
Residual Triplet Attention Network for Single-Image Super-Resolution


Abstract
:1. Introduction
- (1)
- A residual triplet attention network (RTAN) is proposed to make full use the advantages of CNNs and recover clearer and more accurate image details. The comprehensive simulations demonstrate the effectiveness of the proposed RTAN over other chosen SISR models in terms of both evaluation metrics and visual results.
- (2)
- We design the multiple nested residual group (MNRG) structure which reuses more LR features and diminishes the training difficulty of the network.
- (3)
- A residual triplet attention module (RTAM) is proposed to compute the cross-dimensional attention weights by considering the interdependencies and interactions of the features. The RTAM uses the inherent information between the spatial dimension and channel dimension of the features in the intermediate layers, thus achieving sharper SR results and further applying to actual scenes.
2. Related Work
2.1. CNNs-Based Single Image Super-Resolution Network
2.2. Attention Mechanism
3. Proposed Methods
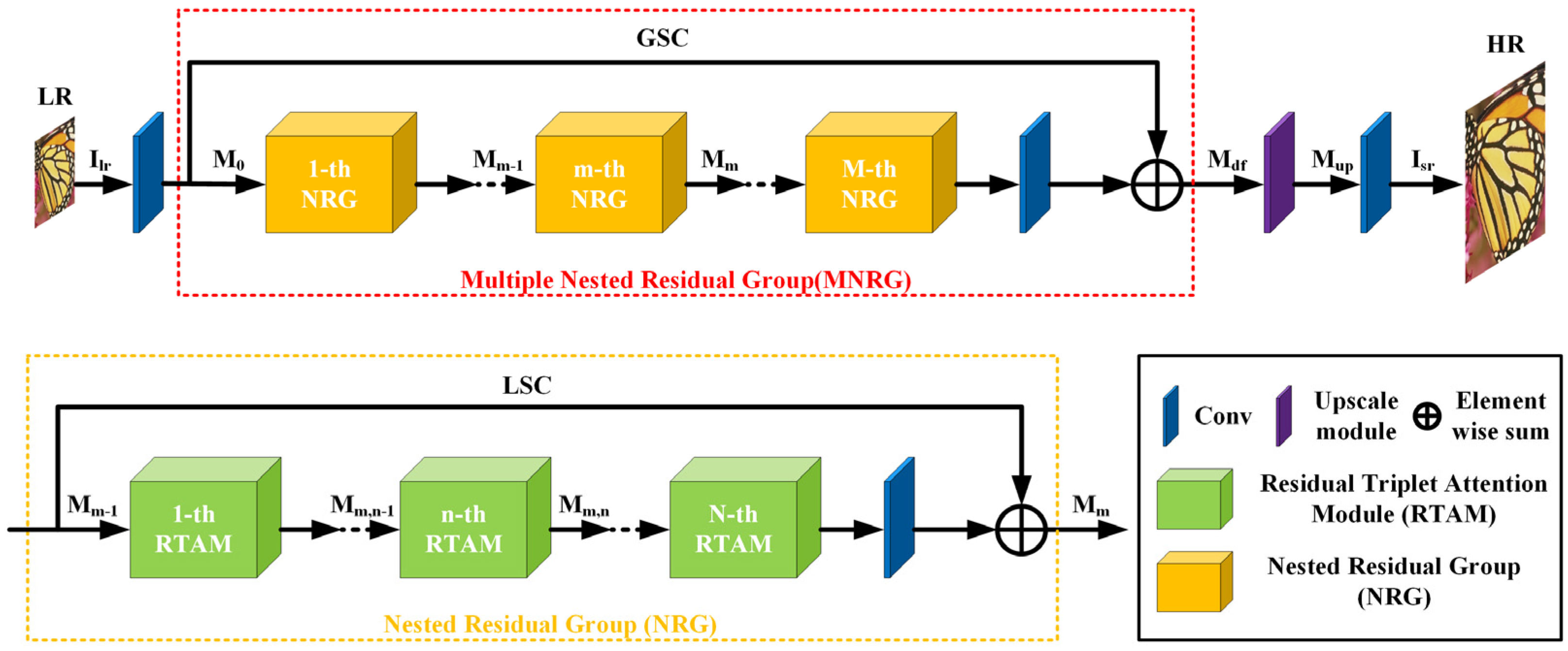
3.1. Network Architecture
3.2. Multiple Nested Residual Group (MNRG) Structure
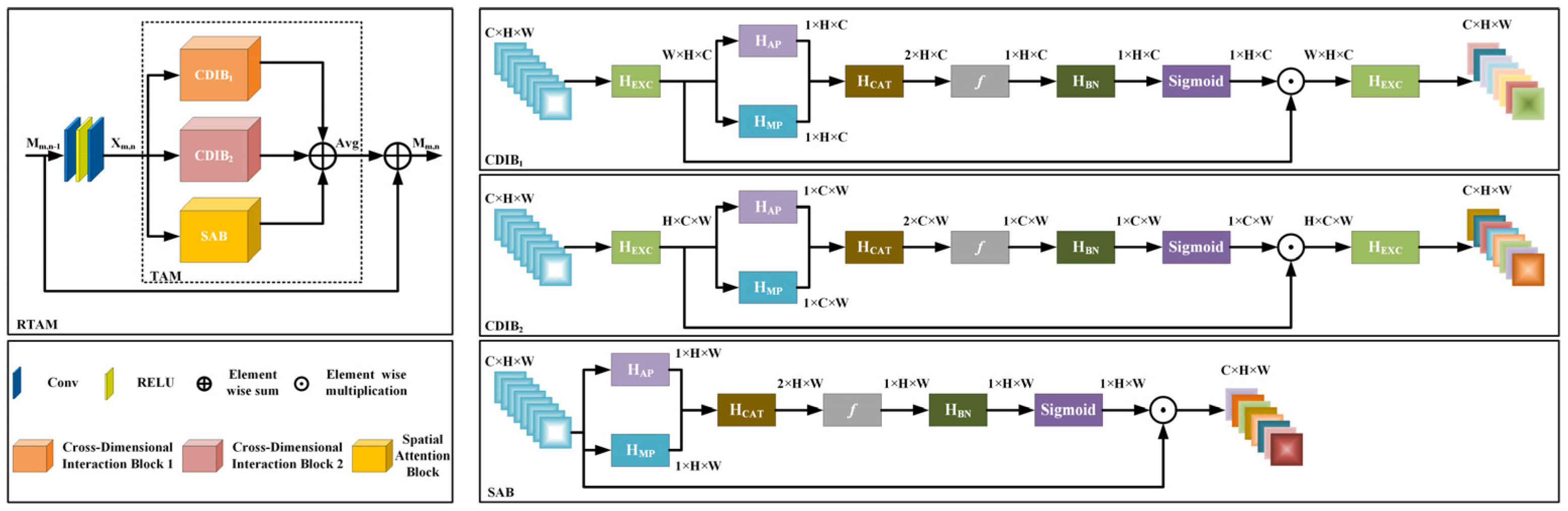
3.3. Triplet Attention Module (TAM)
3.3.1. Cross-Dimensional Interaction Block (CDIB)
3.3.2. Spatial Attention Block (SAB)
3.3.3. Feature Aggregation Method
3.4. Residual Triplet Attention Module (RTAM)
4. Discussion
4.1. Difference between RTAN and RCAN
4.2. Advantages of the RTAN over RCAN
5. Experiments and Analysis
5.1. Datasets and Evaluation Metrics
5.1.1. Datasets
5.1.2. Evaluation Metrics
5.2. Implementation and Training Details
5.3. Ablation Study
5.3.1. GSC and LSC
5.3.2. SAB and CDIB
5.4. Comparison with State-of-the-Art
5.4.1. Results with Bicubic (BI) Degradation Model
5.4.2. Results with Blur-Downscale (BD) Degradation Model
5.4.3. Results with the Real-World Degradation Model
5.5. Model Complexity Comparison
5.5.1. Model Size Analysis
5.5.2. Model Computation Cost Analysis
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Zhang, L.; Wu, X. An edge-guided image interpolation algorithm via directional filtering and data fusion. IEEE Trans. Image Process. 2006, 15, 2226–2238. [Google Scholar] [CrossRef] [Green Version]
- Yang, J.; Wright, J.; Huang, T.S.; Ma, Y. Image super-resolution via sparse representation. IEEE Trans. Image Process. 2010, 19, 2861–2873. [Google Scholar] [CrossRef] [PubMed]
- Yang, J.; Wright, J.; Huang, T.S.; Ma, Y. Image super-resolution as sparse representation of raw image patches. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Anchorage, AK, USA, 23–28 June 2008. [Google Scholar]
- Peleg, T.; Elad, M. A statistical prediction model based on sparse representations for single image super-resolution. IEEE Trans. Image Process. 2014, 23, 2569–2582. [Google Scholar] [CrossRef]
