
Privacy Assessment in Android Apps: A Systematic Mapping Study


Abstract
:1. Introduction
2. Background
2.1. Privacy Assessment
2.2. Assessment Techniques

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Privacy Threat | Description |
|---|---|
| Linkability | “An adversary is able to link two items of interest without knowing the identity of the data subject(s) involved.” [11]. |
| Identifiability | “An adversary is able to identify a data subject from a set of data subjects through an item of interest.” [11]. |
| Non-repudiation | “The data subject is unable to deny a claim (e.g., having performed an action, or sent a request).” [11]. |
| Detectability | “An adversary is able to distinguish whether an item of interest about a data subject exists or not, regardless of being able to read the contents itself.” [11]. |
| Disclosure of information | “An adversary is able to learn the content of an item of interest about a data subject.” [11]. |
| Unawareness | “The data subject is unaware of the collection, processing, storage, or sharing activities (and corresponding purposes) of the data subject’s personal data.” [11]. Unawareness relates to the transparency measures that a system can take to guide and educate the user concerning the personal data processing (e.g., collection and disclosure) and nudge the user into a more privacy-aware use of the system [12]. |
| Non-compliance | “The processing, storage, or handling of personal data is not compliant with legislation, regulation, and/or policy.” [11]. We are further interested in the particular regulation/standard being evaluated (e.g., GDPR, COPPA) and, if mentioned, the concrete principle (e.g., purpose limitation of GDPR). |
| Lack of control | Control enables users to decide what kind or information is processed about them. Focusing on data protection rights, “Intervenability is defined as the property that intervention is possible concerning all ongoing or planned [personal] data processing.” [12]. Intervenability enables, e.g., to exercise the individuals’ rights to rectification and erasure of personal data, providing and withdrawing consent, and so on. |
| Assessment Approach | Description |
|---|---|
| Issue detection | The assessment aims to find privacy-related defects, i.e., a vulnerability or deficiency that potentially may threaten a privacy aspect. A detection technique seeks to find defects or defect patterns already known. For example, dynamic permission requests with missing revocation statements. |
| Specification verification | The assessment aims to verify that an app or its components meet a specification, which can stem, e.g., from a policy or regulation. For example, verifying whether a personal data flow complies with a privacy policy. |
| Risk assessment | The evaluation aims to understand the privacy risk posed by an app. Note that the source of risk may vary, and different authors may consider different aspects to assess the risk e.g., permissions, network connections, etc. The risk assessment output may be qualitative (e.g., a risk level) or quantitative (e.g., a risk score). |
2.3. Technique Quality
3. Methodology
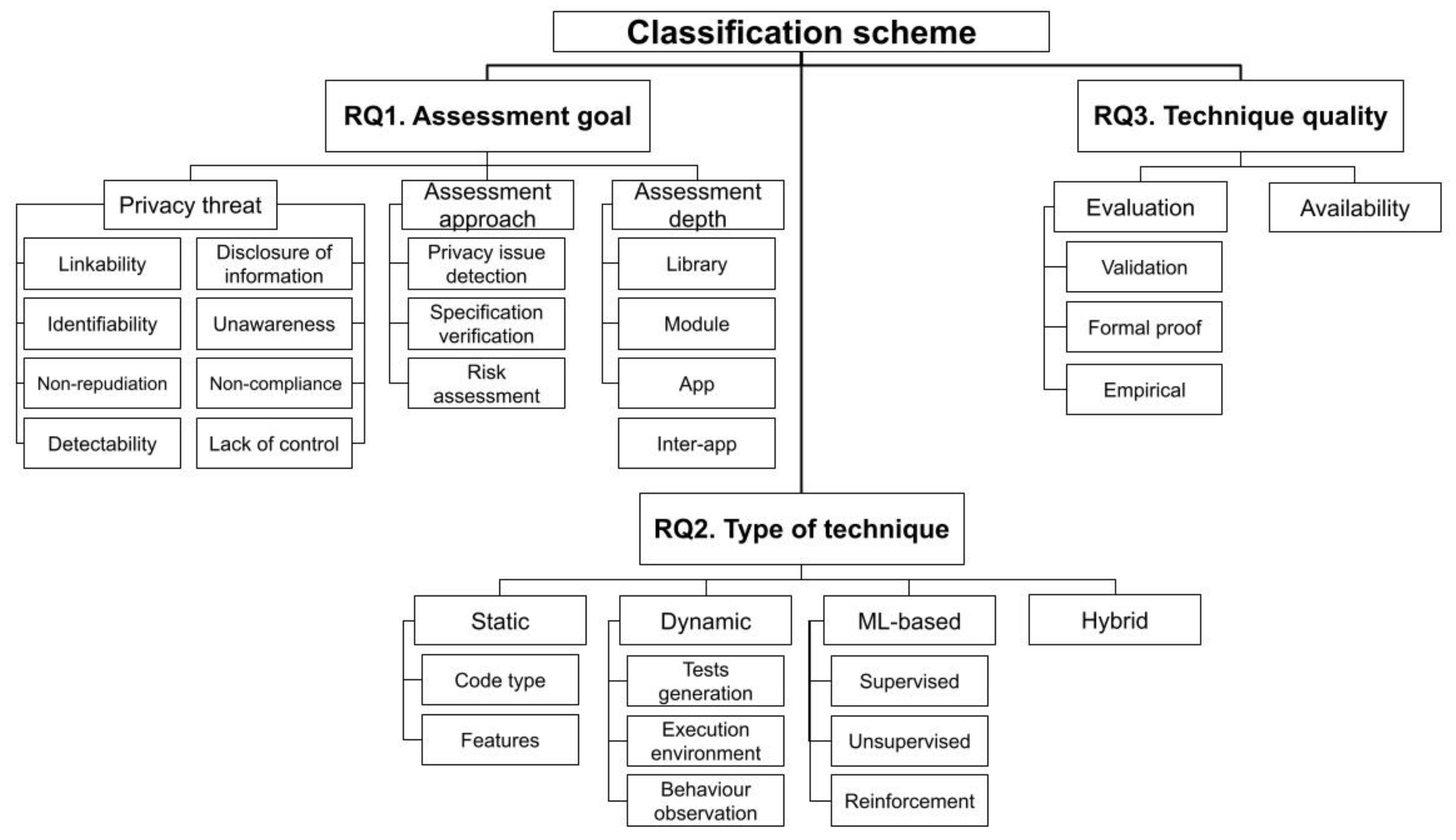
3.1. Scope and Research Questions
- RQ1.
- What privacy issues have been assessed in Android apps? We aim to gain knowledge about the privacy threats that have been evaluated, the approaches taken, and the level of detail reached.
- RQ2.
- What techniques are used to assess these privacy issues? Our goal is to understand what type of techniques have been proposed for finding privacy related anomalies, their status and current challenges.
- RQ3.
- What is the quality level of the techniques identified? We are interested in investigating the quality level of the techniques and tools found, to identify those worth following or applying.
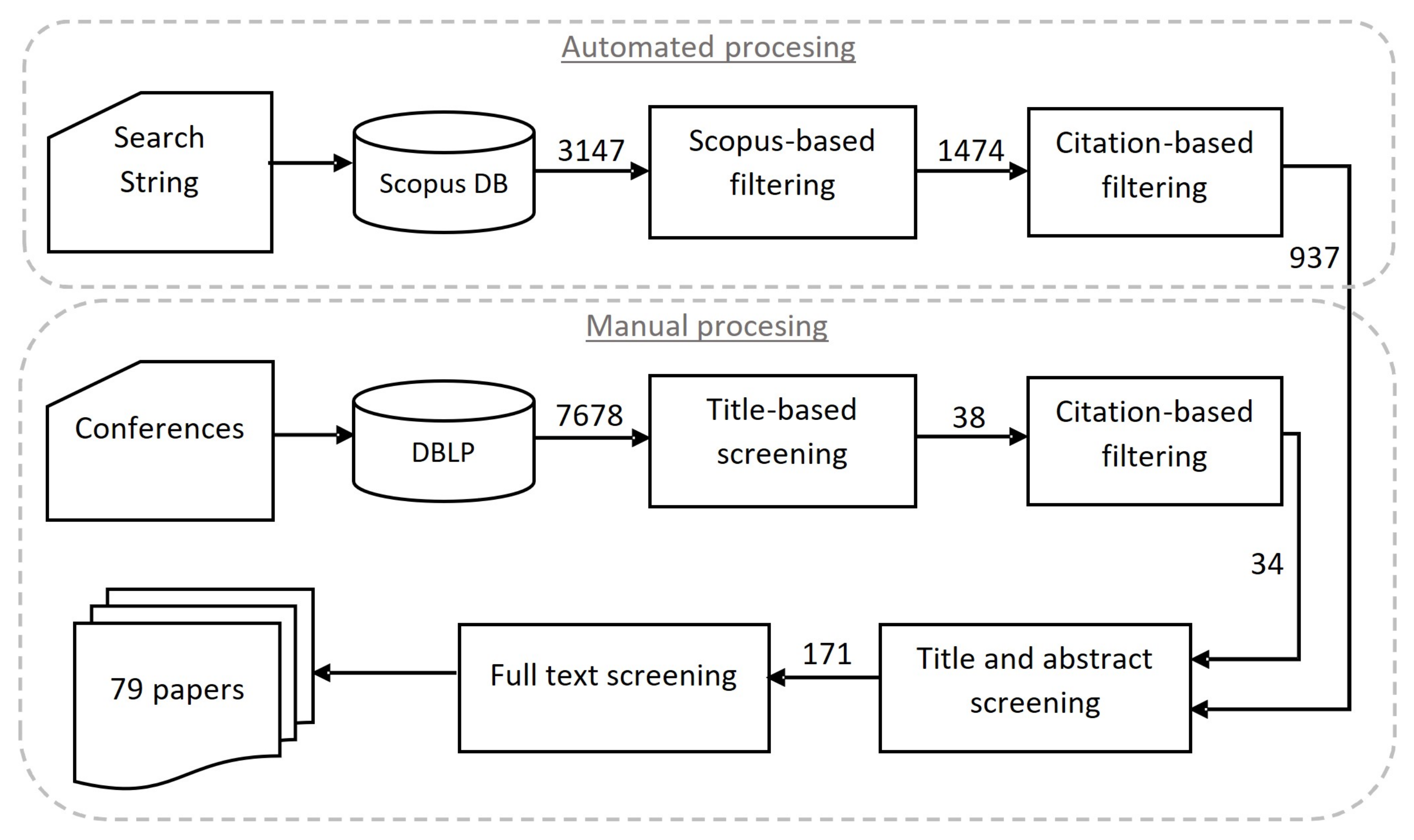
3.2. Paper Search Strategy
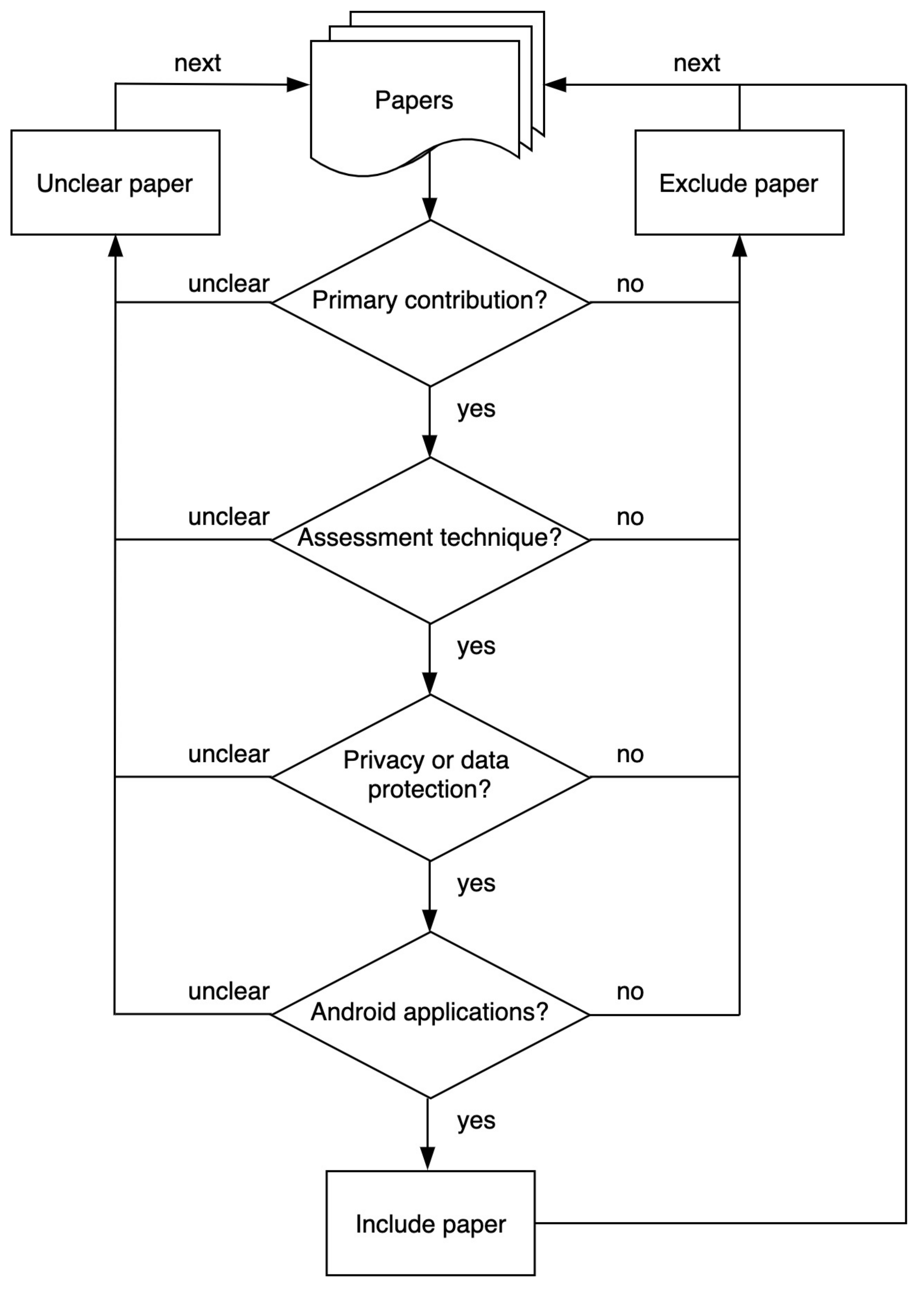
3.3. Inclusion and Exclusion Procedure
3.3.1. Automated Inclusion—Exclusion Procedure
- Research Field: computer science, engineering, decision sciences, or multidisciplinary.
