, M.J.; Morais, R.; Peres, E.; Pereira, C.; Contente, O.; Soares, S.; Valente, A.; Baptista, J.; Ferreira, P.J.S.; Cruz, J.B. Automatic detection of bunches of grapes in natural environment from color images. J. Appl. Log. 2012, 10, 285–290. [Google Scholar] [CrossRef] [Green Version]
- Śkrabánek, P. DeepGrapes: Precise Detection of Grapes in Low-resolution Images. IFAC PapersOnLine 2018, 51, 185–189. [Google Scholar] [CrossRef]
- Liu, S.; Whitty, M. Automatic grape bunch detection in vineyards with an SVM classifier. J. Appl. Log. 2015, 13, 643–653. [Google Scholar] [CrossRef]
- Luo, L.; Zou, X.; Yang, Z.; Li, G.; Song, X.; Zhang, C. Grape image fast segmentation based on improved artificial bee colony and fuzzy clustering. Trans. CSAM 2015, 46, 23–28. [Google Scholar]
- Chinchuluun, R.; Lee, W.S. Citrus yield mapping system in natural outdoor scenes using the watershed transform. In Proceedings of the 2006 ASAE Annual Meeting, Boston, MA, USA, 19–22 August 2006. [Google Scholar]
- Rizon, M.; Yusri, N.A.N.; Kadir, M.F.A.; bin Mamat, A.R.; Abd Aziz, A.Z.; Nanaa, K. Determination of mango fruit from binary image using randomized Hough transform. In Proceedings of the Eighth International Conference on Machine Vision (ICMV 2015), Barcelona, Spain, 19–21 November 2015; p. 987503. [Google Scholar]
- Peng, H.; Wu, P.; Zhai, R.; Liu, S.; Wu, L.; Jing, X. Image segmentation algorithm for overlapping fruits based on disparity map. Trans. Chin. Soc. Agric. Mach. 2012, 43, 167–173. [Google Scholar]
- Song, H.; Zhang, C.; Pan, J.; Yin, X.; Zhuang, Y. Segmentation and reconstruction of overlappedapple images based on convex hull. Trans. Chin. Soc. Agric. Eng. 2013, 29, 163–168. [Google Scholar]
- Lu, J.; Sang, N. Detecting citrus fruits and occlusion recovery under natural illumination conditions. Comput. Electron. Agric. 2015, 110, 121–130. [Google Scholar] [CrossRef]
- Luo, L.; Tang, Y.; Lu, Q.; Chen, X.; Zhang, P.; Zou, X. A vision methodology for harvesting robot to detect cutting points on peduncles of double overlapping grape clusters in a vineyard. Comput. Ind. 2018, 99, 130–139. [Google Scholar] [CrossRef]
- Liu Ping, Z.Y.; Zhang, T.; Hou, J. Algorithm for recognition and image segmentation of overlapping grape cluster in natural environment. Trans. Chin. Soc. Agric. Eng. 2020, 36, 161–169. [Google Scholar]
- Lottes, P.; Behley, J.; Milioto, A.; Stachniss, C. Fully convolutional networks with sequential information for robust crop and weed detection in precision farming. IEEE Robot. Autom. Lett. 2018, 3, 2870–2877. [Google Scholar] [CrossRef] [Green Version]
- Koirala, A.; Walsh, K.; Wang, Z.; McCarthy, C. Deep learning for real-time fruit detection and orchard fruit load estimation: Benchmarking of ‘MangoYOLO’. Precis. Agric. 2019, 20, 1107–1135. [Google Scholar] [CrossRef]
- Xu, Z.-F.; Jia, R.-S.; Sun, H.-M.; Liu, Q.-M.; Cui, Z. Light-YOLOv3: Fast method for detecting green mangoes in complex scenes using picking robots. Appl. Intell. 2020, 50, 4670–4687. [Google Scholar] [CrossRef]
- Yu, Y.; Zhang, K.; Liu, H.; Yang, L.; Zhang, D. Real-time visual localization of the picking points for a ridge-planting strawberry harvesting robot. IEEE Access 2020, 8, 116556–116568. [Google Scholar] [CrossRef]
- Kuznetsova, A.; Maleva, T.; Soloviev, V. Using YOLOv3 algorithm with pre-and post-processing for apple detection in fruit-harvesting robot. Agronomy 2020, 10, 1016. [Google Scholar] [CrossRef]
- Peng, H.; Xue, C.; Shao, Y.; Chen, K.; Xiong, J.; Xie, Z.; Zhang, L. Semantic Segmentation of Litchi Branches Using DeepLabV3+ Model. IEEE Access 2020, 8, 164546–164555. [Google Scholar] [CrossRef]
- Zhang, D.; Ding, Y.; Chen, P.; Zhang, X.; Pan, Z.; Liang, D. Automatic extraction of wheat lodging area based on transfer learning method and deeplabv3+ network. Comput. Electron. Agric. 2020, 179, 105845. [Google Scholar] [CrossRef]