- Dong, C.; Loy, C.C.; He, K.; Tang, X. Image super-resolution using deep convolutional networks. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 38, 295–307. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zhang, Y.; Li, K.; Li, K.; Wang, L.; Zhong, B.; Fu, Y. Image super-resolution using very deep residual channel attention networks. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018. [Google Scholar]
- Zhang, K.; Zuo, W.; Zhang, L. Learning a single convolutional super-resolution network for multiple degradations. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Wang, S.; Zhang, L.; Liang, Y.; Pan, Q. Semi-coupled dictionary learning with applications to image super-resolution and photo-sketch synthesis. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Providence, RI, USA, 16–21 June 2012. [Google Scholar]
- Timofte, R.; De Smet, V.; Van Gool, L. A+: Adjusted anchored neighborhood regression for fast super-resolution. In Proceedings of the Asian Conference on Computer Vision (ACCV), Singapore, 1–5 November 2014. [Google Scholar]
- Timofte, R.; De Smet, V.; Van Gool, L. Anchored neighborhood regression for fast example-based super-resolution. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Sydney, NSW, Australia, 1–8 December 2013. [Google Scholar]
- Ledig, C.; Theis, L.; Huszár, F.; Caballero, J.; Cunningham, A.; Acosta, A.; Aitken, A.; Tejani, A.; Totz, J.; Wang, Z.; et al. Photo-realistic single image super-resolution using a generative adversarial network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Kim, J.; Lee, J.K.; Lee, K.M. Accurate image super-resolution using very deep convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Huang, J.; Singh, A.; Ahuja, N. Single image super-resolution from transformed self-exemplars. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- Ouahabi, A.; Taleb-Ahmed, A. Deep learning for real-time semantic segmentation: Application in ultrasound imaging. Pattern Recognit. Lett. 2021, 144, 27–34. [Google Scholar] [CrossRef]
- Insaf, A.; Ouahabi, A.; Benzaoui, A.; Jacques, S. Multi-block color-binarized statistical images for single sample face recognition. Sensors 2021, 21, 728. [Google Scholar] [CrossRef]
- Zhang, Y.; Tian, Y.; Kong, Y.; Zhong, B.; Fu, Y. Residual dense network for image super-resolution. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Lim, B.; Son, S.; Kim, H.; Nah, S.; Lee, K.M. Enhanced deep residual networks for single image super-resolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Lai, W.; Huang, J.; Ahuja, N.; Yang, M. Deep laplacian pyramid networks for fast and accurate super-resolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Hu, X.; Mu, H.; Zhang, X.; Wang, Z.; Tan, T.; Sun, J. Meta-sr: A magnification-arbitrary network for super-resolution. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- He, J.; Dong, C.; Qiao, Y. Modulating image restoration with continual levels via adaptive feature modification layers. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Dai, T.; Cai, J.; Zhang, Y.; Xia, S.; Zhang, L. Second-order attention network for single image super-resolution. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Hu, J.; Shen, L.; Albanie, S.; Sun, G.; Wu, E. Squeeze-and-excitation networks. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 42, 2011–2023. [Google Scholar] [CrossRef] [Green Version]