- Publication date: >2015. Note that the paper selection phase of this study took place in the first half of October 2020. Only papers included in Scopus until September 2020 are included in our search.
- Document type: conference paper and article.
- Language: English.
- Number of pages: we are looking for papers proposing contributions with some form of validation, and this requires extensive works with detailed publications. Thus, we exclude short papers, i.e., heuristically, papers with less than five pages. If no page numbers are reported then the paper is included.
| Publishing Year | Minimum Citations |
|---|---|
| 2016 | 4 |
| 2017 | 3 |
| 2018 | 2 |
| 2019 | 1 |
| 2020 | 0 |

3.3.2. Manual Inclusion—Exclusion Procedure

3.4. Classification Scheme and Procedure

4. Results
4.1. RQ1: What Privacy Issues Have Been Assessed in Android Apps?
| Disclosure of Information | Non-Compliance | Identifiability | |
|---|---|---|---|
| Library | 2 | 0 | 0 |
| Module | 0 | 0 | 0 |
| Application | 51 | 0 | 0 |
| Inter-Application | 10 | 0 | 0 |
| Total | 63 | 0 | 0 |
| Disclosure of Information | Non-Compliance | Identifiability | |
|---|---|---|---|
| Library | 2 | 0 | 0 |
| Module | 0 | 0 | 0 |
| Application | 13 | 0 | 1 |
| Inter-Application | 0 | 0 | 0 |
| Total | 15 | 0 | 1 |
| Disclosure of Information | Non-Compliance | Identifiability | |
|---|---|---|---|
| Library | 0 | 0 | 0 |
| Module | 0 | 0 | 0 |
| Application | 0 | 7 | 0 |
| Inter-Application | 0 | 0 | 0 |
| Total | 0 | 7 | 0 |
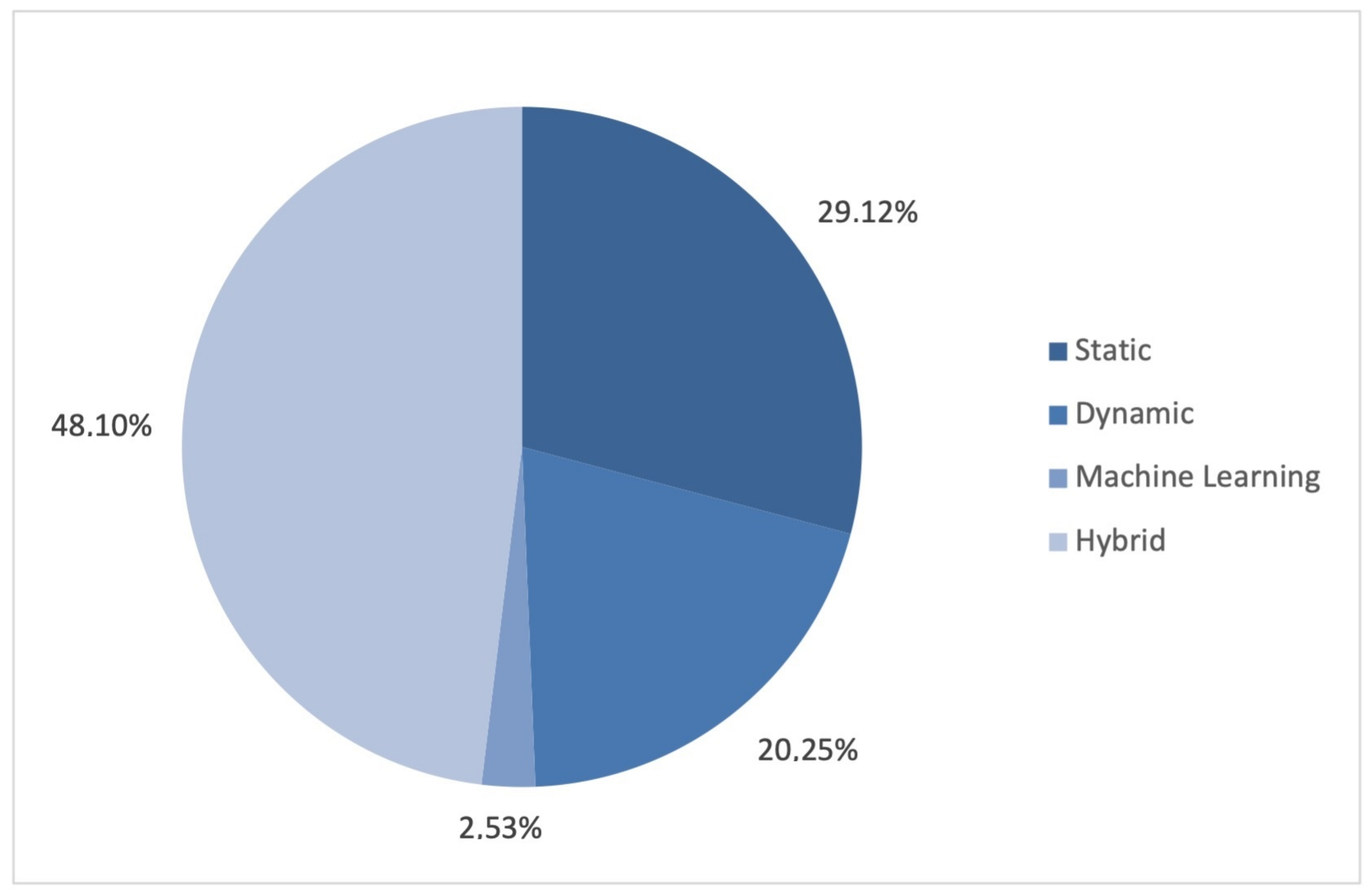
4.2. RQ2: What Techniques Have Been Used to Assess Apps’ Privacy?
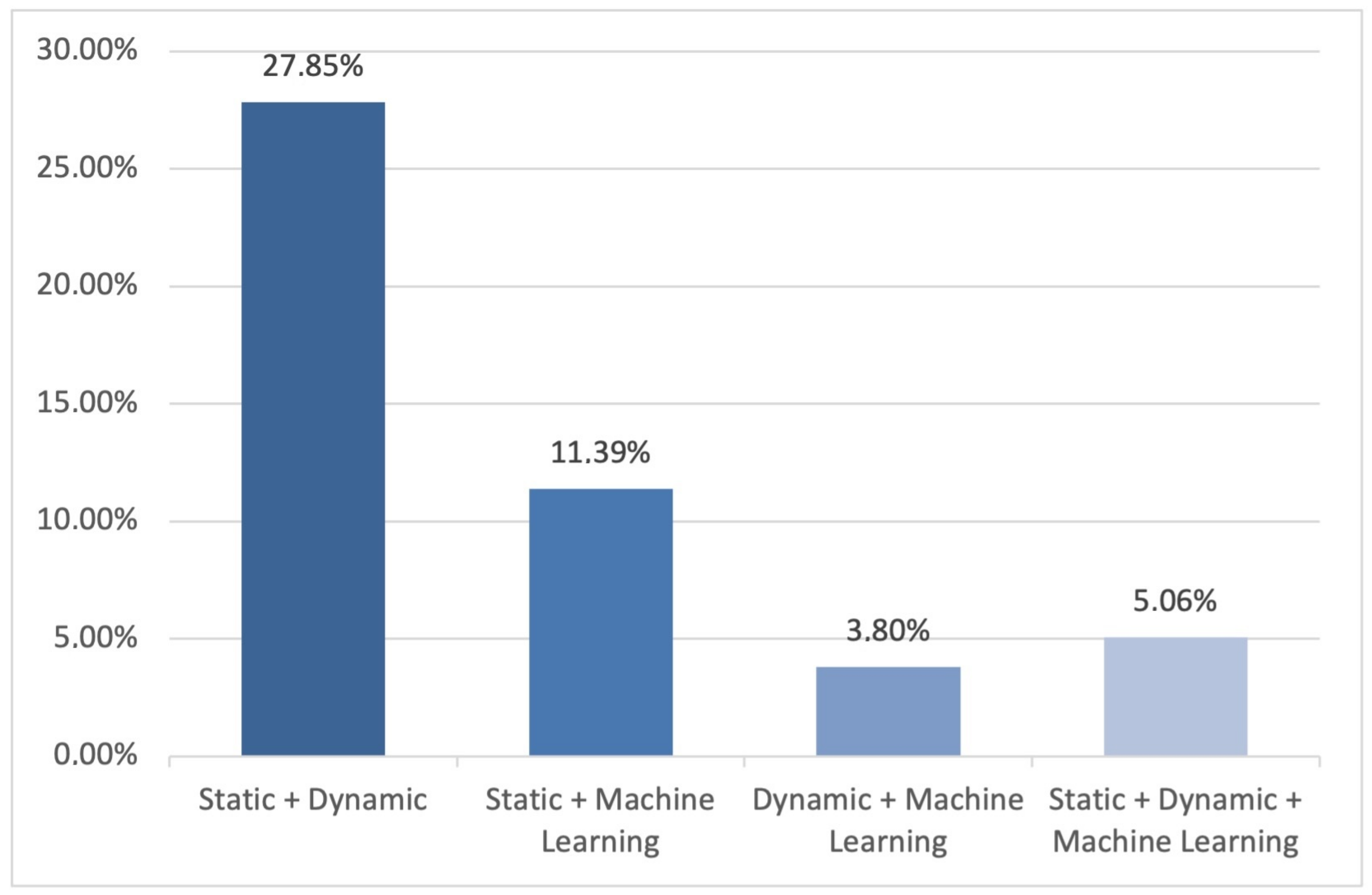
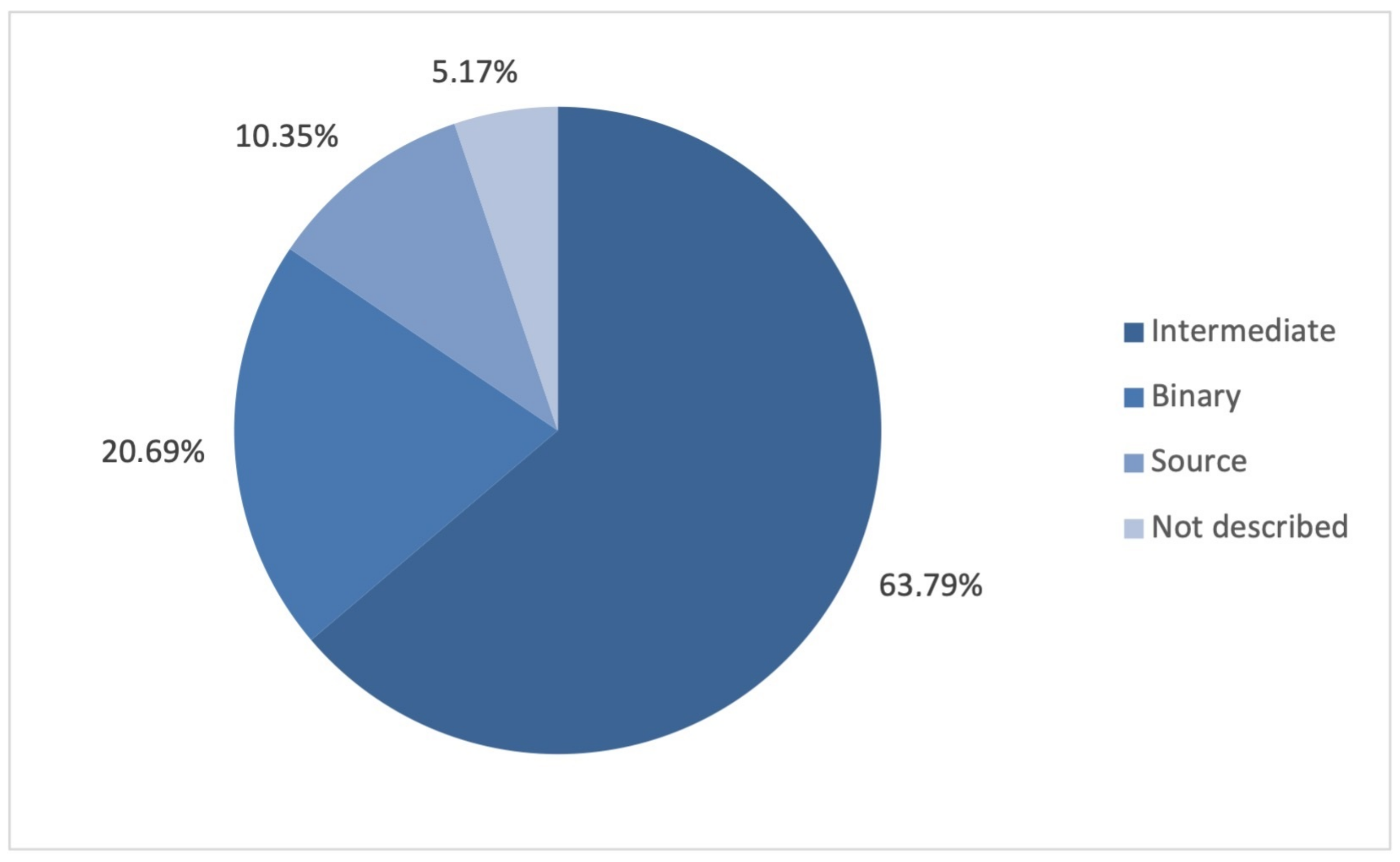
4.2.1. Static Analysis