- Sharifzadeh, S.; Tata, J.; Sharifzadeh, H.; Tan, B. Farm Area Segmentation in Satellite Images Using DeepLabv3+ Neural Networks. In Proceedings of the International Conference on Data Management Technologies and Applications, Prague, Czech Republic, 26–28 July 2019; pp. 115–135. [Google Scholar]
- Chen, L.-C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-decoder with atrous separable convolution for semantic image segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 801–818. [Google Scholar]
- Azad, R.; Asadi-Aghbolaghi, M.; Fathy, M.; Escalera, S. Attention deeplabv3+: Multi-level context attention mechanism for skin lesion segmentation. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; pp. 251–266. [Google Scholar]
- Wu, H.; Yao, L.; Xu, Z.; Li, Y.; Ao, X.; Chen, Q.; Li, Z.; Meng, B. Road pothole extraction and safety evaluation by integration of point cloud and images derived from mobile mapping sensors. Adv. Eng. Inform. 2019, 42, 100936. [Google Scholar] [CrossRef]
- Wang, A.; Xu, Y.; Wei, X.; Cui, B. Semantic segmentation of crop and weed using an encoder-decoder network and image enhancement method under uncontrolled outdoor illumination. IEEE Access 2020, 8, 81724–81734. [Google Scholar] [CrossRef]
- Manzo, M.; Pellino, S. Fighting together against the pandemic: Learning multiple models on tomography images for COVID-19 diagnosis. AI 2021, 2, 261–273. [Google Scholar] [CrossRef]
- Peng, Y.; Wang, A.; Liu, J.; Faheem, M. A Comparative Study of Semantic Segmentation Models for Identification of Grape with Different Varieties. Agriculture 2021, 11, 997. [Google Scholar] [CrossRef]
- Wang, D.; Xu, Y.; Song, H.; He, D.; Zhang, H. Fusion of K-means and Ncut algorithm to realize segmentation and reconstruction of two overlapped apples without blocking by branches and leaves. Trans. Chin. Soc. Agric. Eng. 2015, 31, 227–234. [Google Scholar]
- Ni, X.; Li, C.; Jiang, H.; Takeda, F. Deep learning image segmentation and extraction of blueberry fruit traits associated with harvestability and yield. Horticult. Res. 2020, 7, 1–14. [Google Scholar] [CrossRef] [PubMed]
- Kang, H.; Chen, C. Fruit detection, segmentation and 3D visualisation of environments in apple orchards. Comput. Electron. Agric. 2020, 171, 105302. [Google Scholar] [CrossRef] [Green Version]


























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameters | Value |
|---|---|
| Backbone | Xception |
| Initial learning rate | 0.004 |
| Learning power | 0.9 |
| Epoch | 50 |
| Weight decay | 0.00004 |
| momentum | 0.9 |
| IoU (%) | Mean Time (ms) |
|---|---|
| 97.32 | 98 |
| No. | Reference | Dataset | Fruit Type | Performance |
|---|---|---|---|---|
| 1 | Luo et al. [11] | 30 images containing double overlapping grape clusters. | Grape | Recall: 88.7% |
| 2 | Liu et al. [12] | 22 images (11 target grapes on the left and 11 on the right) captured from a vineyard. | Grape | Recall: 89.71% |
| 3 | Wang et al. [27] | 20 double overlapping apple images. | Apple | Recall: 96.08% |
| 4 | Ni et al. [28] | 724 blueberry images captured under different background conditions. | Blueberry | Mask accuracy: 90.04% |
| 5 | Kang et al. [29] | 400 RGB-D images and 800 RGB images captured in an apple orchard. | Apple | Recall: 86.8% |
| 6 | The proposed method | - | Grape | Recall: 89.2% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Peng, Y.; Zhao, S.; Liu, J. Segmentation of Overlapping Grape Clusters Based on the Depth Region Growing Method. Electronics 2021, 10, 2813. https://doi.org/10.3390/electronics10222813
Peng Y, Zhao S, Liu J. Segmentation of Overlapping Grape Clusters Based on the Depth Region Growing Method. Electronics. 2021; 10(22):2813. https://doi.org/10.3390/electronics10222813
Chicago/Turabian StylePeng, Yun, Shengyi Zhao, and Jizhan Liu. 2021. "Segmentation of Overlapping Grape Clusters Based on the Depth Region Growing Method" Electronics 10, no. 22: 2813. https://doi.org/10.3390/electronics10222813