- Misra, D.; Nalamada, T.; Uppili Arasanipalai, A.; Hou, Q. Rotate to attend: Convolutional triplet attention module. arXiv 2020, arXiv:2010.03045. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.-Y.; Kweon, I.S. CBAM: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018. [Google Scholar]
- Kim, J.; Lee, J.K.; Lee, K.M. Deeply-recursive convolutional network for image super-resolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Tai, Y.; Yang, J.; Liu, X. Image super-resolution via deep recursive residual network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Tai, Y.; Yang, J.; Liu, X.; Xu, C. MemNet: A persistent memory network for image restoration. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017. [Google Scholar]
- Shi, W.; Caballero, J.; Huszár, F.; Totz, J.; Aitken, A.P.; Bishop, R.; Rueckert, D.; Wang, Z. Real-time single image and video super-resolution using an efficient sub-pixel convolutional neural network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Wang, X.; Yu, K.; Wu, S.; Gu, J.; Liu, Y.; Dong, C.; Qiao, Y.; Loy, C.C. ESRGAN: Enhanced super-resolution generative adversarial networks. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018. [Google Scholar]
- Ahn, N.; Kang, B.; Sohn, K.-A. Fast, accurate, and lightweight super-resolution with cascading residual network. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018. [Google Scholar]
- Liu, D.; Wen, B.; Fan, Y.; Change Loy, C.; Huang, T.S. Non-local recurrent network for image restoration. arXiv 2018, arXiv:1806.02919. [Google Scholar]
- Hui, Z.; Gao, X.; Yang, Y.; Wang, X. Lightweight image super-resolution with information multi-distillation network. arXiv 2019, arXiv:1909.11856. [Google Scholar]
- He, X.; Mo, Z.; Wang, P.; Liu, Y.; Yang, M.; Cheng, J. Ode-inspired network design for single image super-resolution. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Cao, F.; Chen, B. New architecture of deep recursive convolution networks for super-resolution. Knowl. Based Syst. 2019, 178, 98–110. [Google Scholar] [CrossRef]
- Wang, L.; Dong, X.; Wang, Y.; Ying, X.; Lin, Z.; An, W.; Guo, Y. Exploring sparsity in image super-resolution for efficient inference. arXiv 2020, arXiv:2006.09603. [Google Scholar]
- Chu, X.; Zhang, B.; Ma, H.; Xu, R.; Li, Q. Fast, accurate and lightweight super-resolution with neural architecture search. arXiv 2019, arXiv:1901.07261. [Google Scholar]
- Tian, C.; Xu, Y.; Zuo, W.; Lin, C.-W.; Zhang, D. Asymmetric CNN for image super-resolution. arXiv 2021, arXiv:2103.13634. [Google Scholar]
- Ullah, I.; Manzo, M.; Shah, M.; Madden, M. Graph convolutional networks: Analysis, improvements and results. arXiv 2019, arXiv:1912.09592. [Google Scholar]
- Zhou, S.; Zhang, J.; Zuo, W.; Change Loy, C. Cross-scale internal graph neural network for image super-resolution. arXiv 2020, arXiv:2006.16673. [Google Scholar]