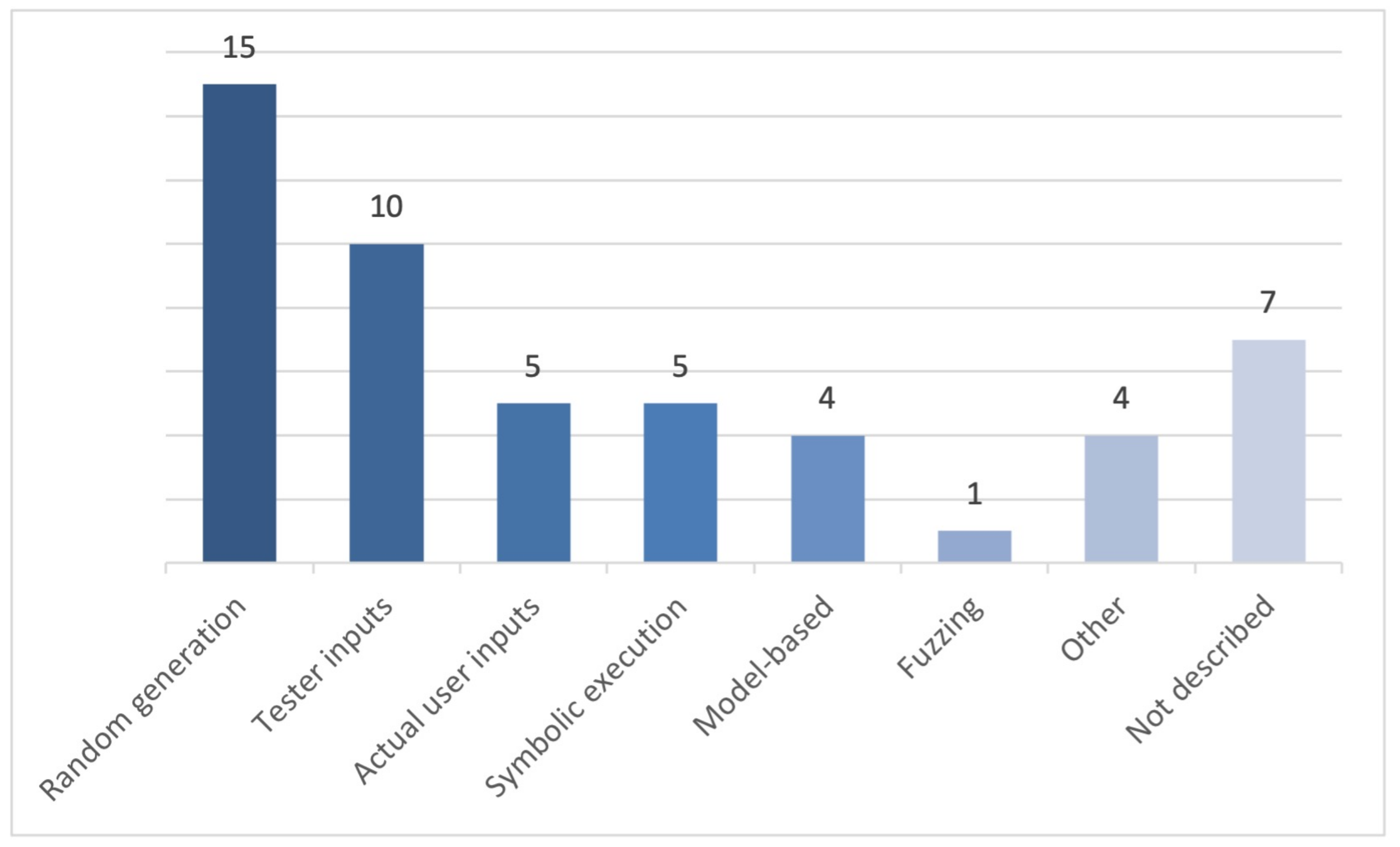
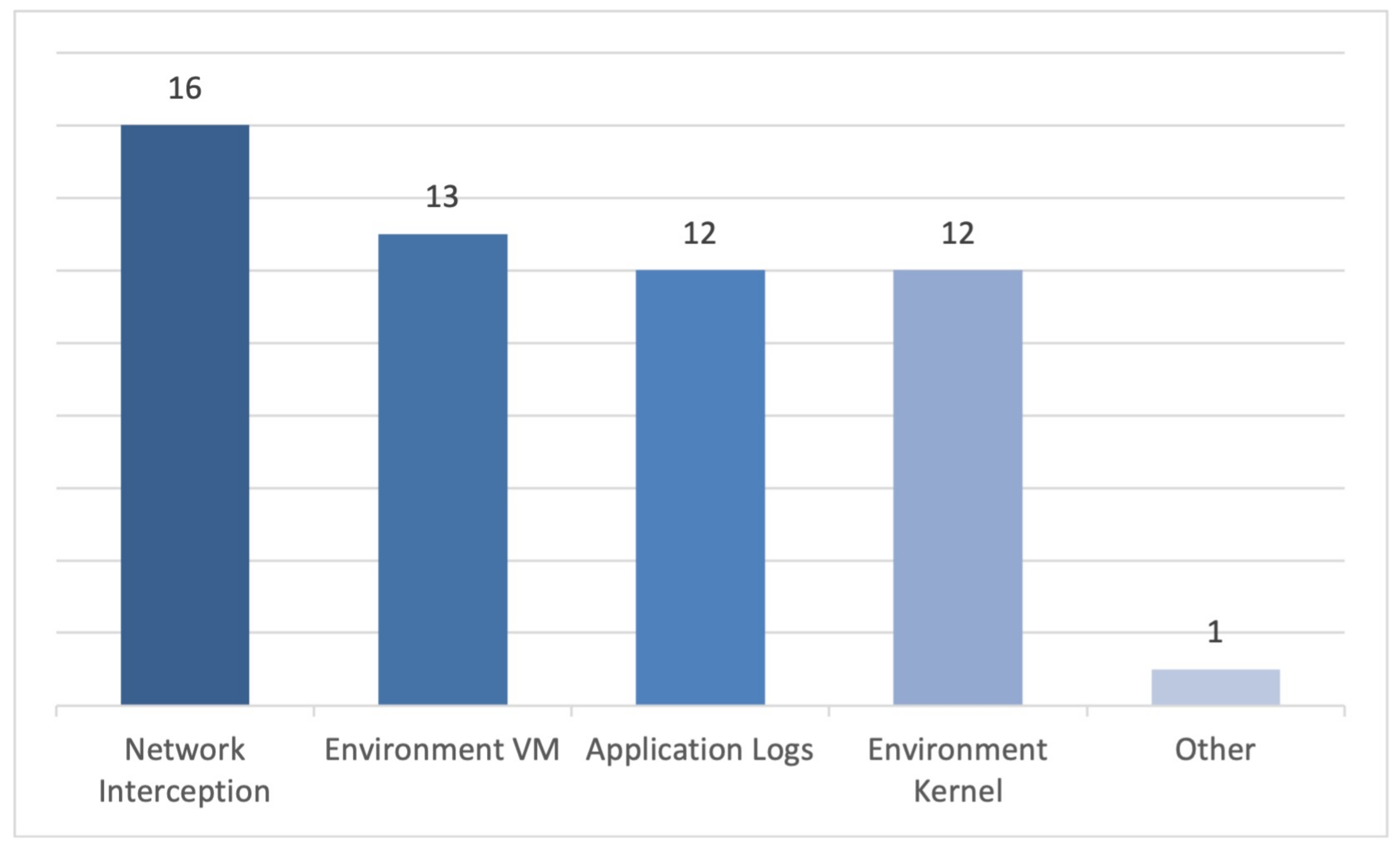
4.2.2. Dynamic Analysis
- Application instrumentation: this is one of the most complex techniques because it requires the modification of the app code to introduce code snippets that log the app status or behaviour at different points. This implies obtaining the application code, changing it, and repackaging it. This procedure heavily depends on the API version. As an advantage, this technique gives a greater insight on the app internals.
- Virtual Machine instrumentation: this technique requires an instrumented version of the Android Virtual Machine to observe the different API calls of the tested app. Unfortunately, this instrumentation is tight to the system version, thus making it very difficult to keep updated. The paradigmatic example was TaintDroid (ID247), which has been extensively used for Android apps assessment but is now deprecated.
- Kernel instrumentation: These tools observe the behaviour of the app at the kernel level. To this end, a modification to the operating system is required, generating again a great dependency on the system version. One of the most widespread tools was Xposed, which is now deprecated too. Some alternatives currently available are Frida or Magisk.
- Network interception: this technique is one of the easiest ways of behavioural observation. It does not require modifying the app code, can be used with both devices and emulators, and does not depend on the Android version. Tools such as tcpdump, Wireshark, or a Man In The Middle (MITM) Proxy can be used to monitor the network traffic. On the downside, the communication payload can be encoded or the channel secured, thus making the detection of data leaks cumbersome.