- Wang, F.; Jiang, M.; Qian, C.; Yang, S.; Li, C.; Zhang, H.; Wang, X.; Tang, X. Residual attention network for image classification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Li, H.; Xiong, P.; An, J.; Wang, L. Pyramid attention network for semantic segmentation. arXiv 2018, arXiv:1805.10180. [Google Scholar]
- Chu, X.; Yang, W.; Ouyang, W.; Ma, C.; Yuille, A.L.; Wang, X. Multi-context attention for human pose estimation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Yuan, Y.; Wang, J. OCNet: Object context network for scene parsing. arXiv 2018, arXiv:1809.00916. [Google Scholar]
- Li, K.; Wu, Z.; Peng, K.; Ernst, J.; Fu, Y. Tell me where to look: Guided attention inference network. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Wang, X.; Girshick, R.; Gupta, A.; He, K. Non-local neural networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Ma, H.; Chu, X.; Zhang, B.; Wan, S.; Zhang, B. A matrix-in-matrix neural network for image super resolution. arXiv 2019, arXiv:1903.07949. [Google Scholar]
- Wang, X.; Wang, Q.; Zhao, Y.; Yan, J.; Fan, L.; Chen, L. Lightweight single-image super-resolution network with attentive auxiliary feature learning. arXiv 2020, arXiv:2011.06773. [Google Scholar]
- Luo, X.; Xie, Y.; Zhang, Y.; Qu, Y.; Li, C.; Fu, Y. Latticenet: Towards lightweight image super-resolution with lattice block. In Proceedings of the European Conference on Computer Vision (ECCV), Glasgow, UK, 23–28 August 2020. [Google Scholar]
- Li, F.; Cong, R.; Bai, H.; He, Y.; Zhao, Y.; Zhu, C. Learning deep interleaved networks with asymmetric co-attention for image restoration. arXiv 2020, arXiv:2010.15689. [Google Scholar]
- Muqeet, A.; Iqbal, M.T.B.; Bae, S.-H. Hybrid residual attention network for single image super resolution. arXiv 2019, arXiv:1907.05514. [Google Scholar] [CrossRef]
- Zamir, S.W.; Arora, A.; Khan, S.; Hayat, M.; Khan, F.S.; Yang, M.-H.; Shao, L. Learning enriched features for real image restoration and enhancement. In Proceedings of the European Conference on Computer Vision (ECCV), Glasgow, UK, 23–28 August 2020. [Google Scholar]
- Hu, Y.; Li, J.; Huang, Y.; Gao, X. Channel-wise and spatial feature modulation network for single image super-resolution. IEEE Trans. Circuits Syst. Video Technol. 2020, 30, 3911–3927. [Google Scholar] [CrossRef] [Green Version]
- Wang, F.; Hu, H.; Shen, C. Bam: A lightweight and efficient balanced attention mechanism for single image super resolution. arXiv 2021, arXiv:2104.07566. [Google Scholar]
- Zhang, Y.; Li, K.; Li, K.; Zhong, B.; Fu, Y. Residual non-local attention networks for image restoration. arXiv 2019, arXiv:1903.10082. [Google Scholar]
- Mei, Y.; Fan, Y.; Zhou, Y.; Huang, L.; Huang, T.S.; Shi, H. Image super-resolution with cross-scale non-local attention and exhaustive self-exemplars mining. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Liu, J.; Zhang, W.; Tang, Y.; Tang, J.; Wu, G. Residual feature aggregation network for image super-resolution. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Muqeet, A.; Hwang, J.; Yang, S.; Heum Kang, J.; Kim, Y.; Bae, S.-H. Multi-attention based ultra lightweight image super-resolution. arXiv 2020, arXiv:2008.12912. [Google Scholar]
- Zhao, H.; Kong, X.; He, J.; Qiao, Y.; Dong, C. Efficient image super-resolution using pixel attention. arXiv 2020, arXiv:2010.01073. [Google Scholar]
- Mei, Y.; Fan, Y.; Zhang, Y.; Yu, J.; Zhou, Y.; Liu, D.; Fu, Y.; Huang, T.S.; Shi, H. Pyramid attention networks for image restoration. arXiv 2020, arXiv:2004.13824. [Google Scholar]
- Huang, Y.; Li, J.; Gao, X.; Hu, Y.; Lu, W. Interpretable detail-fidelity attention network for single image super-resolution. IEEE Trans. Image Process. 2021, 30, 2325–2339. [Google Scholar] [CrossRef]
- Wu, H.; Zou, Z.; Gui, J.; Zeng, W.J.; Ye, J.; Zhang, J.; Liu, H.; Wei, Z. Multi-grained attention networks for single image super-resolution. IEEE Trans. Circuits Syst. Video Technol. 2021, 31, 512–522. [Google Scholar] [CrossRef] [Green Version]
- Chen, H.; Gu, J.; Zhang, Z. Attention in attention network for image super-resolution. arXiv 2021, arXiv:2104.09497. [Google Scholar]
- Timofte, R.; Agustsson, E.; Gool, L.V.; Yang, M.; Zhang, L.; Lim, B.; Son, S.; Kim, H.; Nah, S.; Lee, K.M.; et al. Ntire 2017 challenge on single image super-resolution: Methods and results. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Cai, J.; Zeng, H.; Yong, H.; Cao, Z.; Zhang, L. Toward real-world single image super-resolution: A new benchmark and a new model. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019. [Google Scholar]
- Bevilacqua, M.; Roumy, A.; Guillemot, C.; Alberi-Morel, M.-L. Low-complexity single image super-resolution based on nonnegative neighbor embedding. In Proceedings of the British Machine Vision Conference (BMVC), Guildford, UK, 3–7 September 2012. [Google Scholar]
- Zeyde, R.; Elad, M.; Protter, M. On single image scale-up using sparse-representations. In Proceedings of the International Conference on Curves and Surfaces (ICCS), Avignon, France, 24–30 June 2010. [Google Scholar]
- Martin, D.; Fowlkes, C.; Tal, D.; Malik, J. A database of human segmented natural images and its application to evaluating segmentation algorithms and measuring ecological statistics. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Vancouver, BC, Canada, 7–14 July 2001. [Google Scholar]
- Matsui, Y.; Ito, K.; Aramaki, Y.; Fujimoto, A.; Ogawa, T.; Yamasaki, T.; Aizawa, K. Sketch-based manga retrieval using manga109 dataset. Multimed. Tools Appl. 2017, 76, 21811–21838. [Google Scholar] [CrossRef] [Green Version]
- Wang, Z.; Bovik, A.C.; Sheikh, H.R.; Simoncelli, E.P. Image quality assessment: From error visibility to structural similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Paszke, A.; Gross, S.; Chintala, S.; Chanan, G.; Yang, E.; Devito, Z.; Lin, Z.; Desmaison, A.; Antiga, L.; Lerer, A. Automatic differentiation in pytorch. In Proceedings of the Neural Information Processing Systems Workshop (NIPSW), Long Beach, CA, USA, 9 December 2017. [Google Scholar]
- Haris, M.; Shakhnarovich, G.; Ukita, N. Deep back-projection networks for super-resolution. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Dong, C.; Loy, C.C.; Tang, X. Accelerating the super-resolution convolutional neural network. In Proceedings of the European Conference on Computer Vision (ECCV), Amsterdam, The Netherlands, 11–14 October 2016. [Google Scholar]