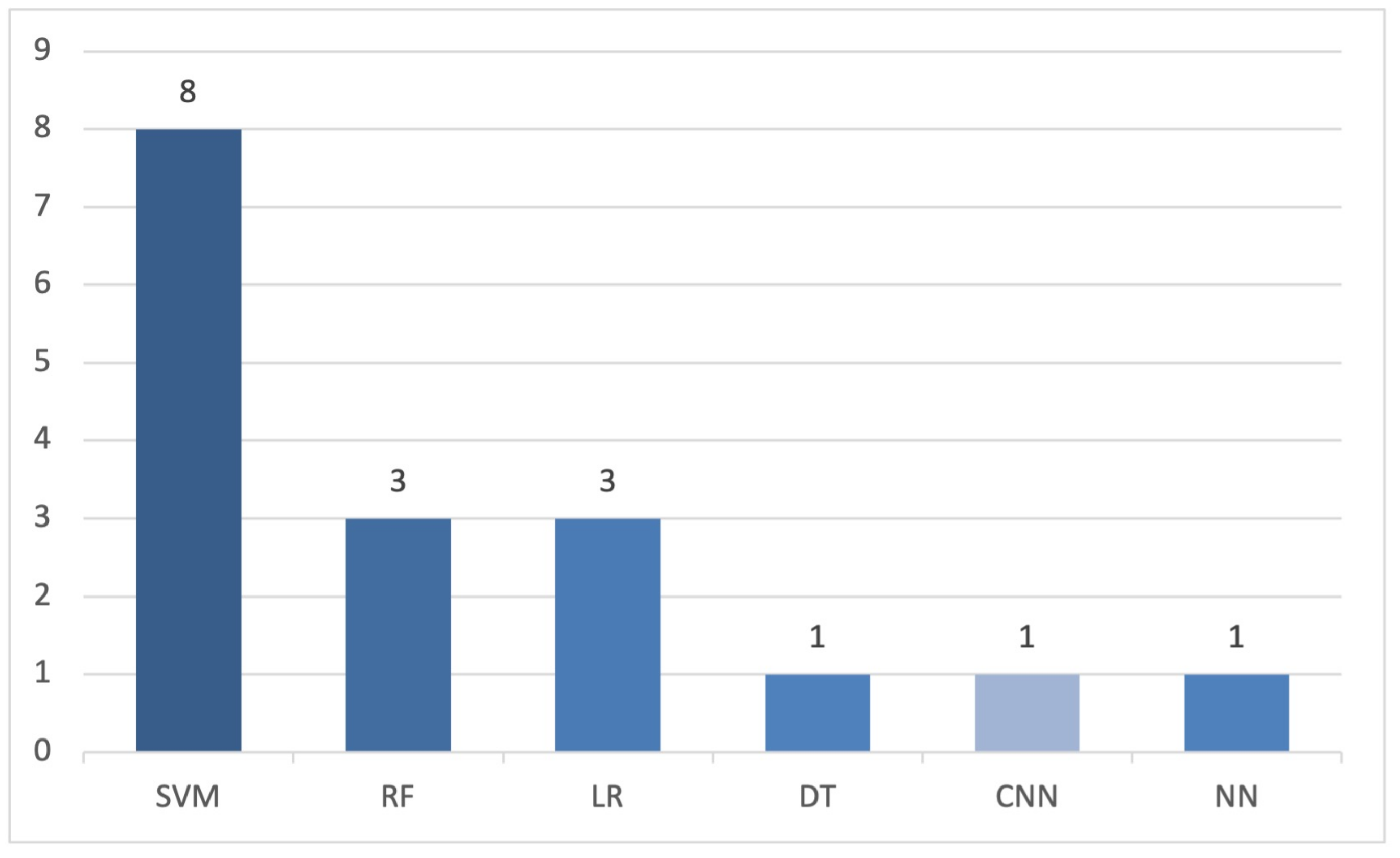
4.2.3. Machine Learning-Based Analysis
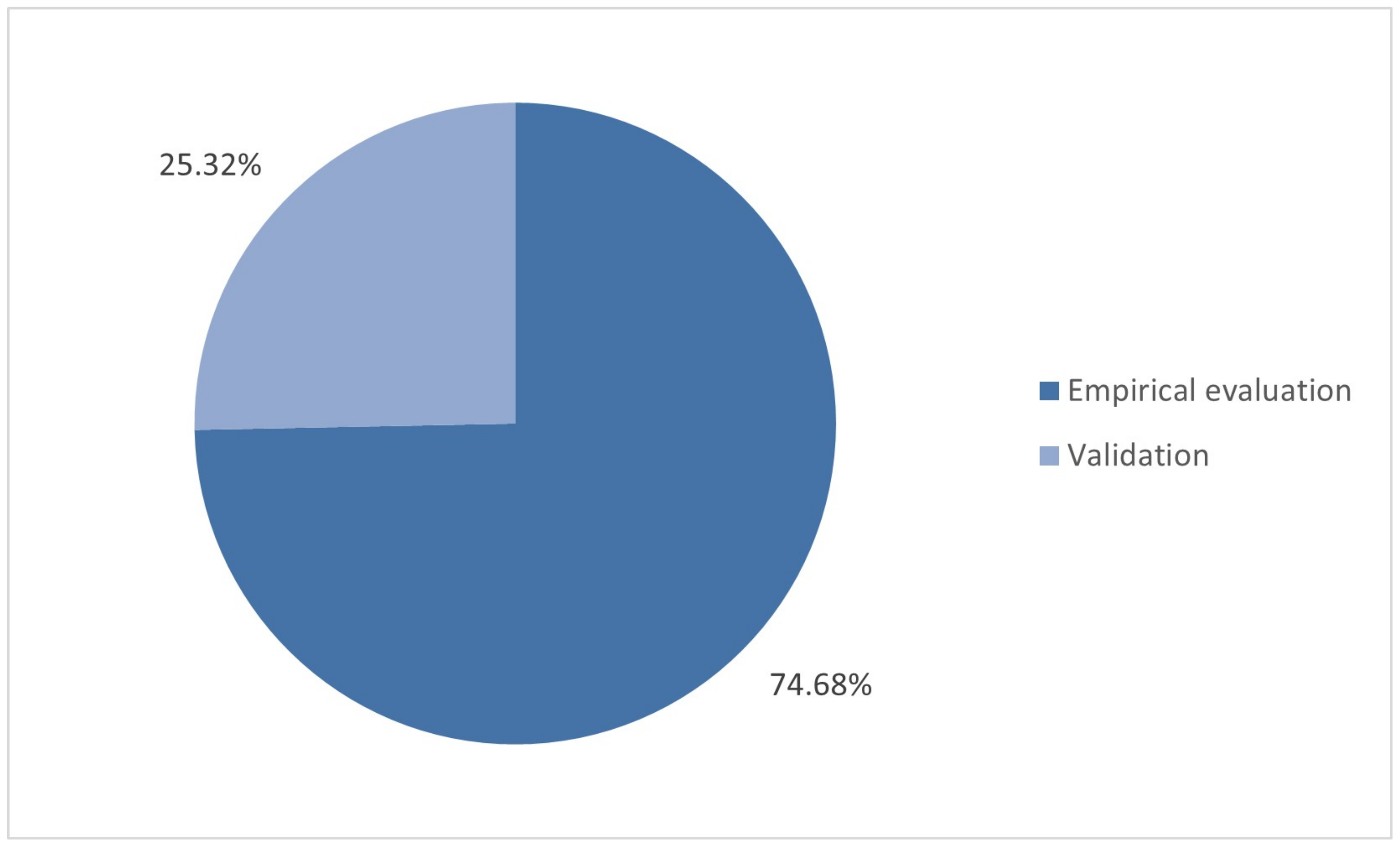
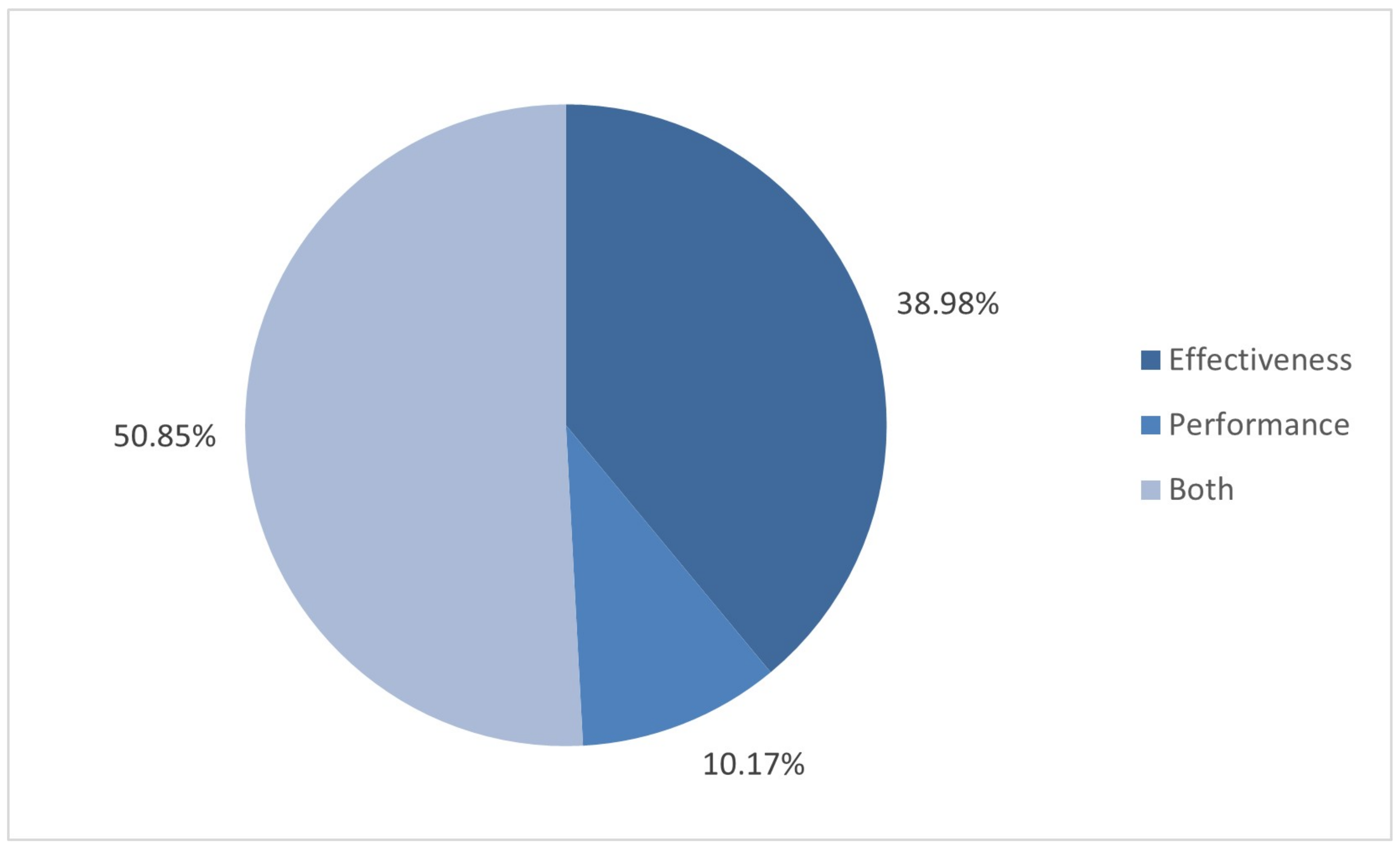
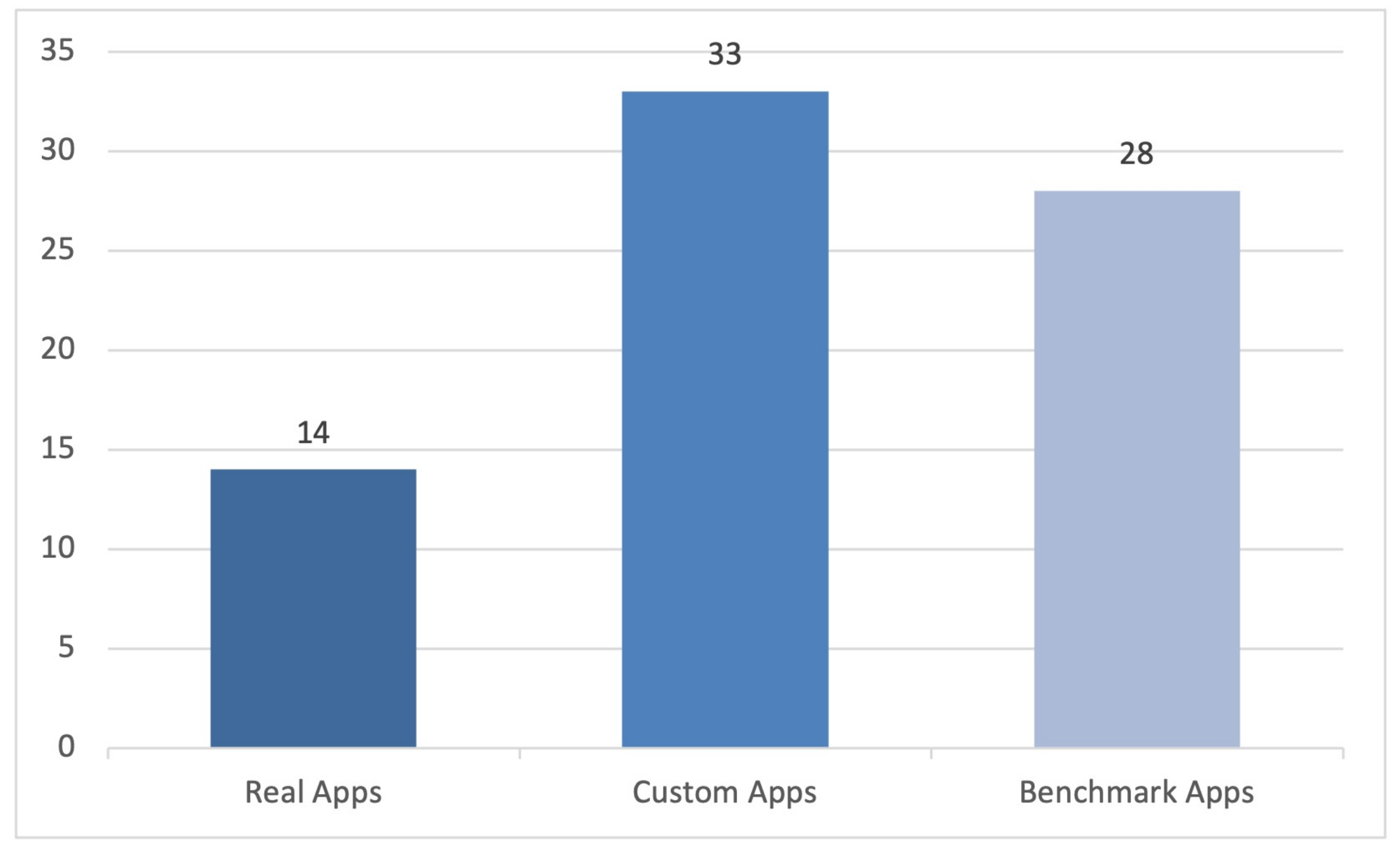
4.3. RQ3: What Is the Quality Level of the Techniques Identified?
| Name | Description | Samples | Last Updated |
|---|---|---|---|
| Droidbench (https://github.com/secure-software-engineering/DroidBench) 2.0/3.0 | Apps covering several types of data leaks | 120 (2.0); 146 (3.0) | 2016 |
| Icc bench (https://github.com/fgwei/ICC-Bench) | Apps with inter-component data leaks | 24 | 2017 |
| F-droid (https://f-droid.org/en/packages/) | General apps (no privacy-related) | 3696 | 2020 |
| Mudflow (https://www.st.cs.uni-saarland.de/appmining/mudflow/) | Apps with abnormal personal data use | 2866 | 2018 |
| Drebin (https://www.sec.cs.tu-bs.de/~danarp/drebin/) | Malware apps | 5560 | 2014 |
| VirusShare (https://virusshare.com/) | Malware apps | 36,643,433 | 2020 |
| Contagio Mobile (http://contagiominidump.blogspot.com/) | Malware apps | 131 | 2018 |
| MobSecLab (http://mobseclab.gazi.edu.tr/datasets/) | Bening apps | 1074 | 2017 |
5. Discussion
5.1. A Switch in Privacy Paradigms
5.2. From Policy Compliance to Legal Compliance
5.3. App Developers Need More Support
5.4. Changes on Apps Delivery Practices
6. Threats to Validity
6.1. Construct Validity
6.2. Internal Validity
6.3. External Validity
7. Related Work
8. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Appendix A. The Full List of Examined Publications
| ID1 | Y. Nan, Z. Yang, X. Wang, Y. Zhang, D. Zhu, M. Yang, Finding Clues for Your Secrets: Semantics-Driven, Learning-Based Privacy Discovery in Mobile Apps, in: Proc. 2018 Netw. Distrib. Syst. Secur. Symp., Internet Society, Reston, VA, 2018. https://doi.org/10.14722/ndss.2018.23092. |
| ID3 | Y. He, B. Hu, Z. Han, Dynamic privacy leakage analysis of android third-party libraries, in: Proc.—2018 1st Int. Conf. Data Intell. Secur. ICDIS 2018, Institute of Electrical and Electronics Engineers Inc., 2018: pp. 275–280. https://doi.org/10.1109/ICDIS.2018.00051. |
| ID8 | A. Rahman, P. Pradhan, A. Partho, L. Williams, Predicting AndroApplication Security and Privacy Risk with Static Code Metrics, in: Proc.—2017 IEEE/ACM 4th Int. Conf. Mob. Softw. Eng. Syst. MOBILESoft 2017, Institute of Electrical and Electronics Engineers Inc., 2017: pp. 149–153. https://doi.org/10.1109/MOBILESoft.2017.14. |
| ID38 | A. Continella, Y. Fratantonio, M. Lindorfer, A. Puccetti, A. Zand, C. Kruegel, G. Vigna, Obfuscation-Resilient Privacy Leak Detection for Mobile Apps Through Differential Analysis, in: Proc. 2017 Netw. Distrib. Syst. Secur. Symp., Internet Society, Reston, VA, 2017. https://doi.org/10.14722/ndss.2017.23465. |
| ID60 | C. Han, I. Reyes, βü. Feal, J. Reardon, P. Wijesekera, N. Vallina-Rodriguez, A. Elazari, K.A. Bamberger, S. Egelman, The Price is (Not) Right: Comparing Privacy in Free and PaApps, Proc. Priv. Enhancing Technol. 2020 (2020) 222-242. https://doi.org/10.2478/popets-2020-0050. |
| ID77 | L. Li, T.F. Bissyandé, D. Octeau, J. Klein, DroidRA: Taming reflection to support whole-program analysis of androapps, in: ISSTA 2016—Proc. 25th Int. Symp. Softw. Test. Anal., Association for Computing Machinery, Inc, 2016: pp. 318–329. https://doi.org/10.1145/2931037.2931044. |
| ID81 | A. Tiwari, S. Groβƒ, C. Hammer, IIFA: Modular Inter-app Intent Information Flow Analysis of AndroApplications, in: Lect. Notes Inst. Comput. Sci. Soc. Telecommun. Eng. LNICST, Springer, 2019: pp. 335–349. https://doi.org/10.1007/978-3-030-37231-6_19. |
| ID88 | V. Sihag, A. Swami, M. Vardhan, P. Singh, Signature based malicious behavior detection in android, in: Commun. Comput. Inf. Sci., Springer, 2020: pp. 251–262. https://doi.org/10.1007/978-981-15-6648-6_20. |
| ID89 | J. Bai, W. Wang, Y. Qin, S. Zhang, J. Wang, Y. Pan, BridgeTaint: A Bi-Directional Dynamic Taint Tracking Method for JavaScript Bridges in AndroHybrApplications, IEEE Trans. Inf. Forensics Secur. 14 (2019) 677–692. https://doi.org/10.1109/TIFS.2018.2855650. |
| ID93 | V. Jain, S. Bhandari, V. Laxmi, M.S. Gaur, M. Mosbah, SniffDroid: Detection of Inter-App Privacy Leaks in Android, in: 2017 IEEE Trust., IEEE, 2017: pp. 331–338. https://doi.org/10.1109/Trustcom/BigDataSE/ICESS.2017.255. |
| ID94 | S. Zimmeck, P. Story, D. Smullen, A. Ravichander, Z. Wang, J. Reidenberg, N. Cameron Russell, N. Sadeh, MAPS: Scaling Privacy Compliance Analysis to a Million Apps, Proc. Priv. Enhancing Technol. 2019 (2019) 66–86. https://doi.org/10.2478/popets-2019-0037. |
| ID104 | Y. Yang, W. Luo, Y. Pei, M. Pan, T. Zhang, Execution enhanced static detection of androprivacy leakage hidden by dynamic class loading, in: Proc. - Int. Comput. Softw. Appl. Conf., IEEE Computer Society, 2019: pp. 149-158. https://doi.org/10.1109/COMPSAC.2019.00029. |
| ID108 | L. Xue, C. Qian, H. Zhou, X. Luo, Y. Zhou, Y. Shao, A.T.S. Chan, NDroid: Toward tracking information flows across multiple androcontexts, IEEE Trans. Inf. Forensics Secur. 14 (2019) 814–828. https://doi.org/10.1109/TIFS.2018.2866347. |
| ID117 | K. Zhu, X. He, B. Xiang, L. Zhang, A. Pattavina, How dangerous are your Smartphones? App usage recommendation with privacy preserving, Mob. Inf. Syst. 2016 (2016). https://doi.org/10.1155/2016/6804379. |
| ID119 | G. Bai, Q. Ye, Y. Wu, H. Botha, J. Sun, Y. Liu, J.S. Dong, W. Visser, Towards Model Checking AndroApplications, IEEE Trans. Softw. Eng. 44 (2018) 595–612. https://doi.org/10.1109/TSE.2017.2697848. |
| ID126 | P. Feng, J. Ma, C. Sun, Selecting Critical Data Flows in AndroApplications for Abnormal Behavior Detection, Mob. Inf. Syst. 2017 (2017). https://doi.org/10.1155/2017/7397812. |
| ID129 | N. Wongwiwatchai, P. Pongkham, K. Sripanidkulchai, Detecting personally identifiable information transmission in androapplications using light-weight static analysis, Comput. Secur. 99 (2020) 102011. https://doi.org/10.1016/j.cose.2020.102011. |
| ID141 | K. Alkhattabi, A. Alshehri, C. Yue, Security and Privacy Analysis of AndroFamily Locator Apps, in: Proc. 25th ACM Symp. Access Control Model. Technol., ACM, New York, NY, USA, 2020: pp. 47–58. https://doi.org/10.1145/3381991.3395612. |
| ID179 | M. Backes, S. Bugiel, E. Derr, S. Gerling, C. Hammer, R-Droid: Leveraging androapp analysis with static slice optimization, in: ASIA CCS 2016—Proc. 11th ACM Asia Conf. Comput. Commun. Secur., Association for Computing Machinery, Inc, 2016: pp. 129–140. https://doi.org/10.1145/2897845.2897927. |
| ID196 | R. Binns, U. Lyngs, M. Van Kleek, J. Zhao, T. Libert, N. Shadbolt, Third party tracking in the mobile ecosystem, in: WebSci 2018—Proc. 10th ACM Conf. Web Sci., Association for Computing Machinery, Inc, 2018: pp. 23–31. https://doi.org/10.1145/3201064.3201089. |