- Zhang, K.; Zuo, W.; Gu, S.; Zhang, L. Learning deep CNN denoiser prior for image restoration. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Li, Z.; Yang, J.; Liu, Z.; Yang, X.; Jeon, G.; Wu, W. Feedback network for image super-resolution. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Molchanov, P.; Tyree, S.; Karras, T.; Aila, T.; Kautz, J. Pruning convolutional neural networks for resource efficient inference. arXiv 2016, arXiv:1611.06440. [Google Scholar]
- Wang, Z.; Chen, J.; Hoi, S.C.H. Deep learning for image super-resolution: A survey. arXiv 2019, arXiv:1902.06068. [Google Scholar] [CrossRef] [Green Version]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Datasets | Amount | Format | Key Category |
|---|---|---|---|
| DIV2K | 1000 | PNG | animals, plants, architecture, scenery, outdoor environment, etc. |
| Set5 | 5 | PNG | baby, bird, butterfly, head, woman |
| Set14 | 14 | PNG | animals, people, flowers, vegetables, boats, bridges, slides, etc. |
| BSD100 | 100 | PNG | animals, plants, landscapes, buildings, etc. |
| Urban100 | 100 | PNG | buildings, city, etc. |
| Manga109 | 109 | PNG | manga volume |
| Real-world SR | 178 | PNG | architecture, plants, environment, handmade items, etc. |
| CDIB1 | × | × | × | × | × | × | √ | √ | √ |
| CDIB2 | × | × | × | × | × | √ | × | √ | √ |
| SAB | × | × | × | × | √ | × | × | × | √ |
| GSC | × | √ | × | √ | √ | √ | √ | √ | √ |
| LSC | × | × | √ | √ | √ | √ | √ | √ | √ |
| Params(K) | 11,809 | 11,809 | 11,809 | 11,809 | 11,854 | 11,839 | 11,839 | 11,839 | 11,854 |
| PSNR | 31.79 | 32.10 | 32.18 | 32.20 | 32.21 | 32.21 | 32.23 | 32.26 | 32.27 |
| Methods | Scale | Set5 | Set14 | BSD100 | Urban100 | Manga109 |
|---|---|---|---|---|---|---|
| PSNR/SSIM | PSNR/SSIM | PSNR/SSIM | PSNR/SSIM | PSNR/SSIM | ||
| Bicubic | 2 | 33.66/0.9299 | 30.24/0.8688 | 29.56/0.8431 | 26.88/0.8403 | 30.80/0.9339 |
| SRMDNF | 2 | 37.79/0.9601 | 33.32/0.9159 | 32.05/0.8985 | 31.33/0.9204 | 38.07/0.9761 |
| NLRN | 2 | 38.00/0.9603 | 33.46/0.9159 | 32.19/0.8992 | 31.81/0.9246 | --/-- |
| DBPN | 2 | 38.09/0.9600 | 33.85/0.9190 | 32.27/0.9000 | 32.55/0.9324 | 38.89/0.9775 |
| EDSR | 2 | 38.11/0.9601 | 33.92/0.9195 | 32.32/0.9013 | 32.93/0.9351 | 39.10/0.9773 |
| NDRCN | 2 | 37.73/0.9596 | 33.20/0.9141 | 32.00/0.8975 | 31.06/0.9175 | --/-- |
| FALSR-A | 2 | 37.82/0.9595 | 33.55/0.9168 | 32.12/0.8987 | 31.93/0.9256 | --/-- |
| OISR-RK2-s | 2 | 37.98/0.9604 | 33.58/0.9172 | 32.18/0.8996 | 32.09/0.9281 | --/-- |
| MCAN | 2 | 37.91/0.9597 | 33.69/0.9183 | 32.18/0.8994 | 32.46/0.9303 | --/-- |
| A2F-SD | 2 | 37.91/0.9602 | 33.45/0.9164 | 32.08/0.8986 | 31.79/0.9246 | 38.52/0.9767 |
| DeFiANS | 2 | 38.03/0.9605 | 33.63/0.9181 | 32.20/0.8999 | 32.20/0.9286 | 38.91/0.9775 |
| A2N-M | 2 | 38.06/0.9601 | 33.73/0.9190 | 32.22/0.8997 | 32.34/0.9300 | 38.80/0.9765 |
| IMDN | 2 | 38.00/0.9605 | 33.63/0.9177 | 32.19/0.8996 | 32.17/0.9283 | 38.88/0.9774 |