| ID224 | M. Junaid, D. Liu, D. Kung, Dexteroid: Detecting malicious behaviors in Androapps using reverse-engineered life cycle models, Comput. Secur. 59 (2016) 92–117. https://doi.org/10.1016/j.cose.2016.01.008. |
| ID240 | S. Bhandari, F. Herbreteau, V. Laxmi, A. Zemmari, P.S. Roop, M.S. Gaur, SneakLeak: Detecting Multipartite Leakage Paths in AndroApps, in: 2017 IEEE Trust., IEEE, 2017: pp. 285–292. https://doi.org/10.1109/Trustcom/BigDataSE/ICESS.2017.249. |
| ID247 | W. Enck, P. Gilbert, S. Han, V. Tendulkar, B.G. Chun, L.P. Cox, J. Jung, P. McDaniel, A.N. Sheth, TaintDroid: An information-flow tracking system for realtime privacy monitoring on smartphones, ACM Trans. Comput. Syst. 32 (2014) 1–29. https://doi.org/10.1145/2619091. |
| ID249 | H. Xu, Y. Zhou, C. Gao, Y. Kang, M.R. Lyu, SpyAware: Investigating the privacy leakage signatures in app execution traces, in: 2015 IEEE 26th Int. Symp. Softw. Reliab. Eng. ISSRE 2015, Institute of Electrical and Electronics Engineers Inc., 2016: pp. 348–358. https://doi.org/10.1109/ISSRE.2015.7381828. |
| ID272 | S. Pooryousef, M. Amini, Enhancing accuracy of andromalware detection using intent instrumentation, in: ICISSP 2017—Proc. 3rd Int. Conf. Inf. Syst. Secur. Priv., SciTePress, 2017: pp. 380–388. https://doi.org/10.5220/0006195803800388. |
| ID281 | L. Yu, X. Luo, C. Qian, S. Wang, H.K.N. Leung, Enhancing the Description-to-Behavior Fidelity in AndroApps with Privacy Policy, IEEE Trans. Softw. Eng. 44 (2018) 834–854. https://doi.org/10.1109/TSE.2017.2730198. |
| ID294 | N.T. Cam, V.H. Pham, T. Nguyen, Detecting sensitive data leakage via inter-applications on Androusing a hybranalysis technique, Cluster Comput. 22 (2019) 1055–1064. https://doi.org/10.1007/s10586-017-1260-2. |
| ID302 | V. Jain, V. Laxmi, M.S. Gaur, M. Mosbah, APPLADroid: Automaton based inter-app privacy leak analysis for android, in: Commun. Comput. Inf. Sci., Springer Verlag, 2019: pp. 219–233. https://doi.org/10.1007/978-981-13-7561-3_16. |
| ID306 | S. Demetriou, W. Merrill, W. Yang, A. Zhang, C.A. Gunter, Free for All! Assessing User Data Exposure to Advertising Libraries on Android, in: Proc. 2016 Netw. Distrib. Syst. Secur. Symp., Internet Society, Reston, VA, 2016. https://doi.org/10.14722/ndss.2016.23082. |
| ID323 | S. Zimmeck, Z. Wang, L. Zou, R. Iyengar, B. Liu, F. Schaub, S. Wilson, N. Sadeh, S.M. Bellovin, J. Reidenberg, Automated analysis of privacy requirements for mobile apps, in: AAAI Fall Symp.—Tech. Rep., AI Access Foundation, 2016: pp. 286–296. https://doi.org/10.14722/ndss.2017.23034. |
| ID329 | H. Cui, S. Shao, S. Niu, W. Zhang, Y. Yuan, Container-based privacy preserving scheme for androapplications, Chinese J. Electron. 29 (2020) 731–737. https://doi.org/10.1049/cje.2020.06.001. |
| ID342 | M. Hatamian, J. Serna, K. Rannenberg, Revealing the unrevealed: Mining smartphone users privacy perception on app markets, Comput. Secur. 83 (2019) 332–353. https://doi.org/10.1016/j.cose.2019.02.010. |
| ID349 | Y. Li, G. Xu, H. Xian, L. Rao, J. Shi, Novel andromalware detection method based on multi-dimensional hybrfeatures extraction and analysis, Intell. Autom. Soft Comput. 25 (2019) 637–647. https://doi.org/10.31209/2019.100000118. |
| ID352 | A. Alzaidi, S. Alshehri, S.M. Buhari, DroidRista: a highly precise static data flow analysis framework for androapplications, Int. J. Inf. Secur. 19 (2020) 523–536. https://doi.org/10.1007/s10207-019-00471-w. |
| ID361 | J. Qiu, J. Zhang, W. Luo, L. Pan, S. Nepal, Y. Wang, Y. Xiang, A3CM: Automatic Capability Annotation for AndroMalware, IEEE Access. 7 (2019) 147156–147168. https://doi.org/10.1109/ACCESS.2019.2946392. |
| ID362 | H. Chen, H.F. Leung, B. Han, J. Su, Automatic privacy leakage detection for massive androapps via a novel hybrapproach, in: IEEE Int. Conf. Commun., Institute of Electrical and Electronics Engineers Inc., 2017. https://doi.org/10.1109/ICC.2017.7996335. |
| ID363 | K. Basu, S.S. Hussain, U. Gupta, R. Karri, COPPTCHA: COPPA Tracking by Checking Hardware-Level Activity, IEEE Trans. Inf. Forensics Secur. 15 (2020) 3213-3226. https://doi.org/10.1109/TIFS.2020.2983287. |
| ID365 | J. Wettlaufer, H. Simo, Decision support for mobile app selection via automated privacy assessment, in: IFIP Adv. Inf. Commun. Technol., Springer, 2020: pp. 292–307. https://doi.org/10.1007/978-3-030-42504-3_19. |
| ID382 | J. Reardon, βü. Feal, P. Wijesekera, A.E.B. On, N. Vallina-Rodriguez, S. Egelman, 50 Ways to Leak Your Data: An Exploration of Apps’ Circumvention of the AndroPermissions System, in: 28th USENIX Secur. Symp. (USENIX Secur. 19), USENIX Association, Santa Clara, CA, 2019: pp. 603–620. https://www.usenix.org/conference/usenixsecurity19/presentation/reardon. |
| ID384 | M. Hatamian, J. Serna, K. Rannenberg, B. Igler, FAIR: Fuzzy alarming index rule for privacy analysis in smartphone apps, in: Lect. Notes Comput. Sci. (Including Subser. Lect. Notes Artif. Intell. Lect. Notes Bioinformatics), Springer Verlag, 2017: pp. 3–18. https://doi.org/10.1007/978-3-319-64483-7_1. |
| ID412 | G. Ascia, V. Catania, R. Di Natale, A. Fornaia, M. Mongiovi, S. Monteleone, G. Pappalardo, E. Tramontana, Making androapps data-leaksafe by data flow analysis and code injection, in: Proc.—25th IEEE Int. Conf. Enabling Technol. Infrastruct. Collab. Enterp. WETICE 2016, Institute of Electrical and Electronics Engineers Inc., 2016: pp. 205–210. https://doi.org/10.1109/WETICE.2016.53. |
| ID452 | L.H. Tuan, N.T. Cam, V.H. Pham, Enhancing the accuracy of static analysis for detecting sensitive data leakage in Androby using dynamic analysis, Cluster Comput. 22 (2019) 1079-1085. https://doi.org/10.1007/s10586-017-1364-8. |
| ID484 | G. Xu, W. Wang, L. Jiao, X. Li, K. Liang, X. Zheng, W. Lian, H. Xian, H. Gao, SoProtector: Safeguard Privacy for Native SO Files in Evolving Mobile IoT Applications, IEEE Internet Things J. 7 (2020) 2539–2552. https://doi.org/10.1109/JIOT.2019.2944006. |
| ID495 | A. Hamed, H.K. Ben Ayed, Privacy risk assessment and users’ awareness for mobile apps permissions, in: Proc. IEEE/ACS Int. Conf. Comput. Syst. Appl. AICCSA, IEEE Computer Society, 2016. https://doi.org/10.1109/AICCSA.2016.7945694. |
| ID501 | M. Eskandari, B. Kessler, M. Ahmad, A.S. de Oliveira, B. Crispo, Analysing Remote Server Locations for Personal Data Transfers in Mobile Apps, Proc. Priv. Enhancing Technol. 2017 (2016) 118–131. https://doi.org/10.1515/popets-2017-0008. |
| ID539 | M. Sun, T. Wei, J.C.S. Lui, TaintART: A practical multi-level information-flow tracking system for AndroRunTime, in: Proc. ACM Conf. Comput. Commun. Secur., Association for Computing Machinery, 2016: pp. 331–342. https://doi.org/10.1145/2976749.2978343. |
| ID541 | T. Watanabe, M. Akiyama, T. Sakai, T. Mori, Understanding the Inconsistencies between Text Descriptions and the Use of Privacy-sensitive Resources of Mobile Apps, in: Elev. Symp. Usable Priv. Secur. (SOUPS 2015), USENIX Association, Ottawa, 2015: pp. 241–255. https://www.usenix.org/conference/soups2015/proceedings/presentation/watanabe. |
| ID565 | Z. Qu, S. Alam, Y. Chen, X. Zhou, W. Hong, R. Riley, DyDroid: Measuring Dynamic Code Loading and Its Security Implications in AndroApplications, in: Proc.—47th Annu. IEEE/IFIP Int. Conf. Dependable Syst. Networks, DSN 2017, Institute of Electrical and Electronics Engineers Inc., 2017: pp. 415–426. https://doi.org/10.1109/DSN.2017.14. |
| ID589 | L.L. Zhang, C.J.M. Liang, Z.L. Li, Y. Liu, F. Zhao, E.H. Chen, Characterizing Privacy Risks of Mobile Apps with Sensitivity Analysis, IEEE Trans. Mob. Comput. 17 (2018) 279–292. https://doi.org/10.1109/TMC.2017.2708716. |
| ID593 | Q. Qian, J. Cai, M. Xie, R. Zhang, Malicious Behavior Analysis for AndroApplications, 2016. |
| ID596 | B. Andow, S.Y. Mahmud, J. Whitaker, W. Enck, B. Reaves, K. Singh, S. Egelman, Actions Speak Louder than Words: Entity-Sensitive Privacy Policy and Data Flow Analysis with PoliCheck, in: 29th USENIX Secur. Symp. (USENIX Secur. 20), USENIX Association, 2020: pp. 985–1002. https://www.usenix.org/conference/usenixsecurity20/presentation/andow. |
| ID597 | Y. Zhang, T. Tan, Y. Li, J. Xue, Ripple: Reflection analysis for androapps in incomplete information environments, in: CODASPY 2017—Proc. 7th ACM Conf. Data Appl. Secur. Priv., Association for Computing Machinery, Inc, 2017: pp. 281–288. https://doi.org/10.1145/3029806.3029814. |
| ID611 | N.W. Lo, K.H. Yeh, C.Y. Fan, Leakage Detection and Risk Assessment on Privacy for AndroApplications: LRPdroid, IEEE Syst. J. 10 (2016) 1361–1369. https://doi.org/10.1109/JSYST.2014.2364202. |
| ID626 | W. Choi, J. Kannan, D. Babic, A scalable, flow-and-context-sensitive taint analysis of androapplications, J. Vis. Lang. Comput. 51 (2019) 1–14. https://doi.org/10.1016/j.jvlc.2018.10.005. |
| ID627 | E.P. Papadopoulos, M. Diamantaris, P. Papadopoulos, T. Petsas, S. Ioannidis, E.P. Markatos, The long-standing privacy debate: Mobile websites Vs mobile apps, in: 26th Int. World Wide Web Conf. WWW 2017, International World Wide Web Conferences Steering Committee, 2017: pp. 153–162. https://doi.org/10.1145/3038912.3052691. |
| ID635 | M. Hatamian, N. Momen, L. Fritsch, K. Rannenberg, A Multilateral Privacy Impact Analysis Method for AndroApps, in: Lect. Notes Comput. Sci. (Including Subser. Lect. Notes Artif. Intell. Lect. Notes Bioinformatics), Springer Verlag, 2019: pp. 87–106. https://doi.org/10.1007/978-3-030-21752-5_7. |
| ID636 | S. Wu, P. Wang, X. Li, Y. Zhang, Effective detection of andromalware based on the usage of data flow APIs and machine learning, Inf. Softw. Technol. 75 (2016) 17–25. https://doi.org/10.1016/j.infsof.2016.03.004. |
| ID657 | S. Lee, J. Dolby, S. Ryu, Hybridroid: Static analysis framework for androhybrapplications, in: ASE 2016—Proc. 31st IEEE/ACM Int. Conf. Autom. Softw. Eng., Association for Computing Machinery, Inc, New York, NY, USA, 2016: pp. 250-261. https://doi.org/10.1145/2970276.2970368. |
| ID658 | J. Malik, R. Kaushal, CREDROid: Andromalware detection by network traffic analysis, in: PAMCO 2016—Proc. 2nd MobiHoc Int. Work. Privacy-Aware Mob. Comput., Association for Computing Machinery, Inc, 2016: pp. 28–36. https://doi.org/10.1145/2940343.2940348. |
| ID666 | S. Bhandari, F. Herbreteau, V. Laxmi, A. Zemmari, M.S. Gaur, P.S. Roop, SneakLeak+: Large-scale klepto apps analysis, Futur. Gener. Comput. Syst. 109 (2020) 593–603. https://doi.org/10.1016/j.future.2018.05.047. |
| ID669 | R.S. Arslan, I.A. Doǧru, N. Barişçi, Permission-Based Malware Detection System for AndroUsing Machine Learning Techniques, Int. J. Softw. Eng. Knowl. Eng. 29 (2019) 43–61. https://doi.org/10.1142/S0218194019500037. |
| ID671 | J. Xie, X. Fu, X. Du, B. Luo, M. Guizani, AutoPatchDroid: A framework for patching inter-app vulnerabilities in androapplication, in: IEEE Int. Conf. Commun., Institute of Electrical and Electronics Engineers Inc., 2017. https://doi.org/10.1109/ICC.2017.7996682. |
| ID692 | B. Buddhadev, P. Faruki, M.S. Gaur, S. Kharche, A. Zemmari, FloVasion: Towards Detection of non-sensitive Variable Based Evasive Information-Flow in AndroApps, IETE J. Res. (2020). https://doi.org/10.1080/03772063.2020.1721338. |
| ID704 | Z. Cheng, X. Chen, Y. Zhang, S. Li, J. Xu, MUI-defender: CNN-driven, network flow-based information theft detection for mobile users, in: Lect. Notes Inst. Comput. Sci. Soc. Telecommun. Eng. LNICST, Springer Verlag, 2019: pp. 329–345. https://doi.org/10.1007/978-3-030-12981-1_23. |
| ID706 | E. Pan, J. Ren, M. Lindorfer, C. Wilson, D. Choffnes, Panoptispy: Characterizing Audio and Video Exfiltration from AndroApplications, Proc. Priv. Enhancing Technol. 2018 (2018) 33–50. https://doi.org/10.1515/popets-2018-0030. |
| ID730 | J.C.J. Keng, L. Jiang, T.K. Wee, R.K. Balan, Graph-aided directed testing of androapplications for checking runtime privacy behaviours, in: Proc.—11th Int. Work. Autom. Softw. Test, AST 2016, Association for Computing Machinery, Inc, 2016: pp. 57–63. https://doi.org/10.1145/2896921.2896930. |
| ID771 | X. Liu, J. Liu, S. Zhu, W. Wang, X. Zhang, Privacy risk analysis and mitigation of analytics libraries in the androecosystem, IEEE Trans. Mob. Comput. 19 (2020) 1184–1199. https://doi.org/10.1109/TMC.2019.2903186. |
| ID783 | H. Fu, Z. Zheng, S. Bose, M. Bishop, P. Mohapatra, LeakSemantic: identifying abnormal sensitive network transmissions in mobile applications, in: Proc.—IEEE INFOCOM, Institute of Electrical and Electronics Engineers Inc., 2017. https://doi.org/10.1109/INFOCOM.2017.8057221. |
| ID813 | J. Ren, M. Lindorfer, D.J. Dubois, A. Rao, D. Choffnes, N. Vallina-Rodriguez, Bug Fixes, Improvements, … and Privacy Leaks—A Longitudinal Study of PII Leaks Across AndroApp Versions, in: Proc. 2018 Netw. Distrib. Syst. Secur. Symp., Internet Society, Reston, VA, 2018. https://doi.org/10.14722/ndss.2018.23143. |
| ID827 | Y. He, L. Zhang, Z. Yang, Y. Cao, K. Lian, S. Li, W. Yang, Z. Zhang, M. Yang, Y. Zhang, H. Duan, TextExerciser: Feedback-driven text input exercising for androapplications, in: Proc.—IEEE Symp. Secur. Priv., Institute of Electrical and Electronics Engineers Inc., 2020: pp. 1071–1087. https://doi.org/10.1109/SP40000.2020.00071. |
| ID829 | Z. Meng, Y. Xiong, W. Huang, L. Qin, X. Jin, H. Yan, AppScalpel: Combining static analysis and outlier detection to identify and prune undesirable usage of sensitive data in Androapplications, Neurocomputing. 341 (2019) 10–25. https://doi.org/10.1016/j.neucom.2019.01.105. |
| ID842 | M. Diamantaris, E.P. Papadopoulos, E.P. Markatos, S. Ioannidis, J. Polakis, Reaper: Real-time app analysis for augmenting the andropermission system, in: CODASPY 2019—Proc. 9th ACM Conf. Data Appl. Secur. Priv., Association for Computing Machinery, Inc, 2019: pp. 37–48. https://doi.org/10.1145/3292006.3300027. |