| SMSR | 2 | 38.00/0.9601 | 33.64/0.9179 | 32.17/0.8990 | 32.19/0.9284 | 38.76/0.9771 |
| PAN | 2 | 38.00/0.9605 | 33.59/0.9181 | 32.18/0.8997 | 32.01/0.9273 | 38.70/0.9773 |
| MGAN | 2 | 38.16/0.9612 | 33.83/0.9198 | 32.28/0.9009 | 32.75/0.9340 | 39.11/0.9778 |
| RNAN | 2 | 38.17/0.9611 | 33.87/0.9207 | 32.32/0.9014 | 32.73/0.9340 | 39.23/0.9785 |
| RTAN(Ours) | 2 | 38.19/0.9605 | 34.07/0.9211 | 32.37/0.9016 | 33.18/0.9372 | 39.34/0.9779 |
| Bicubic | 3 | 30.39/0.8682 | 27.55/0.7742 | 27.21/0.7385 | 24.46/0.7349 | 26.95/0.8556 |
| SRMDNF | 3 | 34.12/0.9254 | 30.04/0.8382 | 28.97/0.8025 | 27.57/0.8398 | 33.00/0.9403 |
| NLRN | 3 | 34.27/0.9266 | 30.16/0.8374 | 29.06/0.8026 | 27.93/0.8453 | --/-- |
| EDSR | 3 | 34.65/0.9282 | 30.52/0.8462 | 29.25/0.8093 | 28.80/0.8653 | 34.17/0.9476 |
| NDRCN | 3 | 33.90/0.9235 | 29.88/0.8333 | 28.86/0.7991 | 27.23/0.8312 | --/-- |
| OISR-RK2-s | 3 | 34.43/0.9273 | 30.33/0.8420 | 29.10/0.8053 | 28.20/0.8534 | --/-- |
| DeFiANS | 3 | 34.42/0.9273 | 30.34/0.8410 | 29.12/0.8053 | 28.20/0.8528 | 33.72/0.9447 |
| A2F-SD | 3 | 34.23/0.9259 | 30.22/0.8395 | 29.01/0.8028 | 27.91/0.8465 | 33.29/0.9424 |
| A2N-M | 3 | 34.50/0.9279 | 30.41/0.8438 | 29.13/0.8058 | 28.35/0.8563 | 33.79/0.9458 |
| IMDN | 3 | 34.36/0.9270 | 30.32/0.8417 | 29.09/0.8046 | 28.17/0.8519 | 33.61/0.9445 |
| SMSR | 3 | 34.40/0.9270 | 30.33/0.8412 | 29.10/0.8050 | 28.25/0.8536 | 33.68/0.9445 |
| PAN | 3 | 34.40/0.9271 | 30.36/0.8423 | 29.11/0.8050 | 28.11/0.8511 | 33.61/0.9448 |
| MCAN | 3 | 34.45/0.9271 | 30.43/0.8433 | 29.14/0.8060 | 28.47/0.8580 | --/-- |
| MGAN | 3 | 34.65/0.9292 | 30.51/0.8460 | 29.22/0.8086 | 28.61/0.8621 | 34.00/0.9474 |
| RTAN(Ours) | 3 | 34.75/0.9288 | 30.60/0.8468 | 29.28/0.8093 | 28.88/0.8669 | 34.05/0.9474 |
| Bicubic | 4 | 28.42/0.8104 | 26.00/0.7027 | 25.96/0.6675 | 23.14/0.6577 | 24.89/0.7866 |
| SRMDNF | 4 | 31.96/0.8925 | 28.35/0.7787 | 27.49/0.7337 | 25.68/0.7731 | 30.09/0.9024 |
| NLRN | 4 | 31.92/0.8916 | 28.36/0.7745 | 27.48/0.7346 | 25.79/0.7729 | --/-- |
| DBPN | 4 | 32.47/0.8980 | 28.82/0.7860 | 27.72/0.7400 | 26.38/0.7946 | 30.91/0.9137 |
| EDSR | 4 | 32.46/0.8968 | 28.80/0.7876 | 27.71/0.7420 | 26.64/0.8033 | 31.02/0.9148 |
| NDRCN | 4 | 31.50/0.8859 | 28.10/0.7697 | 27.30/0.7263 | 25.16/0.7546 | --/-- |
| OISR-RK2-s | 4 | 32.21/0.8950 | 28.63/0.7822 | 27.58/0.7364 | 26.14/0.7874 | --/-- |
| DeFiANS | 4 | 32.16/0.8942 | 28.63/0.7810 | 27.58/0.7363 | 26.10/0.7862 | 30.59/0.9084 |
| A2F-SD | 4 | 32.06/0.8928 | 28.47/0.7790 | 27.48/0.7373 | 25.80/0.7767 | 30.16/0.9038 |
| A2N-M | 4 | 32.27/0.8963 | 28.69/0.7842 | 27.61/0.7376 | 26.28/0.7919 | 30.59/0.9103 |
| IMDN | 4 | 32.21/0.8948 | 28.58/0.7811 | 27.56/0.7353 | 26.04/0.7838 | 30.45/0.9075 |
| SMSR | 4 | 32.12/0.8932 | 28.55/0.7808 | 27.55/0.7351 | 26.11/0.7868 | 30.54/0.9085 |
| PAN | 4 | 32.13/0.8948 | 28.61/0.7822 | 27.59/0.7363 | 26.11/0.7854 | 30.51/0.9095 |
| MCAN | 4 | 32.33/0.8959 | 28.72/0.7835 | 27.63/0.7378 | 26.43/0.7953 | --/-- |
| MGAN | 4 | 32.45/0.8980 | 28.74/0.7852 | 27.68/0.7400 | 26.47/0.7981 | 30.81/0.9131 |