| ID846 | M. Oltrogge, E. Derr, C. Stransky, Y. Acar, S. Fahl, C. Rossow, G. Pellegrino, S. Bugiel, M. Backes, The Rise of the Citizen Developer: Assessing the Security Impact of Online App Generators, in: Proc.—IEEE Symp. Secur. Priv., Institute of Electrical and Electronics Engineers Inc., 2018: pp. 634–647. https://doi.org/10.1109/SP.2018.00005. |
| ID893 | T. Wu, Y. Yang, Detecting AndroInter-App Data Leakage Via Compositional Concolic Walking, Intell. Autom. Soft Comput. (2019). https://doi.org/10.31209/2019.100000079. |
| ID902 | M. Graa, N. Cuppens-Boulahia, F. Cuppens, J.L. Lanet, R. Moussaileb, Detection of side channel attacks based on data tainting in androsystems, in: IFIP Adv. Inf. Commun. Technol., Springer New York LLC, 2017: pp. 205–218. https://doi.org/10.1007/978-3-319-58469-0_14. |
| ID908 | X. Pan, X. Wang, Y. Duan, X. Wang, H. Yin, Dark Hazard: Learning-based, Large-Scale Discovery of Hidden Sensitive Operations in AndroApps, in: Proc. 2017 Netw. Distrib. Syst. Secur. Symp., Internet Society, Reston, VA, 2017. https://doi.org/10.14722/ndss.2017.23265. |
| ID915 | R. Salvia, P. Ferrara, F. Spoto, A. Cortesi, SDLI: Static Detection of Leaks Across Intents, in: Proc.—17th IEEE Int. Conf. Trust. Secur. Priv. Comput. Commun. 12th IEEE Int. Conf. Big Data Sci. Eng. Trust. 2018, Institute of Electrical and Electronics Engineers Inc., 2018: pp. 1002–1007. https://doi.org/10.1109/TrustCom/BigDataSE.2018.00141. |
| ID955 | L. Yu, T. Zhang, X. Luo, L. Xue, H. Chang, Toward Automatically Generating Privacy Policy for AndroApps, IEEE Trans. Inf. Forensics Secur. 12 (2017) 865–880. https://doi.org/10.1109/TIFS.2016.2639339. |
| ID967 | G. Barbon, A. Cortesi, P. Ferrara, E. Steffinlongo, DAPA: Degradation-aware privacy analysis of Androapps, in: Lect. Notes Comput. Sci. (Including Subser. Lect. Notes Artif. Intell. Lect. Notes Bioinformatics), Springer Verlag, 2016: pp. 32–46. https://doi.org/10.1007/978-3-319-46598-2_3. |
References
- Privacy and Data Protection in Mobile Applications—ENISA. Available online: https://www.enisa.europa.eu/publications/privacy-and-data- (accessed on 16 August 2021).
- Gamba, J.; Rashed, M.; Razaghpanah, A.; Tapiador, J.; Vallina-Rodriguez, N. An analysis of pre-installed android software. In Proceedings of the IEEE Symposium on Security and Privacy, San Francisco, CA, USA, 18–21 May 2020; pp. 1039–1055. [Google Scholar]
- Balebako, R.; Marsh, A.; Lin, J.; Hong, J.; Faith Cranor, L. The Privacy and Security Behaviors of Smartphone App Developers. In Proceedings of the 2014 Workshop on Usable Security, Reston, VA, USA, 23 February 2014. [Google Scholar] [CrossRef]
- IDC—Smartphone Market Share—OS. Available online: https://www.idc.com/promo/smartphone-market-share (accessed on 16 August 2021).
- Zang, J.; Dummit, K.; Graves, J.; Lisker, P.; Sweeney, L. Who Knows What About Me? A Survey of Behind the Scenes Personal Data Sharing to Third Parties by Mobile Apps. Technol. Sci. 2015, 30, 1–53. [Google Scholar]
- Li, L.; Bissyandé, T.F.; Papadakis, M.; Rasthofer, S.; Bartel, A.; Octeau, D.; Klein, J.; Traon, L. Static analysis of android apps: A systematic literature review. Inf. Softw. Technol. 2017, 88, 67–95. [Google Scholar] [CrossRef] [Green Version]
- Sadeghi, A.; Bagheri, H.; Garcia, J.; Malek, S. A Taxonomy and Qualitative Comparison of Program Analysis Techniques for Security Assessment of Android Software. IEEE Trans. Softw. Eng. 2017, 43, 492–530. [Google Scholar] [CrossRef]
- Liu, K.; Xu, S.; Xu, G.; Zhang, M.; Sun, D.; Liu, H. A Review of Android Malware Detection Approaches Based on Machine Learning. IEEE Access 2020, 8, 124579–124607. [Google Scholar] [CrossRef]
- Pan, Y.; Ge, X.; Fang, C.; Fan, Y. A Systematic Literature Review of Android Malware Detection Using Static Analysis. IEEE Access 2020, 8, 116363–116379. [Google Scholar] [CrossRef]
- Garg, S.; Baliyan, N. Android security assessment: A review, taxonomy and research gap study. Comput. Secur. 2021, 102087. [Google Scholar] [CrossRef]
- Wuyts, K. Privacy Threats in Software Architectures. 2015, p. 192. Available online: https://limo.libis.be/primo-explore/fulldisplay?docid=LIRIAS1656390&context=L&vid=Lirias&search_scope=Lirias&tab=default_tab&lang=en_US&fromSitemap=1 (accessed on 16 August 2021).
- Hansen, M.; Jensen, M.; Rost, M. Protection goals for privacy engineering. In Proceedings of the 2015 IEEE Security and Privacy Workshops, San Jose, CA, USA, 21–22 May 2015; pp. 159–166. [Google Scholar] [CrossRef]
- Stevens, R.; Gibler, C.; Crussell, J.; Erickson, J.; Chen, H. Investigating User Privacy in Android Ad Libraries. In Workshop on Mobile Security Technologies (MoST); Citeseer: Philadelphia, PA, USA, 2012; Volume 10, pp. 195–197. [Google Scholar]
- About Android App Bundle|Android Developers. Available online: https://developer.android.com/guide/app-bundle (accessed on 16 August 2021).
- Bourque, P.; Dupuis, R.; Abran, A.; Moore, J.W.; Tripp, L. Guide to the Software Engineering Body of Knowledge, Version 3.0; IEEE: Piscataway, NJ, USA, 2014. [Google Scholar]
- Alsharif, M.H.; Kelechi, A.H.; Yahya, K.; Chaudhry, S.A. Machine Learning Algorithms for Smart Data Analysis in Internet of Things Environment: Taxonomies and Research Trends. Symmetry 2020, 12, 88. [Google Scholar] [CrossRef] [Green Version]
- Kong, P.; Li, L.; Gao, J.; Liu, K.; Bissyandé, T.F.; Klein, J. Automated testing of Android apps: A systematic literature review. IEEE Trans. Reliab. 2019, 68, 45–66. [Google Scholar] [CrossRef] [Green Version]
- Wieringa, R.; Maiden, N.; Mead, N.; Rolland, C. Requirements engineering paper classification and evaluation criteria: A proposal and a discussion. Requir. Eng. 2006, 11, 102–107. [Google Scholar] [CrossRef]
- Petersen, K.; Vakkalanka, S.; Kuzniarz, L. Guidelines for conducting systematic mapping studies in software engineering: An update. In Information and Software Technology; Elsevier: Amsterdam, The Netherlands, 2015; Volume 64, pp. 1–18. [Google Scholar] [CrossRef]
- Cavacini, A. What is the best database for computer science journal articles? Scientometrics 2015, 102, 2059–2071. [Google Scholar] [CrossRef]
- 2017 IEEE Thesaurus Version 1.0 Created by the Institute of Electrical and Electronics Engineers (IEEE). Technical Report, IEEE. Available online: https://www.ieee.org/publications/services/thesaurus-access-page.html (accessed on 16 August 2021).
- Computing Classification System. Available online: https://dl.acm.org/ccs (accessed on 16 August 2021).
- ISO—ISO/IEC/IEEE 24765:2017—Systems and Software Engineering—Vocabulary. Available online: https://standards.iso.org/ittf/PubliclyAvailableStandards/c071952_ISO_IEC_IEEE_24765_2017.zip (accessed on 16 August 2021).
- Del Alamo, J.M.; Guaman, D.S.; Diez, A.; Balmori, B. Privacy Assessment in Android Apps: A Systematic Mapping Study. Mendeley Data 2021. [Google Scholar] [CrossRef]
- InCites—Clarivate Analytics. Available online: https://esi.clarivate.com/ (accessed on 16 August 2021).