| RNAN | 4 | 32.49/0.8982 | 28.83/0.7878 | 27.72/0.7421 | 26.61/0.8023 | 31.09/0.9149 |
| RTAN(Ours) | 4 | 32.61/0.8987 | 28.84/0.7873 | 27.77/0.7422 | 26.78/0.8068 | 31.11/0.9156 |
| Methods | Scale | Set5 | Set14 | BSD100 | Urban100 | Manga109 |
|---|---|---|---|---|---|---|
| PSNR/SSIM | PSNR/SSIM | PSNR/SSIM | PSNR/SSIM | PSNR/SSIM | ||
| Bicubic | 3 | 28.78/0.8308 | 26.38/0.7271 | 26.33/0.6918 | 23.52/0.6862 | 25.46/0.8149 |
| SPMSR | 3 | 32.21/0.9001 | 28.89/0.8105 | 28.13/0.7740 | 25.84/0.7856 | 29.64/0.9003 |
| SRCNN | 3 | 32.05/0.8944 | 28.80/0.8074 | 28.13/0.7736 | 25.70/0.7770 | 29.47/0.8924 |
| FSRCNN | 3 | 26.23/0.8124 | 24.44/0.7106 | 24.86/0.6832 | 22.04/0.6745 | 23.04/0.7927 |
| VDSR | 3 | 33.25/0.9150 | 29.46/0.8244 | 28.57/0.7893 | 26.61/0.8136 | 31.06/0.9234 |
| EDSR | 3 | 34.69/0.9278 | 30.58/0.8447 | 29.27/0.8083 | 28.64/0.8611 | 34.24/0.9470 |
| IRCNN | 3 | 33.38/0.9182 | 29.63/0.8281 | 28.65/0.7922 | 26.77/0.8154 | 31.15/0.9245 |
| SRMD | 3 | 34.01/0.9242 | 30.11/0.8364 | 28.98/0.8009 | 27.50/0.8370 | 32.97/0.9391 |
| RDN | 3 | 34.58/0.9280 | 30.53/0.8447 | 29.23/0.8079 | 28.46/0.8582 | 33.97/0.9465 |
| SRFBN | 3 | 34.66/0.9283 | 30.48/0.8439 | 29.21/0.8069 | 28.48/0.8581 | 34.07/0.9466 |
| A2F-SD | 3 | 33.81/0.9217 | 29.96/0.8337 | 28.84/0.7975 | 27.20/0.8285 | 32.54/0.9351 |
| IMDN | 3 | 34.35/0.9254 | 30.31/0.8392 | 29.08/0.8029 | 28.03/0.8472 | 33.66/0.9427 |
| DeFiANS | 3 | 34.34/0.9252 | 30.32/0.8396 | 29.08/0.8030 | 28.06/0.8478 | 33.68/0.9426 |
| PAN | 3 | 34.32/0.9260 | 30.33/0.8406 | 29.08/0.8037 | 27.93/0.8462 | 33.46/0.9431 |
| RCAN | 3 | 34.70/0.9288 | 30.63/0.8462 | 29.32/0.8093 | 28.81/0.8647 | 34.38/0.9483 |
| MGAN | 3 | 34.63/0.9284 | 30.54/0.8450 | 29.24/0.8081 | 28.51/0.8580 | 34.11/0.9467 |
| RTAN(Ours) | 3 | 34.76/0.9285 | 30.66/0.8462 | 29.33/0.8090 | 28.90/0.8649 | 34.39/0.9478 |
| Methods | Params | Scale | Canon PSNR/SSIM | Nikon PSNR/SSIM |
|---|---|---|---|---|
| CARN | 1.59M | 4 | 29.14/0.8336 | 28.42/0.7931 |
| EDSR | 43M | 4 | 29.56/0.8249 | 28.35/0.7986 |
| RCAN | 16M | 4 | 29.79/0.8473 | 28.64/0.8035 |
| IMDN | 0.72M | 4 | 28.95/0.8371 | 28.50/0.7916 |
| RNAN | 9.3M | 4 | 29.44/0.8408 | 28.61/0.8029 |
| LP-KPN | 5.73M | 4 | 29.52/0.8430 | 27.54/0.7923 |
| DeFiANs | 1.06M | 4 | 29.37/0.8390 | 28.60/0.7967 |
| MIRNet | 31.8M | 4 | 29.86/0.8495 | 28.63/0.8034 |
| RTAN(Ours) | 9.6M | 4 | 29.93/0.8504 | 28.86/0.8071 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Huang, F.; Wang, Z.; Wu, J.; Shen, Y.; Chen, L. Residual Triplet Attention Network for Single-Image Super-Resolution. Electronics 2021, 10, 2072. https://doi.org/10.3390/electronics10172072
Huang F, Wang Z, Wu J, Shen Y, Chen L. Residual Triplet Attention Network for Single-Image Super-Resolution. Electronics. 2021; 10(17):2072. https://doi.org/10.3390/electronics10172072
Chicago/Turabian StyleHuang, Feng, Zhifeng Wang, Jing Wu, Ying Shen, and Liqiong Chen. 2021. "Residual Triplet Attention Network for Single-Image Super-Resolution" Electronics 10, no. 17: 2072. https://doi.org/10.3390/electronics10172072