- Krippendorff, K. Testing the reliability of content analysis data: What is involved and why. In The Content Analysis Reader; SAGE Publications: New York, NY, USA, 2009. [Google Scholar]
- Octeau, D.; Jha, S.; McDaniel, P. Retargeting Android applications to Java bytecode. In Proceedings of the ACM SIGSOFT 20th International Symposium on the Foundations of Software Engineering, Cary North, CA, USA, 11–16 November 2012. [Google Scholar] [CrossRef] [Green Version]
- Vallée-Rai, R.; Hendren, L.; Co, P.; Lam, P.; Gagnon, E.; Sundaresan, V. Soot—A Java bytecode optimization framework. In Proceedings of the CASCON ’10: CASCON First Decade High Impact Papers, Toronto, ON, Canada, 1–4 November 2010; pp. 214–224. [Google Scholar] [CrossRef]
- Miecznikowski, J.; Hendren, L. Decompiling Java bytecode: Problems, traps and pitfalls. In Lecture Notes in Computer Science (Including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics); Springer: Berlin/Heidelberg, Germany, 2002; Volume 2304, pp. 111–127. [Google Scholar] [CrossRef] [Green Version]
- Bartel, A.; Klein, J.; Monperrus, M. Dexpler: Converting android dalvik bytecode to jimple for static analysis with soot. In Proceedings of the ACM SIGPLAN International Workshop on State of the Art in Java Program Analysis, Beijing, China, 14 June 2012; pp. 27–38. [Google Scholar] [CrossRef] [Green Version]
- Octeau, D.; McDaniel, P.; Jha, S.; Bartel, A.; Bodden, E.; Klein, J.; Le Traon, Y. Effective inter-component communication mapping in android with epicc: An essential step towards holistic security analysis. In Proceedings of the 22nd USENIX Security Symposium, Washington, DC, USA, 14–16 August 2013; pp. 543–558. [Google Scholar]
- Octeau, D.; Luchaup, D.; Dering, M.; Jha, S.; McDaniel, P. Composite constant propagation: Application to android inter-component communication analysis. In Proceedings of the International Conference on Software Engineering, Florence, Italy, 16–24 May 2015; Volume 1, pp. 77–88. [Google Scholar] [CrossRef]
- Li, L.; Bartel, A.; Bissyandé, T.F.; Klein, J.; Traon, Y.L.; Arzt, S.; Rasthofer, S.; Bodden, E.; Octeau, D.; McDaniel, P. IccTA: Detecting inter-component privacy leaks in android apps. In Proceedings of the International Conference on Software Engineering, Florence, Italy, 16–24 May 2015; Volume 1, pp. 280–291. [Google Scholar] [CrossRef] [Green Version]
- IDA Pro—Hex Rays. Available online: https://hex-rays.com/ida-pro/ (accessed on 16 August 2021).
- Choudhary, S.R.; Gorla, A.; Orso, A. Automated Test Input Generation for Android: Are We There Yet? In Proceedings of the 2015 30th IEEE/ACM International Conference on Automated Software Engineering, Lincoln, NE, USA, 9–13 November 2015; pp. 429–440. [Google Scholar]
- Gürses, S. Can you engineer privacy? Commun. ACM 2014, 57, 20–23. [Google Scholar] [CrossRef]
- Nissenbaum, H. Privacy as contextual integrity. Wash. Law Rev. 2004, 79, 119–157. [Google Scholar]
- ARTICLE 29 DATA PROTECTION WORKING PARTY Opinion 02/2013 on Apps on Smart Devices. Available online: https://ec.europa.eu/justice/article-29/documentation/opinion-recommendation/files/2013/wp202_en.pdf (accessed on 16 August 2021).
- Trade Commission, F. Mobile privacy disclosures: Building trust through transparency. In Mobile Privacy Disclosures: Recommendations of the Federal Trade Commission; Federal Trade Commission: Washington, DC, USA, 2013; pp. 1–34. [Google Scholar]
- Guaman, D.S.; Del Alamo, J.M.; Caiza, J.C. GDPR Compliance Assessment for Cross-border Personal Data Transfers in Android Apps. IEEE Access 2021, 9. [Google Scholar] [CrossRef]
- GDPR Fines & Data Breach Penalties. Available online: https://www.enforcementtracker.com/ (accessed on 16 August 2021).
- Castelluccia, C.; Gürses, S.; Hansen, M.; Hoepman, J.H.; Hoboken, J.V.; Vieira, B. Privacy and Data Protection in Mobile Applications: A Study on the App Development Ecosystem and the Technical Implementation of GDPR; ENISA: Athens, Greece, 2017; p. 70. [Google Scholar]
- Rashid, A.; Chivers, H.; Danezis, G.; Lupu, E.; Martin, A. The Cyber Security Body of Knowledge (CyBoK) 1.0; University of Bristol: Bristol, UK, 2019; p. 299. [Google Scholar]
- McIlroy, S.; Ali, N.; Khalid, H.; Hassan, A.E. Analyzing and automatically labelling the types of user issues that are raised in mobile app reviews. Empir. Softw. Eng. 2016, 21, 1067–1106. [Google Scholar] [CrossRef]
- Mobile Android Version Market Share Worldwide|StatCounter Global Stats. Available online: https://gs.statcounter.com/android-version-market-share/mobile/worldwide/ (accessed on 16 August 2021).
- Guaman, D.S.; Alamo, J.M.; Caiza, J.C. A Systematic Mapping Study on Software Quality Control Techniques for Assessing Privacy in Information Systems. IEEE Access 2020, 8, 74808–74833. [Google Scholar] [CrossRef]
- Ebrahimi, F.; Tushev, M.; Mahmoud, A. Mobile App Privacy in Software Engineering Research: A Systematic Mapping Study. Inf. Softw. Technol. 2019, 14, 106466. [Google Scholar] [CrossRef]









| Type of Assessment | Description |
|---|---|
| Validation | The authors demonstrate the feasibility of their contributions by means of an illustrative (demonstration) scenario. There is no formal proof of correctness nor empirical evaluation. |
| Formal proof | The authors assess the correctness of their contributions by means of mathematical proof. |
| Empirical evaluation | The authors assess the features of their proposal with experiments. Different properties can be evaluated such as the effectiveness or the performance of the proposal. The approach to report the results might be qualitative or quantitative. Different apps sets can be used in the evaluation process, e.g., ad-hoc custom sets developed/adapted by the authors, reference benchmarks containing apps with known privacy issues, or in-the-wild apps from real app stores. Finally, the evaluation may include the results comparison with other tools. |
| Name | Description | Samples |
|---|---|---|
| OPP-115 (https://usableprivacy.org/data) | Website privacy policies annotated with privacy practices | 115 |
| APP-350 (https://usableprivacy.org/data) | Android app privacy policies annotated with privacy practices | 350 |
| Androsec (http://androsec.rit.edu/home) | Dataset of Android applications including details on quality metrics and security characteristics of the applications such as adherence to coding standards, file size, lines of code, over and under permissions, and any defects or security vulnerabilities that may exist | 1179 |
| Drebin (https://www.sec.cs.tu-bs.de/~danarp/drebin/) | Malware repository including apps labelled with malware family, and other features extracted from the applications | 5560 |
| VirusShare (https://virusshare.com/ | Repository of malware samples for cybersecurity research | 36,643,433 * |
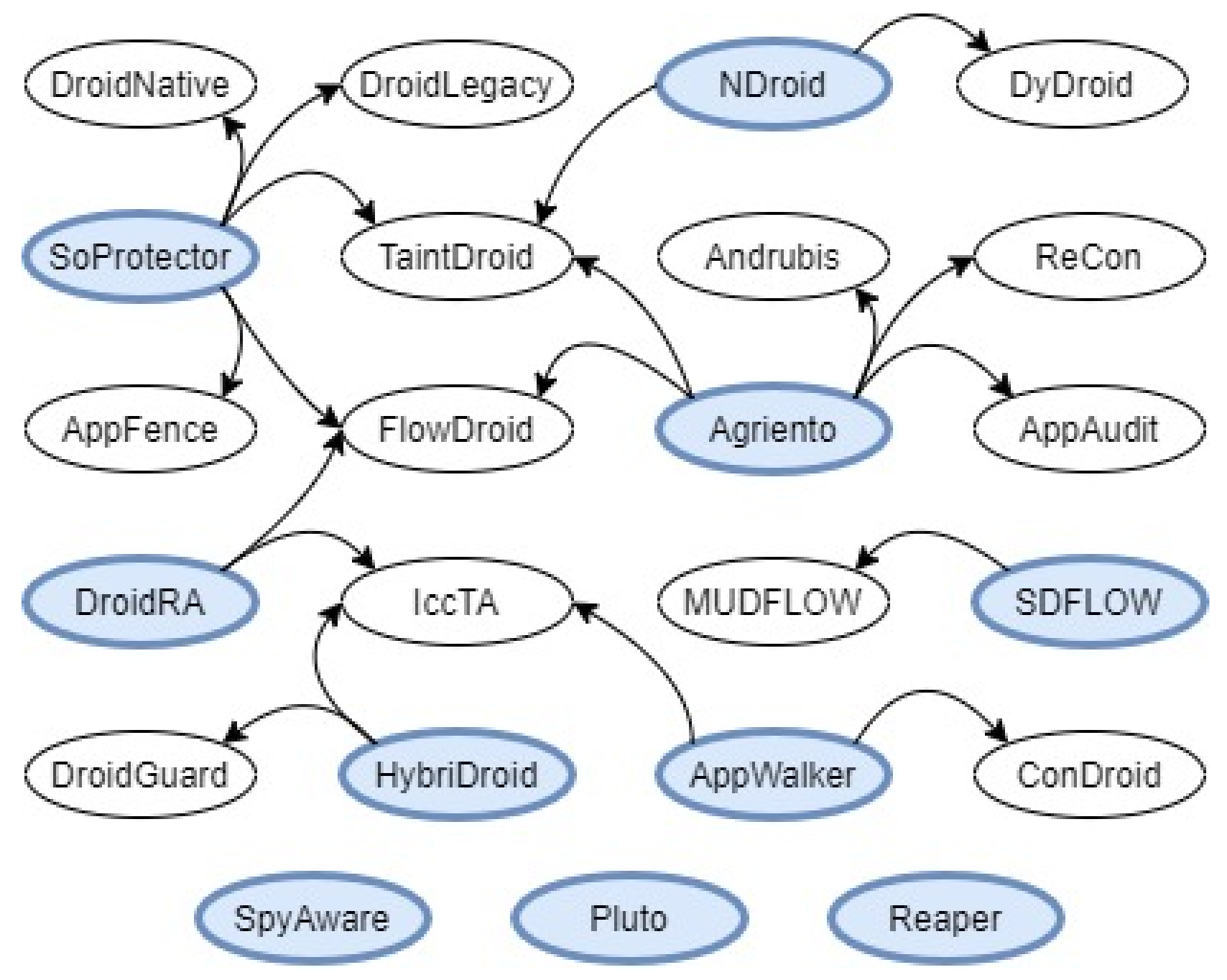
| Contribution | Open Source | Technique Type | Compared |
|---|---|---|---|
| SpyAware (ID249) | No | Dynamic + ML based | No |
| SoProtector (ID484) | No | Static + Dynamic | Yes |
| Agrigento (ID38) | Yes | Dynamic | Yes |
| DroidRA (ID77) | Yes | Static | Yes |
| NDroid (ID108) | Yes | Dynamic | Yes |
| SCDFLOW (ID126) | Yes | Static + ML based | Yes |
| Pluto (ID306) | Yes | Dynamic | No |
| HybriDroid (ID362) | Yes | Static | Yes |
| Reaper (ID842) | Yes | Dynamic | No |
| AppWalker (ID893) | Yes | Static + Dynamic | Yes |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Del Alamo, J.M.; Guaman, D.; Balmori, B.; Diez, A. Privacy Assessment in Android Apps: A Systematic Mapping Study. Electronics 2021, 10, 1999. https://doi.org/10.3390/electronics10161999
Del Alamo JM, Guaman D, Balmori B, Diez A. Privacy Assessment in Android Apps: A Systematic Mapping Study. Electronics. 2021; 10(16):1999. https://doi.org/10.3390/electronics10161999
Chicago/Turabian StyleDel Alamo, Jose M., Danny Guaman, Belen Balmori, and Ana Diez. 2021. "Privacy Assessment in Android Apps: A Systematic Mapping Study" Electronics 10, no. 16: 1999. https://doi.org/10.3390/electronics10161999